









































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
可扩展性和键值分片
云可扩展性技术简介:层次结构,存在点迷你数据中心,完整数据中心,(键值)分片和简单的容错技术,使用DHT加通知来实现发布 -订阅消息总线,DDS或消息队列。综合考虑:Akamai CDN和Facebook大规模内容交付基础设施。
展开查看详情
1 .CS 5412/Lecture 2 Elasticity and Scalability Ken Birman Spring, 2019 http://www.cs.cornell.edu/courses/cs5412/2019sp 1
2 .Concept of Elastic scalability The sheer size of the cloud requires a lot of resources. These are allocated elastically , meaning “on demand”. Size: A company like Facebook needs to run data centers on every continent, and for the United States, has four major ones plus an extra 50 or so “point of presence” locations (mini-datacenters). A single data center might deal with millions of simultaneous users and have many hundreds of thousands of servers. http://www.cs.cornell.edu/courses/cs5412/2019sp 2 Not this kind of elastic!
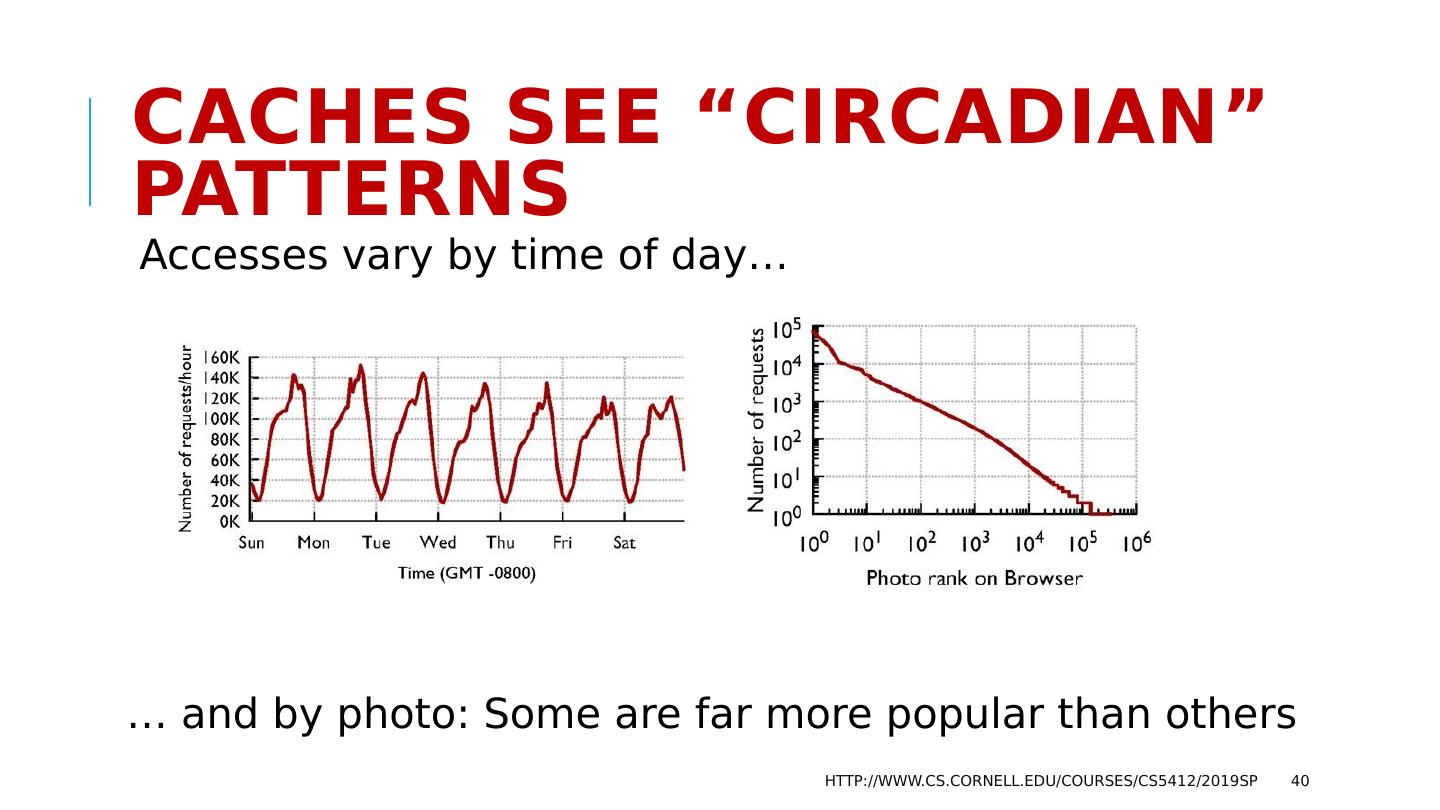
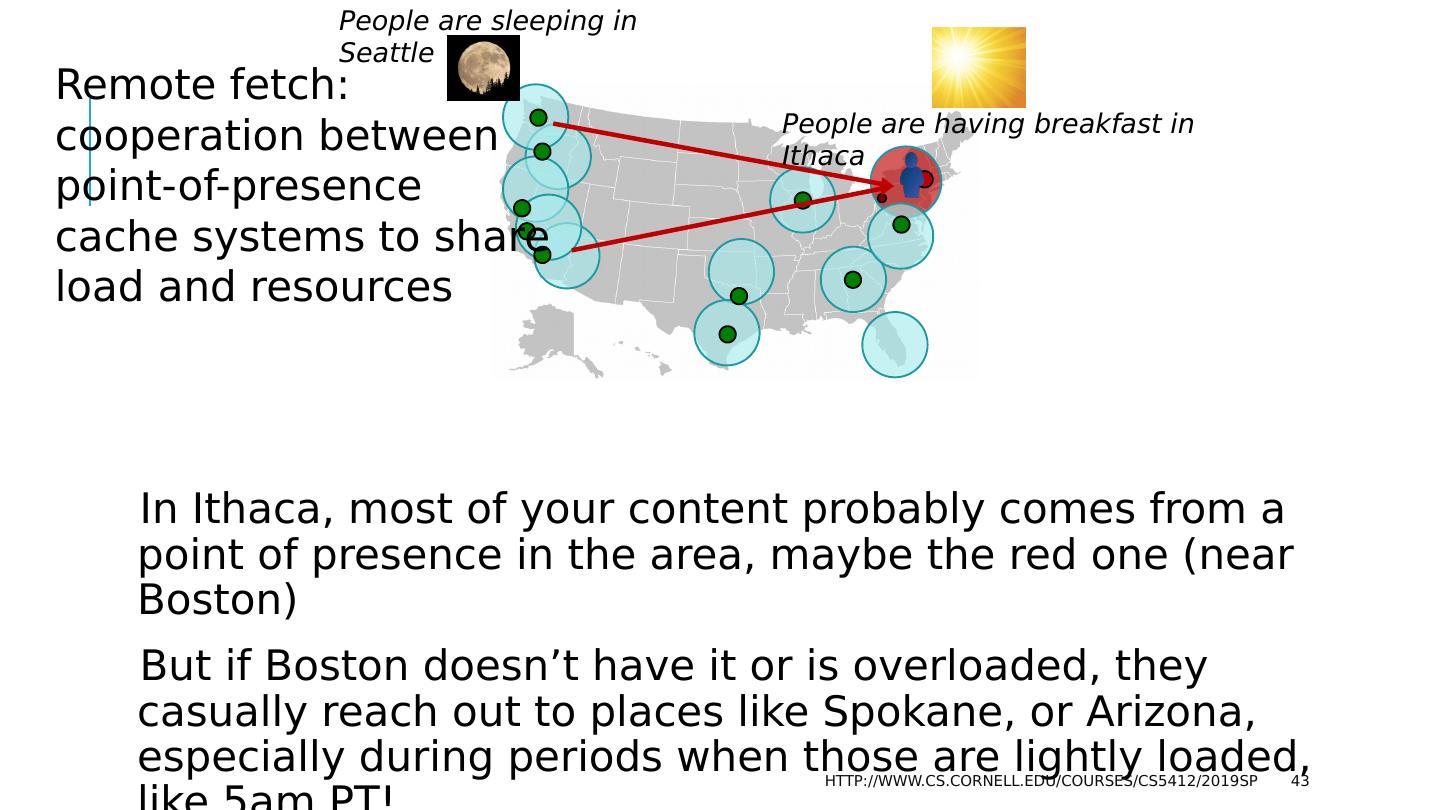
3 .Load swings are inevitable in this model People sleep in Seattle while they are waking up in New York. People work in Mumbia when nobody is working in the USA So any particular datacenter sees huge variation in loads. http://www.cs.cornell.edu/courses/cs5412/2019sp 3
4 .Diurnal and seasonal Load Patterns The cloud emerged for tasks like Google search and Amazon eCommerce , but people sleep. So there are periods of heavy human cloud use, but also long periods when many human users are idle. During those periods the cloud wants to reschedule machines for other tasks, like rebuilding indices for tomorrow morning, or finalizing purchases. So the cloud needs a programming model in which we can just give the service more resources (more machines) on demand. http://www.cs.cornell.edu/courses/cs5412/2019sp 4
5 .Should these elastic services be built as one big thing , or many smaller things ? Much like our “how to implement a NUMA server topic” Except here, we are scaling across nodes on a data center. http://www.cs.cornell.edu/courses/cs5412/2019sp 5
6 .Single big service performs poorly… why? Until 2005 “one server” was able to scale and keep up, like for Amazon’s shopping cart . A 2005 server often ran on a small cluster with, perhaps, 2-16 machines in the cluster. This worked well. But suddenly, as the cloud grew, this form of scaling broke. Companies threw unlimited money at the issue but critical services like databases still became hopelessly overloaded and crashed or fell far behind. http://www.cs.cornell.edu/courses/cs5412/2019sp 6
7 .Single big service performs poorly… why? Until 2005 “one server” was able to scale and keep up, like for Amazon’s shopping cart . A 2005 server often ran on a small cluster with, perhaps, 2-16 machines in the cluster. This worked well. But suddenly, as the cloud grew, this form of scaling broke. Companies threw unlimited money at the issue but critical services like databases still became hopelessly overloaded and crashed or fell far behind. http://www.cs.cornell.edu/courses/cs5412/2019sp 6
8 .How their paper approached it The paper uses a “chalkboard analysis” to think about scaling for a system that behaves like a database. It could be an actual database like SQL Server or Oracle But their “model” also covered any other storage layer where you want strong guarantees of data consistency. Mostly they talk about a single replicated storage instance, but look at structured versions too. http://www.cs.cornell.edu/courses/cs5412/2019sp 8
9 .The core issue The paper assumes that your goal is some form of lock-based consistency, which they model as database serializability (in CS5412 we might prefer “state machine replication”, but the idea is similar). So applications will be using read locks, and write locks, and because we want to accommodate more and more load by adding more servers, the work spreads over the pool of servers. This is a very common way to think about servers of all kinds. http://www.cs.cornell.edu/courses/cs5412/2019sp 9
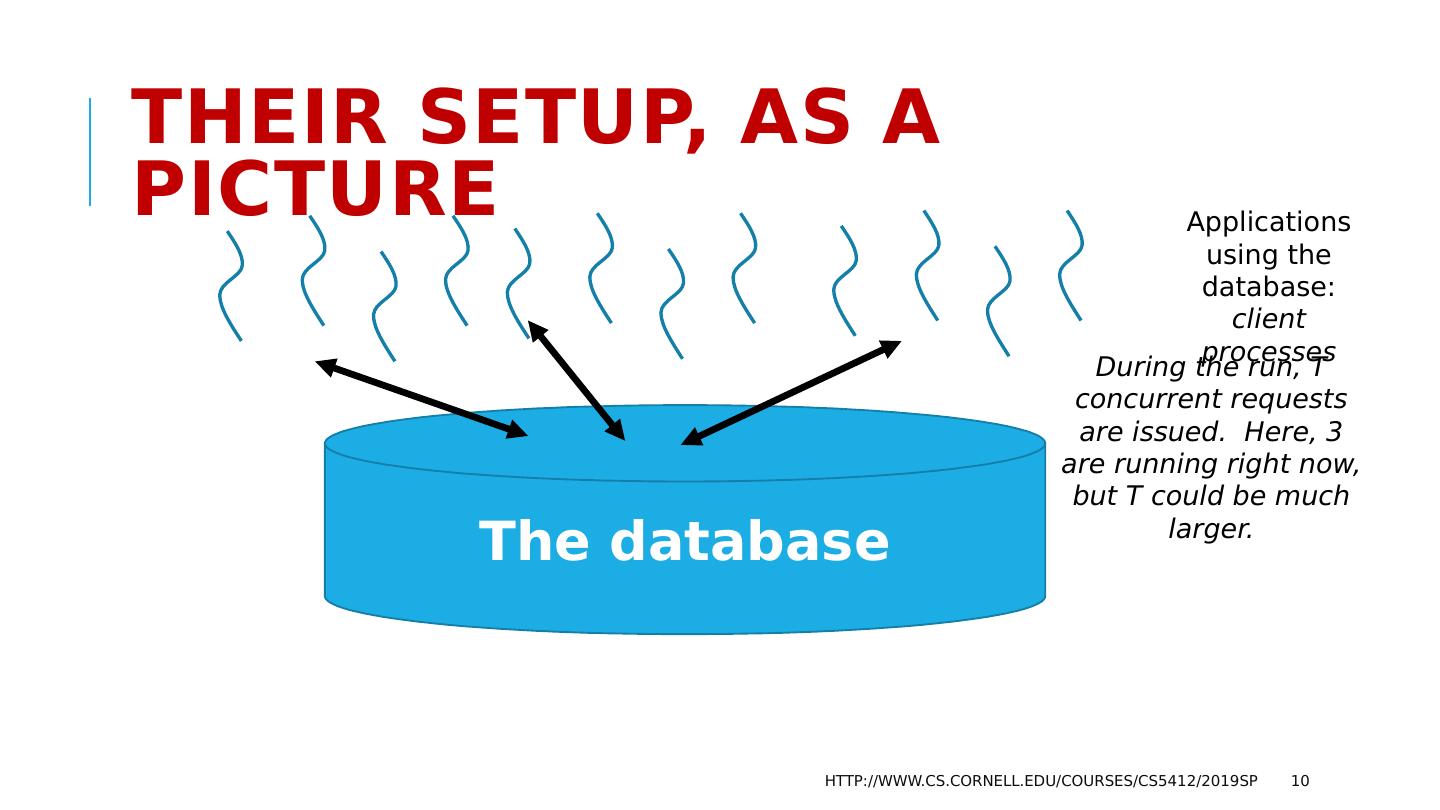
10 .Their setup, as a picture http://www.cs.cornell.edu/courses/cs5412/2019sp 10 The database Applications using the database: client processes During the run, T concurrent requests are issued. Here, 3 are running right now, but T could be much larger.
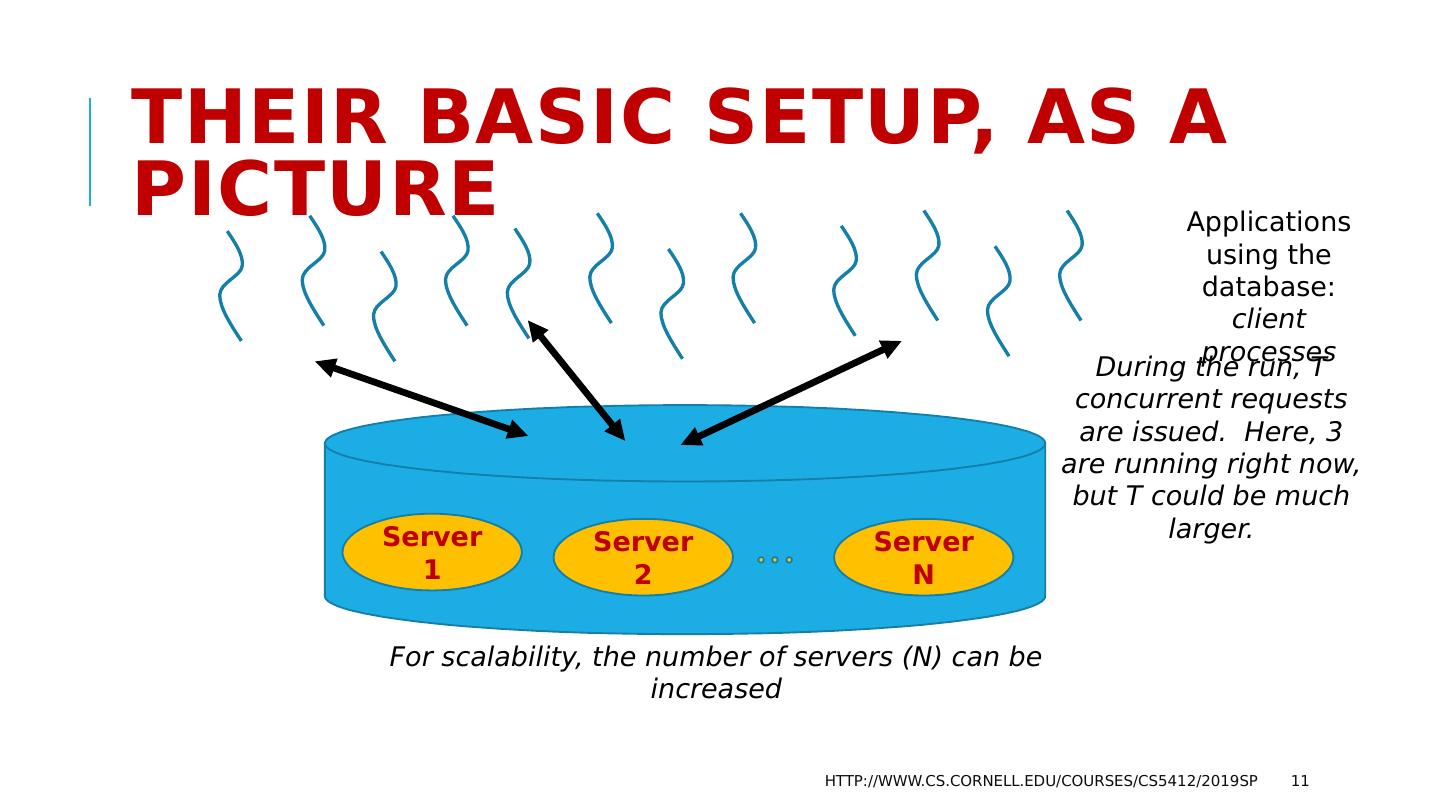
11 .Their Basic setup, as a picture http://www.cs.cornell.edu/courses/cs5412/2019sp 11 For scalability, the number of servers (N) can be increased Server 1 Server 2 Server N Applications using the database: client processes During the run, T concurrent requests are issued. Here, 3 are running right now, but T could be much larger.
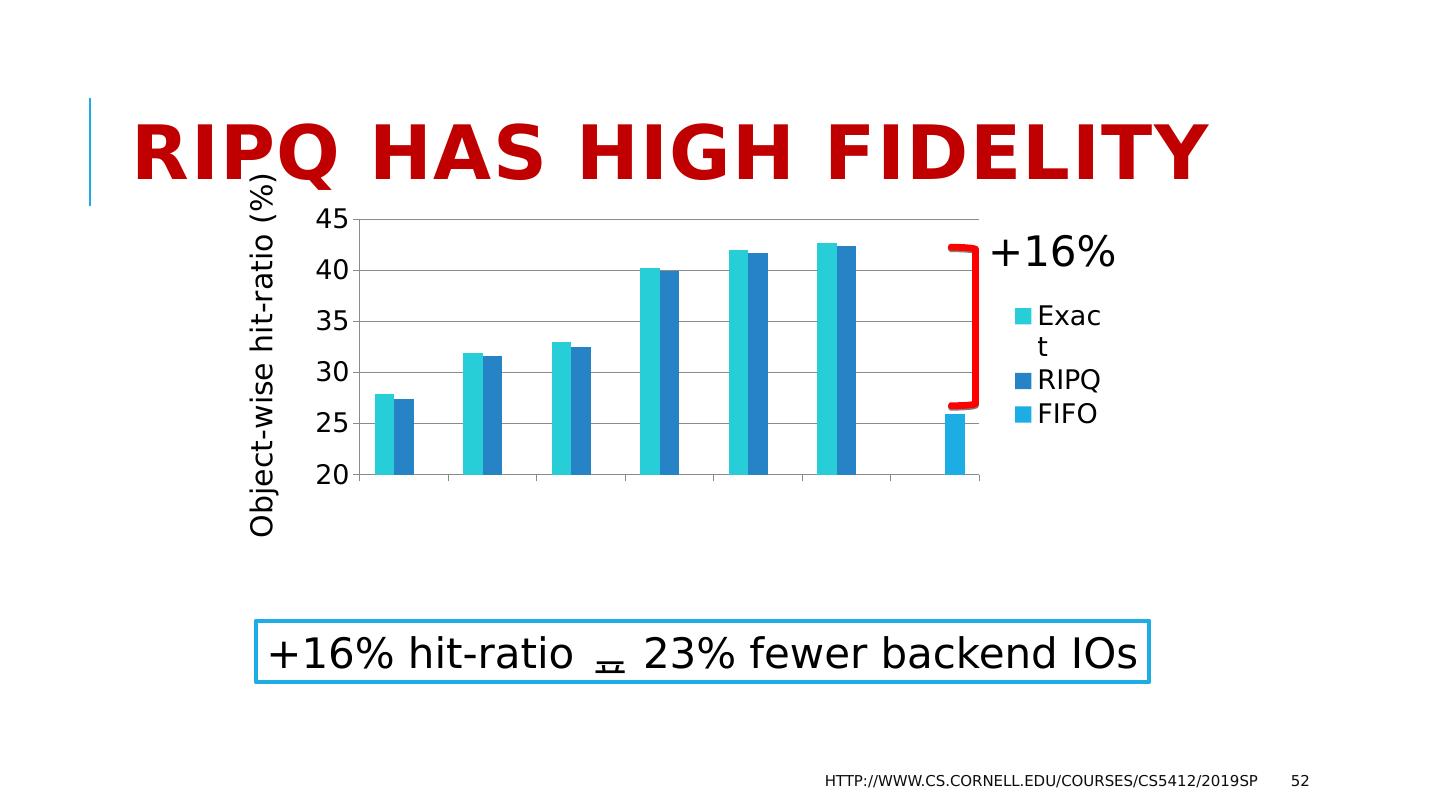
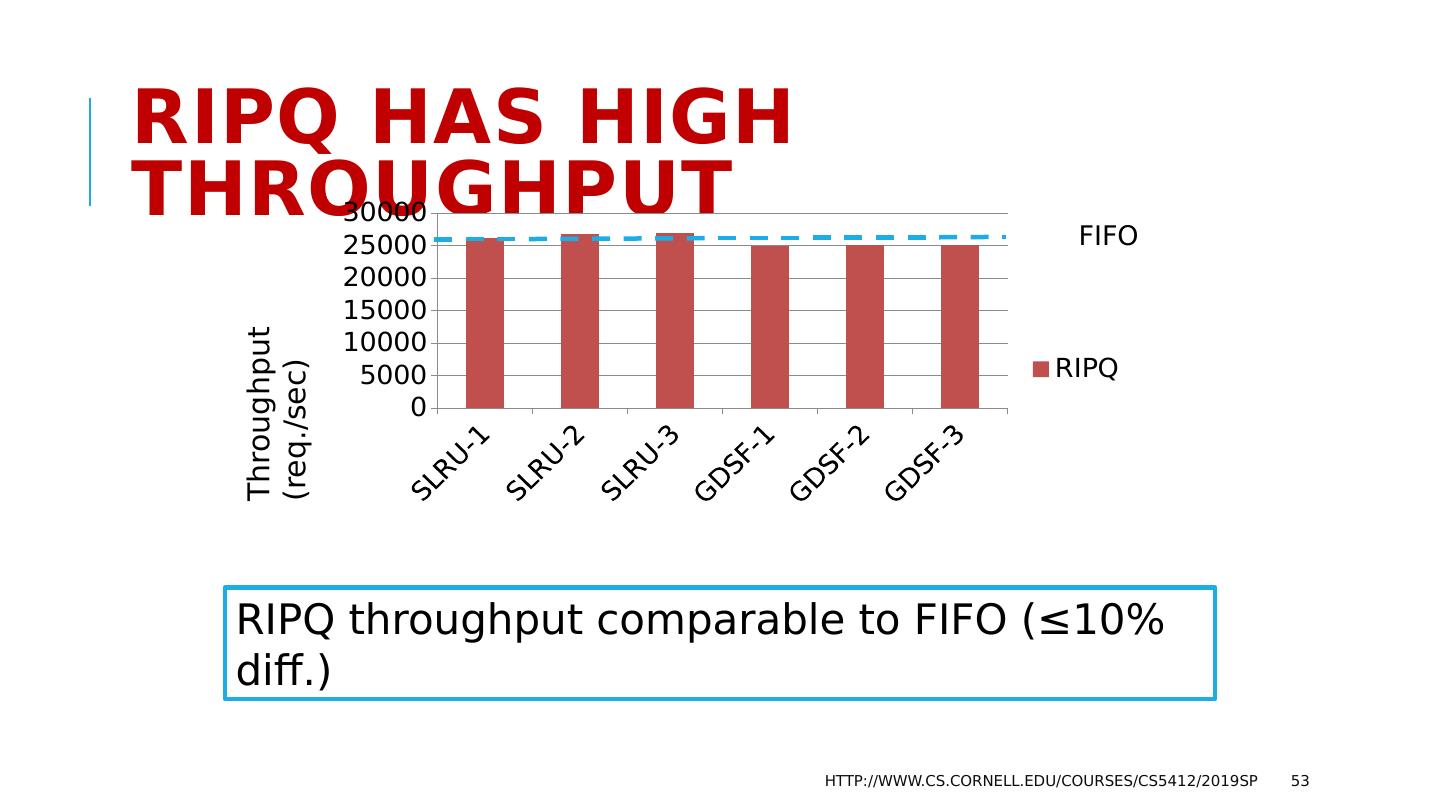
12 .What should be The goals? A scalable system needs to be able to handle “more T’s” by adding to N Instead, they found that the work the servers must do will increase as T 5 Worse, with an even split of work, deadlocks occur as N 3 Example: if 3 servers (N=3) could do 1000 TPS, with 5 servers the rate might drop to 300 TPS, purely because of deadlocks forcing abort/retry. http://www.cs.cornell.edu/courses/cs5412/2019sp 12
13 .Why do services slow down at scale? The paper pointed to several main issues: Lock contention. The more concurrent tasks, the more likely that they will try to access the same object (birthday paradox!) and wait for locks. Abort. Many consistency mechanisms have some form of optimistic behavior built in. Now and then, they must back out and retry. Deadlock also causes abort/retry sequences. The paper actually explores multiple options for structuring the data, but ends up with similar negative conclusions except in one specific situation. http://www.cs.cornell.edu/courses/cs5412/2019sp 13
14 .What Was that one good option? Back in 1996, they concluded that you are forced to shard the database into a large set of much smaller databases, with distinct data in each. By 2007, Jim was designing scalable sharded databases in which transactions only touched a single shard at a time . In 1996, it wasn’t clear that every important service could be sharded . By the 2007 period, Jim was making the case that in fact, this is feasible! http://www.cs.cornell.edu/courses/cs5412/2019sp 14
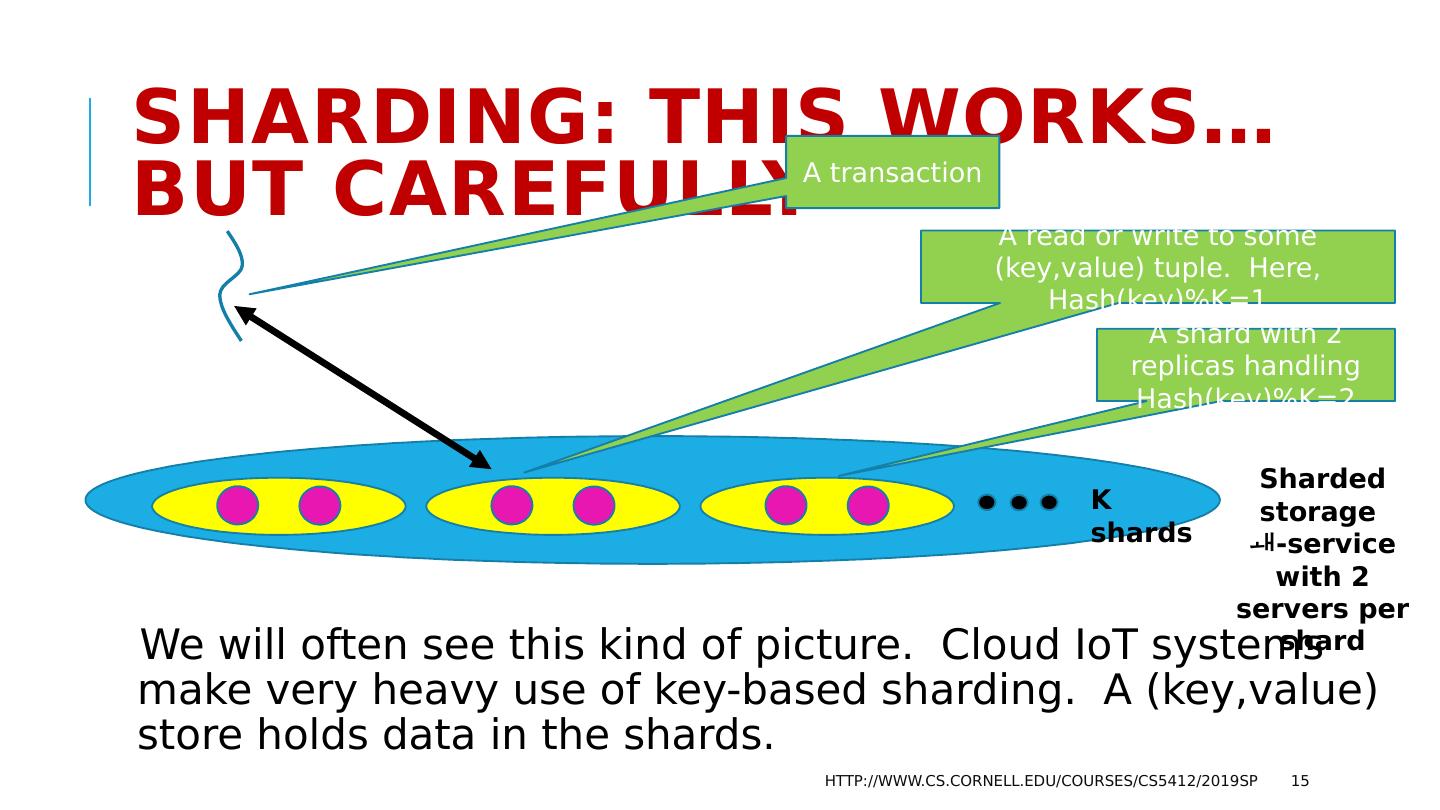
15 .Sharding : This works… but carefully We will often see this kind of picture. Cloud IoT systems make very heavy use of key-based sharding . A ( key,value ) store holds data in the shards. http://www.cs.cornell.edu/courses/cs5412/2019sp 15 Sharded storage - service with 2 servers per shard A shard with 2 replicas handling Hash(key)%K=2 A transaction A read or write to some ( key,value ) tuple. Here, Hash(key)%K=1 K shards
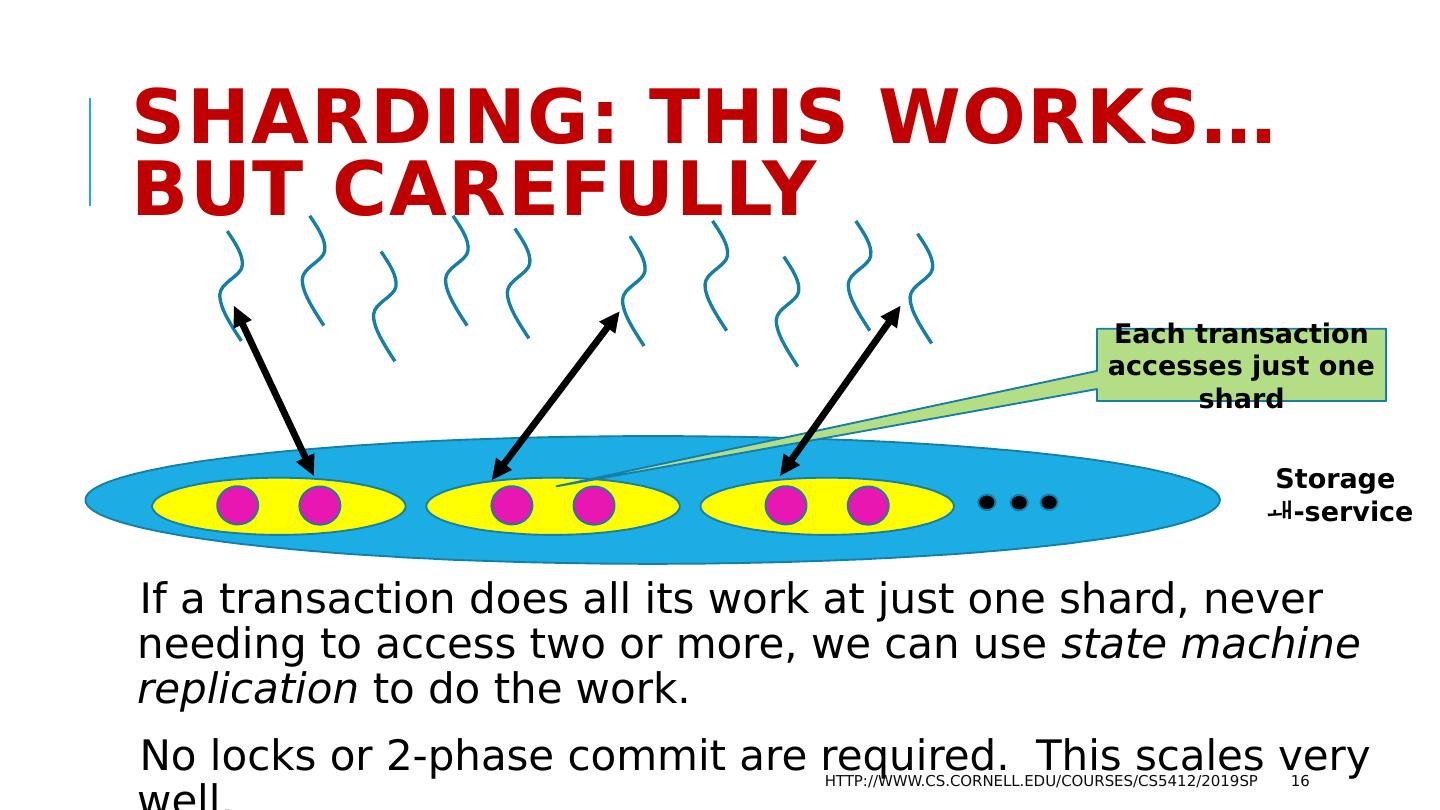
16 .Sharding : This works… but carefully If a transaction does all its work at just one shard, never needing to access two or more, we can use state machine replication to do the work. No locks or 2-phase commit are required. This scales very well. http://www.cs.cornell.edu/courses/cs5412/2019sp 16 Storage - service Each transaction accesses just one shard
17 .DefN : State Machine Replication This is a model in which we can read from any replica. To do an update, we use an atomic multicast or a durable Paxos write (multicast if the state is kept in-memory, and durable if on disk). The replicas see the same updates in the same sequence and so we can keep them in a consistent state. We package the transaction into a message so “delivery of the message” performs the transactional action. http://www.cs.cornell.edu/courses/cs5412/2019sp 17
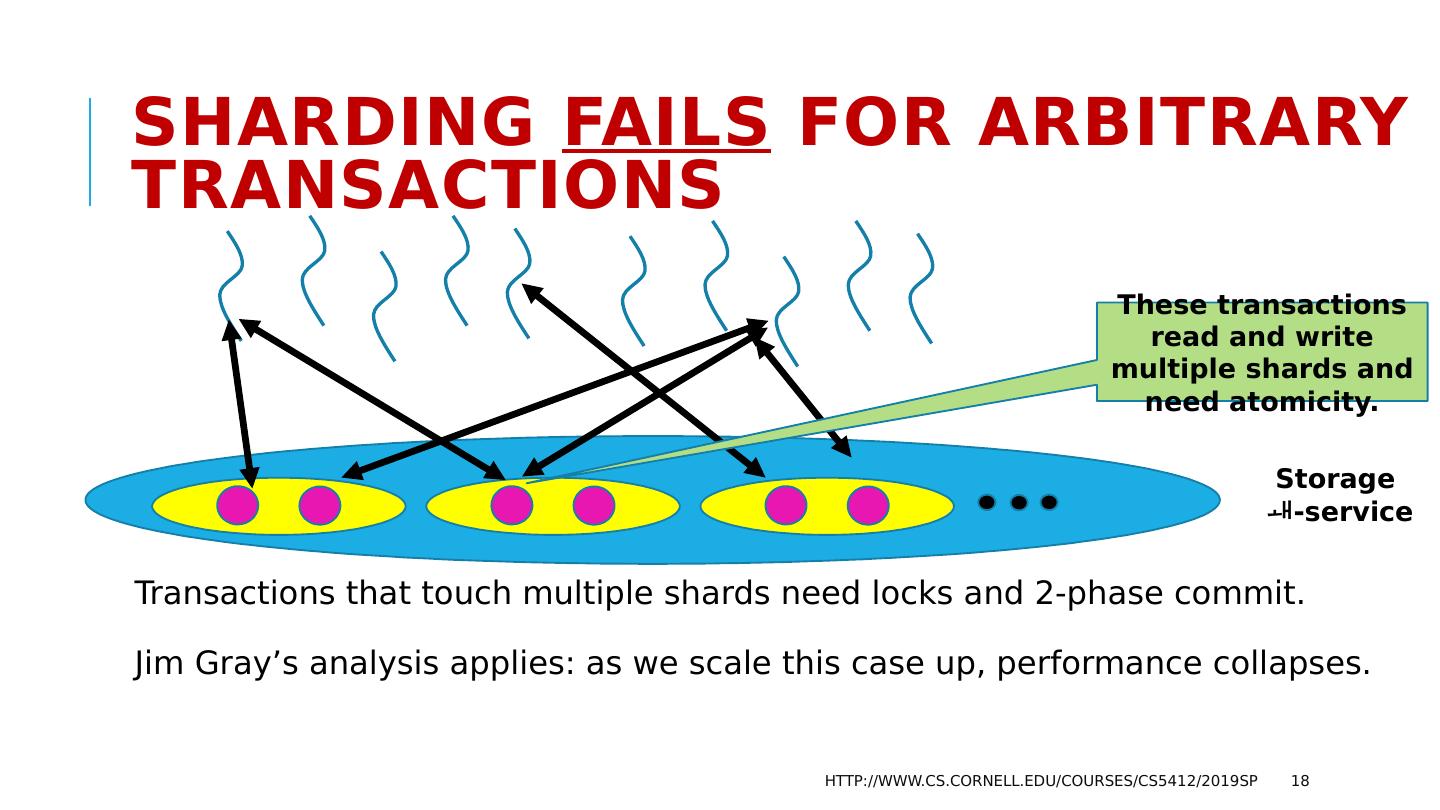
18 .Sharding fails for arbitrary transactions Transactions that touch multiple shards need locks and 2-phase commit. Jim Gray’s analysis applies: as we scale this case up, performance collapses. http://www.cs.cornell.edu/courses/cs5412/2019sp 18 Storage - service These transactions read and write multiple shards and need atomicity.
19 .Example: A -service for caching Let’s look closely at the concept of caching as it arises in a cloud, and at how we can make such a service elastic. This is just one example, but in fact is a great example because key-value data structures are very common in the cloud. http://www.cs.cornell.edu/courses/cs5412/2019sp 19
20 .Key= Birman Accessing Sharded Storage http://www.cs.cornell.edu/courses/cs5412/2019sp 20 Value= Hash(“Birman”)%100000 Each machine has a set of ( key,value ) tuples stored in a local “Map” or perhaps on NVMe In effect, two levels of hashing!
21 .Many systems use a second copy as a backup, for higher availability http://www.cs.cornell.edu/courses/cs5412/2019sp 21 Key=“Ken” Value= Hash(“Ken”)%100000 These two machines both store a copy of the ( key,value ) tuple in a local “Map” or perhaps on NVMe In effect, two levels of hashing!
22 .Terminology This is called a “key value store” (KVS) or a “distributed hash table” (DHT) Each replica holds a “shard” of the KVS: a distinct portion of the data. Hashing is actually done using a cryptographic function like SHA 256. http://www.cs.cornell.edu/courses/cs5412/2019sp 22
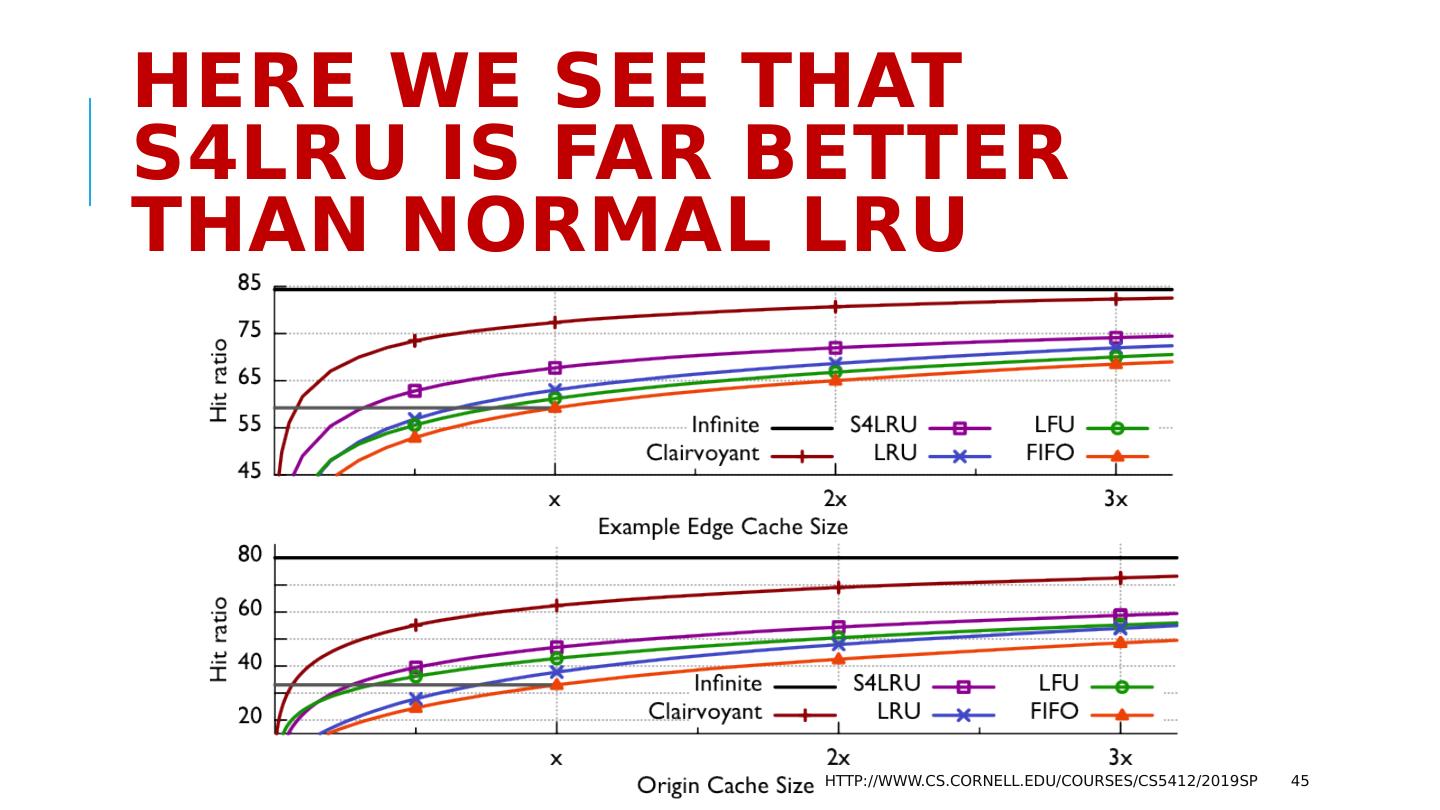
23 .Elasticity Adds a Further dimension If we expect changing patterns of load, the cache may need a way to dynamically change the pattern of sharding . Since a cache “works” even if empty, we could simply shut it down and restart with some other number of servers and some other sharding policy. But cold caches perform very badly. Instead, we would ideally “shuffle” data. http://www.cs.cornell.edu/courses/cs5412/2019sp 23
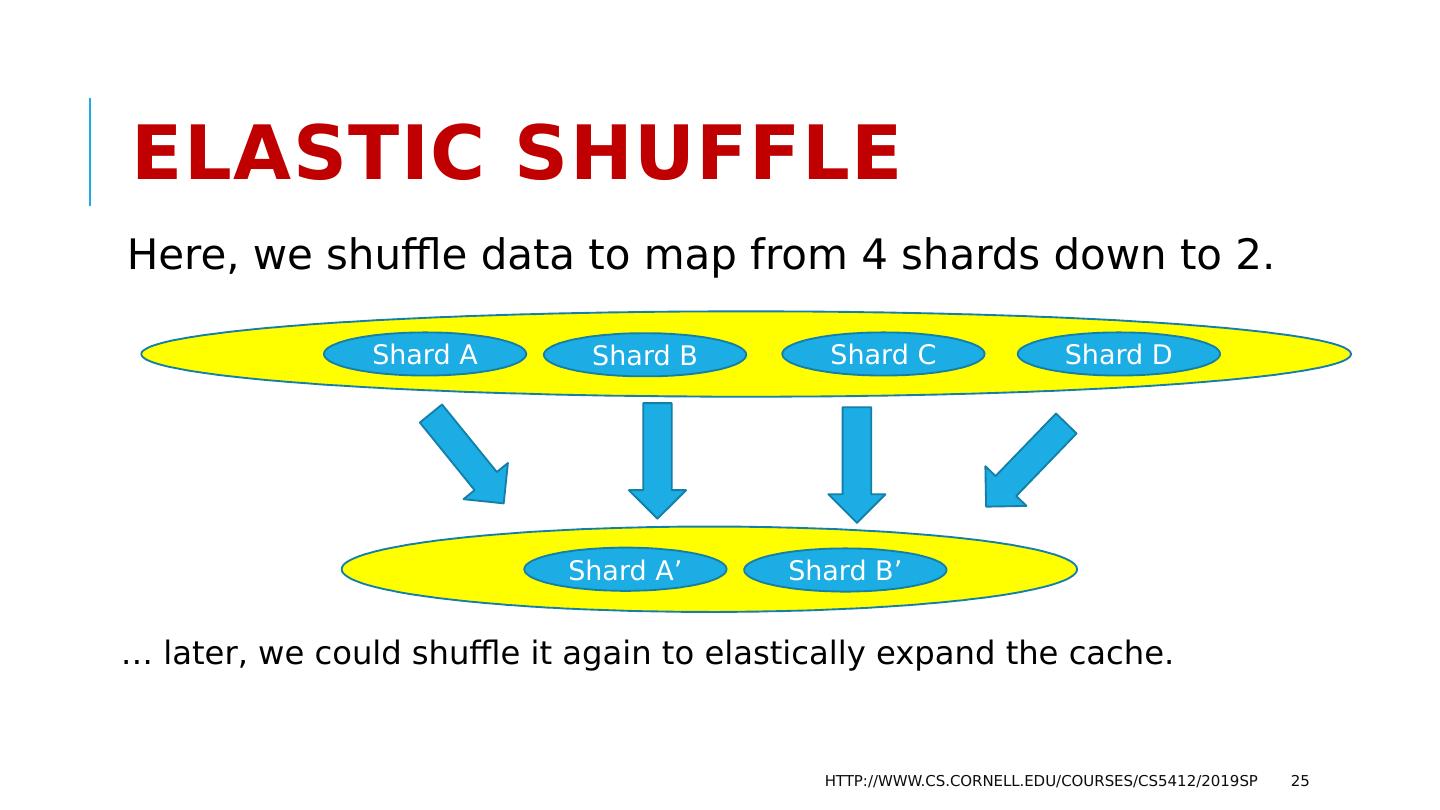
24 .Elastic shuffle Perhaps we initially had data spread over 4 shards. We could drop down to 2 shards during low-load periods. Of course half our items (hopefully, less popular ones) are dropped. http://www.cs.cornell.edu/courses/cs5412/2019sp 24 Shard A Shard B Shard C Shard D
25 .Elastic shuffle Here, we shuffle data to map from 4 shards down to 2. http://www.cs.cornell.edu/courses/cs5412/2019sp 25 Shard A Shard B Shard C Shard D Shard A’ Shard B’ … later, we could shuffle it again to elastically expand the cache.
26 .But how would other services know? A second issue now arises: how can applications that use the cache find out that the pattern just changed? Typically, big data centers have a management infrastructure that owns this kind of information and keeps it in files (lists of the processes currently in the cache, and the parameters needed to compute the shard mapping). If the layout changes, applications are told to reread the configuration. Later we will learn about one tool for this (Zookeeper). http://www.cs.cornell.edu/courses/cs5412/2019sp 26
27 .Typical DHT API? The so-called MemCached API was the first widely popular example. Today there are many important DHTs (Cassandra, Dynamo DB, MemCached , and the list just goes on and on). All support some form of ( key,value ) put , get , and (most) offer watch. Some hide these basic operations behind file system APIs, or “computer-to-computer email” APIs (publish-subscribe or queuing), or database APIs. http://www.cs.cornell.edu/courses/cs5412/2019sp 27
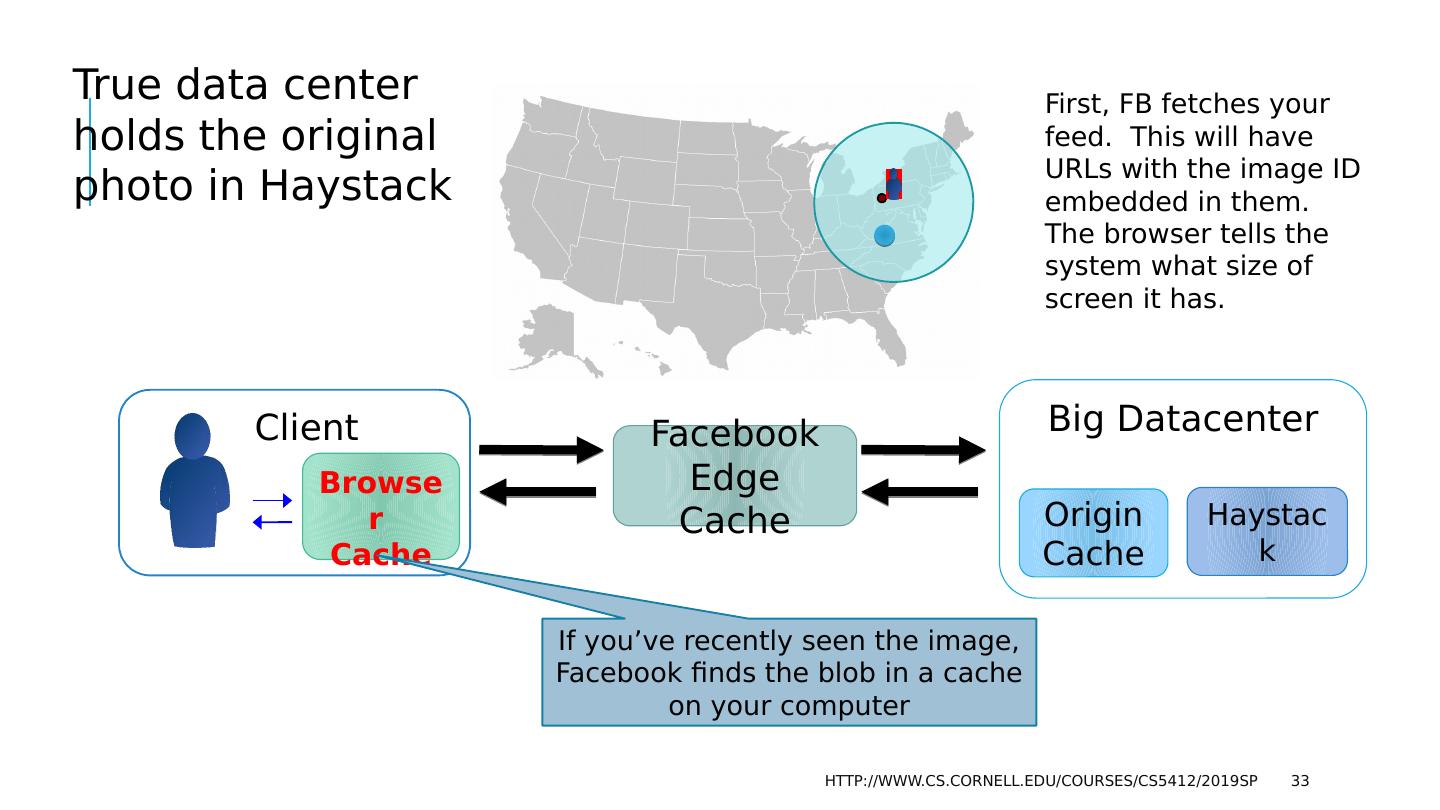
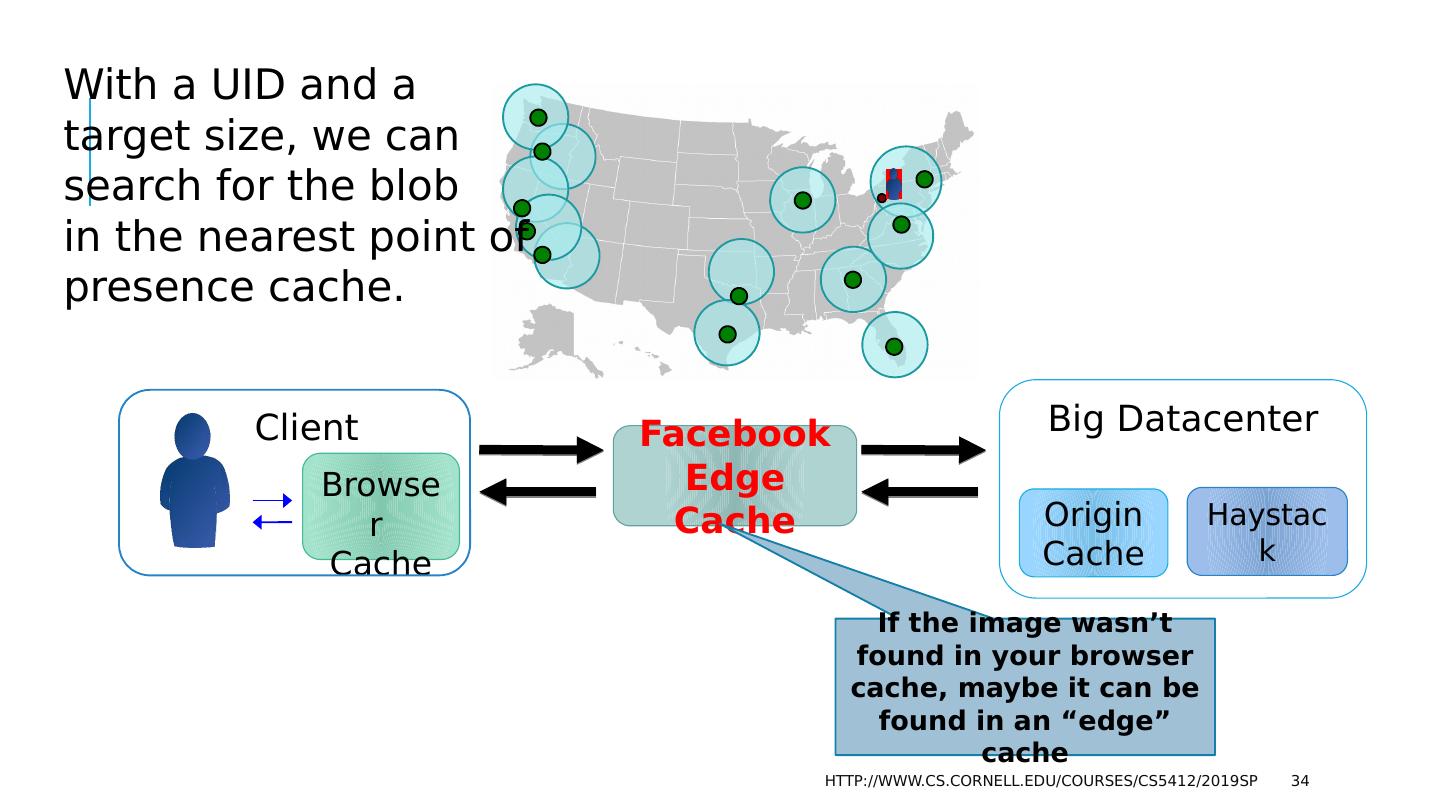
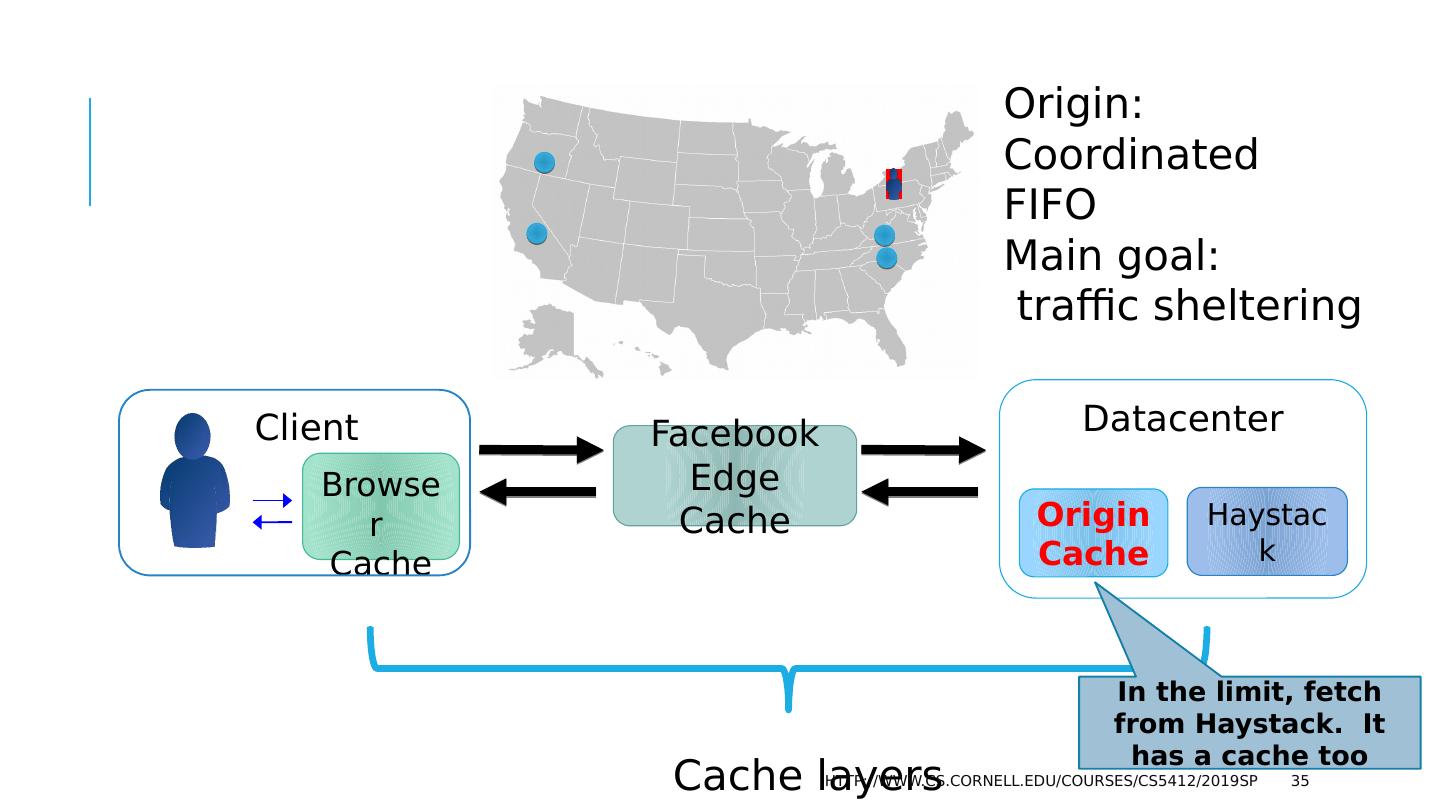
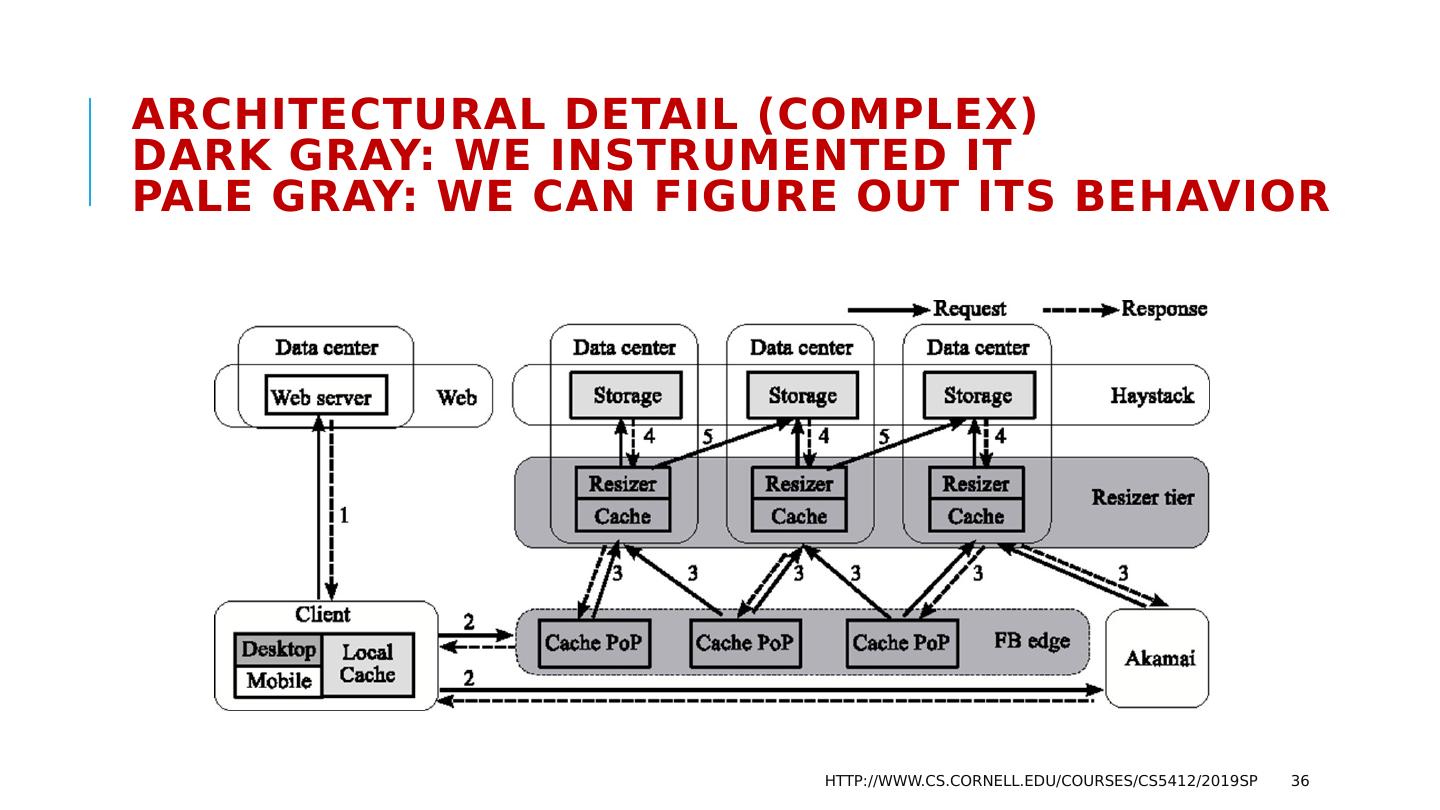
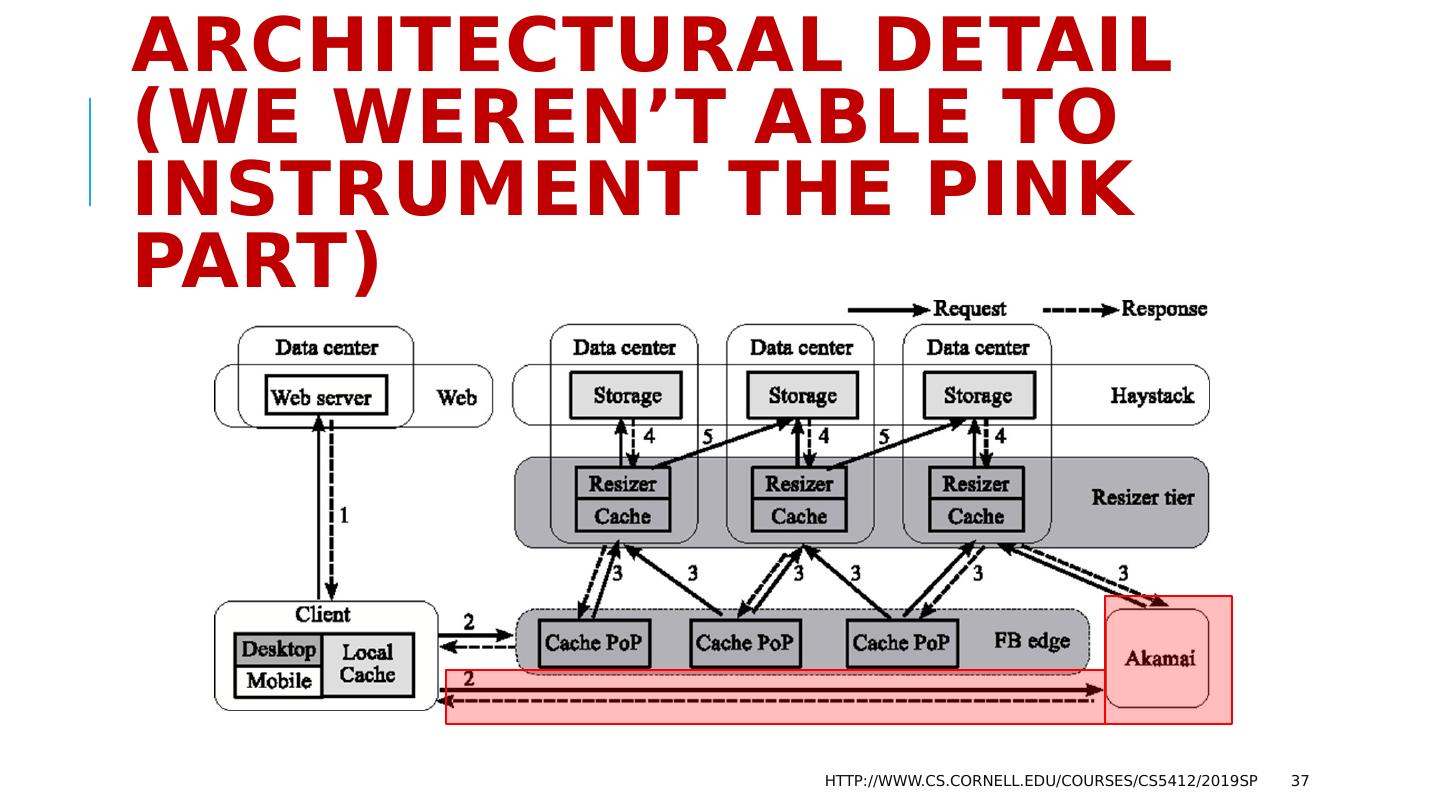
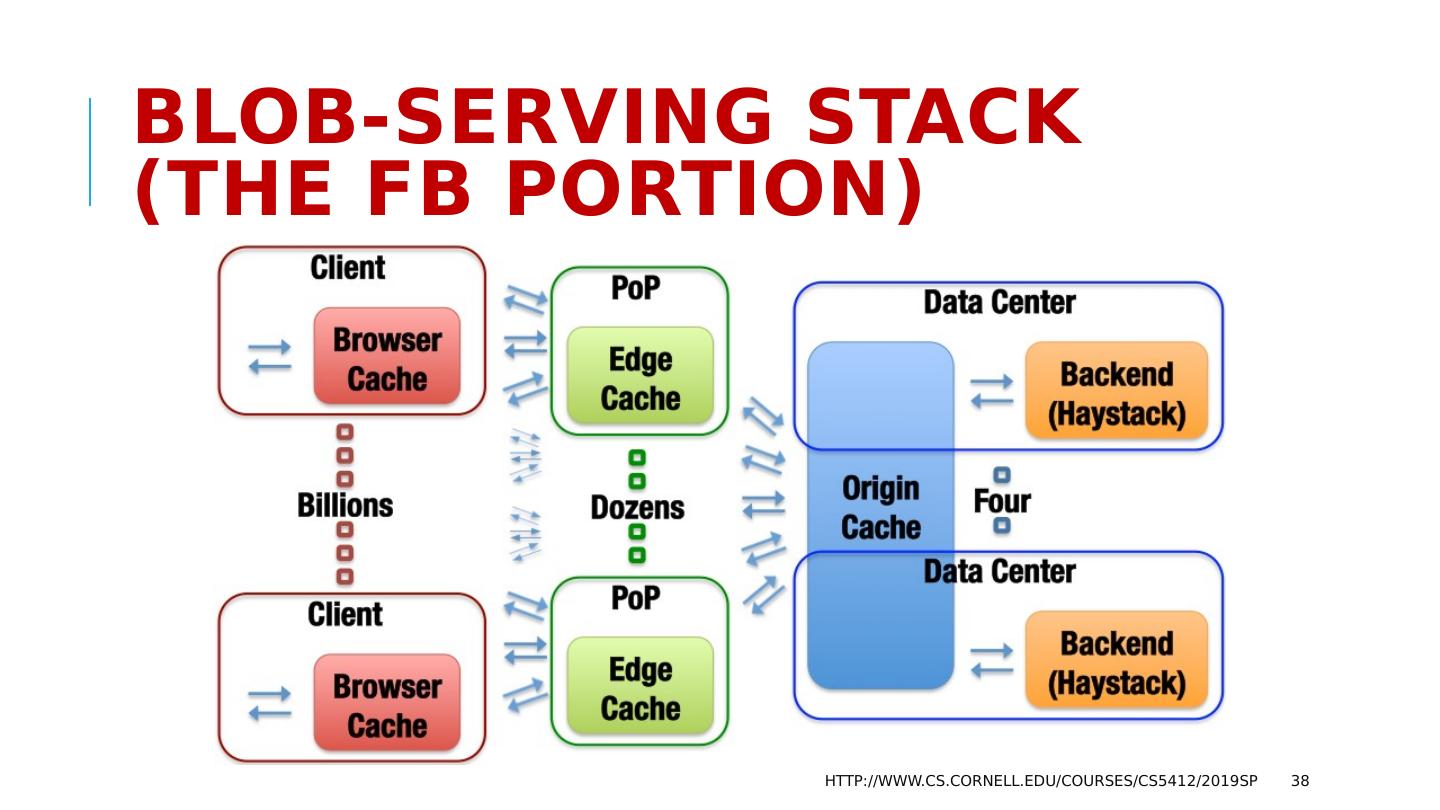
28 .Use case: FB Content Delivery Network Facebook’s CDN is a cloud-scale infrastructure that runs on point of presence datacenters in which key-value caches are deployed. Role is to serve videos and images for end-users. Weak consistency is fine because videos and images are immutable (each object is written once, then read many times). Requirements include speed, scaling, fault-tolerance, self-management http://www.cs.cornell.edu/courses/cs5412/2019sp 28
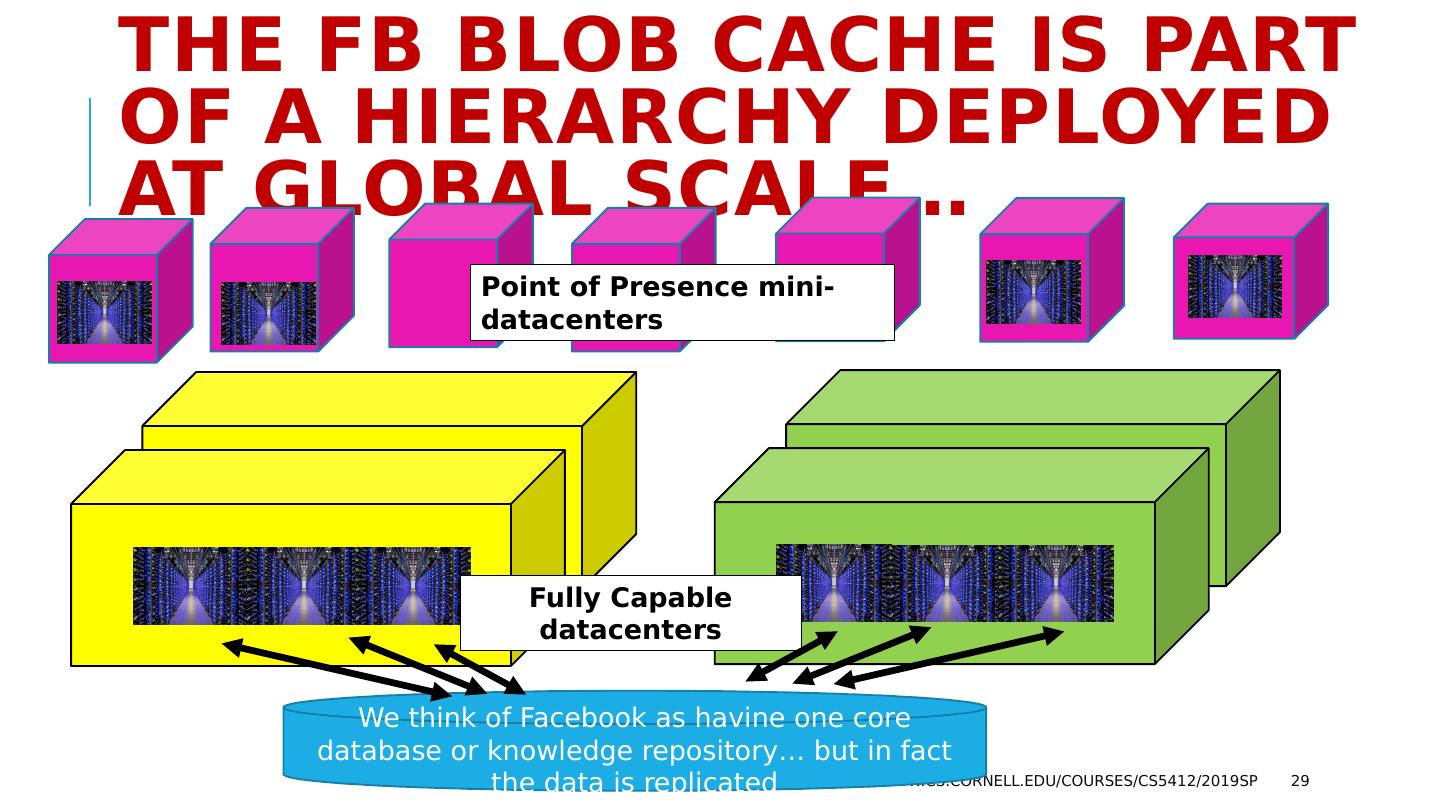
29 .The FB BLOB cache is part of A hierarchy deployed at global scale… http://www.cs.cornell.edu/courses/cs5412/2019sp 29 We think of Facebook as havine one core database or knowledge repository… but in fact the data is replicated Point of Presence mini-datacenters Fully Capable datacenters
3秒后跳转登录页面
去登陆

