































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
ad.pptx
Graphic courtesy Andrew Ng, others. Linear Decision Boundary. Basic Idea Behind Anomaly Detection. Collected 'Nominal' Data. Idea: Assume that a boundary ...
展开查看详情
1 .Anomaly Detection Introduction and Use Cases Derick Winkworth , Ed Henry and David Meyer
2 .Agenda Introduction and a Bit of History So What Are Anomalies? Anomaly Detection Schemes Use Cases Current Events Q&A
3 .Introduction Anomaly Detection: What and Why It is clear that one of the major challenges we face as a civilization is dealing with deluge of data that are being collected from our networks at global (and beyond) scale W hile at the same time we are “knowledge starved” Can’t find the needles in an exponentially growing haystack Anomaly Detection is one piece of the puzzle Machine Learning is a fundamental part of the answer Key Assumption for Anomaly Detection Anomalous events occur relatively infrequently (alternatively: most events normal) Second order assumption: Common events follow a Gaussian distribution (likely to be wrong) What is obvious: When anomalous events do occur, their consequences can be quite serious and often have substantial negative impact on our businesses, security, …
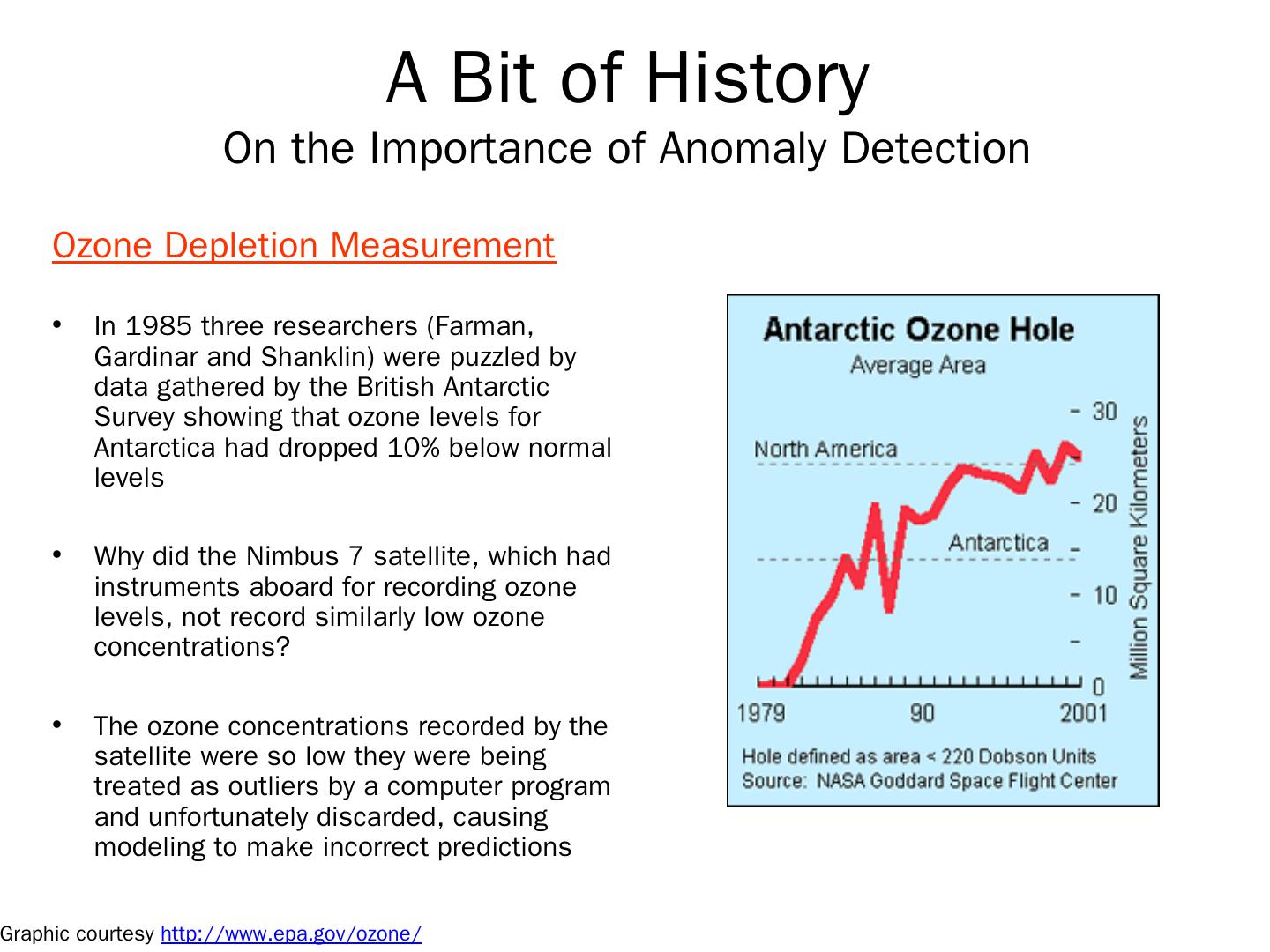
4 .A Bit of History On the Importance of Anomaly Detection Ozone Depletion Measurement In 1985 three researchers (Farman, Gardinar and Shanklin) were puzzled by data gathered by the British Antarctic Survey showing that ozone levels for Antarctica had dropped 10% below normal levels Why did the Nimbus 7 satellite, which had instruments aboard for recording ozone levels, not record similarly low ozone concentrations? The ozone concentrations recorded by the satellite were so low they were being treated as outliers by a computer program and unfortunately discarded, causing modeling to make incorrect predictions Graphic courtesy http://www.epa.gov/ozone/
5 .A Bit of History On the Importance of Anomaly Detection Ozone Depletion Measurement In 1985 three researchers (Farman, Gardinar and Shanklin) were puzzled by data gathered by the British Antarctic Survey showing that ozone levels for Antarctica had dropped 10% below normal levels Why did the Nimbus 7 satellite, which had instruments aboard for recording ozone levels, not record similarly low ozone concentrations? The ozone concentrations recorded by the satellite were so low they were being treated as outliers by a computer program and unfortunately discarded, causing modeling to make incorrect predictions Graphic courtesy http://www.epa.gov/ozone/
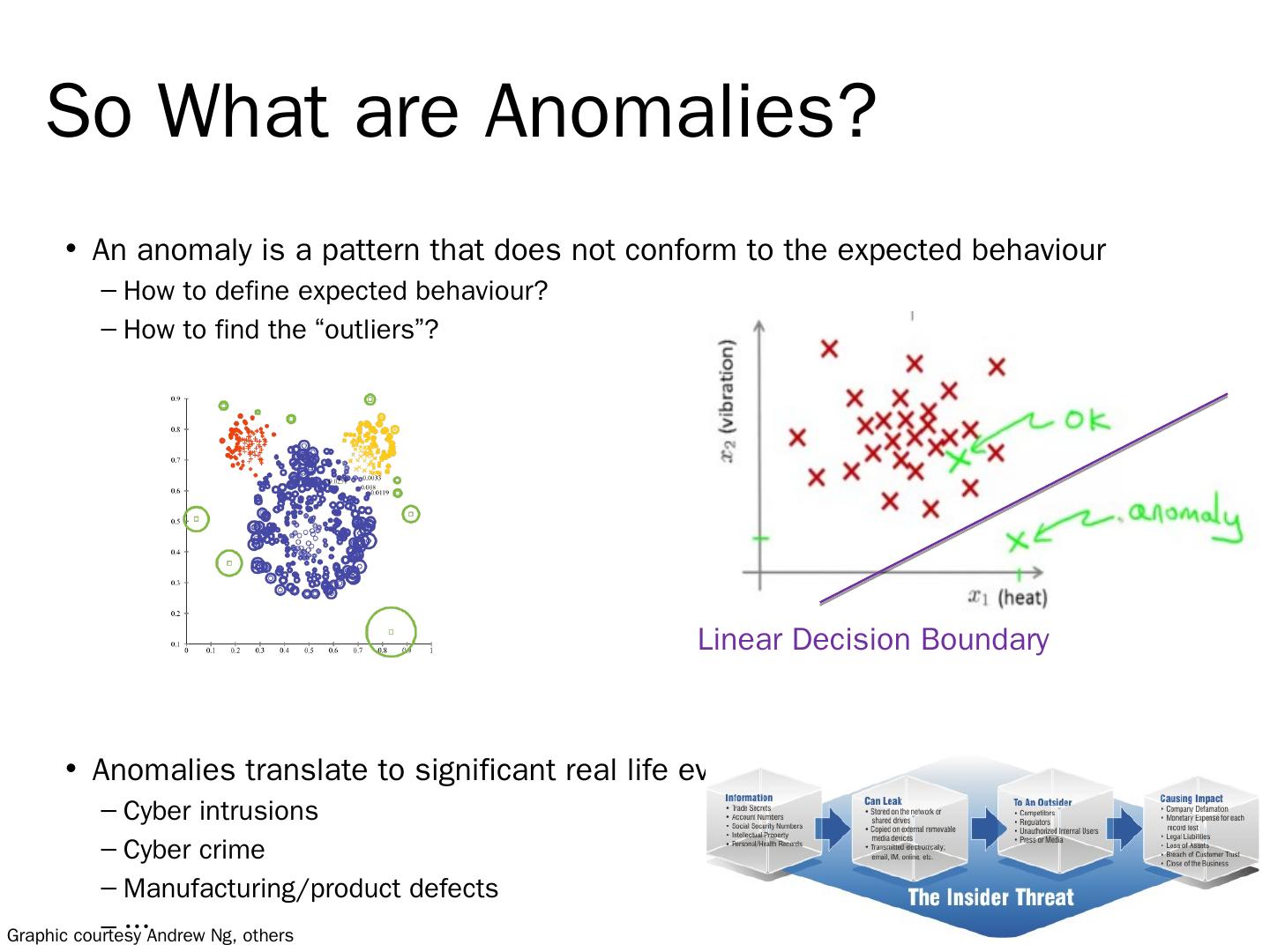
6 .So What are Anomalies? An anomaly is a pattern that does not conform to the expected behaviour How to define expected behaviour? How to find the “outliers”? Anomalies translate to significant real life events Cyber intrusions Cyber crime Manufacturing/product defects … Graphic courtesy Andrew Ng, others Linear Decision Boundary
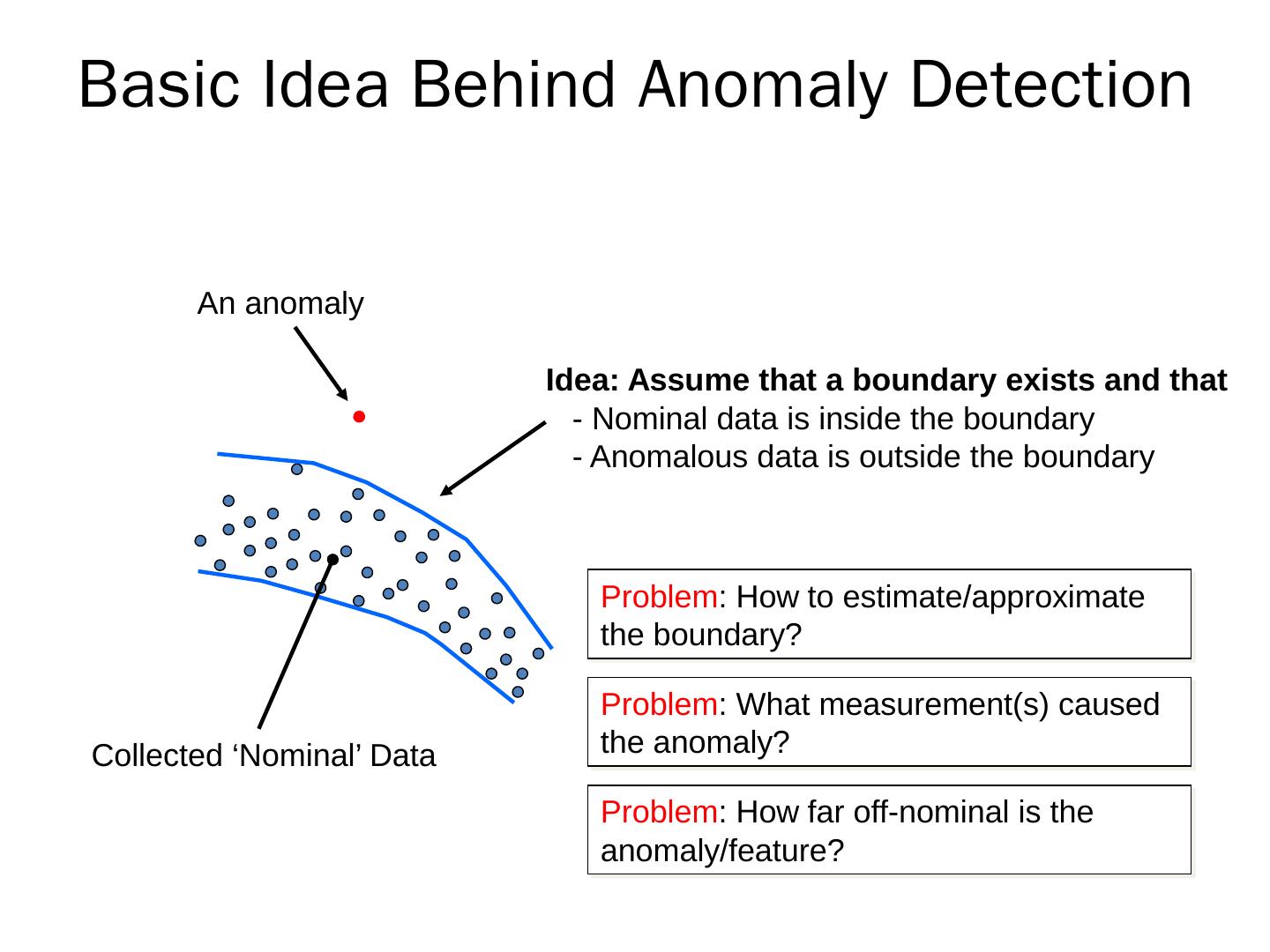
7 .Basic Idea Behind Anomaly Detection Collected ‘Nominal’ Data Idea: Assume that a boundary exists and that - Nominal data is inside the boundary - Anomalous data is outside the boundary An anomaly Problem : How to estimate/approximate the boundary? Problem : What measurement(s) caused the anomaly? Problem : How far off-nominal is the anomaly/feature ?
8 .Simple Example N 1 and N 2 are regions of normal behaviour Say, normal flows in a network Points o 1 and o 2 are anomalies Points in region O 3 are anomalies Challenge: How to define “normal” regions? How to find the outlier points? This is the job of machine learning X Y N 1 N 2 o 1 o 2 O 3
9 .Simple Example N 1 and N 2 are regions of normal behaviour Say, normal flows in a network Points o 1 and o 2 are anomalies Points in region O 3 are anomalies Challenge: How to define “normal” regions? How to find the outlier points? This is the job of machine learning X Y N 1 N 2 o 1 o 2 O 3
10 .Anomaly Detection Schemes General Steps Build a profile of the “normal” behavior Profile can be patterns or summary statistics for the overall population Use the “normal” profile to detect anomalies Anomalies are observations whose characteristics differ significantly from the normal profile Types of anomaly detection schemes Graphical & Statistical-based Distance-based Model-based FP Mining, K-means, …
11 .3 Main Types of Anomaly Point Anomalies Contextual Anomalies Collective Anomalies
12 .Point Anomalies An individual data instance is anomalous if it deviates significantly from the rest of the data set. X Y N 1 N 2 o 1 o 2 O 3 Anomaly
13 .Contextual Anomalies I ndividual data instance is anomalous within a context Requires a notion of context Also referred to as conditional anomalies Normal Anomaly
14 .Collective Anomalies A collection of related data instances is anomalous Requires a relationship among data instances Sequential Data Spatial Data Graph Data The individual instances within a collective anomaly are not anomalous by themselves Anomalous Subsequence Anomalous Subsequence
15 .Key Challenges for Anomaly Detection Algorithms Defining a representative normal region is challenging The boundary between normal and outlying behaviour is often not precise The exact notion of an outlier is different for different application domains Availability of labelled data for training/validation (unsupervised learning) Malicious adversaries Data is very noisy False positive/negatives Normal behaviour keeps evolving
16 .Machine Learning Approaches Time-Based Inductive Methods U se probability and a directed graph to predict the next event Bayesian approaches Can also use undirected approaches (Markov Random Fields) Instance Based Learning Define a distance to measure the similarity between feature vectors K-Means, … Neural Networks This is where we want to go …
17 .V ery good at creating hyper-planes for separating between classes e .g., anomalous vs. normal Non-linear decision boundaries Extremely powerful models for mapping vector spaces Good when dealing with huge data sets/handles noisy data well Downside: Training can be compute intensive Aside: Why Use Neural Networks?
18 .Summary Challenges Many, but the key ones include: What is normal? Where are the outliers (and what do they look like)? What is the shape of the boundary between the two? False positive/negative mitigation Method is unsupervised (unsupervised learning) Validation can be challenging (just like for clustering ) Finding a needle in a haystack And the haystack is growing at an exponential rate Both in raw terms (size of data sets) and Dimensionality of data items (curse of dimensionality) Both make finding outliers more challenging Key working assumptions There are considerably more normal than abnormal observations Normal observations follow a Gaussian distribution (likely wrong) p( X;μ,σ ) < ϵ
19 .What is the I ssue with Dimensionality? Machine Learning is good at understanding the structure of high dimensional spaces Humans aren’t What is a dimension? Informally… A direction in the input vector “Feature” Example: MNIST dataset Mixed NIST dataset Large database of handwritten digits, 0-9 28x28 images 784 (28 2 ) dimensional input data (in pixel space) Consider 4K TV 4096x2160 = 8,847,360 dimensions in the pixel space But why care? Because interesting and unseen relationships frequently live in high- dimensional spaces
20 .But There’s a Hitch The Curse Of Dimensionality To generalize locally , you need representative examples from all relevant variations But there are an exponential number of variations So local representations might not (don ’ t) scale Classical Solution: Hope for a smooth enough target function, or make it smooth by handcrafting good features or kernels. But this is sub-optimal. Alternatives? Mechanical Turk (get more examples) Deep learning Distributed Representations Unsupervised Learning … (i). Space grows exponentially (ii). Space is stretched, points become equidistant See also “Error, Dimensionality, and Predictability”, Taleb, N. & Flaneur, https://dl.dropboxusercontent.com/u/50282823/Propagation.pdf for a different perspective
21 .But There’s a Hitch The Curse Of Dimensionality To generalize locally , you need representative examples from all relevant variations But there are an exponential number of variations So local representations might not (don ’ t) scale Classical Solution: Hope for a smooth enough target function, or make it smooth by handcrafting good features or kernels. But this is sub-optimal. Alternatives? Mechanical Turk (get more examples) Deep learning Distributed Representations Unsupervised Learning … (i). Space grows exponentially (ii). Space is stretched, points become equidistant See also “Error, Dimensionality, and Predictability”, Taleb, N. & Flaneur, https://dl.dropboxusercontent.com/u/50282823/Propagation.pdf for a different perspective
22 .Presentation Layer Domain Knowledge Domain Knowledge Domain Knowledge Domain Knowledge Data Collection Packet brokers, flow data, … Preprocessing Big Data, Hadoop, Data Science, … Model Generation Machine Learning Oracle Model(s) Oracle Logic Remediation/Optimization / … 3 rd Party Applications Learning Analytics Platform Workflow Schematic Intelligence Topology, Anomaly Detection, Root Cause Analysis, Predictive Insight, …. Intent Anomaly Detection
23 .Obvious Use Cases Intrusions Actions that attempt to bypass security mechanisms E.g., unauthorized access, inflicting harm, etc . Example intrusions Denial-of-service attacks Scans Worms and viruses Host compromises Intrusion detection Monitoring and analyzing traffic Identifying abnormal activities Assessing severity and raising alarms Kill-chain Lifecycle Management In general, look at Enterprise Cybersecurity Information leakage, data misuse, … Includes endpoint identity, role and behavior analysis Needed to identify Insider threats/data breaches
24 .Simple Example: Application Profiling Goal: Build t ools for the DevOps environment Provide deeper automation and new capabilities/insight F irst application: Anomaly Detection Low Hanging Fruit: Use Frequent Pattern Mining and K-Means to learn/predict anomalous application behavior Detecting unusual access to intellectual property and internal systems Identifying abnormal financial trading activities or asset allocations Proving alerts when behaviors or actions fall outside of typical patterns T raditional anomaly detection; use a variety of methods Detect the installation, activation, or usage of unapproved software Alert when computers or devices are used in unauthorized ways … L et’s briefly look at FP Mining and K-Means
25 .Frequent Pattern Mining and K-Means FP Mining finds patterns in categorical data Returns “itemsets” S ets of Transaction IDs (TIDs) corresponding to some pattern [src ,dest, srcprt , destprt ,oif, appname,…] K-Means finds clusters in continuous data A cluster can be things like The set of TIDs that show congestion, … TID sets (clusters) Putting these algorithms together allows us to make the following (very) simple inference: TIDset FP ∧ TIDset K-Means patterns that cluster together “These application patterns may result in anomalous behavior”
26 .A Little More on K-Means K-Means Algorithm In words Randomly initialize cluster centroids (the μ i ’s ) Until convergence Assign each observation to the closest cluster centroid Update each centroid to the mean of the points assigned to it Can show that this algorithm minimizes this distortion function
27 .Application Profiling, cont First, we need data (obvious, but ingestion, … not trivial) Lots of frameworks/engines (spark, storm, tigon/cask.io,…) Data we have (public datasets, collected here @brcd) Network and endpoint information Environmental sensor data Chef/Puppet, Openstack Heat, server/cluster state,… … The FP-KMeans pipeline can be used build application profiles Which endpoints an application talks to (and associated templates) Which ports and protocols it uses and associated meta-data, geo-ip, … Flow characteristics including as TOD, volume and duration Other CSNSE configuration associated with the application ACL/QoS, routing policies,… … We are really limited only by our imagination and (of course) our datasets Primarily descriptive/diagnostic analyzes
28 .Application Profiling, cont First, we need data (obvious, but ingestion, … not trivial) Lots of frameworks/engines (spark, storm, tigon/cask.io,…) Data we have (public datasets, collected here @brcd) Network and endpoint information Environmental sensor data Chef/Puppet, Openstack Heat, server/cluster state,… … The FP-KMeans pipeline can be used build application profiles Which endpoints an application talks to (and associated templates) Which ports and protocols it uses and associated meta-data, geo-ip, … Flow characteristics including as TOD, volume and duration Other CSNSE configuration associated with the application ACL/QoS, routing policies,… … We are really limited only by our imagination and (of course) our datasets Primarily descriptive/diagnostic analyzes
29 .Application Profiling, cont First, we need data (obvious, but ingestion, … not trivial) Lots of frameworks/engines (spark, storm, tigon/cask.io,…) Data we have (public datasets, collected here @brcd) Network and endpoint information Environmental sensor data Chef/Puppet, Openstack Heat, server/cluster state,… … The FP-KMeans pipeline can be used build application profiles Which endpoints an application talks to (and associated templates) Which ports and protocols it uses and associated meta-data, geo-ip, … Flow characteristics including as TOD, volume and duration Other CSNSE configuration associated with the application ACL/QoS, routing policies,… … We are really limited only by our imagination and (of course) our datasets Primarily descriptive/diagnostic analyzes
3秒后跳转登录页面
去登陆

