




















































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
16-Why isn't RDMA everywhere?
We will look at the path from the invention of RDMA into modern data centers like Azure, and focus on some of the many "hiccups" that occurred before deployment was finally feasible. Microsoft was kind enough to write a series of papers on their experiences, so we'll focus on the story they describe.
展开查看详情
1 .CS5412 / Lecture 16 The Challenges of Using RDMA Ken Birman Spring, 2019 http://www.cs.cornell.edu/courses/cs5412/2018sp 1
2 .Context for this lecture We saw how the need for performance has pushed some very fancy machine learning components into the edge, like Facebook TAO As we connect the cloud to sensors, we’ll get an even greater demand for real-time updates (hence replication), consistency and coordination at the edge. FFFS and Derecho are examples of a response to that need. But Derecho’s speed comes from RDMA. Does the edge have RDMA? http://www.cs.cornell.edu/courses/cs5412/2018sp 2
3 .Life on the edge The edge demands disruptive changes. … early adopters tend to experience a lot of pain. Nothing works… the hardware may lack programming tools… is undocumented… may even have hardware bugs . And “cutting through the stack” may have unexpected consequences elsewhere. None of the rosy predictions are as easy to leverage as you might expect. Hint: Start by duplicating some reported result for the same setup! http://www.cs.cornell.edu/courses/cs5412/2018sp 3 “Cut through the stack for speed!”
4 .Let’s think about Derecho Provides ultra-fast data replication with Paxos guarantees Key steps: Identified a hardware capability that has been overlooked for data replication tools: RDMA transfers Studied that hardware closely. It has many capabilities, but used two: Reliable “two-sided” RDMA transfers (Q posts a receive, then P’s send can start) Reliable “one-sided” RDMA (Q permits P to write into a memory area) http://www.cs.cornell.edu/courses/cs5412/2018sp 4
5 .Is Derecho as great as Ken claims? All of our experiments were totally honest. But… there are complications. To understand them, we need to understand the hardware better http://www.cs.cornell.edu/courses/cs5412/2018sp 5
6 .Today’s Lecture topic What made it hard to build Derecho? Where are the surprises? In what ways did Paxos and virtual synchrony “evolve” The underlying concepts were unchanged But the implementations are very different than in older systems! http://www.cs.cornell.edu/courses/cs5412/2018sp 6
7 .Derecho Starts with a basic fast multicast What would be the best way to do an RDMA multicast with reliability similar to N side-by-side TCP connections? We could just have N side-by-side reliable unicast RDMA connections We could use one-sided RDMA and have N “round-robin ring buffers”. The sender could do a lock-free buffer “put” and the receiver, a lock- free “get”. We could do a tree to disseminate the data using RDMA unicast http://www.cs.cornell.edu/courses/cs5412/2018sp 7
8 .It turns out that there isn’t one answer! The problem with doing N side-by-side RDMA connections is that with reliable RDMA Unicast (or with TCP!) the sender and receiver need to agree on the size of the object being sent. The receiver will need to have a suitable memory buffer posted for the incoming DMA transfer. So this means the sender must tell the receiver the buffer size first, then wait for the receiver to post the buffer: an RPC interaction. Plus, the solution turns out to scale poorly if you do it this way. http://www.cs.cornell.edu/courses/cs5412/2018sp 8
9 .With small messages, use N ring buffers One-sided RDMA writes into ring buffers work well for smaller messages (maybe up to 1KB). Inside Derecho this is called SMC. There needs to be one ring per destination, each with enough memory for R messages. The memory is allocated and posted in advance Lock-free updates to the counters of messages in the buffer and free slots are easy to implement. The round-robin buffer soaks up any mismatch in speed between the sender and receiver. http://www.cs.cornell.edu/courses/cs5412/2018sp 9
10 .With large messages, though… Here we need something fancier. We don’t want to do N RDMA unicast writes for a big object: inefficient. So we need a tree. http://www.cs.cornell.edu/courses/cs5412/2018sp 10
11 .RDMC: Multicast oN RDMA Source Dest Dest Dest Dest Multicast Binomial Tree Binomial Pipeline Final Step 11
12 .Key idea… and Limitation… RDMA is good at large, steady streams. RDMC is optimized for that case, and works best as a pipeline. SMC is tuned for streams of small messages. But protocols like Paxos also need some amount of back-and forth SMC and RDMC aren’t matched to “2 phase” kinds of interactions. http://www.cs.cornell.edu/courses/cs5412/2018sp 12
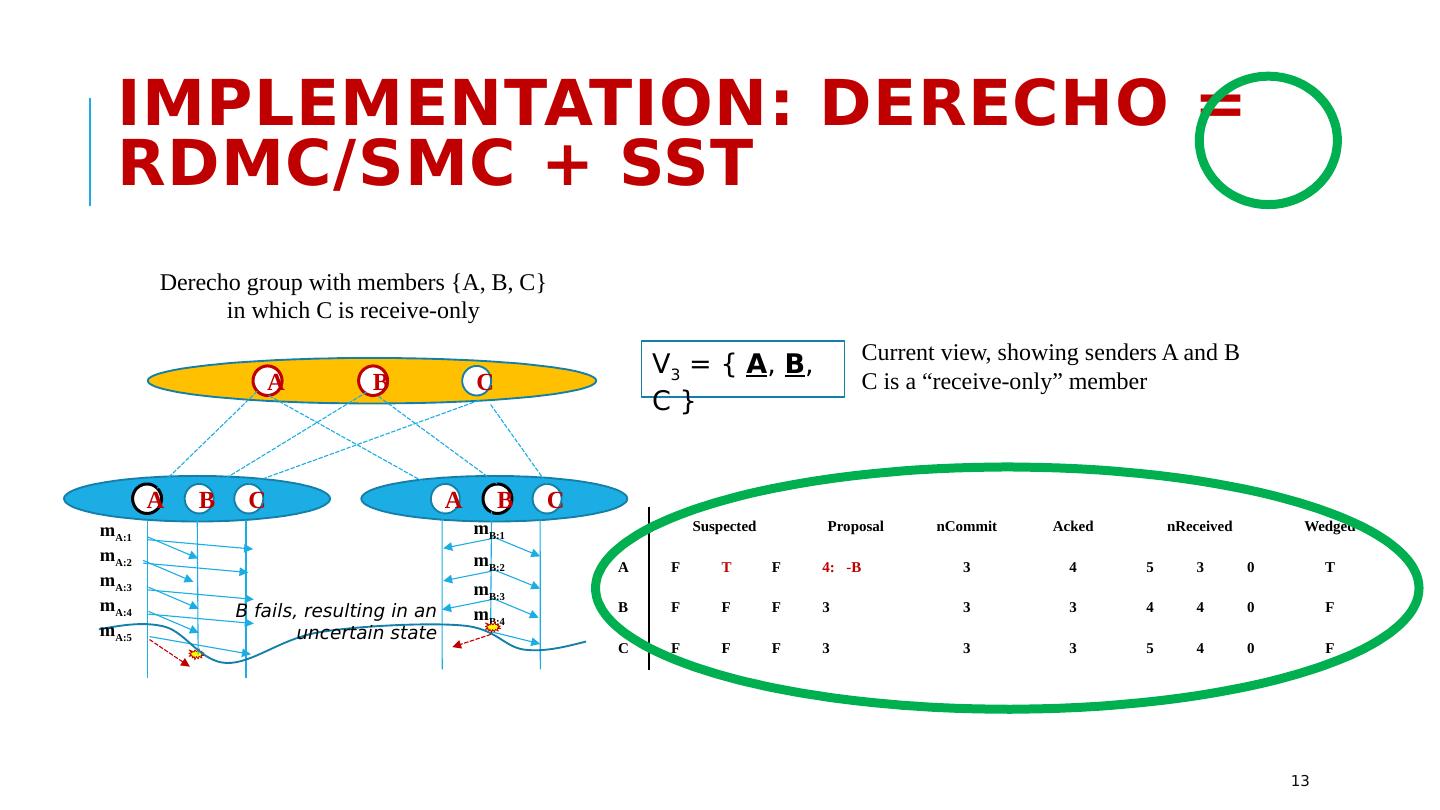
13 .Suspected Proposal nCommit Acked nReceived Wedged A F T F 4: -B 3 4 5 3 0 T B F F F 3 3 3 4 4 0 F C F F F 3 3 3 5 4 0 F A C B B A C B A C m A:1 m A:2 m A:3 m A:4 m A:5 m B:1 m B:2 m B:3 m B:4 Derecho group with members {A, B, C} in which C is receive-only V 3 = { A , B , C } Current view, showing senders A and B C is a “receive-only” member B fails, resulting in an uncertain state Implementation: Derecho = RDMC/SMC + SST 13
14 .Derecho’s Shared State Table Derecho uses the SST for back-and-forth sharing of data: Instead of messages, SST lets programs talk through shared memory Each row is a “struct” in C++. Derecho developers define the format. Each machine can write to its own row, “push” to other machines Each has a read-only replica of the rows of others http://www.cs.cornell.edu/courses/cs5412/2018sp 14 P’s row 227 16 True Q’s row 188 19 False R’s row 191 18 False
15 .SST Push operation P updates its row, then SST issues a series of one-sided RDMA writes. These copy the changes to other machines … the transfers occur “silently” and Q’s row is updated to match P’s new version. The actual transfer is via DMA, low address in memory first, reliable, fifo , etc. Q rereads the data to see that it changed http://www.cs.cornell.edu/courses/cs5412/2018sp 15 P’s row 227 16 True Q’s row 188 19 False R’s row 191 18 False P’s row 227 23 False Q’s row 188 19 False R’s row 191 18 False RDMA writes Machines Q and R have read-only copies of P’s row
16 .SST Programming Because the SST is lock-free, values can change “under your feet”. But this is also good, in the sense that threads don’t disrupt one-another. It motivates us to program the SST in an unusual way http://www.cs.cornell.edu/courses/cs5412/2018sp 16
17 .SST Programming SST programming: via a kind of “predicates” if ( some condition holds) { … trigger this code … } We made a choice: we create rows of “monotonic” values that change in one direction, like a counter (it only gets bigger) We define “aggregating” operators that compute things like min . If the underlying values only get larger, min only gets larger too http://www.cs.cornell.edu/courses/cs5412/2018sp 17
18 .Stable and Monotonic predicates A deduction (a predicate) is stable if, once it becomes true, it remains true Suppose counter is a column in the SST, and is monotonic min( counter) = v is not stable in the SST: if the counters grow, min grows … but min (counter) v , in contrast, remains true once it becomes true http://www.cs.cornell.edu/courses/cs5412/2018sp 18
19 .Stable and Monotonic predicates A deduction (a predicate) is stable if, once it becomes true, it remains true Some stable predicates are also monotonic, in this sense: If Pred (min(c)) holds, then v < c, Pred (v) holds. Monotonic predicates allow receive-side batching of actions, like delivery of messages 0..min(c) if (… messages 0..min(c) are stable) { deliver(0, min(c)) } http://www.cs.cornell.edu/courses/cs5412/2018sp 19
20 .This is not an obvious way to program! Notice how the hardware forced us to program differently: The hardware is very fast, but only if used in a certain way To use it in that way, at that speed, we couldn’t do “normal” things, like sending messages and waiting for acknowledgements, or votes So we had to invent this new shared table abstraction, and had to rewrite the standard Paxos protocols in a totally new way http://www.cs.cornell.edu/courses/cs5412/2018sp 20
21 .… Not unusual with new hardware! New hardware often results in ideas like Derecho Specialty hardware can be extremely fast, but often requires that you use it in some very unfamiliar way. If we just run the old style of algorithm on the new hardware, but in the old way, we wouldn’t benefit http://www.cs.cornell.edu/courses/cs5412/2018sp 21
22 .2-phase commit “via” SST P writes something, like “I propose to change the view”. Q and R echo the data, as a way to say “ok” When all have the identical data in their rows, we consider that the operation has committed. In fact the SST can carry many kinds of information: values that change (ideally, in one direction: monotonic ), messages, even multicasts. http://www.cs.cornell.edu/courses/cs5412/2018sp 22
23 .A long sequence of 2PC actions For a single 2PC, SST wouldn’t be much faster But Derecho has to do 2PC on millions of Paxos atomic multicasts/second At those speeds, the SST monotonicity pays off Senders ask for votes on all messages up to n . N is a counter. Receivers vote ok up through k , and this allows monotonic reasoning. http://www.cs.cornell.edu/courses/cs5412/2018sp 23
24 .Initial conclusion We managed to make Derecho very fast, but to do so: Had to come up with a way to move bytes at crazy speed. Then had to come up with a “control plane” that can run separate from the data plane. Turned out it needed a lot of 2PC kinds of mechanism. To get those to be fast we invented this whole way to program the SST. A lot of work, but the payoff was extreme speed. http://www.cs.cornell.edu/courses/cs5412/2018sp 24
25 .Zero Copy requirement Moreover, to get the full possible speed of Derecho, you need to write code that won’t involve any copying (even using memcpy , or even automated copying done in the programming language runtime). Copying is slower than RDMA! This is quite tricky: Your application needs to use RDMA “everywhere” for large objects where performance will be critical. http://www.cs.cornell.edu/courses/cs5412/2018sp 25
26 .Other accelerators: Similar stories GPU units require entire special programming languages (CUDA) and a really peculiar programming style (move object into GPU, load program, press “run”, move results back into CPU memory) FPGA accelerators have to be coded in a gate-level language, like the ones used for VLSI chip design. Network interfaces can be programmed, but the run a very strange kind of code focused on moving messages (P4, but it isn’t yet a standard). http://www.cs.cornell.edu/courses/cs5412/2018sp 26
27 .Now we know all about Derecho. Should everyone switch to it in all their edge systems? http://www.cs.cornell.edu/courses/cs5412/2018sp 27
28 .There is a small issue… Not so fast… RDMA doesn’t really work in datacenters! A long history… RDMA was invented in connection with a novel networking approach called Infiniband . It competes with optical ethernet In ethernet, senders send packets, and packets are dropped if congestion (overload) occurs. This causes loss if the packets are part of UDP messages, but TCP retransmits missing chunks. It “backs off” (slows down) if loss occurs Additive increase, multiplicative backoff http://www.cs.cornell.edu/courses/cs5412/2018sp 28
29 .Infiniband isn’t Ethernet In Infiniband , no device sends unless it has permission to send from the receiving device first So when a router transmits a packet to another router, for example, the receiver has granted “credit” for the sender to send B bytes. This is true for every step along the route! Hop by hop, no data is moved without assurance of a place to put it The optical network layer is so reliable that Infiniband is lossless! More precisely: Loss is incredibly rare and usually caused by some form of crash http://www.cs.cornell.edu/courses/cs5412/2018sp 29
3秒后跳转登录页面
去登陆

