


















- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
OAP:基于 Spark 的索引加速引擎
介绍Optimized Analytics Package for Apache Spark的原理以及在百度内部使用的性能收益。
展开查看详情
1 .Daoyuan Wang (Intel) Yuanjian Li ( Baidu ) OAP: Optimized Analytics Package for Spark Platform
2 .Daoyuan Wang (Intel) Yuanjian Li ( Baidu ) OAP: Optimized Analytics Package for Spark Platform
3 .About me Daoyuan Wang developer@Intel Focuses on Spark optimization An active Spark contributor since 2014 Yuanjian Li Baidu INF distributed computation Apache Spark contributor B aidu Spark team leader
4 .Agenda Background for OAP Key features Benchmark OAP and Spark in Baidu Future plans
5 .Agenda Background for OAP Key features Benchmark OAP and Spark in Baidu Future plans
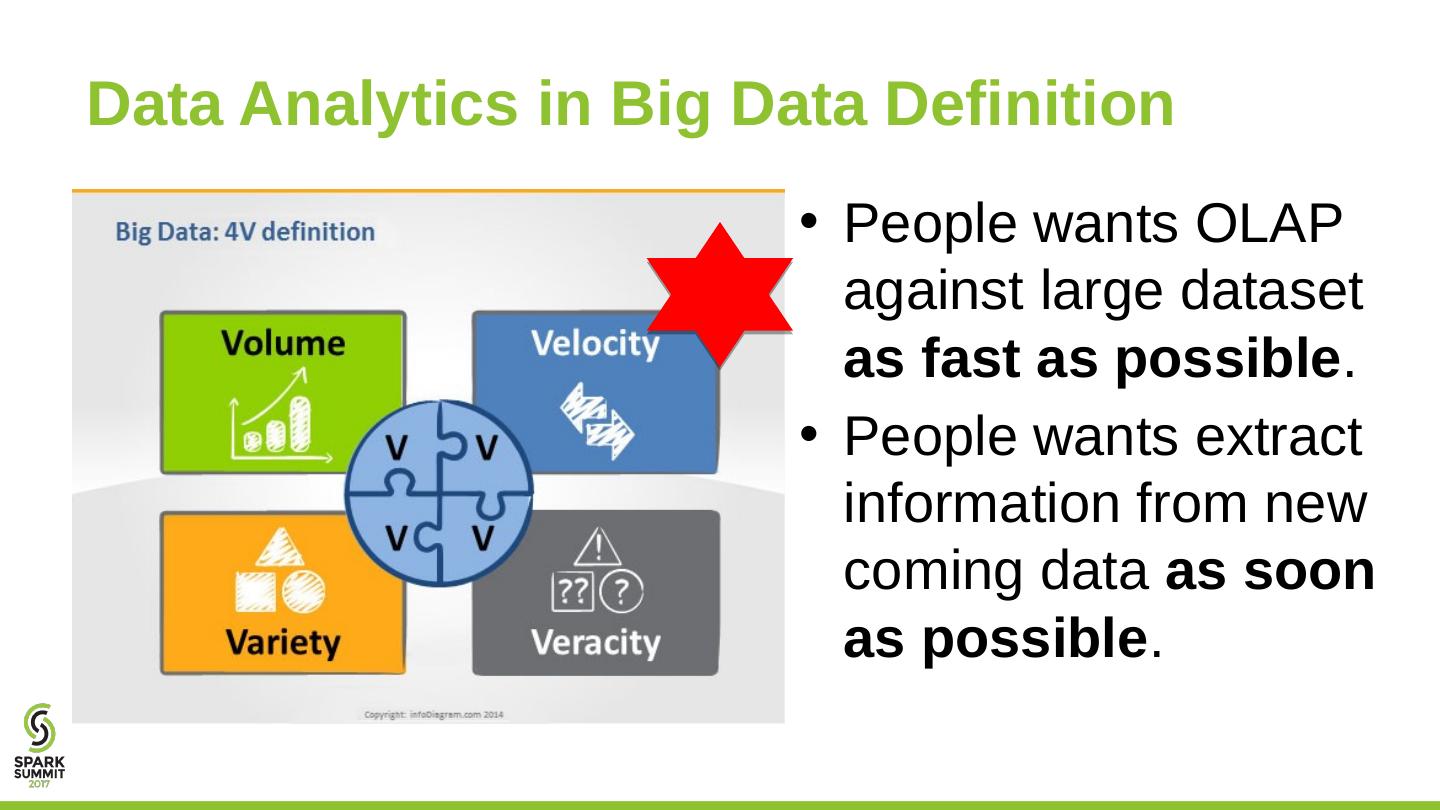
6 .Data Analytics in Big Data Definition People wants OLAP against large dataset as fast as possible . People wants extract information from new coming data as soon as possible .
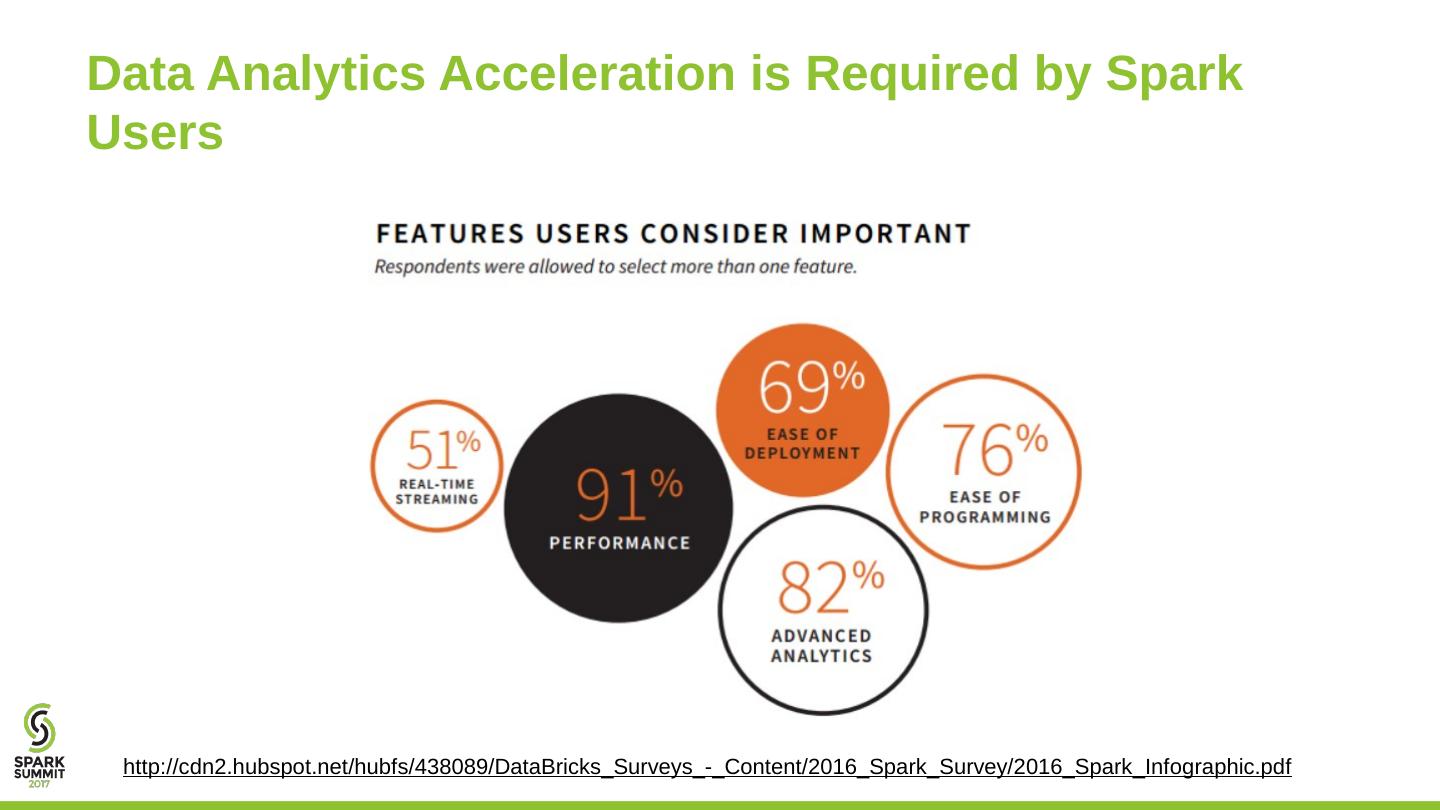
7 .Data Analytics Acceleration is Required by Spark Users http://cdn2.hubspot.net/hubfs/438089/DataBricks_Surveys_-_Content/2016_Spark_Survey/2016_Spark_Infographic.pdf
8 .Emerging hardware technology Intel® Optane ™ Technology Data Center Solutions Accelerate applications for fast caching and storage, reduce transaction costs for latency-sensitive workloads and increase scale per server. Intel® Optane ™ technology allows data centers to deploy bigger and more affordable datasets to gain new insights from large memory pools.
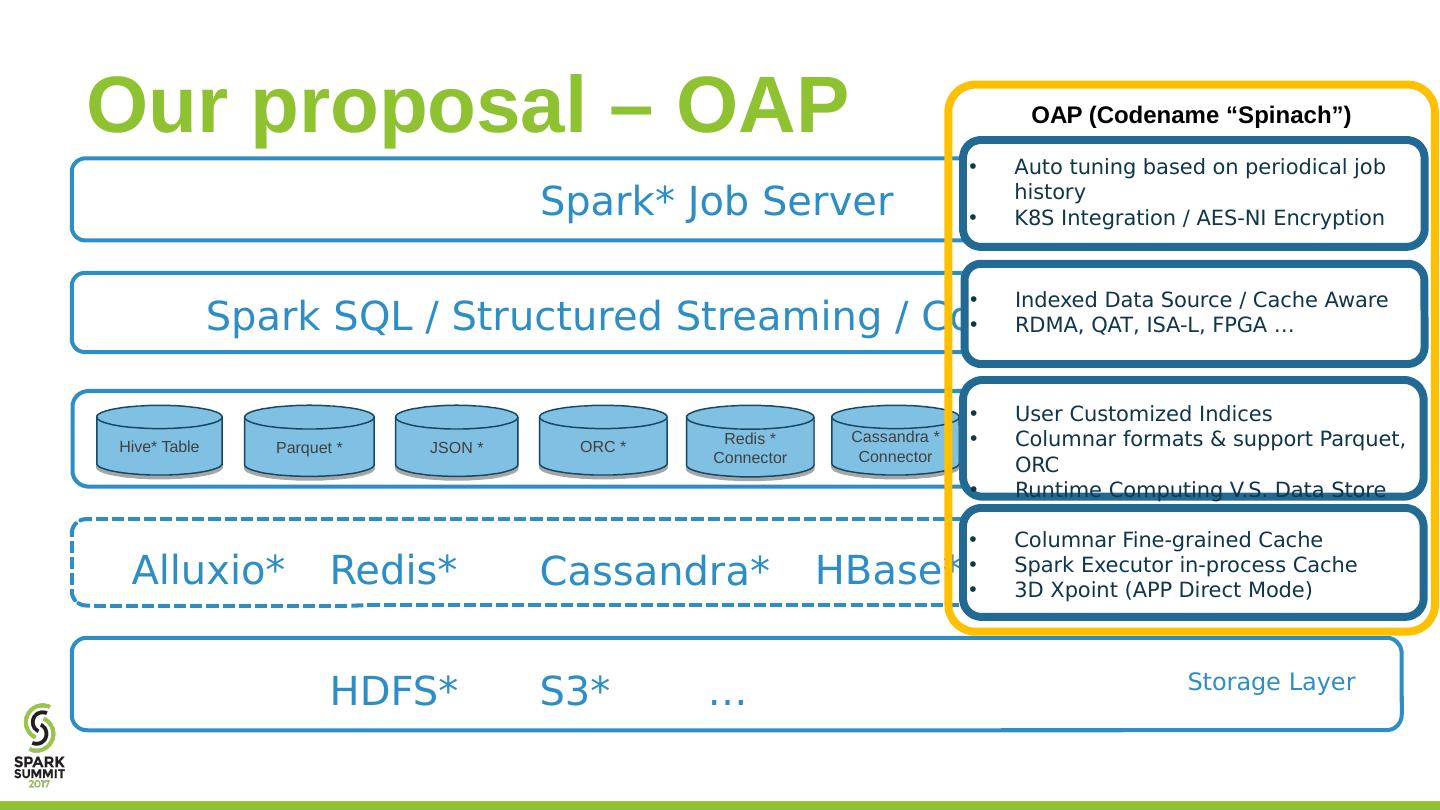
9 .Our proposal – OAP Spark* Job Server Spark SQL / Structured Streaming / Core Cassandra* HBase * Redis * Alluxio * HDFS * S3 * … Storage Layer Hive* Table Parquet * JSON * ORC * Redis * Connector Cassandra * Connector OAP (Codename “Spinach”) Indexed Data Source / Cache Aware RDMA, QAT, ISA-L, FPGA … User Customized Indices Columnar formats & support Parquet, ORC Runtime Computing V.S. Data Store Columnar Fine-grained Cache Spark Executor in-process Cache 3D X p oint (APP Direct Mode) Auto tuning based on periodical job history K8S Integration / AES-NI Encryption
10 .Why OAP
11 .Why OAP
12 .A S imple Example 1. Run with OAP $SPARK_HOME/ sbin /start- thriftserver --package oap.jar ; 2. Create a OAP table beeline> CREATE TABLE src (a: Int , b: String) USING spn ; 3. Create a single column B+ Tree index beeline> CREATE SINDEX idx_1 ON src (a) USING BTREE; 4. Insert data beeline> INSERT INTO TABLE src SELECT key, value FROM xxx; 5. Refresh index beeline> REFRESH SINDEX on src ; 6. Execution would automatically utilize index beeline> SELECT MAX(value), MIN(value) FROM src WHERE a > 100 and a < 1000;
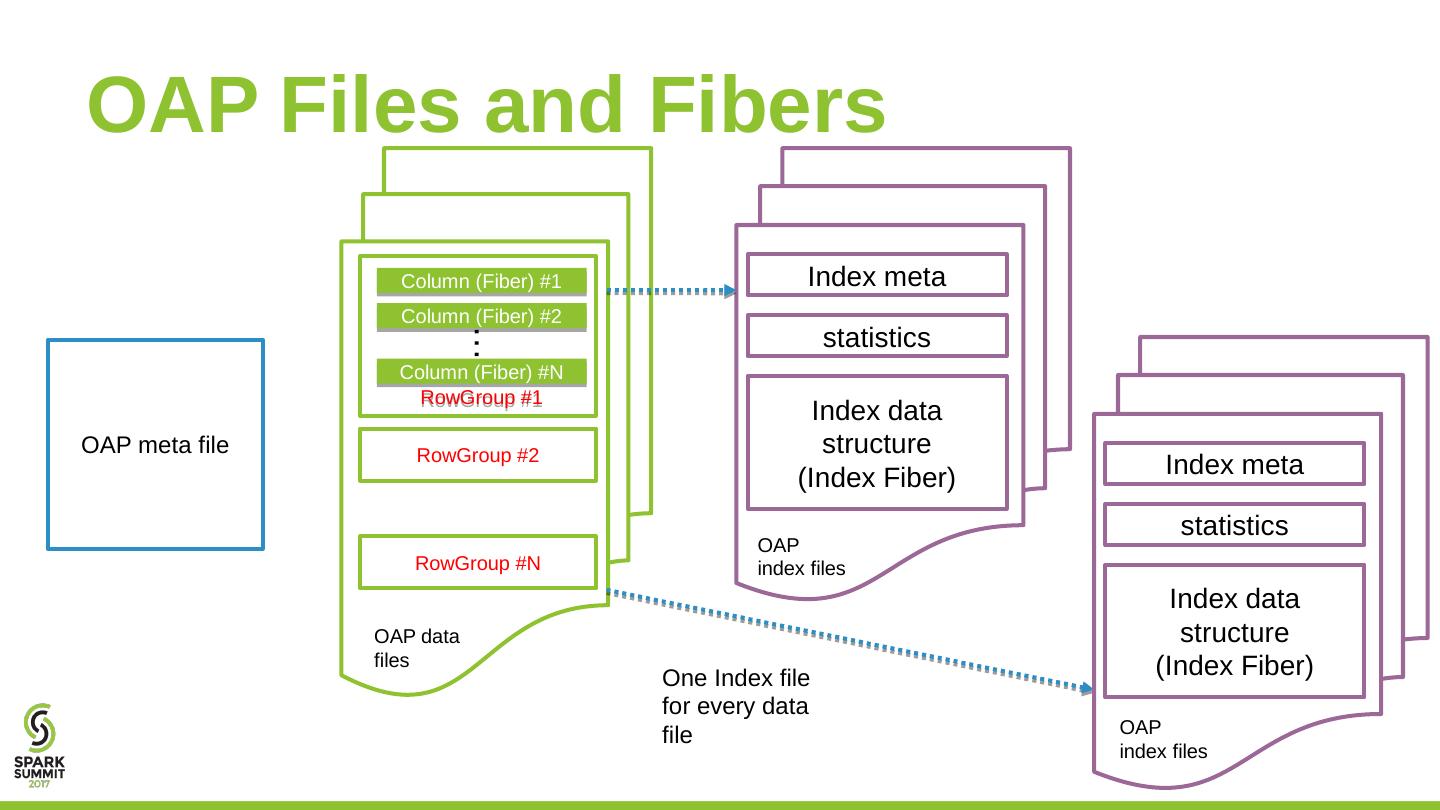
13 .OAP Files and Fibers Column (Fiber) #1 Column (Fiber) #2 Column (Fiber) #N RowGroup #1 … RowGroup #2 RowGroup #N Index meta statistics Index data structure (Index Fiber) One Index file for every data file Index meta statistics Index data structure (Index Fiber) OAP meta file OAP data files OAP index files OAP index files
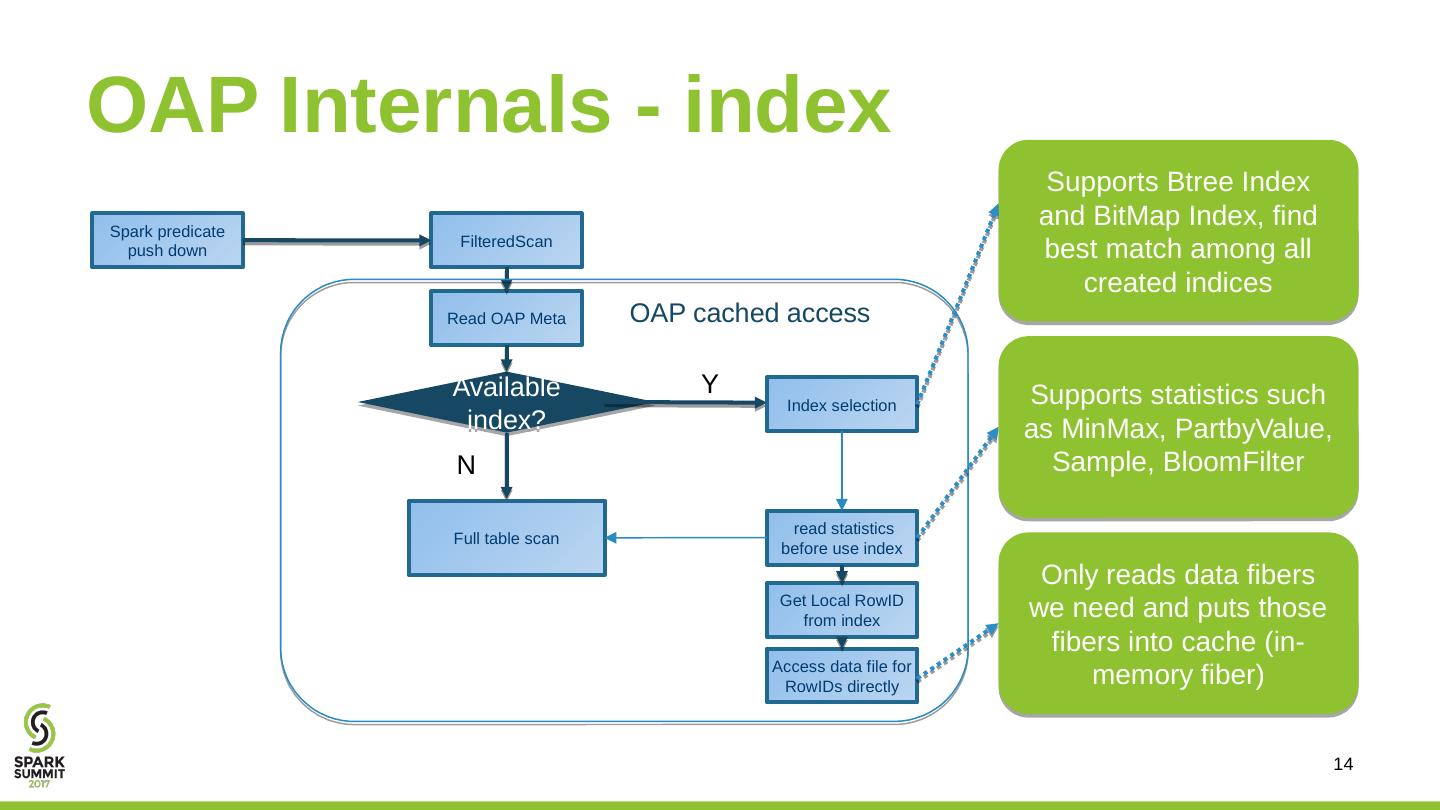
14 .14 OAP Internals - index Spark predicate push down FilteredScan Read OAP Meta Available index ? read statistics before use index Get Local RowID from index Full table scan Access data file for RowIDs directly Y N OAP cached access Index selection Supports Btree Index and BitMap Index, find best match among all created indices Supports statistics such as MinMax , PartbyValue , Sample, BloomFilter Only reads data fibers we need and puts those fibers into cache (in-memory fiber)
15 .OAP compatible layer RowGroup #k RowGroup #1 RowGroup #2 Parquet compatible layer Read row #m from parquet file Find Row group #k Read row group and get specific rows In-memory fiber contains Row #m data Parquet data file Cache
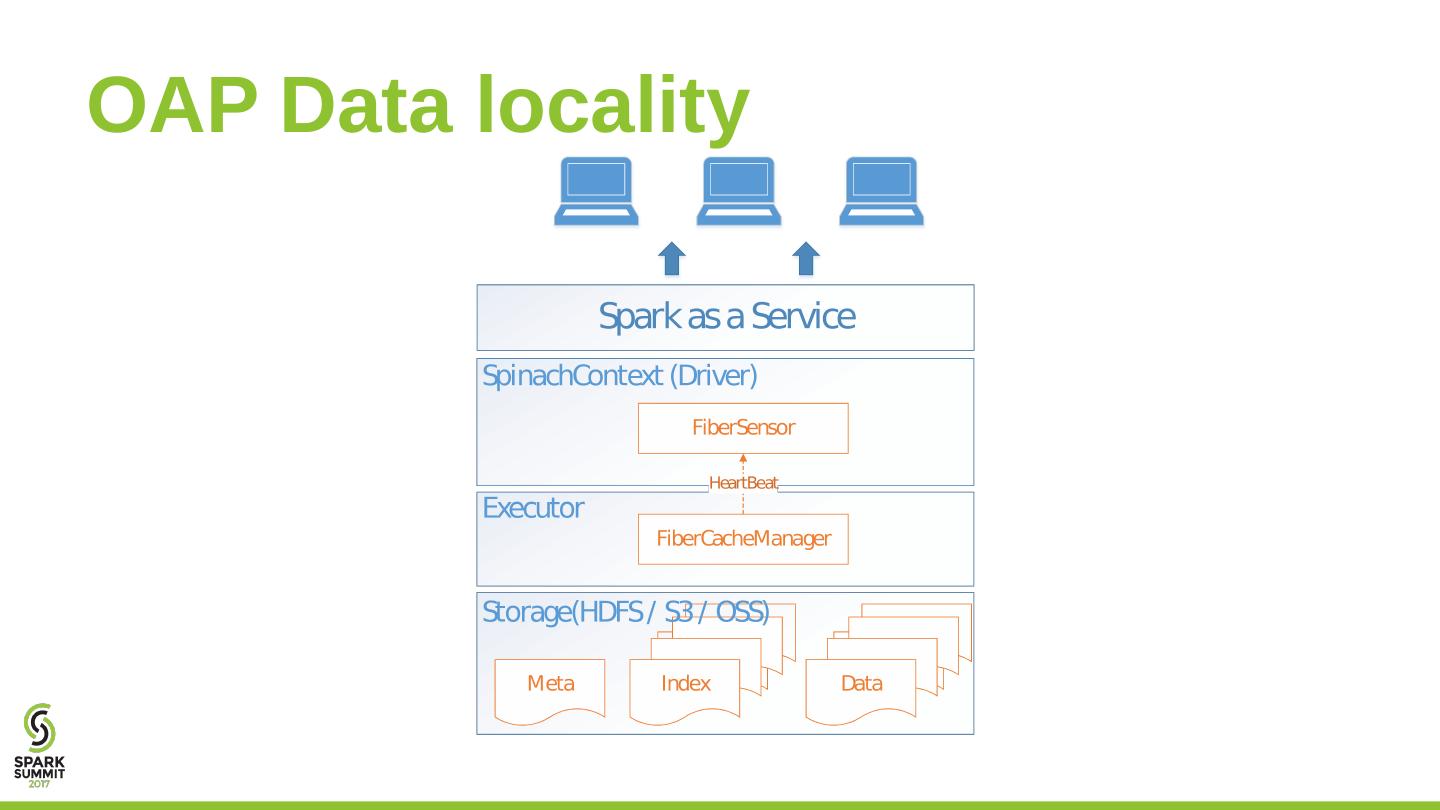
16 .OAP Data locality
17 .OAP Data locality
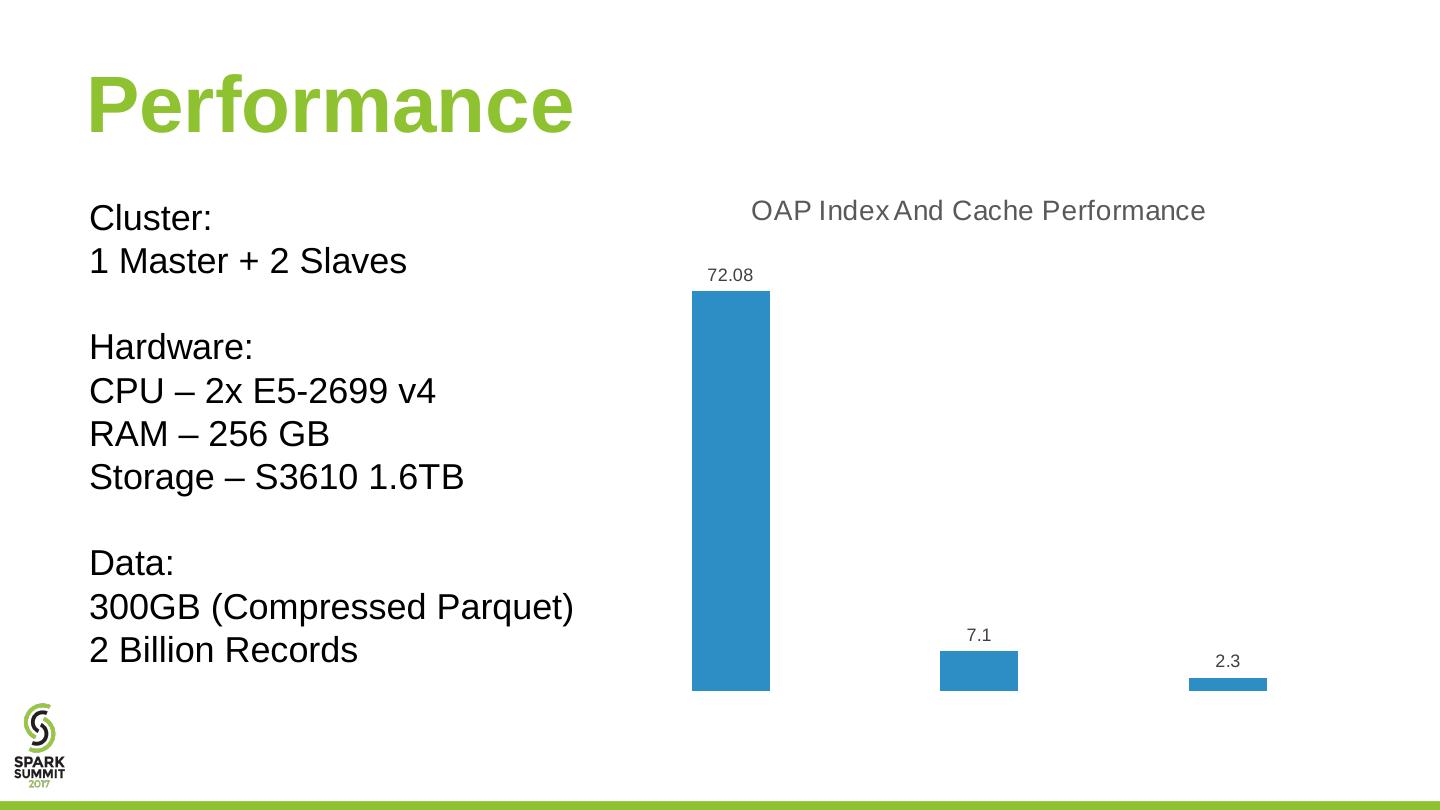
18 .Performance Cluster: 1 Master + 2 Slaves Hardware: CPU – 2x E5-2699 v4 RAM – 256 GB Storage – S3610 1.6TB Data: 300GB (Compressed Parquet ) 2 Billion Records
19 .Performance Cluster: 1 Master + 2 Slaves Hardware: CPU – 2x E5-2699 v4 RAM – 256 GB Storage – S3610 1.6TB Data: 300GB (Compressed Parquet ) 2 Billion Records
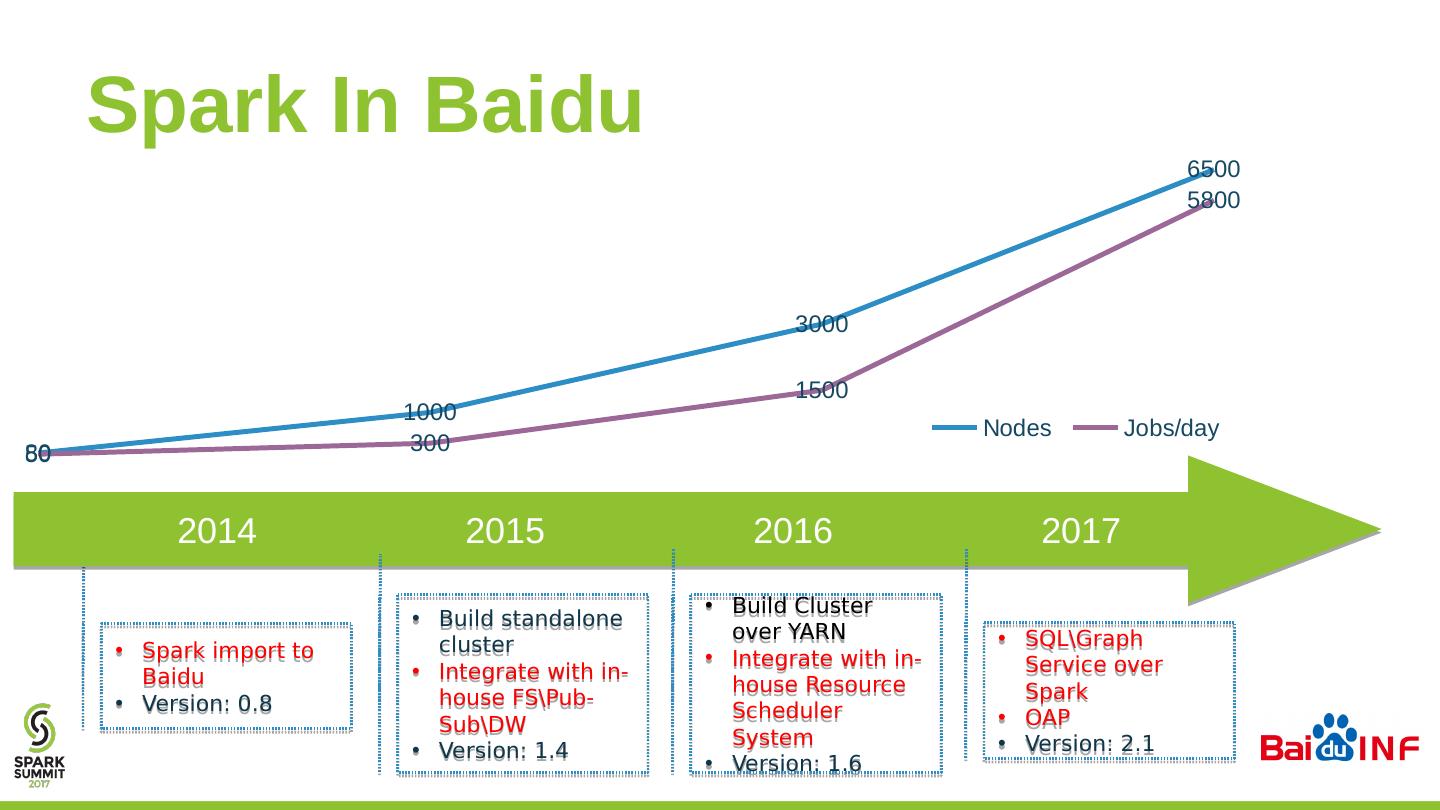
20 .Spark In Baidu Spark i mport to Baidu Version: 0.8 2014 2015 2016 2017 Build standalone c luster Integrate with in-house FS\Pub-Sub\DW Version: 1.4 Build Cluster over YARN Integrate with in-house Resource Scheduler System Version: 1.6 SQL\Graph Service over Spark OAP Version: 2.1
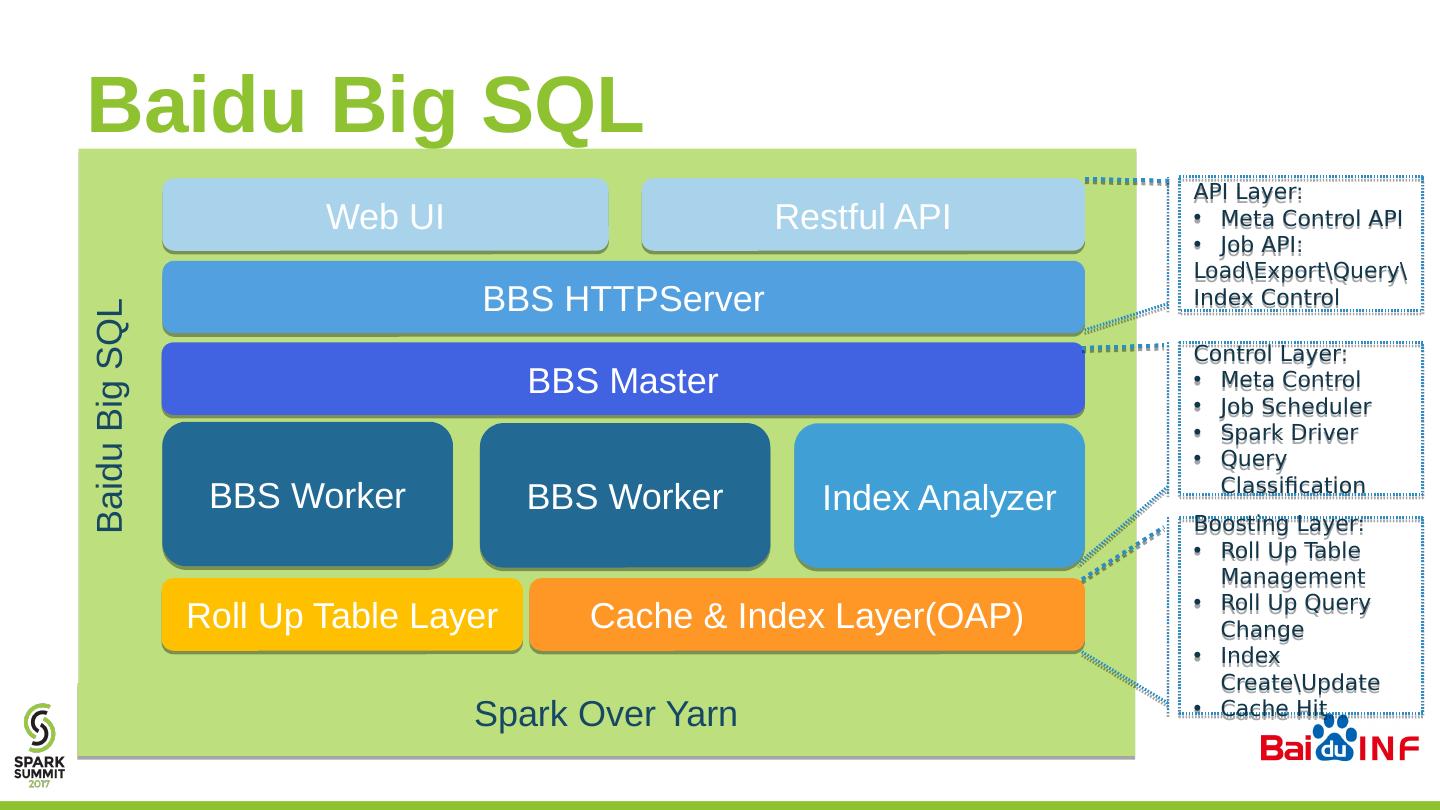
21 .Baidu Big SQL Baidu Big SQL Web UI Restful API BBS HTTPServer BBS Worker BBS Worker Index Analyzer BBS Master Cache & Index Layer(OAP) Spark Over Yarn Roll Up Table Layer API Layer: Meta Control API Job API: Load\Export\Query\Index Control Control Layer: Meta Control Job Scheduler Spark Driver Query Classification Boosting Layer: Roll Up Table Management Roll Up Query Change Index Create\Update Cache Hit
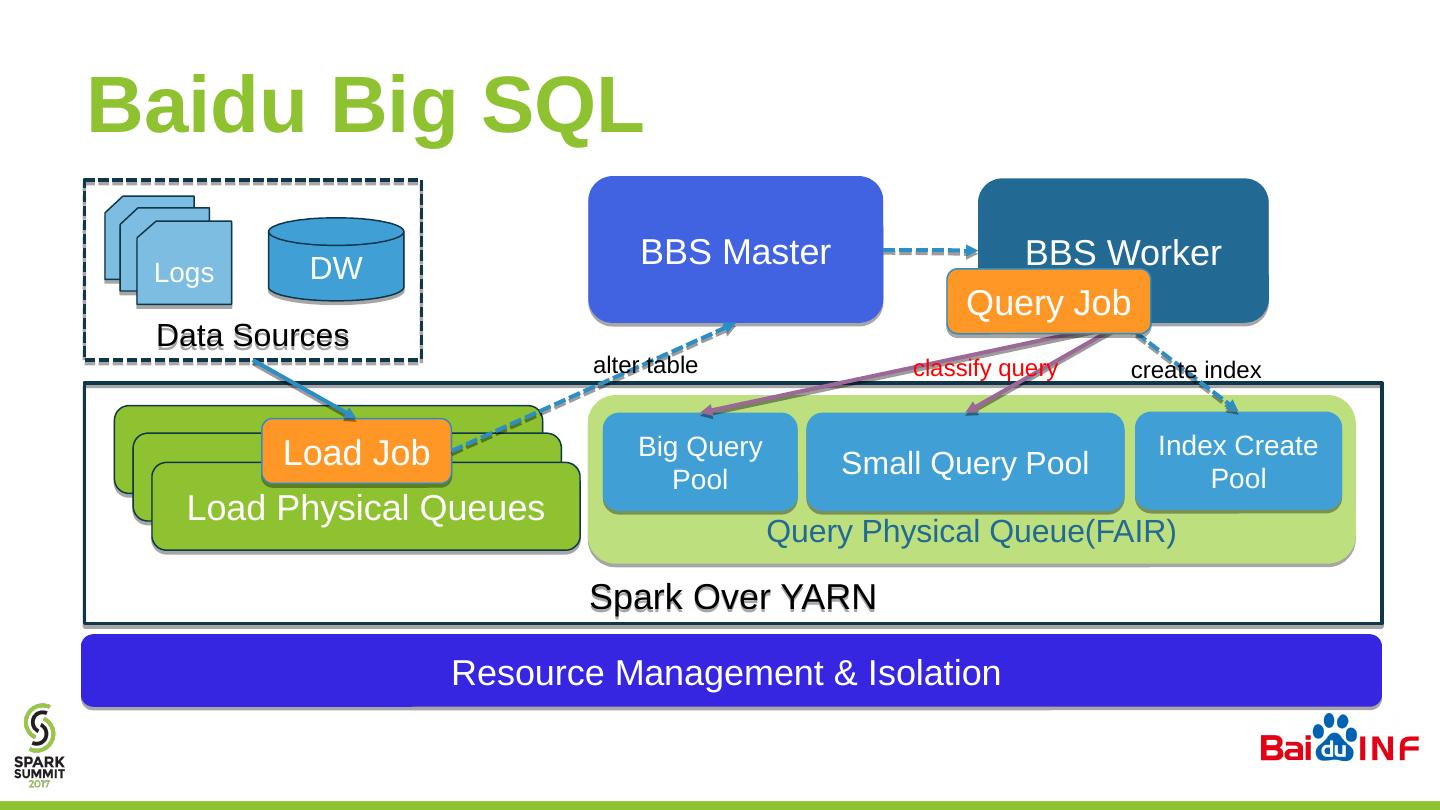
22 .Baidu Big SQL Query Physical Queue(FAIR) Import Physical Queues BBS Worker Big Query Pool Small Query Pool Index Create Pool BBS Master Import Physical Queues Load Physical Queues Spark Over YARN Data Sources Logs DW Load Job a lter table create index classify query Resource Management & Isolation Query Job
23 .Introductory Story
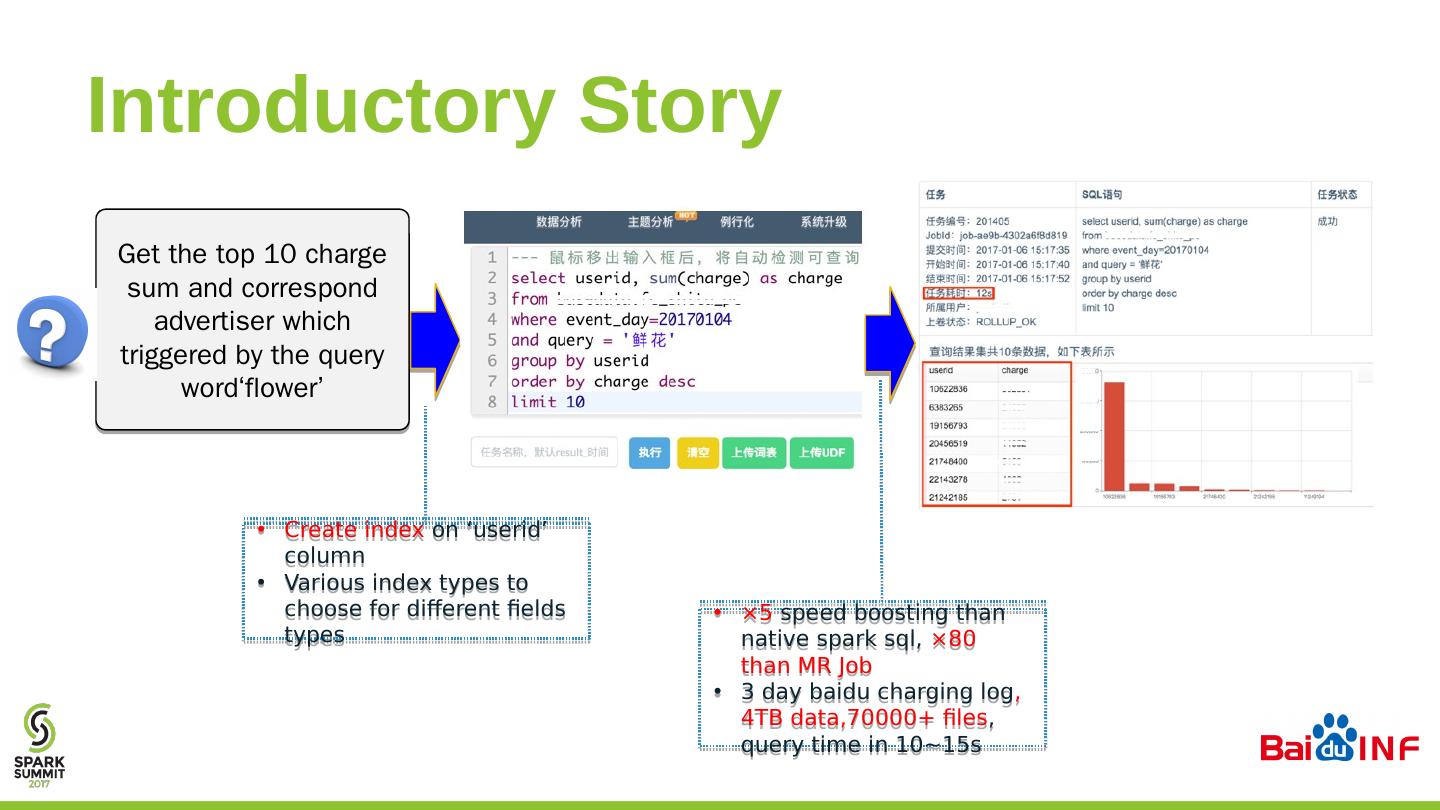
24 .Introductory Story Get the top 10 charge sum and correspond advertiser which triggered by the query word‘flower ’ Create index on ‘ userid ’ column Various index types to choose for different fields types ×5 speed boosting than native spark sql , ×80 than MR Job 3 day baidu charging log , 4TB data,70000+ files , query time in 10~15s
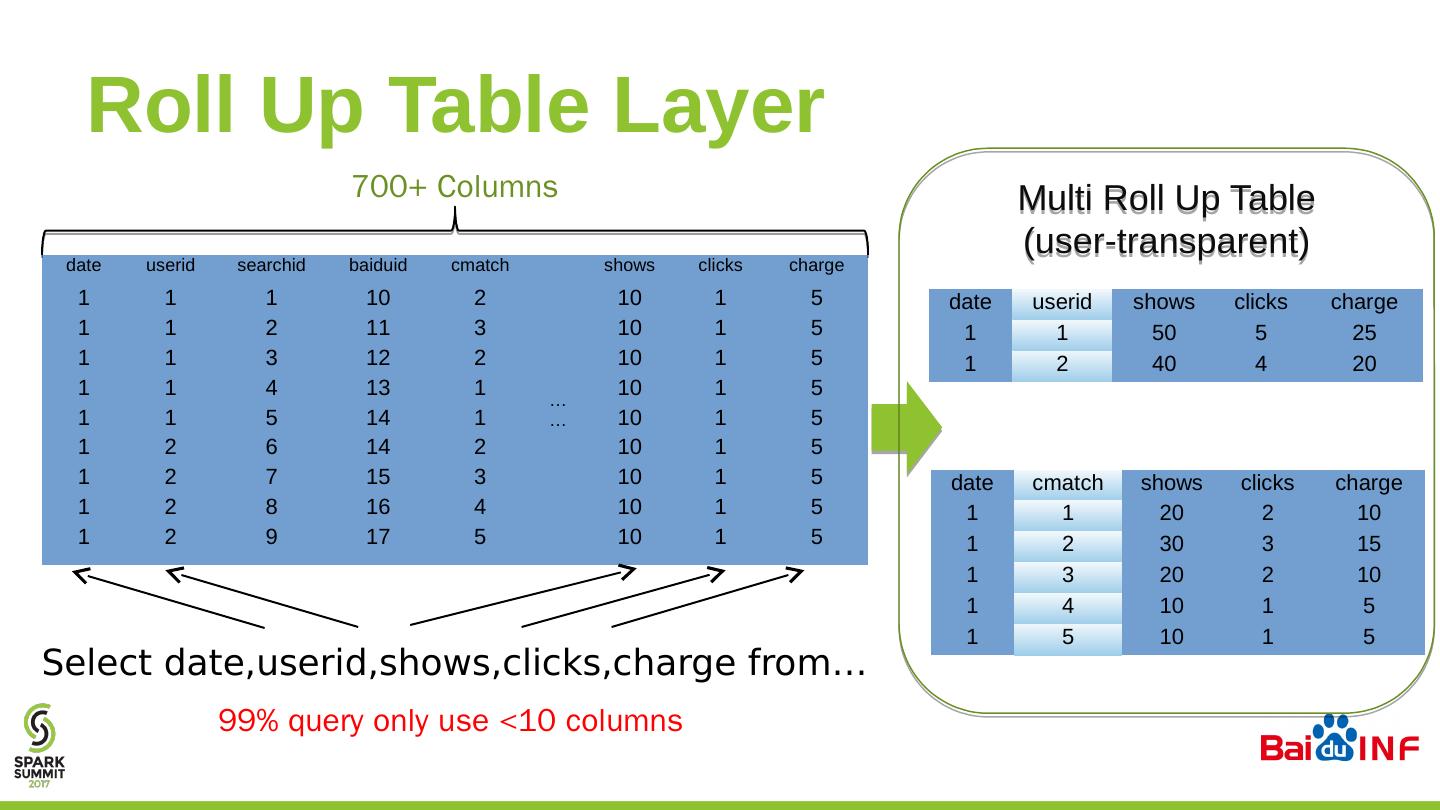
25 .Roll Up Table Layer date userid searchid b aiduid cmatch …… shows clicks charge 1 1 1 10 2 10 1 5 1 1 2 11 3 10 1 5 1 1 3 12 2 10 1 5 1 1 4 13 1 10 1 5 1 1 5 14 1 10 1 5 1 2 6 14 2 10 1 5 1 2 7 15 3 10 1 5 1 2 8 16 4 10 1 5 1 2 9 17 5 10 1 5 700 + Columns 99% query only use <10 columns Select date , userid , shows , clicks , charge from… date userid shows clicks charge 1 1 5 0 5 25 1 2 4 0 4 20 Multi Roll Up Table (user-transparent) date cmatch shows clicks charge 1 1 20 2 10 1 2 30 3 15 1 3 20 2 10 1 4 10 1 5 1 5 10 1 5
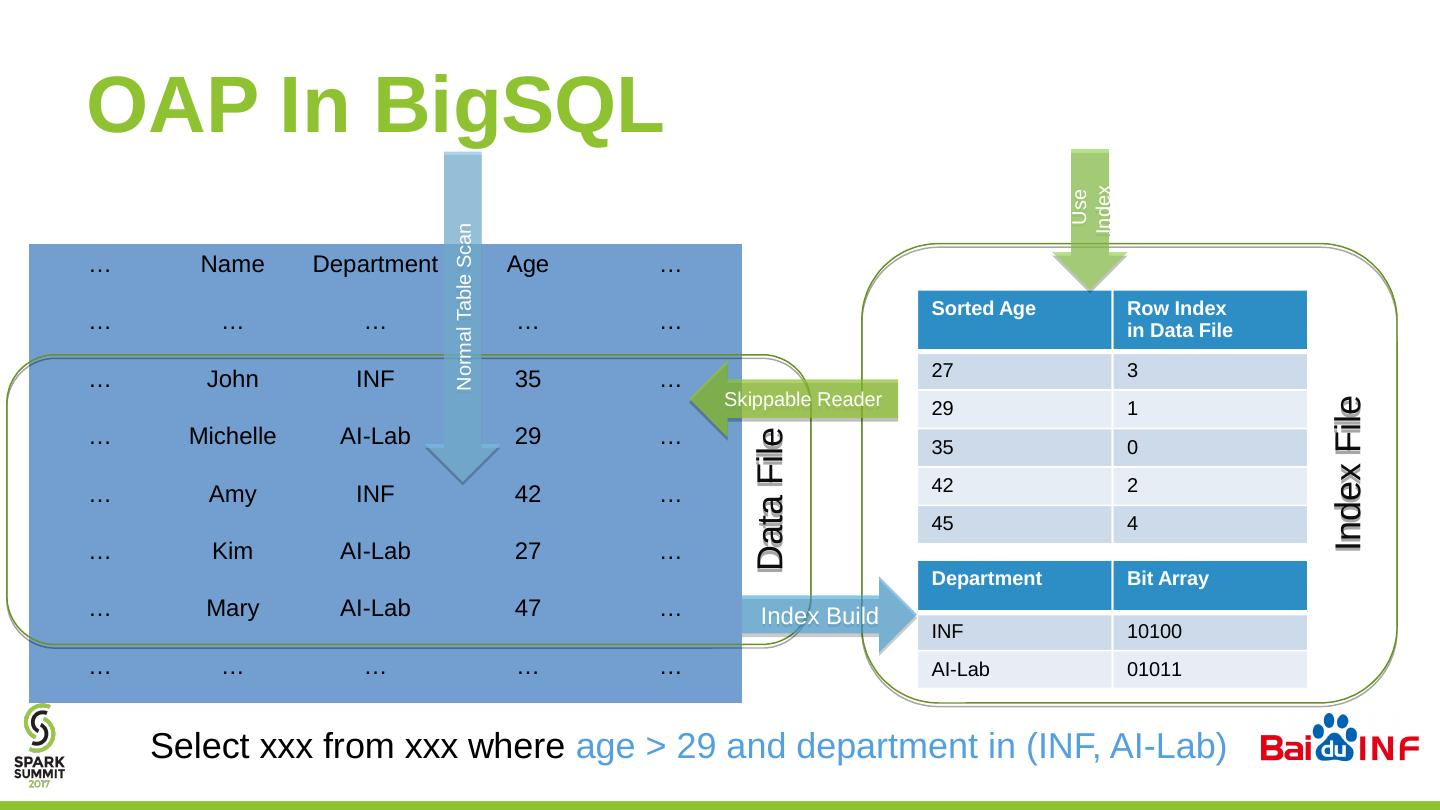
26 .OAP In BigSQL … Name Department Age … … … … … … … John INF 35 … … Michelle AI-Lab 29 … … Amy INF 42 … … Kim AI-Lab 27 … … Mary AI-Lab 47 … … … … … … Data File Index File Sorted Age Row Index in Data File 27 3 29 1 35 0 42 2 45 4 Department Bit Array INF 10100 AI-Lab 01011 Index Build Normal Table Scan Use Index Skippable Reader Select xxx from xxx where age > 29 and department in (INF, AI-Lab)
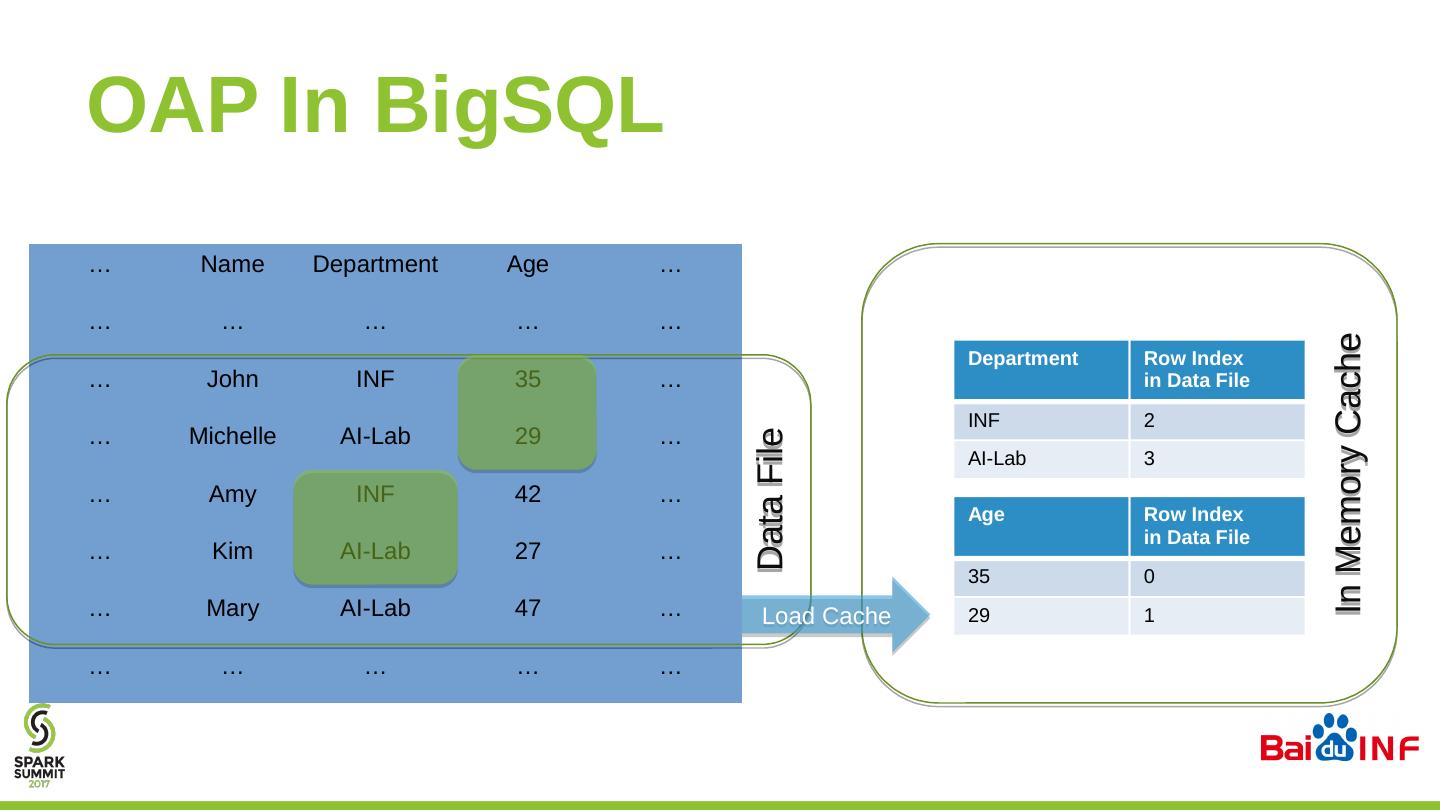
27 .OAP In BigSQL … Name Department Age … … … … … … … John INF 35 … … Michelle AI-Lab 29 … … Amy INF 42 … … Kim AI-Lab 27 … … Mary AI-Lab 47 … … … … … … Data File In Memory Cache Load Cache Department Row Index in Data File INF 2 AI-Lab 3 Age Row Index in Data File 35 0 29 1
28 .BBS’s Contribute to Spark Spark-4502 Spark SQL reads unneccesary nested fields from Parquet Spark-18700 getCached in HiveMetastoreCatalog not thread safe cause driver OOM Spark-20408 Get glob path in parallel to reduce resolve relation time …
29 .BBS’s Contribute to Spark Spark-4502 Spark SQL reads unneccesary nested fields from Parquet Spark-18700 getCached in HiveMetastoreCatalog not thread safe cause driver OOM Spark-20408 Get glob path in parallel to reduce resolve relation time …
相关推荐

加关注
3秒后跳转登录页面
去登陆

