




























- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
04-功能与微服务
简而言之,尽管可能以您喜欢的任何方式实现任何应用程序,但这不是Azure的智能用途,并且会导致性能问题或其他类型的问题。正确的方法是使用函数进行非常简短的操作,只需查询状态或触发带外更新。我们将使用微服务,其中计算方面较重,并且可能存在随时间变化的重要状态。
展开查看详情
1 .CS5412: Lecture 8 implementing a smart Farm Ken Birman Spring, 2018 http://www.cs.cornell.edu/courses/cs5412/2018sp 1
2 .Microsoft FarmBeats Quick reminder of some smart farming ideas: Drones that would survey fields and help with intelligent decisions about seed choices, irrigation, fertilizers, pesticide/fungicide use, etc. BlockChain style audit trails of actions in dairy or similar situations Real-time monitoring of animal health and related tasks, like milking Systems to recycle farm waste into useful products like bio-oil Maybe a “smart calendar” for the farmer’s wall, showing upcoming tasks, explaining the reasoning, like an iPad but for the farm http://www.cs.cornell.edu/courses/cs5412/2019sp 2
3 .Intelligence roles The intelligence takes many forms here, even just in the drones How can program drones to employ optimal search patterns? How should the drone’s battery power be managed? Can we leverage wind to “sail” and reduce consumption? Which crops to photograph, and from what angle, and how close? Are there signs of a problem? Should we get more data? Which photos to upload, and which to save, and which can be deleted? http://www.cs.cornell.edu/courses/cs5412/2019sp 3
4 .How to make an intelligent decision? In a machine-learning setting, we need to start by creating a model! So, offline , a research team develops a “theory” that matches the intended behavior very closely. Like a set of equations describing smart drone overflights of a field, and choices the drone makes as it flies. Next, we collect a huge amount of sample data and label it with the desired choices we would want the system to make under those conditions. http://www.cs.cornell.edu/courses/cs5412/2019sp 4
5 .Training a model With our data and labels and model, we can now select a machine-learning technology matched to the setting. For example, perhaps we settle on a convolutional neural network, or a parameterized Bayesian belief graph, or some other standard option. With our data, we can train the model: we compute a set of parameters that will lead the model to “generate” the desired behavior. http://www.cs.cornell.edu/courses/cs5412/2019sp 5
6 .There are a lot of technicalities! For example, we often need to augment our data with synthetic data to ensure that the model sees a sufficiently broad set of examples. If the model itself wasn’t rich enough, it won’t converge to an acceptable solution, and we might need to refine the model. When finished, our model might not be able to make ideal choices in every case, but hopefully it does well enough to justify “field trials”. http://www.cs.cornell.edu/courses/cs5412/2019sp 6
7 .What does this model look like? The model we would want to run on our drones consists of: Code that takes input data, identical in style to our training data The equations, implemented in a language like Tensor Flow or SciPy The parameters that were obtained from the training process. This will be a set of tensors: big files containing numerical data, perhaps gigabytes in size (even this assumes some form of compression) http://www.cs.cornell.edu/courses/cs5412/2019sp 7
8 .But such a model will be “general” We can definitely train drones to overly “any field”, given its boundaries and a topographic map. But any specific field will have all sorts of unique characteristics. So FarmBeats will need to adapt its plans dynamically and might even need to learn dynamically (to learn things about this specific field) in order to do the best job! And we won’t have time to do this offline! http://www.cs.cornell.edu/courses/cs5412/2019sp 8
9 .Where does training occur? The offline training involves “big data analytics” and need to be done on massive data centers with huge compute and storage resources. In fact we will discuss this topic later in the course, in the last few lectures. But the dynamic form of learning needs to occur in real-time, closer to the edge. Since the drone itself lacks compute resources, this would be on a cluster of computers “near” the farm. Maybe, in that nice blue truck. http://www.cs.cornell.edu/courses/cs5412/2019sp 9
10 .Dynamic Updates What would be examples of dynamic updates? The drones will discover today’s wind patterns and output a learned model that they steadily refine as they scan the field. The drones may discover a very dry area, or a muddy one. Crop issues in that whole area would probably be associated with irrigation issues, even if they “show up” as brown spots, or as fungal breakouts on the leaves. http://www.cs.cornell.edu/courses/cs5412/2019sp 10
11 .Using Dynamic Updates to update plans With dynamically learned updates, a control system might realize that it can triple battery lifetime by switching to a new drone flight plan that sails on the breezes in a particular way. So here we would have a system that recomputes the flight plan, uploads the new plans (but without activating them), then tells all the drones to pause briefly, then allows all to start using the new plans. Question: Why upload, then pause, and only then switch to the new plan ? http://www.cs.cornell.edu/courses/cs5412/2019sp 11
12 .… because we prefer not to see this! http://www.cs.cornell.edu/courses/cs5412/2019sp 12 Still using search plan A Starting to use search plan B
13 .Functions? Or -Services? We actually could implement everything as a giant state machine with a large amount of state in our Azure key-value store. But would that be the best plan? It might be very hard to debug such a complex function application. The logic itself might be very complicated, especially since everything will be event driven. As we “learn current conditions” we run into a big-data problem. A function server isn’t intended for such cases. http://www.cs.cornell.edu/courses/cs5412/2018sp 13
14 .Should everything be in -Services? Historically this was the most popular approach. But we end up with ultra-specialized services, and they run all the time, so they might not be very cost-effective. The nice feature of the function model is that it offers such a simple way to handle large numbers of events elastically. http://www.cs.cornell.edu/courses/cs5412/2018sp 14
15 .Approach this leads towards Use the functions for “lightweight” tasks and actions Ideal for read-only actions like making a quick decision OK for reporting events that go into some kind of record or log But don’t use functions for serious computing. Then build new -services for the heavy-weight tasks, like learning a new machine-learned model, or computing the optimal search path with wind. http://www.cs.cornell.edu/courses/cs5412/2018sp 15
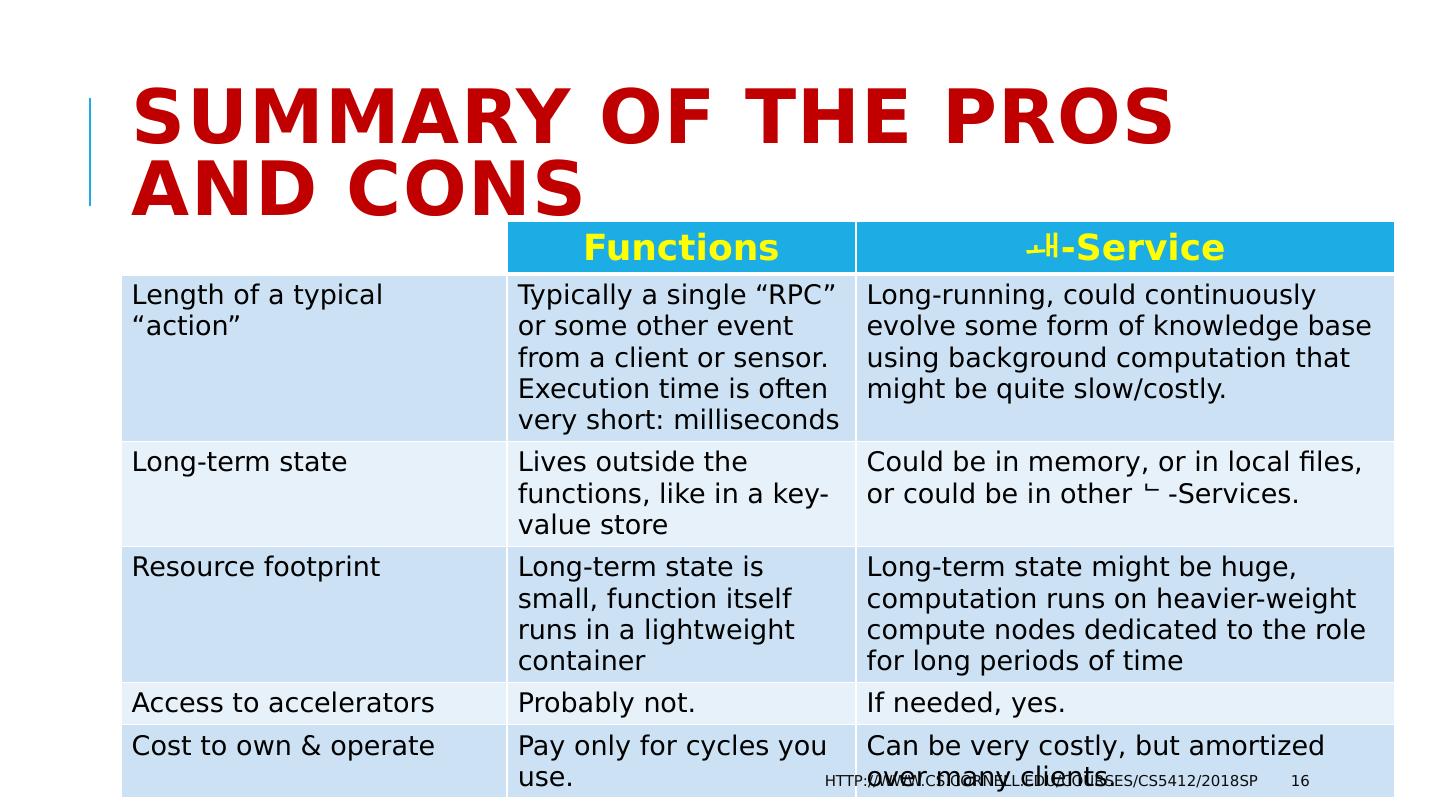
16 .Summary of the pros and cons Functions -Service Length of a typical “action” Typically a single “RPC” or some other event from a client or sensor. Execution time is often very short: milliseconds Long-running, could continuously evolve some form of knowledge base using background computation that might be quite slow/costly. Long-term state Lives outside the functions, like in a key-value store Could be in memory, or in local files, or could be in other -Services. Resource footprint Long-term state is small, function itself runs in a lightweight container Long-term state might be huge, computation runs on heavier-weight compute nodes dedicated to the role for long periods of time Access to accelerators Probably not. If needed, yes. Cost to own & operate Pay only for cycles you use. Can be very costly, but amortized over many clients. http://www.cs.cornell.edu/courses/cs5412/2018sp 16
17 .How to create new functions Register the corresponding event (or class of events). Tell the function server to run your container for the specific events it will handle. Develop code using cloud-vendor supplied tool that will provide a skeleton. You might write just a few lines to specialize it for your events. http://www.cs.cornell.edu/courses/cs5412/2018sp 17
18 .How to create new -Services? Architecture can be fairly complex, so you’ll start by really thinking hard about functionality, data representations, API. Many services have a non-trivial internal structure: a top-level group but with several subgroups inside it, playing distinct roles. Usually developed on a cluster of Linux servers using libraries that help with hard aspects. http://www.cs.cornell.edu/courses/cs5412/2018sp 18
19 .How to create new -Services? We can start with Jim Gray’s suggestion: key-value sharding from the outset. Within a shard, data will need to be replicated. This leads to what is called the “state machine replication model”, which involves A group of replicas (and a membership service to track the set) Each update occurs as a message delivered to all replicas The updates are in the identical order No matter what happens (failures, restarts) “amnesia” won’t occur. http://www.cs.cornell.edu/courses/cs5412/2018sp 19
20 .Will this scale? Jim Gray’s analysis told us that general database transactions won’t scale. But this simple key-value approach would scale very well provided that updates and queries run on a single shard at a time. This was a sweet spot in Jim’s model. http://www.cs.cornell.edu/courses/cs5412/2018sp 20
21 .So, back to our FarmBeats Drones http://www.cs.cornell.edu/courses/cs5412/2018sp 21 Azure Function Server Functions: Lightweight, event-triggered programs in containers, “pay for what you use” resource model Message bus or queue -Services: some Azure provided, some “new”
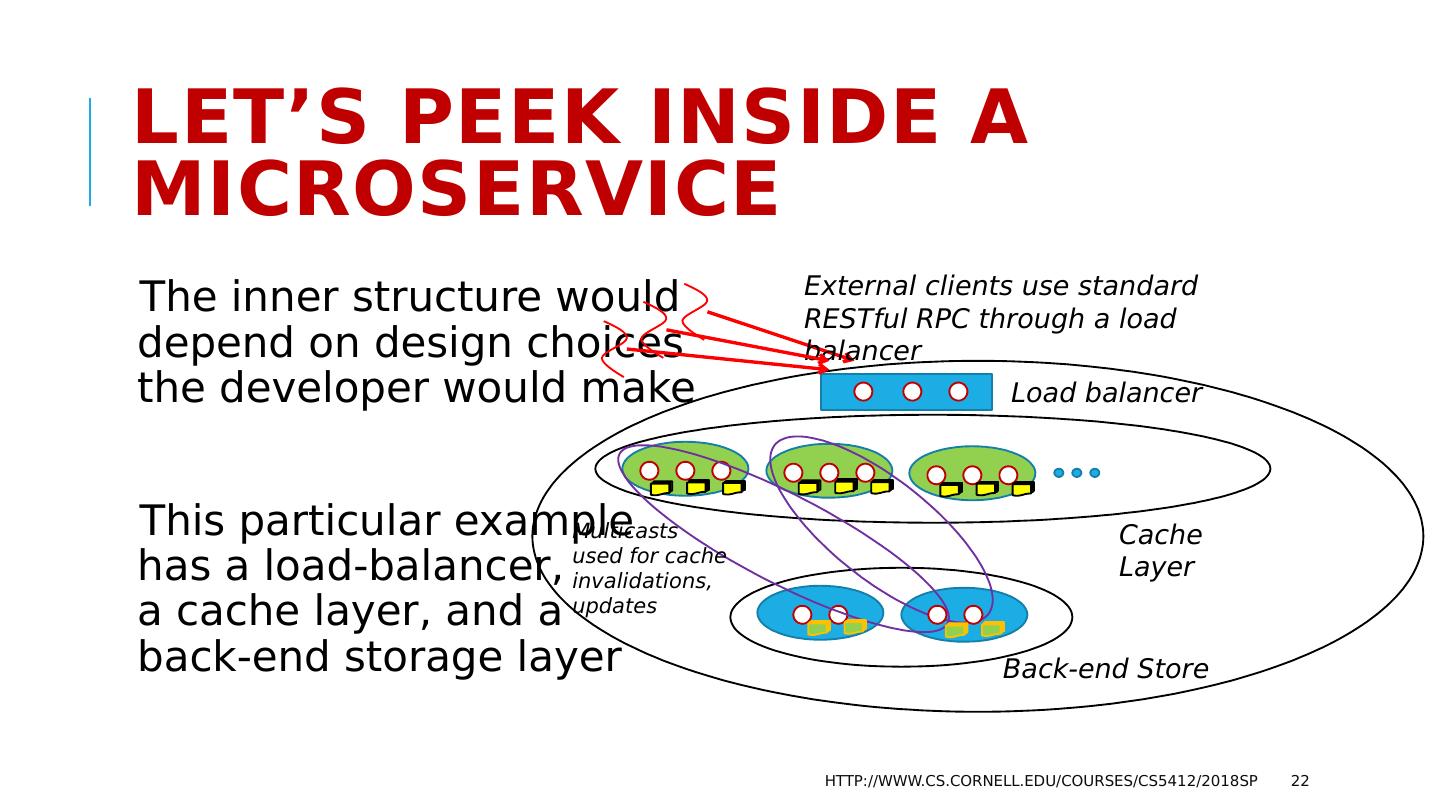
22 .Let’s peek inside a microservice The inner structure would depend on design choices the developer would make This particular example has a load-balancer, a cache layer, and a back-end storage layer http://www.cs.cornell.edu/courses/cs5412/2018sp 22 Cache Layer Back-end Store Multicasts used for cache invalidations, updates Load balancer External clients use standard RESTful RPC through a load balancer
23 .A -Service might be hard to build! The solution needs to restart into this configuration after failures, handle process crashes or reboots of individual components. Data has to be stored and reloaded from files (or other - services) We need to manage the service in a consistent manner and program it to self-repair after a crash or disruption. http://www.cs.cornell.edu/courses/cs5412/2018sp 23
24 .This is a situation where Derecho can help Derecho is Cornell’s software library for automating those kinds of tasks. The design was created with “intelligent edge” use cases in mind. The developer would attach event handlers in various places, and Derecho automates the remainder of the “life cycle” This greatly simplifies the development challenge http://www.cs.cornell.edu/courses/cs5412/2018sp 24
25 .How might we tackle the cases mentioned earlier? Consider one example: “Image analysis: “Are these plants healthy or diseased?” How might we solve such a problem using modern machine learning? How would we turn our solution into a -service? How would a function in a function server interact with it? http://www.cs.cornell.edu/courses/cs5412/2018sp 25
26 .Image knowledge base We could start with labeled data: photos from drones that are hand-labeled to tag crop damage and identify possible causes. Use this to train a computer-vision model (perhaps, a convolutional neural network – a CNN). The resulting models will be large tensors. Copy them to our -service. http://www.cs.cornell.edu/courses/cs5412/2018sp 26
27 .Image knowledge We might have two cases: one for initial thumbnail images (small, low-resolution) and a second for follow-up detail imaging (ultra-high resolution) Now our -service could have an API with operations such as “classify new thumbnail”, “analyze follow-up imagery”. The function server would take a drone event and just turn around and make a call into the -service http://www.cs.cornell.edu/courses/cs5412/2018sp 27
28 .Secondary actions The -service would then be able to “tell” the function what action to take. This avoids having to talk directly to the drones: the functions become specialists in drone operations, while the -service plays general roles. Similarly for requesting “ followup detail”: the -service can request this in its reply to the function layer, and then the function would turn to the -service that plans detailed imaging studies for advice on camera angles and image settings to use. Functions aren’t doing much, but they glue the heavy lifters together. http://www.cs.cornell.edu/courses/cs5412/2018sp 28
3秒后跳转登录页面
去登陆

