展开查看详情
1 .Lakehouse in Databricks
Wenchen Fan
�
2 .What is Lakehouse?
SQL on data lakes.
Compete with DWs for workloads:
- Interactive analysis
- Dashboarding / reporting / BI tools
- ETL
We started 7 years ago without calling it explicitly Lakehouse, and will
take multi years to build out the full vision
�
3 .Agenda
A brief history of SQL at Databricks
Our “plan”:
▪ UX (look and feel)
▪ SQL Language & Docs
▪ Catalog & Security
▪ Performance
�
6 .2013
Michael: I have this novel way of building a query optimizer,
and I can replace the optimizer component in Shark.
Reynold: Why not build a new SQL system from scratch?
Hive was too big of a baggage.
�
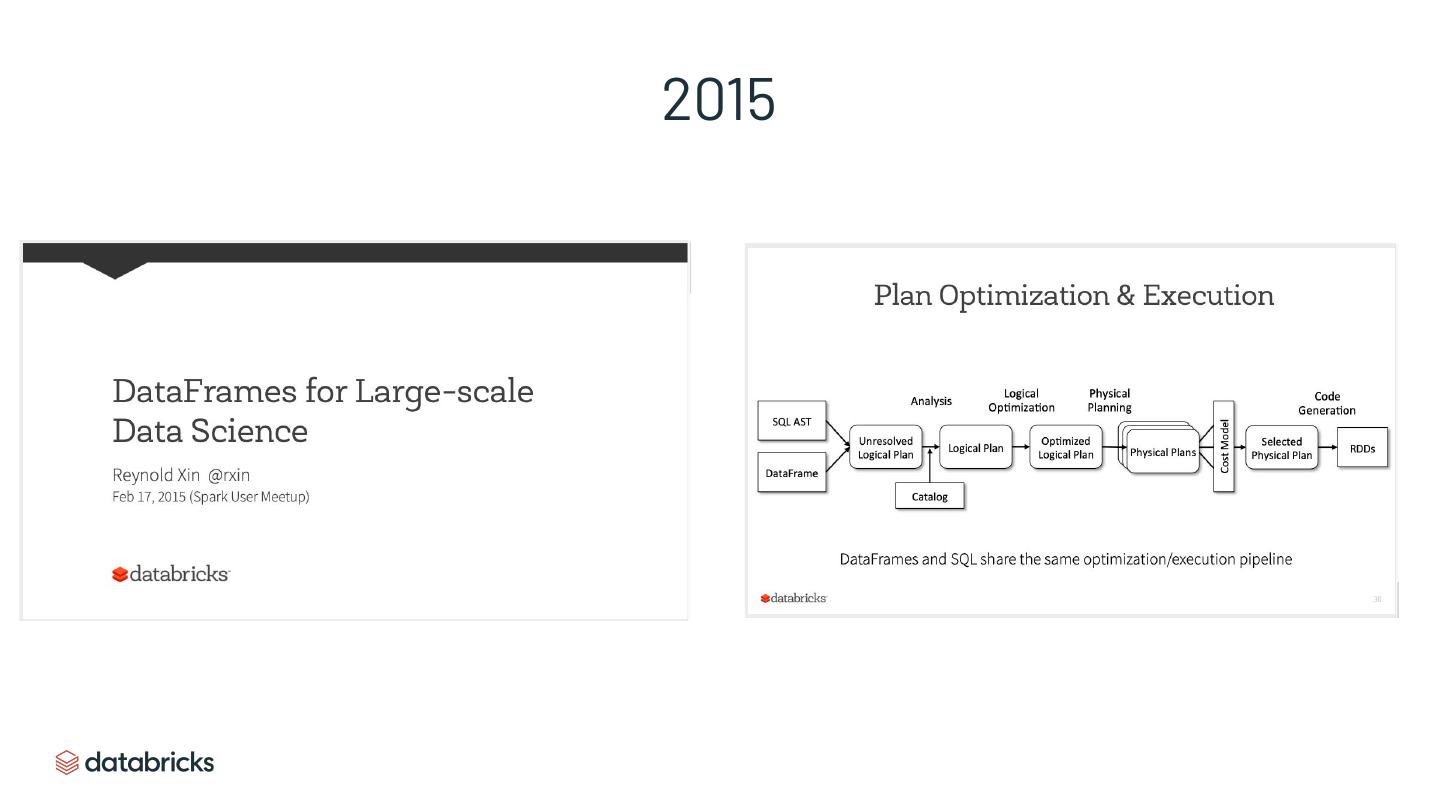
10 .Spark 2.0 wasn’t really “Spark” anymore
New APIs (DataFrame API)
New optimization and execution engine (codegen)
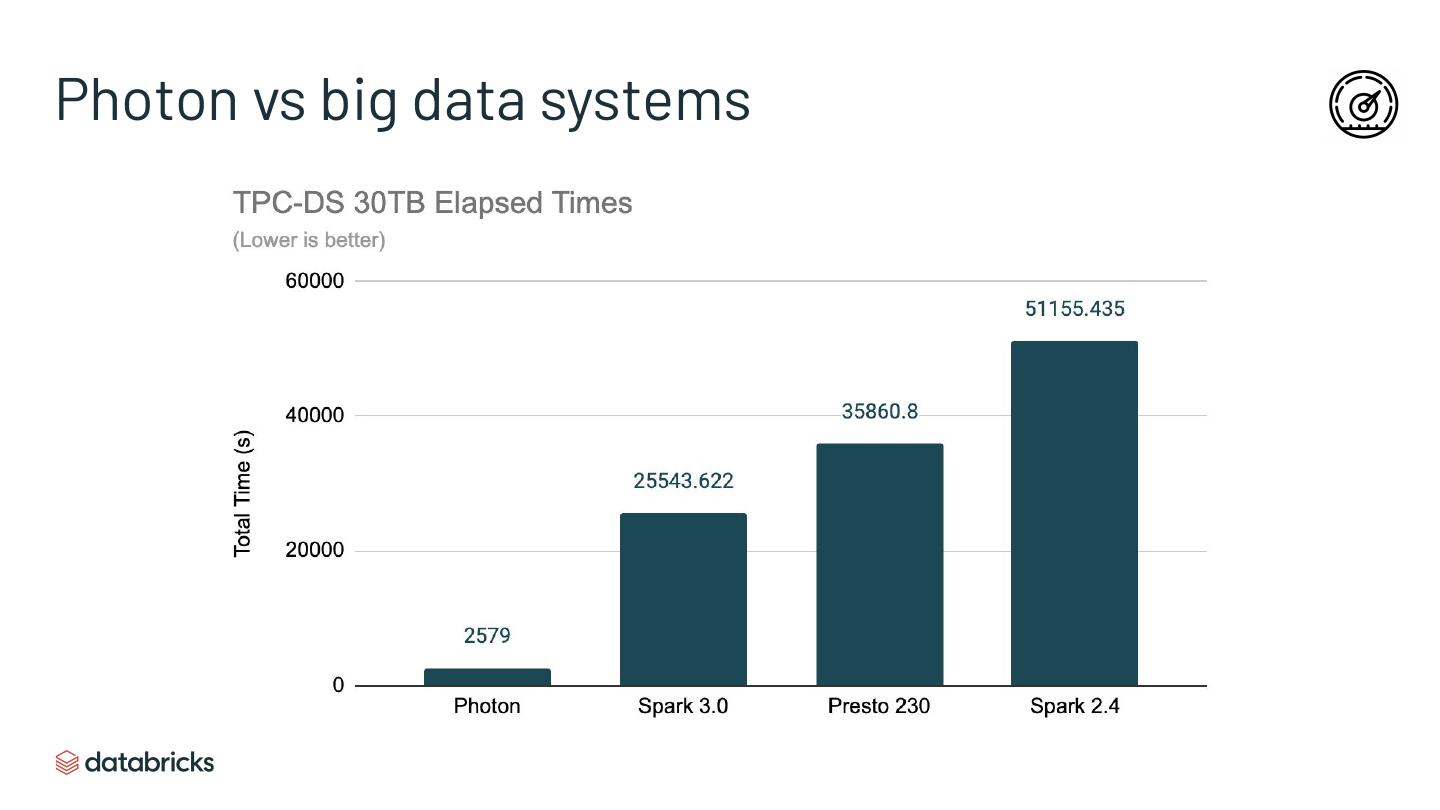
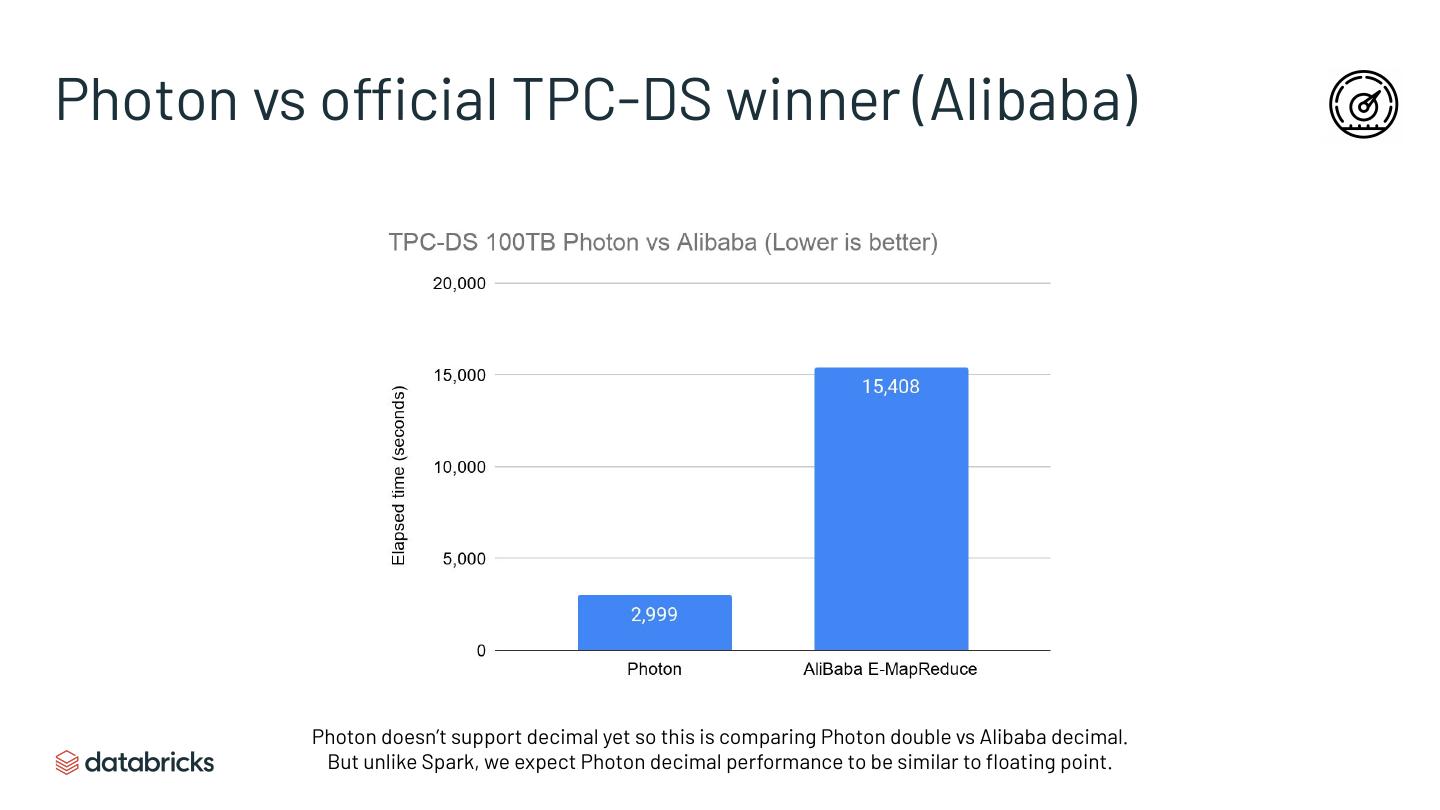
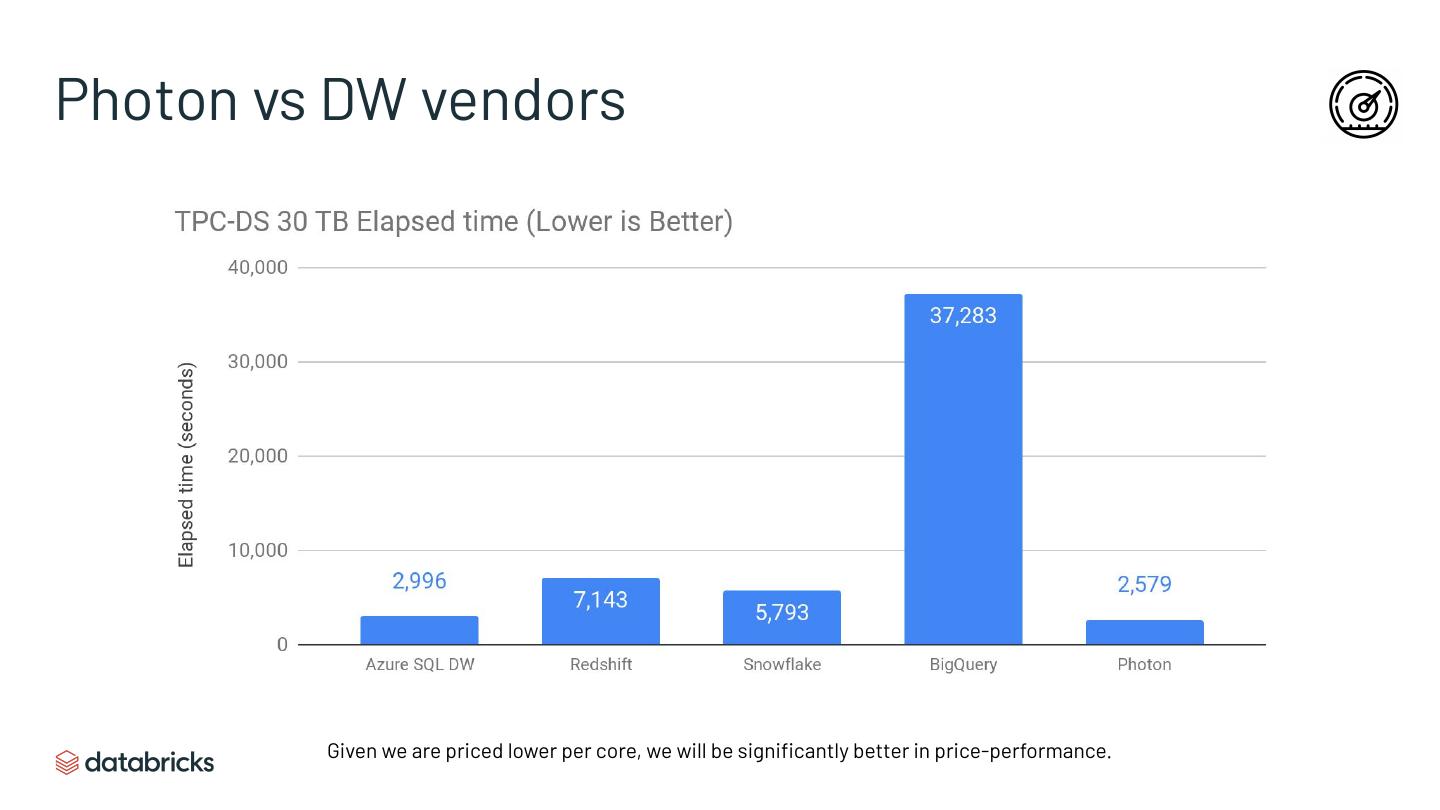
▪ Beats Hive/Presto by a large margin and even many DWs in performance
More complete SQL functionalities
▪ Could run all TPC-DS queries (window functions, rollups, etc)
Track record of architectural changes to enable new use cases
�
11 .Perception of Databricks as a SQL / DW platform
Don’t look like a DW
Require “superpowers” to use
Slow for SQL
�
12 .Lakehouse Workstreams
User experience SQL Language Catalog Performance
and simplicity & Docs & Security
No “superpowers” required
End user & admin UX
�
13 .Lakehouse Workstreams
User experience SQL Language Catalog Performance
and simplicity & Docs & Security
No “superpowers” required
End user & admin UX
�
14 .Product Lenses
A simpler, more contextual user experience for different
types of users on Databricks via product lenses:
Built on
Redash!
�
15 .Navigation - Sneak Peek
Databricks
Workspace
SQL
Lens
Lens
�
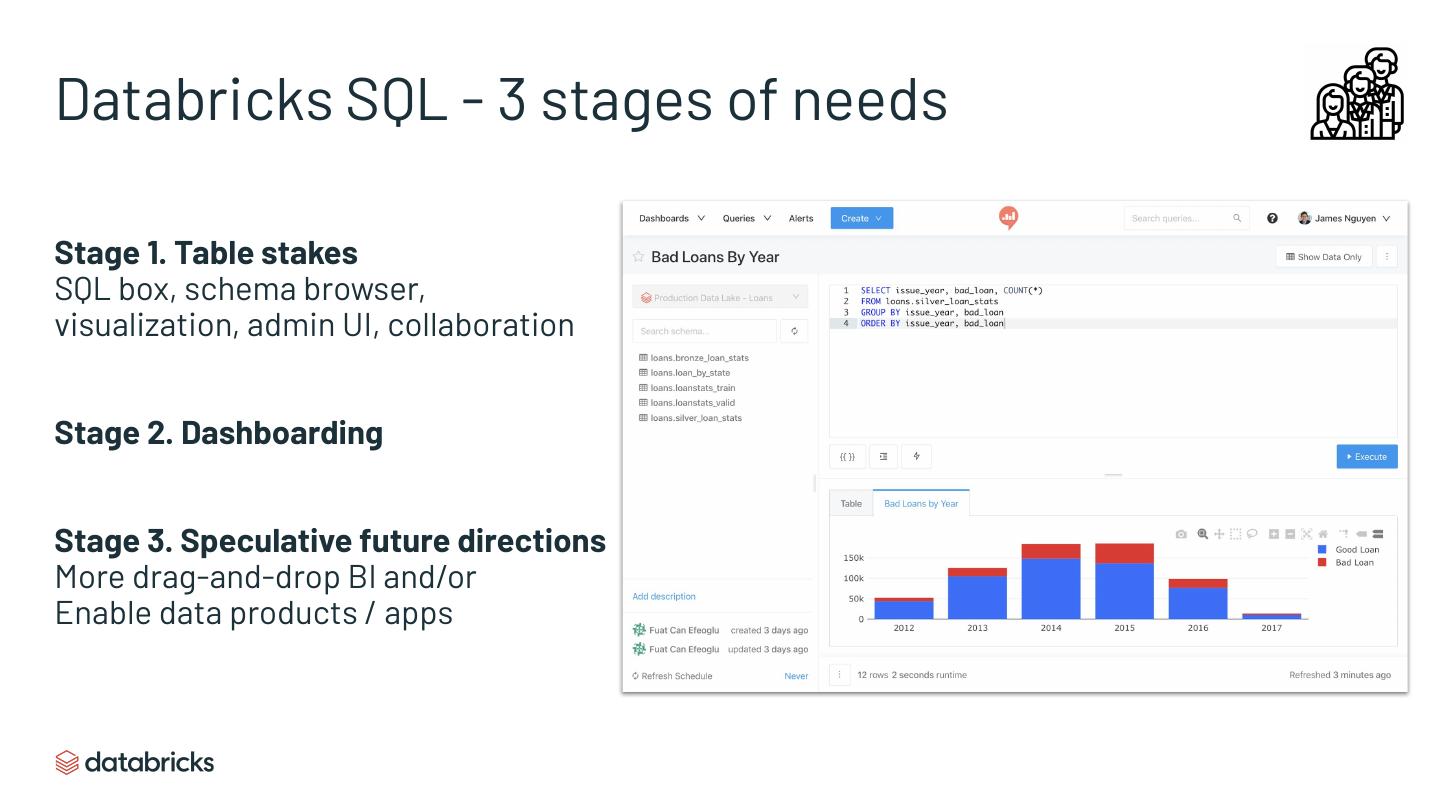
16 .Databricks SQL - 3 stages of needs
Stage 1. Table stakes
SQL box, schema browser,
visualization, admin UI, collaboration
Stage 2. Dashboarding
Stage 3. Speculative future directions
More drag-and-drop BI and/or
Enable data products / apps
�
17 .Databricks SQL: Initial Redash Integration
Self-serve on the Data Lake!
Collaborative queries, dashboards &
alerts on your data lake.
Simple, SQL oriented UX
Analysts don’t need to understand or
get exposed to notebooks or jobs.
Ready-to-go
Tightly integrated with Databricks
compute (via Virtual Clusters) &
security.
�
18 .Databricks SQL: History
Central Query Log
Track & understand usage across virtual
clusters, users & time. Easily observe
workloads across Redash, BI tools & any
other SQL client usage.
Troubleshoot & debug
History is the starting point for
understanding / triaging any errors &
performance issues. Jump into detailed
Spark query profile as needed.
�
19 .Databricks SQL: Beyond Initial Integration
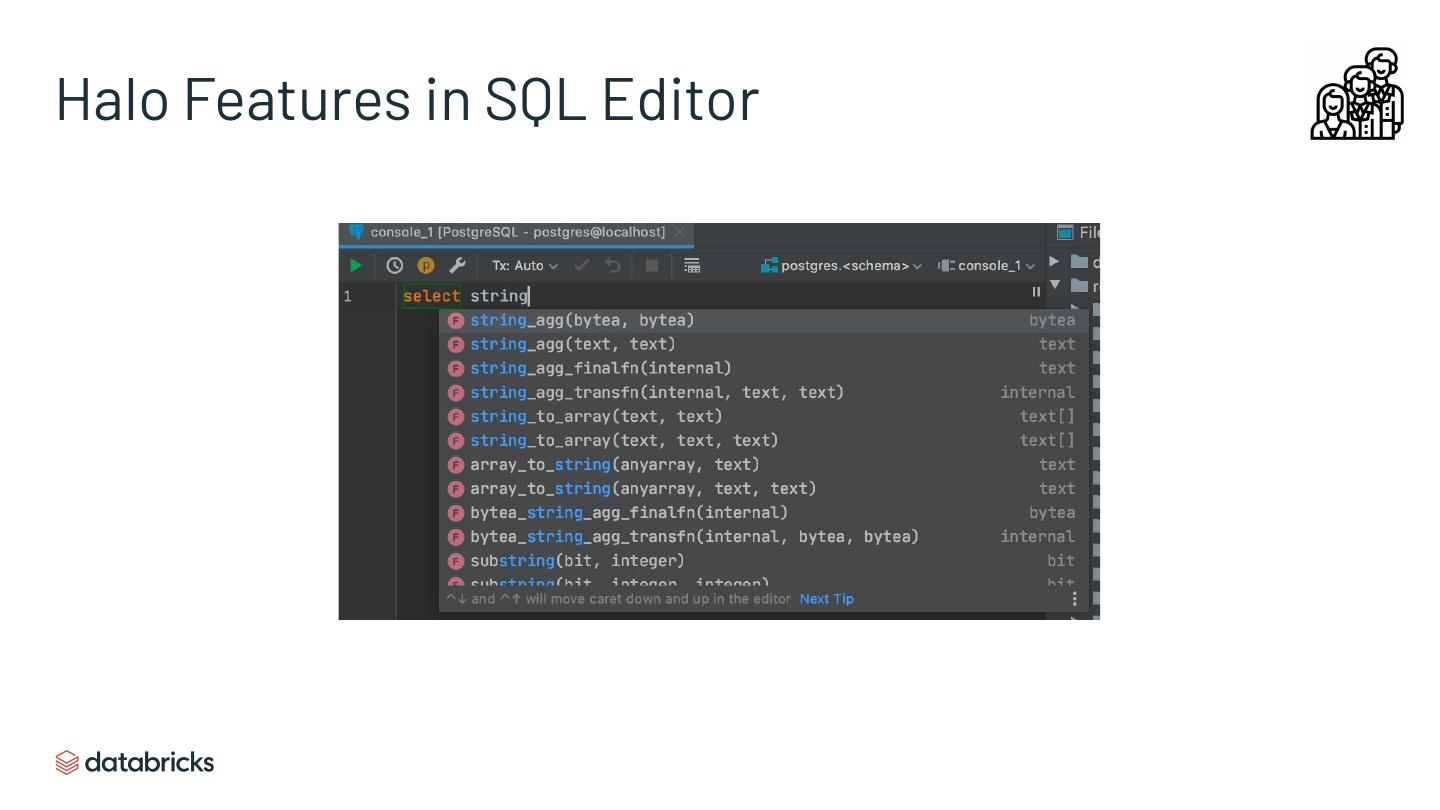
Query Editor Improvements Email Reports
Improved multi-tasking (e.g. persistent query tabs), Ability to email scheduled dashboard/query runs.
contextual auto-complete, improved metadata/data
preview experience & integrated query history
view.
Access Control Improvements
Organization & Asset Management Improve Redash security to include queries,
Help manage large amount of queries, dashboards, dashboards & alert ACLs.
alert with better content organization. (e.g. folders,
projects)
Improved Charting
Lifecycle Mgmt. & Version Control Dynamic pivot tables (w/ auto SQL generation), new
Ability to co-version related queries, dashboards, chart types, usability improvements to existing
alerts together & manage throughout their lifecycle. charts.
�
20 .Halo Features in SQL Editor
�
21 .Databricks SQL: Speculative Future Directions
Direction 1. Drag and drop data modeling
▪ Spectrum: Simple drag-and-drop aggregation/pivot (notebooks) to full fledged PowerBI/Tableau
▪ Most customers say drag-and-drop works well for simple queries, but not complex ones.
▪ Likely implement the low hanging fruits but not intend to compete with BI tools
Direction 2. Data products / apps
▪ Embedded analytics
▪ Customizing look and feel
▪ More complex interactions
▪ White labeling
▪ Some Redash users already do this, so a natural extension
�
22 .Lakehouse Workstreams
User experience SQL Language Catalog Performance
and simplicity & Docs & Security
No “superpowers” required
End user & admin UX
�
23 .SQL Language and Docs
Missing functionalities
▪ Information schema
▪ LATERAL SUBQUERY
▪ SQL UDF
▪ Better support of correlated subquery
▪ ...
Reduce friction when customers migrate from other DWs
▪ Compatibility with ANSI and other DWs
Make our docs feel like database docs
▪ Not Spark or component centric, but “how do I accomplish X on Databricks”
�
24 .Lakehouse Workstreams
User experience SQL Language Catalog Performance
and simplicity & Docs & Security
No “superpowers” required
End user & admin UX
�
25 .Catalog & Security Directions
DW-like ACL on “managed tables”, and object store ACL (passthrough) on
external tables.
▪ Data security team staffed and ready to execute.
Scalable, cross-workspace, and externally accessible catalog
�
26 .Lakehouse Workstreams
User experience SQL Language Catalog Performance
and simplicity & Docs & Security
No “superpowers” required
End user & admin UX
�
27 .Performance Dimensions
Concurrency (concurrent users / queries per sec)
Throughput (large queries)
Latency (small queries)
�
28 .Performance Dimensions
Concurrency (concurrent users / queries per sec) -> virtual clusters
Throughput (large queries) -> Photon vectorized engine
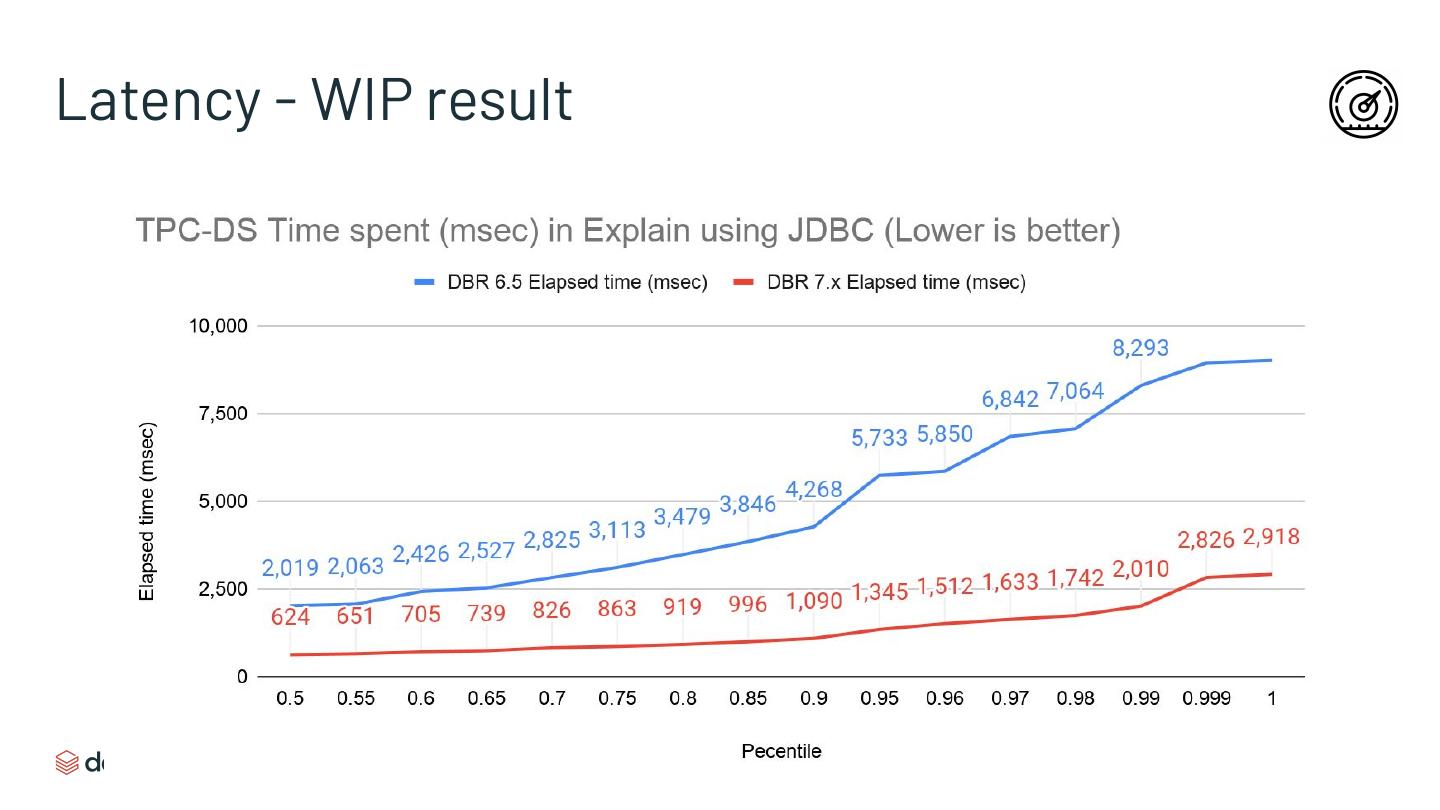
Latency (small queries) -> new scheduler & cutting overheads
�
29 .Concurrency - Virtual Clusters
SQL Optimize Compute
Virtual clusters give a quick way to setup
SQL / BI optimized compute. You pick a
tshirt size & Databricks determines
instance types & relevant settings.
Virtual clusters live under SQL Analytics /
Redash UI.
Concurrency Scaling Built-in
Virtual clusters can load balance queries
across multiple clusters behind the scenes,
providing unlimited concurrency.
�