展开查看详情
1 .vivo离线HDFS集群的架构演进及存储治理实践
主讲人 – vivo互联网 大数据专家 赵永祥
�
2 .vivo HDFS集群的发展之路
2021.04 2022.02 2022.11 2023.10
启动3.x大版本升级 完成3.x大版本升级 联邦&EC稳定上线 存储治理取得阶段性成果
版本落后于社区较多 离线主集群规模近万台 引入联邦机制建设冷热共享DN 大规模推广EC/ZSTD等技术,
较多新特性/优化没有 涉及12个region EC特性基本稳定,试用业务的 节约160PB+存储空间
数据0丢失/损坏 数据性能/安全性满足要求
业务全程无感知
�
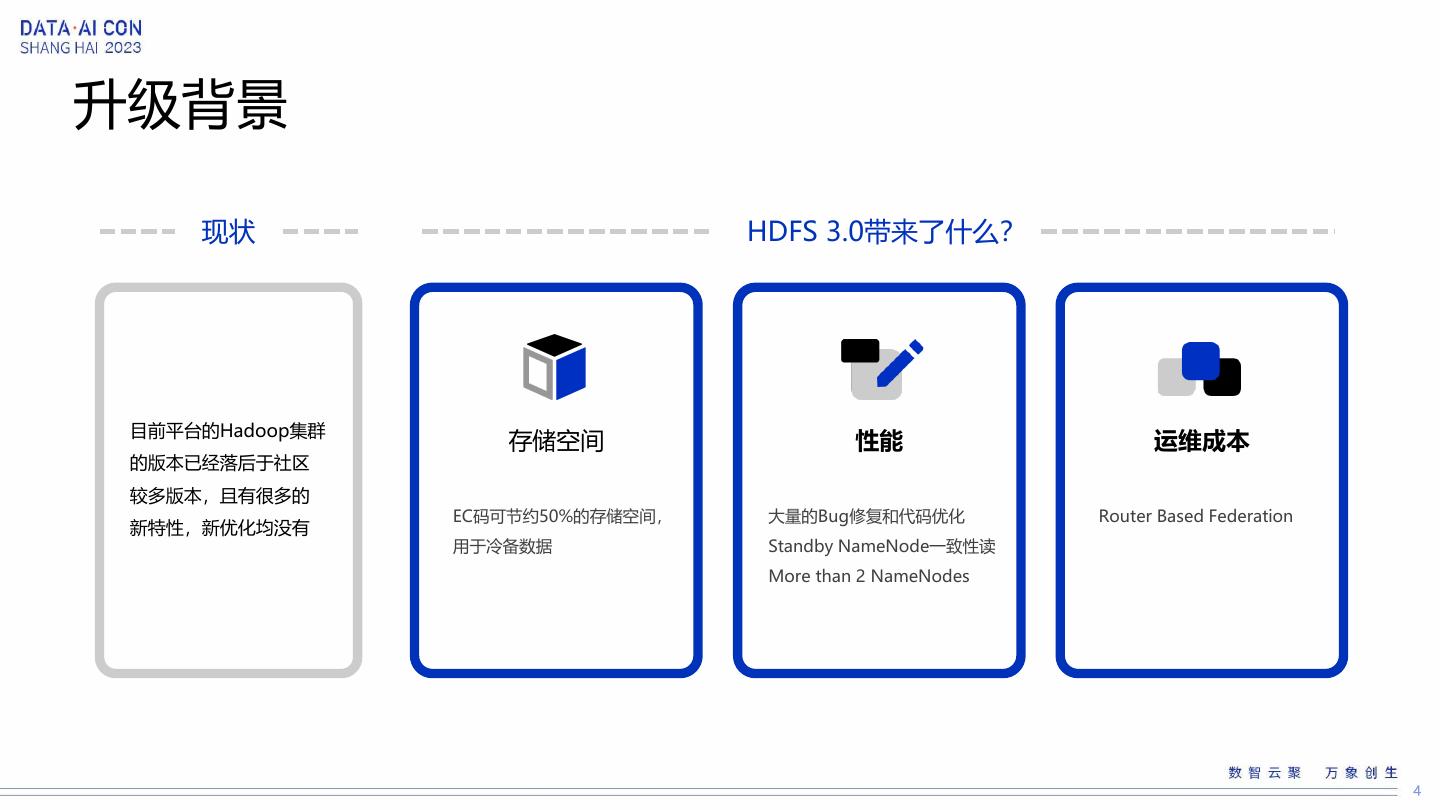
4 .升级背景
现状 HDFS 3.0带来了什么?
目前平台的Hadoop集群
存储空间 性能 运维成本
的版本已经落后于社区
较多版本,且有很多的
EC码可节约50%的存储空间, 大量的Bug修复和代码优化 Router Based Federation
新特性,新优化均没有
用于冷备数据 Standby NameNode一致性读
More than 2 NameNodes
�
5 .挑战
1 严格的上线标准 2 集群规模庞大
数据一致性校验 升级的离线数仓集群涉及12个Region(近万台机器)
性能测试 逐台滚动升级,并且要求业务全程无感知
兼容性测试
完备的升级/降级/回滚方案
�
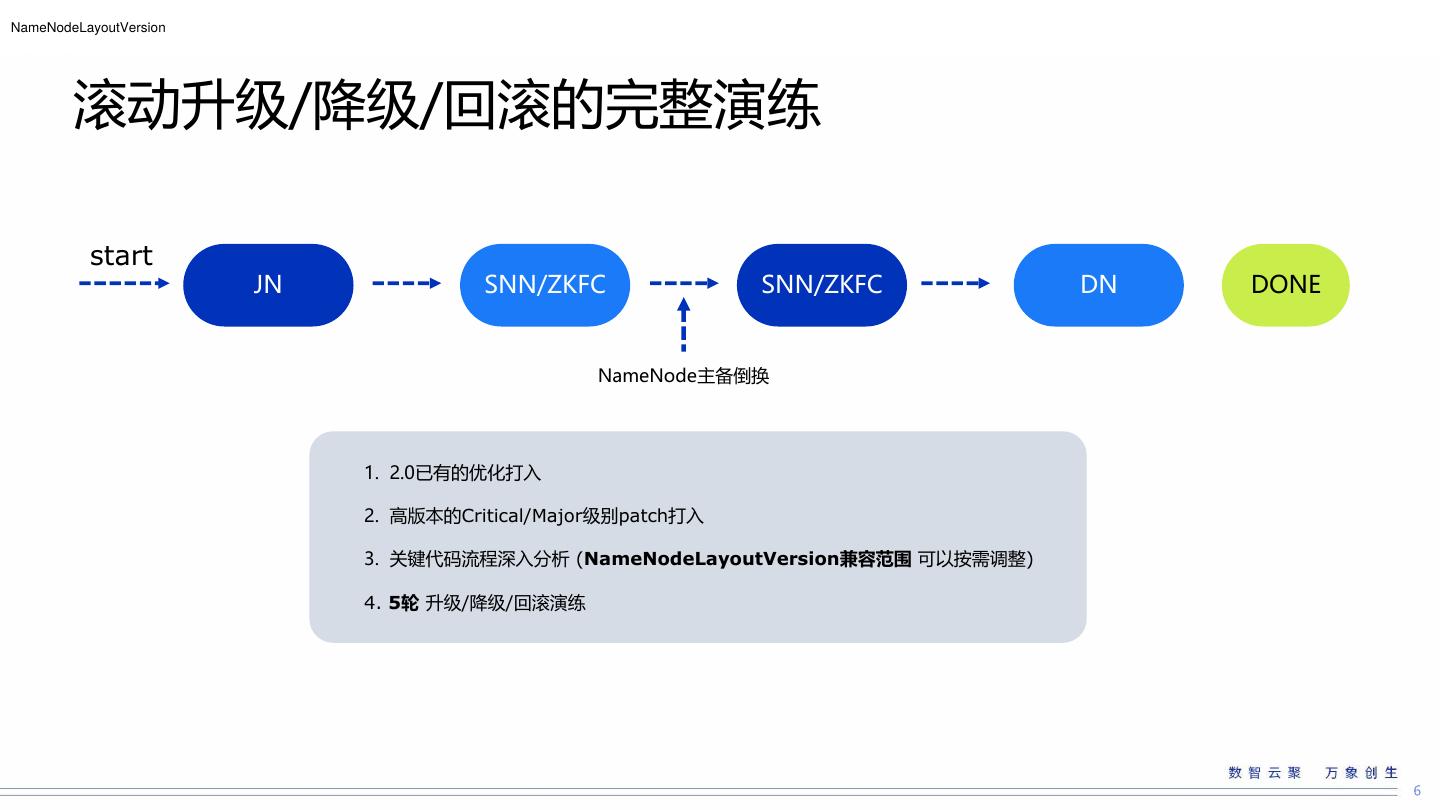
6 .NameNodeLayoutVersion
滚动升级/降级/回滚的完整演练
start
JN SNN/ZKFC SNN/ZKFC DN DONE
NameNode主备倒换
1. 2.0已有的优化打入
2. 高版本的Critical/Major级别patch打入
3. 关键代码流程深入分析 (NameNodeLayoutVersion兼容范围 可以按需调整)
4. 5轮 升级/降级/回滚演练
�
7 .数据一致性校验 & RPC性能测试
数据一致性校验
fsck工具检查升级后的文件系统是否有丢块
Spark程序批量比对大目录的MD5值
RPC性能测试
官方工具Dynamometer NNBench Hive动态分区
通过回放审计日志来做性能压测 测试简单 RPC种类比较丰富
架构复杂,测试成本高 RPC种类过于单一 可以达到线上峰值的量(110万/min)
测试成本低
�
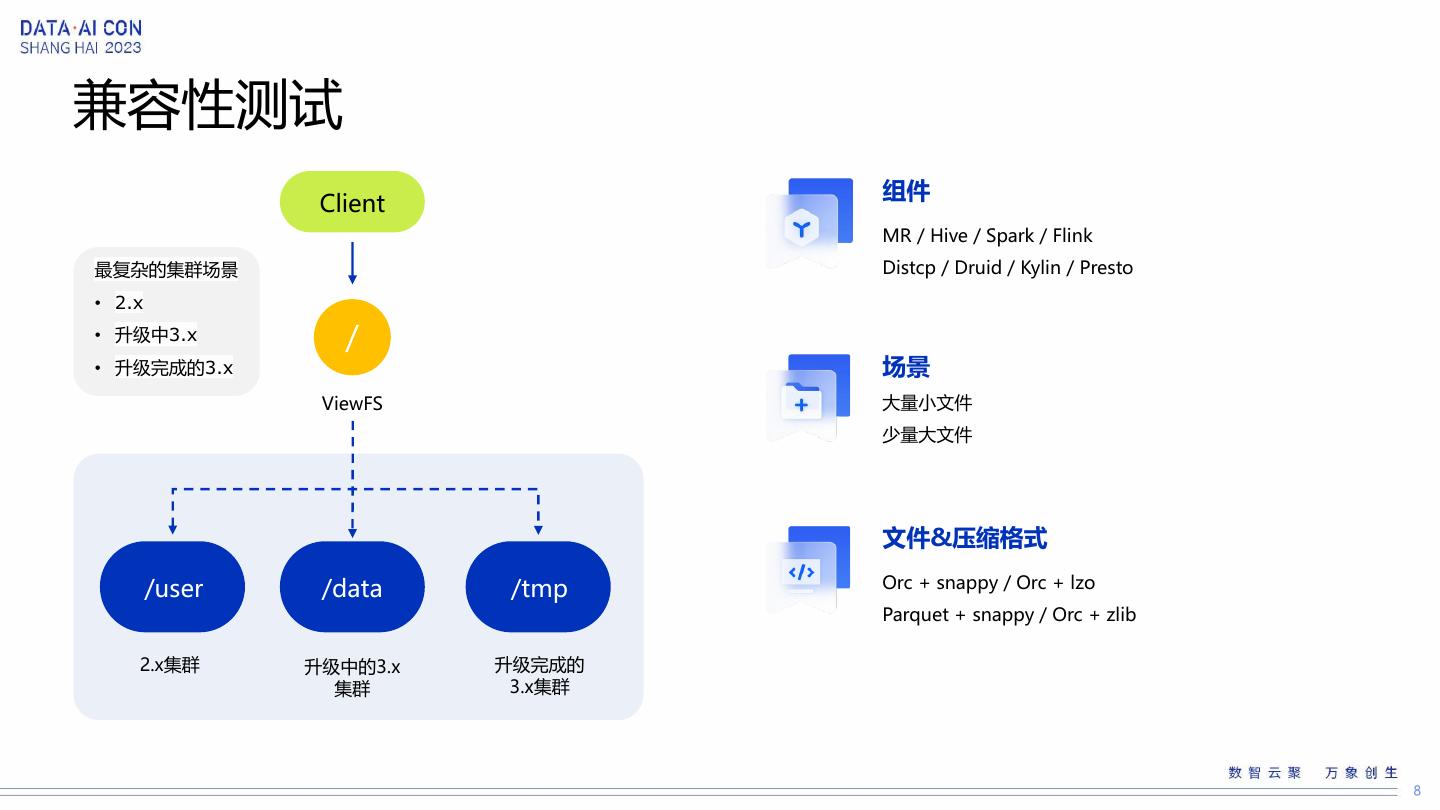
8 .兼容性测试
组件
Client
MR / Hive / Spark / Flink
最复杂的集群场景 Distcp / Druid / Kylin / Presto
• 2.x
• 升级中3.x /
• 升级完成的3.x 场景
ViewFS 大量小文件
少量大文件
文件&压缩格式
/user /data /tmp Orc + snappy / Orc + lzo
Parquet + snappy / Orc + zlib
2.x集群 升级中的3.x 升级完成的
集群 3.x集群
�
9 .升级结果
升级结果
近万台机器/12个region的集群在11个月内完成全部升级
全程数据0丢失/损坏,业务无感知
RPC性能指标不差于2.0版本
总结文章:<< vivo万台规模HDFS集群升级HDFS3.x实践>> // https://mp.weixin.qq.com/s/MReYEmPB8LKo8L4WESIcFA
兼容性情况
组件 版本 兼容性情况
Spark 2.x 3.x 正常
Yarn/MR 2.x 正常
HDFS Client 2.x 正常
Flink 1.13.x 正常
Hive 1.x 正常
�
10 .02 HDFS架构优化 & DN
读写性能优化
�
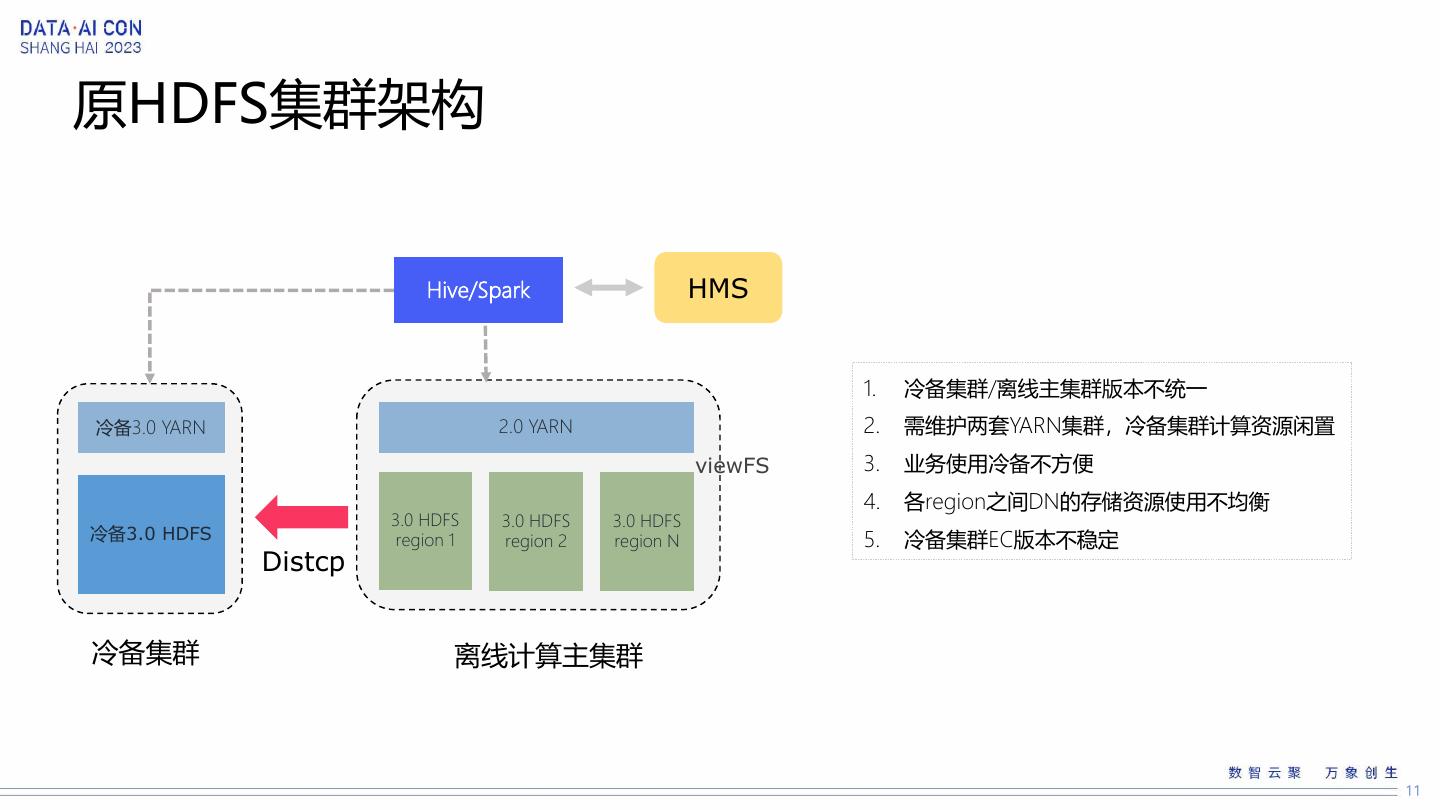
11 .原HDFS集群架构
Hive/Spark HMS
1. 冷备集群/离线主集群版本不统一
冷备3.0 YARN 2.0 YARN 2. 需维护两套YARN集群,冷备集群计算资源闲置
viewFS 3. 业务使用冷备不方便
4. 各region之间DN的存储资源使用不均衡
3.0 HDFS 3.0 HDFS 3.0 HDFS
冷备3.0 HDFS region 1 region 2 region N 5. 冷备集群EC版本不稳定
Distcp
冷备集群 离线计算主集群
�
12 .优化后HDFS集群架构
Hive/Spark HMS
2.0 YARN 1. 合并冷/热两套集群为一套集群
2. 引入联邦机制, 提高DN的存储资源利用率
viewFS 3. 原地冷备,不需要迁移数据
4. 冷热分层, 降低存储成本
region 1 region 2 region 3 region N 5. EC版本更稳定
NN NN NN NN
离线计算主集群
DNs DNs DNs DNs
热共享DN (DISK)
Federation
冷共享DN (ARCHIVE)
�
13 .DN读写性能优化
随着HDFS集群规模越来越大,业务越来越多,经常会有业务反馈DN读写性能存在瓶颈
一. 慢节点剔除 二. 优化DN锁 三. 减少IO访问
通过DN统计写入慢的节点,并上报至 排他锁改为读写锁 delete block时在代码上剔除非必
NN汇总处理 更细粒度(BlockPool/Volume级别) 要的toURI接口调用,在I/O负载
锁在跟进中 比较高的DN节点效果很明显
实际效果未达预期
四. DirectoryScanner 五. 使用外部Shuffle服务 六. 存算I/O隔离
参数优化 降低计算任务对磁盘I/O的占用 共享DN(存算混部)对NM/DN的盘做
扫描限速 & 降低扫描频率 隔离
�
15 .存储治理
存储面临的问题
目前线上 HDFS 集群机器数已经超过万台,数据总存储成本高,每年新增数据大,亟需进行治理
解决的方法
• Erasure Coding
• 更高压缩比的算法(例如:ZSTD/ZLIB)
• 生命周期管理
• 数据冷热分层
• 成本更低的硬件/架构
�
16 .Erasure Coding原理
对 k 份原始数据进行纠错编码得到 m 份冗余数据,当数据丢失不多于 m 份时,通过剩余数据可恢复原始数
据。EC有多种实现,目前HDFS使用的是Reed-Solomon编码。
cell1 cell2 cell3 cell4 cell5 cell6 parity1 parity2 parity3 stripe
跟三副本对比
三副本 EC
k=6 m=3 存储冗余 200% 50%
容忍DN宕机 2台 3台
前向纠错编码
�
17 .遇到的问题
一. 文件损坏问题 二. 损坏文件修复 三. EC补块逻辑
代码存在Bug,导致补块时内存 利用Hive的orcfiledump命令, EC补块这部分代码逻辑Bug有点
被覆盖 再结合定制的HDFS Client修复 多,不过社区基本已经都修复,
HDFS-15240 目前版本稳定
HDFS-14946 HDFS-14768
HDFS-14920 HDFS-14186
HDFS-15798 HDFS-14353
四. NN内存上涨 五. DN下线慢 HDFS-16182
HDFS-16839: 补块时没有考虑 需要打入补丁:HDFS-14854
EC补块任务的负载,导致补不出 并行下线
去
�
18 .Erasure Coding 读性能测试
Spark任务测试 Caas任务测试
Spark任务 三副本任务耗时 EC任务耗时 差异 Caas任务 三副本任务耗时 EC任务耗时 差异
任务1 5小时5分14秒 5小时14分15秒 +8 min 第一次测试 7小时60分 6小时57分 -63 min
任务2 2小时38分31秒 2小时34分4秒 -4 min 第二次测试 7小时32分 6小时38分 -54 min
任务3 4小时29分56秒 4小时36分45秒 +7 min 第三次测试 6小时56分 7小时5分 +9 min
任务4 6小时7分6秒 6小时12分5秒 +5 min 第四次测试 7小时7分 6小时24分 -43 min
任务5 2小时24分10秒 2小时40分28秒 +16 min 测试结论: Caas任务EC性能稍优
测试结论: Spark任务三副本/EC差距不大
TensorFlow任务读性能测试 单机大量读性能测试
单机128线程 单机128线程
数据量: 920GB 数据量: 920GB
EC目录相比三副本目录有30%的性能降低 EC目录相比三副本目录有15%的性能降低
�
19 .Erasure Coding 写性能测试
写性能测试
文件大小 EC写入时间 三副本写入时间
测试集群配置:
DN数量:9 128M 938ms 258ms
机器型号:2018H1-B1 256M 1774ms 503ms
384M 2681ms 770ms
测试方法:
512M 3413ms 979ms
每种文件大小的写入测试,
640M 4424ms 1254ms
重复30次,取平均值
768M 5096ms 1515ms
1536M 9949ms 3086ms
2304M 15021ms 4552ms
3072M 21052ms 6286ms
3840M 25110ms 7842ms
4608M 31097ms 9392ms
5376M 36360ms 11079ms
�
20 .Erasure Coding落地场景
平台在后台转EC
1. 2023年新增EC总量100PB+
Hive库表 Hive库表(EC)
2. EC占总存储比例约22%
APP目录 APP目录(EC)
开发目录全量EC
临时数据EC
�
21 .ZSTD
ZSTD是Facebook在2016年开源的新无损压缩算法,有着突出的压缩率和
压缩/解压缩性能表现
官方参考测试数据 平台实际测试数据
业务实际测试数据
�
22 .压缩测试结论 & 值班的版本
测试结论
1. ZSTD在压缩比/压缩解压缩性能方面表现最优
2. ZSTD/ZLIB压缩比差距不大
3. ZSTD/ZLIB相较SNAPPY在压缩比方面有20~30%的收益
4. 具体比例还会依赖业务数据属性(训练平台的数据ZSTD收益较高 (相较GZIP))
支持的组件 & 版本
组件 版本 备注
Spark 3.x 可以使用Hadoop或Spark自带Codec
Spark 2.x ORC文件可以用Spark自带Codec
Flink 1.13.x 移植至Hadoop 2.x (HADOOP-13578),用Hadoop Codec
MapReduce 2.x 移植至Hadoop 2.x (HADOOP-13578),用Hadoop Codec
Hive 1.x 不支持
�
23 .数据现状 & 解决方案
离线服务的现状 离线任务ZLIB压缩测试
1. 80% 的离线任务是Spark任务 任务 任务类型 SNAPPY压缩 ZLIB压缩
2. >50% 的数据量产出方仍然是Hive任务
任务1 Hive(产出) 10分17秒 10分22秒
3. 大量的表使用的还是SNAPPY压缩
任务2 Spark(产出) 39分25秒 42分40秒
任务3 Hive(产出) 1小时6分59秒 1小时10分39秒
解决方案 任务4 Hive(产出) 49分24秒 47分53秒
场景 方案 任务5 Spark(产出) 1小时48分58秒 1小时42分49秒
增量数据 & 版本支持 SNAPPY -> ZSTD
测试结论: Spark/Hive任务数据从SNAPPY切换为ZLIB后, 任务运行时长差距不大
增量数据 & 版本不支持 SNAPPY -> ZLIB
存量数据 后台SNAPPY->ZSTD/ZLIB
EC + ZSTD/ZLIB 节约存储160PB+
�
24 .HDFS未来的探索
一. 数据迁移的优化 & 更方便的横向元数据扩展
二. Erasure Coding的进一步覆盖 & 尝试更低冗余的EC编码
三. 数据冷热自动分层
四. 更低成本的机器引入
五. 统一存储的建设(POSIX API/S3 API)
�