
















































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
物联网:概述
Azure IoT模型:传感器,Azure物联网边缘角色,Azure智能边缘和物联网中心,u服务模型,数据中心文件系统和数据库基础架构,大数据分析基础架构。
我们专注于Azure只是为了一致性,但亚马逊AWS拥有完全类似的组件,除了在物联网上关注度较低
展开查看详情
1 . CS 5412/Lecture 1 Topics in Cloud Computing Ken Birman Spring, 2019 http://www.cs.cornell.edu/courses/cs5412/2019sp 1
2 .Cloud Computing CS5412 is… A deep study of a big topic. In spring 2019 our focus will be on “smart farming” in Azure IoT Edge. The farming focus leverages a Cornell and Microsoft interest (and an Azure product area) and makes it real. http://www.cs.cornell.edu/courses/cs5412/2019sp 2 Today… people like you Tomorrow… Bessie! Fog computing!
3 .The cloud is “big”! Google: 40,000 queries per second (1.2 Trillion per year) YouTube: 1.9B active users per month, viewing 5B videos per day Facebook: 2.23B active users, 8B video views,15M photos uploaed per day Cloud: Nearly 4B of the world’s 7B accessed cloud resources in 2018 … the scale of computing to support these stories is just surreal! http://www.cs.cornell.edu/courses/cs5412/2019sp 3
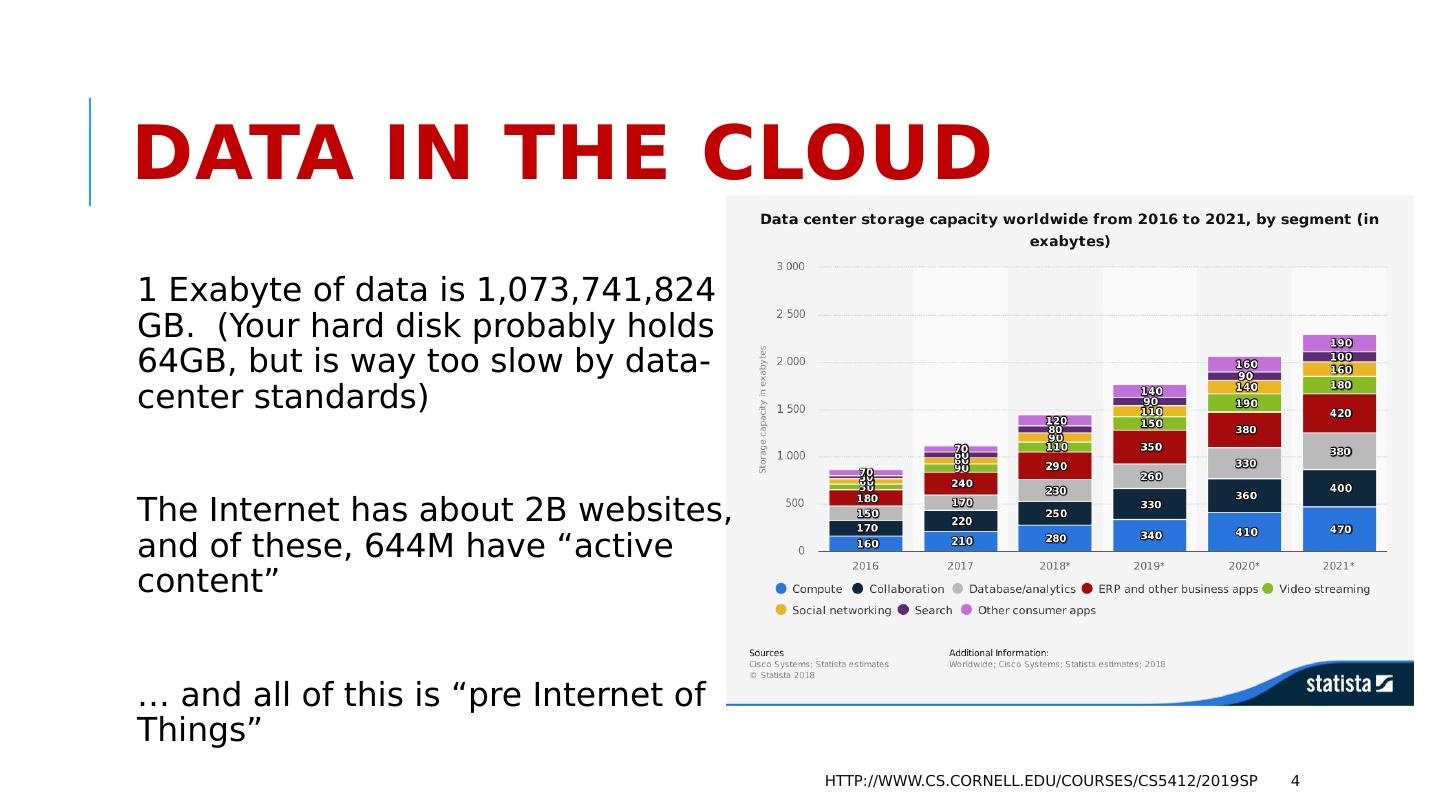
4 .Data in the cloud 1 Exabyte of data is 1,073,741,824 GB. (Your hard disk probably holds 64GB, but is way too slow by data-center standards) The Internet has about 2B websites, and of these, 644M have “active content” … and all of this is “pre Internet of Things” http://www.cs.cornell.edu/courses/cs5412/2019sp 4
5 .… and there is big money, too. Everything costs money. In fact the cloud computing platform vendors spend $20B per year on data centers (all costs combined) This money is coming from a advertising, product sales, services. The big players spend “in proportion” to what they earn. … so the cloud is “optimized” for today’s profitable tasks, at scale. Until IoT is self-sustaining, the trick is to reuse the existing cloud (if possible). http://www.cs.cornell.edu/courses/cs5412/2019sp 5
6 .How did today’s Cloud evolve? Prior to ~2005, we had “data centers designed for high availability”. Amazon had especially large ones, to serve its web requests This is all before the AWS cloud model The real goal was just to support online shopping Their system wasn’t very reliable and the core problem was scaling Like a theoretical complexity growth issue. Amazon’s computers were overloaded and often crashed http://www.cs.cornell.edu/courses/cs5412/2019sp 6
7 .Yahoo Experiment At Yahoo, they tried an “alpha/beta” experiment Customers who saw fast web page rendering (below 100ms) were happy. For every 100ms delay, purchase rates noticeably dropped . Speed at scale determines revenue, and revenue shapes technology: an arms race to speed up the cloud. http://www.cs.cornell.edu/courses/cs5412/2019sp 7 A sprint to render your web page!
8 .Starting around 2006, Amazon led in reinventing data center computing Amazon reorganized their whole approach: Requests arrived at a “first tier” of very lightweight servers. These dispatched work requests on a message bus or queue. The requests were selected by “micro-services” running in relastic pools. One web request might involve tens or hundreds of -services! They also began to guess at your next action and precompute what they would probably need to answer your next query or link click. http://www.cs.cornell.edu/courses/cs5412/2019sp 8
9 .Old Approach (2005) Product List Computers were mostly desktops Internet routing was pretty static, except for load balancing Web Server built the page… in Seattle Image Database Billing and Account Info Databases held the real product inventory http://www.cs.cornell.edu/courses/cs5412/2019sp 9
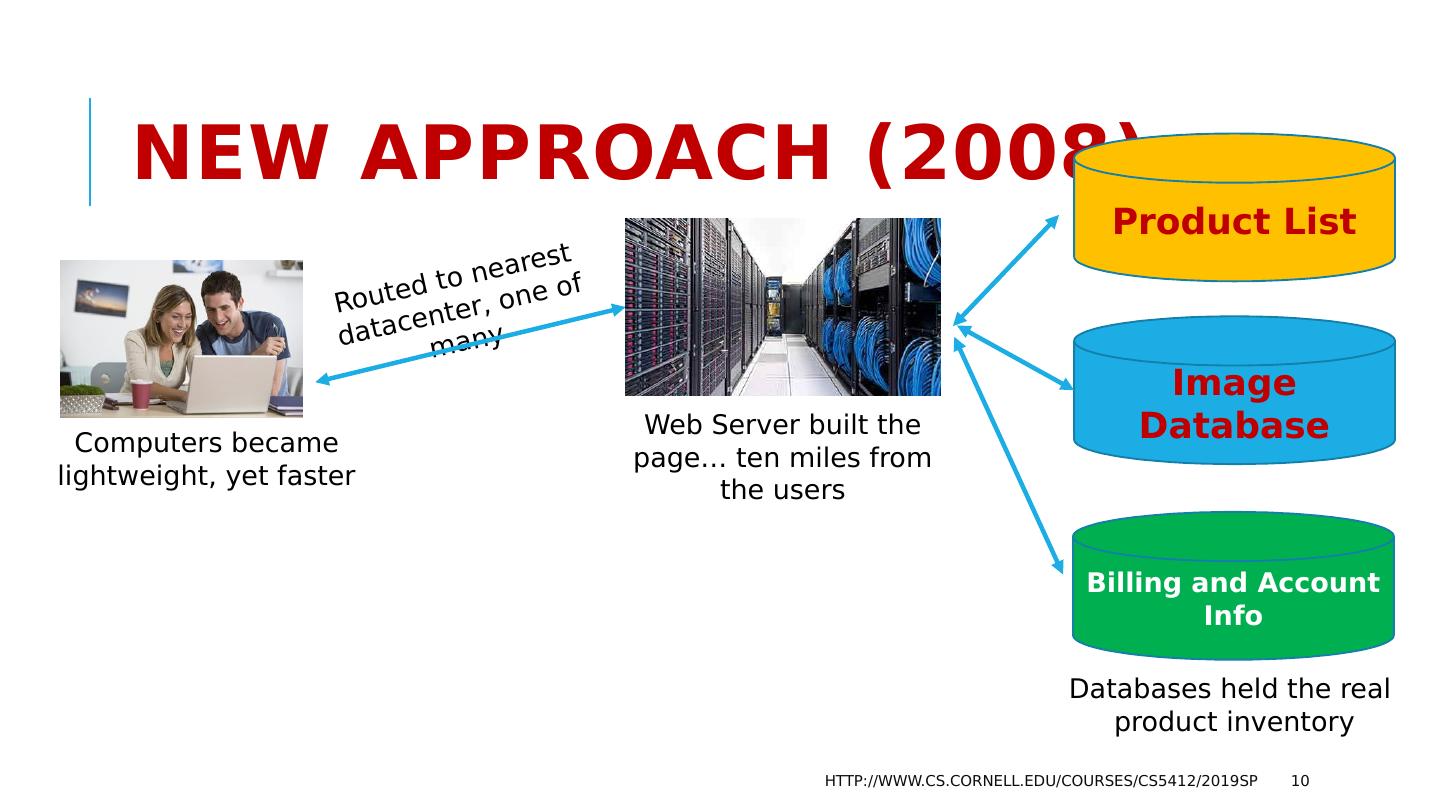
10 .New Approach (2008) Product List Computers became lightweight, yet faster Image Database Billing and Account Info Databases held the real product inventory http://www.cs.cornell.edu/courses/cs5412/2019sp 10 Routed to nearest datacenter, one of many Web Server built the page… ten miles from the users
11 .New Approach (2008) Product List Computers became lightweight, yet faster Image Database Billing and Account Info Databases held the real product inventory http://www.cs.cornell.edu/courses/cs5412/2019sp 11 Routed to nearest datacenter, one of many Web Server built the page… ten miles from the users More and more mobile apps Backup routing options
12 .New Approach (2008) Desktops with snappier response More and more mobile apps Routed to nearest datacenter, one of many http://www.cs.cornell.edu/courses/cs5412/2019sp 12 Message Bus Racks of highly parallel workers do much of the data fetching and processing, ideally ahead of need… The old databases are split into smaller and highly parallel services. Web Server becomes simpler and does less of the real work GeoReplication
13 .Tier one / Tier Two We often talk about the cloud as a “multi-tier” environment. Tier one: programs that generate the web page you see. Tier two: services that support tier one. We will see one later (DHT/KVS storage used to create a massive cache) http://www.cs.cornell.edu/courses/cs5412/2019sp 13
14 .Today’s Cloud Tier one runs on very lightweight servers: They use very small amounts of computer memory They don’t need a lot of compute power either They have limited needs for storage, or network I/O Tier two -Services specialize in various aspects of the content delivered to the end-user. They may run on somewhat “beefier” computers. http://www.cs.cornell.edu/courses/cs5412/2019sp 14
15 .Deep Dive: Best Way to Leverage Parallelism Not every way of scaling is equally effective. Pick poorly and you might make less money! To see this, we’ll spend a minute on just one example. This may feel like a small detour but actually is typical of CS5412 http://www.cs.cornell.edu/courses/cs5412/2019sp 15 Slight digression
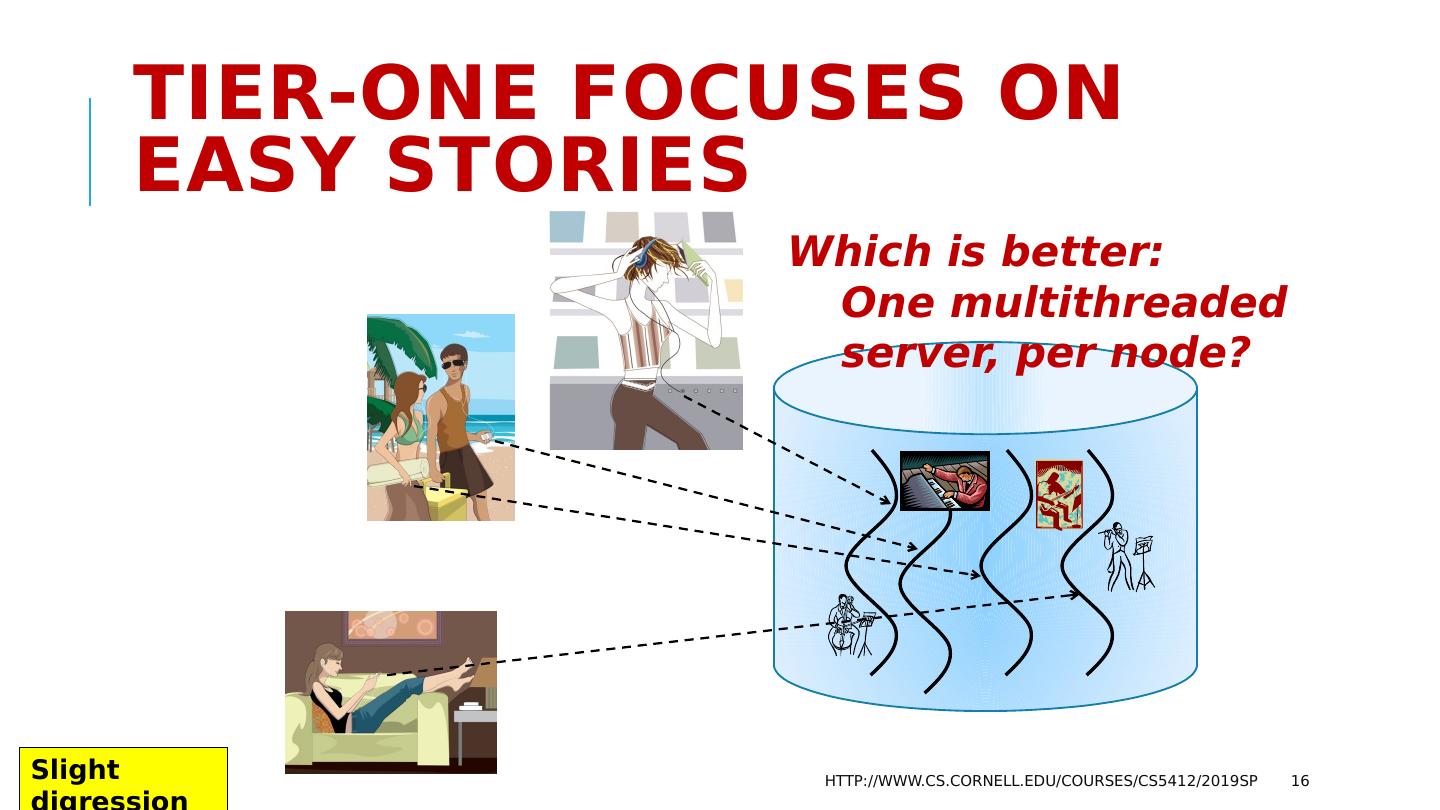
16 .Tier-One focuses on easy stories Which is better: One multithreaded server, per node? http://www.cs.cornell.edu/courses/cs5412/2019sp 16 Slight digression
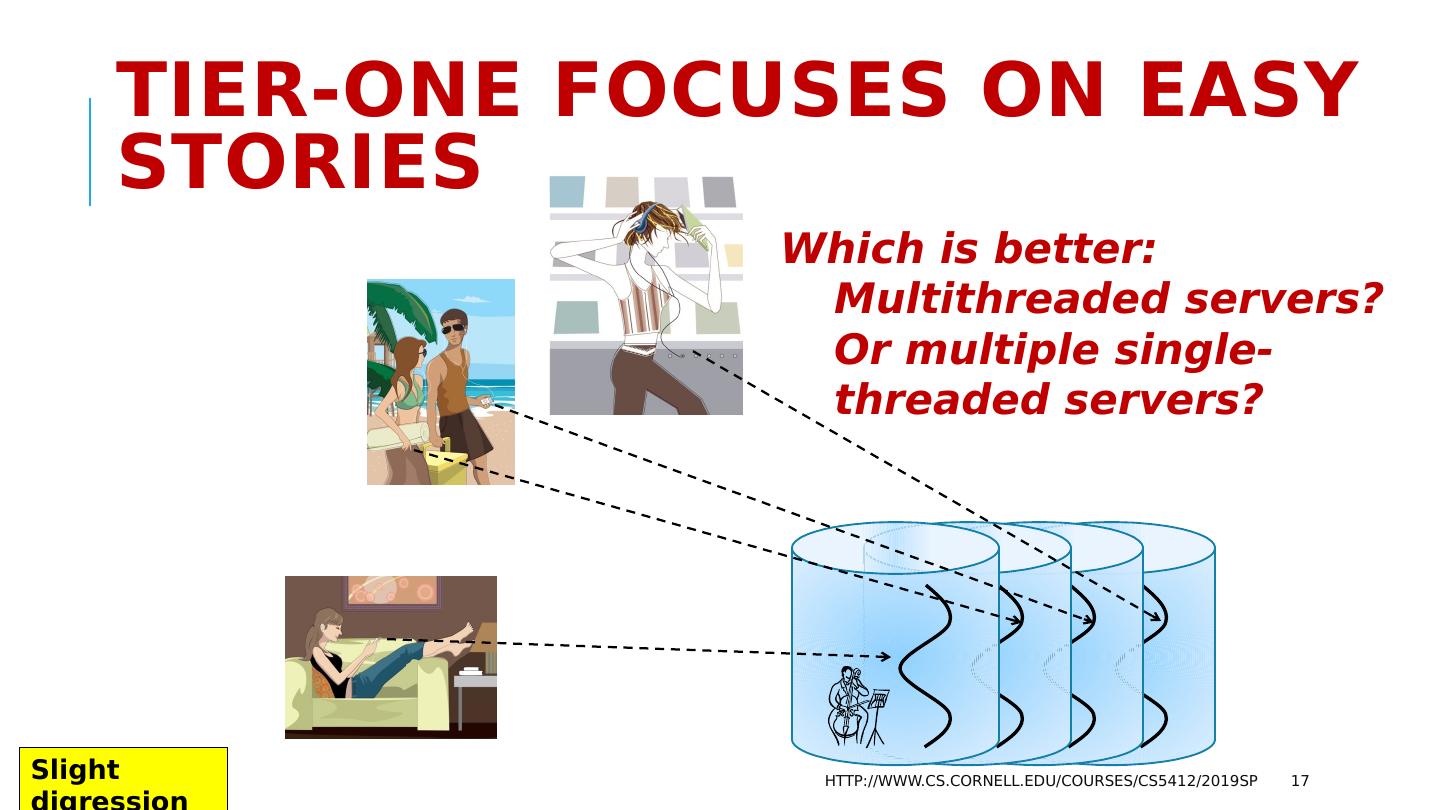
17 .Tier-One focuses on easy stories Which is better: Multithreaded servers? Or multiple single-threaded servers? http://www.cs.cornell.edu/courses/cs5412/2019sp 17 Slight digression
18 .What you learned in O/S course Probably, you just took a class where the big focus was concurrency and threaded programs, and probably they taught you to go for multithreading The story you heard was something like this: Because of Moore’s law, modern computers are NUMA multiprocessors. To leverage that power, create lots of threads, link with a library like “ pthreads ”, and request that your program be allocated multiple cores. Use thread synchronization/critical sections to ensure correctness. http://www.cs.cornell.edu/courses/cs5412/2019sp 18 Slight digression
19 .But is this the right choice? First, we should identify other design options, even ones that look dumb at first glance. Then we can evaluate based on a variety of considerations: Expected speed and scaling (more is good) Complexity of the solution (more is bad) Cost of the solution (more is bad) http://www.cs.cornell.edu/courses/cs5412/2019sp 19
20 .What you learned in O/S course Another thing you learned about was the virtual machine approach. With true virtualization, programs run on private virtual machines. Today, a recent alternative is “containers”, which give the illusion of a private virtual machine in a Linux process address space, not a true VM. http://www.cs.cornell.edu/courses/cs5412/2019sp 20 Slight digression
21 .… even our “easy” cloud poses choices! Are those threads? … Linux processes? … virtual machines? … Linux containers? http://www.cs.cornell.edu/courses/cs5412/2019sp 21 Are those threads? Slight digression
22 .How would you decide between them? Basically, we have four options: Keep my server busy by running one multithreaded application on it Keep it busy by running N unthreaded versions of my application as virtual machines, sharing the hardware Keep it busy by running N side by side processes, but don’t virtualize Keep it busy by running N side by side processes using containers http://www.cs.cornell.edu/courses/cs5412/2019sp 22 Slight digression
23 .Choices as a table Option Speed Complexity Costs Multithreaded server Poor Poor Development: expensive. Use of resources: best. But may be hard to administer. Single-thread + VM Poor Good Inexpensive development, but inefficient use of memory resources, high overheads Single-threaded process model Very good if interference can be avoided Least complex! Inexpensive development, but administering to ensure that the processes won’t somehow interfere can be tricky. Single-threaded, containers Best of all. Just like a single-threaded process model. Inexpensive development. T he approach helps by protecting containerized apps from most forms of interference . http://www.cs.cornell.edu/courses/cs5412/2019sp 23 Slight digression
24 .Why container model “wins”… We want the edge of the cloud to be as cost-effective as possible. Development and management complexity is one kind of cost. Also think about CPU load, memory, and context switching overheads: Best would be a single program with multiple threads Containers offer isolation and can share code pages, saving memory http://www.cs.cornell.edu/courses/cs5412/2019sp 24 Slight digression
25 .Slight digression Why doesn’t a multi-threaded solution perform best? This is almost always a surprise to CS5412 students. To appreciate the issue, we need to understand more about modern server hardware Early days of the web were before we fell off Moore’s curve. Today’s servers are NUMA machines with many cores. 32-core Intel Aubrey chip. Some servers have as many as 128 cores today! 25 http://www.cs.cornell.edu/courses/cs5412/2019sp
26 .NUMA architecture A NUMA computer is really a small rack of computers on a chip Each has its own L2 cache, and small groups of them share DRAM. With, say, 12 cores you might have 4 DRAM modules serving 3 each. Accessing your nearby DRAM is rapid Accessing the other DRAM modules is much slower, 15x or more NUMA hardware provides cache consistency and locking, but costs can be quite high if these features have much work to do. http://www.cs.cornell.edu/courses/cs5412/2019sp 26 Slight digression
27 .Multithreading on a NUMA. On a NUMA architecture, many threaded programs slow down on > 1 cores! Many reasons: Locking and NUMA memory coherency, Weak control over “placement” (which memory is on which DRAM?), Higher scheduling delays, Issues of reduced L2 cache hit rate http://www.cs.cornell.edu/courses/cs5412/2019sp 27 Slight digression
28 .Deep Dive On that Question What about true virtualization? In effect, we will have perhaps 12 VMs. Our programs might still have threads, but we will mostly use just one core per program (or per VM) Now we won’t have memory contention: each program is isolated. On the other hand, we use more memory, because sharing is harder. But the virtualization layer causes page-table translation slowdown, and I/O operations might also be slower. DMA might not work. http://www.cs.cornell.edu/courses/cs5412/2019sp 28 Slight digression
29 .Containers Win! http://www.cs.cornell.edu/courses/cs5412/2019sp 29 A container is a normal Linux process with a library that mimics a full VM. The system looks “private” but without full virtualization. Eliminates the 10% or so performance overheads seen with true VMs. Also, containers launch and shut down much faster than a full VM, because we don’t need to load the whole OS. We won’t see NUMA memory contention problems. Security and “isolation” are nearly as good as for VMs. Popular options? Kubenetes and Docker. Slight digression
3秒后跳转登录页面
去登陆

