
















































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
The Apache big-data technologies
The Apache "ecosystem" uses Zookeeper for distributed system management and configuration control.
展开查看详情
1 .CS5412 / Lecture 20 Zookeeper Ken Birman Spring , 2019 http://www.cs.cornell.edu/courses/cs5412/2018sp 1
2 .Cloud systems have many “file Systems” Before we discuss Zookeeper, let’s think about file systems. Clouds have many! One is for bulk storage: some form of “global file system” or GFS. At Google, it is actually called GFS At Amazon, S3 plays this role Azure uses “Azure storage fabric” These often offer built-in block replication through a Linux feature, but the guarantees are somewhat weak. http://www.cs.cornell.edu/courses/cs5412/2018sp 2
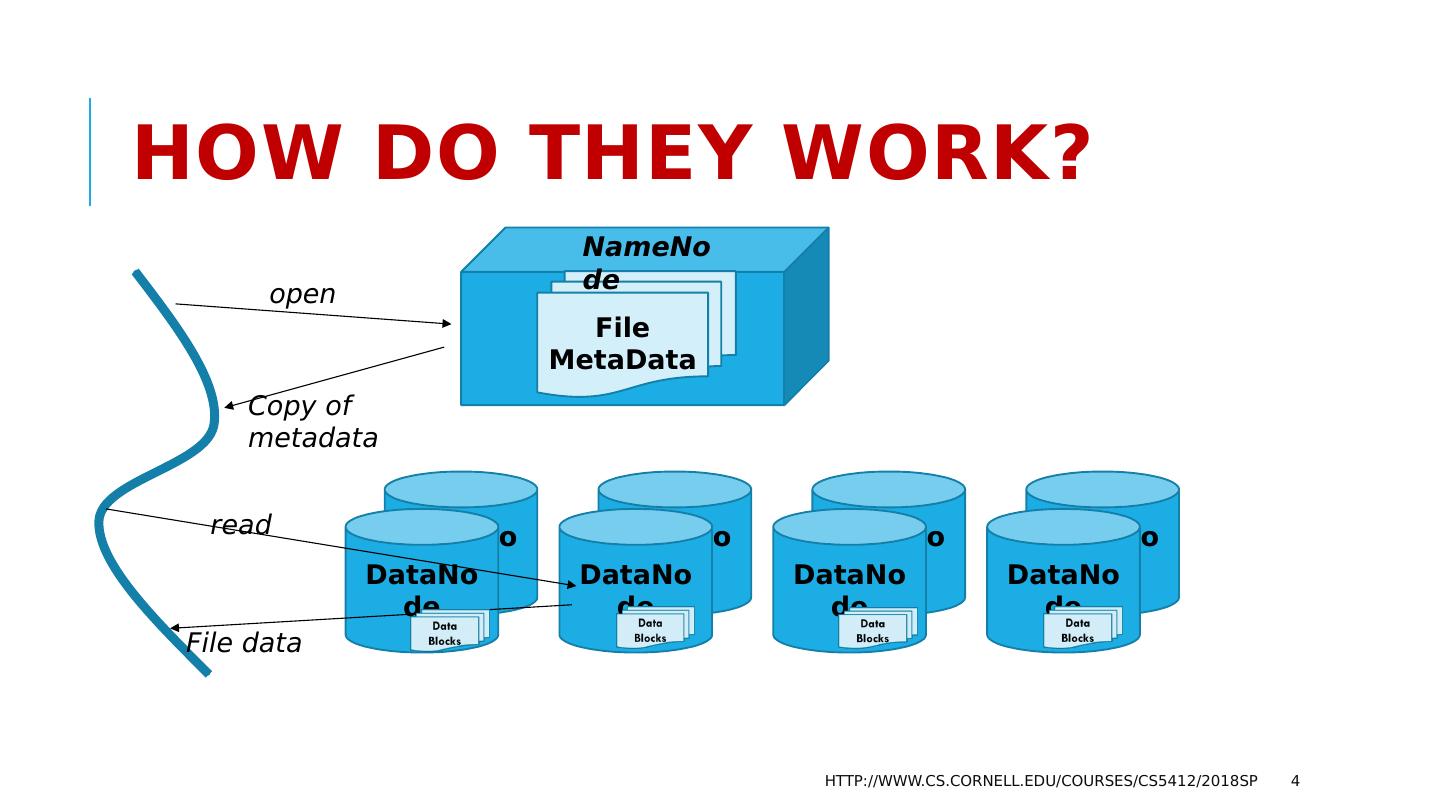
3 .How do they work? A “Name Node” service runs, fault-tolerantly, and tracks file meta-data (like a Linux inode ): Name, create/update time, size, seek pointer, etc. The name node tells you which data nodes hold your file. Very common to use a simple DHT scheme to fragment the NameNode into subsets, hopefully spreading the work around. DataNodes are hashed at the block level (large blocks) Some form of primary/backup scheme for fault-tolerance. Writes are automatically forwarded from the primary to the backup. http://www.cs.cornell.edu/courses/cs5412/2018sp 3
4 .How do they work? http://www.cs.cornell.edu/courses/cs5412/2018sp 4 File MetaData NameNode DataNode DataNode DataNode DataNode DataNode DataNode DataNode DataNode open Copy of metadata read File data
5 .Global File Systems: Summary Pros Scales well even for massive objects, Works well for large sequential reads/writes, etc. Provides High Performance (massive throughput) Simple but robust reliability model. Cons Namenode (Master) can become overloaded, especially if individual files become extremely popular. NameNode is a single-point of failure A slow NameNode can impact the whole data center Concurrent writes to the same file can interfere with one another http://www.cs.cornell.edu/courses/cs5412/2018sp 5
6 .edge/fog USE case Building a smart highway: Like an air traffic control system, but for cars We want to make sure there is always exactly one controller for each runway at the airport. We need to be reliable: if the primary controller crashes, the backup takes over within a few seconds. http://www.cs.cornell.edu/courses/cs5412/2018sp 6
7 .Could we use a global file system? Yes, for images and videos of the cars We could capture them on a cloud of tier-one data collectors Store the data into the global file system, run image analysis on the files. http://www.cs.cornell.edu/courses/cs5412/2018sp 7
8 .What about the consistency aspect? Consider the “configuration” of our application, which implements this control behavior. We need to track which machines are operational, what roles they have. We want a file that will hold a table of resources and roles. Every application in the system would track the contents of this file. So… this file is in the cloud file system! But which file system? http://www.cs.cornell.edu/courses/cs5412/2018sp 8
9 .Cloud File System Limitations Consider this simple approach: We maintain a log of computer status events: “crashed”, “recovered”… The log is append-only. When you sense something, do a write to the end of the log. Issue: If two events occur more or less at the same time, one can overwrite the other, hence one might be lost. http://www.cs.cornell.edu/courses/cs5412/2018sp 9 A has crashed D restarted A is primary, C is backup A, B and C are running
10 .Overwrites cause Inconsistency! We have discussed the concept of consistency many times, but haven’t really spent so much time on its evil nemesis, in consistency. If we are logging versions of flight plans, when one update overwrites a second one, some machines might have “seen” the lost one, and be in a state different from others. An example of a split-brain problem. If we are logging status of machines, some machines may think that C crashed, but others never saw this message (worst case: maybe C really is up, and the original log report was due to a transient timeout… but now half out system thinks C is up, and half thinks C is down: another split brain scenario) http://www.cs.cornell.edu/courses/cs5412/2018sp 10
11 .Avoiding “Split Brain” The name is from the title of an old science-fiction movie We must never have two active controllers simultaneously, or two different versions of the same flight plan record that use the same version id. You can turn this one type of mistake into many kinds of risky problems that we would never want to tolerate in an ATC system. So we must avoid such problems entirely! http://www.cs.cornell.edu/courses/cs5412/2018sp 11
12 .Root Issue (1) The quality of failure sensing is limited If we sense faults because of noticing timeout, we might make mistakes. Then if we reassign the role but the “faulty” machine is really still running and was just transiently inaccessible, we have two controllers! This problem is unavoidable in a distributed system, so we have to use agreement on membership, not “apparent timeout”. The log plays this role http://www.cs.cornell.edu/courses/cs5412/2018sp 12
13 .Root ISSUE (2) In many systems two or more programs can try to write to the same file at the same time, or to create the same file. In such situations the normal Linux file system will work correctly if the programs and the files are all on one machine . Writes to the local file system won’t interfere. But in distributed systems, using global file systems, we lack this property! http://www.cs.cornell.edu/courses/cs5412/2018sp 13
14 .How does a consistent log solve this? If you trust the log, just read log records from top to bottom you get an unambiguous way to track membership. Even if a logged record is “wrong”, e.g. “node 6 has crashed” but it hasn’t, we are forced to agree to use that record. Equivalent mechanisms exist in systems like Derecho (self-managed Paxos ). http://www.cs.cornell.edu/courses/cs5412/2018sp 14 In effect, membership is managed in a consistent way. But this works only if we can trust the log And that in turn depends on the file system!
15 .With S3 or GFS we cannot trust a log! These file systems don’t guarantee consistency! They are unsafe with concurrent writes. C oncurrent log appends could Overwrite one-another, so one is lost Be briefly perceived out of order, or some machine might glimpse a written record that will then be erased a moment later and overwritten Sometimes we can even have two conflicting versions that linger for extended periods. http://www.cs.cornell.edu/courses/cs5412/2018sp 15
16 .Exactly what goes wrong? “ Append-only log” behavior Machines A, B and C are running 2-a. Machine D is launched 2-b. Concurrently, B thinks A crashed. 2-b is overwritten by 2-a A turns out to be fine, after all. In our application using it A is selected to be the primary controller for runway 7. C is assigned as backup. C notices 2-b, and takes over. But A wasn’t really crashed – B was wrong! Log entry 2-b is gone. A keeps running. Now we have A and C both in the “control runway 7 role” – a split brain! http://www.cs.cornell.edu/courses/cs5412/2018sp 16
17 .Why can’t we just fix the bug? First, be aware that S3 and GFS and similar systems are perfectly fine for object storage by a single, non-concurrent writer. If nervous, take one more step and add a “self-certifying signature” SHA3 hash codes are common for this, very secure and robust. But there are many options, even simple parity codes can help. The reason that they don’t handle concurrent writes well is that the required protocol is slower than the current weak consistency model. http://www.cs.cornell.edu/courses/cs5412/2018sp 17
18 .Zookeeper: A Solution for this issue The need in many systems is for a place to store configuration, parameters, lists of which machines are running, which nodes are “primary” or “backup”, etc. We desire a file system interface, but “strong, fault-tolerant semantics” Zookeeper is widely used in this role. Stronger guarantees than GFS. Data lives in (small) files. Zookeeper is quite slow and not very scalable. But even so, it is useful for many purposes. Even locking, synchronization. http://www.cs.cornell.edu/courses/cs5412/2018sp 18
19 .Should I use Zookeeper for everything? Zookeeper isn’t for long-term storage, or for large objects. Put those in the GFS. Then share the URL, which is small. Use Zookeeper for small files used to do distributed coordination, synchronization or configuration data (small objects). Mostly, try to have Zookeeper handle “active” configuration, so it won’t need to persist data to a disk, at all. http://www.cs.cornell.edu/courses/cs5412/2018sp 19
20 .Zookeeper durability limitation Zookeeper is mostly used with no real “persistency” guarantee, meaning that if we shut it down completely, it normally loses any “state” There is a checkpointing mechanism, but not fully synchronized with file updates. Recent updates might not yet have been checkpointed. The developers view this as a tradeoff for high performance. Normally, it is configured to run once every 5s. Many applications simply leave Zookeeper running and if it shuts down, the whole application must shut down, then restart. http://www.cs.cornell.edu/courses/cs5412/2018sp 20
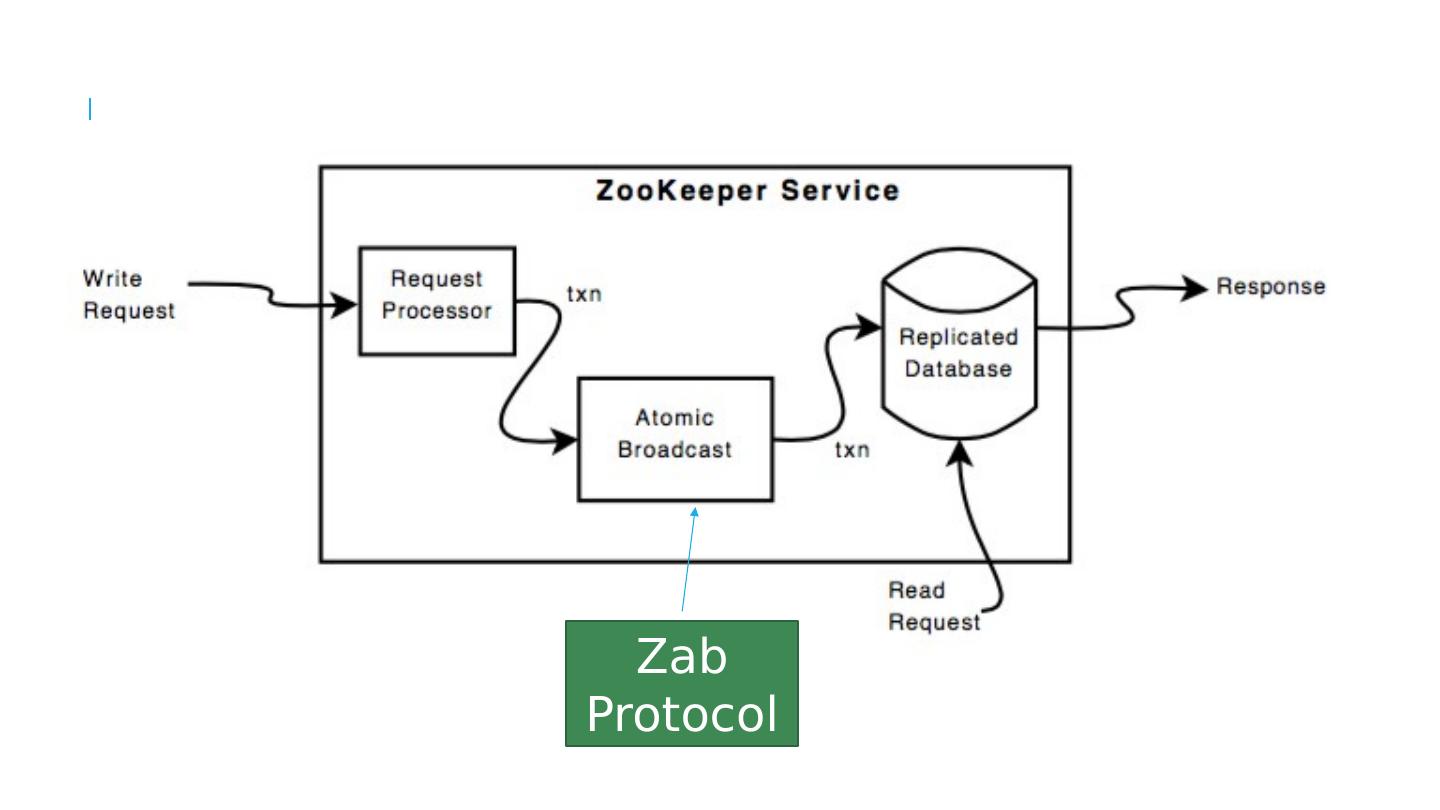
21 .How does Zookeeper Work? Zookeeper has a layered implementation. The health of all components is tracked, so that we know who is up and who has crashed. In Derecho, this is called membership status. The Zookeeper meta-data layer is a single program: consistent by design. The Zookeeper data replication layer uses an atomic multicast to ensure that all replicas are in the same state. For long-term robustness, they checkpoint periodically (every 5s) and restart from checkpoint. http://www.cs.cornell.edu/courses/cs5412/2018sp 21
22 .Details on Zookeeper (this is their slide set and repeats some parts of mine) Hunt, P., Konar , M., Junqueira , F.P. and Reed, B., 2010, June. ZooKeeper : Wait-free Coordination for Internet-scale Systems. In USENIX Annual Technical Conference (Vol. 8, p. 9). Several other papers can be found on http://scholar.google.com.
23 .Zookeeper goals An open-source platform created to behave like a simple file system Easy to use, fault-tolerant. A bit slow, but not to a point of being an issue. Unlike standard cloud computing file systems, provides strong guarantees. Employed in many cloud computing platforms as a quick and standard way to manage configuration data fault-tolerantly. http://www.cs.cornell.edu/courses/cs5412/2018sp 23
24 .How is Zookeeper used today? Naming service − Identifying the nodes in a cluster by name. It is similar to DNS, but for nodes Configuration management − Latest and up-to-date configuration information of the system for a joining node Cluster management − Joining / leaving of a node in a cluster and node status at real time Leader election − Electing a node as leader for coordination purpose Locking and synchronization service − Locking the data while modifying it. This mechanism helps you in automatic fail recovery while connecting other distributed applications like Apache HBase Highly reliable data registry − Availability of data even when one or a few nodes are down
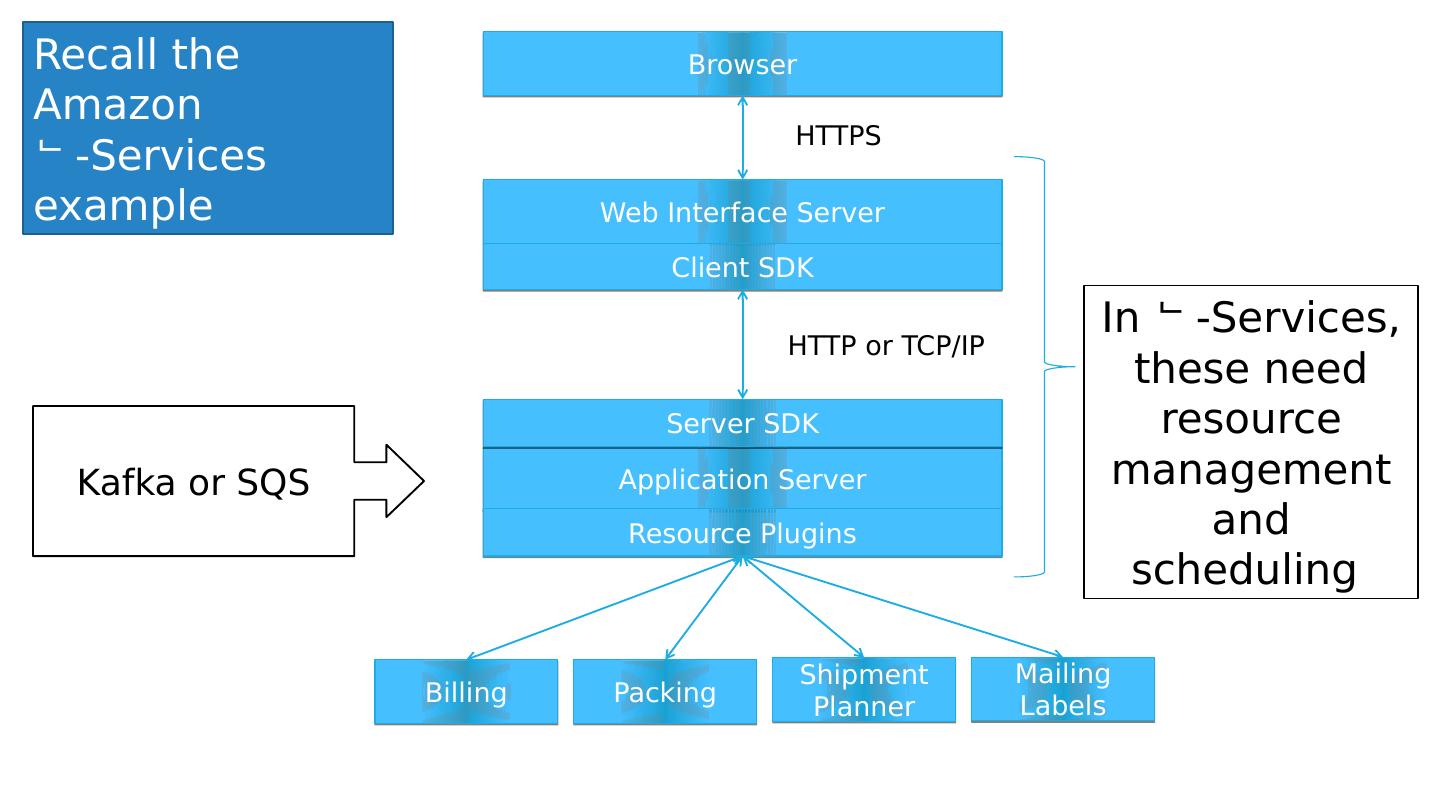
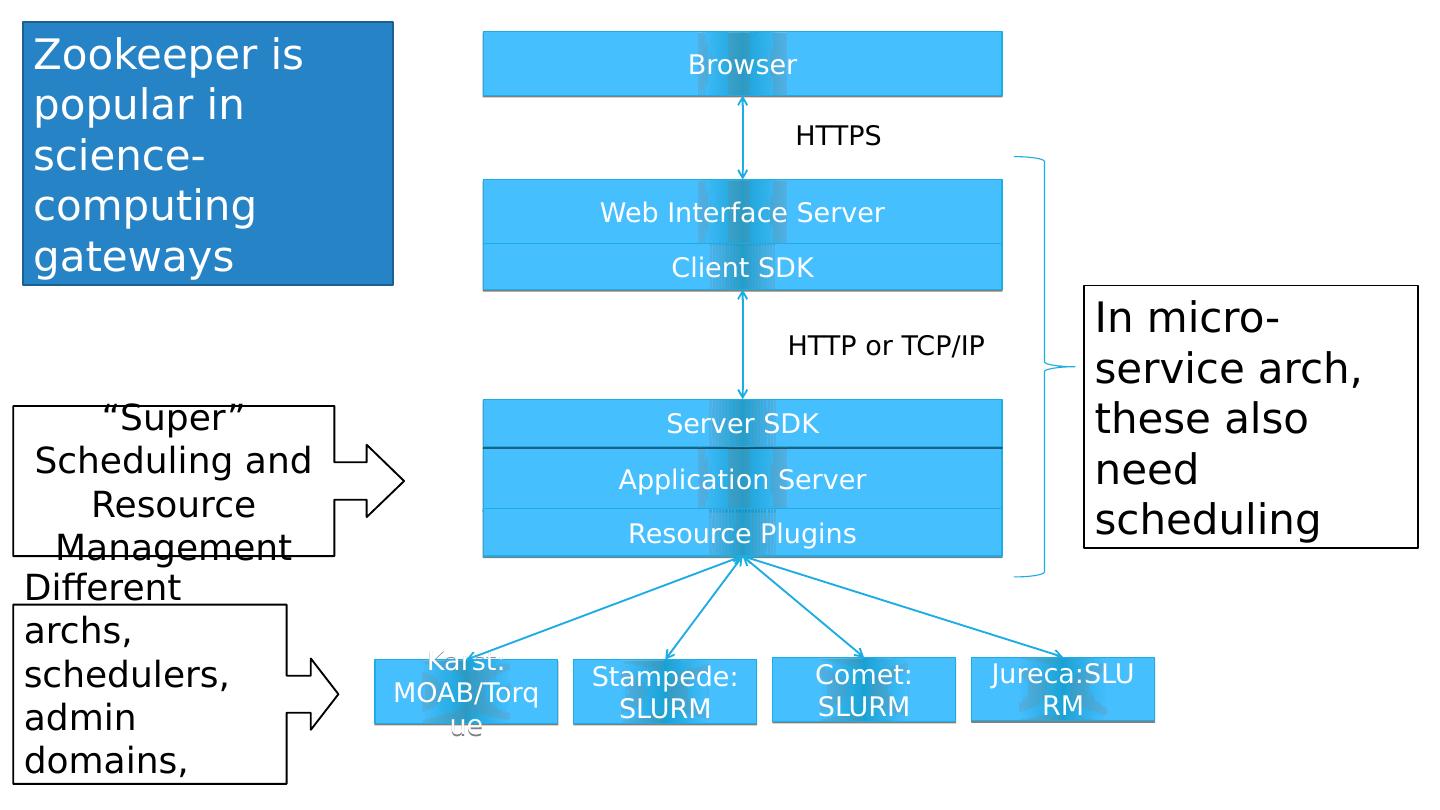
25 .Browser Web Interface Server Application Server Server SDK Client SDK Billing Resource Plugins Packing Shipment Planner Mailing Labels HTTPS HTTP or TCP/IP Recall the Amazon -Services example Kafka or SQS In -Services , these need resource management and scheduling
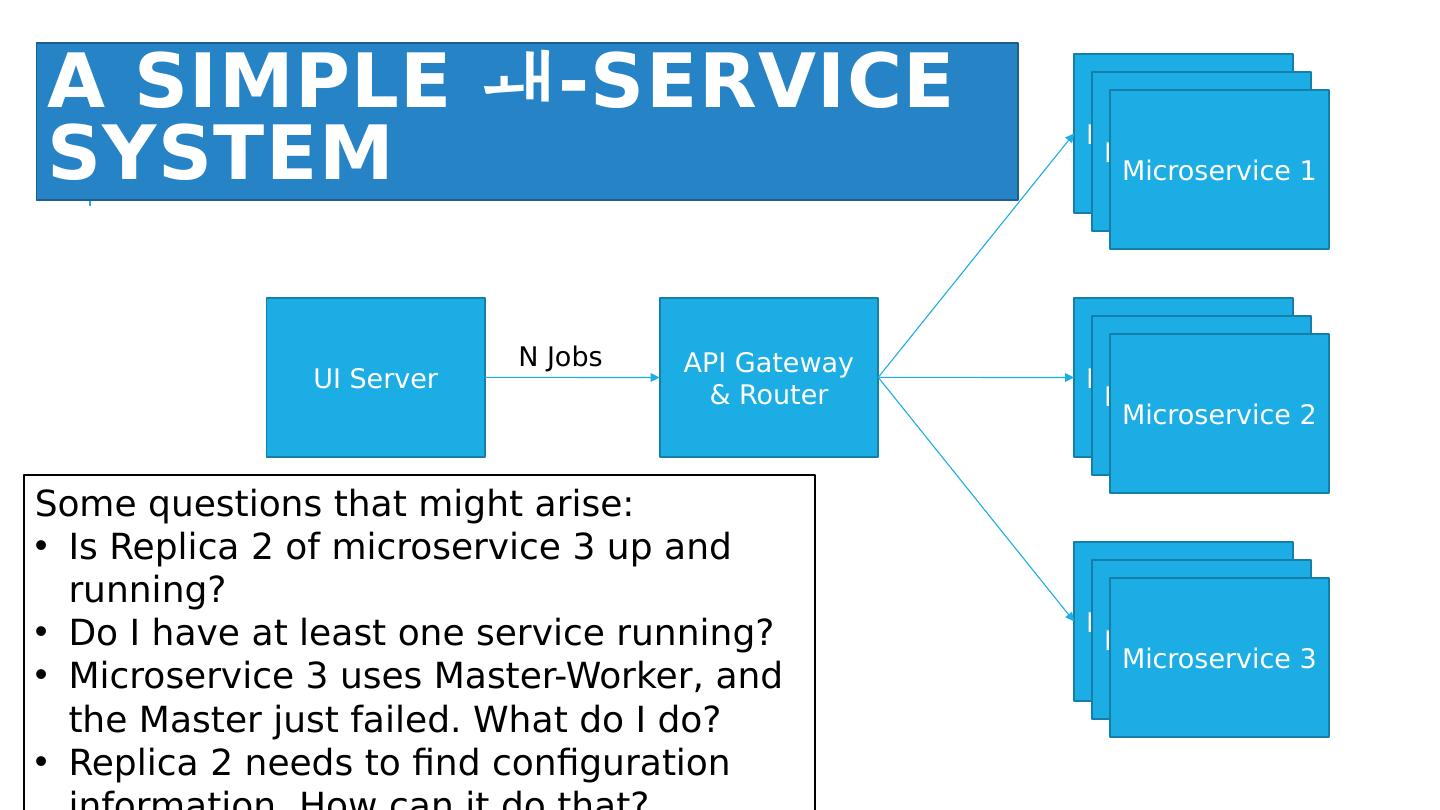
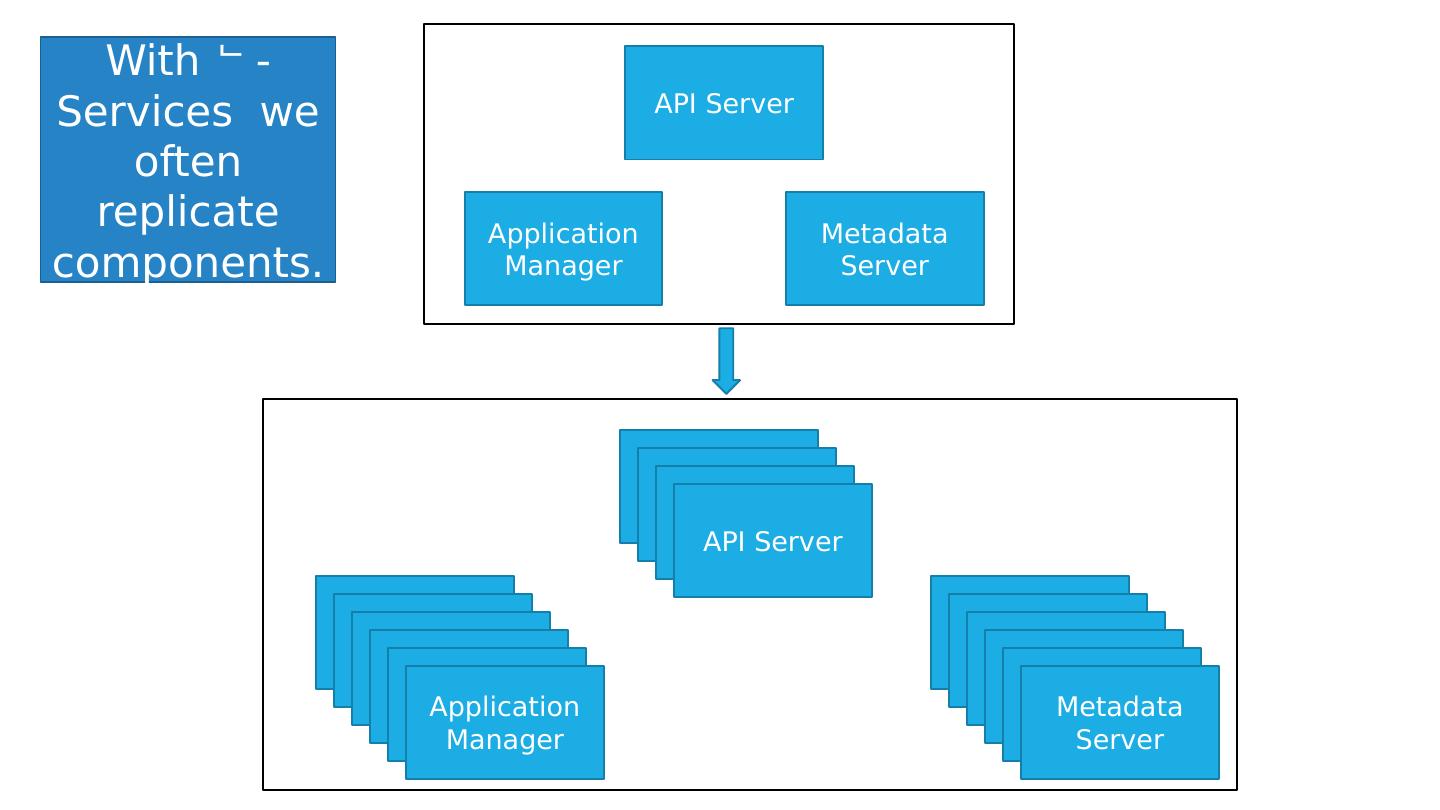
26 .A Simple - service System API Gateway & Router UI Server N Jobs Microservice 1 Microservice 2 Microservice 3 Microservice 1 Microservice 1 Microservice 2 Microservice 2 Microservice 3 Microservice 3 Some questions that might arise: Is Replica 2 of microservice 3 up and running? Do I have at least one service running? Microservice 3 uses Master-Worker, and the Master just failed. What do I do? Replica 2 needs to find configuration information. How can it do that?
27 .Apache Zookeeper and - services Zookeeper can manage information in your system IP addresses, version numbers, and other configuration information of your microservices . The health of the microservices . The state of a particular calculation. Group membership
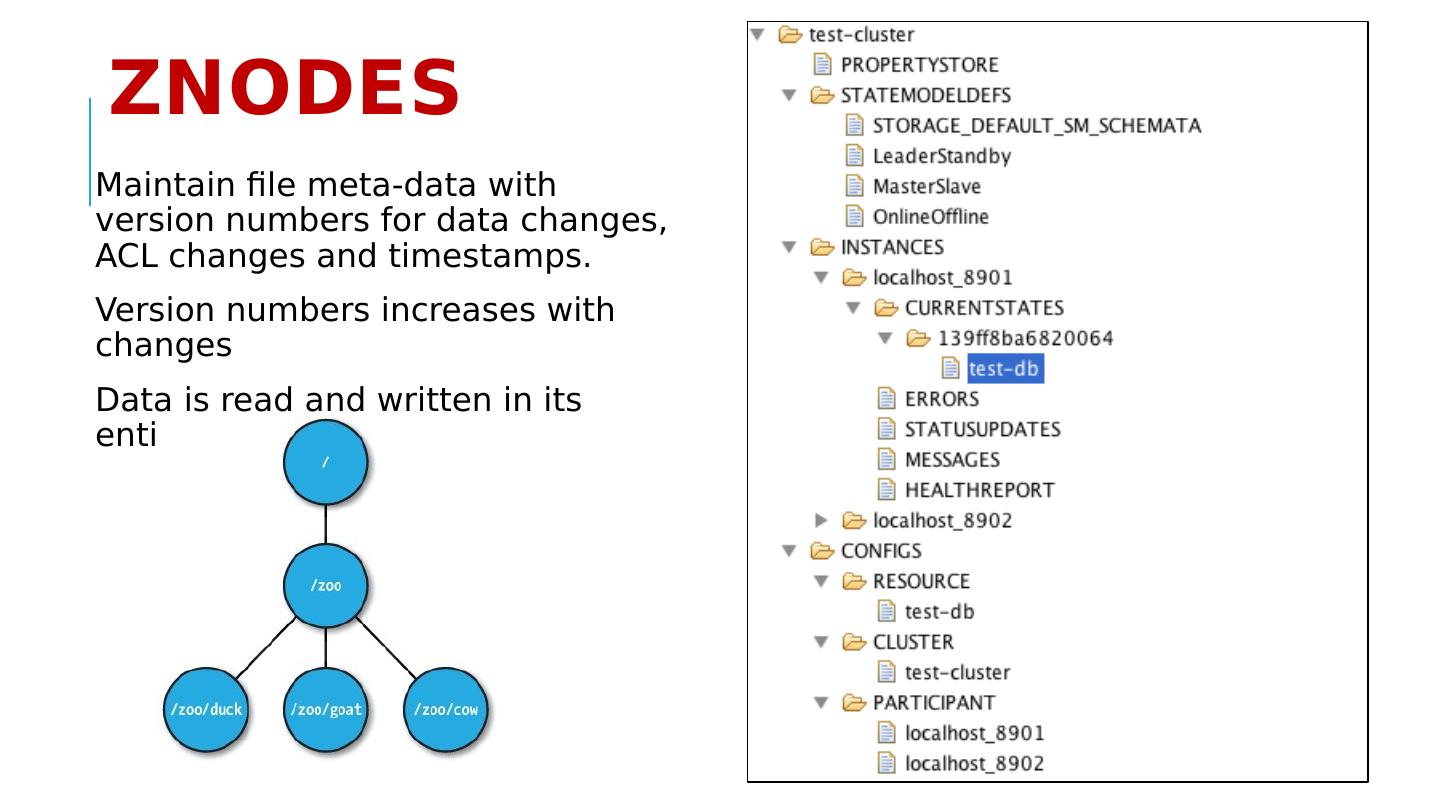
28 .Apache Zookeeper Is … A system for solving distributed coordination problems for multiple cooperating clients. A lot like a distributed file system... As long as the files are tiny. You could get notified when the file changes The full file pathname is meaningful to applications A way to solve - service management problems.
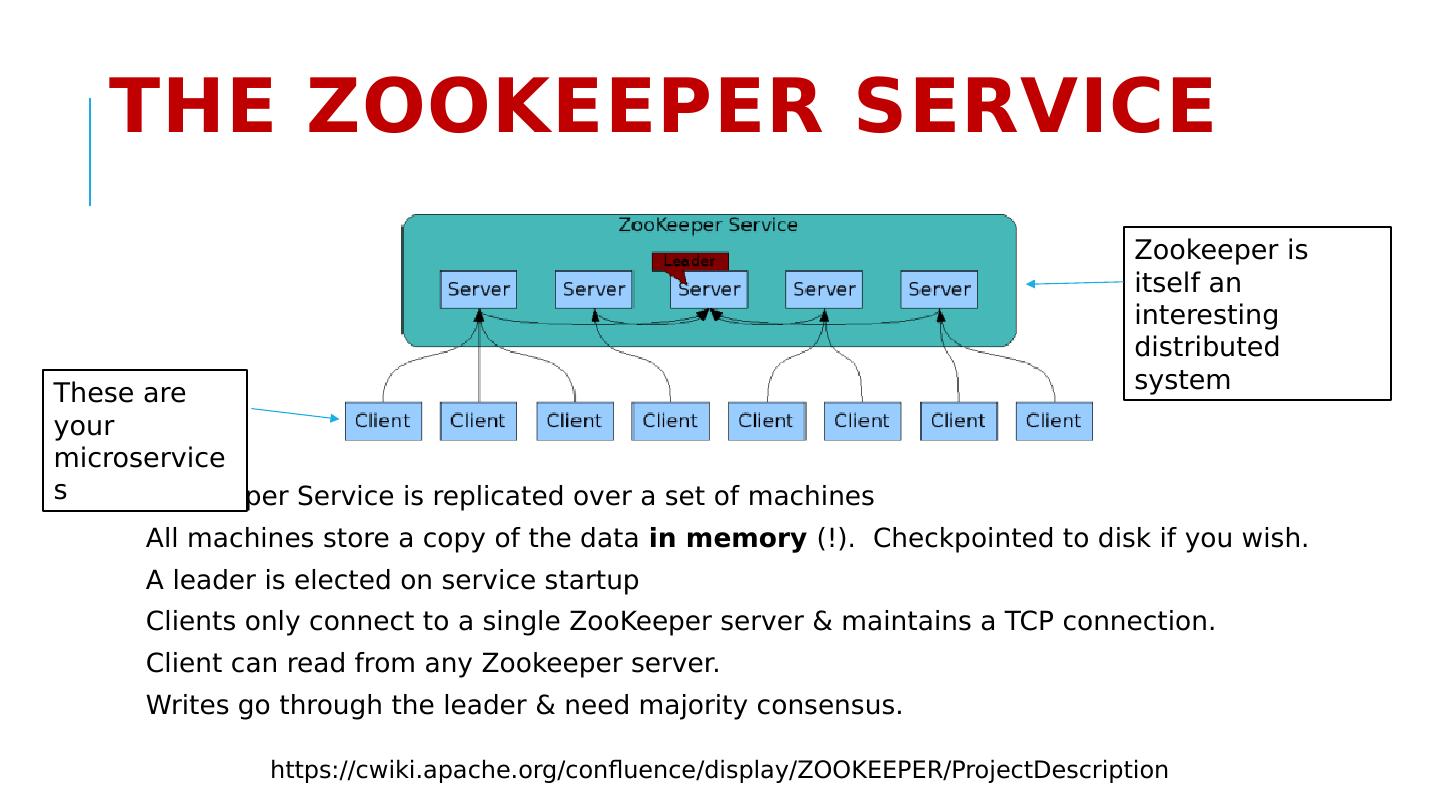
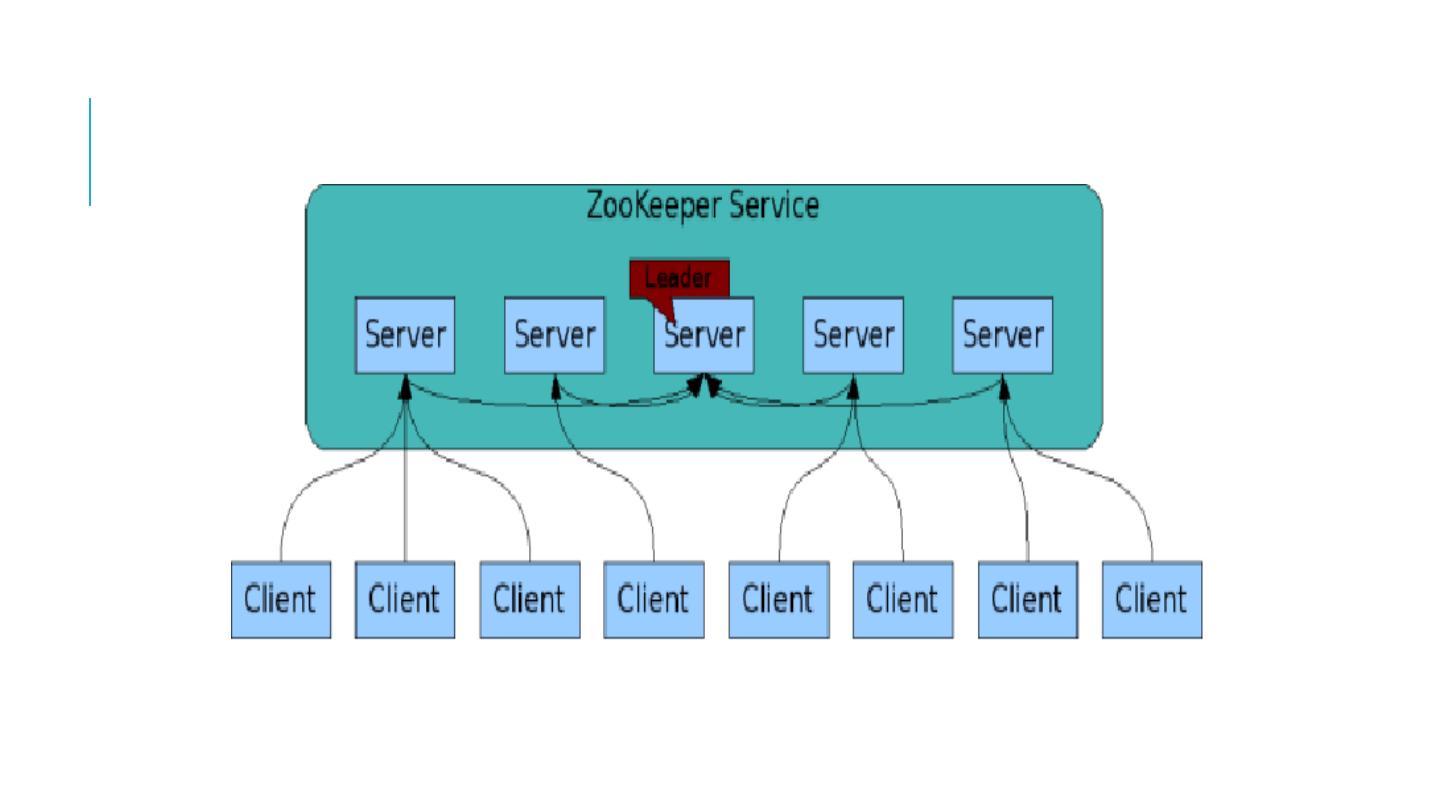
29 .The ZooKeeper Service ZooKeeper Service is replicated over a set of machines All machines store a copy of the data in memory (!). Checkpointed to disk if you wish. A leader is elected on service startup Clients only connect to a single ZooKeeper server & maintains a TCP connection. Client can read from any Zookeeper server . W rites go through the leader & need majority consensus. https://cwiki.apache.org/confluence/display/ZOOKEEPER/ProjectDescription These are your microservices Zookeeper is itself an interesting distributed system
3秒后跳转登录页面
去登陆

