
























































































































































































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
ElasticSearch 101
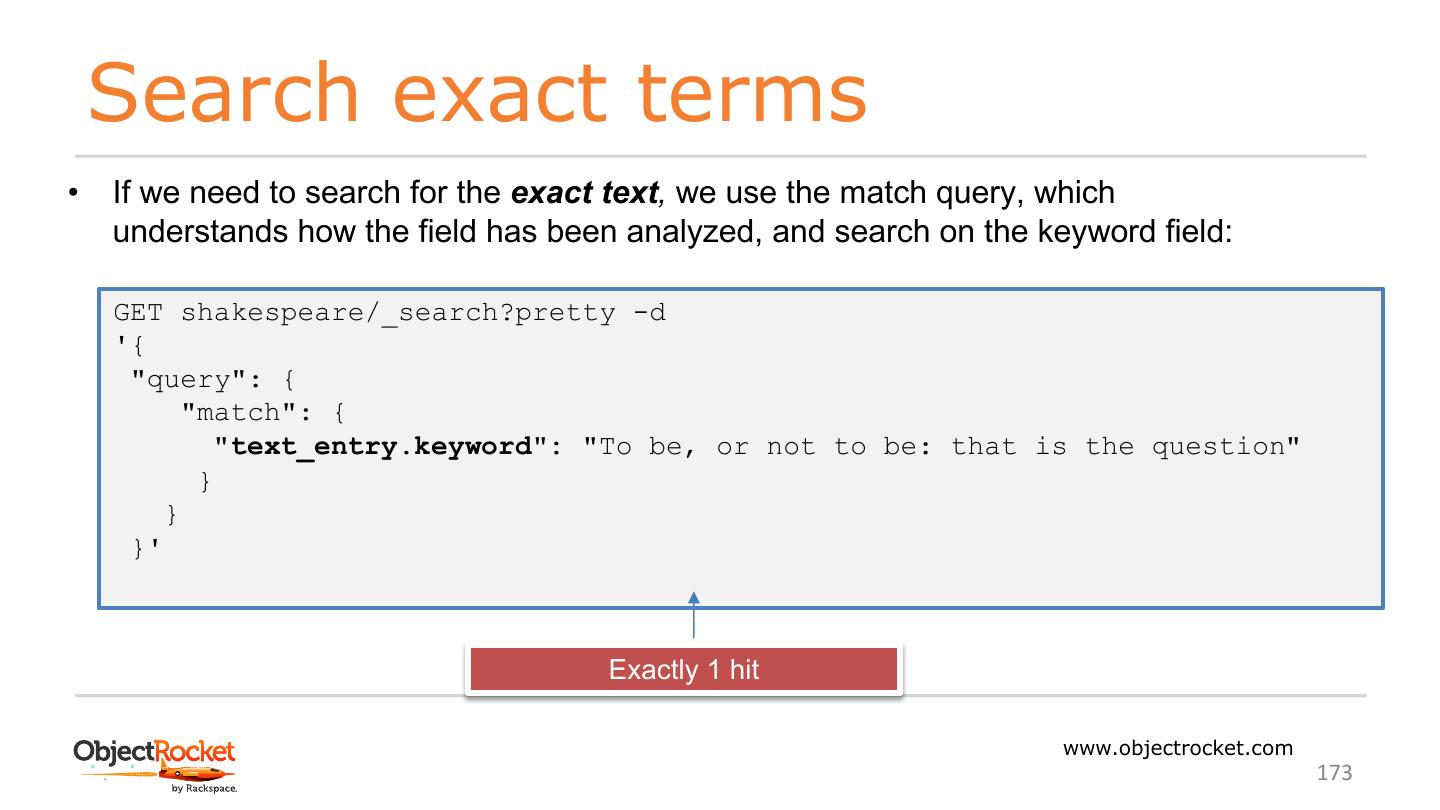
ElasticSearch是一个众所周知的高度可扩展的搜索引擎,它以一种为基于语言的搜索优化的结构存储数据,但它的功能和用例并没有就此止步。在本教程中,我将向您介绍ElasticSearch的实际操作,并让您大致了解一些基本概念。
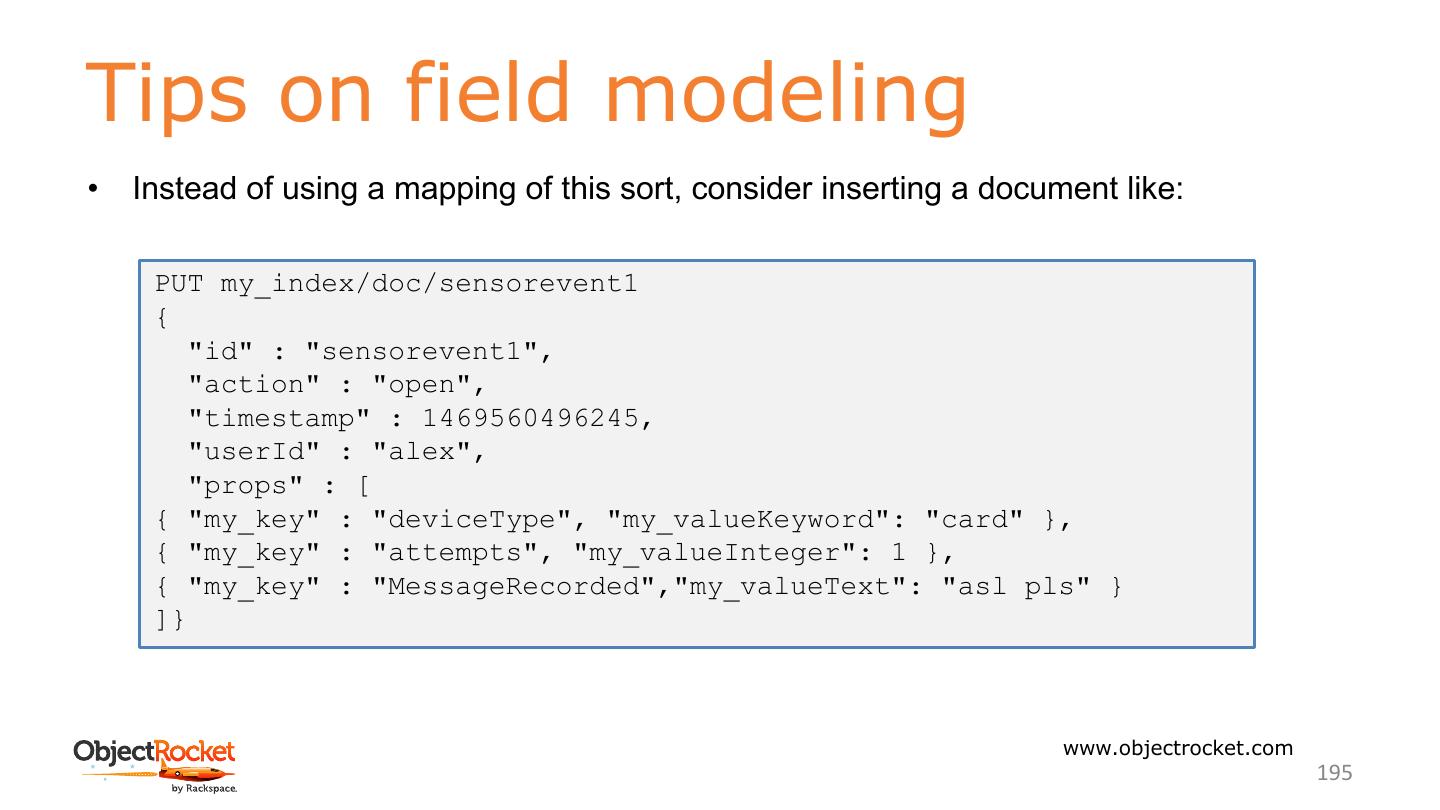
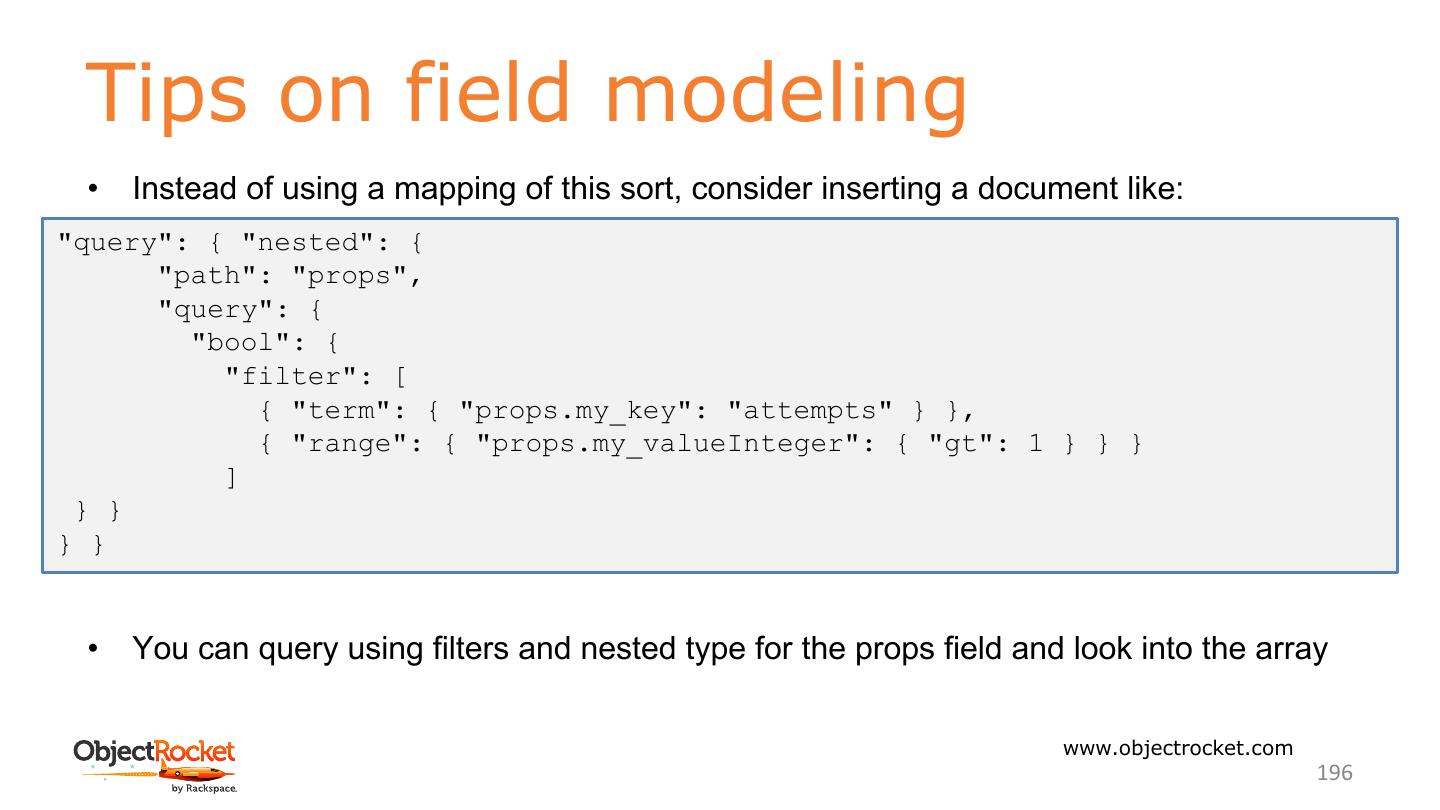
数据库管理具有挑战性,而ElasticSearch也不例外。在本教程中,我们将介绍各种管理主题,如安装和配置、群集/节点管理、索引管理和监视群集运行状况,这些主题将帮助您。在ElasticSearch之上构建应用程序也具有挑战性,并引起了对模式设计的关注。在本教程中,我们将介绍面向开发人员的主题,如映射和分析、聚合和模式设计,这些主题将帮助您在ElasticSearch之上构建一个健壮的应用程序。
在一些章节的结尾会有实验课,所以请随身携带笔记本电脑。
展开查看详情
1 . Elastic 101 Antonios Giannopoulos DBA @ Rackspace/ObjectRocket Alex Cercel DBA @ Rackspace/ObjectRocket Mihai Aldoiu CDE @ Rackspace/ObjectRocket linkedin.com/in/antonis | linkedin.com/in/alexcercel | linkedin.com/in/aldoiu 1
2 .Introduction Antonios Alex Cercel Mihai Aldoiu Giannopoulos www.objectrocket.com 2
3 .Overview • Introduction • Working with data • Scaling the cluster • Operating the cluster • Troubleshooting the cluster • Upgrade the cluster • Security best practices • Working with data – Advanced operations • Best Practices www.objectrocket.com 3
4 . 1. Unzip the provided .vmdk file Labs 2. Install and or Open VirtualBox 3. Select New 4. Enter A Name 5. Select Type: Linux 6. Select Version: Red Hat (64-bit) 7. Set Memory to at least 4096 (more won’t hurt) 8. Select "Use an existing ... disk file", select the provided .vmdk file 9. Select Create 10. Select Start 11. Login with username: elasticuser , password: elasticuser 12. Navigate to /Percona2018/Lab01 for the first lab. https://bit.ly/2D1tXL6 www.objectrocket.com 4
5 .Introduction ● Key Terms ● Installation ● Configuration files ● JVM fundamentals ● Lucene basics www.objectrocket.com 5
6 .What is elasticsearch? Lucene: - A search engine library entirely written in Java - Developed in 1999 by Doug Cutting - Suitable for any application that requires full text indexing and searching capability But: - Challenging to use - Not originally designed for scaling Elasticsearch: - Built on top of Lucene - Provides scaling - Language independent www.objectrocket.com 6
7 .What is ELK stack? ElasticSearch: - The main datastore - Provides distributed search capabilities Logstash: - Parse & transform data for ingestion - Ingests from multiple of sources simultaneously Kibana: - An analytics and visualization platform - Search, visualize & interact with Elasticsearch data www.objectrocket.com 7
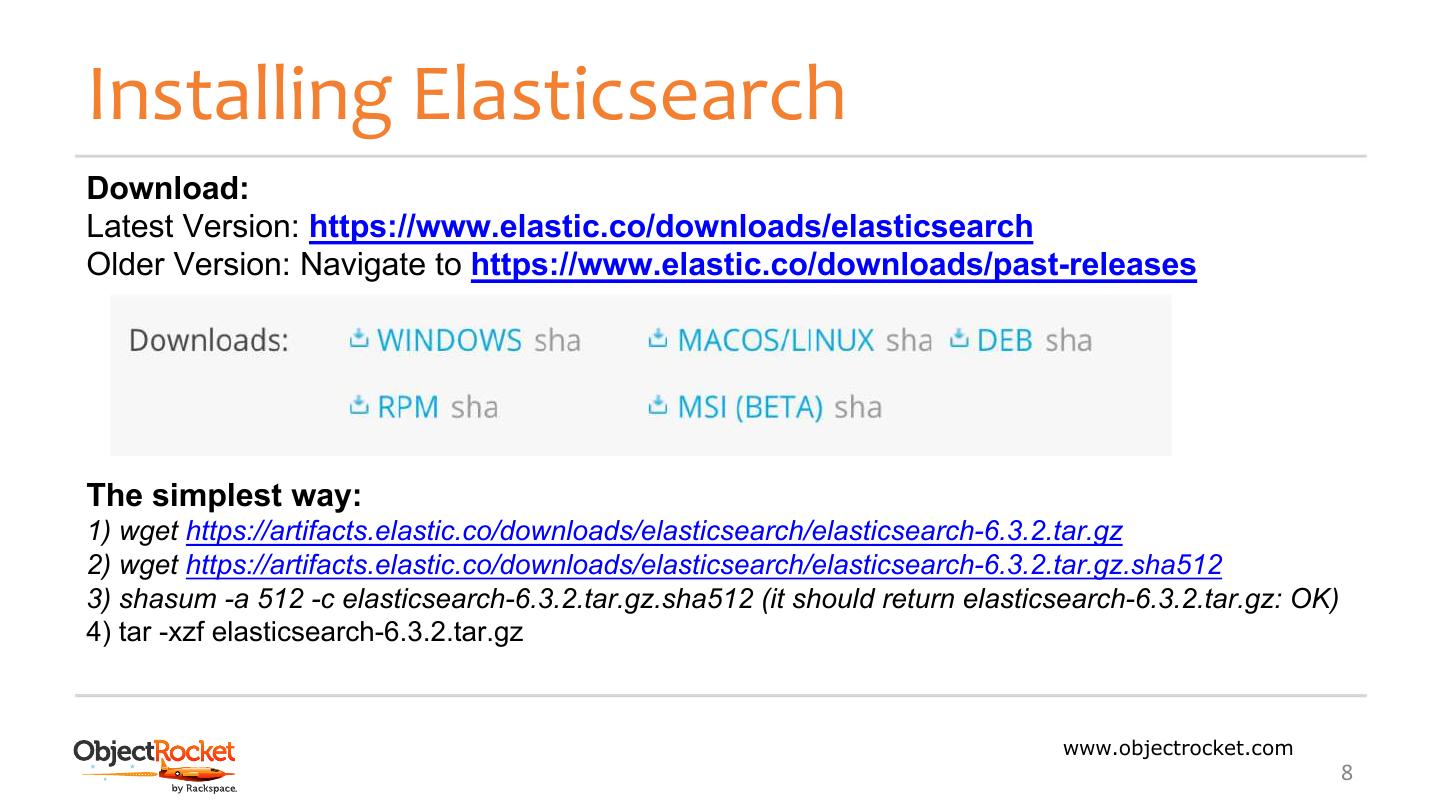
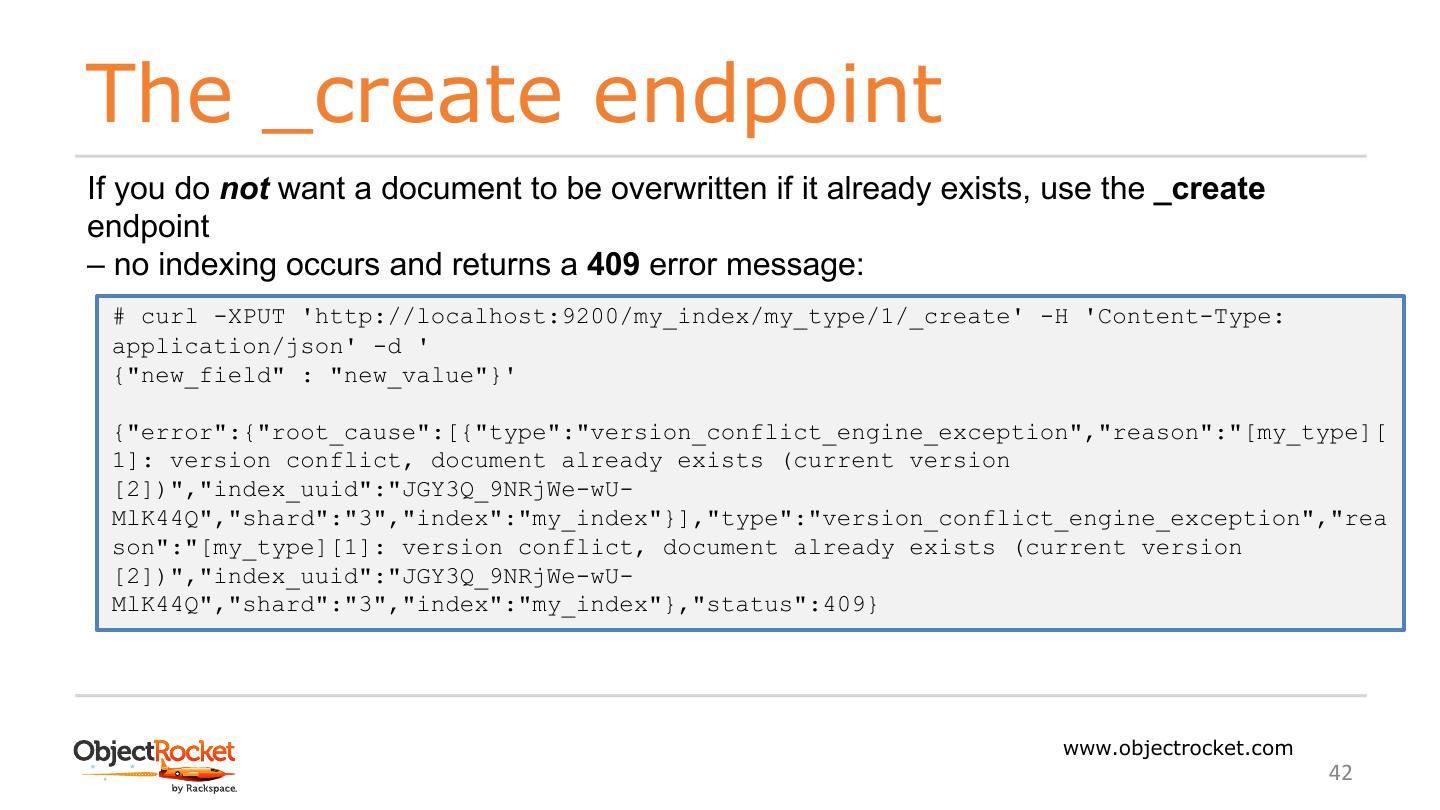
8 .Installing Elasticsearch Download: Latest Version: https://www.elastic.co/downloads/elasticsearch Older Version: Navigate to https://www.elastic.co/downloads/past-releases The simplest way: 1) wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.3.2.tar.gz 2) wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.3.2.tar.gz.sha512 3) shasum -a 512 -c elasticsearch-6.3.2.tar.gz.sha512 (it should return elasticsearch-6.3.2.tar.gz: OK) 4) tar -xzf elasticsearch-6.3.2.tar.gz www.objectrocket.com 8
9 .Installing Java ElasticSearch requires JRE (JavaSE runtime environment) or JDK (Java Development Kit) - OpenJDK CentOS: yum install java-1.8.0-openjdk - OpenJDK Ubuntu: apt-get install openjdk-8-jre ES versions 6, requires Java8 or higher https://www.elastic.co/support/matrix set JAVA_HOME appropriately - Create a file under /etc/profile.d for example jdk.sh - Add the following lines: export JAVA_HOME="/usr/lib/jvm/java-1.8.0-openjdk-*" export PATH=$JAVA_HOME/bin:$PATH www.objectrocket.com 9
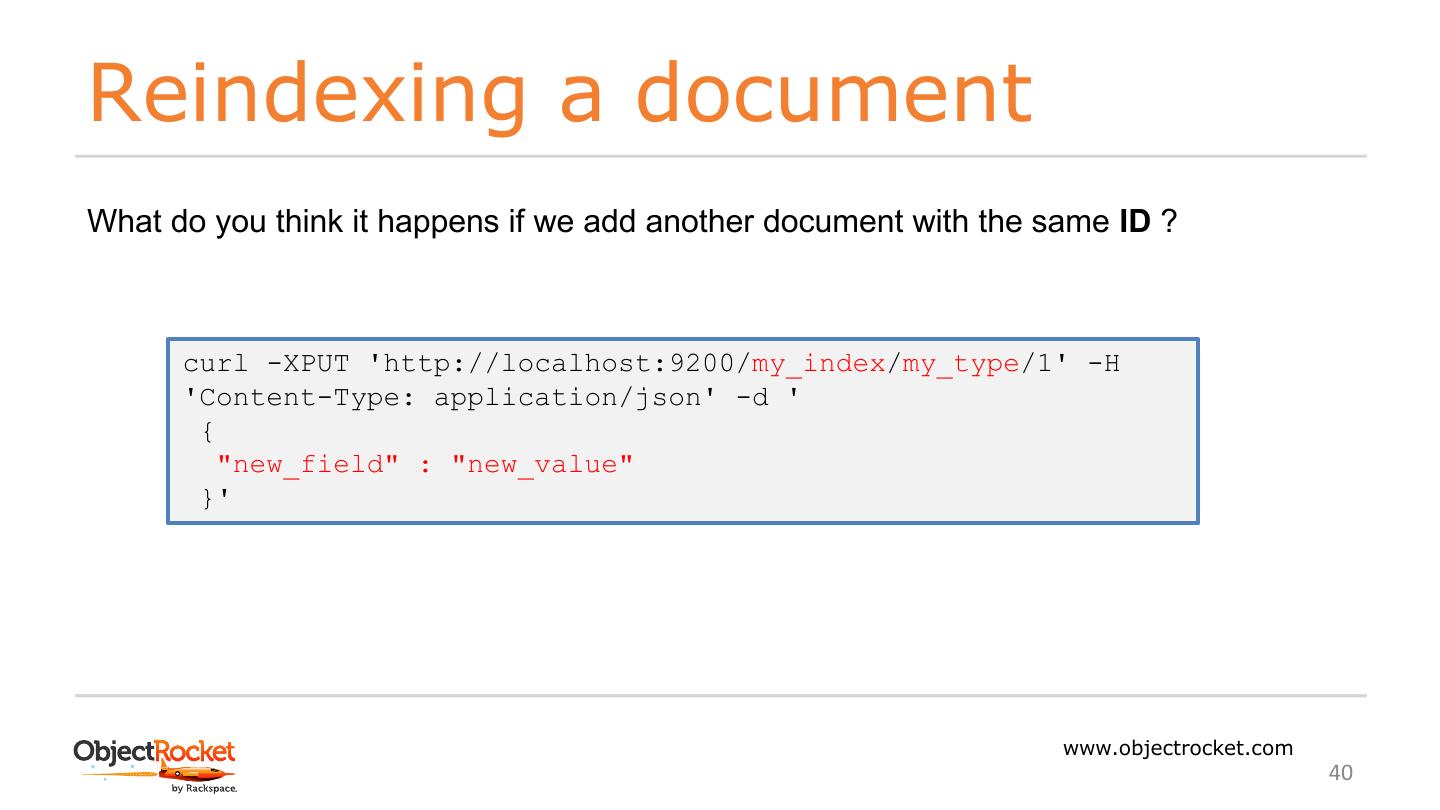
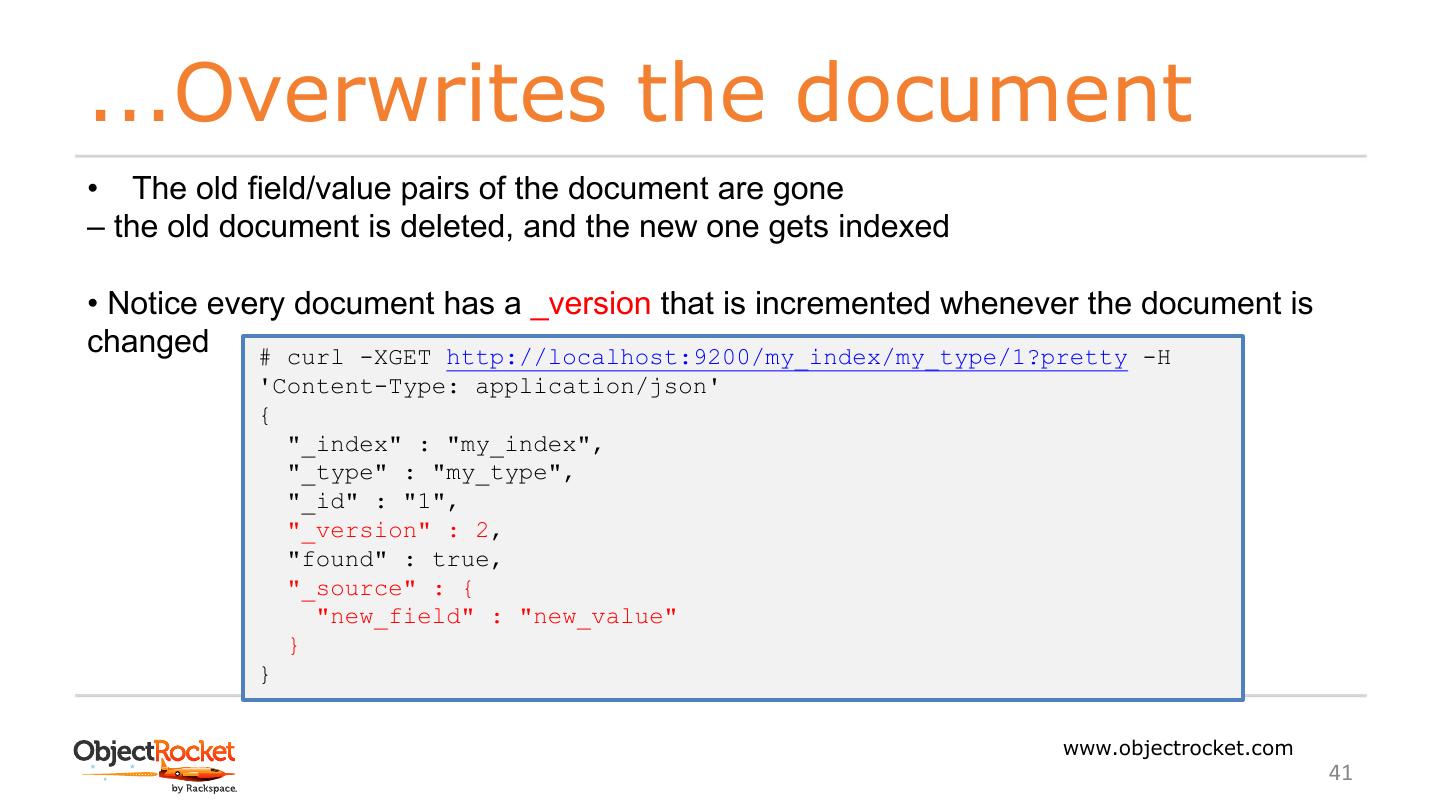
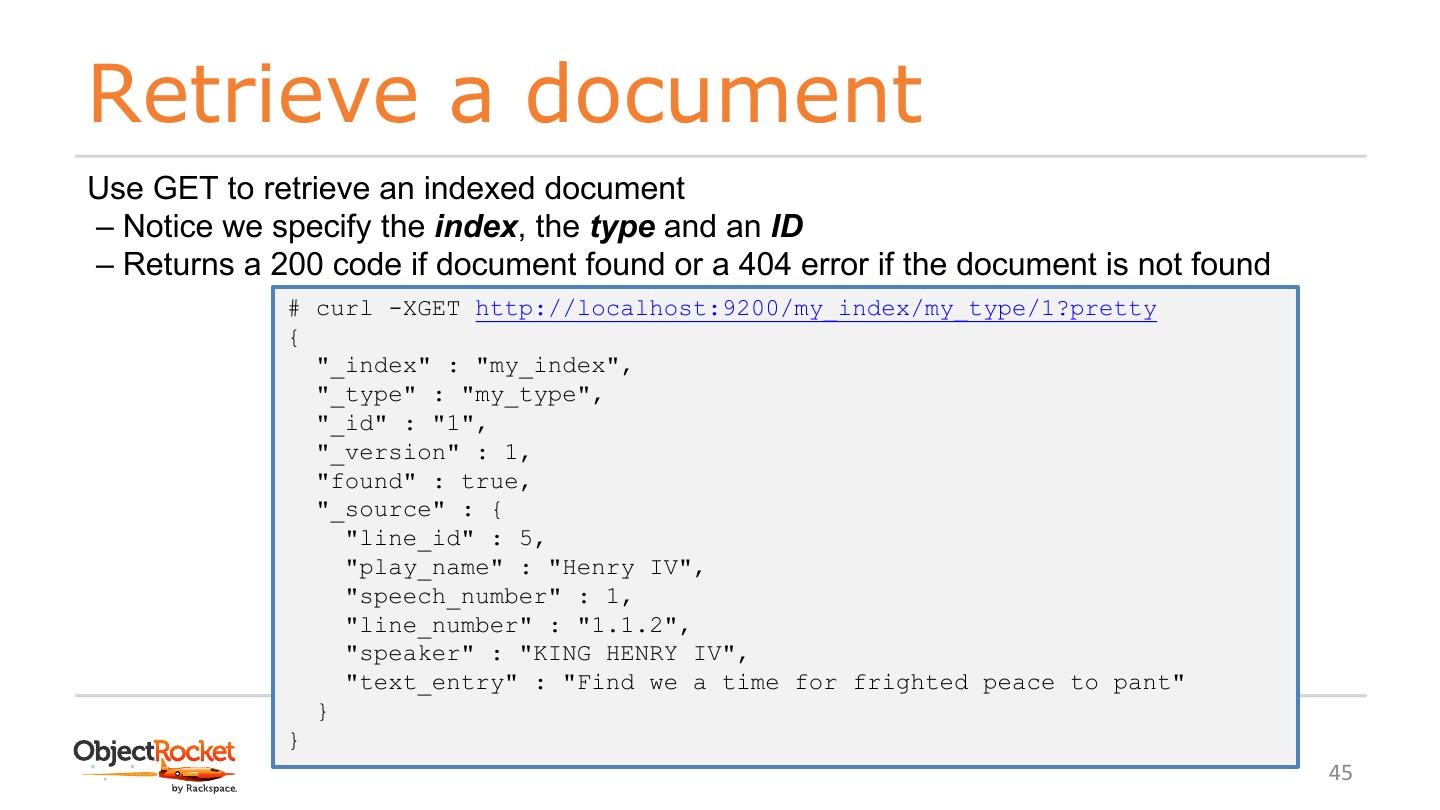
10 .Start the server $ curl -X GET "localhost:9200/" { "name" : "KG-_6s9", Create a user elasticuser* "cluster_name" : "elasticsearch", "cluster_uuid" : "T9uHpto6QtWRmsjzNFrReA", Using elasticuser execute: "version" : { "number" : "6.3.2", "build_flavor" : "default", bin/elasticsearch "build_type" : "tar", "build_hash" : "053779d", After some noise: "build_date" : "2018-07- [INFO ][o.e.n.Node] [name] started 20T05:20:23.451332Z", "build_snapshot" : false, "lucene_version" : "7.3.1", "minimum_wire_compatibility_version" : How I know is up and running? "5.6.0", "minimum_index_compatibility_version" : "5.0.0" *You can’t start ES using root }, "tagline" : "You Know, for Search" } www.objectrocket.com 10
11 . Explore the directories Folder Description Setting bin Contains the binary scipts, like elasticsearch config Contains the configuration files ES_PATH_CONF data Holds the data (shards/indexes) path.data lib Contains JAR files logs Contains the log files path.logs modules Contains the modules plugins Contains the plugins. Each plugin has its own subdirectory www.objectrocket.com 11
12 .Configuration files elasticsearch.yml - The primary way of configuring a node. - Its a template which lists the most important settings for a production cluster jvm.options - JVM related options log4j2.properties - Elasticsearch uses Log4j 2 for logging Variables can be set either: -Using the configuration file: jvm.options: -Xms512mb - or, using command line ES_JAVA_OPTS="-Xms512m" ./bin/elasticsearch www.objectrocket.com 12
13 .Elasticsearch.yml node.name - Every node should have a unique node.name - Set it to something meaningful (aws-zone1-objectrocket-es-01) cluster.name - A cluster is a set of nodes sharing the same cluster.name - Set it to something meaningful (production, qa, staging) path.data - Path to directory where to store the data (accepts multiple locations) path.logs - Path to log files www.objectrocket.com 13
14 .Elasticsearch.yml cluster.name: production node.name: dc1-prd-es1 path.data: /data/es1 path.logs: /logs/es1 bin/elasticsearch -d -p 'elastic.pid' $ curl -X GET "localhost:9200/" { "name" : "dc1-prd-es1", "cluster_name" : "production", … www.objectrocket.com 14
15 .jvm.Options Each Elasticsearch node runs on its own JVM instance JVM is a virtual machine that enables a computer to run Java programs The most important setting is the Heap Size: - Xms: Represents the initial size of total heap space - Xmx: Represents the maximum size of total heap space Best Practices - Set Xms and Xmx to the same size - Set Xmx to no more than 50% of your physical RAM - Do not set Xms and Xmx over 30ish GiB - Use the server version of OpenJDK - Lock the RAM for Heap bootstrap.memory_lock www.objectrocket.com 15
16 .jvm.Options Heap Off Heap Indexing buffer Completion suggester Cluster state … and more Caches: - query cache (10%) - field data cache (unbounded) - … www.objectrocket.com 16
17 .jvm.Options Garbage collector - It is a form of automatic memory management - Gets rid of objects which are not being used by a Java application anymore - Automatically reclaims memory for reuse Garbage collectors - ConcMarkSweepGC (CMS) - G1GC (has some Issues with JDK 8) Elasticsearch uses -XX:+UseConcMarkSweepGC GC threads -XX:ParallelGCThreads=N, where N varies on the platform -XX:ParallelCMSThreads=N , where N varies on the platform www.objectrocket.com 17
18 .jvm.Options Minor GC Major GC or full GC Eden s0 s1 Old Generation Perm XX: PermSize JVM Heap –Xms -Xmx XX: MaxPermSize New Gen -Xmn 1) A new Page stored in Eden 2) After a GC if it survives it moves to s0 ,s1 3) After multiple GCs, s0 or s1 gets full then pages moves to Old Gen www.objectrocket.com 18
19 .OS settings Disable swap - sysctl vm.swappiness=1 - Remove Swap File descriptors - Set nofile to 65536 - curl -X GET ”<host>:<port>/_nodes/stats/process?filter_path=**.max_file_descriptors” Virtual Memory - sysctl -w vm.max_map_count=262144 Max user process - nproc to 4096 DNS cache settings - networkaddress.cache.ttl=<timeout> - networkaddress.cache.negative.ttl=<timeout> www.objectrocket.com 19
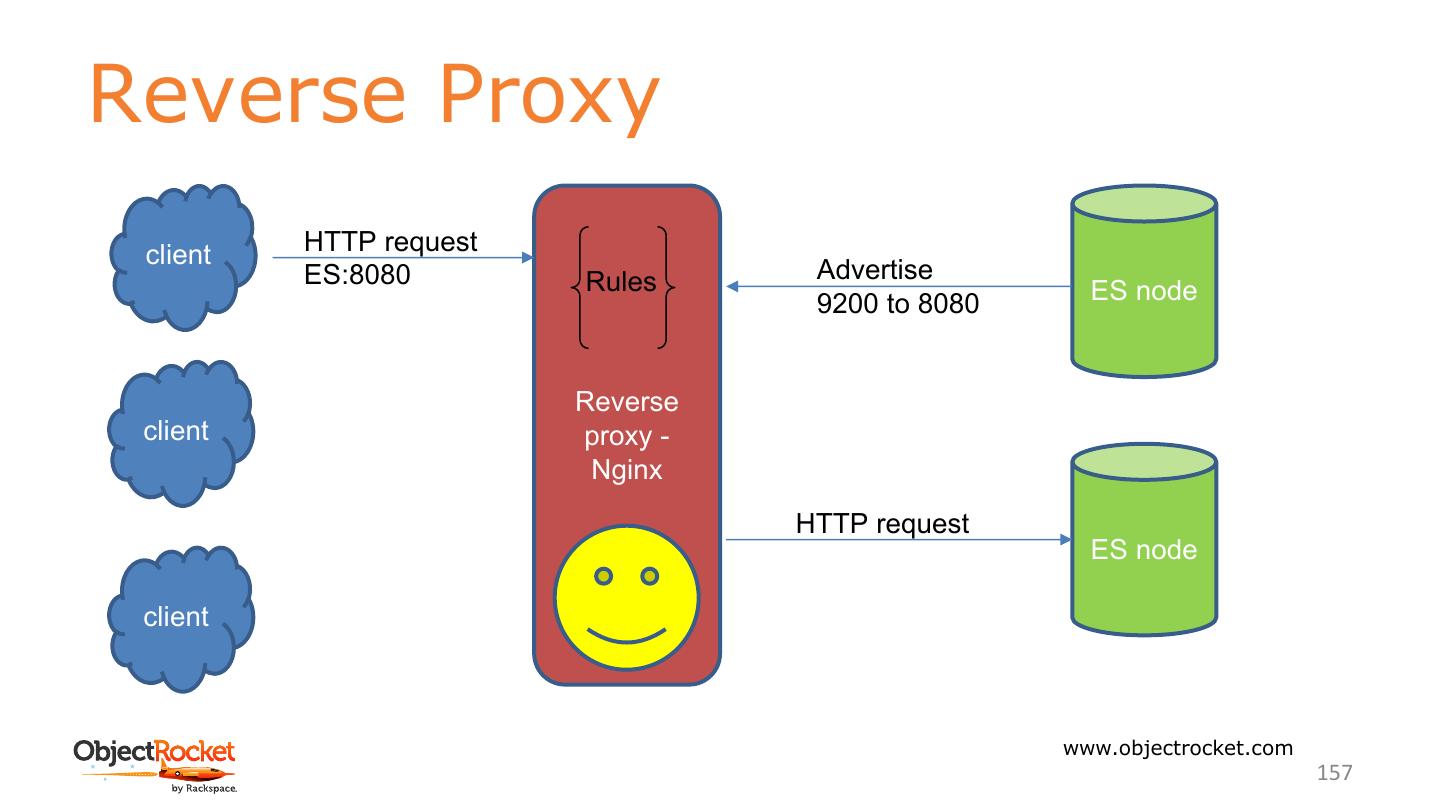
20 .Network settings Two network communication mechanisms in Elasticsearch - HTTP: which is how the Elasticsearch REST APIs are exposed - Transport: used for internal communication between nodes within the cluster Node 1 HTTP Client Transport Node 2 www.objectrocket.com 20
21 .Network settings The REST APIs of Elasticsearch are exposed over HTTP - The HTTP module binds to localhost by default - Configure with http.host on elasticsearch.yml - Default port is the first available between 9200-9299 - Configure with http.port on elasticsearch.yml Each call that goes from one node to another uses the transport module - Transport binds to localhost by default - Configure with transport.host on elasticsearch.yml - Default port is the first available between 9300-9399 - Configure with transport.tcp.port on elasticsearch.yml www.objectrocket.com 21
22 . Network settings network.host value Description _[networkInterface]_ Addresses of a network interface, for example _en0_. _local_ Any loopback addresses on the system, for example 127.0.0.1. _site_ Any site-local addresses on the system, for example 192.168.0.1. _global_ Any globally-scoped addresses on the system, for example 8.8.8.8. network.host sets the bind host and the publish host at the same time network.publish_host - Defaults to network.host.network.publish_host. Multiple interfaces network.bind_host - Defaults to the “best” address from network.host. One interface only www.objectrocket.com 22
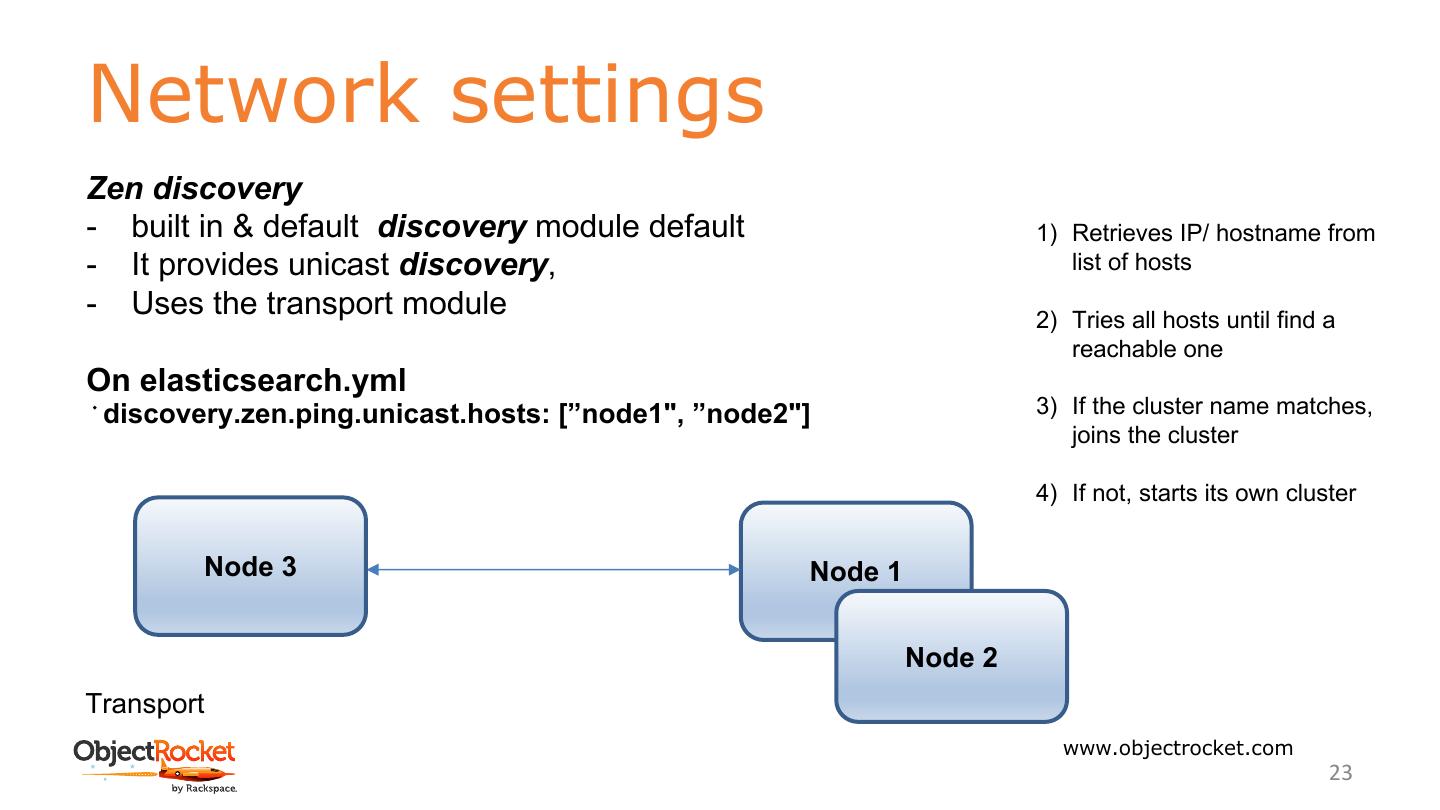
23 .Network settings Zen discovery - built in & default discovery module default 1) Retrieves IP/ hostname from - It provides unicast discovery, list of hosts - Uses the transport module 2) Tries all hosts until find a reachable one On elasticsearch.yml discovery.zen.ping.unicast.hosts: [”node1", ”node2"] 3) If the cluster name matches, joins the cluster 4) If not, starts its own cluster Node 3 Node 1 Node 2 Transport www.objectrocket.com 23
24 .Bootstrap tests Development mode: if it does not bind transport to an external interface (the default) Production mode: if it does bind transport to an external interface Bypass production mode: Set discovery.type to single-node Bootstrap Tests - Inspect a variety of Elasticsearch and system settings - A node in production mode must pass all Bootstrap tests to start - es.enforce.bootstrap.checks=true on jvm.options - Highly recommended to have this setting enabled www.objectrocket.com 24
25 .Bootstrap tests List of Bootstrap Tests - Heap size check - File descriptor check - Memory lock check - Maximum number of threads check - Max file size check - Maximum size virtual memory check - Maximum map count check - Client JVM check - Use serial collector check - System call filter check - OnError and OnOutOfMemoryError checks - Early-access check - G1GC check - All permission check www.objectrocket.com 25
26 .Lucene Lucene uses a data structure called Inverted Index. An Inverted Index, inverts a page-centric data structure (page->words) to a keyword- centric data structure (word->pages) Allow fast full text searches, at a cost of increased processing when a document is added to the database. Frequency Location give 3 1,2,3 us 3 1,2,3 1) Give us your name your 3 1,2,3 2) Give us your home number 3) Give us your home address name 1 1 number 1 2 home 2 2,3 address 1 3 www.objectrocket.com 26
27 .Lucene – Key Terms A Document is the unit of search and index. A Document consists of one or more Fields. A Field is simply a name-value pair. An index consists of one or more Documents. Indexing: involves adding Documents to an Index Searching: - involves retrieving Documents from an index. - Searching requires an index to have already been built - Returns a list of Hits www.objectrocket.com 27
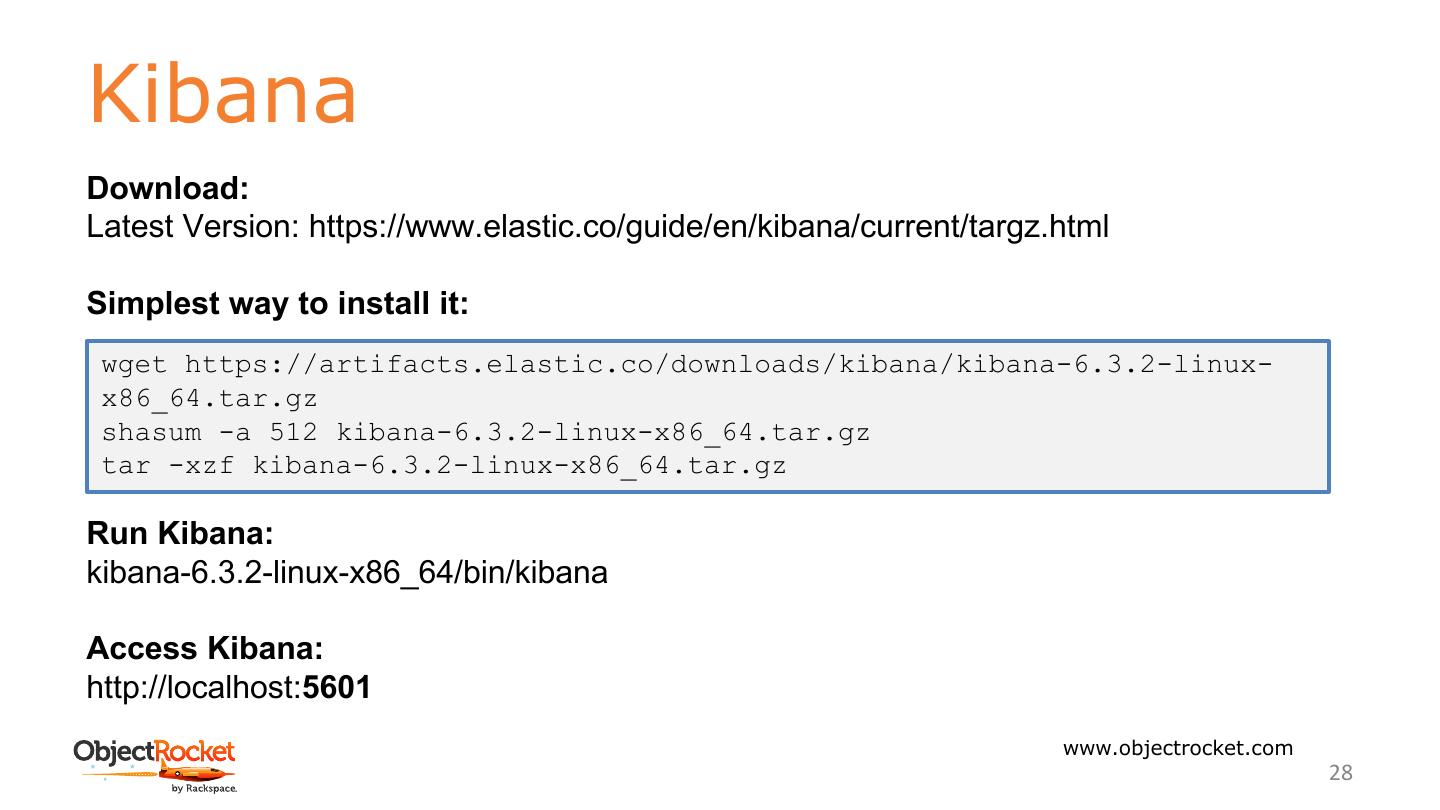
28 .Kibana Download: Latest Version: https://www.elastic.co/guide/en/kibana/current/targz.html Simplest way to install it: wget https://artifacts.elastic.co/downloads/kibana/kibana-6.3.2-linux- x86_64.tar.gz shasum -a 512 kibana-6.3.2-linux-x86_64.tar.gz tar -xzf kibana-6.3.2-linux-x86_64.tar.gz Run Kibana: kibana-6.3.2-linux-x86_64/bin/kibana Access Kibana: http://localhost:5601 www.objectrocket.com 28
29 .Kibana - Devtools www.objectrocket.com 29
3秒后跳转登录页面
去登陆

