







































































































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Deploying MongoDB in Production
在生产中运行MongoDB可能具有挑战性。
在本教程中,我们将介绍如何配置数据库,以及如何解析和解释日志和度量,以使您的日常工作更加轻松。
我们将学习如何:
解释MongoDB日志和服务器状态输出
使用“currentop”命令检查当前运行的查询
使用数据库探查器
为生产配置Linux,包括操作系统参数、网络参数和磁盘配置
在副本集和碎片中安全运行维护
创建索引而不降低性能
选择正确的切碎键,以及何时和为什么使用切碎标签
使用基准测试和负载重放工具
选择最佳备份方法
用PMM监控系统
评估应用程序是否可以利用4.0中的事务
配置更改流并通过几行获取通知
展开查看详情
1 .Deploying MongoDB in Production Monday, November 5, 2018 9:00 AM - 12:00 PM Bull
2 .About us 4
3 .Agenda ● Hardware and OS configuration ● MongoDB in Production ● Backups and Monitoring ● Q&A 5
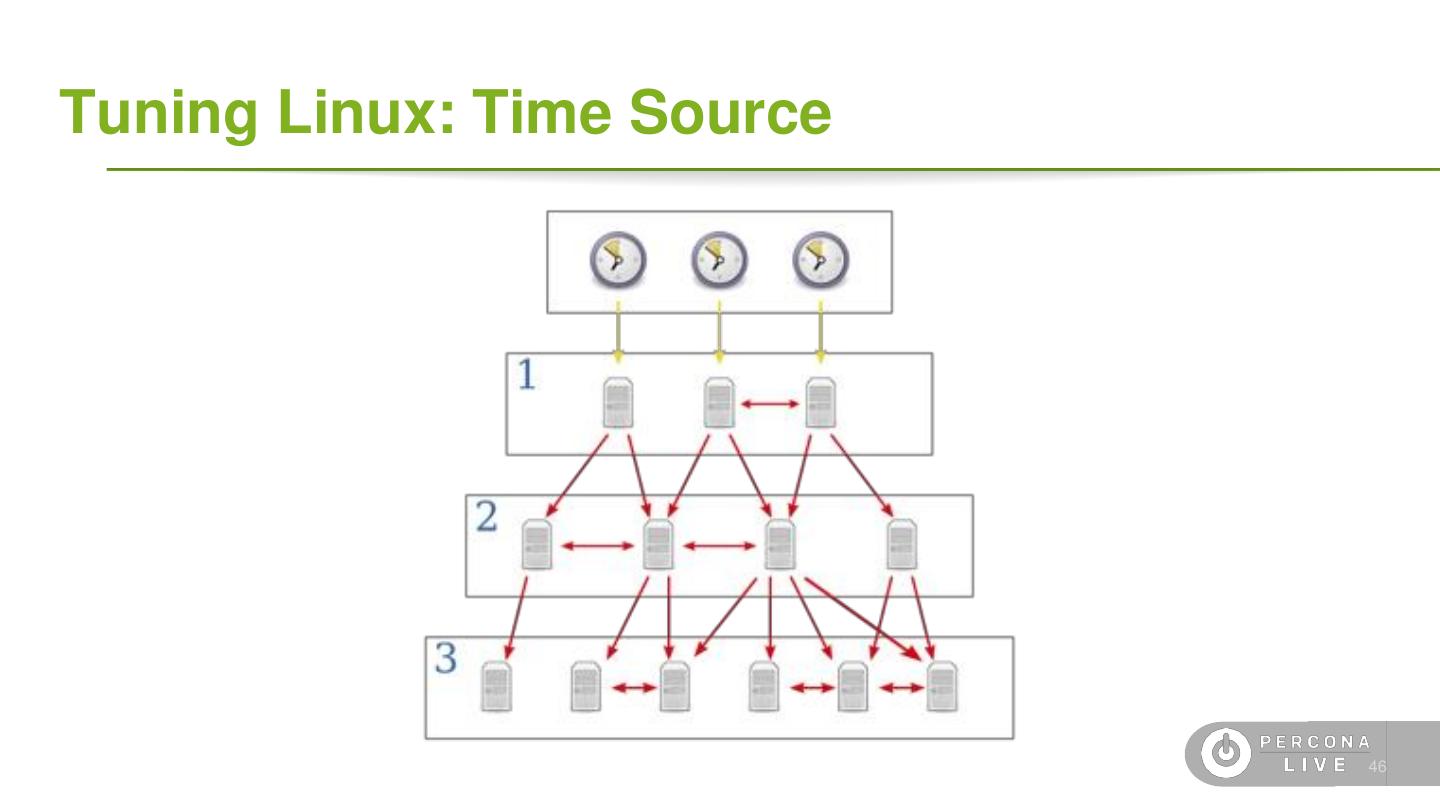
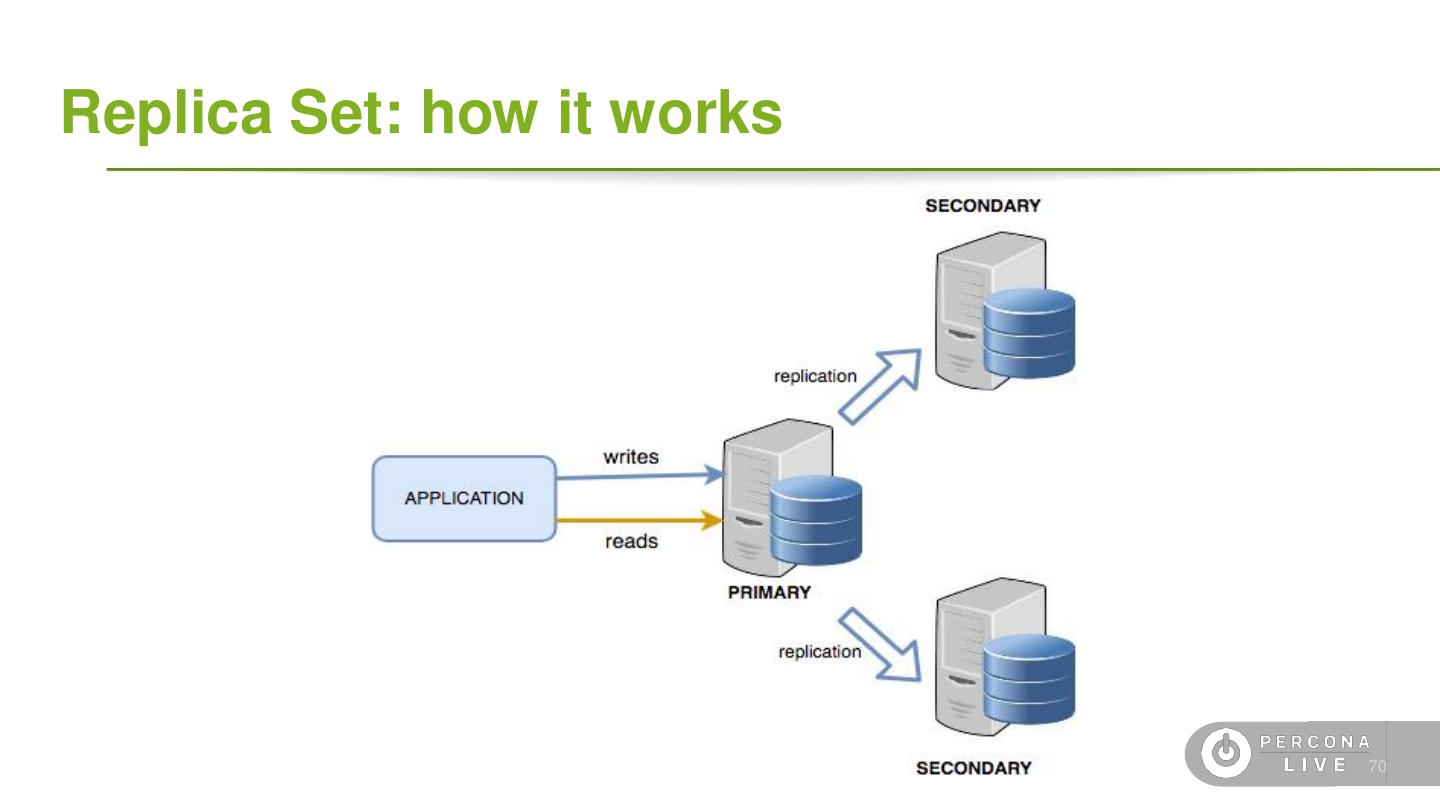
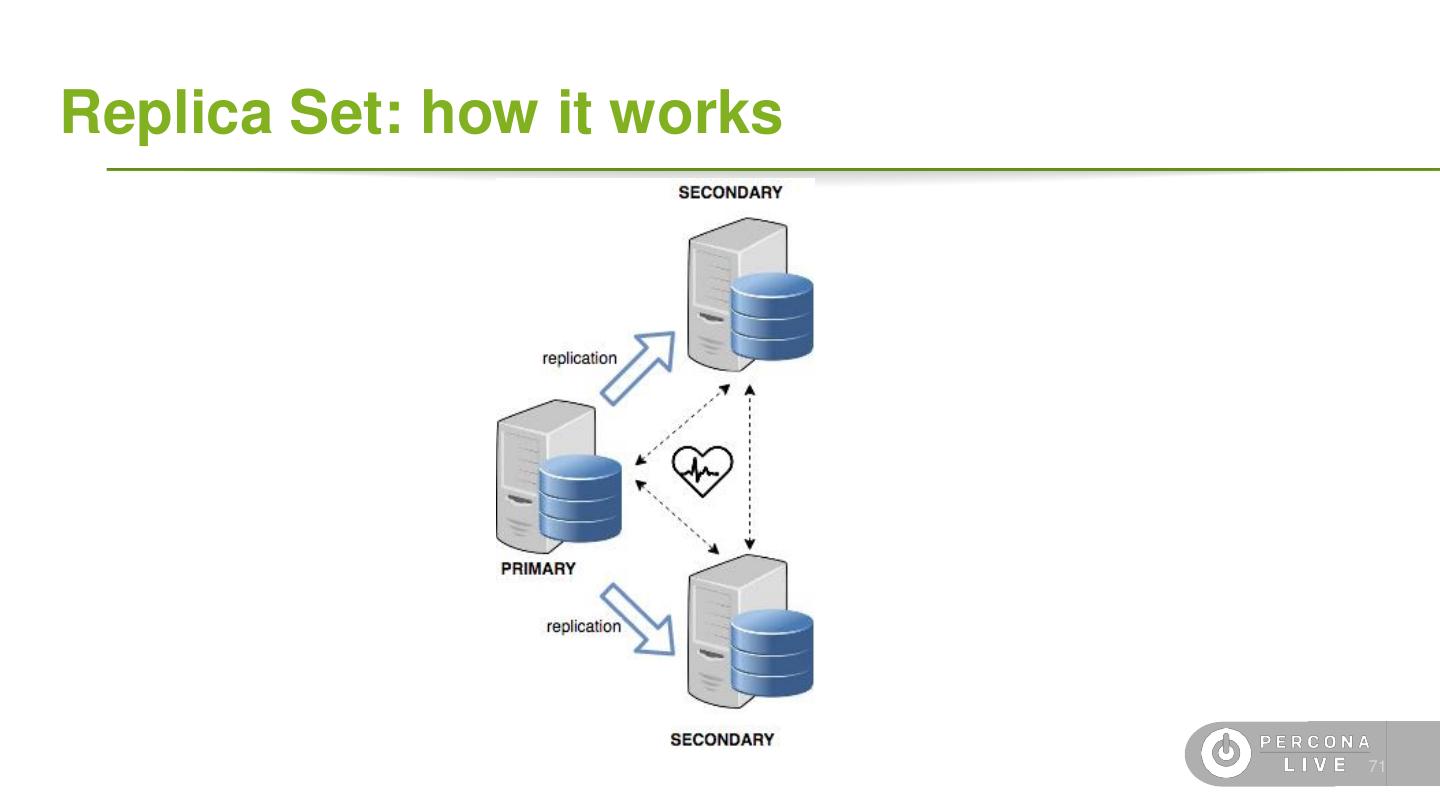
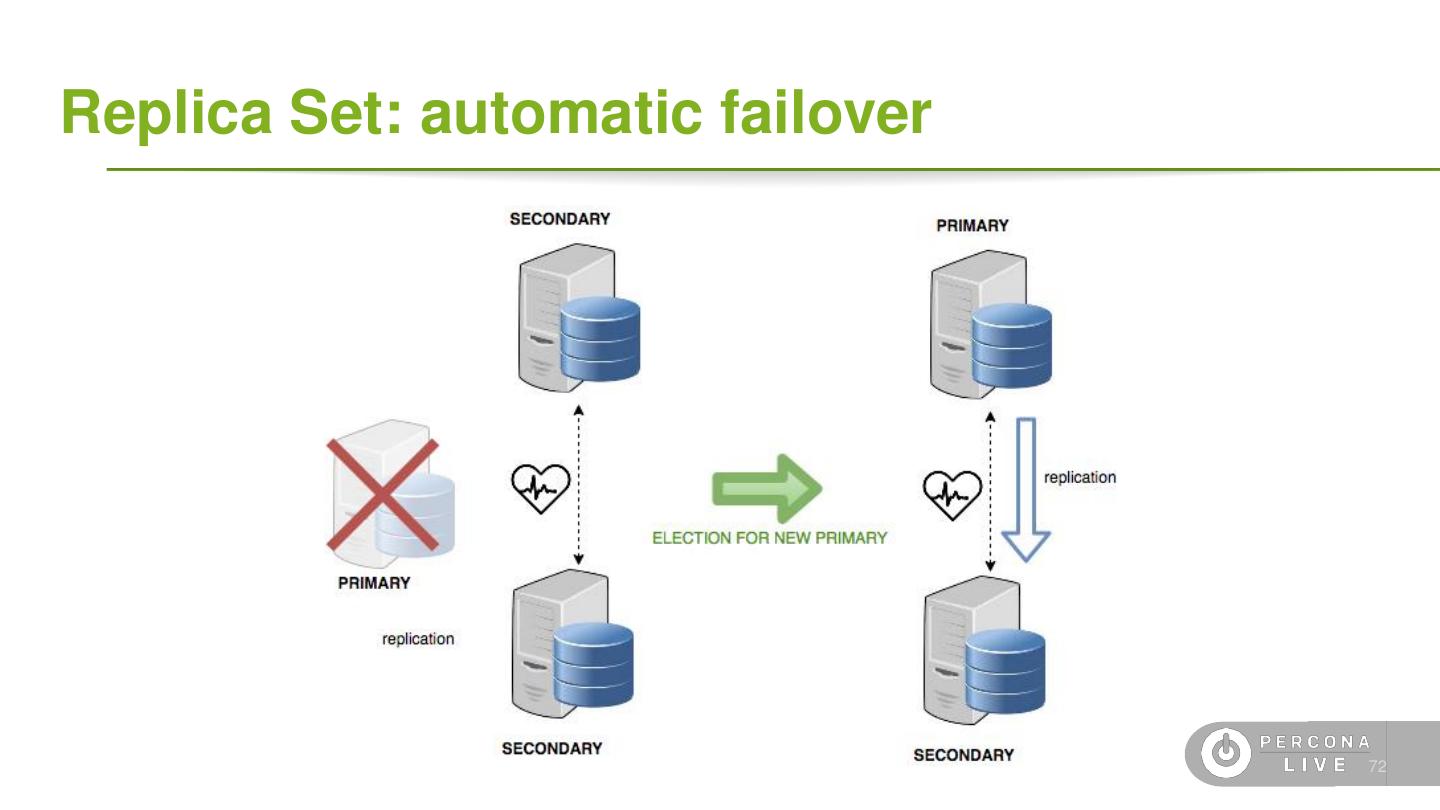
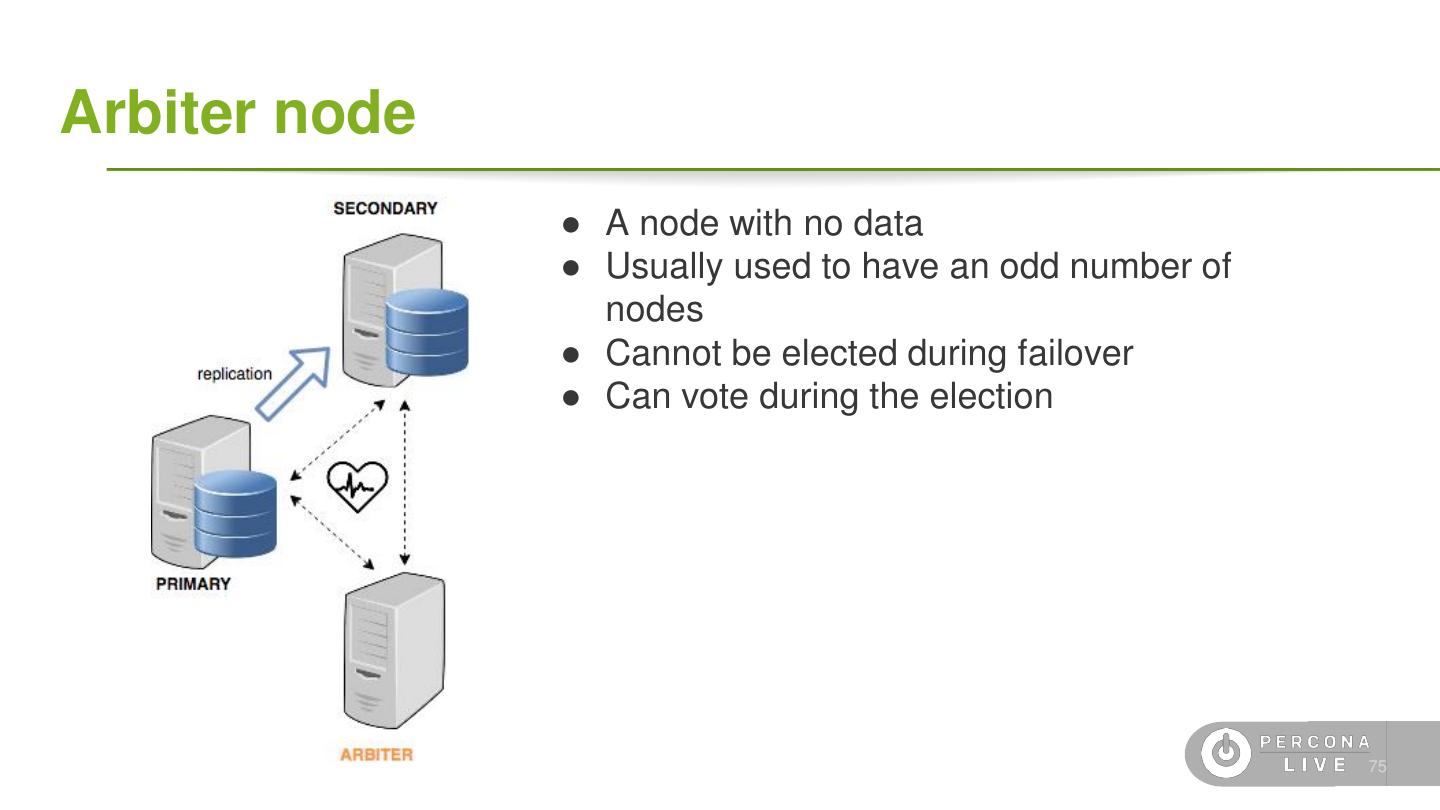
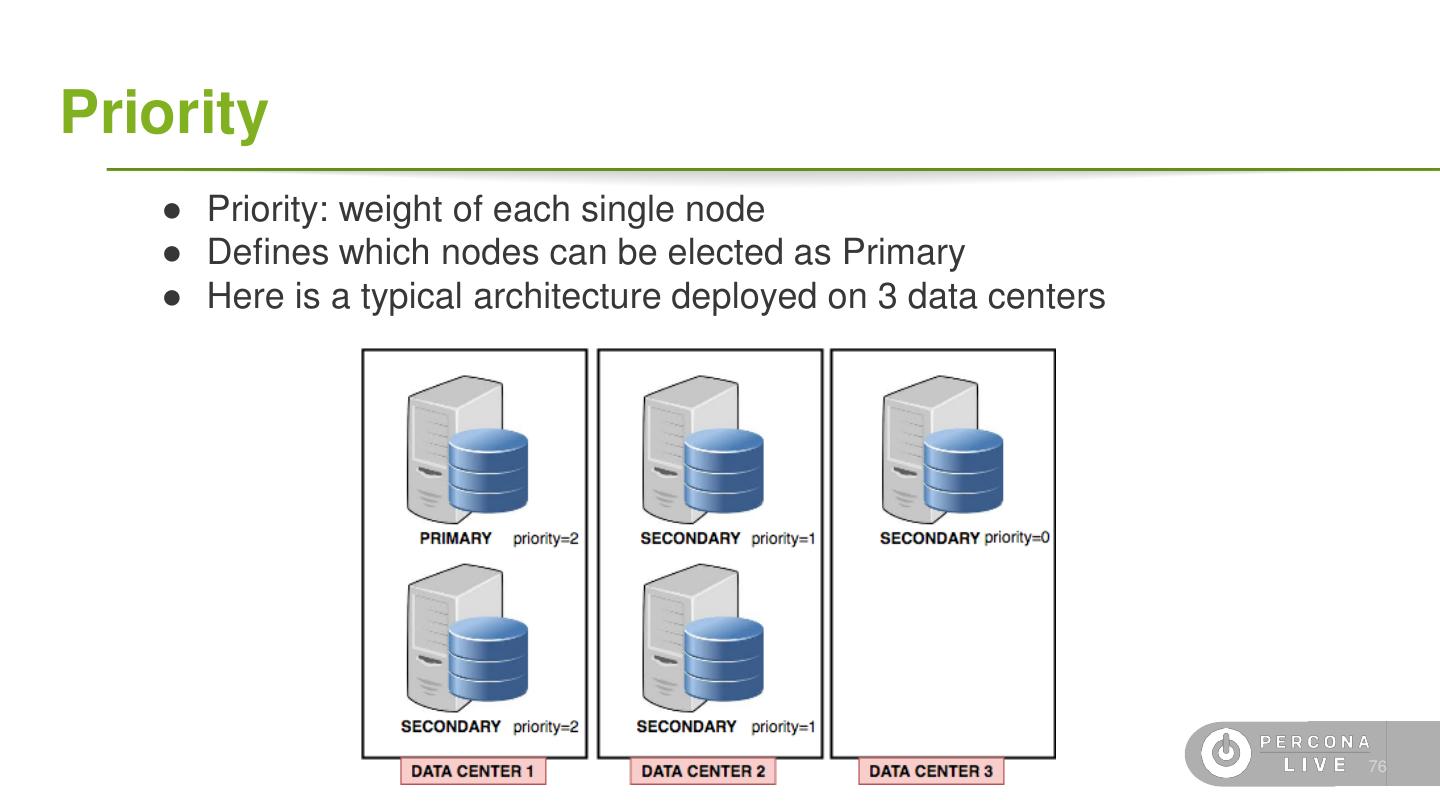
4 .Terminology ● Data ○ Document: single *SON object, often nested ○ Field: single field in a document ○ Collection: grouping of documents ○ Database: grouping of collections ○ Capped Collection: A fixed-size FIFO collection ● Replication ○ Oplog: A special capped collection for replication ○ Primary: A replica set node that can receive writes ○ Secondary: A replica of the Primary that is read-only ○ Voting: A process to elect a Primary node ○ Hidden-Secondary: A replica that cannot become Primary 6
5 .Common database architecture
6 .On site (local DC) ● Buy the biggest machine possible with a lot of fancy disks and memory. ● Retire the equipment 5 years later because they are outdated. ● Open source was available but also proprietary softwares were very present in companies. ● Buy fiber links, more than one for safety. ● Huge and heavy UPS ● Routers configuration 8
7 .On the public cloud ● Rent or reserve a machine according to the needs. ● No upfront investment ● No huge hydro bills ● No need to setup cables and buy link At the end someone else did that for you. 9
8 .On the private cloud ● Considerable upfront ● Still need to configure the hardware and buy links and disks. ● Abstraction layer to configure virtual machines usually using a platform. 10
9 .Beyond the cloud ● Use the database as a service. ● Scale up and down with a few commands ● Doesn't matter where the service is running anymore ● Docker/Mesosphere/Kubernetes and a lot more... 11
10 .Hardware configuration
11 .Hardware configuration ● Not all of those options are available in cloud, private and services. 13
12 .Disks
13 .Disks ● Crucial resource to any database or system. ● Databases needs disk to persist the data. ● Options available: Magnetic disks SSD/nvMe 15
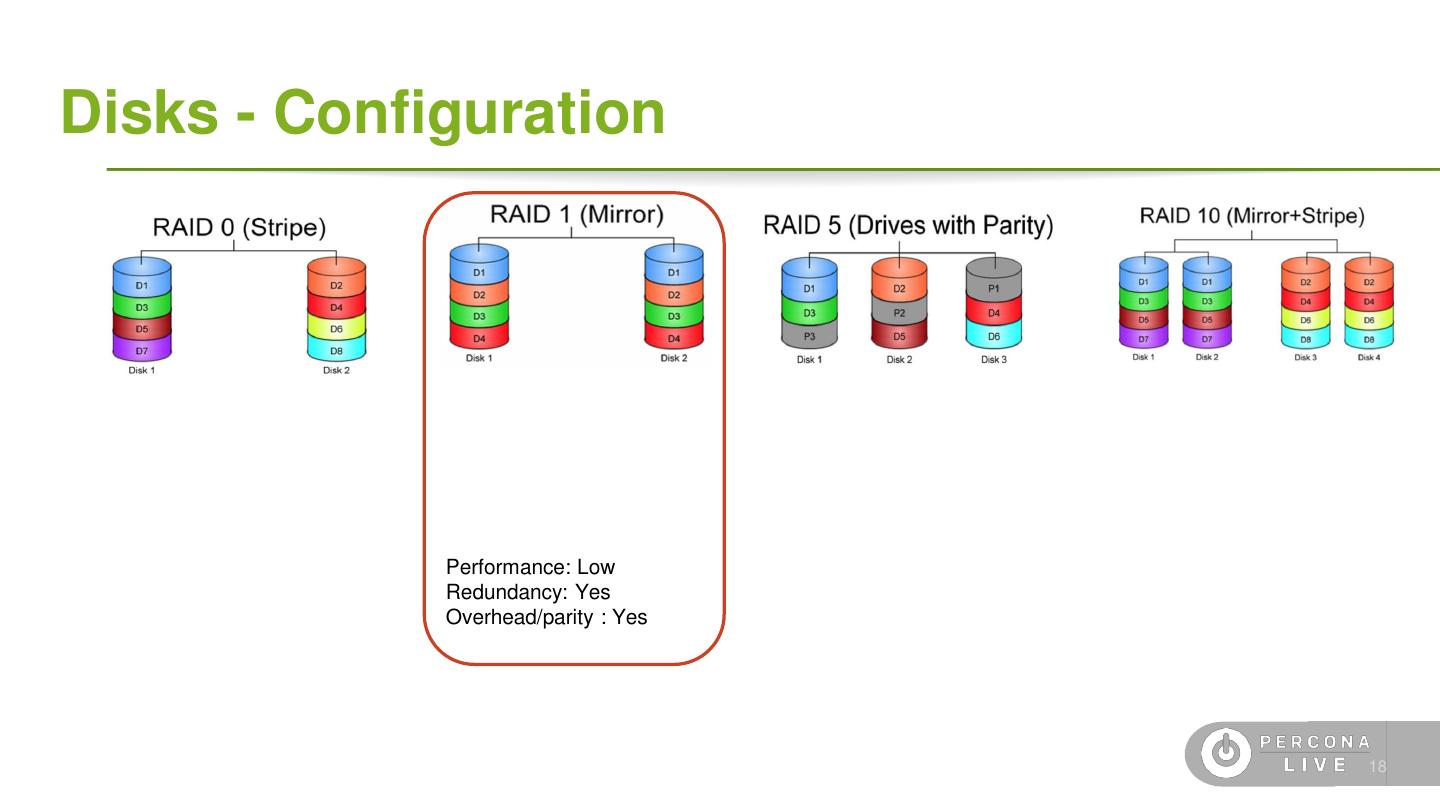
14 .Disk Configuration ● What is RAID? ● If using RAID prefer 1+0 ● Avoid RAID5 and RAID6 (write performance penalty) 16
15 .Disks - Configuration Performance: High Redundancy: None Overhead/parity : None 17
16 .Disks - Configuration Performance: Low Redundancy: Yes Overhead/parity : Yes 18
17 .Disks - Configuration Performance: High Redundancy: None Overhead/parity : Yes 19
18 . Disks - Configuration Performance: High Redundancy: Yes Overhead/parity : Yes 20 source: http://www.icc-usa.com/raid-calculator.html
19 .Disks - Configuration For cloud services local storage offers best throughput/price but remember, once the machine is restarted, all the data is erased. It is not common to see RAID 10 in cloud environments, replica-sets keeps the same data across different nodes and in case of failure all we need is to start a new box. 21
20 .Disks - Configuration Good Practices: ● Use different disk for the data folder. ● If possible move the journal to a different disk. ● SSD will give a better performance than spinning disks. ● If using EBS consider io2 family to guarantee IOPS 22
21 .Disks - Configuration Warnings: ● EBS without PIOPS may reach out the IOPS limits in the middle of the business day slowing down the application. ● Do not share the same disks for replica-sets in a storage. ● NFS/remote disks will slow down the database and tend to have more issues than local/fiber connected disks 23
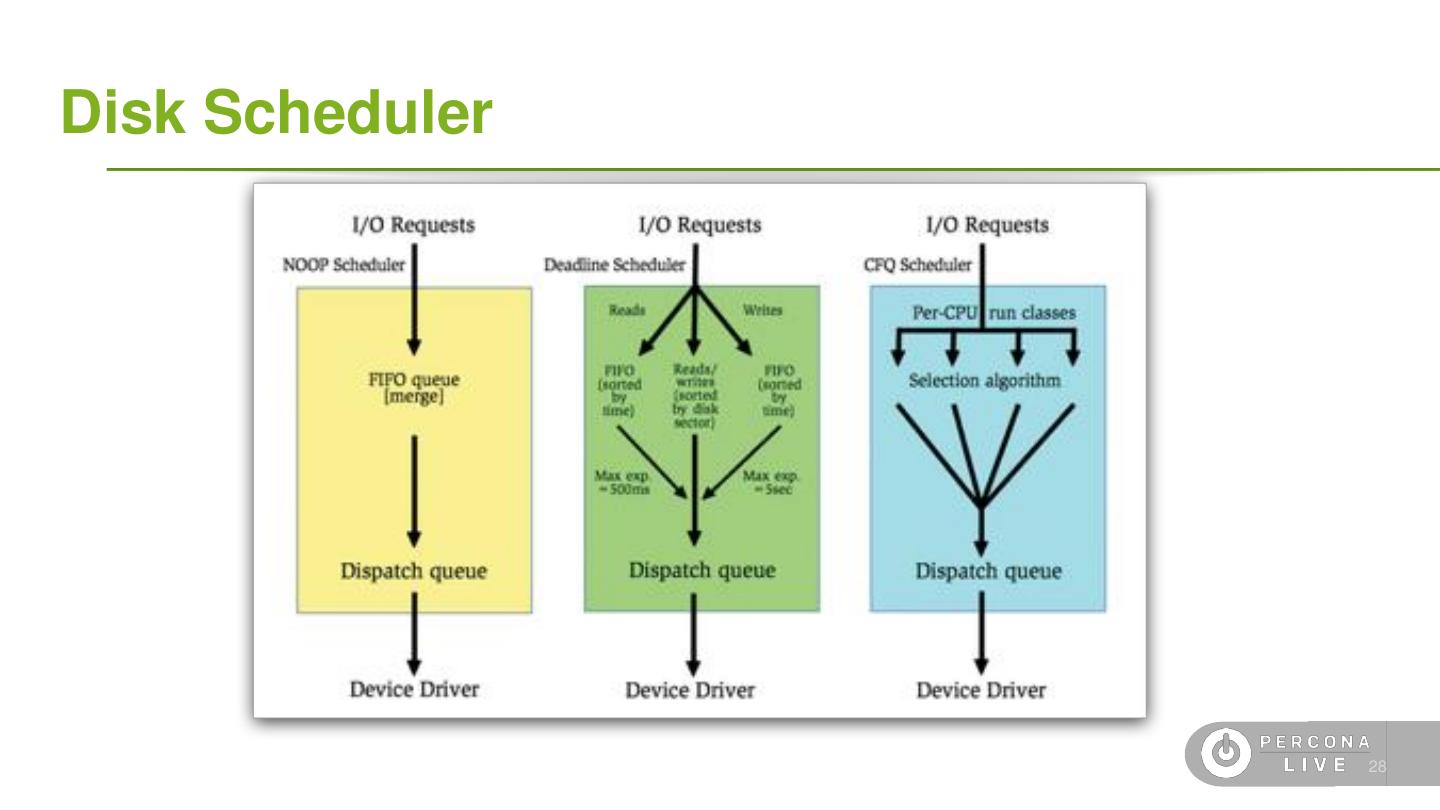
22 .Disk Scheduler ● Disk scheduler may affect the database performance. ● Most common disk schedulers are: NOOP DEADLINE CFQ 24
23 .Disk Scheduler - NOOP First Come First Serve 25
24 .Disk Scheduler - Deadline Reads have priority. Writes are queued as that can happen asynchronous. This scheduler try to speed up reads as the application may need the data to return results to the client. 26
25 .Disk Scheduler - Complete Fair Queue Time slide per process 27
26 .Disk Scheduler 28
27 .Disk Filesystems ● Filesystem Types ○ Use XFS or EXT4 ■ Use XFS only on WiredTiger ■ EXT4 “data=ordered” mode recommended ○ Btrfs not tested, yet! ● Filesystem Options ○ Set ‘noatime’ on MongoDB data volumes in ‘/etc/fstab’: ○ ○ Remount the filesystem after an options change, or reboot 29
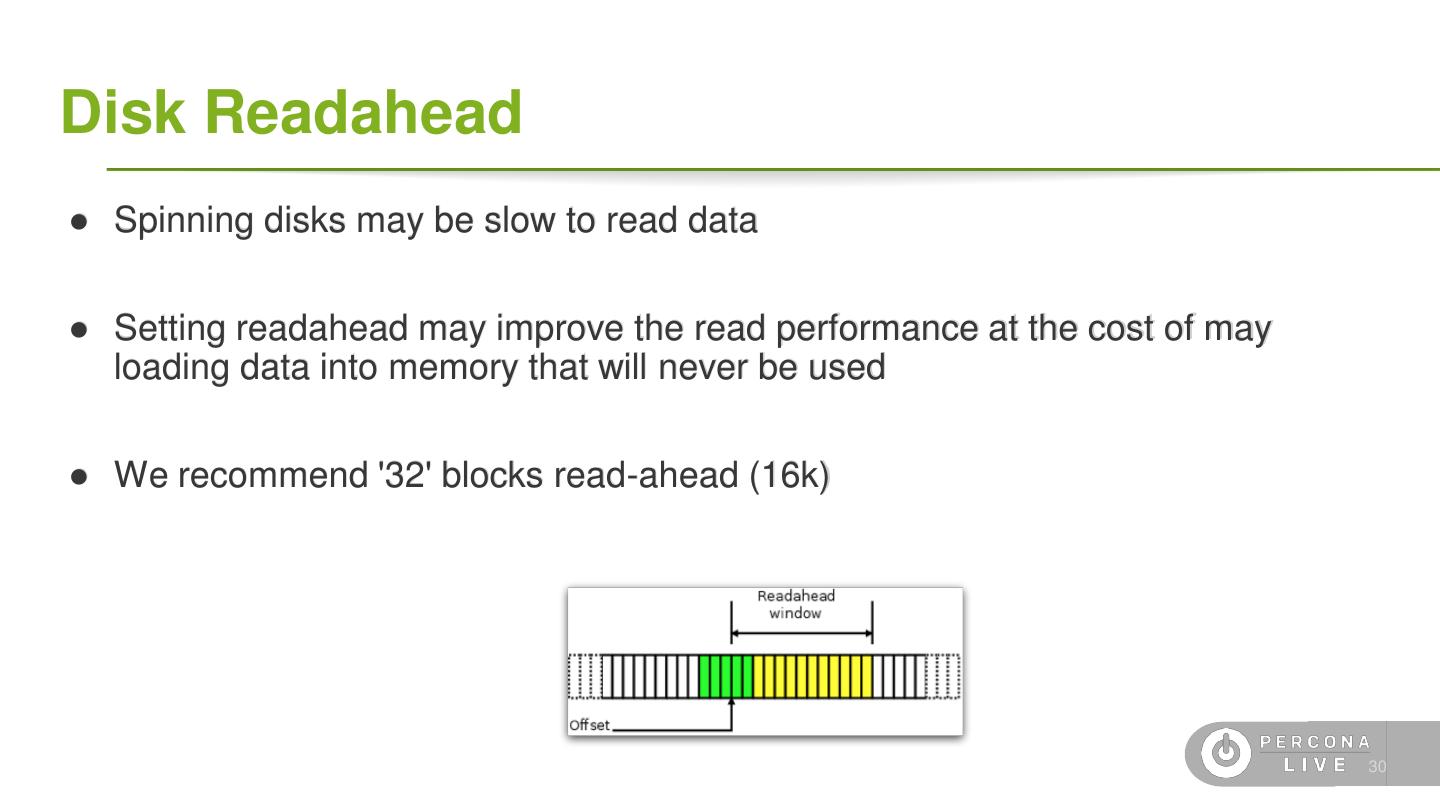
28 .Disk Readahead ● Spinning disks may be slow to read data ● Setting readahead may improve the read performance at the cost of may loading data into memory that will never be used ● We recommend '32' blocks read-ahead (16k) 30
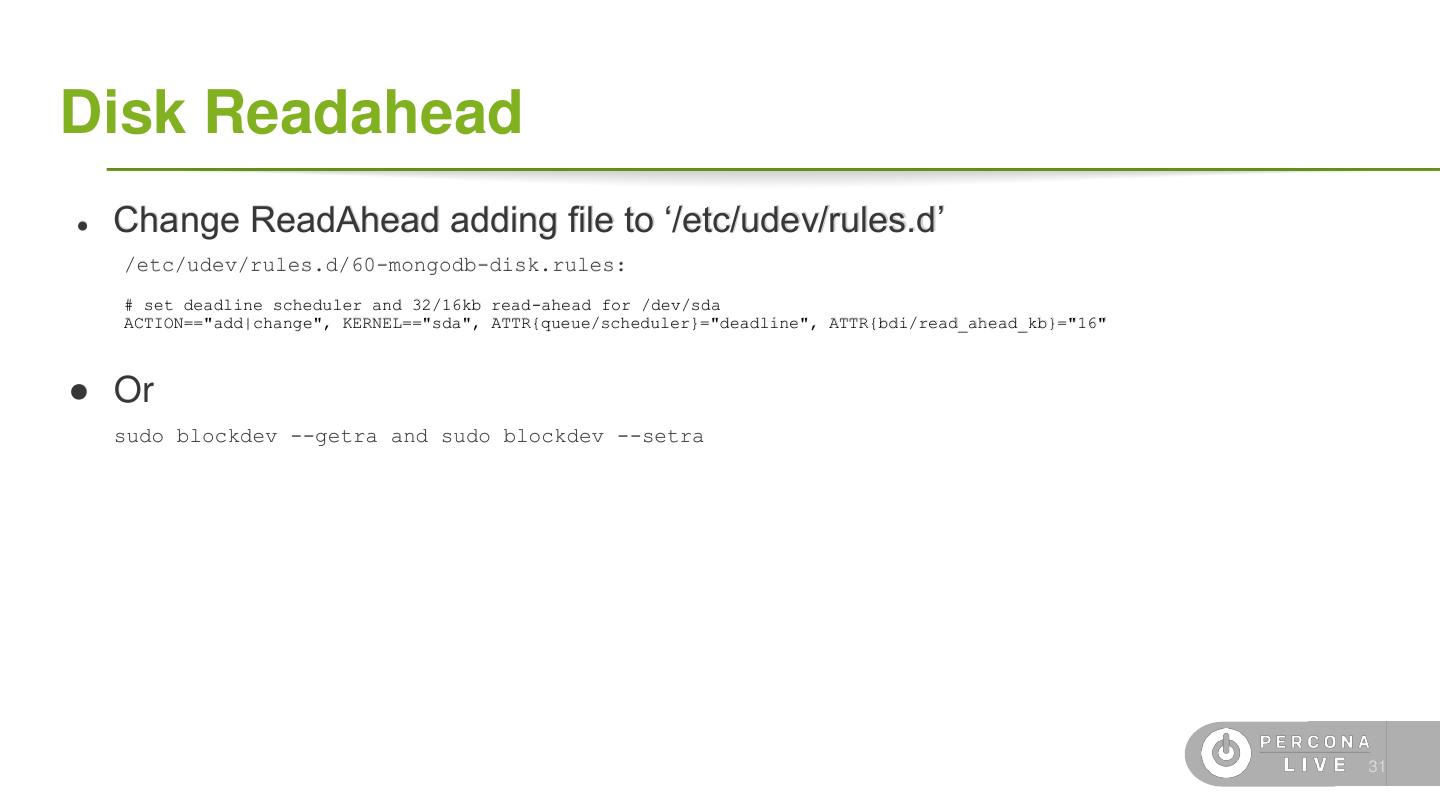
29 .Disk Readahead ● Change ReadAhead adding file to ‘/etc/udev/rules.d’ /etc/udev/rules.d/60-mongodb-disk.rules: # set deadline scheduler and 32/16kb read-ahead for /dev/sda ACTION=="add|change", KERNEL=="sda", ATTR{queue/scheduler}="deadline", ATTR{bdi/read_ahead_kb}="16" ● Or sudo blockdev --getra and sudo blockdev --setra 31
3秒后跳转登录页面
去登陆

