













- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 视频嵌入链接 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
DPDK Acceleration With GPU
我们展示了GPU作为数据包处理加速器的适用性,特别是对于计算密集型任务。 将讨论以下技术和挑战:
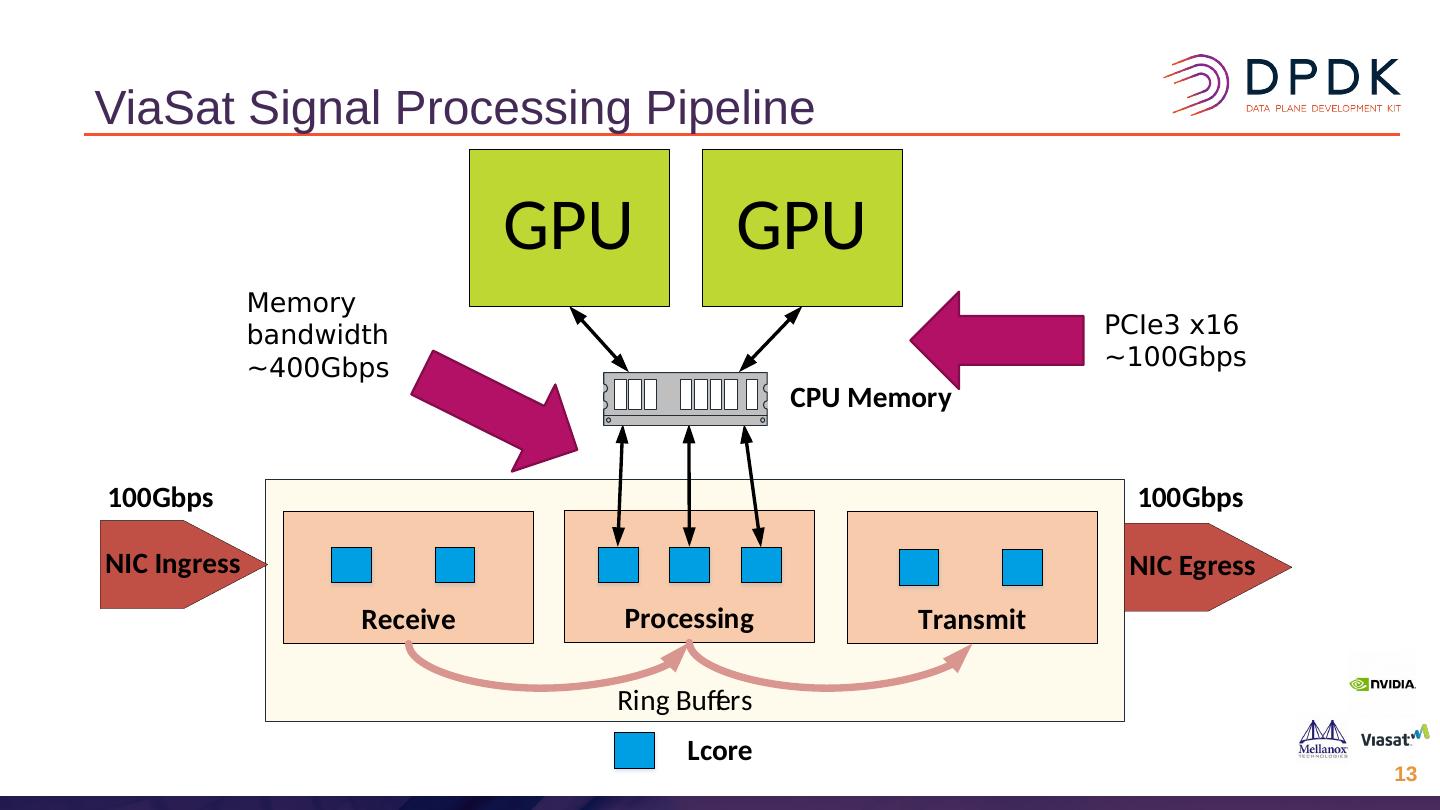
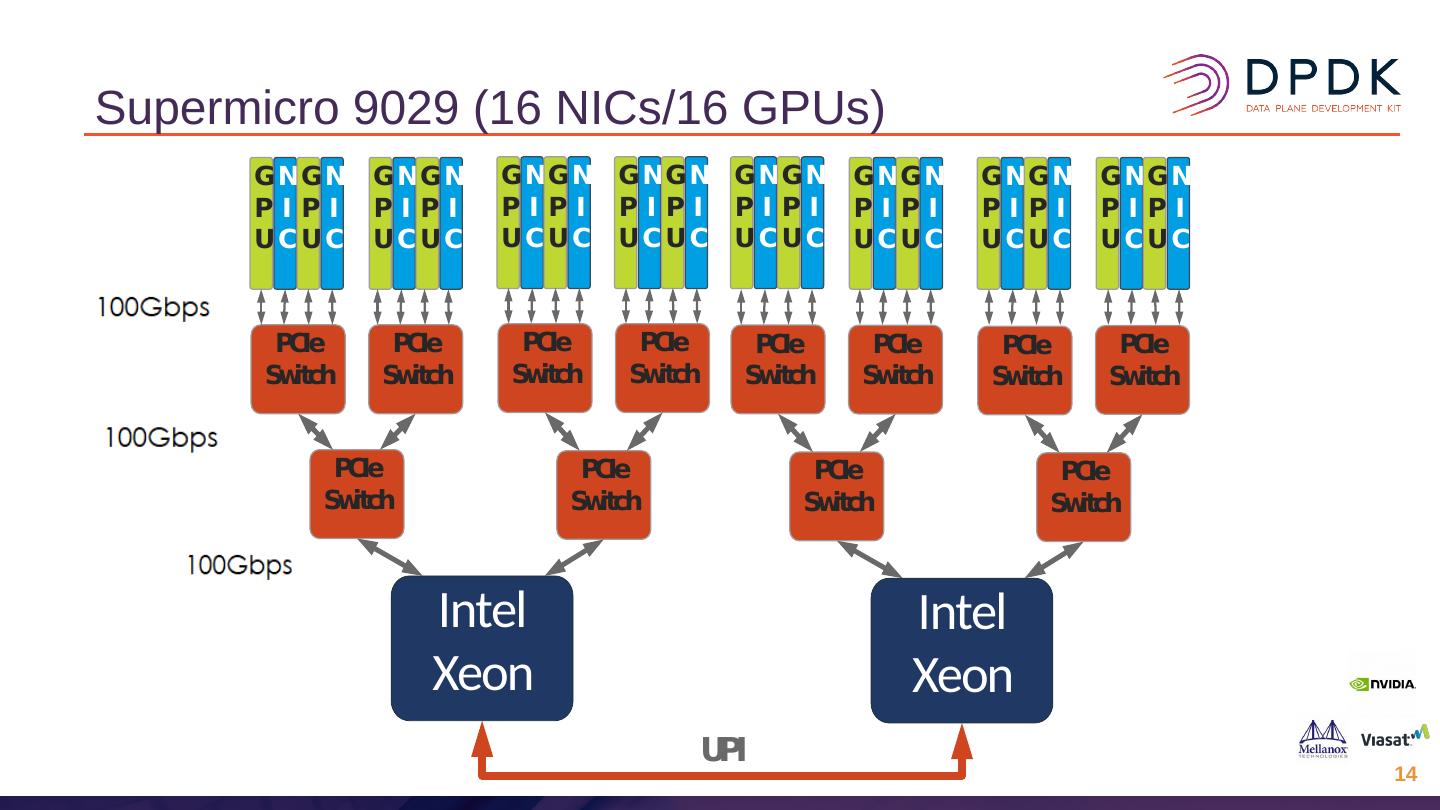
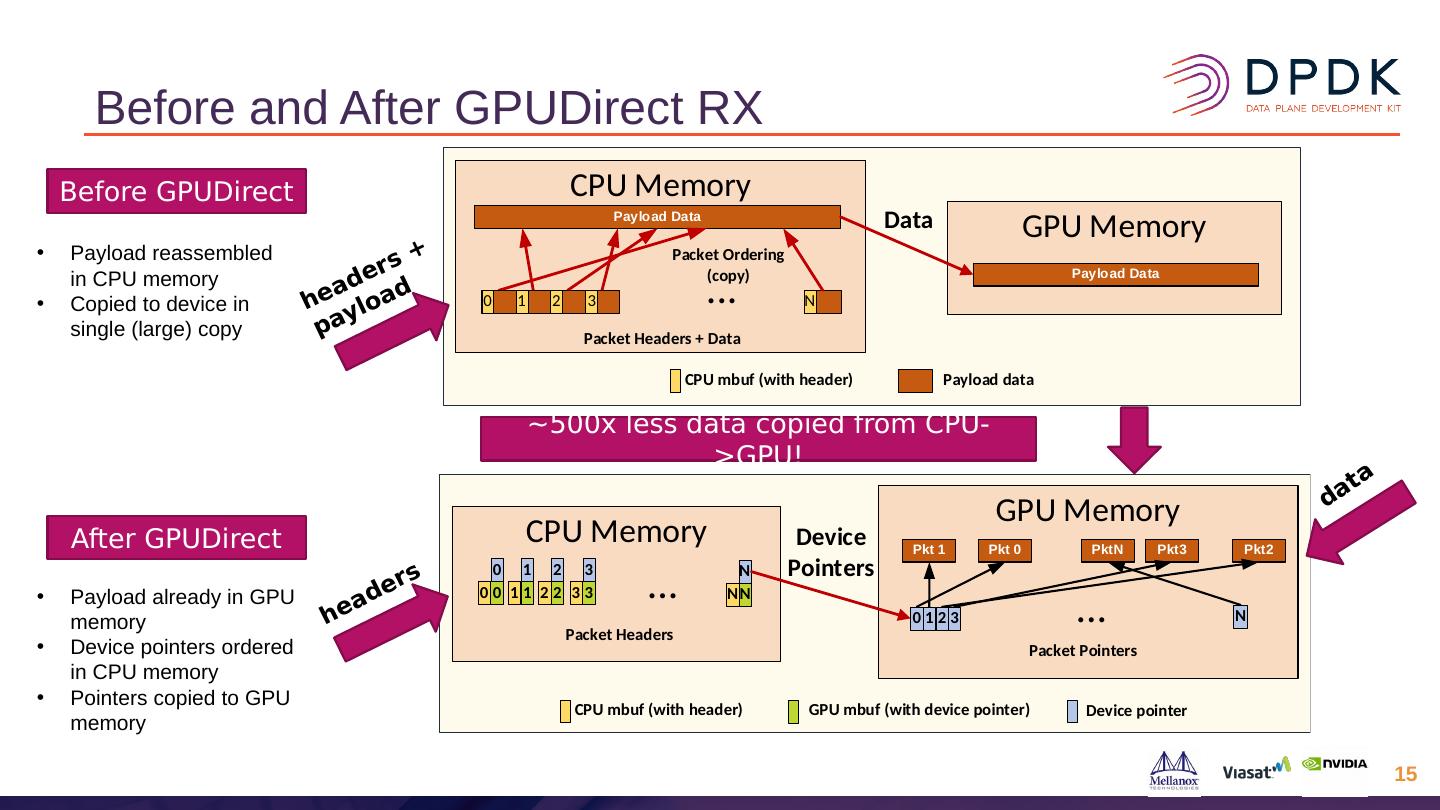
–允许GPU Direct RDMA Rx和Tx,其中数据包在NIC和GPU之间直接交换。
–对于zero-copy,mbuf数据需要放置在两个设备均可使用的内存中,因此使用mbuf的外部缓冲区功能,而外部缓冲区位于GPU片上内存或GPU可寻址CPU内存中。
–可以选择将Rx队列配置为在CPU和GPU内存之间拆分传入的数据包,从而允许CPU处理数据包头,并且GPU直接访问数据包有效负载。
各种应用程序都在演示这些技术,包括:
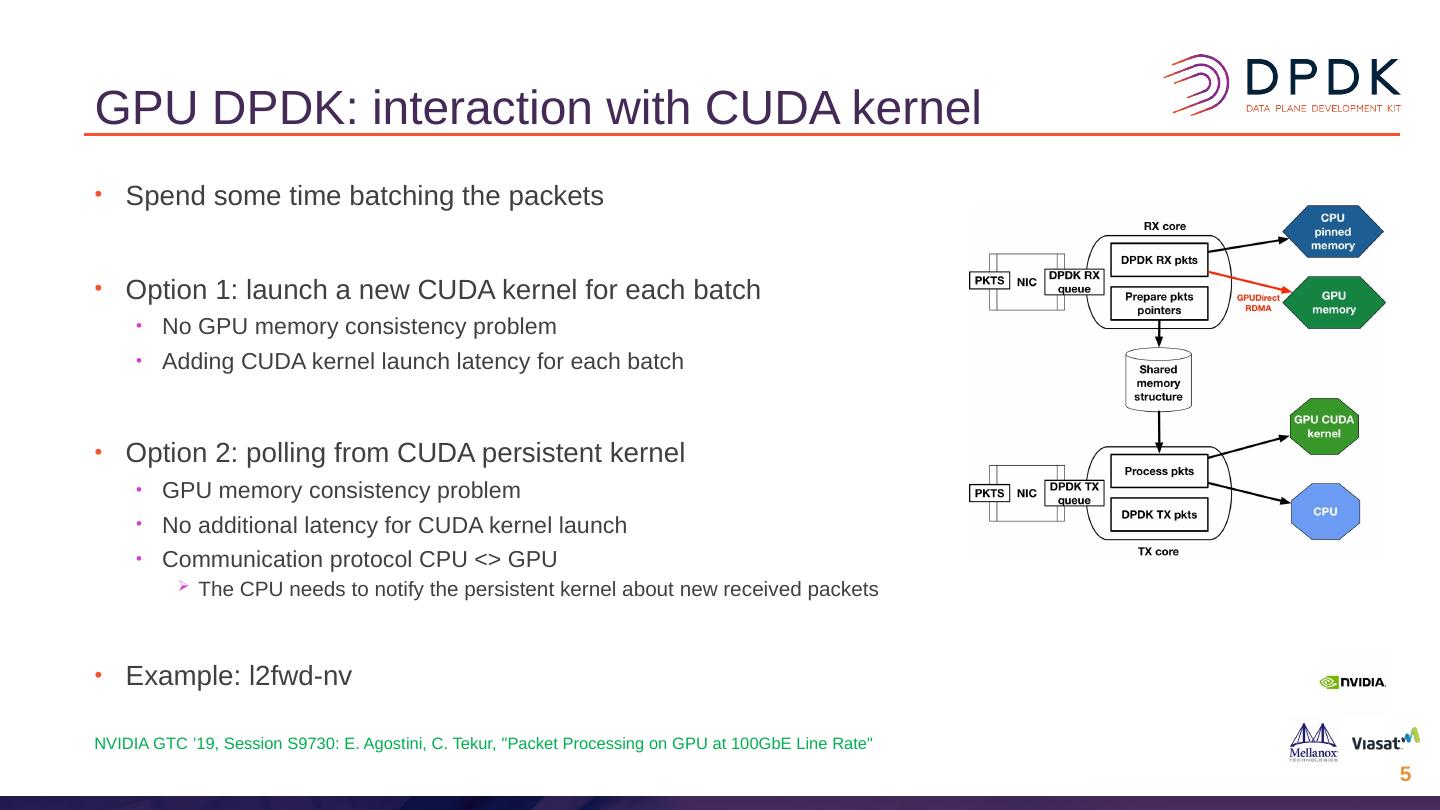
–使用CUDA内核的L2转发应用程序。
–使用CPU / GPU标头/数据拆分的应用程序匹配流在GPU上处理。
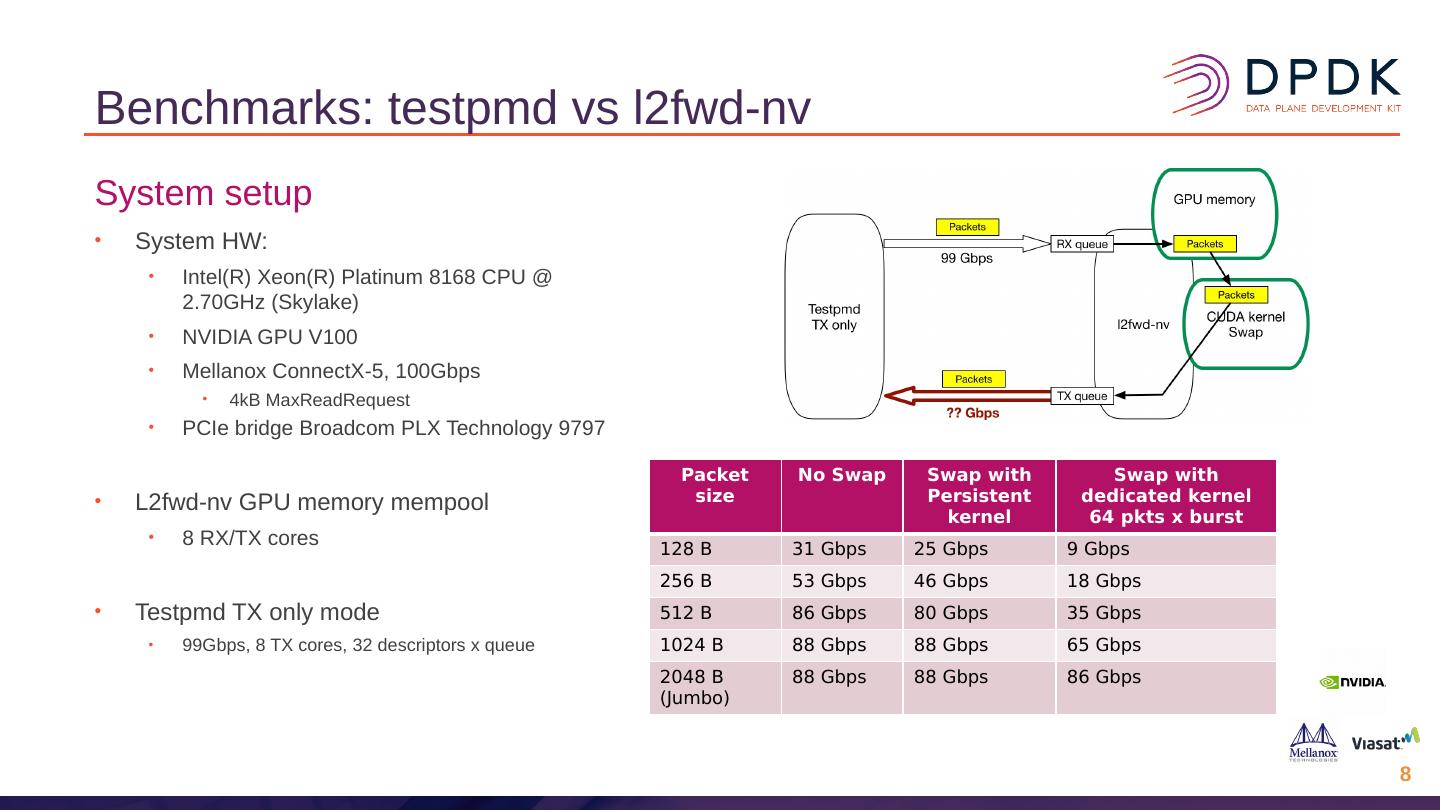
–使用GPU内存的testpmd的修改版本
3秒后跳转登录页面
去登陆

