

































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
XOM-Switch - Black Hat
Since keys are assigned to pages in the page-table entries, only the kernel can change those.” ... eXecutable Only Memory Supported in Linux 4.9+. Enhanced ...
展开查看详情
1 .eXecutable-Only-Memory-Switch (XOM-Switch) Hiding Your Code From Advanced Code Reuse Attacks in One Shot Mingwei Zhang, Ravi Sahita (Intel Labs) Daiping Liu (University of Delaware) 1
2 .[Short BIO of Speaker] Mingwei Zhang is currently a research scientist in Anti-Malware Team in Intel Labs. His current research areas span a wide range of topics including program hardening using Intel hardware features , anti-malware techniques , dynamic sandboxing for Android and etc. Mingwei received his Ph.D of computer science from Stony Brook University in 2015. His research in the Ph.D program was focused on software security protection via binary rewriting and program analysis. https://www.linkedin.com/in/mingwayzhang https://scholar.google.com/citations?user=llCSAtwAAAAJ&hl=en http://www3.cs.stonybrook.edu/~mizhang / 2
3 .Agenda Problem Statement and Motivation Intel’s protection keys design and implementation. Binary r ewriting in program loader Evaluation Conclusion 3
4 .Code Reuse Attacks Effective way to bypass DEP, i.e., executing code without code injection. Code reuse attacks requires accurate locations of “gadgets”, which may Suffer from code diversity and availability. Advanced Code Reuse Attacks. JIT-ROP : Harvesting code pages and dynamically constructing gadgets at runtime. (JIT-ROP SP’13) Blind-ROP: Blindly chaining simple gadgets to launch a ret2libc attack that reads code and constructs gadgets offline followed by a complicated ROP attack ( Hacking Blind SP’14). 4
5 .0101001110101110 Traditional Code Reuse Attacks Just-In-Time Code Reuse Attacks 1 st ROP harvest code pages 2 st ROP launch real attack Blind Code Reuse Attacks 5
6 .Reason of Advanced ROP: Convenience : Robustness of attacks on binaries in many versions. Robustness on defenses like fine grained code randomizations. Larger attack vector : Both JIT-ROP and BROP makes significant threat to close-source/private-distribute binaries. Advanced ROP attacks require code reading capability. This is why defenses on eXecutable Only Memory. 6
7 .Prevention on advanced code reuse focuses on eXecutable Only Memory. Using page fault handler: XnR (CCS ’14) Using Extended Page Table: X^R Using side effects in micro-architecture: HideM Using hardware support in ARM: NORAX They are all beautiful, but they have their own drawbacks High runtime overhead . Require Hypervisor support (nested virtualization in cloud?) Significant effort on Code Refactoring/Rewriting/Recompilation. Not available on x86 architecture (not available for cloud apps) eXecutable Only Memory could be easily achieved using new Intel hardware capability 7
8 .Intel Protection Keys 8
9 .Intel Protection Keys 8
10 .How is Intel’s MPK named? Protection Keys , defined in Intel Software Developer Manual Volume 3a, part1, page 135 . Properties? Fast permission switches of user level pages . Allows pages to be “ read-only ” or “ inaccessible ”. 10
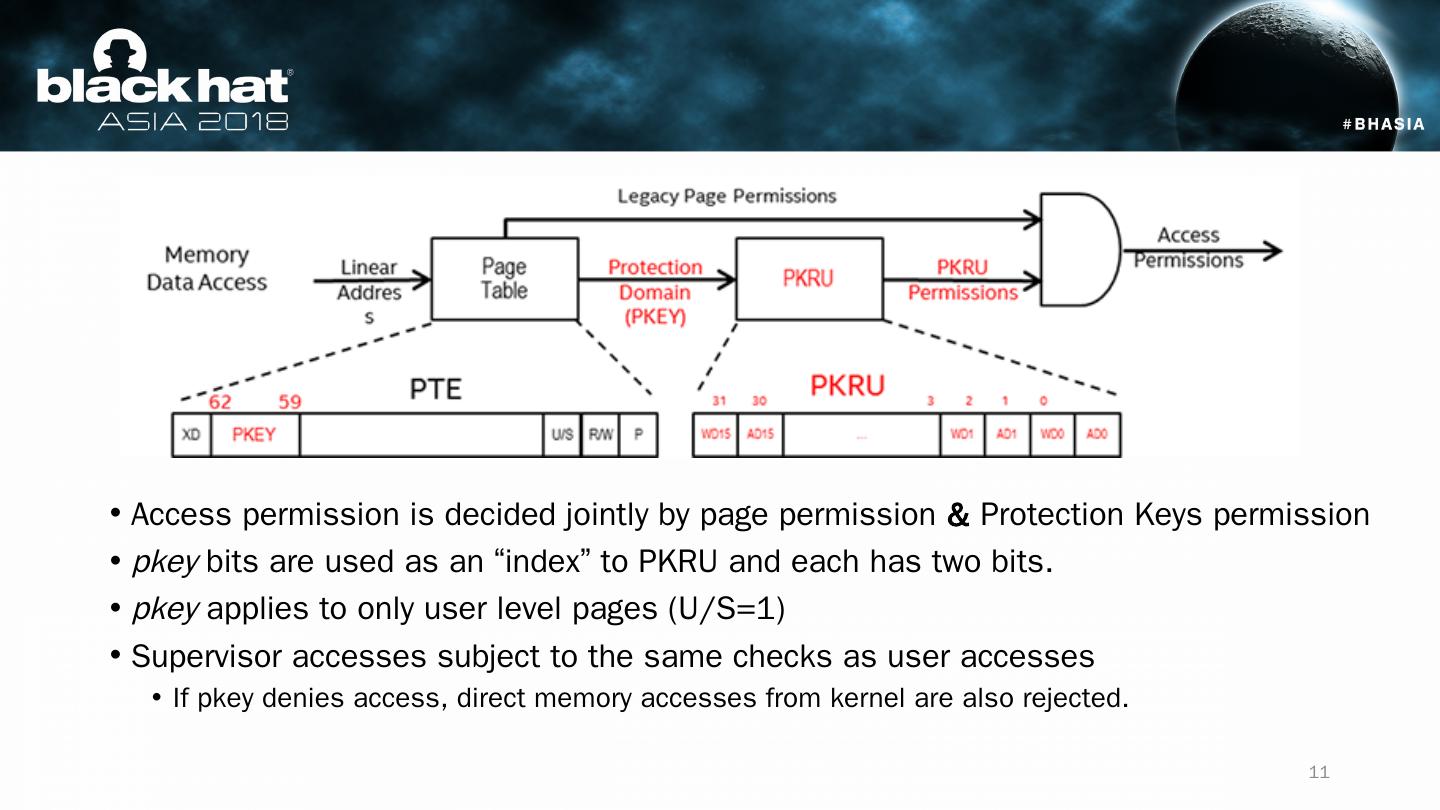
11 .Access permission is decided jointly by page permission & Protection Keys permission pkey bits are used as an “index” to PKRU and each has two bits. pkey applies to only user level pages (U/S=1) Supervisor accesses subject to the same checks as user accesses If pkey denies access, direct memory accesses from kernel are also rejected. 11
12 .Primitives: 3 new syscalls and 2 new instructions added : New Syscall : int pkey_alloc (unsigned long flags, unsigned long initial_rights ); New Syscall : int pkey_mprotect (void *start, size_t len , int prot , int pkey); New Syscall : int pkey_free ( int key); New Insn : wrpkru /* change memory permission of pages that bind to a pkey. */ New Insn : rdpkru /* get the memory permission of a pkey */ 12
13 .Turned on for each process. 16 keys per process Each key could bind to a large number of non-contiguous memory regions. Permission change by one instruction “ wrpkru ” Permission is per-thread based. 13 rw rw rw Pkey # 1 (thread #1) Disable write None None None Unintended/malicious read/write Permission by mmap / mprotect Permission by pkey (thread #1) Intel CPU PKRU (thread #1) DRAM PKRU (thread #2) Pkey #1 (thread #2) r r r Permission by pkey (thread #2) Performance: 60 ~ 120 cycles for wrpkru . Almost no relevance to memory range size. In compare, 20,000 cycles for one “ mprotect ”.
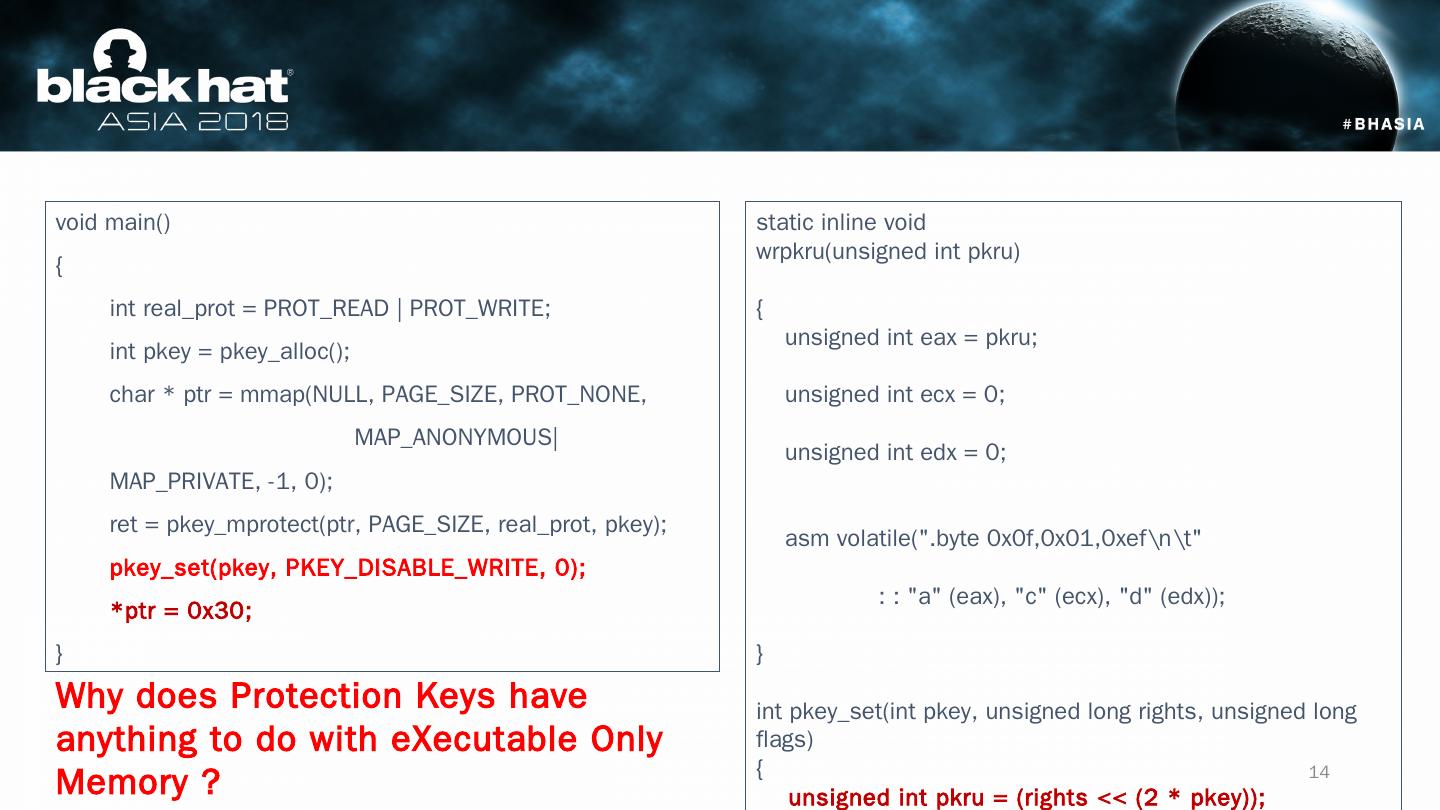
14 .void main() { int real_prot = PROT_READ | PROT_WRITE; int pkey = pkey_alloc (); char * ptr = mmap (NULL, PAGE_SIZE, PROT_NONE, MAP_ANONYMOUS|MAP_PRIVATE, -1, 0); ret = pkey_mprotect ( ptr , PAGE_SIZE, real_prot , pkey ); pkey_set ( pkey , PKEY_DISABLE_WRITE, 0); * ptr = 0x30; } static inline void wrpkru (unsigned int pkru ) { unsigned int eax = pkru ; unsigned int ecx = 0; unsigned int edx = 0; asm volatile(".byte 0x0f,0x01,0xef " : : "a" ( eax ), "c" ( ecx ), "d" ( edx )); } int pkey_set ( int pkey , unsigned long rights, unsigned long flags) { unsigned int pkru = (rights << (2 * pkey )); wrpkru ( pkru ); return 0; } pkey_set () disables the memory write access using wrpkru instruction (opcode: 0x0f 0x01) Why does Protection Keys have anything to do with eXecutable Only Memory ? 14
15 .Protection Keys can be used for eXecutable Only Memory Marking a code page “inaccessible” does not prevent execution eXecutable Only Memory Supported in Linux 4.9+ Enhanced mprotect ( addr , PROT_EXEC) = 0 Makes a code page executable only. Update: glibc adopts Protection Keys support in 12/2017. However, Support of XOM is missing in both GLIBC and compiler! Recompiling/rewriting code is needed 15
16 .Applying Protection Keys based eXecutable Only Memory to ELF Binaries. 16
17 .We use a static binary rewriting to enable Protection Keys on ELF executables and libraries with the following key features: No source code or significant binary rewriting/translation needed. Almost no runtime overhead and works on large applications. Open source (GPLv2 and later) for community. 17
18 .Assumptions You have Intel CPU with Protection Keys feature turned on AND You have Linux kernel 4.9+ that supports Protection Keys OR you have Amazon AWS account and launch an C5 instance [1] Idea Identifying code pages of a program at load time and marking them as executable. Challenges Applying Protection Keys accurately on just code pages. Applying Protection Keys on all ELF binaries including dependent libraries Attackers may subvert XOM by abusing wrpkru / xsave 18
19 .Challenge #1: Code and data mixed in Binary. ELF has two “views ” Information is lost from link time to runtime . ELF header PHDR 19
20 .ELF header PHDR Challenge #1: Code and data mixed in Binary. ELF has two “views” Runtime code segment mixes: ELF metadata Read-only data Data in the middle of code (jump tables, lookup tables and/or compiler issues). We use section table information to discover code pages. 20
21 .Challenge #2: Applying Protection Keys on all ELF binaries. Need to do it at runtime… executable path is known, but libraries may not be known until runtime. Need to find the right method/place to hook. LD_PRELOAD/LD_LIBRARY_PATH: too late Protection Keys enabling in kernel: cumbersome Recompiling program loader (ld.so): cumbersome/unstable recompile the whole glibc libraries. l d.so incompatible with libc.so.6 in different compilation . Recompiled glibc may have compatibility issues with other libs ( e.g , libstdc ++.so.6) XOM-switch does not require recompilation of glibc or heavyweight binary rewriting 21
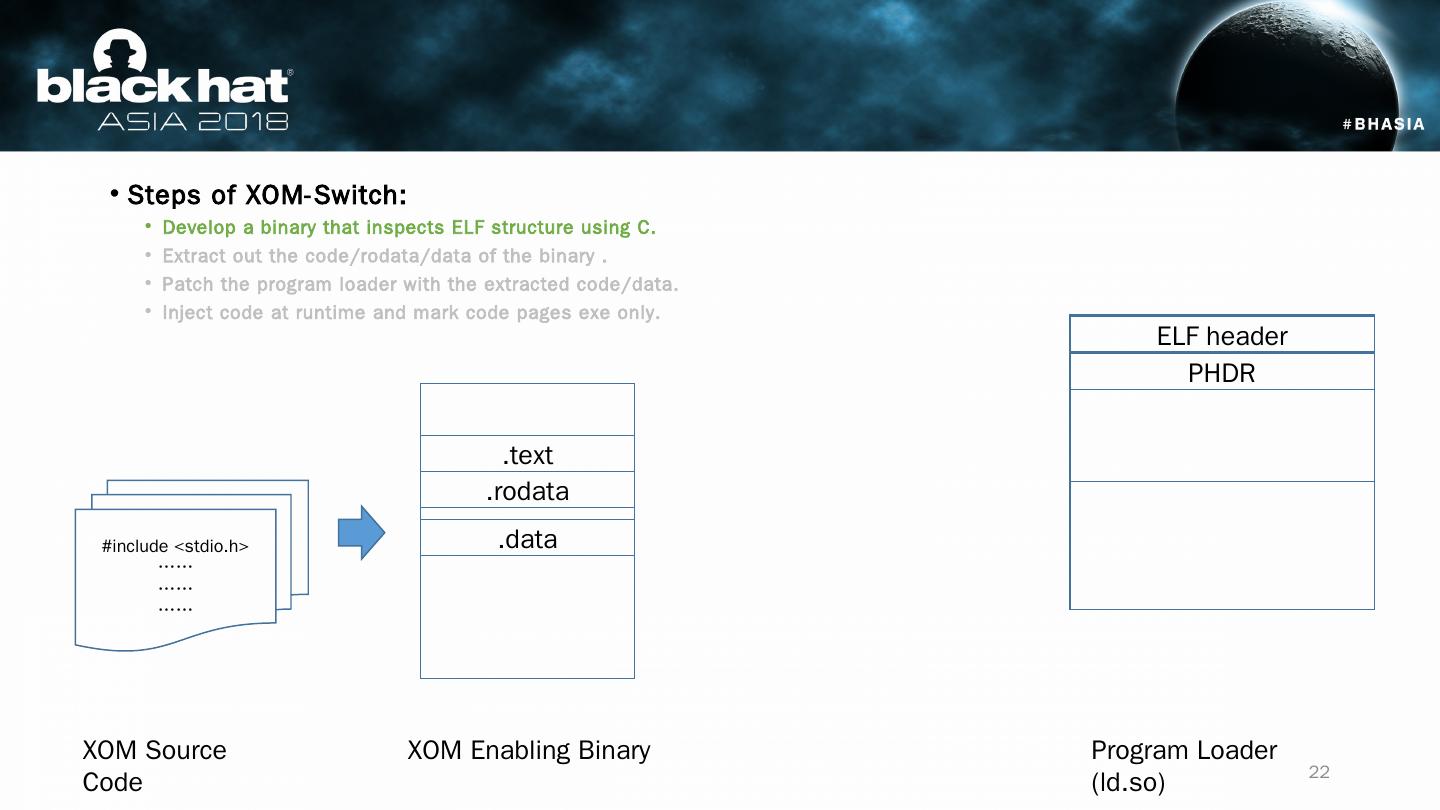
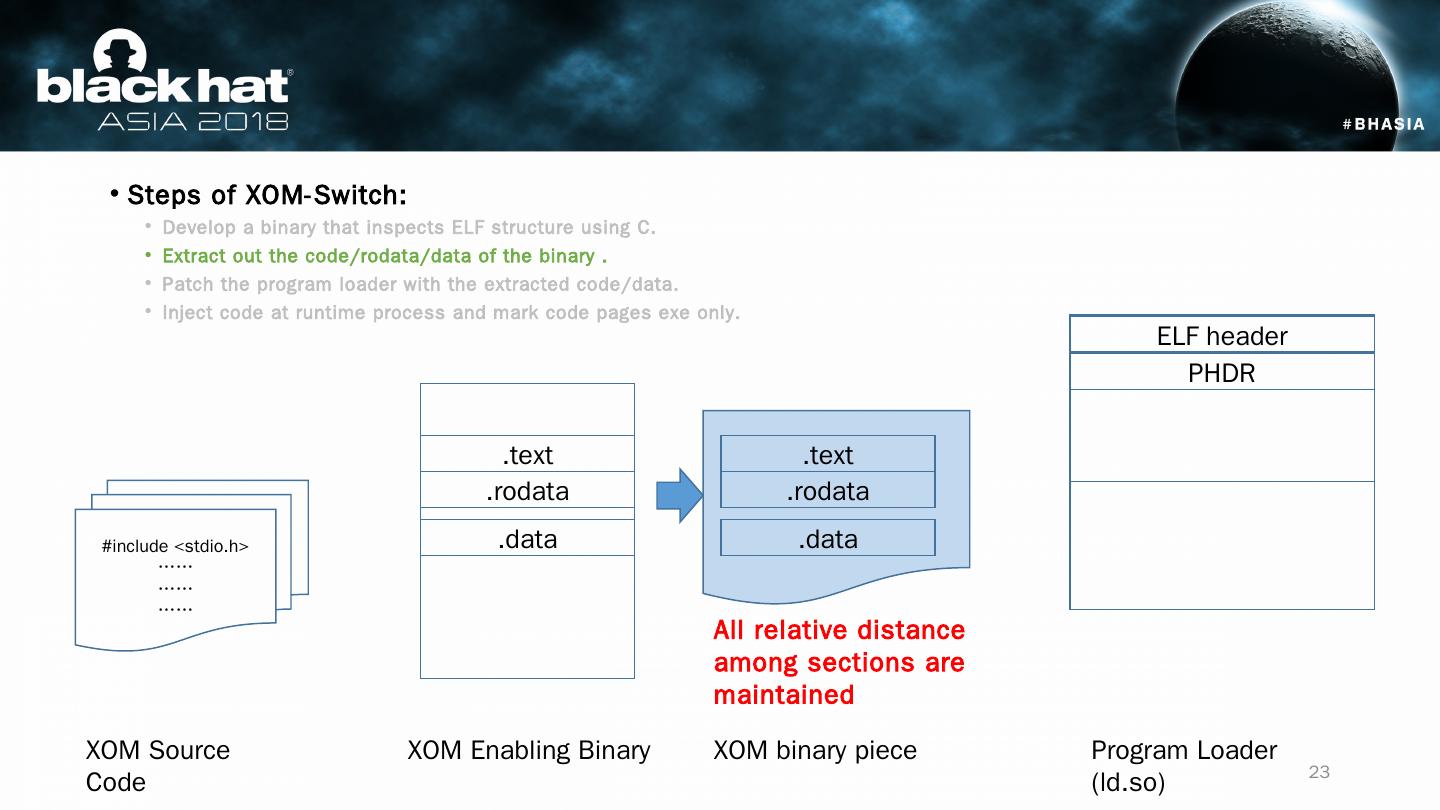
22 .Steps of XOM-Switch: Develop a binary that inspects ELF structure using C. Extract out the code/ rodata /data of the binary . Patch the program loader with the extracted code/data. Inject code at runtime and mark code pages exe only. #include < stdio.h > …… …… …… XOM Source Code XOM Enabling Binary Program Loader (ld.so) ELF header PHDR .text .rodata .data 22
23 .Steps of XOM-Switch: Develop a binary that inspects ELF structure using C. Extract out the code/ rodata /data of the binary . Patch the program loader with the extracted code/data. Inject code at runtime process and mark code pages exe only. #include < stdio.h > …… …… …… XOM Source Code XOM Enabling Binary Program Loader (ld.so) ELF header PHDR .text .rodata .data .text .rodata .data XOM binary piece All relative distance among sections are maintained 23
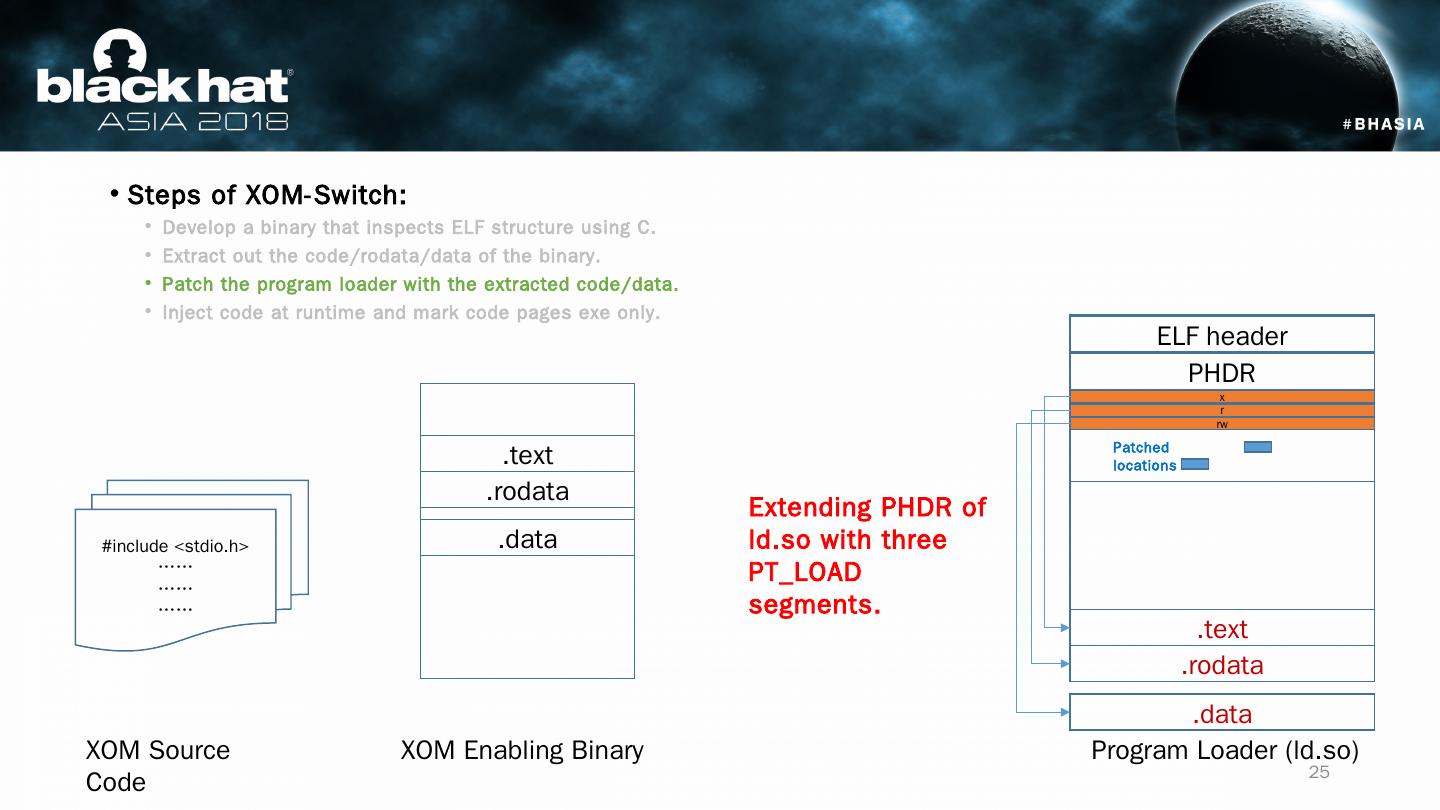
24 .Steps of XOM-Switch: Develop a binary that inspects ELF structure using C. Extract out the code/ rodata /data of the binary. Patch the program loader with the extracted code/data. Inject code at runtime process and mark code pages exe only. #include < stdio.h > …… …… …… XOM Source Code XOM Enabling Binary Program Loader (ld.so) ELF header PHDR .text .rodata .data .text .rodata .data XOM binary piece .text .rodata .data .text .rodata .data All relative distance among sections are maintained 24
25 .Steps of XOM-Switch: Develop a binary that inspects ELF structure using C. Extract out the code/ rodata /data of the binary. Patch the program loader with the extracted code/data. Inject code at runtime and mark code pages exe only. #include < stdio.h > …… …… …… XOM Source Code XOM Enabling Binary Program Loader (ld.so) ELF header PHDR .text .rodata .data x Extending PHDR of ld.so with three PT_LOAD segments. .text .rodata .data r rw Patched locations 25
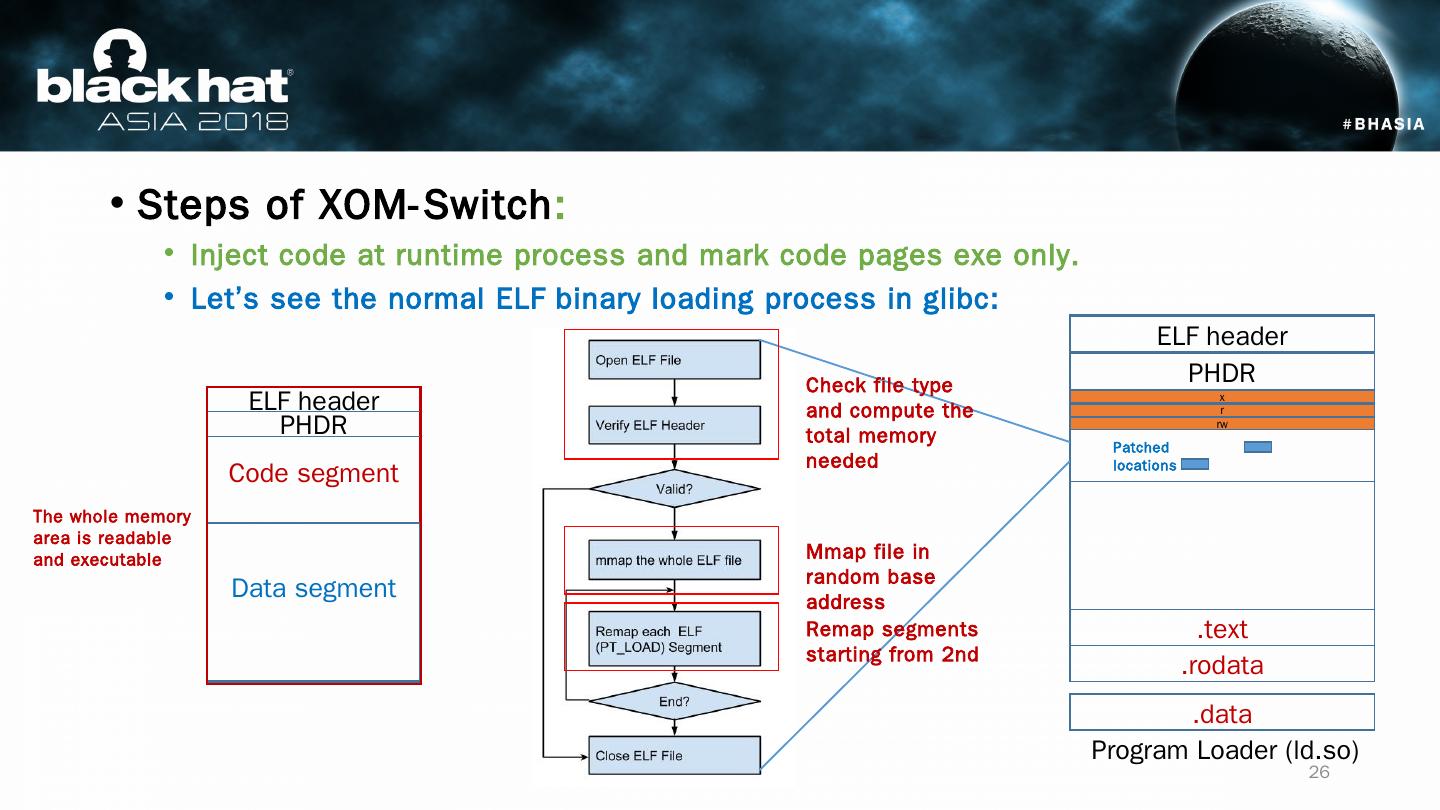
26 .Steps of XOM-Switch : Inject code at runtime process and mark code pages exe only . Let’s see the normal ELF binary loading process in glibc : Program Loader (ld.so) ELF header PHDR x .text .rodata .data r rw Patched locations Code segment Data segment ELF header PHDR Mmap file in random base address Remap segments starting from 2nd Check file type and compute the total memory needed The whole memory area is readable and executable 26
27 .Steps of XOM-Switch : Injected code at runtime process all ELF loaded and mark code pages exe only . Now let’s see the modified (patched) ELF binary loading process Program Loader (ld.so) ELF header PHDR x .text .rodata .data r rw Patched locations Code segment (exe only) Data segment Map elf metadata as read only Map code sections as exe only Load section table and do analysis Map rodata as read only metadata rodata Section table The whole memory area initially is read only m map whole file as read only 27
28 .Challenge #3: Abusing Protection Keys to disable XOM Attackers may use gadgets that contain wrpkru / xsave to disable XOM! ff 15 0f 01 ef c3 callq *-0x3c10fef1(%rip) 0f 01 ef wrpkru c3 ret m alicious control flow Intended control flow 28
29 .Challenge #3: Abusing Protection Keys to disable XOM We could potentially scan the code sections and rewrite dangerous instructions We could also reset PKRU on each system call. Ultimate solution: Intel CET. (not immediately available) Program Loader (ld.so) ELF header PHDR x .text .rodata .data r rw Patched locations Code segment (exe only) Data segment Scan the code sections and rewrite any wrpkru gadgets Map code sections as exe only Map rodata as read only metadata rodata Defense #2: Linux kernel: reset PKRU at each system call …… Code rewritten The defense is limited in power, but could be helped by CFI/code randomizations. 29
3秒后跳转登录页面
去登陆

