









































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
11-Geoscale Computing
如果您依赖云,那么显然您需要您的云可靠。然而数据中心确实失败了。可用区域是一组2个或3个并排的云数据中心,供应商管理这些数据中心以确保(如果可能)最多1个将随时关闭。由于距离非常小,因此延迟与数据中心内延迟类似。
当数据中心位于很远的距离时,甚至可能是全局的,都会出现WAN复制。即使在这种规模下,我们仍然可以进行强大的一致性数据复制。
展开查看详情
1 .CS5412/Lecture 11 The GeoScale Cloud Ken Birman CS5412 Spring 2019 http://www.cs.cornell.edu/courses/cs5412/2019sp 1
2 .Beyond the datacenter Although we saw a picture of Facebook’s global blob service, we have talked entirely about technologies used inside a single datacenter. How do cloud developers approach global-scale application design? Today we will discuss “ georeplication ” and look at some solutions. http://www.cs.cornell.edu/courses/cs5412/2019sp 2
3 .Where to start? Availability Zones Companies like Amazon and Microsoft faced a problem early in the cloud build-out: servicing a data center can require turning it off! Why? Some hardware components are too critical to service while active, like the datacenter power and cooling systems, or the “spine” of routers. Some software components can’t easily be upgraded while running, like the datacenter management system. In fact there is a very long list of cases like these http://www.cs.cornell.edu/courses/cs5412/2019sp 3
4 .Availability zones So… they decided that instead of building one massive datacenter, they would put two or even three side by side. When all are active, they spread load over them, so everything stays busy. But this also gives them an option for shutting one down entirely to do upgrades (and with three, they would still be able to “tolerate” a major equipment failure in one of the two others). http://www.cs.cornell.edu/courses/cs5412/2019sp 4
5 .Availability Zones – Amazon AWS AWS Edge is less capable The AWS “region” has an availability zone structure http://www.cs.cornell.edu/courses/cs5412/2019sp 5
6 .Availability Zones – Microsoft Azure Notice the blue circles. Those are regions with three zones. http://www.cs.cornell.edu/courses/cs5412/2019sp 6
7 .Models for high-availability Replication Within a datacenter you can just make TCP connections and build your own chain replication solution, or download Derecho and configure it. But communication between datacenters is tricky for several reasons. Those same approaches might not work well, or perhaps not at all. http://www.cs.cornell.edu/courses/cs5412/2019sp 7
8 .Connectivity limitations Every datacenter has a firewall forming a very secure perimeter: applications cannot pass data through it without following the proper rules. Zone-redundant services are provided by AWS and Azure and others to help you mirror data across zones, or even communicate from your service in Zone A to a “sibling” in Zone B. Direct connections via TCP would probably be blocked: it is easy to connect into a datacenter but hard to connect out from inside! http://www.cs.cornell.edu/courses/cs5412/2019sp 8
9 .Why do they restrict outgoing TCP? The modern datacenter network can have millions of IP addresses inside each single datacenter. But these won’t actually be unique IP addresses if you compare across different data centers: the addresses only make sense within a zone. Thus a computer in datacenter A often would not have an IP address visible to a computer in datacenter B, blocking connectivity! http://www.cs.cornell.edu/courses/cs5412/2019sp 9
10 .How does a browser overcome this? Your browser is on the public internet, not internal to a datacenter. So it sends a TCP connect request to the datacenter over one of a small set of datacenter IP addresses covering the full datacenter. AWS, which hosts for many other sites, has a few IP addresses per site. Some systems mimic this approach, others have their own ways of ensuring that traffic to Acme.com gets to Acme’s servers, even if hosted on their framework. http://www.cs.cornell.edu/courses/cs5412/2019sp 10
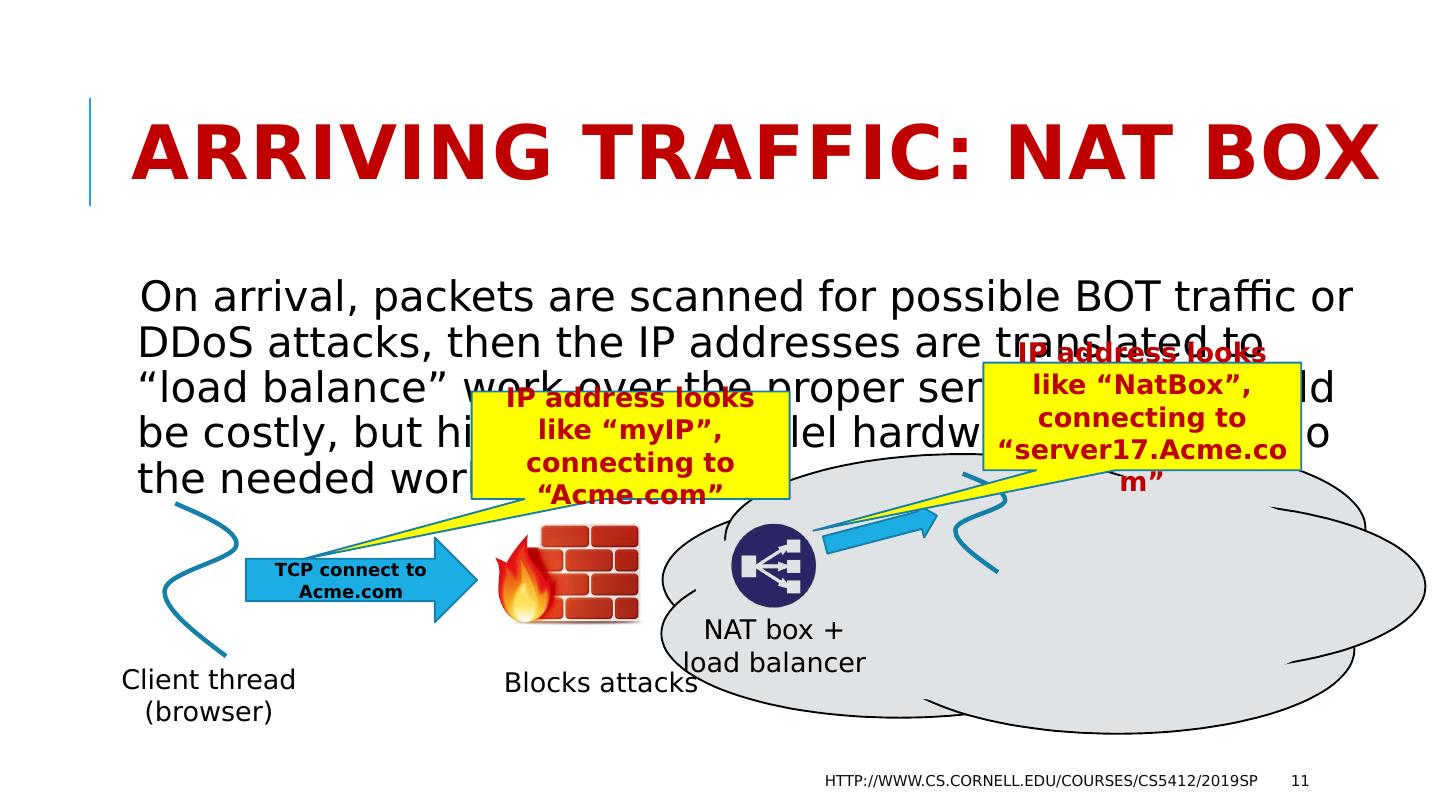
11 .Arriving traffic: NAT Box On arrival, packets are scanned for possible BOT traffic or DDoS attacks, then the IP addresses are translated to “load balance” work over the proper servers. This would be costly, but high-speed parallel hardware is used to do the needed work at line rates. http://www.cs.cornell.edu/courses/cs5412/2019sp 11 TCP connect to Acme.com Blocks attacks NAT box + load balancer Client thread (browser) IP address looks like “ myIP ”, connecting to “Acme.com” IP address looks like “ NatBox ”, connecting to “server17.Acme.com”
12 .How does it pull this trick off? The NAT box maintains a table of “internal IP addresses (and port numbers) and the matching “external” ones. As messages arrive, if they are TCP traffic, it does a table lookup and substitution, then adjusts the packet header to correct the checksum. Thus “server17.Acme.com” cannot be accessed directly and yet your messages are routed to it, and vice versa. http://www.cs.cornell.edu/courses/cs5412/2019sp 12
13 .But with GeoReplication , this blocks your code from connecting to itself If you have machine A.Acme.com inside AWS or Azure, and then try to connect to B.Acme.com, it works inside a single datacenter. In fact you will be running in an “ enterprice VLAN” or “VPC”: what seems to be a private cloud. If you were to launch Ethereal or a similar sniffer you only see traffic from your own machines, not traffic from other datacenter tenants. But if B was in a different datacenter, the connection simply won’t work. Both A and B are behind NAT boxes, so neither can see the other! http://www.cs.cornell.edu/courses/cs5412/2019sp 13
14 .OptioNs ? Some vendors do offer ways to make an A-B connection across datacenters in the same region (availability zone). You need to use a special library they provide and otherwise, the connection would fail. And they charge for this service. More common is to use some existing “Zone-aware” service http://www.cs.cornell.edu/courses/cs5412/2019sp 14
15 .Zone Aware Services on Azure Linux Virtual Machines Windows Virtual Machines Virtual Machine Scale Sets Managed Disks Load Balancer Public IP address Zone-redundant storage SQL Database Event Hubs Service Bus VPN Gateway ExpressRoute Application Gateway http://www.cs.cornell.edu/courses/cs5412/2019sp 15
16 .A few worth noting Zone-aware storage is a storage mirroring option. Files written in zone A would be available as read-only replicas in zone B. B sees them as a read-only file volume under path /Zone/A/… This is a very common way to share information between data centers. http://www.cs.cornell.edu/courses/cs5412/2019sp 16
17 .A Few Worth Noting The Azure Service Bus in its “Premium” configuration This is a message bus used by services within your VPC to communicate. Azure offers a configuration that automatically transfers data across zones under your control. Again, you need to follow their instructions to set it up. They charge but the performance and rate have historically favored this model. Basically, two queues hold messages, and then they use a set of side by side TCP connections to shuttle data in both directions. Very efficient! 17
18 .A Few Worth Noting Azure’s zone-redundant virtual network gateway Used when you really do want a connection of your own, via TCP Setup is fairly sophisticated but they walk you through it. In effect, creates a special “pseudo-public” IP address for your services, which can then connect to each other. Not visible to other external users But performance might be balky: this isn’t their most performant option. And they charge by the megabyte transferred over the links. http://www.cs.cornell.edu/courses/cs5412/2019sp 18
19 .Heavy tailed Latency A big concern with georeplication is erratic delays. Within an availability zone, the issue is minimal: the networks are short (maybe blocks, maybe a few miles), so latencies are tiny. But with global WAN links, latencies can be huge and variation grows. Mean delay from New York to London: 90ms Mean delay from New York to Tokyo: 103ms http://www.cs.cornell.edu/courses/cs5412/2019sp 19
20 .Heavy Tailed Latency Studies reveal “ Zipf ” latency distributions Most traffic gets through very quickly But some traffic takes extremely long. We say that these distributions are heavy- tailed if the “very slow” traffic adds up to a substantial portion of the total traffic. http://www.cs.cornell.edu/courses/cs5412/2019sp 20 Zipf’s law The number of events in the i’th popularity bin is proportional to
21 .Issue this raises In protocols like Paxos , would we want to wait for all sites to respond, or just a quorum? Seemingly, a quorum is far better. On the other hand, perhaps we would want all sites within an availability zone, but then wouldn’t need to wait for geo-replicas to respond? Leads to a three-level concept of Paxos stability. Locally stable in datacenter… Availability-zone stable… WAN stable http://www.cs.cornell.edu/courses/cs5412/2019sp 21
22 .What have experiments shown? Basically, Paxos performs poorly with high, erratic latencies. A big issue is that delay isn’t symmetric: The path from Zone A to Zone B might be slow Yet the path from Zone B to Zone A could be fast at that same instant. So the outgoing proposals experience one set of delays, and replies from Paxos members experience different delays. You end up waiting “for everyone” http://www.cs.cornell.edu/courses/cs5412/2019sp 22
23 .Google Spanner Idea: T rue T ime Google uses actual time as a way to build an asynchronous totally ordered data replication solution called Spanner. Google TrueTime is a global time service that uses atomic clocks together with GPS-based clocks to issue timestamps with the following guarantee: For any two timestamps, T and T’ If T’ was fully generated before generation of T started, Then T > T’ http://www.cs.cornell.edu/courses/cs5412/2019sp 23
24 .Why such a tortured definition? With the guarantee they offer, if some operation B was timestamped T, and could possibly have seen the effects of operation A with timestamp T’, then we can order B and A so that A occurs before B. The full API is very elegant and simple: TT.now (), TT.before (), TT.after (). TT.now () returns a range from TT.before () to TT.after (). The basic guarantee is that the true time is definitely in the range TT.now (). TT.before () is definitely a past time, and TT.after () is definitely in the future. http://www.cs.cornell.edu/courses/cs5412/2019sp 24
25 .Implementing T rue T ime Google starts with a basic observation: Suppose clocks are synchronized to precision It is 10:00.000 on my clock, and someone wants to run transaction X. What is the largest possible timestamp any zone could have issued? My clock could be slow, and some other clock could be fast. So the largest (worst case) possible will be T+2 http://www.cs.cornell.edu/courses/cs5412/2019sp 25
26 .Minimizing Google uses a mix of atomic clocks and GPS synchronization for this. They synchronize against the mix every 30s, then might drift in between. GPS can be corrected for various factors, including Einstein’s relativistic time dilation, and they take those steps. In the end their value of is quite small (0-6ms). So at actual time 10am, transaction X might get a TT.after () timestamp like (10:00.006, zone-id, uid ). The zone id and uid are to break ties. http://www.cs.cornell.edu/courses/cs5412/2019sp 26
27 .Spanner’s use of True Time Spanner is a transactional database system (in fact using a key-value structure, but that won’t matter today). Any application worldwide can generate a timestamped Spanner transaction. These are relayed over the Google version message services. Their service delivers messages from Zone X to Zone Y in timestamp order. http://www.cs.cornell.edu/courses/cs5412/2019sp 27
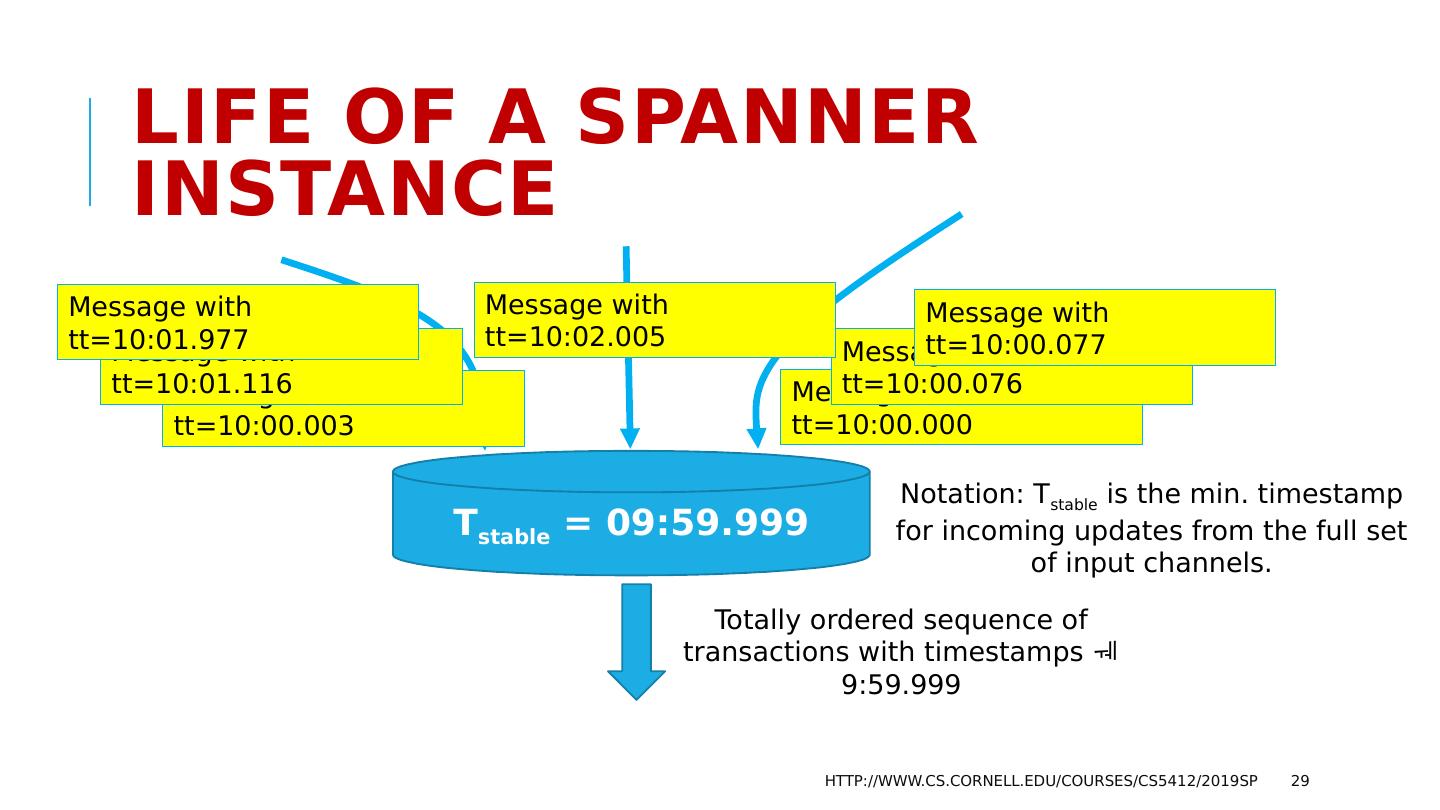
28 .Life of a Spanner Instance Spanner has connections to perhaps hundreds of remote zones. Transactions flow in on these connections, and it stores them until every zone has sent some transaction with a timestamp of value T stable or larger. Then it can apply all transactions with timestamps T stable , in order. http://www.cs.cornell.edu/courses/cs5412/2019sp 28
29 .Life of a Spanner instance http://www.cs.cornell.edu/courses/cs5412/2019sp 29 Notation: T stable is the min. timestamp for incoming updates from the full set of input channels. Message with tt =10:00.000 Message with tt =10:00.076 Message with tt =10:00.077 Message with tt =10:00.003 Message with tt =10:01.116 Message with tt =10:01.977 Message with tt =10:02.005 T stable = 09:59.999 Totally ordered sequence of transactions with timestamps 9:59.999
3秒后跳转登录页面
去登陆

