













































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
10-容错:深度研究
容错概念。裂脑概念......使用复制的持久数据进行“无状态”计算。状态机复制。链复制。
展开查看详情
1 .CS5412 / Lecture 10 Replication and Consistency Ken Birman Spring, 2019 http://www.cs.cornell.edu/courses/cs5412/2018sp 1
2 .Tasks that require Consistent Replication Copying programs to machines that will run them, or entire virtual machines. Replication of configuration parameters and input settings. Copying patches or other updates. Replication for fault-tolerance, within the datacenter or at geographic scale. Replication so that a large set of first-tier systems have local copies of data needed to rapidly respond to requests Replication for parallel processing in the back-end layer. Data exchanged in the “shuffle/merge” phase of MapReduce Interaction between members of a group of tasks that need to coordinate Locking Leader selection and disseminating decisions back to the other members Barrier coordination http://www.cs.cornell.edu/courses/cs5412/2018sp 2
3 .Chain Replication A common approach is “chain replication”, used to make copies of application data in a small group. We form our group into a chain and send updates to the head. The updates transit node by node to the tail, and only then are they applied: first at the tail, then node by node back to the head. Queries are always sent to the tail of the chain: it is the most up to date. http://www.cs.cornell.edu/courses/cs5412/2018sp 3 A (head) B C (tail) Update Ok: Do It Update Update
4 .Frameworks like Derecho support much fancier uses We listed a set of roles, like managing the “layout” of a complex -service, orchestrating self-repair after a crash, mapping updates to RDMA. But how can we understand the associated computing model? In today’s lecture we explore this and some related models. http://www.cs.cornell.edu/courses/cs5412/2018sp 4 -service built using Derecho, showing subgroups, two of which are sharded .
5 .Membership Management: One need Automates tasks such as tracking which computers are in the service, what roles have been assigned to them. May also be integrated with fault monitoring, management of configuration data (and ways to update the configuration). Often has a notification mechanism to report on changes http://www.cs.cornell.edu/courses/cs5412/2018sp 5
6 .State Machine Replication Model We’ve seen it a few times since Lecture 2, but let’s be more detailed. Take some set of machines that are initially in identical states. Run a deterministic program on them. If we present updates in identical order, the replicas remain in the same state. This is a very general way to describe replicating a log or a file or a database, coordinating reactions when some event happens in a fog computing setting, locking and barrier synchronization, etc. http://www.cs.cornell.edu/courses/cs5412/2018sp 6 Leslie Lamport
7 .Building an “SMR” solution Leslie proposed several solutions over many years. His very first protocol assumed that the shard membership is fixed and no failures occur, and used a two-phase commit with a cute trick to put requests into order even if updates were issued concurrently. http://www.cs.cornell.edu/courses/cs5412/2018sp 7
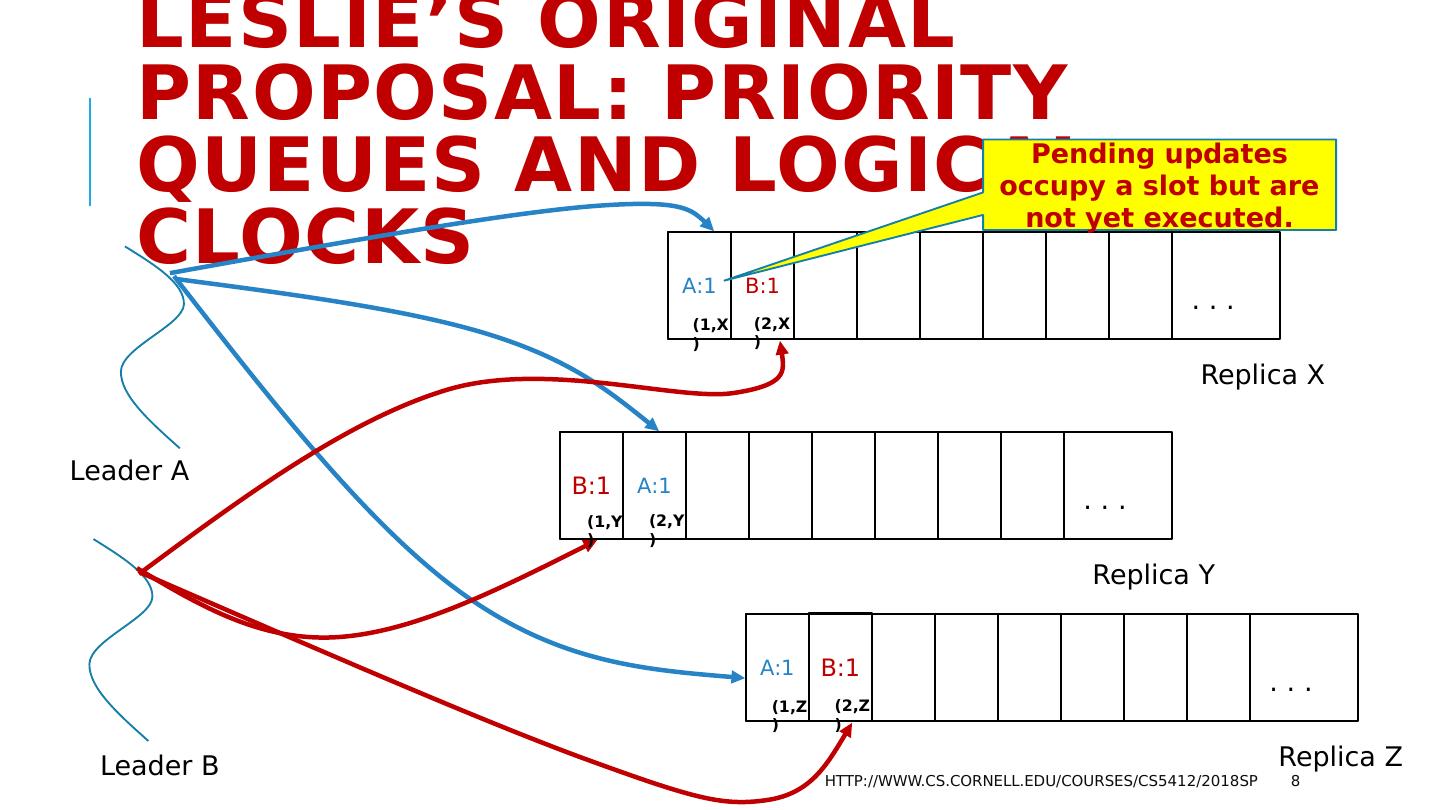
8 .Leslie’s original proposal: Priority Queues and Logical Clocks http://www.cs.cornell.edu/courses/cs5412/2018sp 8 Leader A Leader B A:1 B:1 . . . Replica X B:1 A:1 . . . Replica Y A:1 B:1 . . . Replica Z (1,X) (2,X) (1,Y) (2,Y) (1,Z) (2,Z) Pending updates occupy a slot but are not yet executed.
9 .Lamport’s rule: Leader sends proposed message. Receivers timestamp the message with a logical clock, insert to a priority queue and reply with (timestamp, receiver-id). For example: A:1 was put into slots {(1,X), (2,Y), (1,Z)} B:1 was put into slots {(2,X), (1,Y), (2,Z)} Leaders now compute the maximum by timestamp, breaking ties with ID. http://www.cs.cornell.edu/courses/cs5412/2018sp 9
10 .Lamport’s protocol, second phase Now Leaders send the “commit times” they computed Receivers reorder their priority queues Receivers deliver committed messages, from the front of the queue http://www.cs.cornell.edu/courses/cs5412/2018sp 10
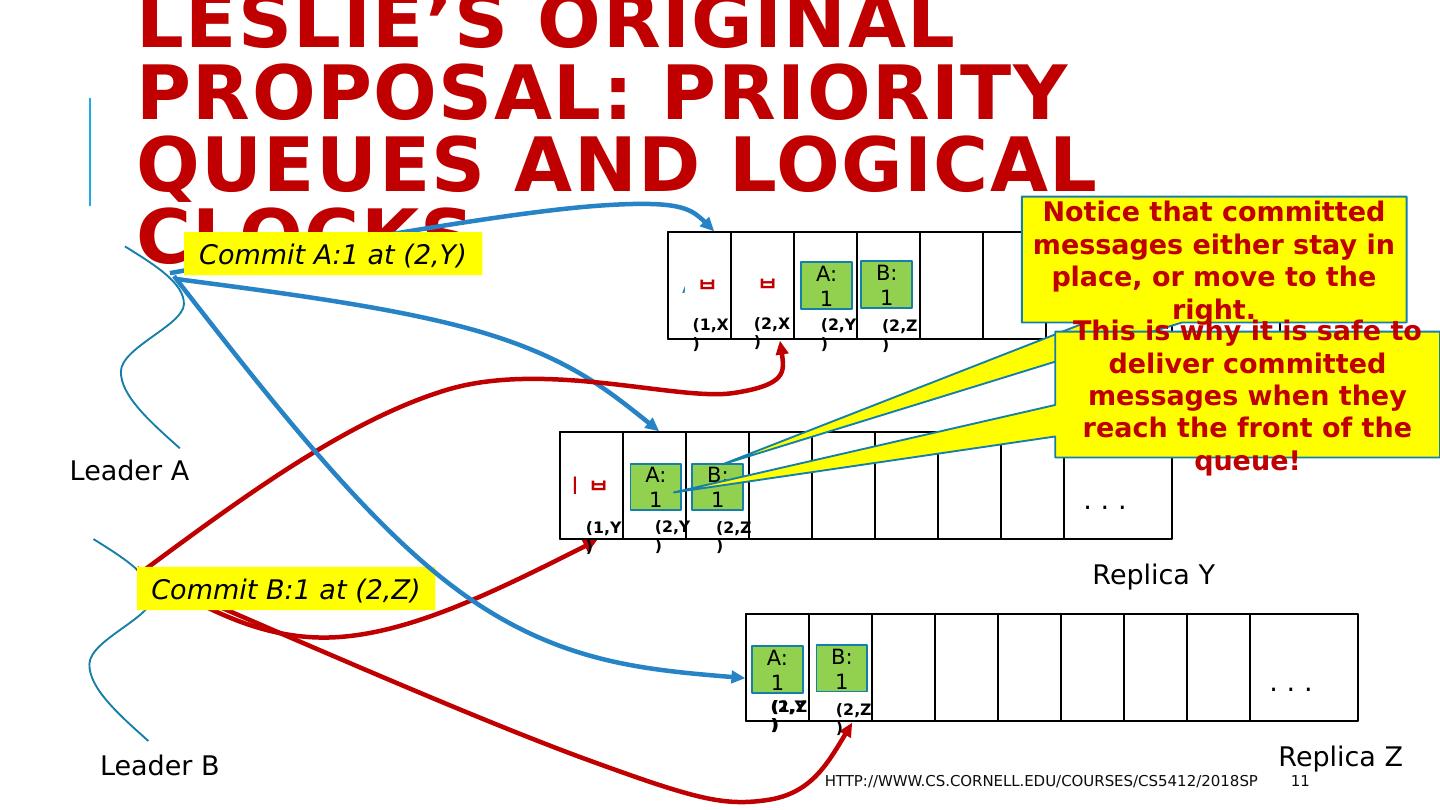
11 .Leslie’s original proposal: Priority Queues and Logical Clocks http://www.cs.cornell.edu/courses/cs5412/2018sp 11 Leader A Leader B A:1 B:1 . . . Replica X B:1 A:1 . . . Replica Y A:1 B:1 . . . Replica Z Commit A:1 at (2,Y) Commit B:1 at (2,Z) A:1 A:1 A:1 B:1 B:1 B:1 Notice that committed messages either stay in place, or move to the right. This is why it is safe to deliver committed messages when they reach the front of the queue! (2,Y) (2,Z) (2,Y) (2,Z) (2,Y) (2,Z) (1,X) (2,X) (1,Y) (1,Z)
12 .Is this a “good” SMR protocol? The 2-phase approach works well for a totally ordered atomic multicast. But it isn’t correct if the state will be durable (on disk). Also, handling membership changes is a bit tricky. So Lamport pushed further and proposed his Paxos protocol. http://www.cs.cornell.edu/courses/cs5412/2018sp 12
13 .Paxos Concept Leslie Lamport proposed the Paxos model as a way to Express the state machine replication problem in a more formal way Solve it, using the “ Paxos protocol”. Now we call it the “classic” one: Over the years, many Paxos protocols have been developed All of them solve the Paxos specification, but the details vary widely One source of confusion with Paxos concerns storage of data Is Paxos “delivering messages” to an application that has the state/storage role? Or is Paxos itself a kind of “database of messages”? Leslie likes this model. http://www.cs.cornell.edu/courses/cs5412/2018sp 13 Paxos (Greek Island)
14 .How Paxos works. Similar to the original protocol, but in Paxos , Lamport only requires a reply from a majority (quorum) of the participants. He has two “phases”. In the first, a leader keeps proposing to place messages into slots and the receivers either accept or reject the proposal. They write the pending messages to logged storage, but then wait. In the second phase, a leader with a quorum of accept votes can use a two-phase commit to finalize the update. http://www.cs.cornell.edu/courses/cs5412/2018sp 14 Paxos (Greek Island)
15 .How do these behaviors differ? In the first protocol, we do an atomic multicast to update in-memory state. This is sometimes called a vertical Paxos protocol. The key insight is that it isn’t safe if all the processes might crash. In the second protocol, Paxos “implements” a durable storage system Like an append-only log, and updates are appended The application would read the log, but the log is durable. http://www.cs.cornell.edu/courses/cs5412/2018sp 15
16 .Not everything needs such an elaborate model and solution In many key-value stores, membership management is just done by a service that periodically updates a file listing the members and mapping. Then the members are expected to “shuffle” data until they have the proper key-value tuples. There can be a brief period of inconsistency but it wouldn’t last for long. http://www.cs.cornell.edu/courses/cs5412/2018sp 16
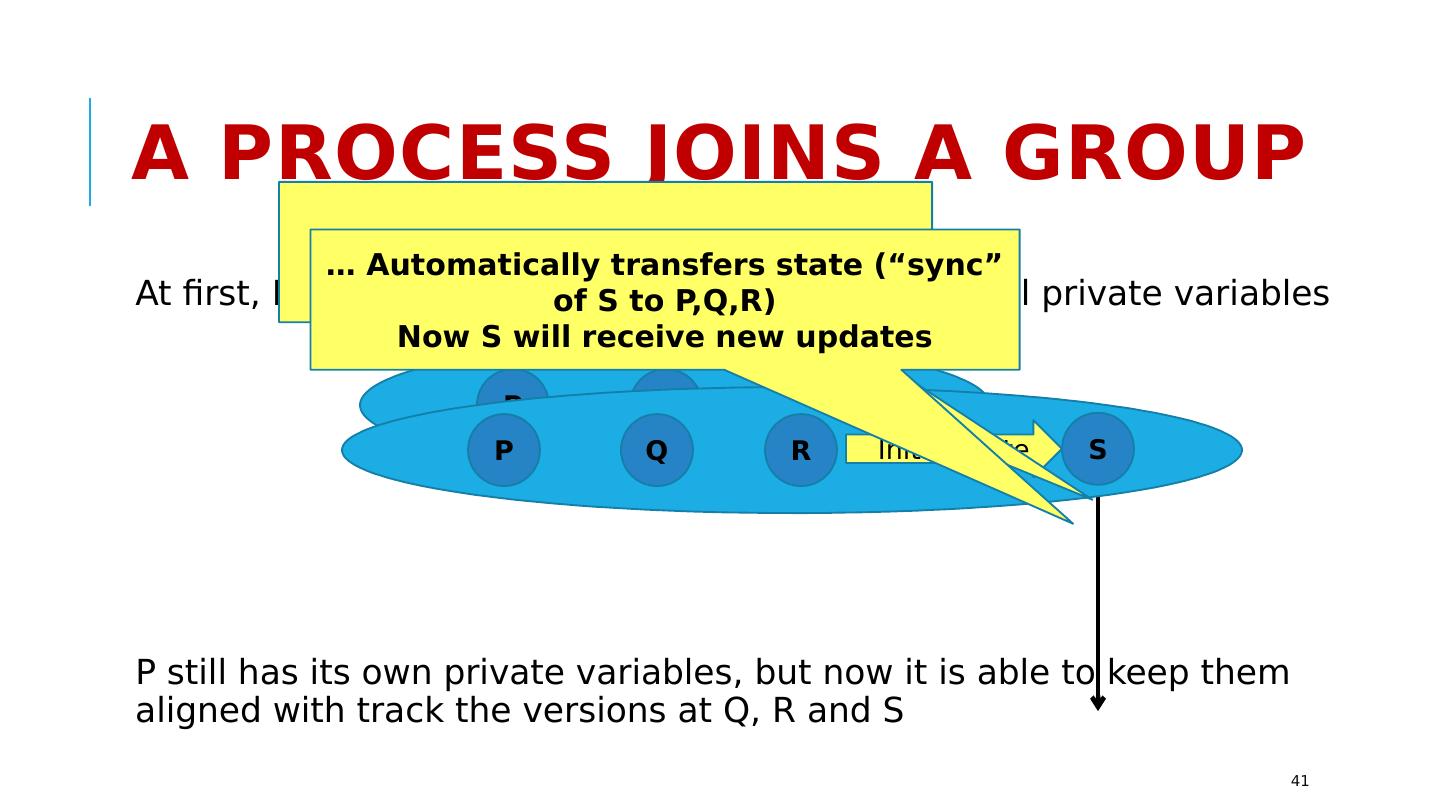
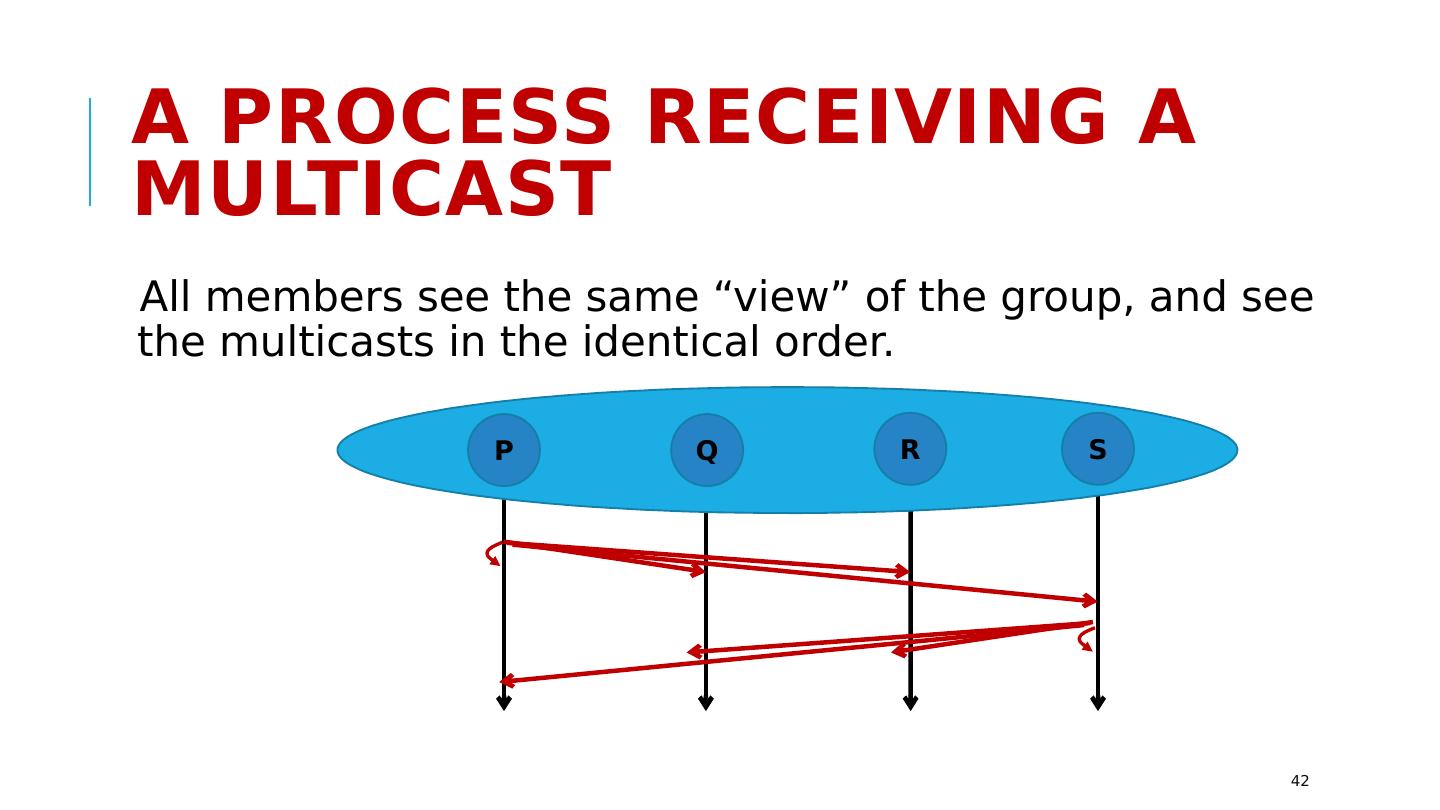
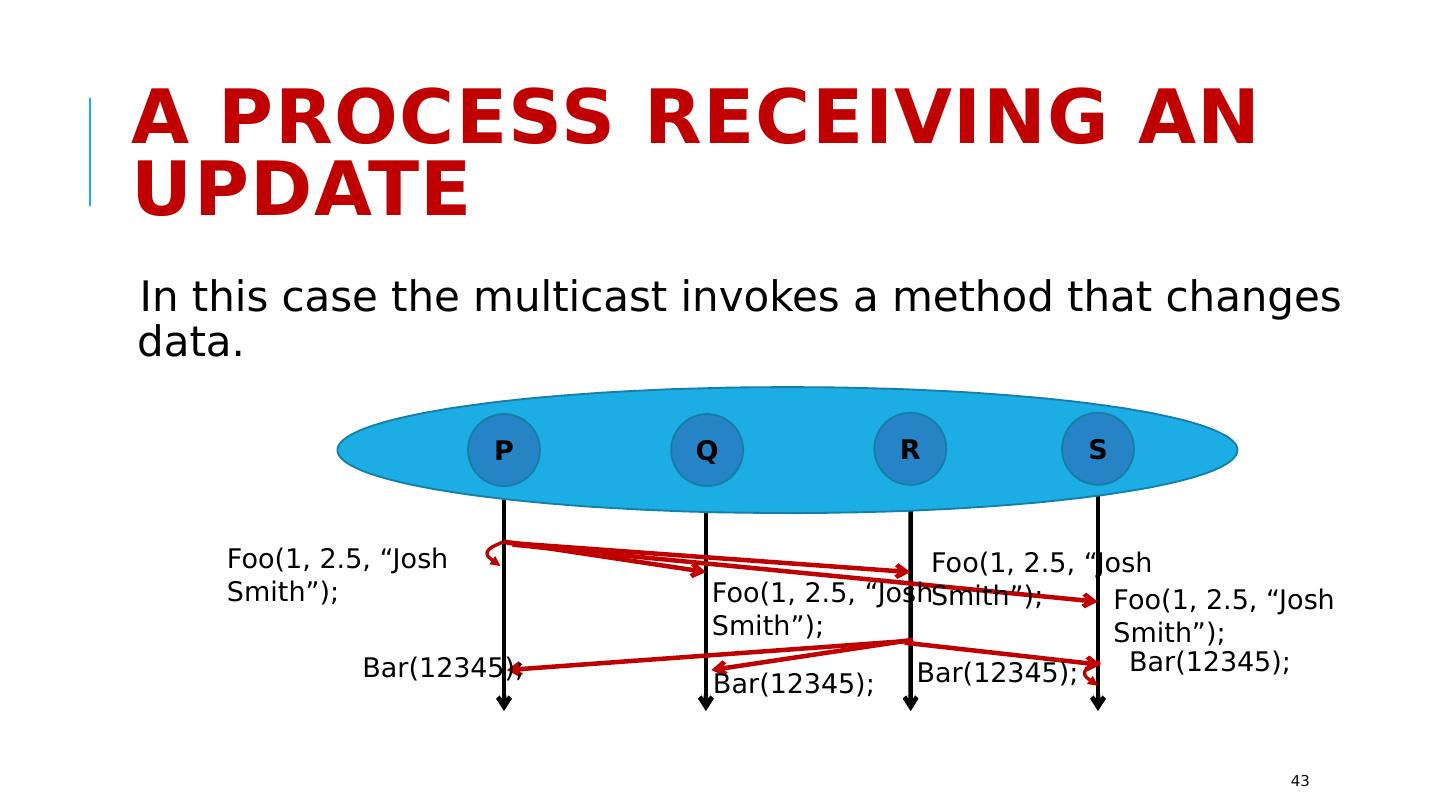
17 .VirtuaLLy Synchronous Membership Manages a group of replicas that are using Paxos . Members can join the group, leave it, crash (failed members are ejected). “State transfer” to initialize the new members when they join Updates occur entirely in a single epoch: during a period when membership is stable. Every replica receives the identical updates. http://www.cs.cornell.edu/courses/cs5412/2018sp 17
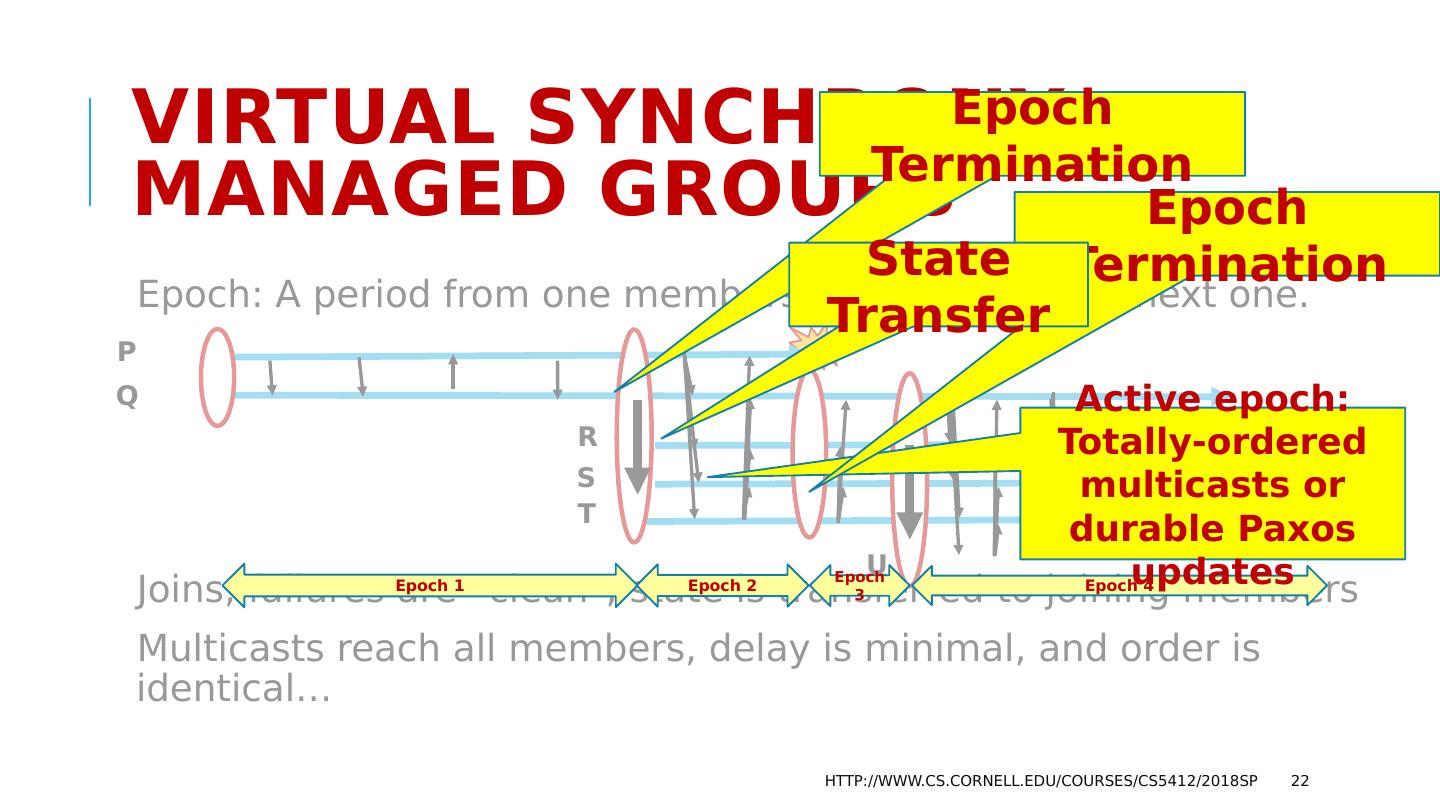
18 .Virtual synchrony: Managed Groups Epoch: A period from one membership view until the next one. Joins, failures are “clean”, state is transferred to joining members Multicasts reach all members, delay is minimal, and order is identical… http://www.cs.cornell.edu/courses/cs5412/2018sp 18 P Q R S T U
19 .Derecho uses Paxos for Membership Agreement! In Derecho, a “true” Paxos protocol is used to compute each new membership epoch (“view”) We pick a leader, and it attempts to gain agreement on the next view and other configuration parameters for the epoch (like the mapping of view to subgroup layout and sharding ). If the leader fails, a different leader takes over. This terminates when a quorum is able to accept and switch to the new epoch. http://www.cs.cornell.edu/courses/cs5412/2018sp 19
20 .Life in an Epoch Then, during the epoch, multicasts or durable Paxos updates can be done under an assumption that no failures occur. This simplifies protocols: Derecho’s protocols are optimally efficient . If some process does fail, the event triggers a new epoch-agreement protocol, which also finalizes the prior epoch. http://www.cs.cornell.edu/courses/cs5412/2018sp 20
21 .Multicasts versus Paxos For a virtual synchrony multicast, a totally-ordered in-memory message triggers a state machine update. The state itself lives in memory. With durable Paxos , state lives in a file or append-only log, on disk. Here because the state is non-volatile, even a failure can’t cause it to be lost. In both cases, if a process joins a group, state transfer is used to initialize it. http://www.cs.cornell.edu/courses/cs5412/2018sp 21
22 .Virtual synchrony: Managed Groups Epoch: A period from one membership view until the next one. Joins, failures are “clean”, state is transferred to joining members Multicasts reach all members, delay is minimal, and order is identical… http://www.cs.cornell.edu/courses/cs5412/2018sp 22 P Q R S T U Epoch 1 Epoch Termination Epoch 2 Epoch 3 Epoch 4 Active epoch: Totally-ordered multicasts or durable Paxos updates Epoch Termination State Transfer
23 .Strong models prevent “Split brain” problems Imagine an air traffic control computer, and a backup Network fails, but just for a moment… both machines remain active. Machine X never noticed the outage and thinks A is the active controller. But machine Y “rolled over” to the backup, and is talking to B. Now we have two controller computers for the same landing strip! http://www.cs.cornell.edu/courses/cs5412/2018sp 23 Partitioning (split brain) and similar inconsistencies can never happen with virtually synchronous Paxos solutions. Use virtual synchronous Paxos whenever you are at risk of unsafe behavior in the event of inconsistency.
24 .Let’s take a closer look What might a service using these concepts be doing? How would a person code such a service? http://www.cs.cornell.edu/courses/cs5412/2018sp 24
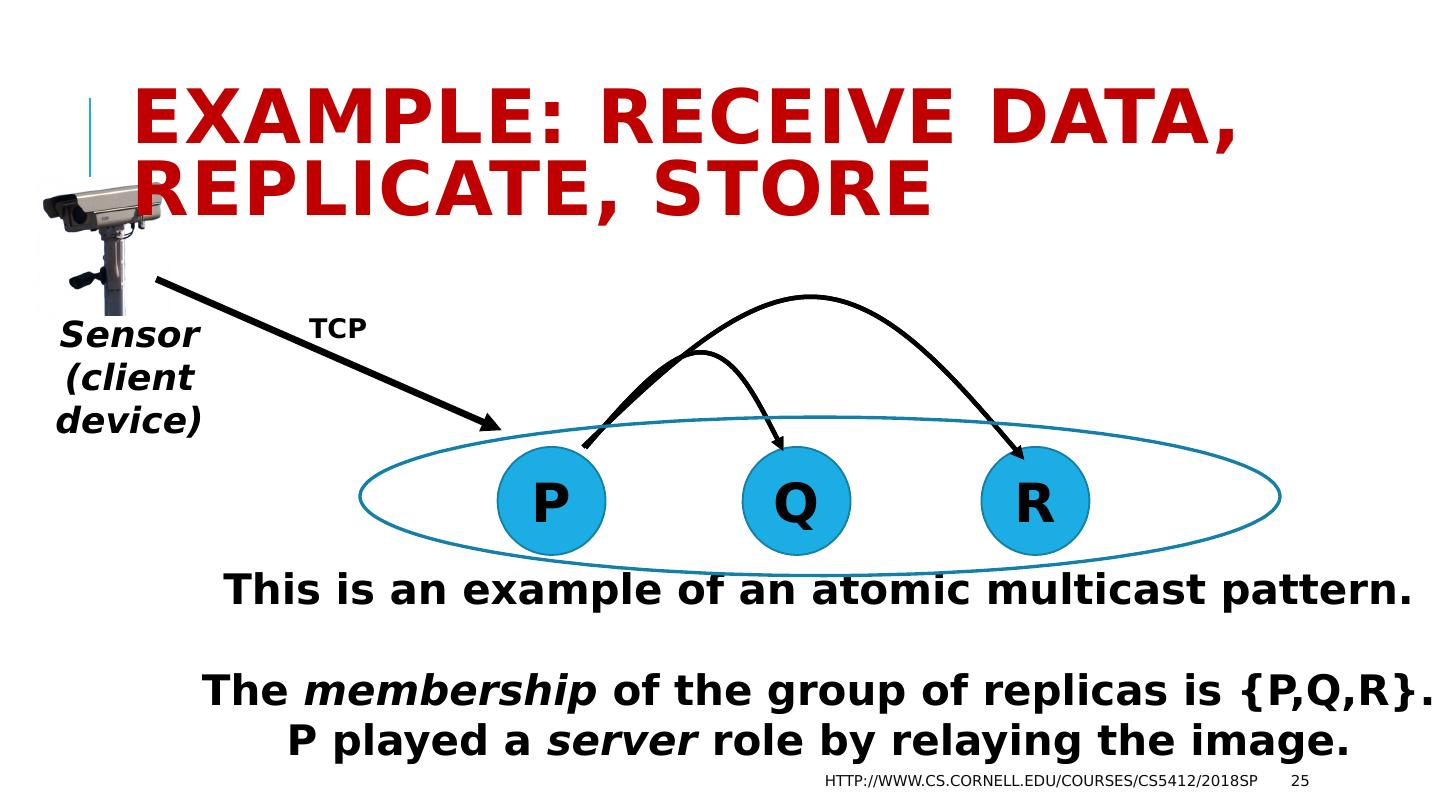
25 .Example: Receive data, replicate, store http://www.cs.cornell.edu/courses/cs5412/2018sp 25 Sensor (client device) P Q R This is an example of an atomic multicast pattern. The membership of the group of replicas is {P,Q,R}. P played a server role by relaying the image. TCP
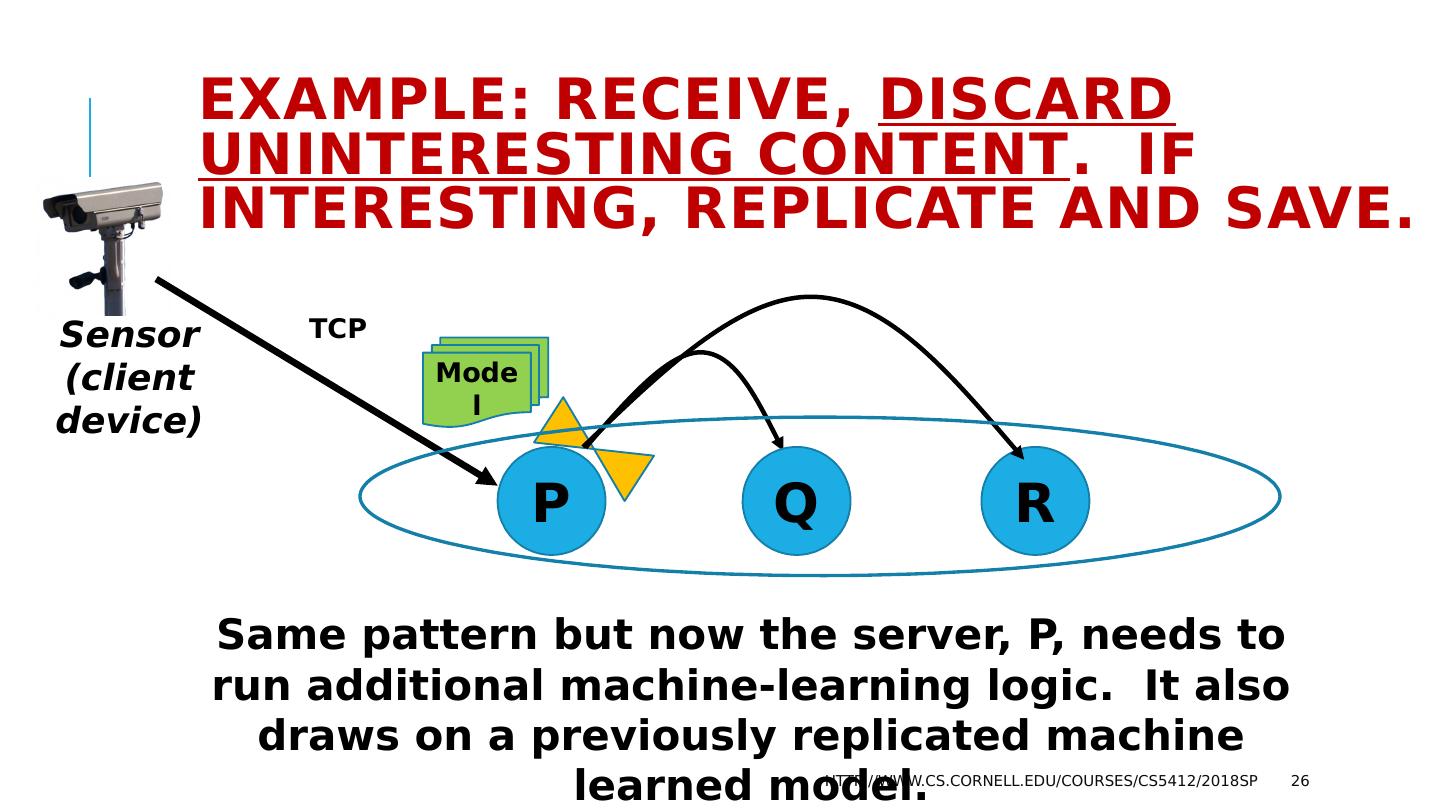
26 .Example: Receive, Discard uninteresting content . If interesting, replicate and save. http://www.cs.cornell.edu/courses/cs5412/2018sp 26 Sensor (client device) Same pattern but now the server, P, needs to run additional machine-learning logic. It also draws on a previously replicated machine learned model. TCP Model P Q R
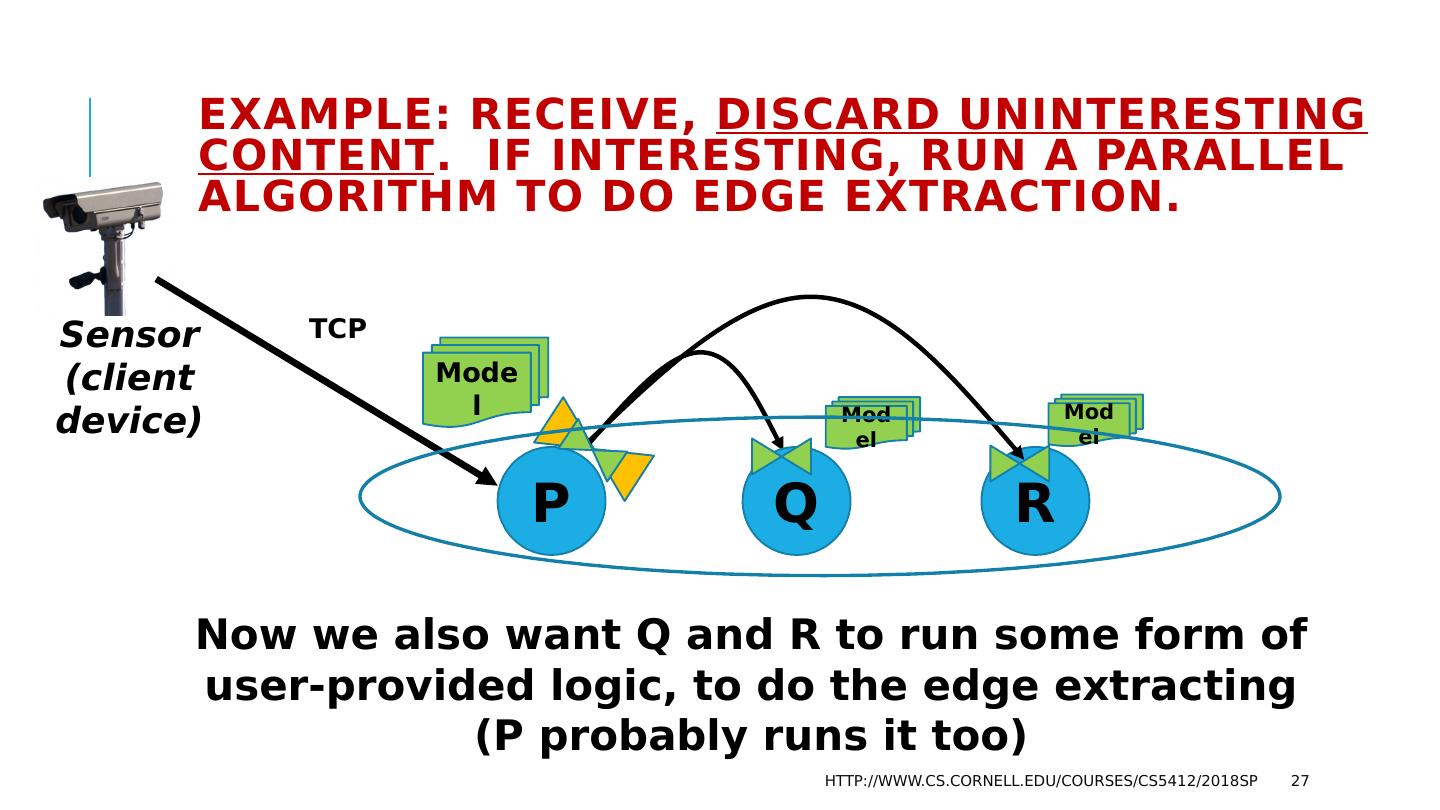
27 .Example: Receive, Discard uninteresting content . If interesting, Run a parallel algorithm to do edge extraction. http://www.cs.cornell.edu/courses/cs5412/2018sp 27 Sensor (client device) Now we also want Q and R to run some form of user-provided logic, to do the edge extracting (P probably runs it too) TCP Model P Q R Model Model
28 .What did our examples show? We need a way to write a piece of code that can Open a TCP connection endpoint. The sensor will connect to it. Read in an image or video, over the connection. Run some sort of “artificially intelligent” test procedure that makes use of a machine-learned model that was uploaded previously (tier 2) Then, if data is interesting, “ask” for it to be replicated When replicas arrive at Q, R, write them to storage. http://www.cs.cornell.edu/courses/cs5412/2018sp 28 For this, Azure IoT might use a REST library. It handles these standard steps and is easy to use.
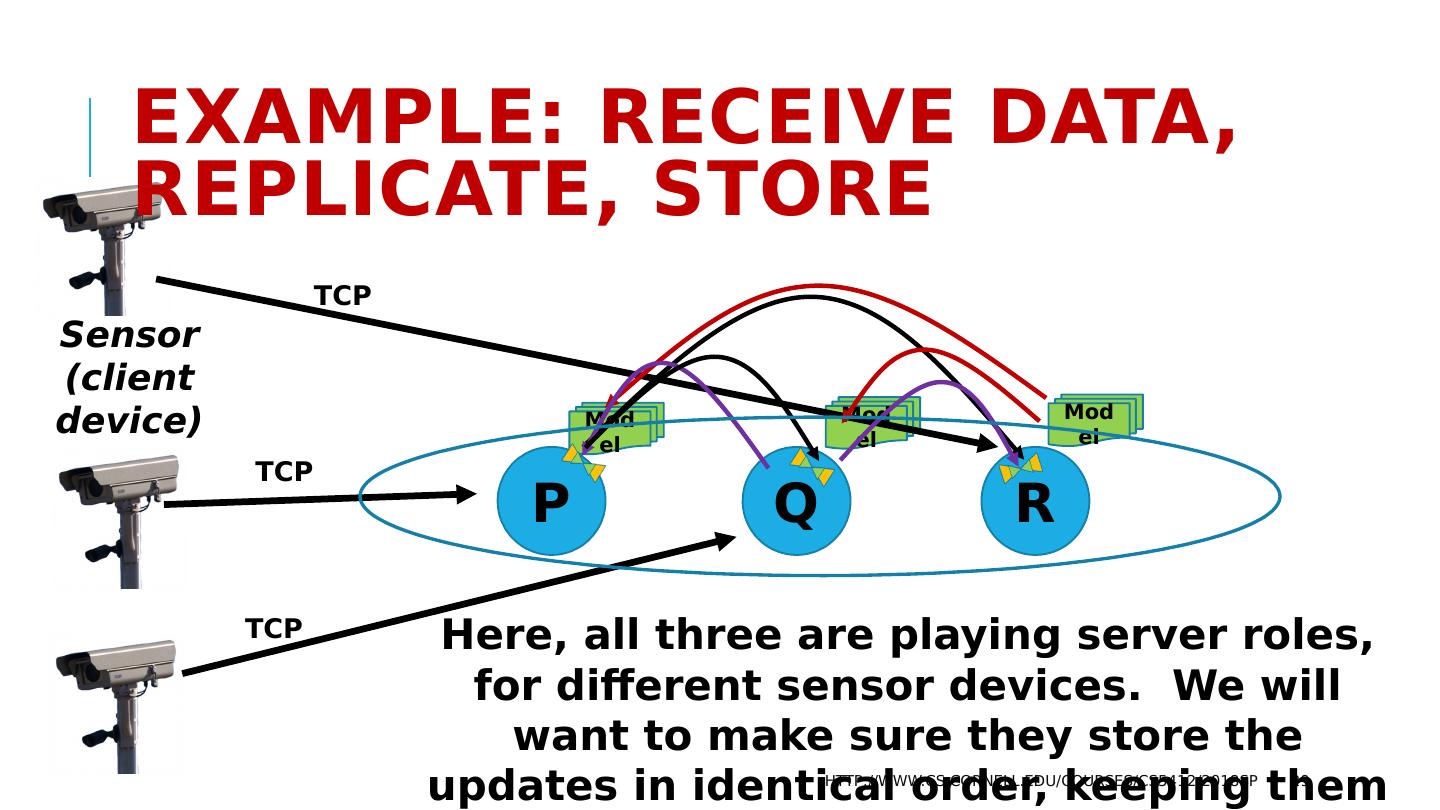
29 .Model Model Model Example: Receive data, replicate, store http://www.cs.cornell.edu/courses/cs5412/2018sp 29 Sensor (client device) P Q R TCP TCP TCP Here, all three are playing server roles, for different sensor devices. We will want to make sure they store the updates in identical order, keeping them consistent.
3秒后跳转登录页面
去登陆

