


















- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
I/O系统
本文主要结束了I/O系统的基本组成及应用。本文首先学习了内存层次结构的通用框架,引出了本文主题i/o系统即输入输出系统,操作系统中负责管理输入输出设备的部分称为i/o系统。学习I/O系统的设计问题。例如:奔腾系统,通过讲述奔腾系统的图解学习输入输出系统性能。利用不同类型的I/O系统模型学习I/O系统的设计。
展开查看详情
1 . ECE 4680 Computer Organization and Architecture I/O Systems Features of I/O devices: performance, benchmarks and types How to connect I/O devices: bus Bus: features, performance, types, connections, timing, arbitration, ECE4680 io.1 April 1, 2003 Common Framework for Memory Hierarchy °Question 1: Where can a Block be Placed • Cache: - direct mapped, n-way set associative • VM: - fully associative °Question 2: How is a block found • index, • index the set and search among elements • search all cache entries or separate lookup table °Question 3: Which block be replaced • Random, LRU, NRU °What happens on a write • write through vs write back • write allocate vs write no-allocate on a write miss ECE4680 io.2 April 1, 2003
2 . The Big Picture: Where are We Now? °Today’s Topic: I/O Systems Network Processor Processor Input Input Control Control Memory Memory Datapath Output Datapath Output ECE4680 io.3 April 1, 2003 I/O System Design Issues (§8.1) • Performance • Expandability • Resilience in the face of failure interrupts Processor Cache Memory - I/O Bus Main I/O I/O I/O Memory Controller Controller Controller Disk Disk Graphics Network ECE4680 io.4 April 1, 2003
3 . Example: Pentium System Organization Processor/Memory Bus PCI Bus I/O Busses ECE4680 io.5 April 1, 2003 I/O System Performance (§8.1) °I/O System performance depends on many aspects of the system(§8.9) • The CPU • The memory system: - Internal and external caches - Main Memory • The underlying interconnection (buses) • The I/O controller • The I/O device • The speed of the I/O software • The efficiency of the software’s use of the I/O devices °Two common performance metrics: • Throughput: I/O bandwidth • Response time: Latency ECE4680 io.6 April 1, 2003
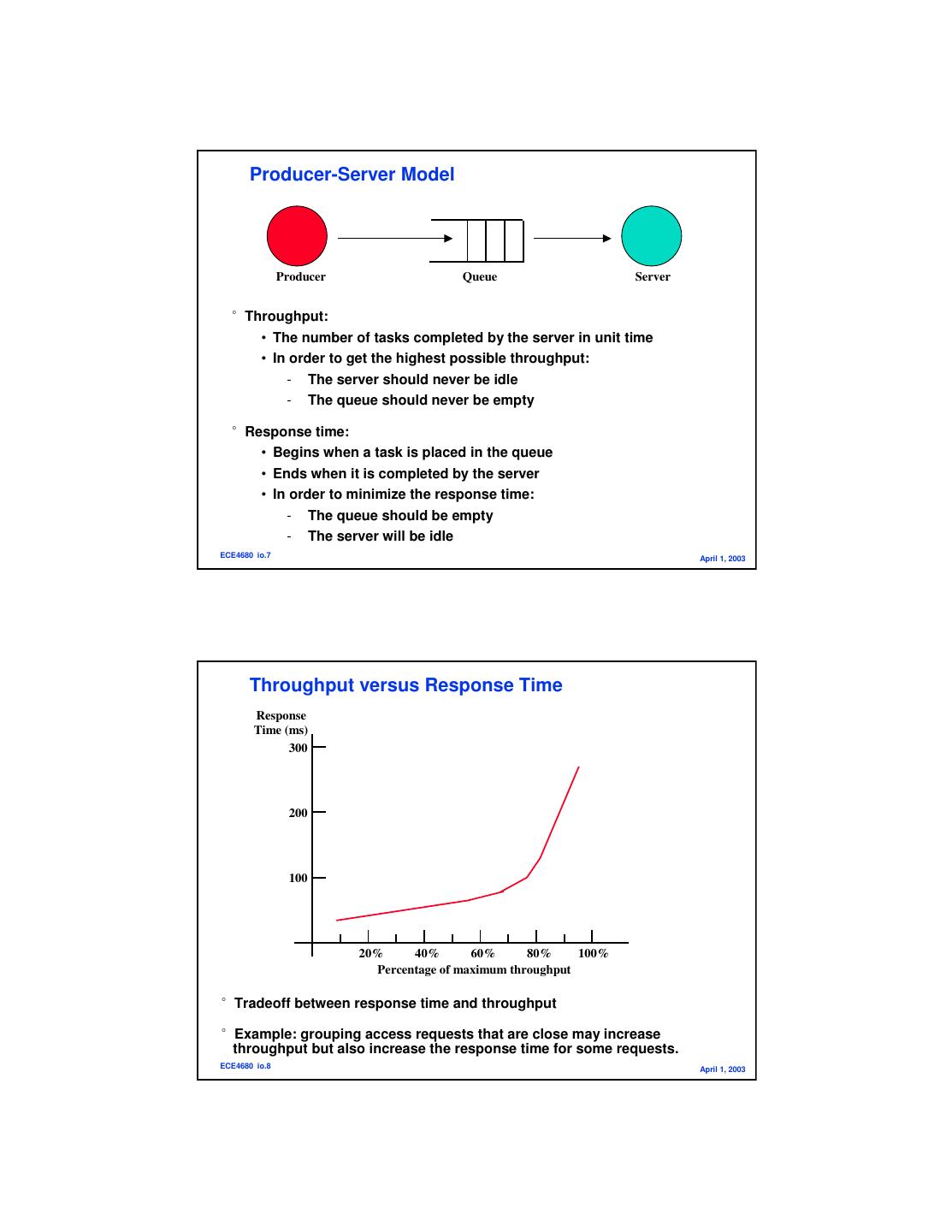
4 . Producer-Server Model Producer Queue Server °Throughput: • The number of tasks completed by the server in unit time • In order to get the highest possible throughput: - The server should never be idle - The queue should never be empty °Response time: • Begins when a task is placed in the queue • Ends when it is completed by the server • In order to minimize the response time: - The queue should be empty - The server will be idle ECE4680 io.7 April 1, 2003 Throughput versus Response Time Response Time (ms) 300 200 100 20% 40% 60% 80% 100% Percentage of maximum throughput °Tradeoff between response time and throughput °Example: grouping access requests that are close may increase throughput but also increase the response time for some requests. ECE4680 io.8 April 1, 2003
5 . Throughput Enhancement Server Queue Producer Queue Server °In general throughput can be improved by: • Throwing more hardware at the problem °Response time is much harder to reduce: • Ultimately it is limited by the speed of light • You cannot bribe God! ECE4680 io.9 April 1, 2003 I/O Benchmarks for Magnetic Disks (§8.2) °Supercomputer application: • Large-scale scientific problems °Transaction processing: • Examples: Airline reservations systems and banks °File system: • Example: UNIX file system ECE4680 io.10 April 1, 2003
6 . Supercomputer I/O °Supercomputer I/O is dominated by: • Access to large files on magnetic disks °Supercomputer I/O consists of one large read (read in the data) • Many writes to snapshot the state of the computation °Supercomputer I/O consists of more output than input °The overriding supercomputer I/O measures is data throughput: • Bytes/second that can be transferred between disk and memory ECE4680 io.11 April 1, 2003 Transaction Processing I/O °Transaction processing: • Examples: airline reservations systems, bank ATMs • A lot of small changes to a large body of shared data °Transaction processing requirements: • Throughput and response time are important • Must be gracefully handling certain types of failure °Transaction processing is chiefly concerned with I/O rate: • The number of disk accesses per second °Each transaction in typical transaction processing system takes: • Between 2 and 10 disk I/Os • Between 5,000 and 20,000 CPU instructions per disk I/O ECE4680 io.12 April 1, 2003
7 . File System I/O °Measurements of UNIX file systems in an engineering environment: • 80% of accesses are to files less than 10 KB • 90% of all file accesses are to data with sequential addresses on the disk • 67% of the accesses are reads • 27% of the accesses are writes 100% • 6% of the accesses are read-write accesses ECE4680 io.13 April 1, 2003 Types and Characteristics of I/O Devices (§8.3) °Behavior: how does an I/O device behave? • Input: read only • Output: write only, cannot read • Storage: can be reread and usually rewritten °Partner: • Either a human or a machine is at the other end of the I/O device • Either feeding data on input or reading data on output °Data rate: • The peak rate at which data can be transferred: - Between the I/O device and the main memory - Or between the I/O device and the CPU ECE4680 io.14 April 1, 2003
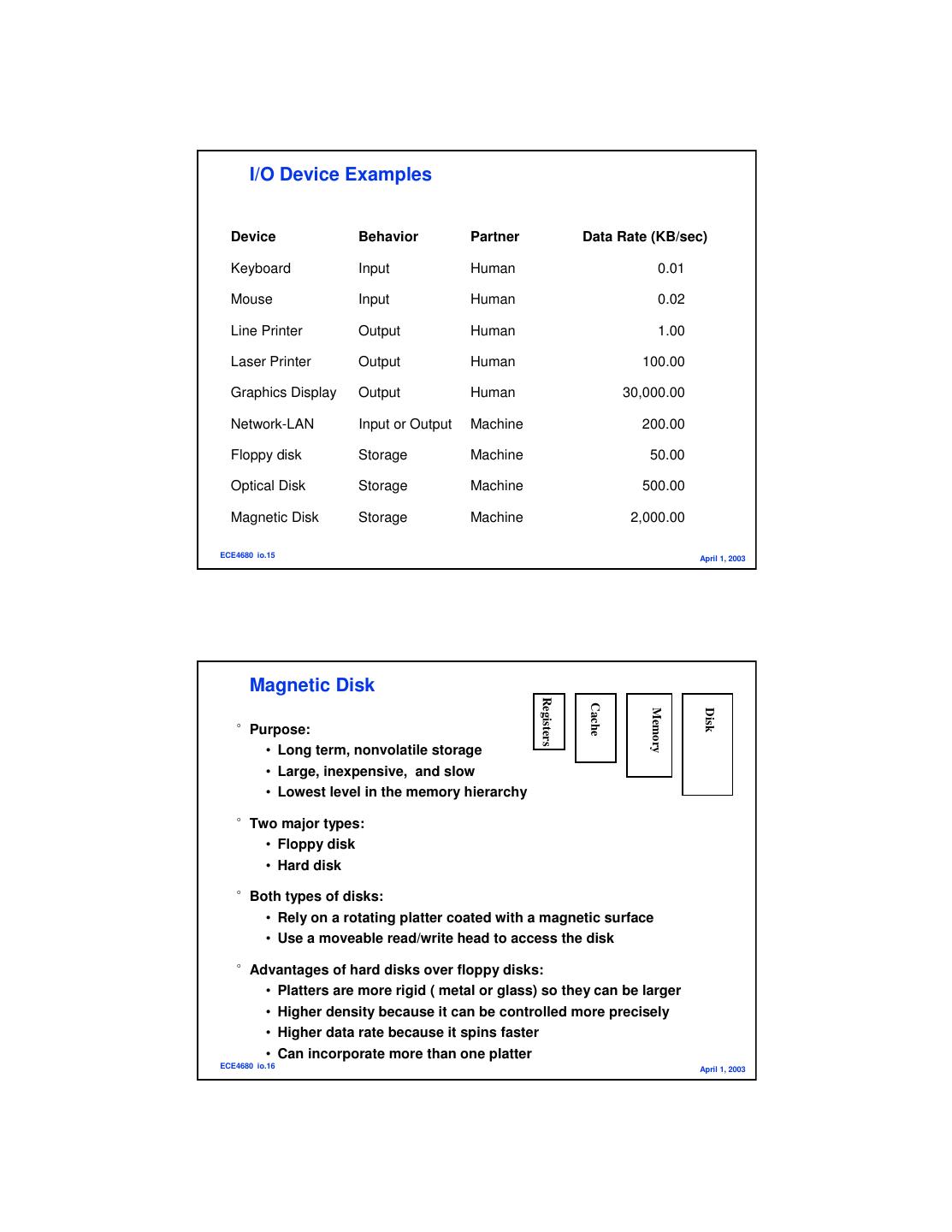
8 . I/O Device Examples Device Behavior Partner Data Rate (KB/sec) Keyboard Input Human 0.01 Mouse Input Human 0.02 Line Printer Output Human 1.00 Laser Printer Output Human 100.00 Graphics Display Output Human 30,000.00 Network-LAN Input or Output Machine 200.00 Floppy disk Storage Machine 50.00 Optical Disk Storage Machine 500.00 Magnetic Disk Storage Machine 2,000.00 ECE4680 io.15 April 1, 2003 Magnetic Disk Registers Cache Memory Disk °Purpose: • Long term, nonvolatile storage • Large, inexpensive, and slow • Lowest level in the memory hierarchy °Two major types: • Floppy disk • Hard disk °Both types of disks: • Rely on a rotating platter coated with a magnetic surface • Use a moveable read/write head to access the disk °Advantages of hard disks over floppy disks: • Platters are more rigid ( metal or glass) so they can be larger • Higher density because it can be controlled more precisely • Higher data rate because it spins faster • Can incorporate more than one platter ECE4680 io.16 April 1, 2003
9 . Organization of a Hard Magnetic Disk Platters Track Sector °A stack of platters, a surface with a magnetic coating °Typical numbers (depending on the disk size): • 500 to 2,000 tracks per surface • 32 to 128 sectors per track - A sector is the smallest unit that can be read or written °Traditionally all tracks have the same number of sectors: • Constant bit density: record more sectors on the outer tracks ECE4680 io.17 April 1, 2003 Magnetic Disk Characteristic Track °Disk head: each side of a platter has separate disk head Sector °Cylinder: all the tracks under the head at a given point on all surface Cylinder °Read/write data is a three-stage process: Platter • Seek time: position the arm over the proper track Head • Rotational latency: wait for the desired sector to rotate under the read/write head • Transfer time: transfer a block of bits (sector) under the read-write head °Average seek time as reported by the industry: • Typically in the range of 8 ms to 15 ms • (Sum of the time for all possible seek) / (total # of possible seeks) °Due to locality of disk reference, actual average seek time may: • Only be 25% to 33% of the advertised number ECE4680 io.18 April 1, 2003
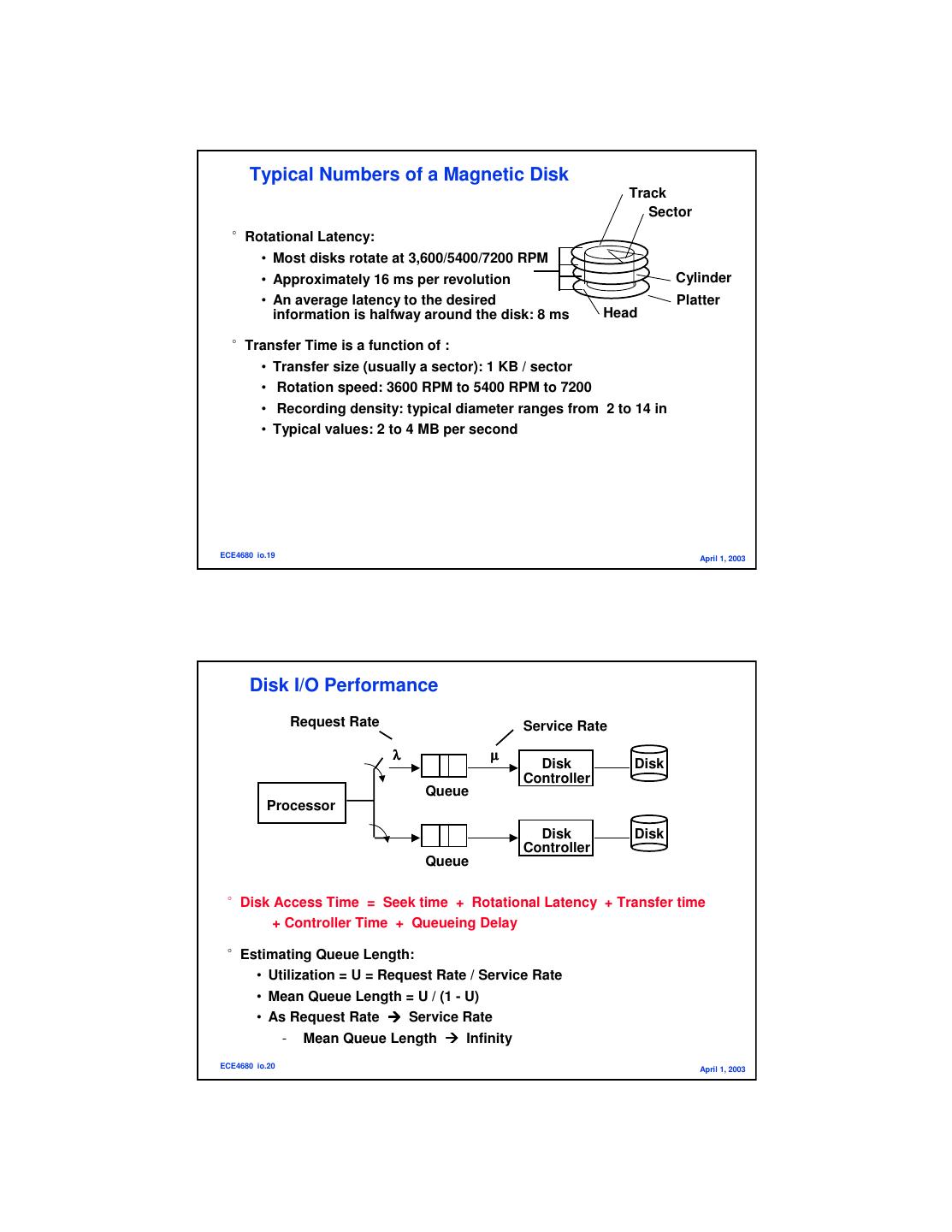
10 . Typical Numbers of a Magnetic Disk Track Sector °Rotational Latency: • Most disks rotate at 3,600/5400/7200 RPM • Approximately 16 ms per revolution Cylinder • An average latency to the desired Platter information is halfway around the disk: 8 ms Head °Transfer Time is a function of : • Transfer size (usually a sector): 1 KB / sector • Rotation speed: 3600 RPM to 5400 RPM to 7200 • Recording density: typical diameter ranges from 2 to 14 in • Typical values: 2 to 4 MB per second ECE4680 io.19 April 1, 2003 Disk I/O Performance Request Rate Service Rate λ µ Disk Disk Controller Queue Processor Disk Disk Controller Queue °Disk Access Time = Seek time + Rotational Latency + Transfer time + Controller Time + Queueing Delay °Estimating Queue Length: • Utilization = U = Request Rate / Service Rate • Mean Queue Length = U / (1 - U) • As Request Rate Service Rate - Mean Queue Length Infinity ECE4680 io.20 April 1, 2003
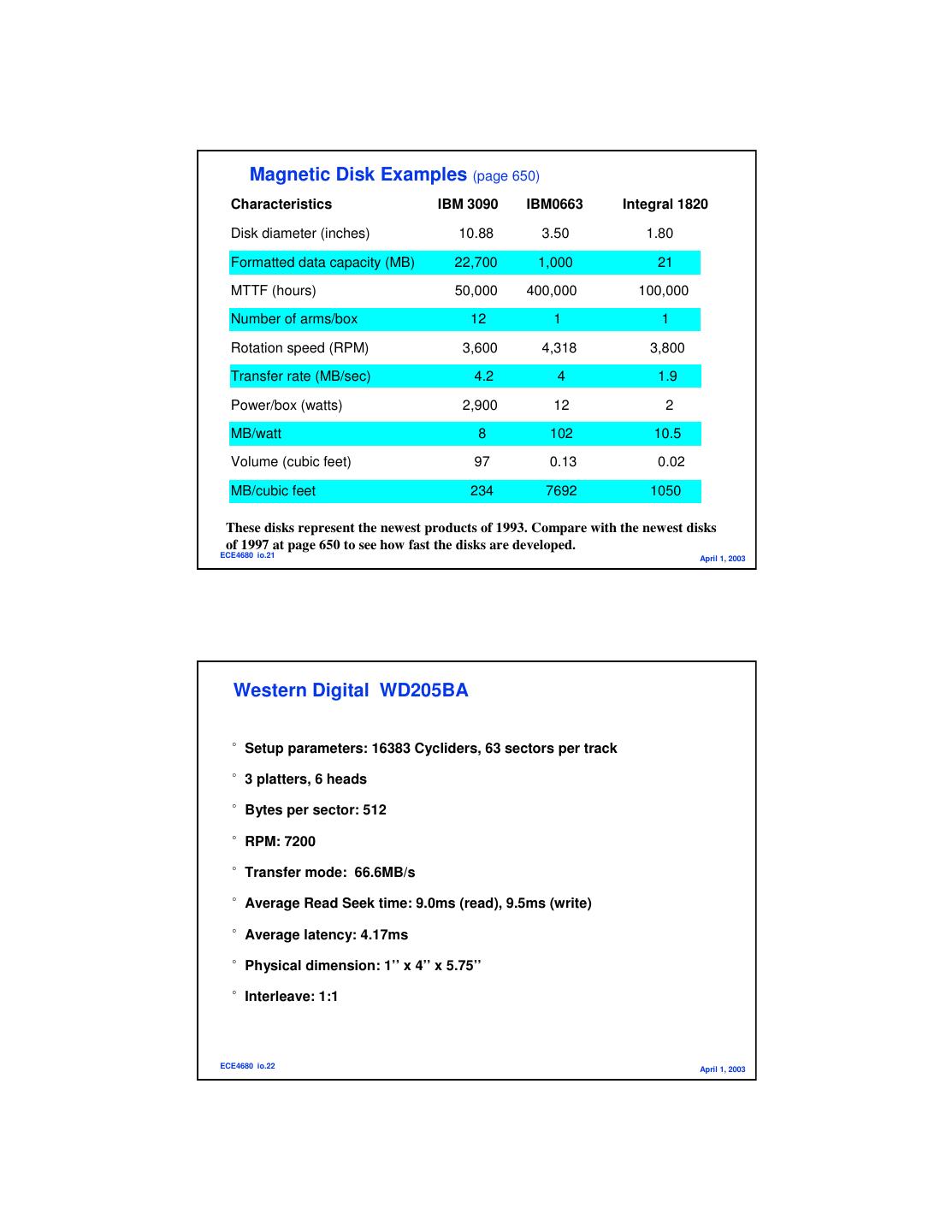
11 . Magnetic Disk Examples (page 650) Characteristics IBM 3090 IBM0663 Integral 1820 Disk diameter (inches) 10.88 3.50 1.80 Formatted data capacity (MB) 22,700 1,000 21 MTTF (hours) 50,000 400,000 100,000 Number of arms/box 12 1 1 Rotation speed (RPM) 3,600 4,318 3,800 Transfer rate (MB/sec) 4.2 4 1.9 Power/box (watts) 2,900 12 2 MB/watt 8 102 10.5 Volume (cubic feet) 97 0.13 0.02 MB/cubic feet 234 7692 1050 These disks represent the newest products of 1993. Compare with the newest disks of 1997 at page 650 to see how fast the disks are developed. ECE4680 io.21 April 1, 2003 Western Digital WD205BA °Setup parameters: 16383 Cycliders, 63 sectors per track °3 platters, 6 heads °Bytes per sector: 512 °RPM: 7200 °Transfer mode: 66.6MB/s °Average Read Seek time: 9.0ms (read), 9.5ms (write) °Average latency: 4.17ms °Physical dimension: 1’’ x 4’’ x 5.75’’ °Interleave: 1:1 ECE4680 io.22 April 1, 2003
12 . Example (pp.648-649) °512 byte sector, rotate at 5400 RPM, advertised seeks is 12 ms, transfer rate is 4 BM/sec, controller overhead is 1 ms, queue idle so no service time °Disk Access Time = Seek time + Rotational Latency + Transfer time + Controller Time + Queuing Delay °Disk Access Time = 12 ms + 0.5 / 5400 RPM + 0.5 KB / 4 MB/s + 1 ms + 0 °Disk Access Time = 12 ms + 0.5 / 90 RPS + 0.125 / 1024 s + 1 ms + 0 °Disk Access Time = 12 ms + 5.5 ms + 0.1 ms + 1 ms + 0 ms °Disk Access Time = 18.6 ms °If real seeks are 1/3 advertised seeks, then it is 10.6 ms, with rotation delay at 50% of the time! ECE4680 io.23 April 1, 2003 Disk Arrays(p.692, 709) °A new organization of disk storage: • Arrays of small and inexpensive disks • Increase potential throughput by having many disk drives: - Data is spread over multiple disk - Multiple accesses are made to several disks °Reliability is lower than a single disk: • But availability can be improved by adding redundant disks: Lost information can be reconstructed from redundant information • MTTR: mean time to repair is in the order of hours • MTTF: mean time to failure of disks is three to five years ECE4680 io.24 April 1, 2003
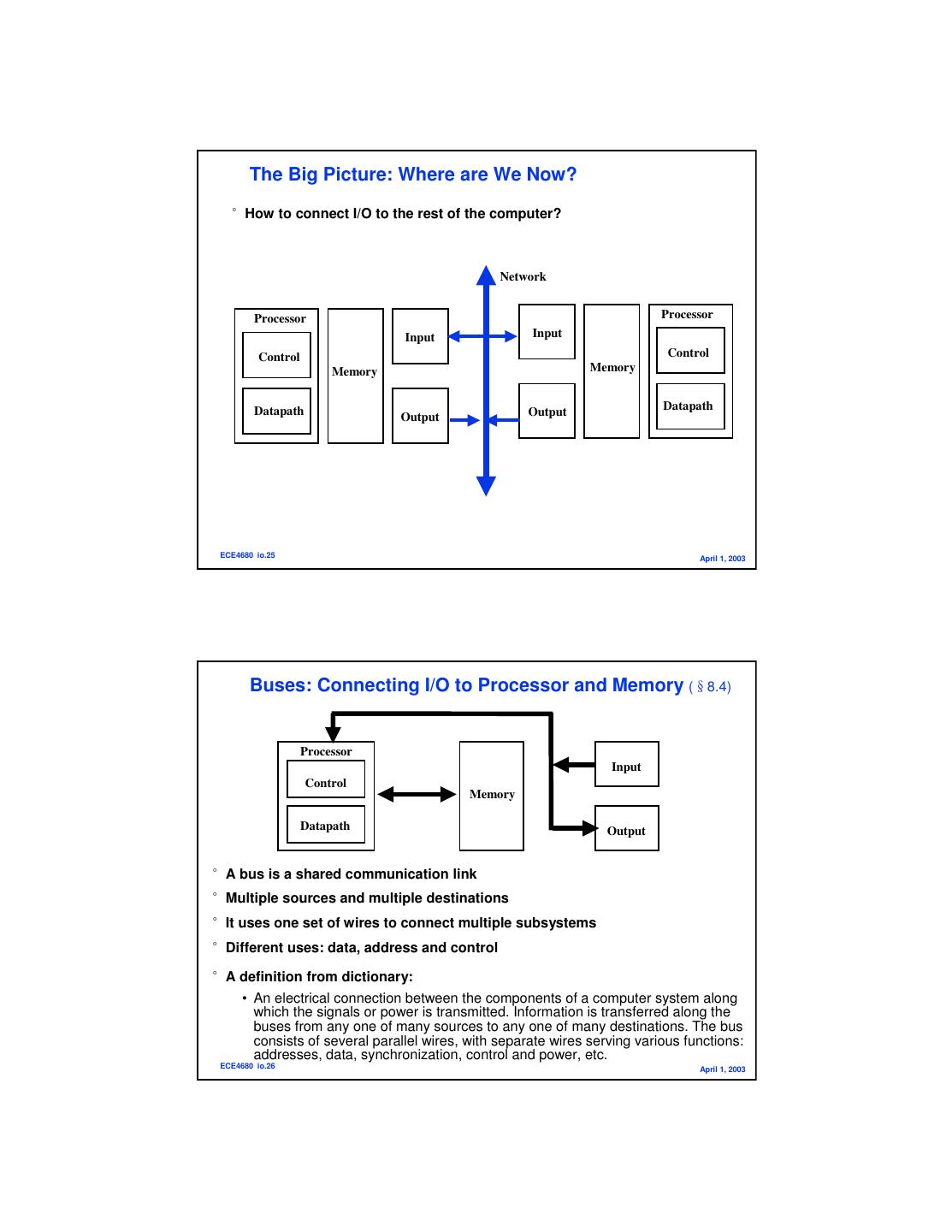
13 . The Big Picture: Where are We Now? °How to connect I/O to the rest of the computer? Network Processor Processor Input Input Control Control Memory Memory Datapath Output Datapath Output ECE4680 io.25 April 1, 2003 Buses: Connecting I/O to Processor and Memory (§8.4) Processor Input Control Memory Datapath Output °A bus is a shared communication link °Multiple sources and multiple destinations °It uses one set of wires to connect multiple subsystems °Different uses: data, address and control °A definition from dictionary: • An electrical connection between the components of a computer system along which the signals or power is transmitted. Information is transferred along the buses from any one of many sources to any one of many destinations. The bus consists of several parallel wires, with separate wires serving various functions: addresses, data, synchronization, control and power, etc. ECE4680 io.26 April 1, 2003
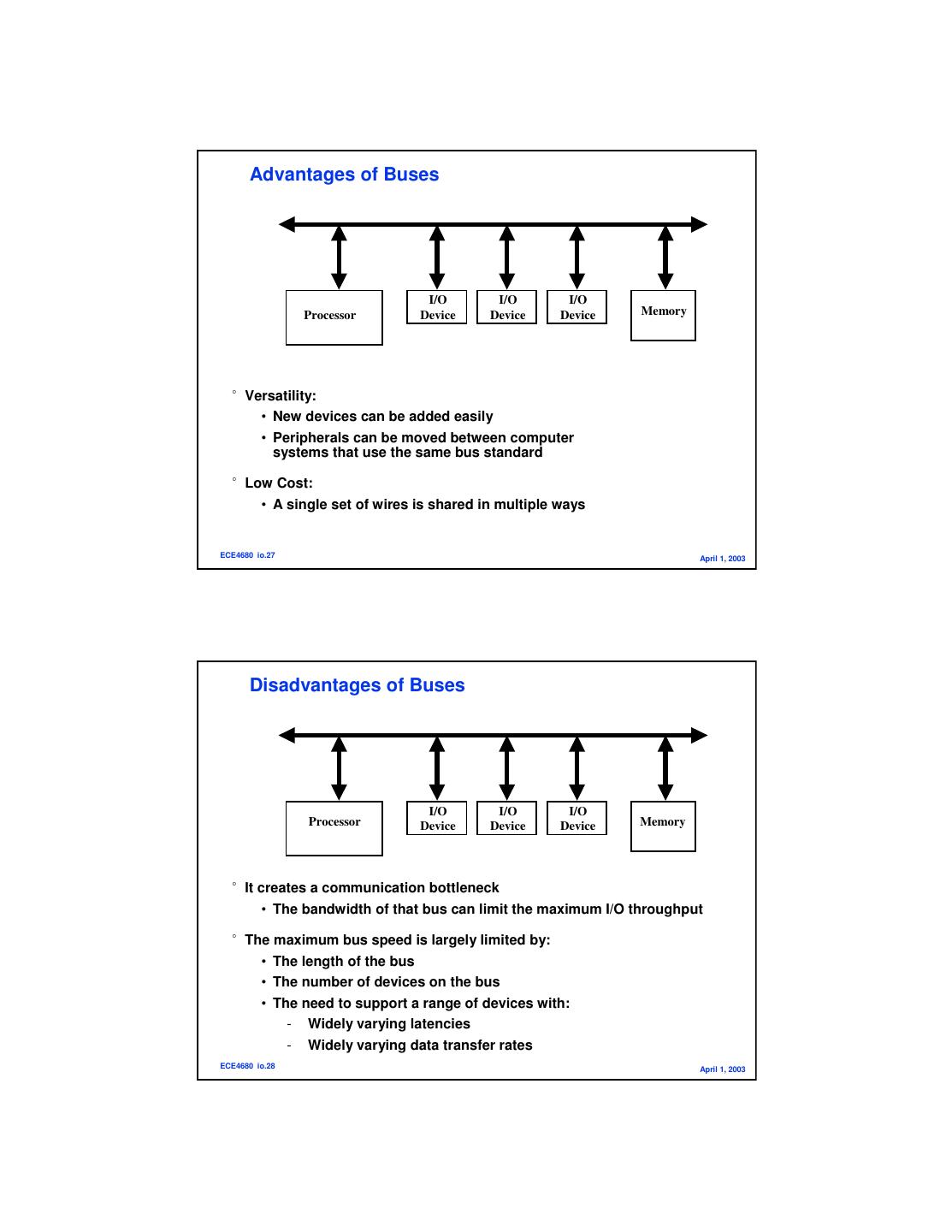
14 . Advantages of Buses I/O I/O I/O Processor Device Device Device Memory °Versatility: • New devices can be added easily • Peripherals can be moved between computer systems that use the same bus standard °Low Cost: • A single set of wires is shared in multiple ways ECE4680 io.27 April 1, 2003 Disadvantages of Buses I/O I/O I/O Processor Device Device Device Memory °It creates a communication bottleneck • The bandwidth of that bus can limit the maximum I/O throughput °The maximum bus speed is largely limited by: • The length of the bus • The number of devices on the bus • The need to support a range of devices with: - Widely varying latencies - Widely varying data transfer rates ECE4680 io.28 April 1, 2003
15 . The General Organization of a Bus Control Lines Data Lines °Control lines: • Signal requests and acknowledgments • Indicate what type of information is on the data lines °Data lines carry information between the source and the destination: • Data and Addresses • Complex commands °A bus transaction includes two parts: • Sending the address • Receiving or sending the data ECE4680 io.29 April 1, 2003 Master versus Slave Master send address Bus Bus Master Data can go either way Slave °A bus transaction includes two parts: • Sending the address • Receiving or sending the data °Master is the one who starts the bus transaction by: • Sending the address °Salve is the one who responds to the address by: • Sending data to the master if the master ask for data • Receiving data from the master if the master wants to send data ECE4680 io.30 April 1, 2003
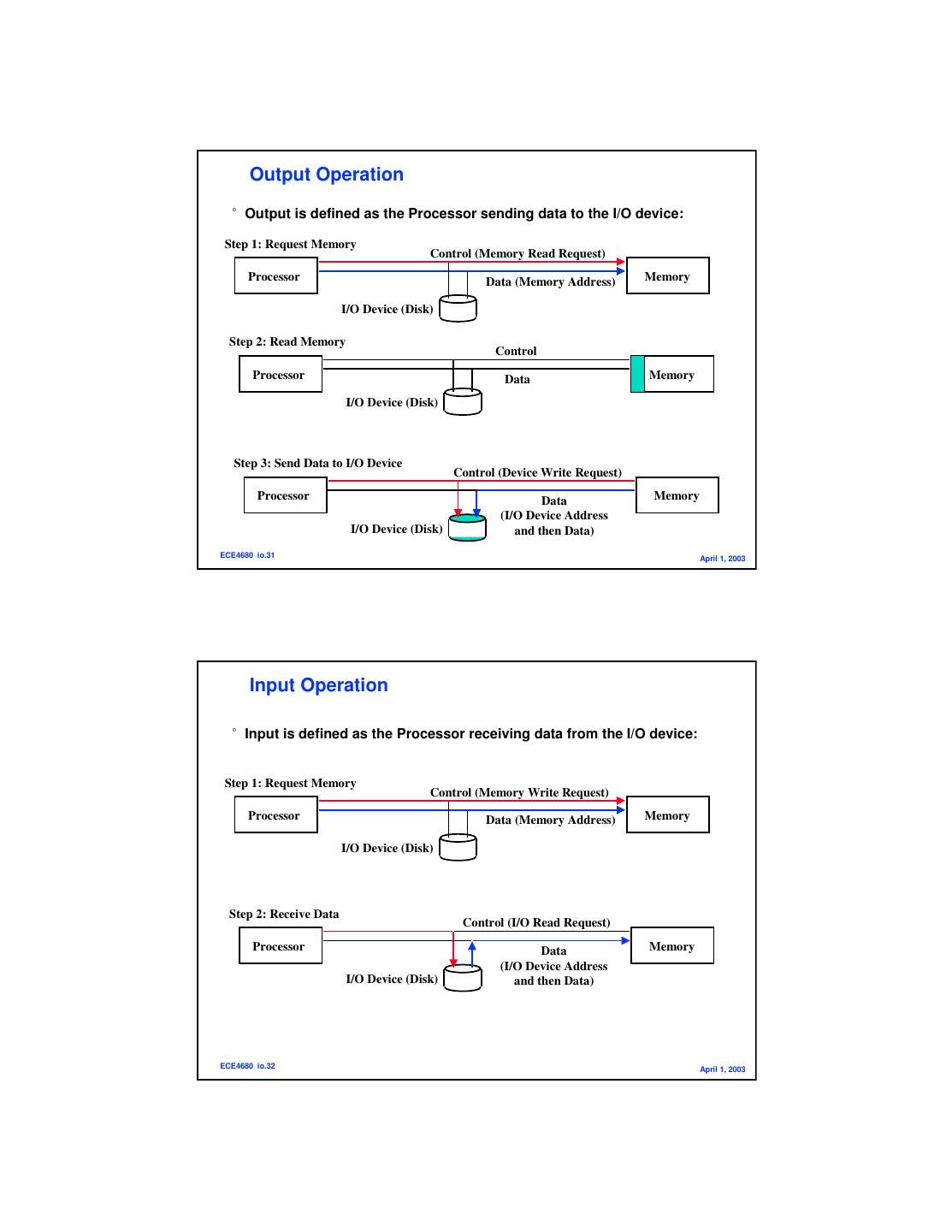
16 . Output Operation °Output is defined as the Processor sending data to the I/O device: Step 1: Request Memory Control (Memory Read Request) Processor Data (Memory Address) Memory I/O Device (Disk) Step 2: Read Memory Control Processor Data Memory I/O Device (Disk) Step 3: Send Data to I/O Device Control (Device Write Request) Processor Data Memory (I/O Device Address I/O Device (Disk) and then Data) ECE4680 io.31 April 1, 2003 Input Operation °Input is defined as the Processor receiving data from the I/O device: Step 1: Request Memory Control (Memory Write Request) Processor Data (Memory Address) Memory I/O Device (Disk) Step 2: Receive Data Control (I/O Read Request) Processor Data Memory (I/O Device Address I/O Device (Disk) and then Data) ECE4680 io.32 April 1, 2003
17 . Types of Buses °Processor-Memory Bus (design specific or proprietary) • Short and high speed • Only need to match the memory system - Maximize memory-to-processor bandwidth • Connects directly to the processor °I/O Bus (industry standard) • Usually is lengthy and slower • Need to match a wide range of I/O devices • Connects to the processor-memory bus or backplane bus °Backplane Bus (industry standard) • Backplane: an interconnection structure within the chassis • Allow processors, memory, and I/O devices to coexist • Cost advantage: one single bus for all components ECE4680 io.33 April 1, 2003 A Computer System with One Bus: Backplane Bus Backplane Bus Processor Memory I/O Devices °A single bus (the backplane bus) is used for: • Processor to memory communication • Communication between I/O devices and memory °Advantages: Simple and low cost °Disadvantages: slow and the bus can become a major bottleneck °Example: IBM PC ECE4680 io.34 April 1, 2003
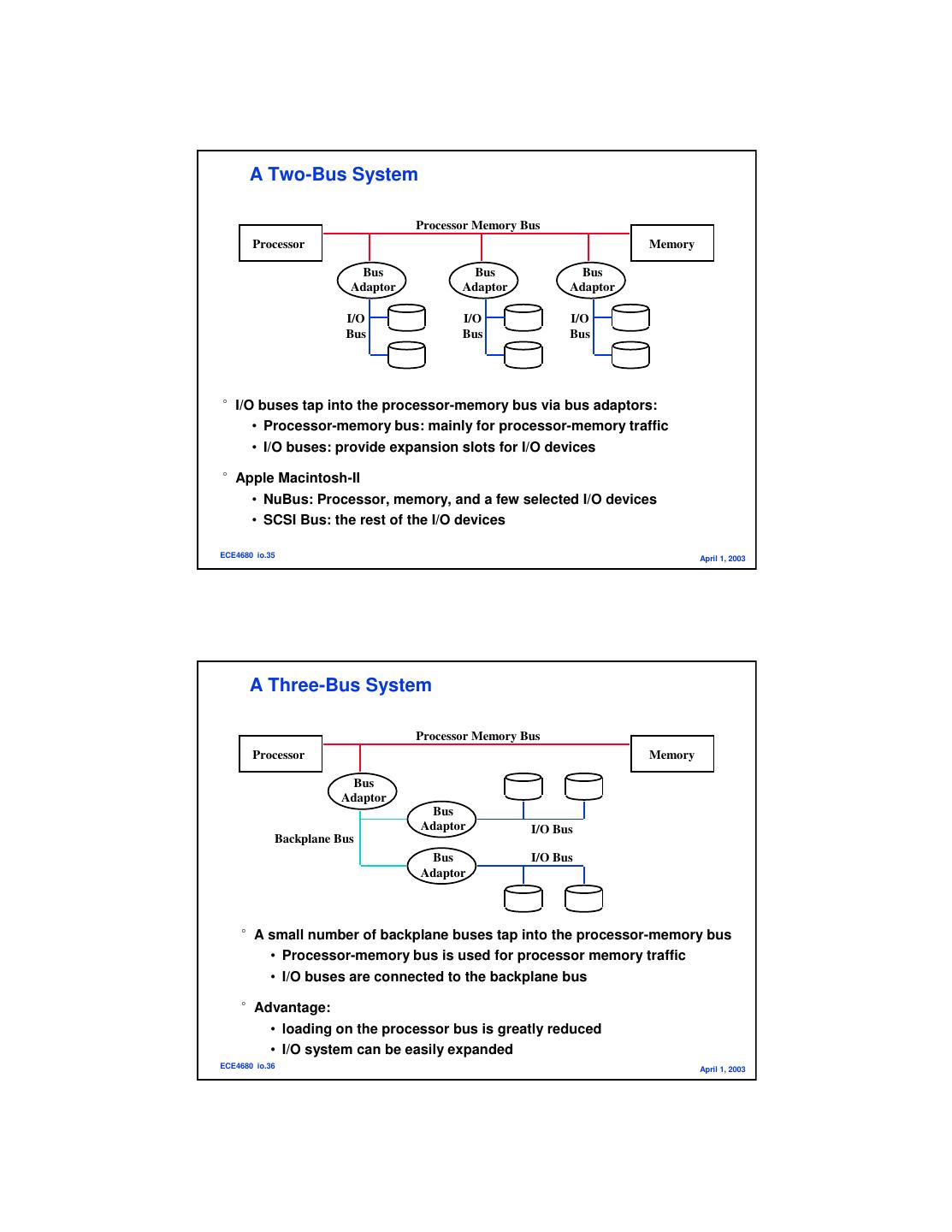
18 . A Two-Bus System Processor Memory Bus Processor Memory Bus Bus Bus Adaptor Adaptor Adaptor I/O I/O I/O Bus Bus Bus °I/O buses tap into the processor-memory bus via bus adaptors: • Processor-memory bus: mainly for processor-memory traffic • I/O buses: provide expansion slots for I/O devices °Apple Macintosh-II • NuBus: Processor, memory, and a few selected I/O devices • SCSI Bus: the rest of the I/O devices ECE4680 io.35 April 1, 2003 A Three-Bus System Processor Memory Bus Processor Memory Bus Adaptor Bus Adaptor I/O Bus Backplane Bus Bus I/O Bus Adaptor °A small number of backplane buses tap into the processor-memory bus • Processor-memory bus is used for processor memory traffic • I/O buses are connected to the backplane bus °Advantage: • loading on the processor bus is greatly reduced • I/O system can be easily expanded ECE4680 io.36 April 1, 2003
19 . Synchronous and Asynchronous Bus °Synchronous Bus: • Includes a clock in the control lines • A fixed protocol for communication that is relative to the clock • Advantage: involves very little logic and can run very fast • Disadvantages: - Every device on the bus must run at the same clock rate - To avoid clock skew, they cannot be long if they are fast °Asynchronous Bus: • It is not clocked • It can accommodate a wide range of devices • It can be lengthened without worrying about clock skew • It requires a handshaking protocol ECE4680 io.37 April 1, 2003 Simplest bus paradigm °All agents operate synchronously °All can source / sink data at same rate °=> simple protocol • just manage the source and target ECE4680 io.38 April 1, 2003
20 . Simple Synchronous Protocol BReq BG R/W Cmd+Addr Address Data Data1 Data2 °Even memory busses are more complex than this • memory (slave) may take time to respond • it need to control data rate ECE4680 io.39 April 1, 2003 Typical Synchronous Protocol BReq BG R/W Cmd+Addr Address Wait Data Data1 Data1 Data2 °Slave indicates when it is prepared for data transfer °Actual transfer goes at bus rate ECE4680 io.40 April 1, 2003
21 . A Handshaking Protocol (page 661) ReadReq 1 2 3 Data Address Data 2 4 6 5 Ack 6 7 4 DataRdy °Three control lines • ReadReq: indicate a read request for memory Address is put on the data lines at the same line • DataRdy: indicate the data word is now ready on the data lines Data is put on the data lines at the same time • Ack: acknowledge the ReadReq or the DataRdy of the other party °This figure is for read operation, but is almost the same for write operation ECE4680 io.41 April 1, 2003 Increasing the Bus Bandwidth °Separate versus multiplexed address and data lines: • Address and data can be transmitted in one bus cycle if separate address and data lines are available • Cost: (a) more bus lines, (b) increased complexity °Data bus width: • By increasing the width of the data bus, transfers of multiple words require fewer bus cycles • Example: SPARCstation 20’s memory bus is 128 bit wide • Cost: more bus lines °Block transfers: • Allow the bus to transfer multiple words in back-to-back bus cycles • Only one address needs to be sent at the beginning • The bus is not released until the last word is transferred • Cost: (a) increased complexity (b) decreased response time for request ECE4680 io.42 April 1, 2003
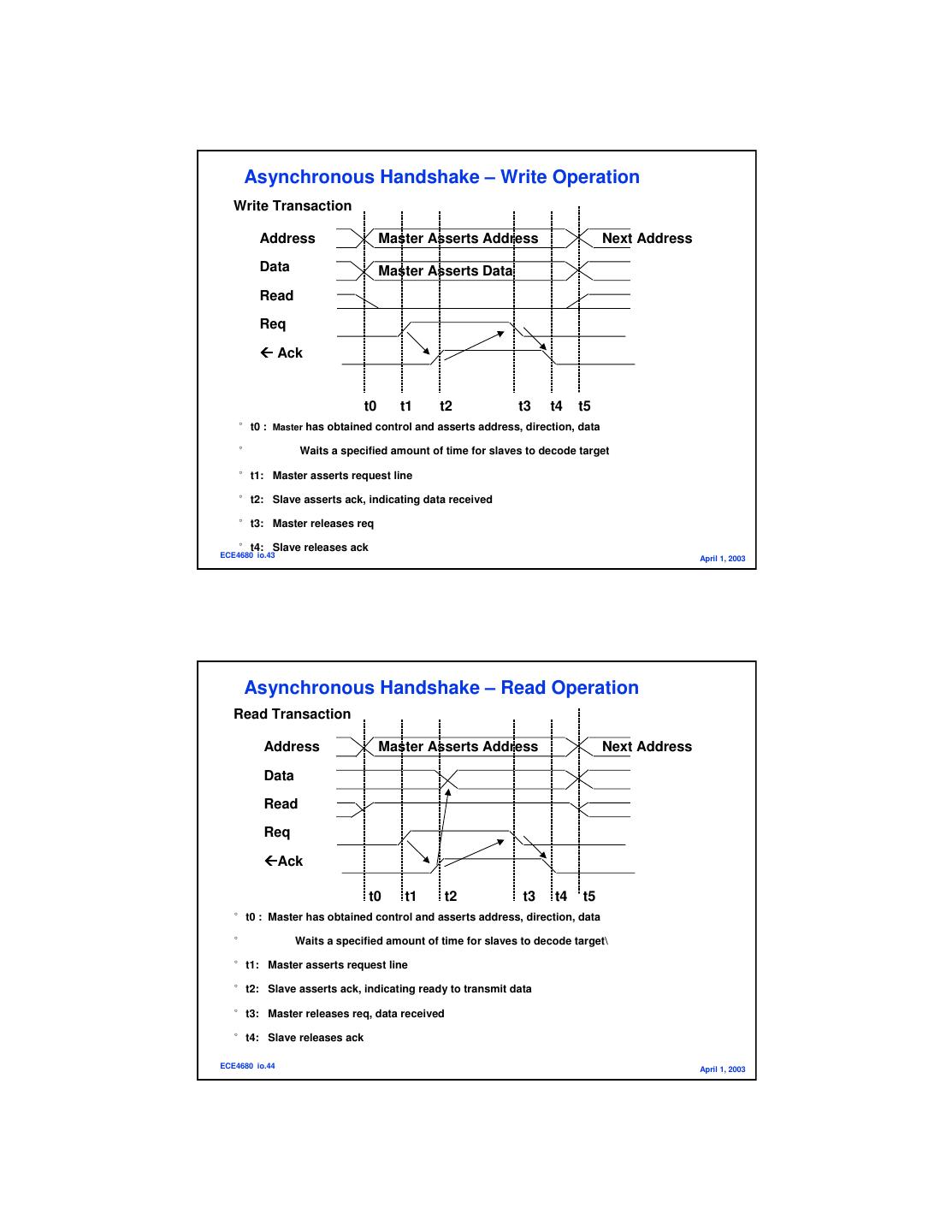
22 . Asynchronous Handshake – Write Operation Write Transaction Address Master Asserts Address Next Address Data Master Asserts Data Read Req Ack t0 t1 t2 t3 t4 t5 ° t0 : Master has obtained control and asserts address, direction, data ° Waits a specified amount of time for slaves to decode target ° t1: Master asserts request line ° t2: Slave asserts ack, indicating data received ° t3: Master releases req ° t4: Slave releases ack ECE4680 io.43 April 1, 2003 Asynchronous Handshake – Read Operation Read Transaction Address Master Asserts Address Next Address Data Read Req Ack t0 t1 t2 t3 t4 t5 ° t0 : Master has obtained control and asserts address, direction, data ° Waits a specified amount of time for slaves to decode target\ ° t1: Master asserts request line ° t2: Slave asserts ack, indicating ready to transmit data ° t3: Master releases req, data received ° t4: Slave releases ack ECE4680 io.44 April 1, 2003
23 . Example: Performance Analysis(page 665) ° Consider a system with the following characteristics: • Its memory and bus supporting block access of 4 to 16 32-bit words • 64-bit synchronous bus clocked at 200MHz, with each 64-bit transfer taking 1 clock cycle, and 1 clock cycle required to send an address to memory • Two clock cycles needed between each bus operation • A memory access time for the first four words of 200ns; each additional set of four words can be read in 20ns. Assume that a bus transfer of the most recently read data and a read of the next four words can be overlapped. ° Find the sustained bandwidth and the latency for a read of 256 words that use 4-word blocks; ° Compute the effective number of bus transactions per second ? ° Repeat the question for transfers that use 16-word blocks 200 ns 1 clock 5 ns / cycle = 40 clock 2 clock 2 clock Latency = 2880 clock cycles I/O Memory Block Read Data Bus Bandwidth = 71.11MB /sec address memory transfer idle 1 clock 40 clock 2 clock 2 clock I/O Memory Latency = 912 clock cycles Bandwidth = 224.56MB /sec ECE4680 io.45 April 1, 2003 Obtaining Access to the Bus Control: Master initiates requests Bus Bus Master Data can go either way Slave °One of the most important issues in bus design: • How is the bus reserved by a devices that wishes to use it? °Chaos is avoided by a master-slave arrangement: • Only the bus master can control access to the bus: It initiates and controls all bus requests • A slave responds to read and write requests °The simplest system: • Processor is the only bus master • All bus requests must be controlled by the processor • Major drawback: the processor is involved in every transaction ECE4680 io.46 April 1, 2003
24 . Split Bus Transaction (page 666:elaboration) °Request-Reply • CPU initiates a read or write transaction - address, data, and command • then waiting for reply from memory °Split bus transaction • CPU initiates a read or write transaction - address, data, and command • Memory initiates a reply transaction - data (read) or acknowledge (write) °+ bandwidth is improved °- latency for an individual read/write ?? ECE4680 io.47 April 1, 2003 Multiple Potential Bus Masters: the Need for Arbitration °Bus arbitration scheme: • A bus master wanting to use the bus asserts the bus request • A bus master cannot use the bus until its request is granted • A bus master must signal to the arbiter after finish using the bus °Bus arbitration schemes usually try to balance two factors: • Bus priority: the highest priority device should be serviced first • Fairness: Even the lowest priority device should never be completely locked out from the bus °Bus arbitration schemes can be divided into four broad classes: • Distributed arbitration by self-selection: each device wanting the bus places a code indicating its identity on the bus. • Distributed arbitration by collision detection: Ethernet uses this. • Daisy chain arbitration: see next slide. • Centralized, parallel arbitration: see next-next slide ECE4680 io.48 April 1, 2003
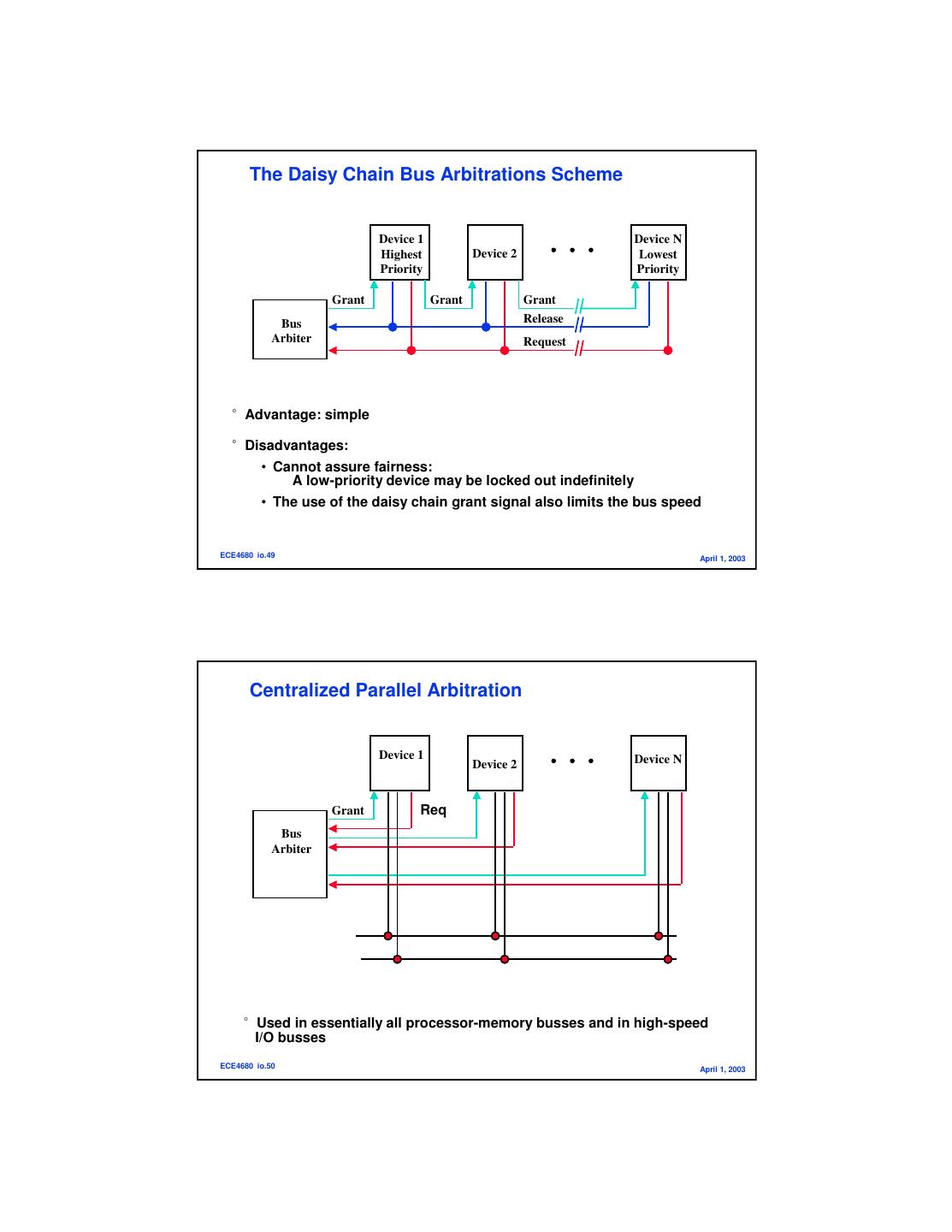
25 . The Daisy Chain Bus Arbitrations Scheme Device 1 Device N Highest Device 2 Lowest Priority Priority Grant Grant Grant Bus Release Arbiter Request °Advantage: simple °Disadvantages: • Cannot assure fairness: A low-priority device may be locked out indefinitely • The use of the daisy chain grant signal also limits the bus speed ECE4680 io.49 April 1, 2003 Centralized Parallel Arbitration Device 1 Device N Device 2 Grant Req Bus Arbiter °Used in essentially all processor-memory busses and in high-speed I/O busses ECE4680 io.50 April 1, 2003
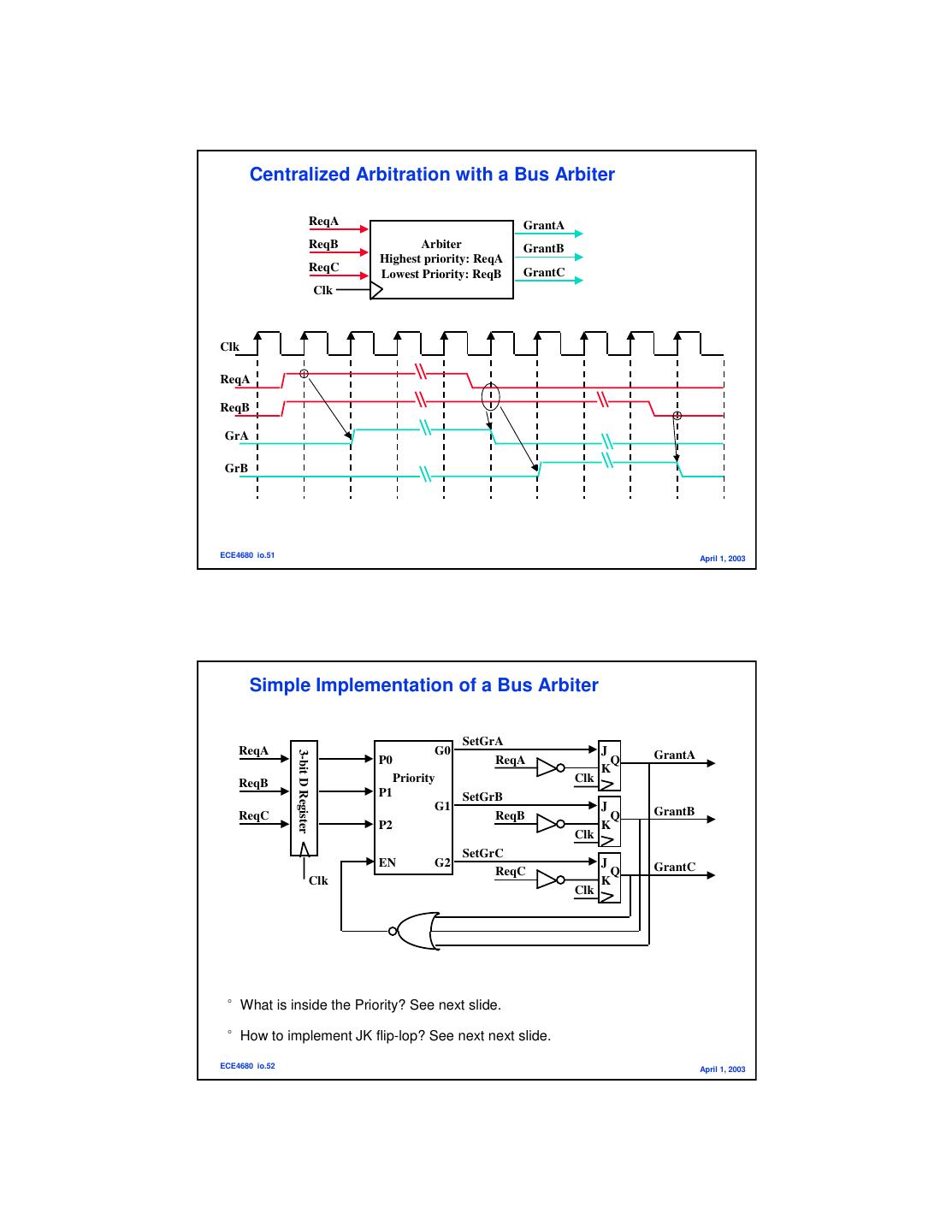
26 . Centralized Arbitration with a Bus Arbiter ReqA GrantA ReqB Arbiter GrantB Highest priority: ReqA ReqC GrantC Lowest Priority: ReqB Clk Clk ReqA ReqB GrA GrB ECE4680 io.51 April 1, 2003 Simple Implementation of a Bus Arbiter SetGrA ReqA G0 J 3-bit D Register P0 ReqA Q GrantA K ReqB Priority Clk P1 SetGrB G1 J GrantB ReqC ReqB Q P2 K Clk SetGrC EN G2 J GrantC ReqC Q Clk K Clk °What is inside the Priority? See next slide. °How to implement JK flip-lop? See next next slide. ECE4680 io.52 April 1, 2003
27 . Priority Logic P0 G0 P1 G1 P2 G2 EN ECE4680 io.53 April 1, 2003 JK Flip Flop °JK Flip Flop can be implemented with a D-Flip Flop J J K Q(t-1) Q(t) 0 0 0 0 0 0 1 1 Q D 0 1 x 0 1 0 x 1 K 1 1 0 1 1 1 1 0 clk ECE4680 io.54 April 1, 2003
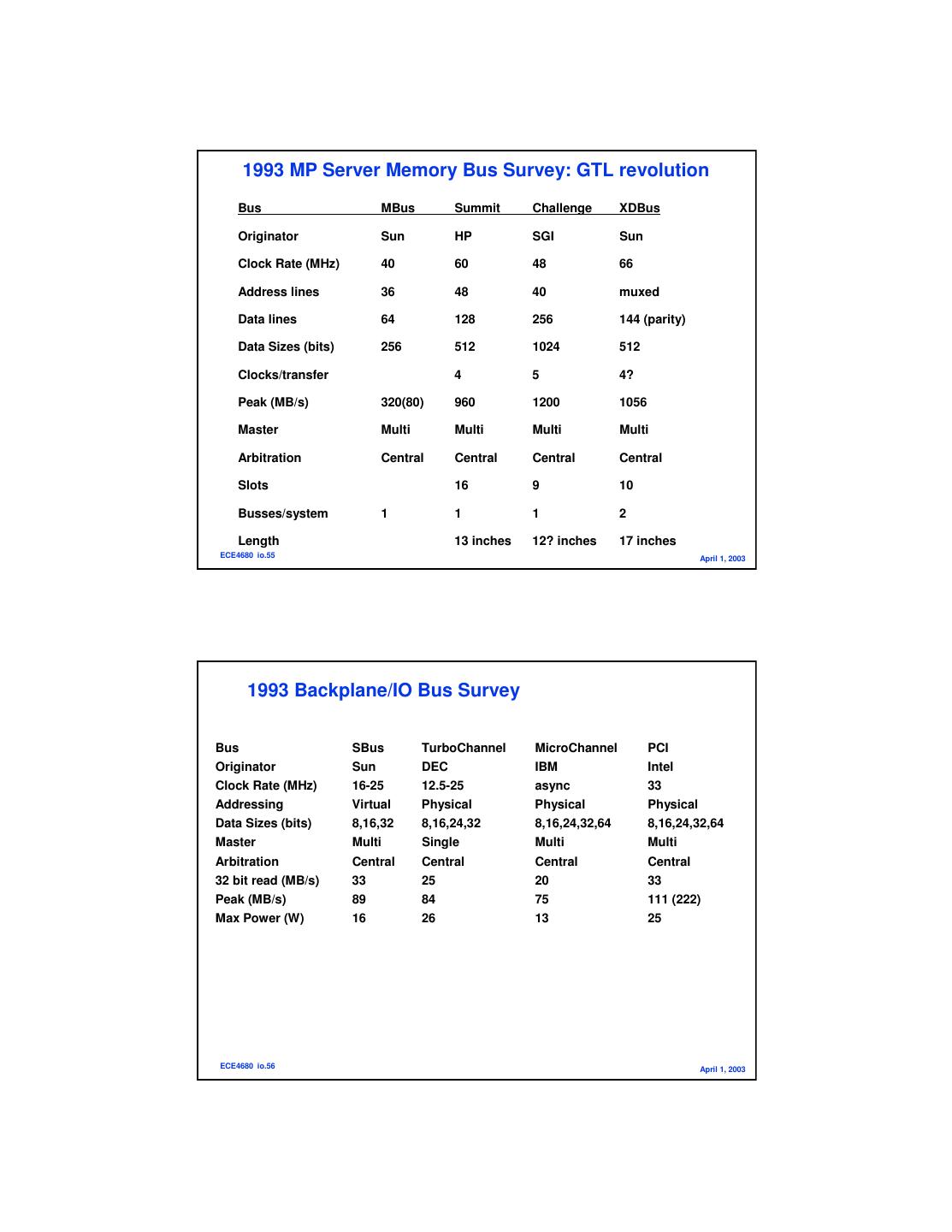
28 . 1993 MP Server Memory Bus Survey: GTL revolution Bus MBus Summit Challenge XDBus Originator Sun HP SGI Sun Clock Rate (MHz) 40 60 48 66 Address lines 36 48 40 muxed Data lines 64 128 256 144 (parity) Data Sizes (bits) 256 512 1024 512 Clocks/transfer 4 5 4? Peak (MB/s) 320(80) 960 1200 1056 Master Multi Multi Multi Multi Arbitration Central Central Central Central Slots 16 9 10 Busses/system 1 1 1 2 Length 13 inches 12? inches 17 inches ECE4680 io.55 April 1, 2003 1993 Backplane/IO Bus Survey Bus SBus TurboChannel MicroChannel PCI Originator Sun DEC IBM Intel Clock Rate (MHz) 16-25 12.5-25 async 33 Addressing Virtual Physical Physical Physical Data Sizes (bits) 8,16,32 8,16,24,32 8,16,24,32,64 8,16,24,32,64 Master Multi Single Multi Multi Arbitration Central Central Central Central 32 bit read (MB/s) 33 25 20 33 Peak (MB/s) 89 84 75 111 (222) Max Power (W) 16 26 13 25 ECE4680 io.56 April 1, 2003
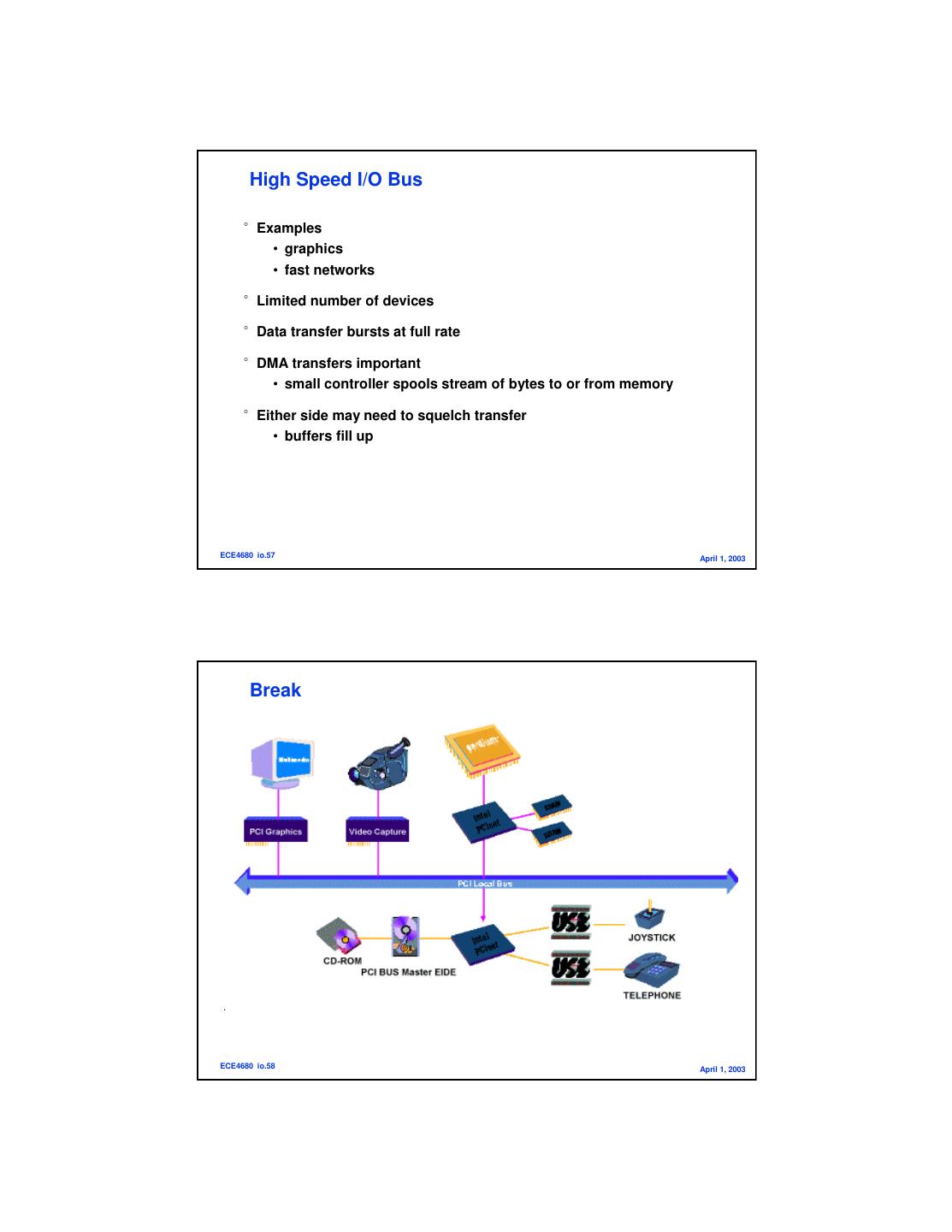
29 . High Speed I/O Bus °Examples • graphics • fast networks °Limited number of devices °Data transfer bursts at full rate °DMA transfers important • small controller spools stream of bytes to or from memory °Either side may need to squelch transfer • buffers fill up ECE4680 io.57 April 1, 2003 Break ECE4680 io.58 April 1, 2003
3秒后跳转登录页面
去登陆

