



























































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
黄东旭-开源项目 TiDB 研发体系简介
开源项目 TiDB 研发体系简介
展开查看详情
1 .TiDB 研发体系简介 Dongxu
2 .
3 .
4 .关于我 ● 黄东旭 ● Infrastructure engineer / Hacker / CTO of PingCAP ● MSRA / Netease Youdao / WandouLabs ● Working on open source projects: TiDB/TiKV https://github.com/pingcap/tidb https://github.com/pingcap/tikv
5 .Part I - TiDB 的前世今生
6 .为什么我们需要一个新数据库? ● 从 0 开始 RDBMS NoSQL NewSQL、HTAP ● 现有的数据库的缺陷 ○ 传统单机关系型数据 库 ○ NoSQL 1970s 2010 2015 Present ● NewSQL is coming ○ HTAP MySQL Redis Google PostgreSQL HBase Spanner Oracle Cassandra Google F1 DB2... MongoDB TiDB
7 .以前的数据库世界
8 .以前的数据库世界 ● 分库 ○ 根据业务垂直拆分 ■ 比如用户库,订单库,产品库都独立开来 ● 分表 ○ 大表拆分多张表 ■ 比如按照省份, 时间,或者 hash 来 sharding ● 可以人肉自己在代码里面写,也可以用中间件 看起来很完美,可是。。。
9 .
10 .项目 组织 编程语言 MaxScale MariaDB C Atlas Qihoo 360 C ProxySQL Percona? C++ kingshard 金山 Go Sharding-jdbc 当当网 Java Cobar/MyCat 阿里/未知 Java JProxy(未开源) 京东 Java Vitess Youtube Go MySQL proxy MySQL 官方 C
11 .分库分表的 100 条军规 假设用户在登陆的那个表里有 手机/邮箱/用户 3条记录, 怎么选择 Sharding key? 非唯一索引查询怎么路由? 广播给所有节点。。。 怎么做 Join ? 没好办法,不要做 分布式事务?不能很好支持 … 终于在 2015 年的春天,三个某互 联网公司的分布式存 储工程师实在受不了没日没夜拆 库拆表熬夜扩容 的日子...
12 .TiDB 解决的问题 ● 弹性伸缩 ○ 再也不用担心 单库/表容量问题 ○ 任意时间都可以做扩容,凌晨做扩容成为历史 ○ 按需扩容,告别 2x 的扩容方式 ● 跨行 ACID 事务的支持 ○ 告别 sharding key 的历史 ● 强一致的复制 ○ 不再受到一致性的折磨 ● 多机/数据中心高可用 ○ 一切为了睡个安稳觉 ● 开源!
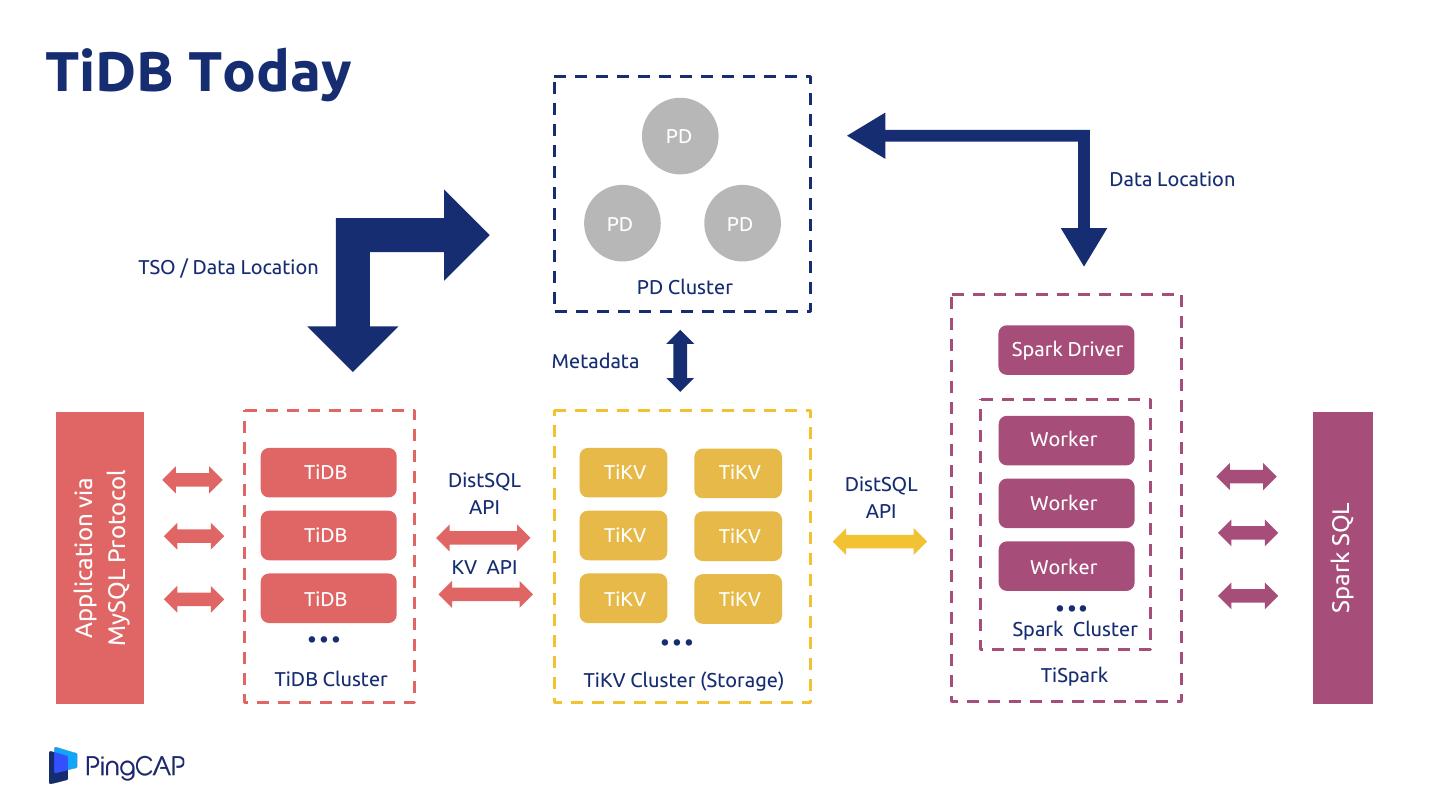
13 .TiDB Today PD Data Location PD PD TSO / Data Location PD Cluster Spark Driver Metadata Worker TiDB DistSQL TiKV TiKV MySQL Protocol DistSQL Application via API API Worker Spark SQL TiDB TiKV TiKV KV API Worker TiDB TiKV TiKV ... ... ... Spark Cluster TiDB Cluster TiKV Cluster (Storage) TiSpark
14 . TiDB Today PD TiDB on Github (14600+ stars / 200+ 2017.6 TiDB 入选 CNCF Landscape 2018.7 TiDB 入选 Big Data Landscape contributors) https://github.com/pingcap/tidb https://github.com/cncf/landscape http://mattturck.com/wp-content/uploads/ 2018/07/Matt_Turck_FirstMark_Big_Data _Landscape_2018_Final.png
15 .TiDB Today 2018年8月28日,TiKV 被全球 知名云原生计算基金会 (CNCF) 接纳为托管项目,这是 CNCF 基金会全球范围内接纳的第一 个 KV Database 项目。 https://www.cncf.io/blog/2018/0 8/28/cncf-to-host-tikv-in-the-sa ndbox/
16 .TiDB Today ● Boston Apache Spark Meetup 2018 @ Cambridge Introducing the Kubernetes Operator for TiDB ● Big Data Application Meetup 2018 @ GSV Labs ● Area NewSQL Database Meetup 2018 @ Redwood 5 Questions for Evaluating a Distributed Database ● RustConf 2018 @ Portland ● Boss Workshop 2018 @ Rio PingCAP eyes US market with database targeting operational and ● Rust Belt Rust 2018 @ Wyndham Garden analytical workloads ● IEEE Infra Conference 2018 @ San Francisco Chaos Tools and Techniques for ● FOSDEM 2018 @ Brussels Testing the TiDB Distributed NewSQL Database ● Percona Live 2018 @ Santa Clara ● Spark + AI Summit 2018 @ San Francisco TiDB: Performance-tuning a distributed NewSQL database ● Open Source Summit Japan 2018 @ Tokyo ● VLDB 2018 @ Rio The Hybrid Database Capturing Perishable Insights at Yiguo ● Strange Loop 2018 @ St.Louis Tick or Tock? Keeping Time and Order ● Kubecon + CloudNativeCon 2018 @ Seattle in Distributed Databases ● Percona Live 2017 @ Santa Clara TiDB Brings Distributed Scalability to ● ... SQL
17 .Part II - TiDB 的软件工程哲学
18 .TiDB 的软件工程哲学 ● 分层!分层!分层! ● 设计良好的数据结构,而不是逻辑 ● Done is better than perfect ● 不放弃捷径,站在巨人的肩膀上往往事半功倍 ● Talk is cheap, show me the tests ● Always believe shit is about to happen ● 相信机器和代码,不要相信人 ● There’s metric, there’s a way PingCAP.com
19 .分层和抽象 ● Rule 1: 将存储引擎的行为抽象成很薄 Transaction 的几个接口,使得可以无缝的接入各 种嵌入式 storage engine MVCC ● Rule 2: 软件本身微服务化,拆成多个 RaftKV 独立服务 ● Rule 3: 每一层只和和它相邻的上下两 Local KV Storage (RocksDB) 层通信,不允许跨层次调用 ● 举个例子 PingCAP.com
20 .分层和抽象
21 .设计好的数据结构而不是复杂的代码 ● 好的数据结构能够减少: ○ Review 的复杂度,对于 Code reviewer 来说,复杂逻辑是很难 Review 的,但是数据结构的好坏却是一目了然 ○ 写出复杂逻辑的机会 ● 举个例子
22 .Always believe shit is about to happen
23 .理想中.... ● 网络是健壮的 ● 网络延迟是稳定的 ● 带宽无穷大 ● 机器重来不 Crash ● 系统管理员永远在线,总是能找到开发者 ● 服务进程永远不会被杀 ● 跨 IDC 通信,链路永远不断
24 .现实...
25 .解决之道 ● 给接口层留出错误注入的可能 ● 7x24x365 分布式测试框架 ○ Jepsen ○ Namazu ○ *Schrodinger* ● 单元/回归测试 ● 写模拟器
26 .
27 .
28 .关于人肉测试 ● 软件质量来自于良好的架构设计和稳健的工程实现 ● Stop talking and go build things. ● 我们从不雇佣专职测试人员 ○ 测试是所有工程团队的工作 ○ 测试是文化并非流程 ○ 吃自己的狗粮! ● 雇佣最优秀的工程师并持续给他们新的挑战
29 .重度依赖自动化测试 ● 开发者在开发过程中实时得到单元测试结果 ● 在合并代码前保证所有单元测试通过 ● 实时计算测试代码覆盖率, 不允许新提交导致整体的覆盖率下降 ● Dashboards everywhere, 正向反馈 ● Automate everything ○ 薛定谔
3秒后跳转登录页面
去登陆

