












































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
22-The Apache big-data technologies
Some files have immense key-value tables or other forms of structured data, but way too much to load into memory (like log files from entire data centers). How would you process those on Hadoop? It turns out that they have some answers.
First we will look at Hive and PIG, which are more tools for file access, but a bit fancier than HBase. Then we will switch topics a bit, and discuss Kafka. You might think that files and messaging are totally different ideas, but a long history of work on "message oriented middleware" has yielded some very popular systems that merge the two concepts: in these, you can generate objects that are not just stored, but also "notified" in the sense that applications can monitor files or "topics" for updates.
展开查看详情
1 .CS5412 / Lecture 22 Big Data Systems – Part 2 Ken Birman & Kishore Pusuku ri , Spring 2018 HTTP://WWW.CS.CORNELL.EDU/COURSES/CS5412/2018SP 1
2 .PUTTING IT ALL TOGETHER Reminder: Apache Hadoop Ecosystem HDFS (Distributed File System) HBase (Distributed NoSQL Database -- distributed map) YARN (Resource Manager) MapReduce (Data Processing Framework) HTTP://WWW.CS.CORNELL.EDU/COURSES/CS5412/2018SP 2
3 .Hadoop Ecosystem: Processing HTTP://WWW.CS.CORNELL.EDU/COURSES/CS5412/2018SP 3 Yet Another Resource Negotiator (YARN) Map Reduce Hive Spark Stream Other Applications Data Ingest Systems e.g., Apache Kafka, Flume, etc Hadoop NoSQL Database (HBase) Hadoop Distributed File System (HDFS) Pig Processing
4 .Apache Hive: SQL on MapReduce HTTP://WWW.CS.CORNELL.EDU/COURSES/CS5412/2018SP 4 Hive is an abstraction layer on top of Hadoop ( MapReduce /Spark) Use Cases: Data Preparation Extraction-Trans formation- Loading Jobs (Data Warehousing) Data Mining
5 .Apache Hive: SQL on MapReduce HTTP://WWW.CS.CORNELL.EDU/COURSES/CS5412/2018SP 5 Hive is an abstraction layer on top of Hadoop (MapReduce/Spark) Hive uses a SQL-like language called HiveQL Facilitates reading, writing, and managing large datasets residing in distributed storage using SQL-like queries Hive executes queries using MapReduce ( and also using Spark ) HiveQL queries → Hive → MapReduce Jobs
6 .Apache Hive HTTP://WWW.CS.CORNELL.EDU/COURSES/CS5412/2018SP 6 Structure is applied to data at time of read → No need to worry about formatting the data at the time when it is stored in the Hadoop cluster Data can be read using any of a variety of formats: Unstructured flat files with comma or space-separated text Semi-structured JSON files (a web standard for event-oriented data such as news feeds, stock quotes, weather warnings, etc ) Structured HBase tables Hive is not designed for online transaction processing. Hive should be used for “data warehousing” tasks, not arbitrary transactions.
7 .Apache Pig: Scripting on MapReduce HTTP://WWW.CS.CORNELL.EDU/COURSES/CS5412/2018SP 7 Pig is an abstraction layer on top of Hadoop (MapReduce/Spark) Use Cases: Data Preparation ETL Jobs (Data Warehousing) Data Mining
8 .Apache Pig: Scripting on MapReduce HTTP://WWW.CS.CORNELL.EDU/COURSES/CS5412/2018SP 8 Pig is an abstraction layer on top of Hadoop (MapReduce/Spark) Code is written in Pig Latin “script” language (a data flow language) Facilitates reading, writing, and managing large datasets residing in distributed storage Pig executes queries using MapReduce ( and also using Spark ) Pig Latin scripts → Pig → MapReduce Jobs
9 .Apache Hive & ApachePig HTTP://WWW.CS.CORNELL.EDU/COURSES/CS5412/2018SP 9 Instead of writing Java code to implement MapReduce, one can opt between Pig Latin and Hive SQL to construct MapReduce programs Much fewer lines of code compared to MapReduce, which reduces the overall development and testing time
10 .Apache Hive vs Apache Pig HTTP://WWW.CS.CORNELL.EDU/COURSES/CS5412/2018SP 10 Declarative SQL-like language ( HiveQL ) Operates on the server side of any cluster Better for structured Data Easy to use, specifically for generating reports Data Warehousing tasks Facebook Procedural data flow language (Pig Latin) Runs on Client side of any cluster Best for semi structured data Better for creating data pipelines allows developers to decide where to checkpoint data in the pipeline Incremental changes to large data sets and also better for streaming Yahoo
11 .Apache Hive vs ApachePig: example HTTP://WWW.CS.CORNELL.EDU/COURSES/CS5412/2018SP 11 insert into ValuableClicksPerDMA select dma , count(*) from geoinfo join ( select name, ipaddr from users join clicks on (users.name = clicks.user ) where value > 0; ) using ipaddr group by dma ; Users = load users as (name, age, ipaddr ); Clicks = load clicks as (user, url , value); ValuableClicks = filter Clicks by value > 0; UserClicks = join Users by name, ValuableClicks by user; Geoinfo = load geoinfo as ( ipaddr , dma ); UserGeo = join UserClicks by ipaddr , Geoinfo by ipaddr ; ByDMA = group UserGeo by dma ; ValuableClicksPerDMA = foreach ByDMA generate group, COUNT( UserGeo ); store ValuableClicksPerDMA into ValuableClicksPerDMA ; Job: Get data from sources users and clicks is to be joined and filtered, and then joined to data from a third source geoinfo and aggregated and finally stored into a table ValuableClicksPerDMA
12 .Comment: “Client side”?? When we say “runs on client side” we don’t mean “runs on the iPhone”. Here the client is any application using Hadoop. So the “client side” is just “inside the code that consumes the Pig output” In contrast, the “server side” lives “inside the Hive/HDFS layer” 12
13 .Hadoop Ecosystem: Data Ingestion HTTP://WWW.CS.CORNELL.EDU/COURSES/CS5412/2018SP 13 Yet Another Resource Negotiator (YARN) Map Reduce Hive Spark Stream Other Applications Data Ingest Systems e.g., Apache Kafka, Flume, etc Hadoop NoSQL Database (HBase) Hadoop Distributed File System (HDFS) Pig
14 .Data Ingestion Systems/Tools (1) HTTP://WWW.CS.CORNELL.EDU/COURSES/CS5412/2018SP 14 Hadoop typically ingests data from many sources and in many formats: Traditional data management systems, e.g. databases Logs and other machine generated data (event data) e.g., Apache Sqoop , Apache Fume, Apache Kafka (focus of this class) Storage Data Ingest Systems HBase HDFS
15 .Data Ingestion Systems/Tools (2) HTTP://WWW.CS.CORNELL.EDU/COURSES/CS5412/2018SP 15 Apache Sqoop High speed import to HDFS from Relational Database (and vice versa) Supports many data base systems, e.g. Mongo, MySQL, Teradata, Oracle Apache Flume Distributed service for ingesting streaming data Ideally suited for event data from multiple systems, for example, log files
16 .Concept: “Publish-Subscribe” tool The Apache ecosystem is pretty elaborate. It has many “tools”, and several are implemented as separate μ-services. The μ-services run in pools: we configure the cloud to automatically add instances if the load rises, reduce if it drops So how can individual instances belonging to a pool cooperate? 16
17 .Models for cooperation One can have explicit groups, the members know one-another, and the cooperation is scripted and deterministic as a function of a consistent view of the task pool and the membership (Zookeeper) But this is a more complex model than needed. In some cases, we prefer more of a loose coordination, with members that take tasks from some kind of list, perform them, announce completion. 17
18 .Concept: “Publish-Subscribe” tool This is a model in which we provide middleware to glue requestors to workers, with much looser coupling. The requests arrive as “published messages”, on “topics” The workers monitor topics (“subscribe”) and then an idle worker can announce that it has taken on some task, and later, finished it. 18
19 .Apache Kafka HTTP://WWW.CS.CORNELL.EDU/COURSES/CS5412/2018SP 19 Functions like a distributed publish-subscribe messaging system (or a distributed streaming platform) A high throughput, scalable messaging system Distributed, reliable publish-subscribe system Design as a message queue & Implementation as a distributed log service Originally developed by LinkedIn, now widely popular Features: Durability, Scalability, High Availability, High Throughput
20 .What is Apache Kafka used for? (1) HTTP://WWW.CS.CORNELL.EDU/COURSES/CS5412/2018SP 20 The original use case (@LinkedIn): To track user behavior on websites. Site activity (page views, searches, or other actions users might take) is published to central topics, with one topic per activity type. Effective for two broad classes of applications: Building real-time streaming data pipelines that reliably get data between systems or applications Building real-time streaming applications that transform or react to the streams of data
21 .What is Apache Kafka used for? (2) HTTP://WWW.CS.CORNELL.EDU/COURSES/CS5412/2018SP 21 Lets you publish and subscribe to streams of records, similar to a message queue or enterprise messaging system Lets you store streams of records in a fault-tolerant way Lets you process streams of records as they occur Lets you have both offline and online message consumption
22 .Apache Kafka: Fundamentals HTTP://WWW.CS.CORNELL.EDU/COURSES/CS5412/2018SP 22 Kafka is run as a cluster on one or more servers The Kafka cluster stores streams of records in categories called topics Each record (or message) consists of a key, a value, and a timestamp Point-to-Point: Messages persisted in a queue, a particular message is consumed by a maximum of one consumer only Publish-Subscribe : Messages are persisted in a topic, consumers can subscribe to one or more topics and consume all the messages in that topic
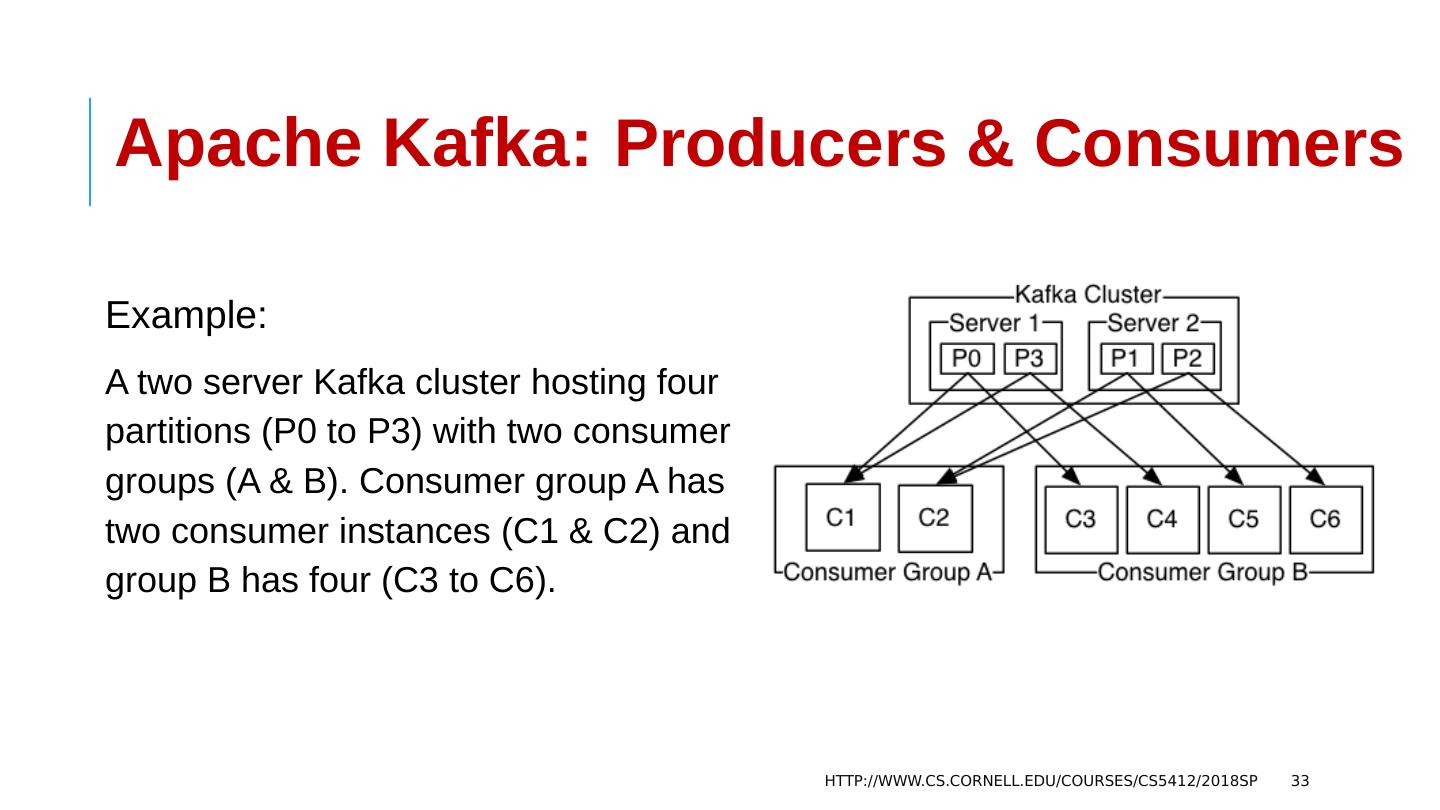
23 .Apache Kafka: Components HTTP://WWW.CS.CORNELL.EDU/COURSES/CS5412/2018SP 23 Logical Components : Topic: The named destination of partition Partition: One Topic can have multiple partitions and it is an unit of parallelism Record or Message: Key/Value pair (+ Timestamp) Physical Components : Producer: The role to send message to broker Consumer: The role to receive message from broker Broker: One node of Kafka cluster ZooKeeper : Coordinator of Kafka cluster and consumer groups
24 .Apache Kafka: Topics & Partitions (1) HTTP://WWW.CS.CORNELL.EDU/COURSES/CS5412/2018SP 24 A stream of messages belonging to a particular category is called a topic (or a feed name to which records are published) Data is stored in topics. Topics in Kafka are always multi-subscriber -- a topic can have zero, one, or many consumers that subscribe to the data written to it Topics are split into partitions. Topics may have many partitions, so it can handle an arbitrary amount of data
25 .Apache Kafka: Topics & Partitions (2) HTTP://WWW.CS.CORNELL.EDU/COURSES/CS5412/2018SP 25 For each topic, the Kafka cluster maintains a partitioned log that looks like this: Each partition is an ordered, immutable sequence of records that is continually appended to -- a structured commit log. Partition offset : The records in the partitions are each assigned a sequential id number called the offset that uniquely identifies each record within the partition.
26 .Apache Kafka: Topics & Partitions (3) HTTP://WWW.CS.CORNELL.EDU/COURSES/CS5412/2018SP 26 The only metadata retained on a per-consumer basis is the offset or position of that consumer in the log. This offset is controlled by the consumer -- normally a consumer will advance its offset linearly as it reads records (but it can also consume records in any order it likes)
27 .Apache Kafka: Topics & Partitions (4) HTTP://WWW.CS.CORNELL.EDU/COURSES/CS5412/2018SP 27 The partitions in the log serve several purposes: Allow the log to scale beyond a size that will fit on a single server. Handles an arbitrary amount of data -- a topic may have many partitions Acts as the unit of parallelism
28 .Apache Kafka: Distribution of Partitions(1) HTTP://WWW.CS.CORNELL.EDU/COURSES/CS5412/2018SP 28 The partitions are distributed over the servers in the Kafka cluster and each partition is replicated for fault tolerance Each partition has one server acts as the “leader” (broker) and zero or more servers act as “followers” (brokers). The leader handles all read and write requests for the partition The followers passively replicate the leader. If the leader fails, one of the followers will automatically become the new leader. Load Balancing: Each server acts as a leader for some of its partitions and a follower for others within the cluster.
29 .Apache Kafka: Distribution of Partitions (2) HTTP://WWW.CS.CORNELL.EDU/COURSES/CS5412/2018SP 29 Here, a topic is configured into three partitions. Partition 1 has two offset factors 0 and 1. Partition 2 has four offset factors 0, 1, 2, and 3. Partition 3 has one offset factor 0. The id of the replica is same as the id of the server that hosts it.
3秒后跳转登录页面
去登陆

