展开查看详情
1 .Design of BigQuery ML
Umar Syed
Google
�
2 .About me
• Researcher in machine learning at Google.
• Involved in design and implementation of BigQuery ML since its inception.
• Not a database expert!
�
3 .Agenda
What are BigQuery and BigQuery ML?
Design
Implementation
Discussion
Future work
�
4 .BigQuery
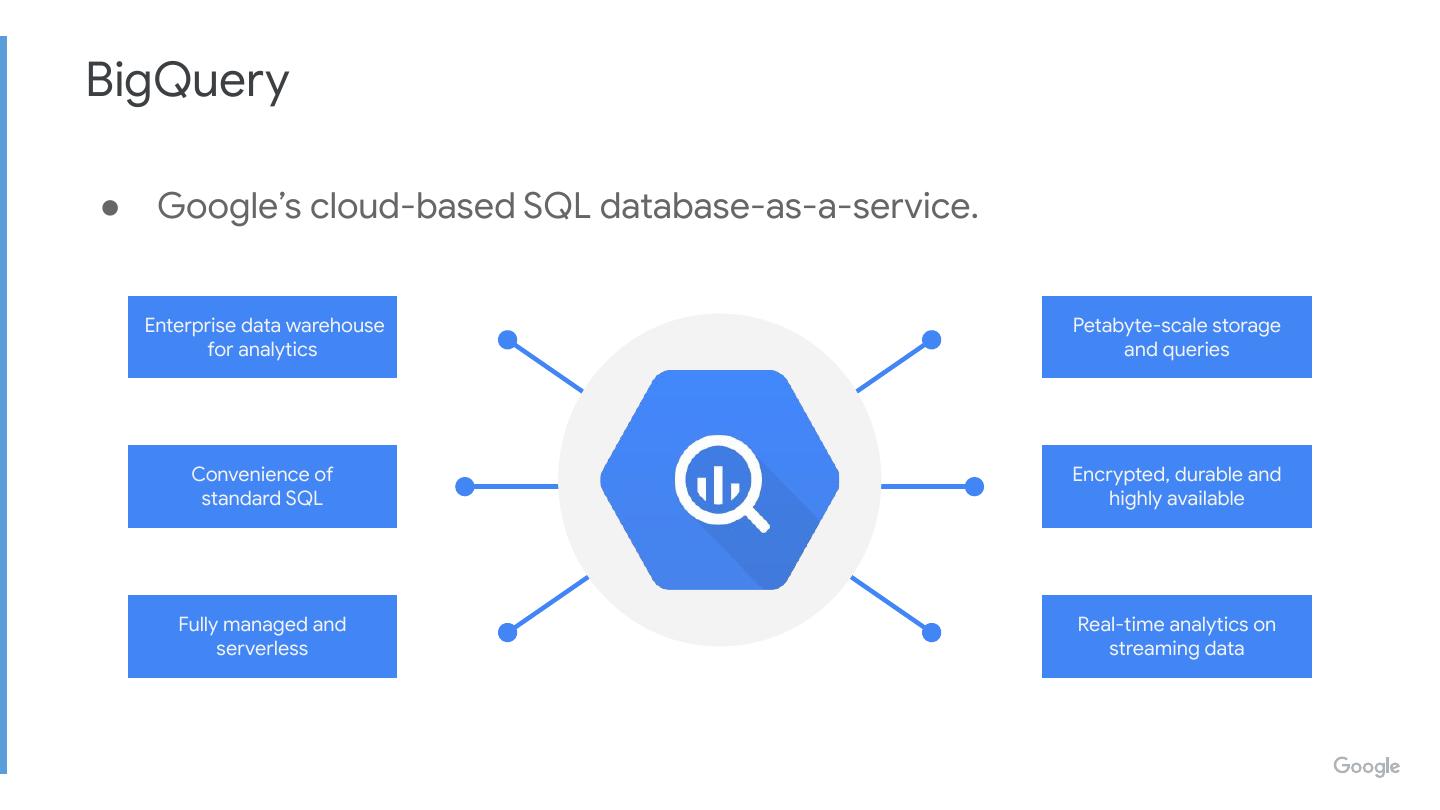
● Google’s cloud-based SQL database-as-a-service.
Enterprise data warehouse Petabyte-scale storage
for analytics and queries
Convenience of Encrypted, durable and
standard SQL highly available
Fully managed and Real-time analytics on
serverless streaming data
�
5 .BigQuery
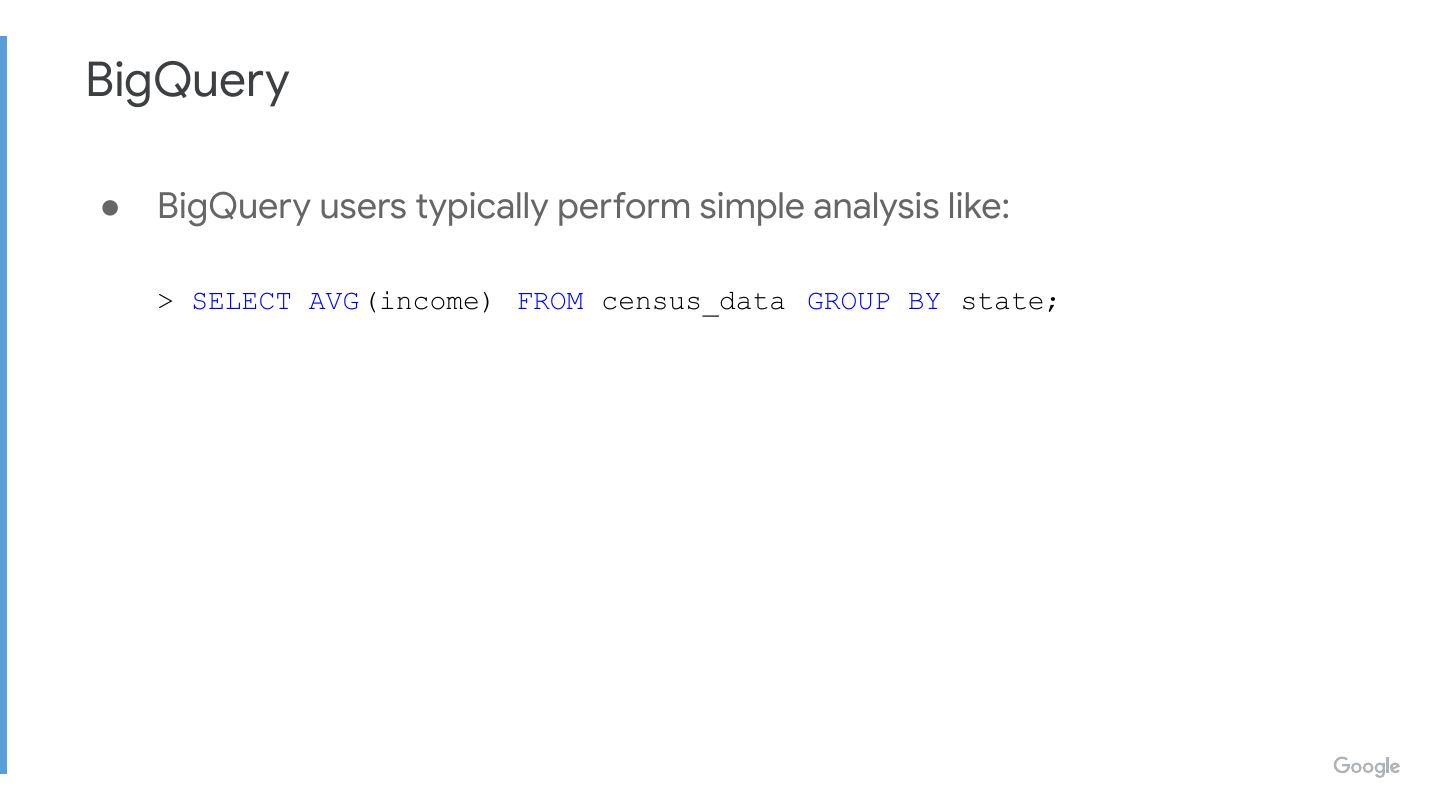
● BigQuery users typically perform simple analysis like:
> SELECT AVG (income) FROM census_data GROUP BY state;
�
6 .BigQuery ML
● With BigQuery ML, they can perform sophisticated analysis like:
> CREATE MODEL income_model
OPTIONS (model_type=‘linear_reg’, labels=[‘income’])
AS SELECT state, job, income FROM census_data;
> SELECT predicted_income FROM PREDICT (MODEL ‘income_model’,
SELECT state, job FROM customer_data);
● Enables in-database machine learning for BigQuery users.
�
7 .BigQuery ML
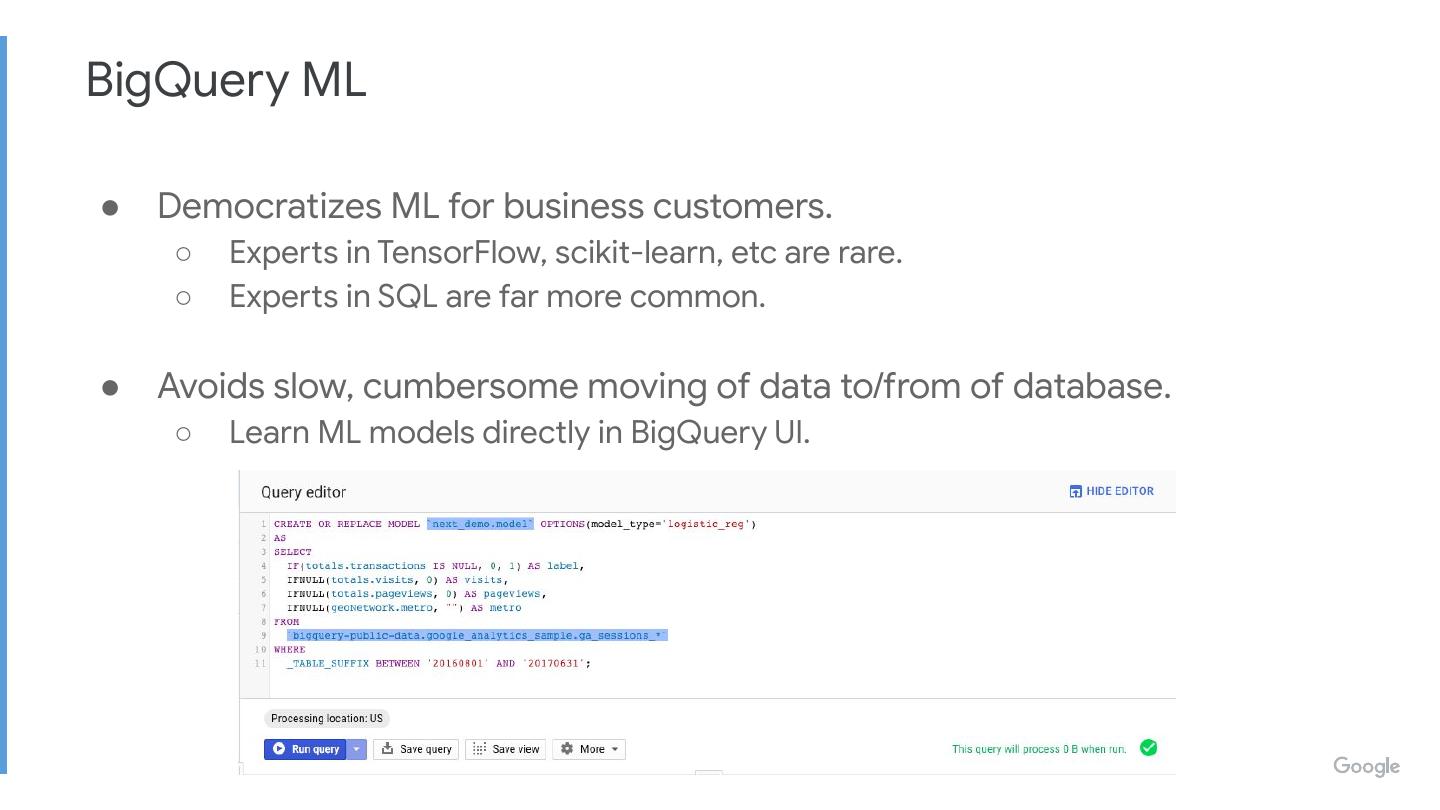
● Democratizes ML for business customers.
○ Experts in TensorFlow, scikit-learn, etc are rare.
○ Experts in SQL are far more common.
● Avoids slow, cumbersome moving of data to/from of database.
○ Learn ML models directly in BigQuery UI.
�
8 .Customer use cases
Customer churn Audience conversion Weather-based harsh driving
prediction prediction for media planning prediction for smart cities
Customer subscription Traffic prediction Automated IP address
prediction for smart cities threat prediction
Try it yourself at https://cloud.google.com/bigquery/
Send feedback to bqml-feedback@google.com
�
9 .Agenda
What are BigQuery and BigQuery ML?
Design
Implementation
Discussion
Future work
�
10 .Design desiderta
1. Adaptable to BigQuery infrastructure. While leveraging its strengths.
2. Scalable. No limit on dataset or model size.
○ Should easily handle billions of examples, millions of features.
3. General purpose. Able to learn many kinds of ML models.
�
11 .Design landscape
Published in-database ML systems can be divided into 3 categories:
Integrated system UDA-based system Pure SQL system
�
12 .Integrated system
● Query processing engine and ML algorithms are implemented on top of
common infrastructure.
● Example: Shark, a.k.a., Spark SQL.1
1
Xin, Rosen, Zaharia, Franklin, Shenker, Stoica (2012). Shark: SQL and rich analytics at scale.
�
13 .Disadvantages of integrated system
● Re-implementing BigQuery was totally infeasible in the short-term.
�
14 .UDA-based system
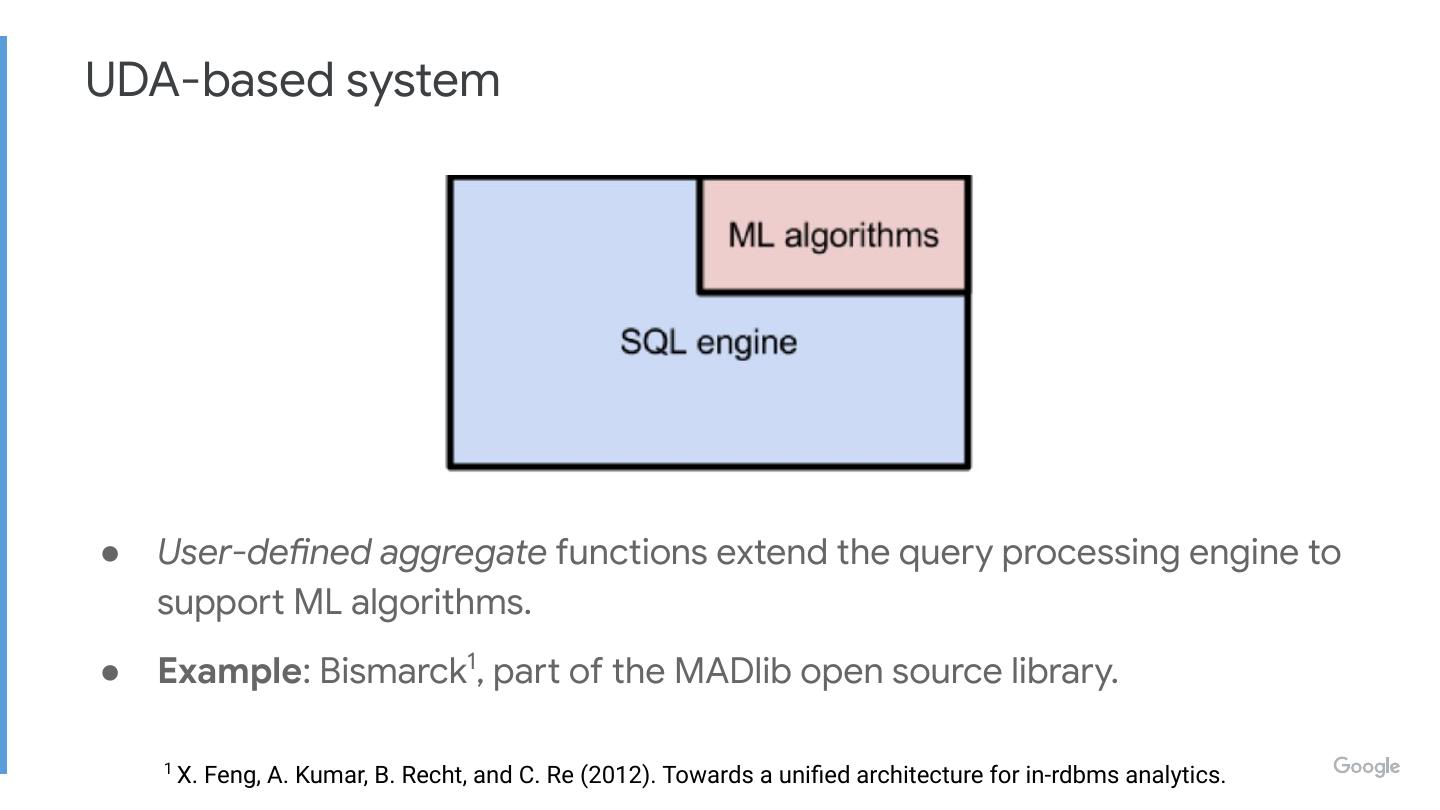
● User-defined aggregate functions extend the query processing engine to
support ML algorithms.
● Example: Bismarck1, part of the MADlib open source library.
1
X. Feng, A. Kumar, B. Recht, and C. Re (2012). Towards a unified architecture for in-rdbms analytics.
�
15 .Disadvantages of UDA-based system
● UDAs assume ML model can fit in memory.
○ ML model = State of the UDA.
● UDAs assume invariance to how data is distributed on disk.
○ Can lead to poor performance (we’ll see some experiments later).
�
16 .Pure SQL system
● ML algorithms are implemented in SQL; query processing engine itself is
unchanged.
● Examples: Clustering1, Naive Bayes classification.2
1
Ordonez (2006). Integrating k-means clustering with a relational DBMS using SQL.
2
Pitchaimalai and Ordonez (2009). Bayesian classifiers programmed in SQL.
�
17 .“Disadvantages” of pure SQL system
● Conventional wisdom held that pure SQL is inadequate for implementing
sophisticated ML algorithms.
● From the MADlib1 developers:
“The portable core of ‘vanilla’ SQL is often not quite enough to
express the kinds of algorithms needed for advanced analytics.”
● And yet BigQuery ML is a pure SQL system.
1
Hellerstein, Schoppmann, Wang, Fratkin, Gorajek, Ng, Welton, Feng, Li, Kumar (2012). The MADlib analytics
library or MAD skills, the SQL.
�
18 .Agenda
What are BigQuery and BigQuery ML?
Design
Implementation
Discussion
Future work
�
19 .Background: Generalized linear models
● A generalized linear model has the form:
where:
○ x is an example’s feature vector.
○ w is the model’s weight vector (or parameter vector).
○ p() is the model’s prediction function.
�
20 .Training a generalized linear model
● Collect labeled training examples (x1, y1), ..., (xn, yn).
● Minimize the objective:
where loss function ℓ() measures discrepancy between model’s prediction
for example xi and true label yi.
�
21 .Types of generalized linear models
● Many ML models can be expressed as generalized linear models:
�
22 .Training a generalized linear model
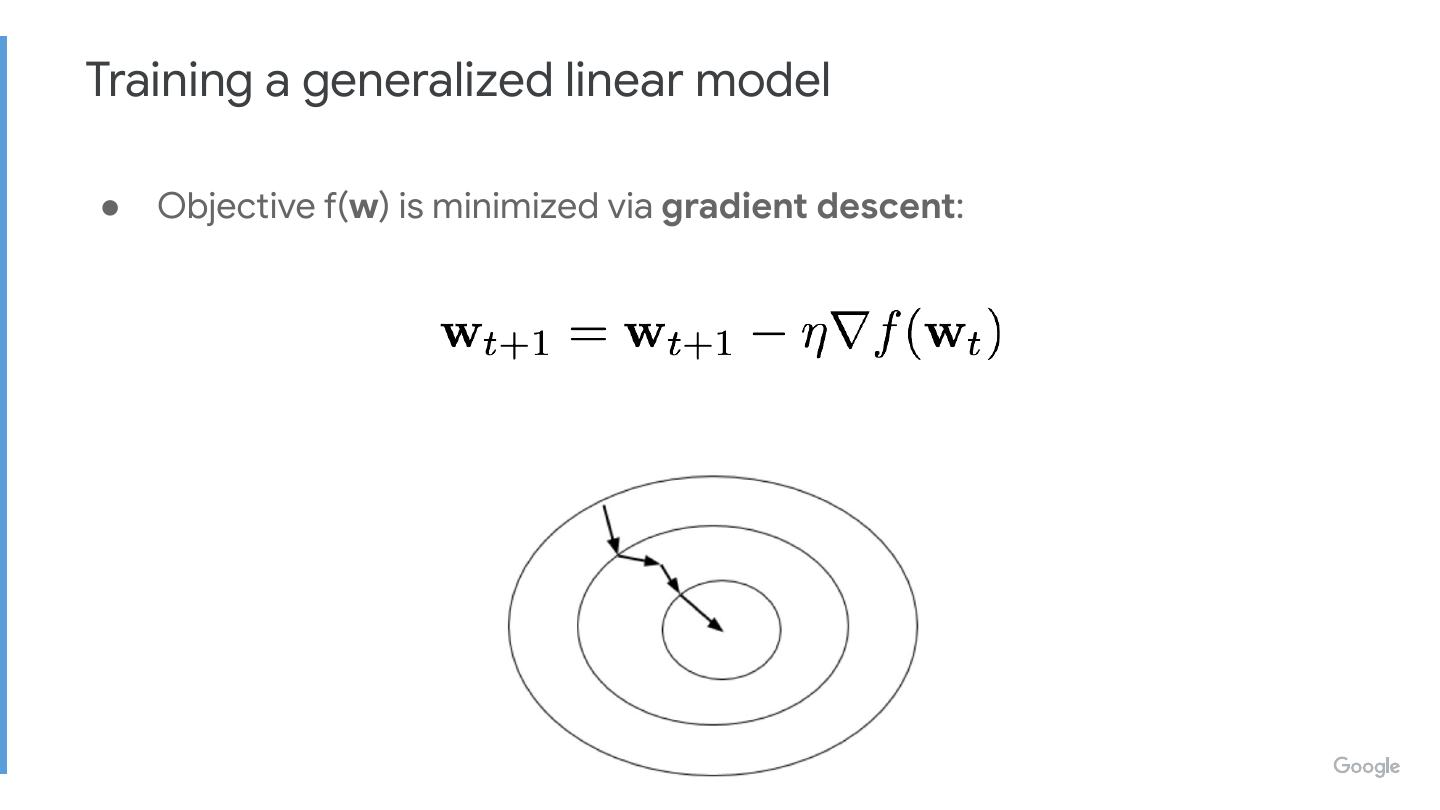
● Objective f(w) is minimized via gradient descent:
�
23 .Training a generalized linear model in BigQuery ML
● Gradient descent implemented as sequence of pure SQL queries.
● Both data and models are represented as tables:
data model
state job label feature weight
NY nurse 65 state:CA +5.7
CA chef 55 job:nurse -3.5
... ... ... ... ...
�
24 .Model training in BigQuery ML
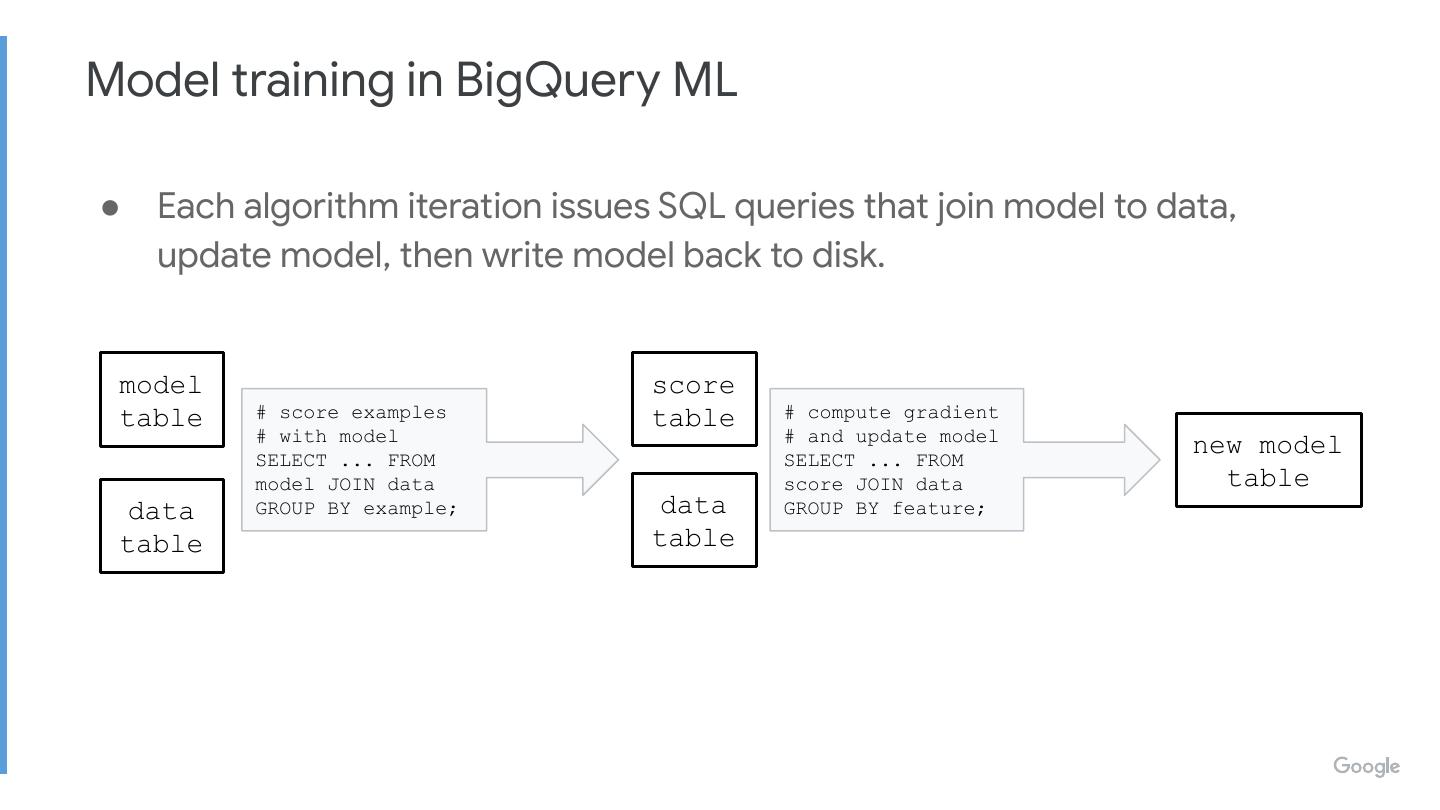
● Each algorithm iteration issues SQL queries that join model to data,
update model, then write model back to disk.
model score
table # score examples table # compute gradient
# with model # and update model
SELECT ... FROM SELECT ... FROM
new model
model JOIN data score JOIN data table
data GROUP BY example; data GROUP BY feature;
table table
�
25 .Model training in BigQuery ML
● Query to update model weights:
�
26 .Model training in BigQuery ML
● Query to compute inner products per example:
�
27 .Agenda
What are BigQuery and BigQuery ML?
Design
Implementation
Discussion
Future work
�
28 .Why a batch method?
● Modern ML algorithms tend to be “incremental”.
○ Many iterations, each processing a few examples.
● But BigQuery ML algorithm is “batch”.
○ Few iterations, each processing every example.
�
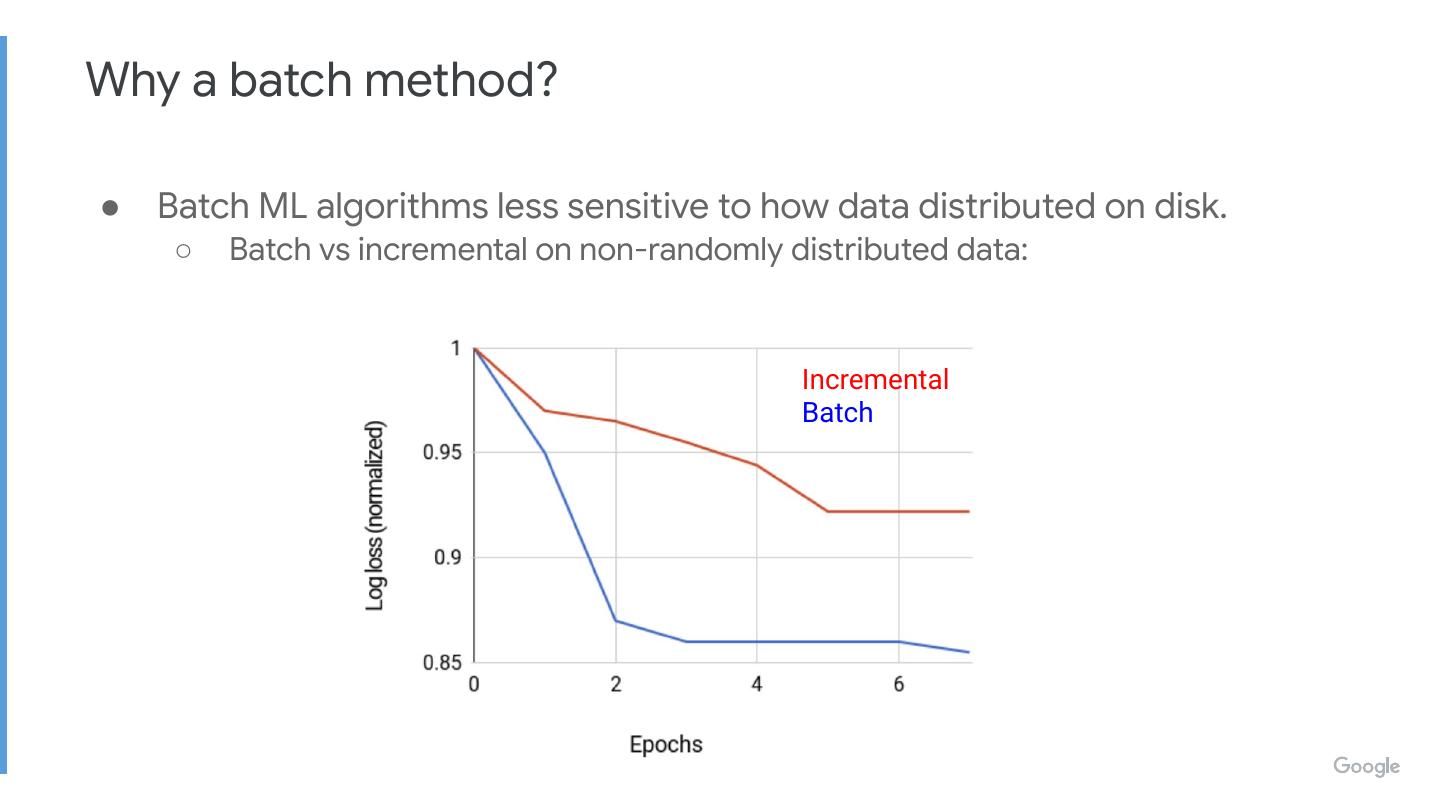
29 .Why a batch method?
● Incremental ML algorithms require efficient random sampling and access.
○ No support for this in BigQuery.
● Batch algorithm + BigQuery’s parallelism still yields good performance.
○ Can train model with 2B examples, 10M features in ~ 1 hour.
�