






























- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
创新AI计算,加速人工智能研发效率-邸双朋-浪潮
面对海量数据,需要超大速率的计算能力,浪潮通过搭建AI计算平台来解决这一难题,并且详细介绍浪潮在搭建时候的选择以及每一种选择背后的性能优化考虑
展开查看详情
1 .创新AI计算,加速人工智能研发效率 邸双朋 浪潮AI系统架构师
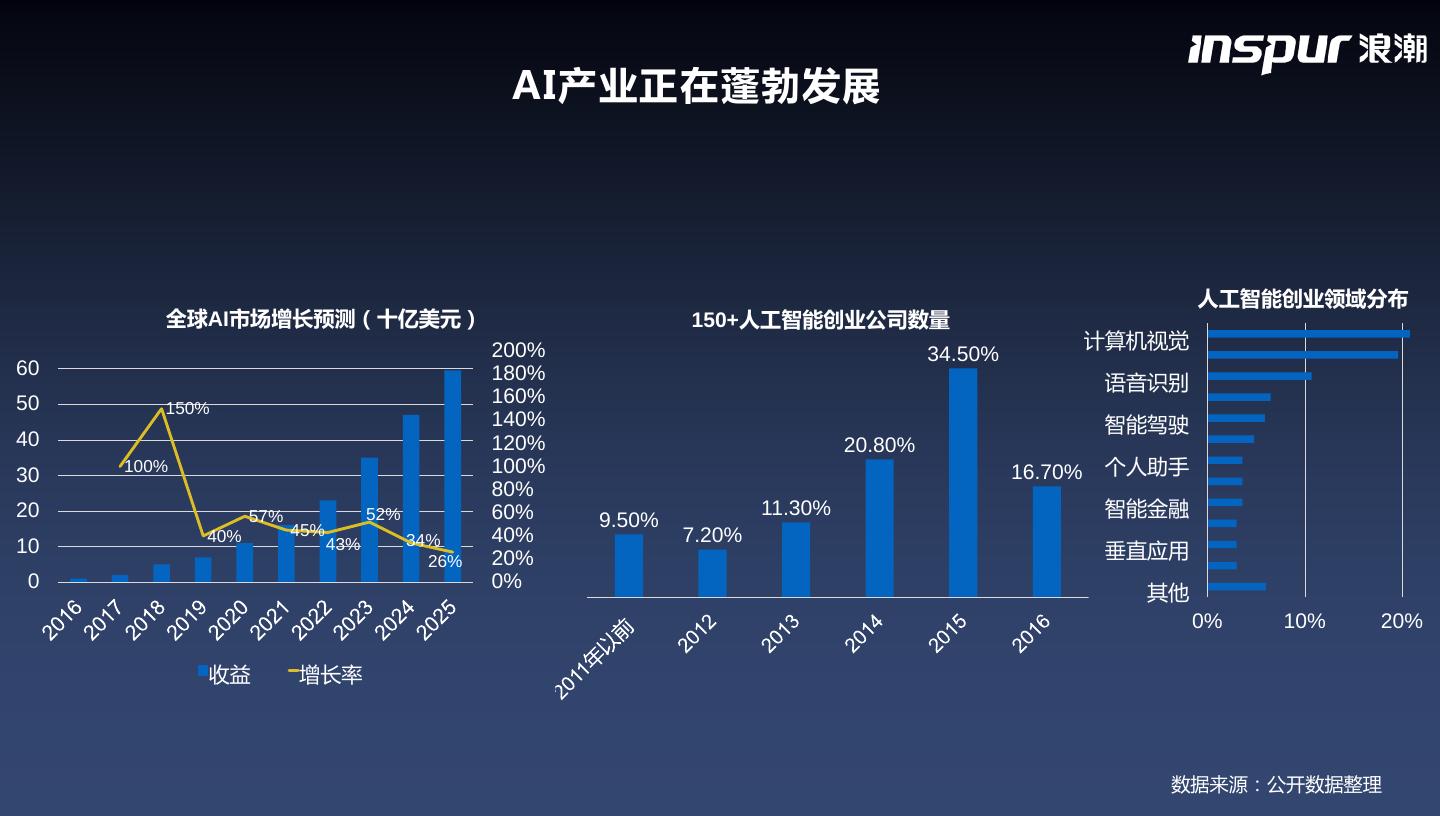
2 . AI产业正在蓬勃发展 人工智能创业领域分布 全球AI市场增长预测(十亿美元) 150+人工智能创业公司数量 200% 计算机视觉 34.50% 60 180% 语音识别 50 160% 150% 140% 智能驾驶 40 120% 20.80% 30 100% 100% 16.70% 个人助手 80% 20 57% 52% 60% 11.30% 智能金融 45% 9.50% 40% 34% 40% 7.20% 10 43% 26% 20% 垂直应用 0 0% 其他 0% 10% 20% 收益 增长率 数据来源:公开数据整理
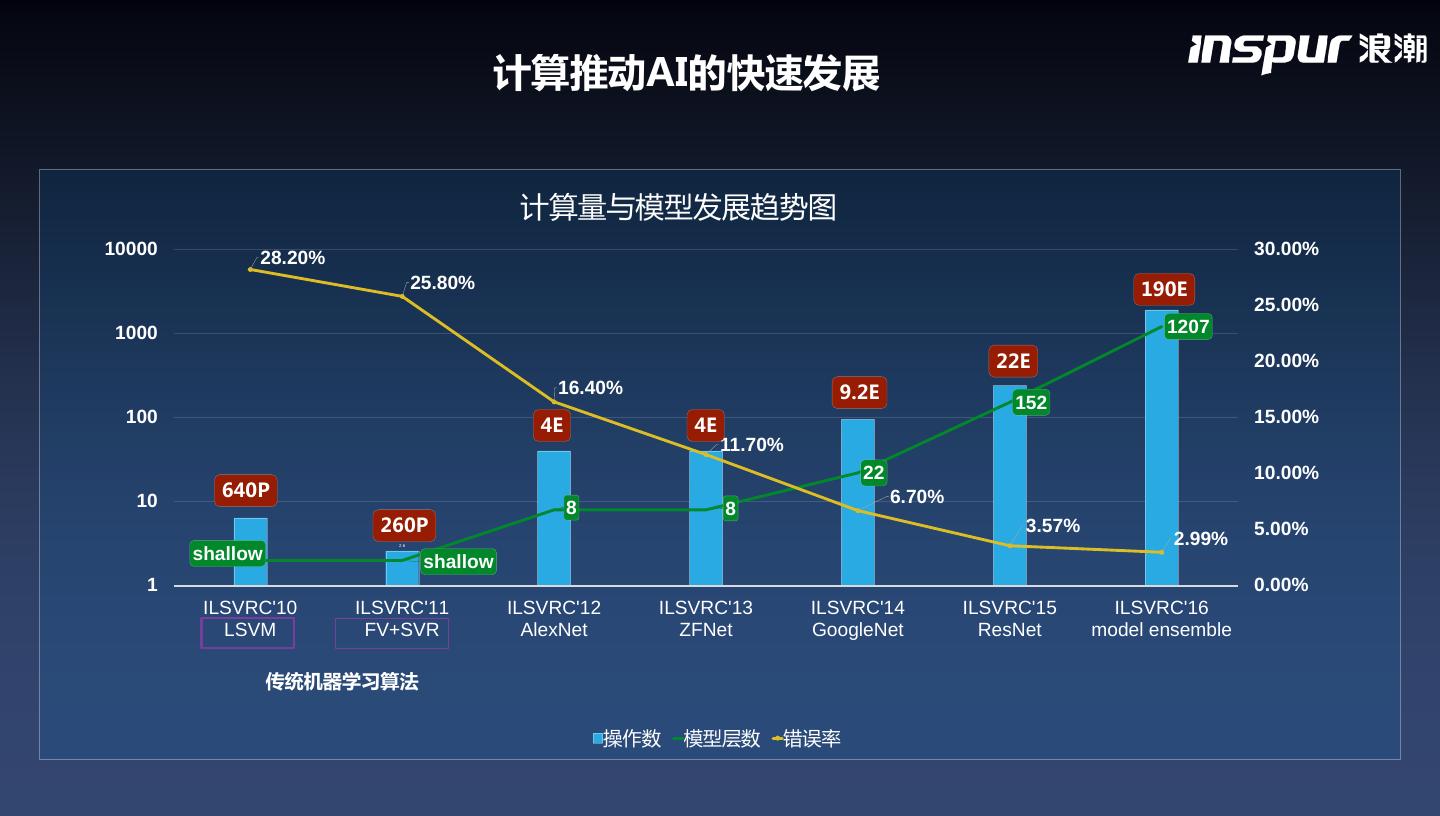
3 . 计算推动AI的快速发展 计算量与模型发展趋势图 10000 28.20% 30.00% 25.80% 190E 25.00% 1000 1207 22E 20.00% 16.40% 9.2E 152 100 4E 4E 15.00% 11.70% 22 10.00% 640P 6.70% 10 8 8 260P 3.57% 5.00% 2.6 2.99% shallow shallow 1 0.00% ILSVRC'10 ILSVRC'11 ILSVRC'12 ILSVRC'13 ILSVRC'14 ILSVRC'15 ILSVRC'16 LSVM FV+SVR AlexNet ZFNet GoogleNet ResNet model ensemble 传统机器学习算法 操作数 模型层数 错误率
4 . AI当前面临的计算挑战 应用数据 数据中心 后端训练系统 前端推理系统 模型训练 模型部署 推理 训练 Training 智能 Deployment 预测 Inference 数据集 模型 结果 ImageNet 数据集 ResNet 数 计算量(浮点操作) 耗时 据 增 224x224 强 152层 训练 2千2百亿亿次 41天 Nvidia TITANX 100亿连接 120万张 24.57亿张
5 . AI发展面临的计算挑战 Inception 自 算法专家 + 大数据 + 计算 block 动 模型 x … y Relu Add FCN Mul 生成 学 w b 习 “事实证明,我们真正需要的是 ModelLib 模 模 大数据 + 100 * 计算 模型 Inception GRN 型 评 型 匹配 超过现在 100万倍 的计算能力, Residual Unit RNN 价 而不只是区区几十倍的增长。” 通 用 一次建模,各处适用 ——Jeff Dean 学 大规模、稀疏网络 习 模 对计算提出更高要求 型 参考Jeff Dean「Hot Chips 2017」演讲:AI对计算机系统设计的影响
6 . 浪潮AI计算平台解决方案 AI应用方案 E2E Solution AI计算框架 Caffe-MPI TF-OPT AI系统管理 AIStation T-Eye AI计算平台 2/4/8/16 GPU Server F10A FPGA
7 . 浪潮AI计算平台 – GPU server 4GPU服务器 8GPU服务器 4×4GPU box 16GPU box 8/16GPU服务器 FPGA卡 NF5280M5 AGX-2 GX4 AGX-5 NF5468M F10A FPGA 数据处理或推理 线下训练 线下训练 线下训练 训练或推理 线上推理
8 . AGX-2极致计算密度,实现高性能训练 全球唯一在2U空间支持8颗NVLink的P100/V100的高性能AI计算平台 Caffe-AlexNet(Batch=128) 针对参数密集型模型 7000 6000 Images/s 5000 支持NVLink 2.0 4000 3000 2000 1000 0 1 2 4 8 Num of GPU NF5288M5(PCIE) NF5288M5(NVLink) Tensorflow-ResNet(Batch=128) 700 600 500 Images/s 400 针对计算密集型模型 300 200 100 支持2U 8×Tesla V100 0 1 2 4 8 Num of GPU NF5288M5(PCIE) NF5288M5(NVLink)
9 . GX4弹性计算架构,应对多场景训练 CPU Server与GPU BOX分离设计,实现拓扑灵活调整,应对复杂AI训练需求 8GPU配置 16GPU配置 Scale out
10 . AGX-5 最强AI超级服务器 4X 训练规模-AI计算力革命性提升;10X 训练速度-前所未见的加速体验 最强计算性能 • 全球最强大AI计算主机,计算性能高达每秒2千万亿 • 单机配置16颗目前性能最强的NVIDIA Tesla® V100 32GB • 2颗28核心的强大CPU,提供顶级通用计算性能 全芯片群高速互联 • 基于NVIDIA最新的HGX-2TM平台,采用业界最先进的 NVSwitchTM互联结构 • 可实现48通道、2.4TB/s的全芯片群高速互联 数据吞吐速度全面提升 • 512GB HBM2 全局共享超高速图形缓存 • 6 TB持久内存可提供超大数据高速访问
11 .AGX-5 最强AI超级服务器 全球“最大GPU”逻辑架构 单OS下最高数量GPU,驱动归一化 AGX-5从逻辑上变成一整个GPU,任何GPU的高速 HBM2显存都可以被其他GPU无干预访问 所有GPU显存地址不受CPU NUMA域影响,显存可采 用全局地址空间 近、远端内存带宽比例3:1,相比原来18:1更均衡
12 . NF5468M :训练+推理 弹性配置能力最优 弹性PCI-E拓扑和数量配比,适配多种框架的运算需求 易于管理和维护的远程GPU拓扑重构技术 AI模型训练性能最好 8颗最高性能的Tesla Volta GPU 可支持PCI-E或高速NVLink互联 AI在线推理效能比最大 16颗高能效比的Tesla P4 GPU 同时处理300路以上1080p高清视频结构化 NF5468M5 数据存储与通讯性能极大化 面向AI云的最佳服务器平台 288TB大容量存储,或32TB固态存储 400Gbps通信带宽,1us延迟
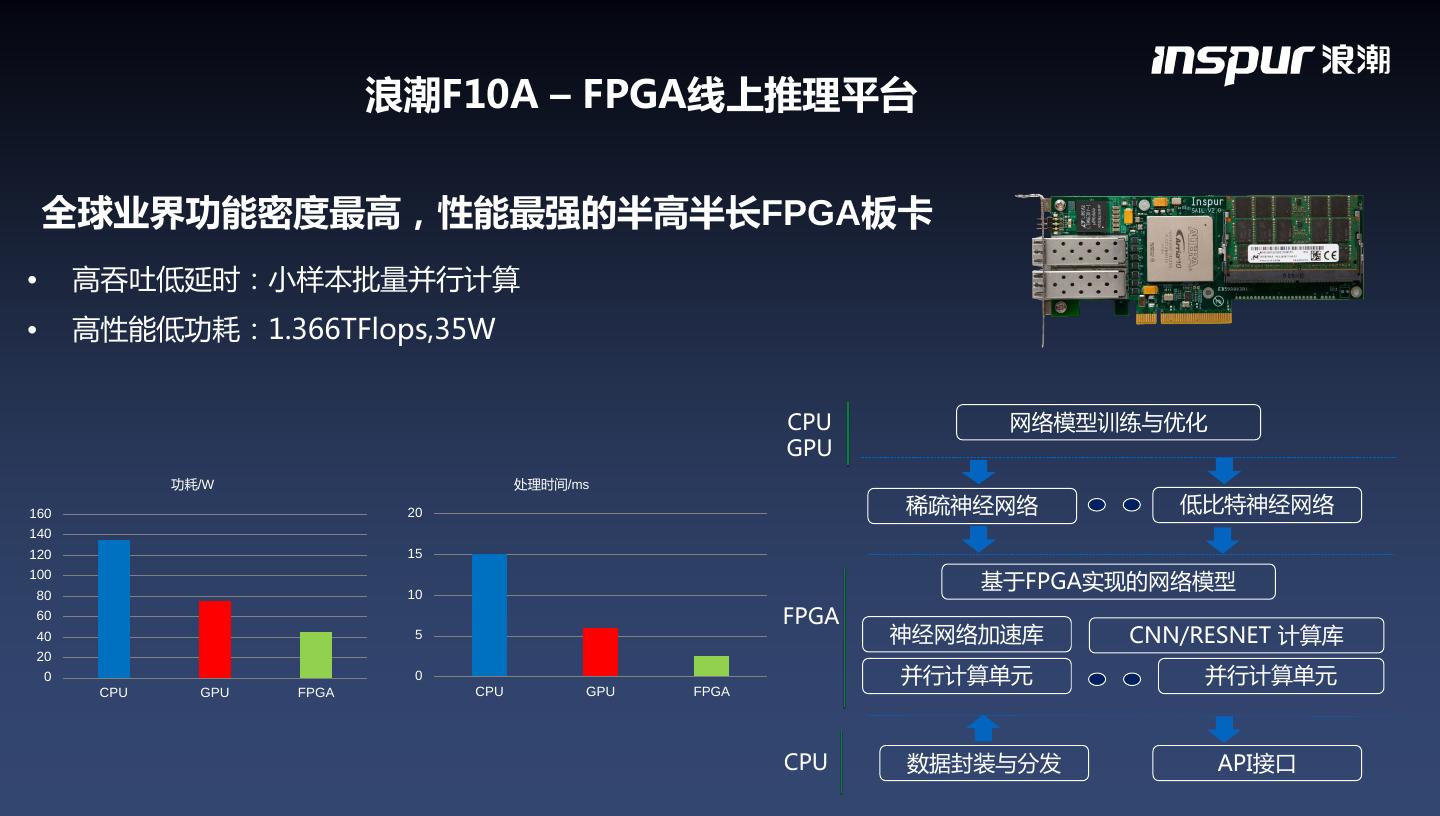
13 . 浪潮F10A – FPGA线上推理平台 支持OpenCL高级语言开发 业界功能密度最高、性能最强的半高半长FPGA卡
14 . 浪潮F10A – FPGA线上推理平台 全球业界功能密度最高,性能最强的半高半长FPGA板卡 • 高吞吐低延时:小样本批量并行计算 • 高性能低功耗:1.366TFlops,35W CPU 网络模型训练与优化 GPU 功耗/W 处理时间/ms 160 20 稀疏神经网络 低比特神经网络 140 120 15 100 80 10 基于FPGA实现的网络模型 60 FPGA 40 5 神经网络加速库 CNN/RESNET 计算库 20 0 0 并行计算单元 并行计算单元 CPU GPU FPGA CPU GPU FPGA CPU 数据封装与分发 API接口
15 . AI计算管理平台 – AIStation 实现AI开发与资源管理的高效平台 • 开发环境快速构建 • 缩短模型开发和调试时间 AI开发者 • 缩短模型训练时间 • 应用的计算性能优化 • GPU资源统一管理监控 AI运维者 • GPU资源统一调度分配 • 精细化的GPU调度策略 • 容器实现资源隔离 框架部署 可视化开发 任务管理与调度 系统监控 应用分析
16 . AI计算管理平台 – AIStation 集中化管理 容器化部署 可视化开发 不同计算资源的高效 不同框架与开发包的 模型调试可视化,加 管理与调度,训练系 快速部署,效率从4小 快模型开发及优化速 统效率从50%提升 时降低到1分钟 度,性能提升25% 80%
17 . AI计算管理平台 – AIStation GPU资源统一管理 GPU集群性能优化 可视化开发流程 资源利用率提高75% GPU性能提高:1倍 每日完成训练任务提升:2倍 -实时掌握集群资 可 管 源使用情况 调 -系统瓶颈优化 -容器镜像优化 视 -训练流程化 理 -精细化的调度策 略 优 -编译参数优化 化 -模型可视化
18 . AI计算管理平台 – AIStation 监 - 资源监控 - 性能监控 控 - 故障监控 资源管理 - 任务排队 调 - 资源配额 优 - 应用特征分析 度 - 拓扑优化 化 - 系统性能优化 - GPU共享
19 . AI计算管理平台 – AIStation 通过容器实现GPU分配调度略 GPU用户配额及限制策略 GPU资源独占与多用户共享 GPU分组调度优化 训练任务排队策略
20 . AI计算管理平台 – AIStation 通过容器快速构建AI开发环境 按需创建容器:容器数量,容器配置 资源弹性伸缩:动态添加或删除容器 容器管理:shell,编辑,保存 应用编排:快速启动并行训练 镜像管理:公有镜像,私有镜像
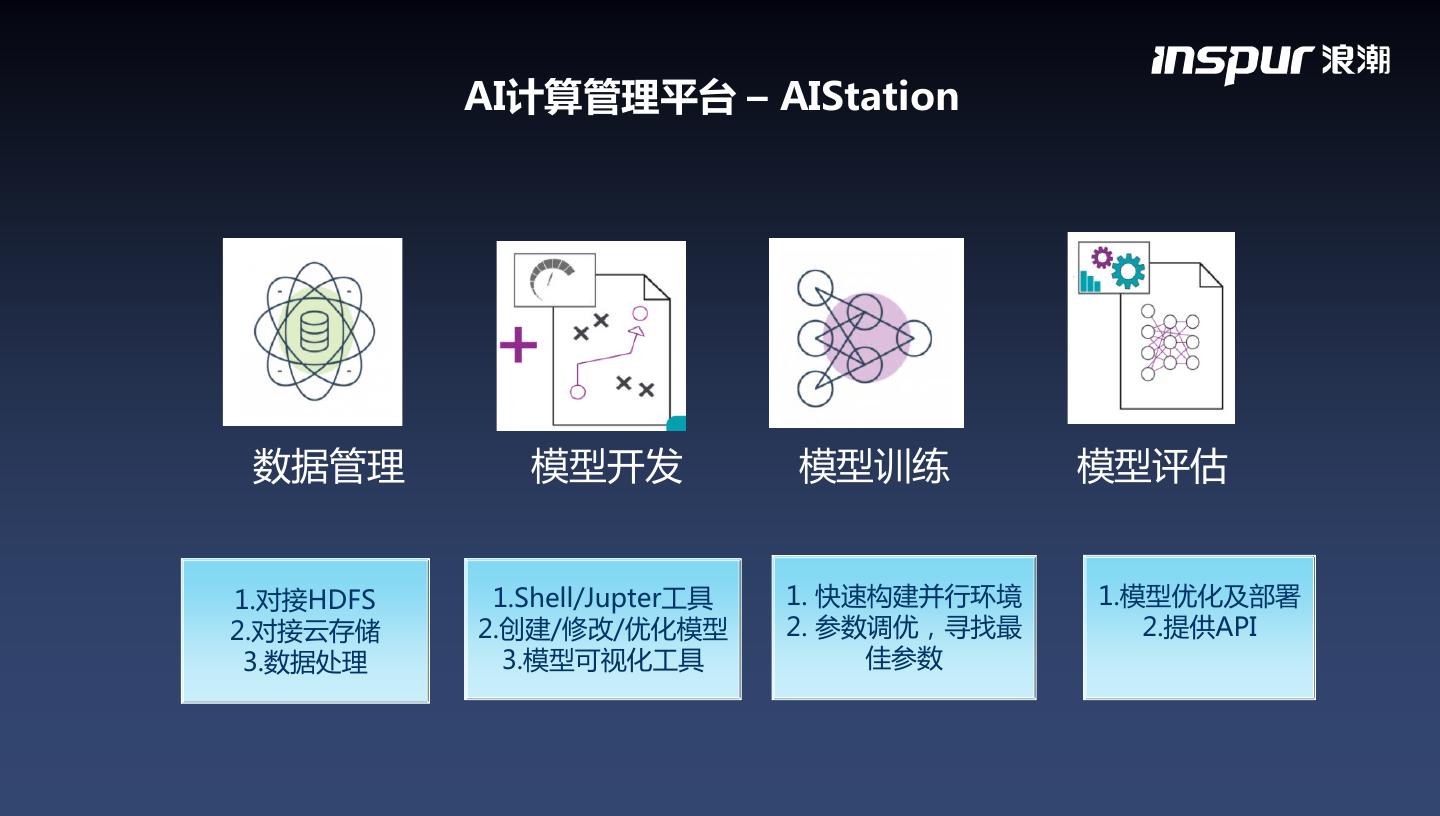
21 . AI计算管理平台 – AIStation 数据管理 模型开发 模型训练 模型评估 1.对接HDFS 1.Shell/Jupter工具 1. 快速构建并行环境 1.模型优化及部署 2.对接云存储 2.创建/修改/优化模型 2. 参数调优,寻找最 2.提供API 3.数据处理 3.模型可视化工具 佳参数
22 . AI计算平台的瓶颈 在线实时推理 低延迟、低能耗 线上推理平台 频繁参数交换 参数密集型 计算密集型 高密度计算 通信性能 计算性能 AlexNet VGGNet GoogLeNet ResNet MXNet Caffe TensorFlow PaddlePaddle 计算框架 分布式架构 计算扩展 复杂业务模式 弹性扩展 线下训练平台
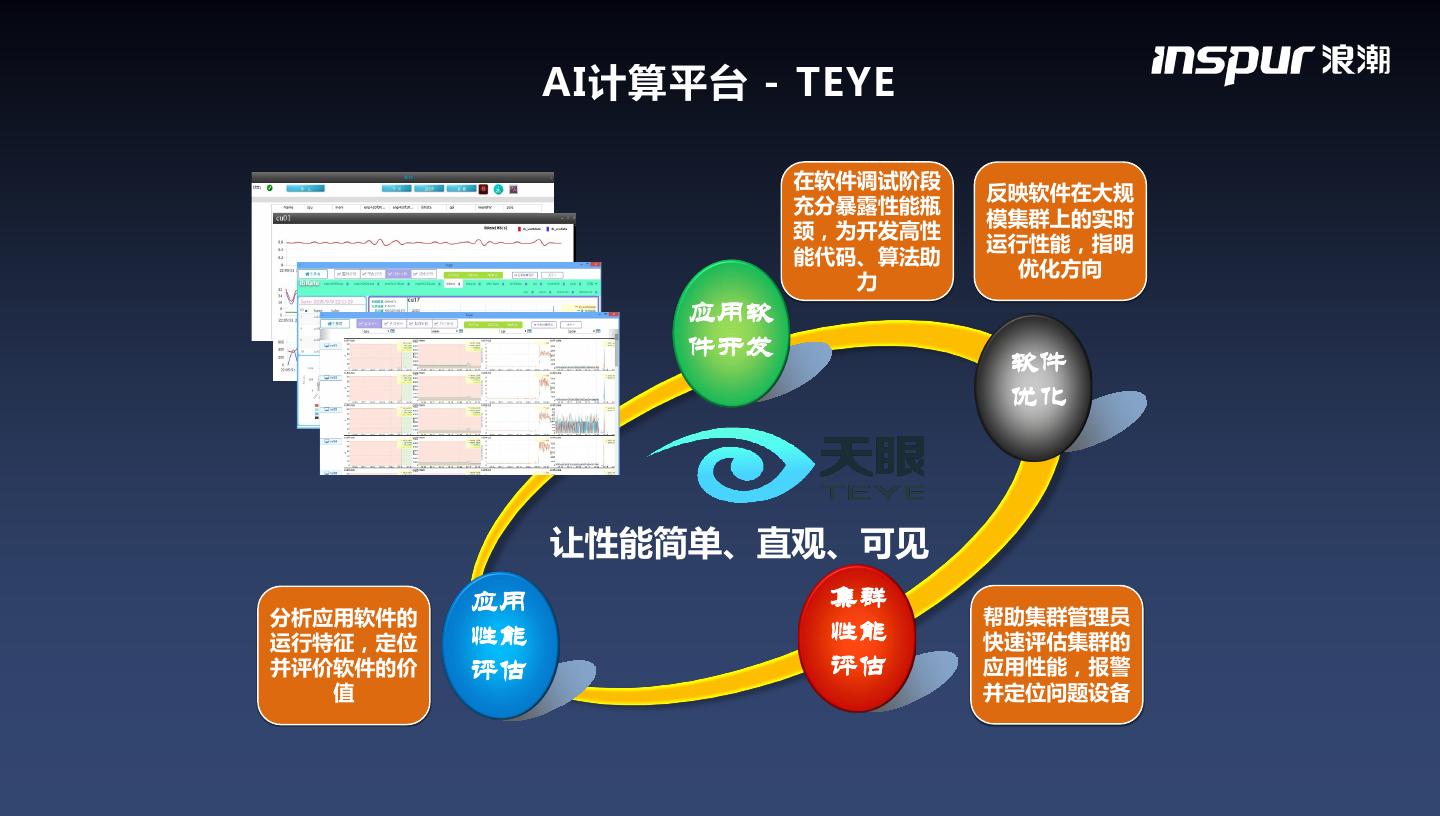
23 . AI计算平台 - TEYE 在软件调试阶段 反映软件在大规 充分暴露性能瓶 模集群上的实时 颈,为开发高性 运行性能,指明 能代码、算法助 优化方向 力 应用软 件开发 软件 优化 让性能简单、直观、可见 应用 集群 分析应用软件的 帮助集群管理员 运行特征,定位 性能 性能 快速评估集群的 并评价软件的价 评估 评估 应用性能,报警 值 并定位问题设备
24 . AI计算平台 - TEYE DDR4 DDR4 QPI CPU CPU 计算节点性能优化 QPI DMI 进程优化:NUMA PCIe PCIe PCH 访存优化:数据对齐、Cache 磁盘 设备通信:PCIe 加速卡 本地I/O:硬盘、SSD Infiniband 以太网 网络通信:IB、以太网 加速卡:GPU,FPGA CPU优化:微架构
25 . 100 0 20 40 60 80 1 0 5 10 15 20 25 30 35 40 45 3 1 5 3 7 5 9 7 11 内存 9 13 PCI-E 11 15 13 17 15 19 17 21 微构架级 19 23 21 25 23 27 25 29 27 31 29 33 31 35 33 37 35 39 37 41 39 43 41 45 43 47 45 49 47 51 49 53 51 55 53 57 55 总浮点运算速度 59 57 61 59 63 61 65 63 67 65 69 67 71 • 执行效率:CPI 69 73 71 75 73 77 75 79 77 81 79 83 81 85 83 87 85 89 87 91 89 93 91 95 93 97 95 99 97 101 99 103 101 105 总内存带宽 103 107 105 109 107 111 109 113 111 X87单元运算速度 115 113 117 115 119 117 121 119 123 121 125 123 127 125 129 127 131 129 133 • 利用率:Usr%, sys%, idle%, iowait% 131 135 133 137 135 137 139 139 141 141 143 • 向量化率:SP/DP SSE VEC, SP/DP AVX VEC 143 145 145 147 147 149 149 151 • 内存访问:内存读操作带宽、内存写操作带宽 • 内存容量:总容量,used, cached, buffered 151 153 153 155 155 157 157 159 内存带宽 (GB/s) 159 161 161 163 163 165 165 167 167 169 171 内存读带宽 169 • PCI-Express访问:PCIE读操作带宽、PCIE写操作带宽 173 CPU浮点运算速度(GFlops) 171 173 175 SSE向量化运算速度 175 177 177 179 179 181 181 183 183 185 185 187 187 189 189 191 191 193 193 195 195 197 AI计算平台 - TEYE 197 199 199 201 201 203 203 205 205 207 207 209 209 211 211 213 213 215 215 217 217 219 219 221 221 223 223 225 225 227 227 229 229 231 SSE标量运算速度 231 233 233 235 235 内存写带宽 237 237 239 239 241 241 243 243 245 245 247 247 249 249 251 251 253 253 255 255 257 257 259 259 261 261 263 263 265 265 267 267 269 269 271 271 273 273 275 275 277 277 279 • 浮点性能:X87 GFLOPS, SP/DP SSE scalar/packed GFLOPS, SP/DP AVX scalar/packed GFLOPS 279 281 281 283 283 285 285 287 287 289 289 291 291 AVX向量化运算速度 293 293 295 295 297 297 299 299 301 301 303 303
26 . 200 400 600 800 1000 1200 1400 1600 1800 2000 0 100 200 300 400 500 600 700 800 0 1 1 3 8 5 15 级 22 7 29 9 36 11 43 13 50 57 15 网络级 64 17 71 19 78 21 85 文件系统 23 92 99 25 106 27 113 29 120 31 127 134 33 141 35 148 37 155 39 162 41 169 176 43 183 45 190 47 197 49 204 51 211 218 53 225 55 232 57 239 59 246 253 61 260 63 267 (总)写 65 274 67 281 69 288 295 71 302 73 309 75 316 77 323 79 330 337 81 344 83 351 85 358 87 365 372 89 379 91 386 93 393 95 400 97 407 414 99 421 101 428 103 435 105 442 107 449 456 109 463 111 470 113 477 115 484 491 117 498 119 505 121 512 123 519 125 526 533 127 540 129 547 131 554 133 561 •设备支持:Gigabit, Infiniband 568 135 575 137 I/O读 582 139 589 发送速率 141 596 143 603 610 145 617 147 624 149 631 151 •协议支持:TCP/IP, UDP, RDMA, IPoIB 638 153 645 652 155 659 157 666 159 673 161 680 687 163 694 165 701 167 708 169 715 171 722 •流量监控:以太网收、以太网发、IB收、IB发 I/O吞吐(MB/s) 729 173 736 175 743 177 750 179 757 181 764 771 183 778 185 785 187 I/O写 792 189 799 806 191 193 AI计算平台 - TEYE 813 Infiniband收发速率 (MB/s) 820 195 827 197 834 199 841 •包数量监控:以太网平均收/发包大小、IB收/发包数量 848 201 855 203 862 205 869 207 876 接收速率 209 883 890 211 897 213 904 215 911 217 918 925 219 932 221 939 223 946 225 953 227 960 967 229 974 231 981 233 988 235 995 1002 237 1009 239 1016 241 1023 243 1030 245 1037 1044 247 1051 249 1058 251 1065 253 1072 255 1079 1086 257 1093 259 1100 261 1107 263 •本地磁盘:本地读、本地写、本地读数据块大小、本地写数据块大小 1114 265 1121 1128 267 1135 269 1142 271 1149 273 1156 1163 275 1170 277 1177 279 1184 281 1191 283 1198 1205 285 1212 287 1219 289 •NFS文件系统:NFS客户端读、NFS客户端写、NFS服务端(总)读、NFS服务端 1226 291 1233 1240 293 1247 295 1254 297 1261 299 1268 301 303
27 . AI计算平台 - TEYE 显示各指标的数据分布情况,横向比较各指标,发掘各指标对应用性能的影响及相互之间 的关联,发现性能瓶颈,有针对性的进行优化,消除瓶颈。 TensorFlow Caffe MXNet CPU GPU
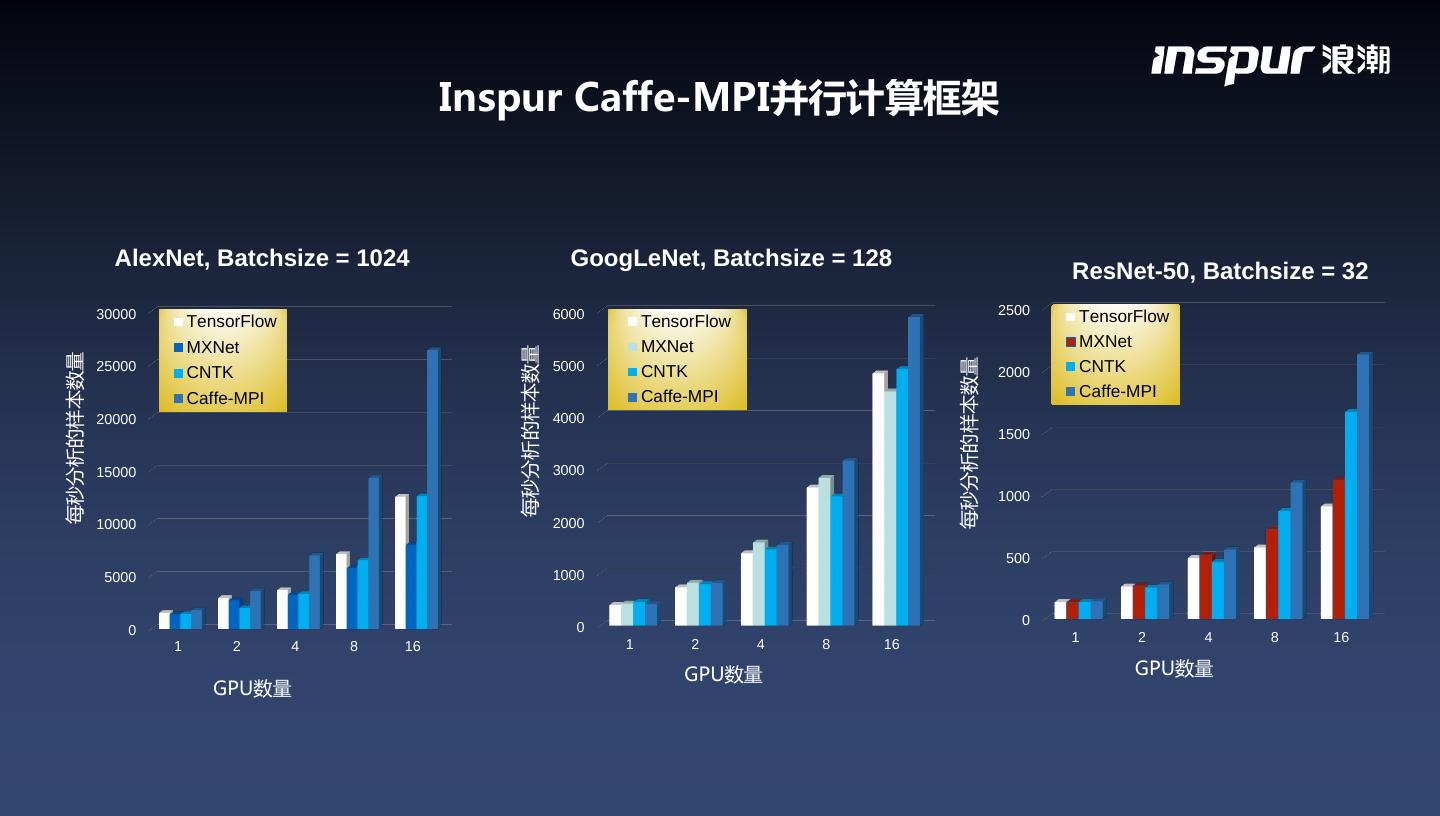
28 . Inspur Caffe-MPI并行计算框架 images/s 全球首个集群并行版的Caffe深度学习计算框架,基于BVLC Caffe开发,在算法设计 上进行了突破:节点内GPU卡间及节点间RDMA两层通信模式,克服了传统通信模式中 PCIE与网络之间带宽不均衡的影响,极大降低了网络通信的压力,非常适合高密度GPU 服务器。基于Imagenet数据集进行深度学习模型训练,Caffe-MPI表现出良好的并行扩 展,较单卡性能提升13倍。 环形通信:NCCL2.0 GPU3 GPU2 GPU1 GPU0 GPU0 GPU1 GPU2 GPU3 server1 server2 开源地址:https://github.com/Caffe-MPI/Caffe-MPI.github.io
29 . Inspur Caffe-MPI并行计算框架 AlexNet, Batchsize = 1024 GoogLeNet, Batchsize = 128 ResNet-50, Batchsize = 32 30000 6000 2500 TensorFlow TensorFlow TensorFlow MXNet MXNet MXNet 每秒分析的样本数量 每秒分析的样本数量 每秒分析的样本数量 25000 CNTK 5000 CNTK 2000 CNTK Caffe-MPI Caffe-MPI Caffe-MPI 20000 4000 1500 15000 3000 1000 10000 2000 500 5000 1000 0 0 0 1 2 4 8 16 1 2 4 8 16 1 2 4 8 16 GPU数量 GPU数量 GPU数量
3秒后跳转登录页面
去登陆

