



















































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Why Do Developers Prefer MongoDB
作为当今增长最快的数据库技术,MongoDB®帮助跨行业的组织和企业创建可扩展的应用程序,而这些应用程序在几年前被认为是不可能实现的。
世界正处于信息过载的边缘,需要庞大的数据库来存储和操作这些信息。这在MongoDB中是可能的,它既灵活又强大。您可以构建非常高性能的应用程序,享受无模式的生活方式。它易于采用和部署,这就是开发人员喜欢数据库的原因。
我们将研究MongoDB与其他NoSQL数据库平台的关系,并提供一个并行比较,帮助您确定MongoDB是否适合您的应用程序。
展开查看详情
1 .Why Do Developers Prefer MongoDB? Tim Vaillancourt Software Engineer, Percona Speaker Name
2 .`whoami` { name: “tim”, lastname: “vaillancourt”, employer: “percona”, techs: [ “mongodb”, “mysql”, “cassandra”, “redis”, “rabbitmq”, “solr”, “mesos” “kafka”, “couch*”, “python”, “golang” ] }
3 .Agenda ● Data Models ○ Key/Value ○ Relational ○ Columnar ○ Document ● Common Problems ● MongoDB Features ● Comparisons ● Misconceptions ● Percona MongoDB Software
4 .Data Models
5 .Key / Value Stores ● A simple database for storing associative arrays ● Data can be queried by key only ● Values are opaque “blobs” ● Use cases: ○ Caches ■ Do something that takes a long time (JOINs, API calls, etc) ■ Serialise to something like JSON ■ Write a key/value pair to Memcache ■ Read the key/value pair ■ Deserialize from something like JSON
6 .Key / Value Stores ● Benefits ○ Simple ○ Fast / efficient ● Drawbacks ○ Query language is very limited ■ Get / Set / Incr. / Decr. / Delete ○ Values are meaningless / keys only
7 .Relational Model ● Started in 1970 ● Data organised into table(s) of columns and rows ● Generally each “entity type” (eg: customer, product, etc) is a table ● Schema and data types are static ● SQL query language ● Relationships are generally made using foreign keys to other tables ○ Querying these relationships require JOINs
8 .Relational Model ● Benefits ○ Powerful SQL query language ○ Data strictness (type, size, etc) ● Drawbacks ○ JOIN-heavy database models are inefficient at scale ■ Caching JOINs became popular with release of memcached (a Key/Value store) in 2003 ○ Rigid schema
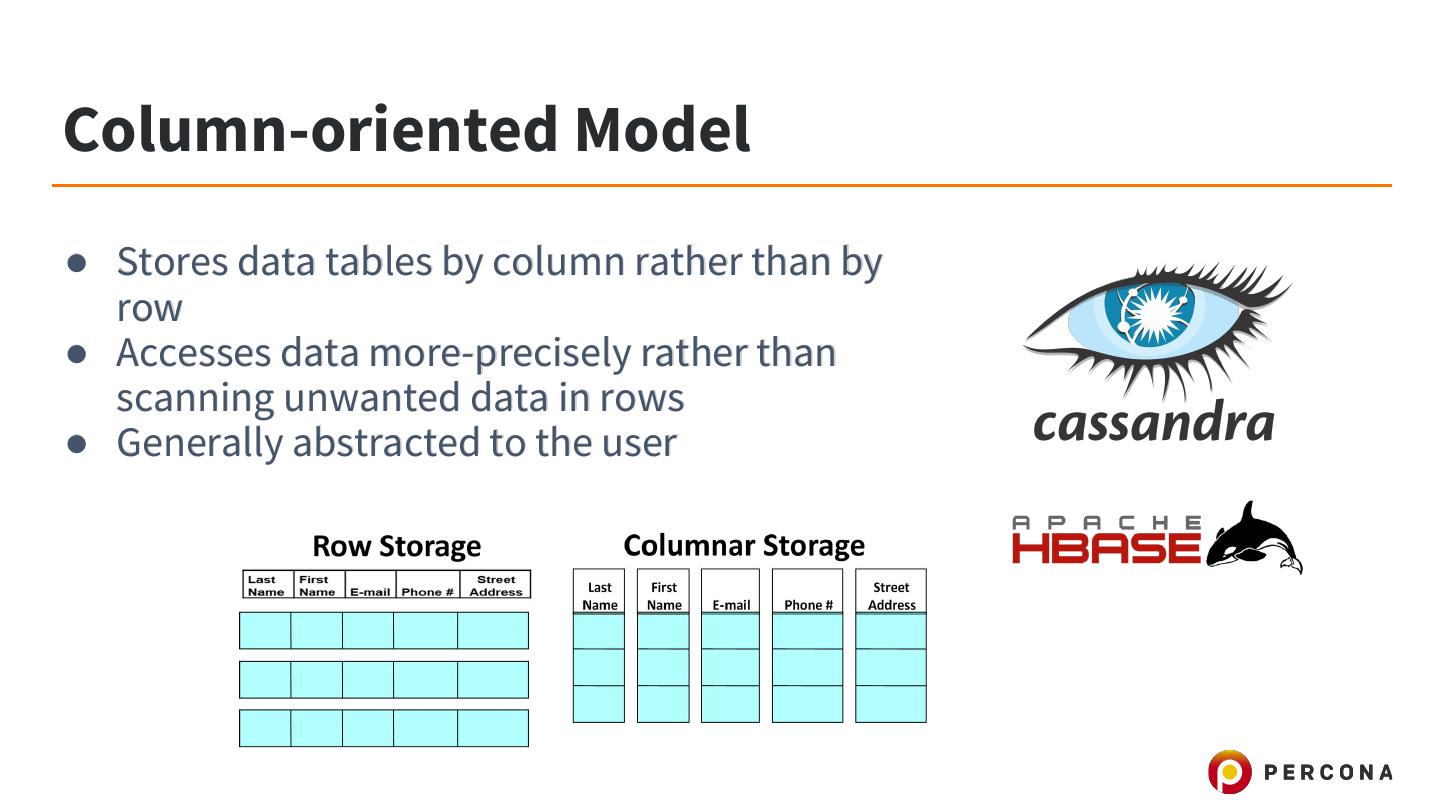
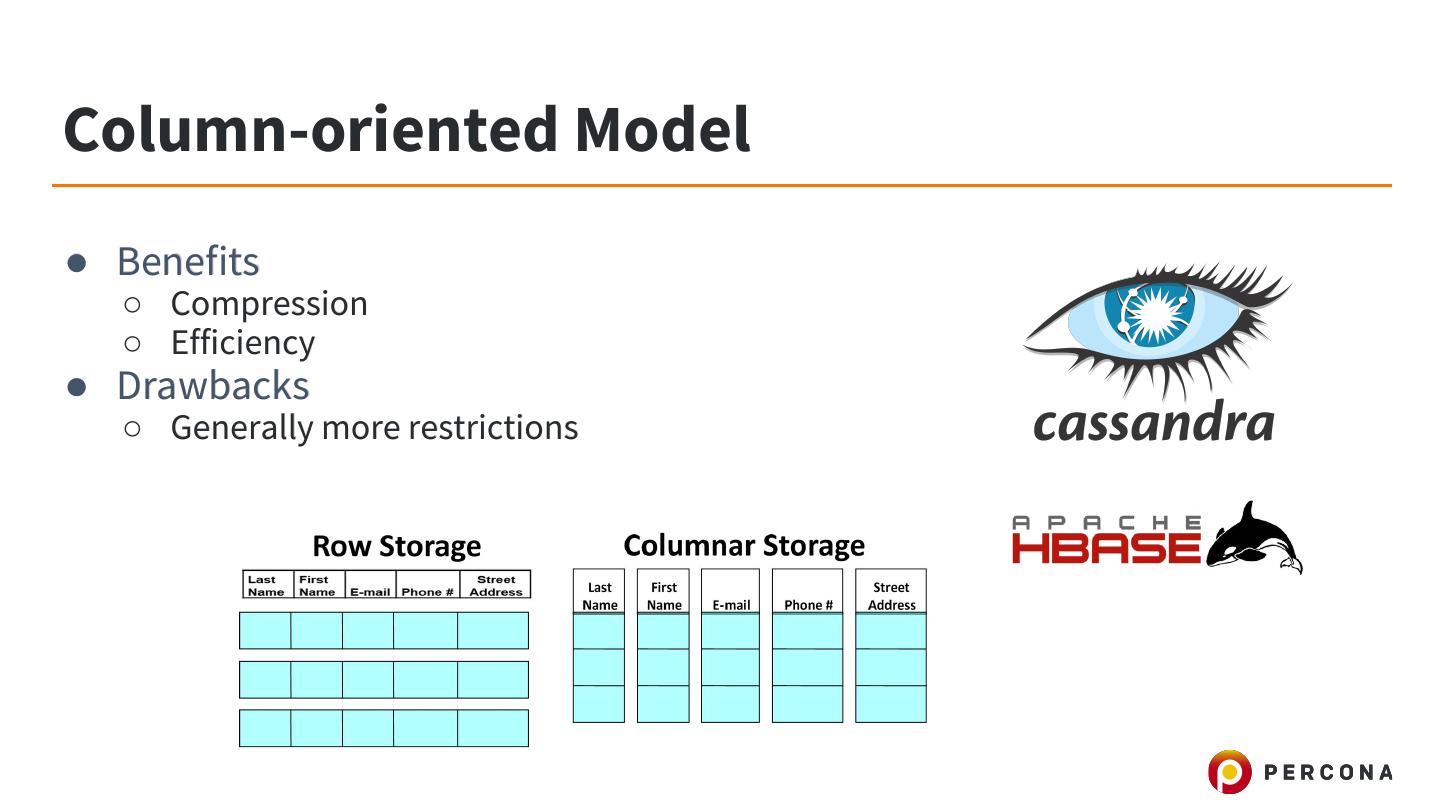
9 .Column-oriented Model ● Stores data tables by column rather than by row ● Accesses data more-precisely rather than scanning unwanted data in rows ● Generally abstracted to the user
10 .Column-oriented Model ● Benefits ○ Compression ○ Efficiency ● Drawbacks ○ Generally more restrictions
11 .Document-oriented Model ● Allows storage of rich, semi-structured/nested documents ● Fields and data types do not need to be predefined ● Data is stored into collections of documents ● Aligns more closely with Objects in modern programing languages ● Nested objects are the new standard
12 .Document-oriented Model ● Benefits ○ Documents == objects ○ Flexible schema ○ Data locality with documents ■ Ie: relationships are already “JOINed” ● “Ever cached a complex structure built from SQL queries? Why not make it a single MongoDB document?” ■ No cross-node JOINing (at scale) ○ Rapid development ● Drawbacks ○ Flexible schema :)
13 .Documents == Objects ● Most data sources are structured JSON now ● Developers like Objects ○ Most database-driven applications use nested objects in their code: ■ Python dictionaries ■ Golang structs ■ Ruby+Perl hashes ○ Object-Relational Mappers ■ A lot of SQL-driven apps are pretending their not SQL-driven apps :)
14 .MongoDB Features
15 .Overview ● Flexible document model ● Built-in High-availability ● Built-in Scalability ● Secondary, partial, geo and text Index support ● ACID Transaction (4.0+) ● Powerful Aggregation Framework ● Query profiling ● Role-based access control ● Change streams
16 .Document Model ● Document schema does not need to be pre-defined ○ However, you can enable Schema Validation (more later) ● Documents can be up to 16MB total ● Documents are stored as BSON ○ Data is displayed as JSON in the shell, logs, etc ● Up to 100 levels of nesting ● Supports sub-documents, arrays, strings, references, date/time and numeric types ● Sub-documents and arrays are accessed with dot-notation syntax
17 .Document Model ● Schema best practice ○ Avoid cross document/collection relationships ○ Pack as much data as possible into a single document ■ Ie: move data you would get via JOINs into a single document ■ Specify only the required document-fields on .find() queries ○ Use correct data types ■ Do not store dates as strings (use the time types) ■ Do not store booleans as strings (use booleans) ■ Do not store numbers as strings (use real numbers) ○ Indexes ■ Add them only if you actually need them ■ Do not duplicate indexes
18 .Indexes ● Compound Indexes are supported ○ Read left -> right ○ Can be partially read ● Indexes have a forward or backward direction ○ Try to cover .sort() with index and match direction!’ ● Partial ○ Updates an index based on a condition ○ Only documents matching the condition are indexed ● Text Indexes ○ Allows quick string-based searches on text ● Geo Indexes
19 .Replica Sets ● Replication ○ Changelog based, using the “Oplog” ○ Asynchronous, idempotent changes to data ● Auto-recovery/failover during failures ● More members == more read capacity ● Maximum 50 members ● Maximum 7 voting members ● Oplog ○ The “oplog.rs” capped-collection in “local” database ○ Read by secondary members for replication
20 .Write Concerns ● Allow fine control of data integrity of a write to a Replica Set ● Tuneable per operation or database session ● Write Concern Modes ○ “w: <num>” - Writes must ack to # of nodes ○ “majority” - Writes must ack on a majority of nodes ○ “<replica set tag>” - Writes must ack to a member with the specified replica set tags ● Durable ○ Add option “j: true” to journal to disk before ack!
21 .Read Concern ● Like write concerns, the consistency of reads can be tuned per session or operation ● Levels ○ “local” - Default, return the current node’s most-recent version of the data ○ “majority” - Reads return the most-version of the data that has been ack’d on a majority of nodes. Not supported on MMAPv1. ○ “linearizable” (3.4+) - Reads return data that reflects a “majority” read of all changes prior to the read
22 .Scaling: Read Preference ● Defines which nodes can perform a read operation ○ Can be changed per operation or session ○ Example (probably a bad one): ■ Read unread email messages using “secondaryPreferred” ■ Read deleted email message from “primary” ● Read Preference modes ○ primary (default) ○ primaryPreferred ○ secondary ○ secondaryPreferred (recommended for Read Scaling!) ○ nearest
23 .Scaling: Read Preference ● Tags ○ Select nodes based on key/value pairs (one or more) ○ Often used for ■ Datacenter awareness, eg: { “dc”: “eu-east” } ■ Specific workflows, eg: Analytics, BI, Batch summaries, Backups
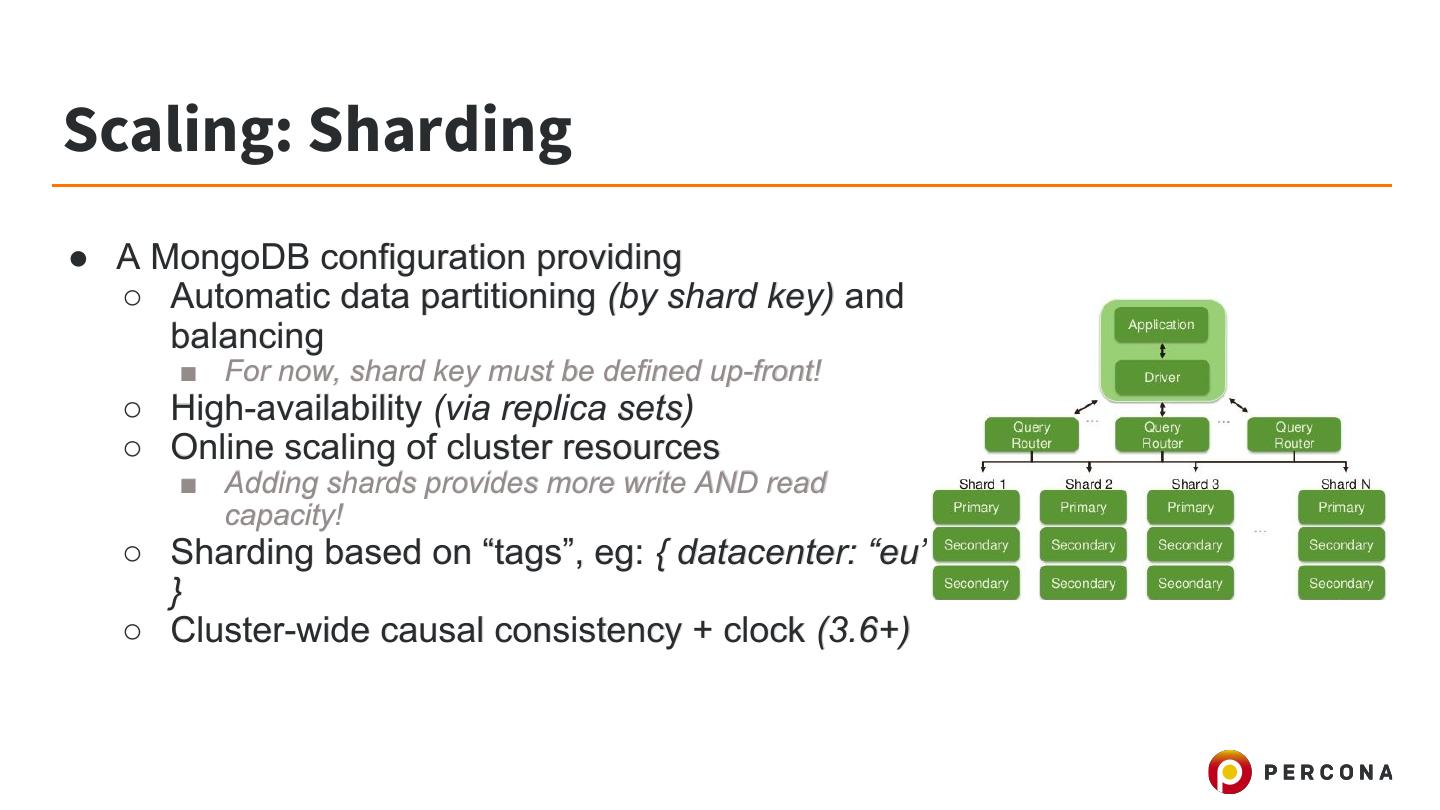
24 .Scaling: Sharding ● A MongoDB configuration providing ○ Automatic data partitioning (by shard key) and balancing ■ For now, shard key must be defined up-front! ○ High-availability (via replica sets) ○ Online scaling of cluster resources ■ Adding shards provides more write AND read capacity! ○ Sharding based on “tags”, eg: { datacenter: “eu” } ○ Cluster-wide causal consistency + clock (3.6+)
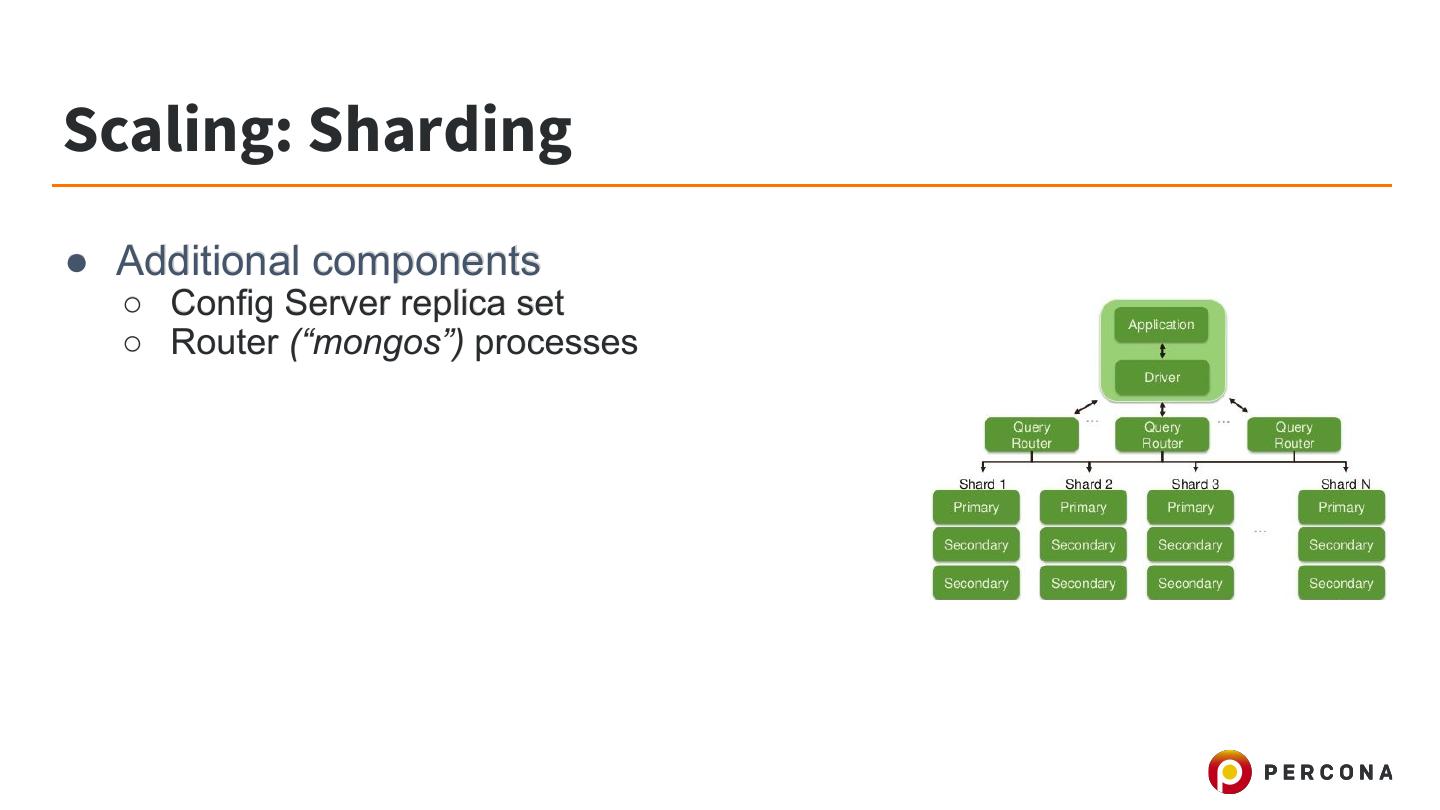
25 .Scaling: Sharding ● Additional components ○ Config Server replica set ○ Router (“mongos”) processes
26 .Hardware: Mainframe vs Commodity ● Databases: The Past ○ Buy some really amazing, expensive hardware ○ Buy some crazy expensive license ■ Don’t run a lot of servers due to above ○ Scale up: ■ Buy even more amazing hardware for monolithic host ■ Hardware came on a truck ○ HA: When it rains, it pours ● Databases: Today ○ Buy what you can afford ○ Use a scalable database ○ Add resources as needed
27 .Aggregation Pipeline ● Run as a pipeline of “stages” on a MongoDB collection ○ Each stage passes it’s result to the next ○ Aggregates the entire collection by default ■ Add a $match stage to reduce the aggregation data ● Runs inside the MongoDB Server ○ Much more efficient than .mapReduce() operations ● Example stages: ○ $match - only aggregate documents that match ■ Must be 1st stage to use indexes! ○ $group - group documents by certain conditions ■ Similar to “SELECT …. GROUP BY”
28 .Aggregation Pipeline ● Example stages: ○ $count - count the # of documents ○ $project - only output specific pieces of the data ○ $bucket and $bucketAuto - Group documents based on specified expression and bucket boundaries ■ Useful for Faceted Search ○ $geoNear - Returns documents based on geo-proximity ○ $graphLookup - Performs a recursive search on a collection ○ $sample - Returns a random sample of documents of a specified size ○ $unwind - Unwinds arrays into many separate documents ○ $facet - Runs many aggregation pipelines within a single stage
29 .Aggregation Pipeline ● Just a few examples of operators that can be used each stage: ○ $and / $or /$not ○ $add / $subtract / $multiply ○ $gt / $gte / $lt / $lte / $ne ○ $min / $max / $avg / $stdDevPop ○ $log / $log10 ○ $sqrt ○ $floor / $ceil ○ $in (inefficient) ○ $dayOfWeek / $dayOfMonth / $dayOfYear ○ $concat / $split /…
3秒后跳转登录页面
去登陆

