文件存储在AI时代的实践与演进-苏锐
分享
点赞
4
收藏
1
下载 10
-
快召唤伙伴们来围观吧
-
微博
QQ
QQ空间
贴吧
-
视频嵌入链接
文档嵌入链接
- 复制
-
-
微信扫一扫分享
-
已成功复制到剪贴板

苏锐-Juicedata 合伙人
Juicedata合伙人,作为1号成员参与创建JuiceFS,一直深度参与在开源社区中支持开发者使用JuiceFS。
分享介绍:
在大模型、大数据的今天,大规模的分布式训练成为加速模型训练的必需条件。然而,随着企业GPU的使用量越来越大、对文件容量的需求增长迅猛等诸多因素,使得使得提升底层存储的性能与效率成为挑战。文件系统诞生于上个世纪80年代,伴随着数据需求的爆发式增长,经历了从单机到分布式的演进;同时,云计算也推动着存储的发展,越来越多的企业开始使用云进行备份和存档。一些传统在本地机房进行的高性能计算场景以及很多AI场景,也开始向云端迁移。因此,文件系统也在向云原生的架构进行演进。JuiceFS是一款开源分布式文件系统产品,专为云环境设计,与对象存储结合。目前,JuiceFS已经应用在多个行业的AI应用实践,包括生命科学、无人驾驶、量化投资等等。本次分享将介绍JuiceFS在AI存储领域的设计与实践,同时以自动驾驶领域百亿小文件管理,和量化金融高吞吐模型训练场景的案例分享。
展开查看详情
1 .文件存储在 AI 时代的实践与演进
苏锐,Juicedata 合伙人
1
�
2 .分享内容
• AI 场景中的数据挑战
• 文件存储的发展与选择
• JuiceFS 的设计思路
• 多云上的 AI 训练与数据管理
2
�
3 .数据在 AI 场景中的挑战
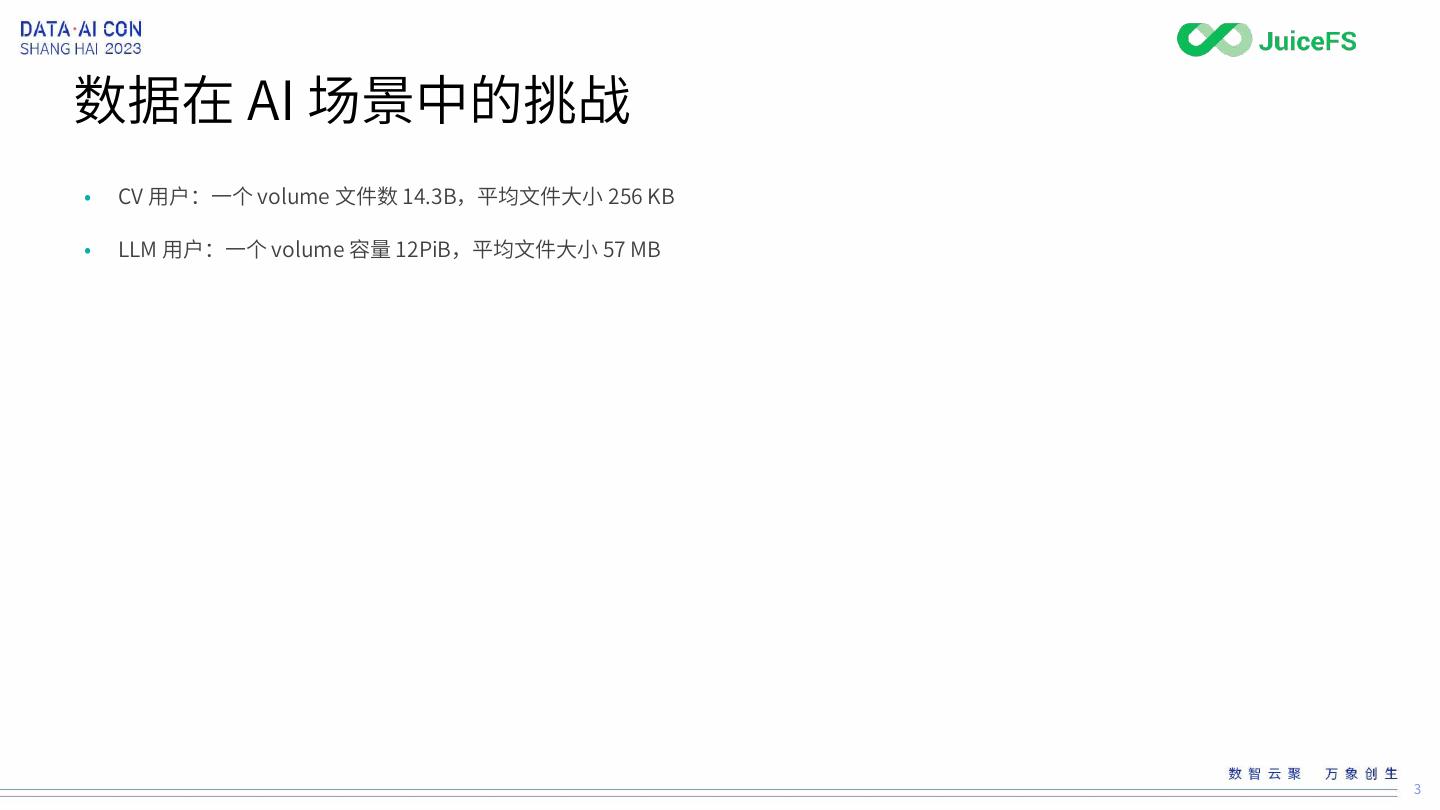
• CV 用户:一个 volume 文件数 14.3B,平均文件大小 256 KB
• LLM 用户:一个 volume 容量 12PiB,平均文件大小 57 MB
3
�
4 .数据在 AI 场景中的挑战
• CV 用户:一个 volume 文件数 14.3B,平均文件大小 256 KB
• LLM 用户:一个 volume 容量 12PiB,平均文件大小 57 MB
常见的存储系统
• HDFS,2006年发布,单 namespace 不要超 5亿文件,RBF 可以扩展,但使用复杂
• CephFS,2006年发布,单 namespace 不要超 10亿文件,运维复杂
• AWS EFS,2016年发布,读吞吐 10GBps,每个客户端最大 500MBps,USD $0.3/GB/mo
4
�
5 .数据在 AI 场景中的挑战
• CV 用户:一个 volume 文件数 14.3B,平均文件大小 256 KB
•
性能
LLM 用户:一个 volume 容量 12PiB,平均文件大小 57 MB
AI 带给存储系统挑战
常见的存储系统
• HDFS,2006年发布,单 namespace 不要超 5亿文件,RBF 可以扩展,但使用复杂
• CephFS,2006年发布,单 namespace 不要超 10亿文件,运维复杂
• AWS EFS,2016年发布,读吞吐 10GBps,每个客户端最大 500MBps,USD $0.3/GB/mo
规模 成本
5
�
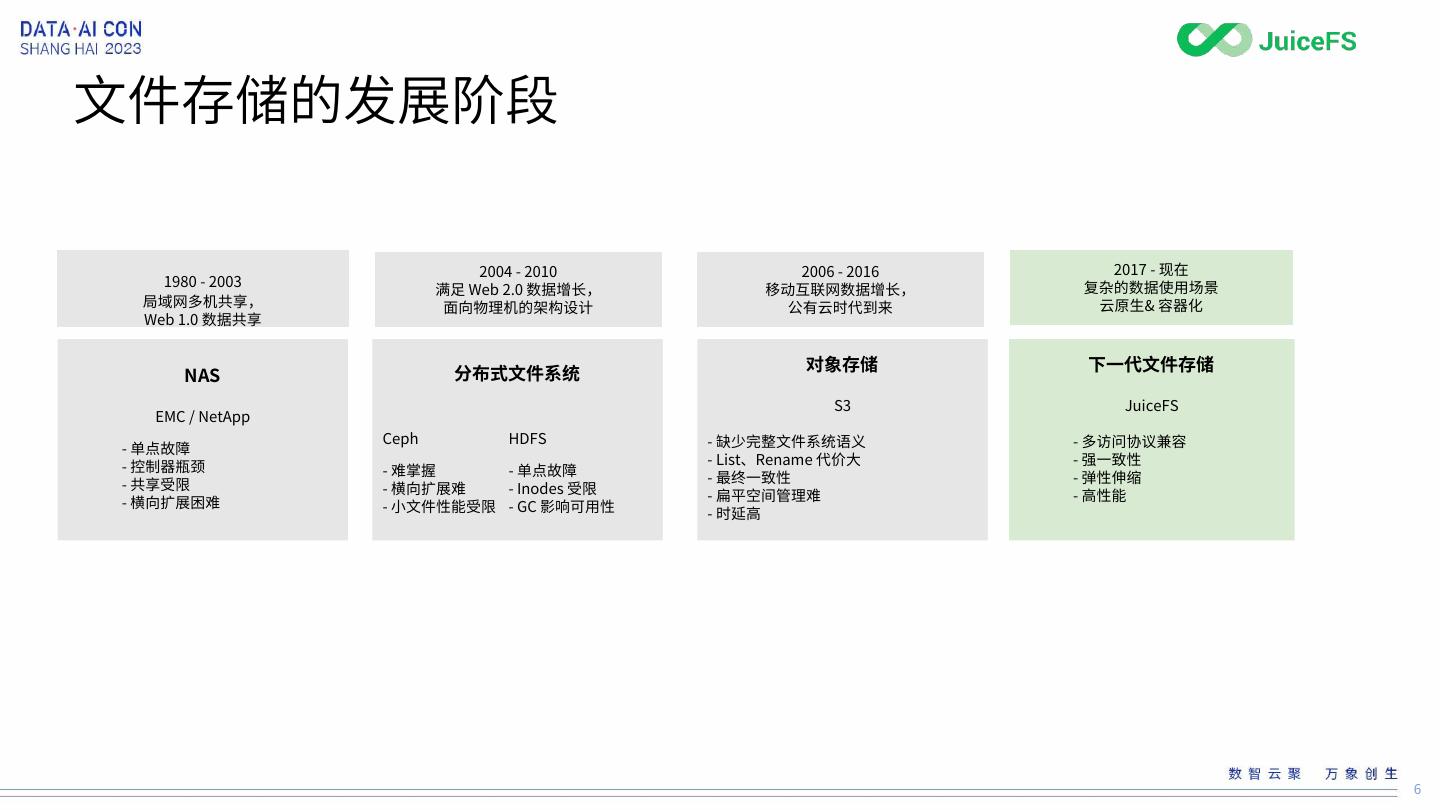
6 .文件存储的发展阶段
2004 - 2010 2006 - 2016 2017 - 现在
1980 - 2003 复杂的数据使用场景
满足 Web 2.0 数据增长, 移动互联网数据增长,
局域网多机共享, 面向物理机的架构设计 公有云时代到来 云原生& 容器化
Web 1.0 数据共享
分布式文件系统 对象存储 下一代文件存储
NAS
S3 JuiceFS
EMC / NetApp
Ceph HDFS - 缺少完整文件系统语义 - 多访问协议兼容
- 单点故障
- 控制器瓶颈 - List、Rename 代价大 - 强一致性
- 难掌握 - 单点故障 - 最终一致性 - 弹性伸缩
- 共享受限 - 横向扩展难 - Inodes 受限
- 横向扩展困难 - 扁平空间管理难 - 高性能
- 小文件性能受限 - GC 影响可用性 - 时延高
6
�
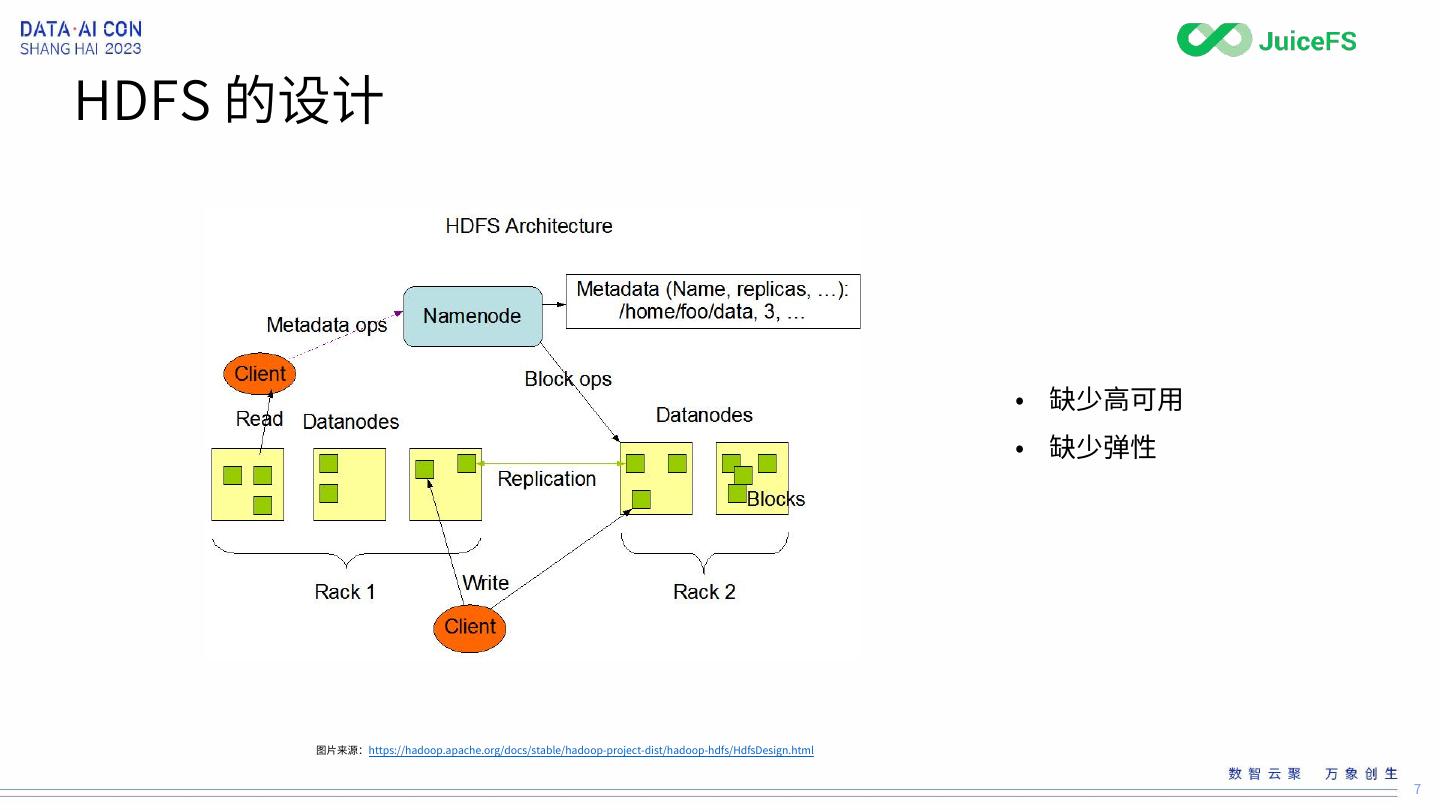
7 .HDFS 的设计
• 缺少高可用
• 缺少弹性
图片来源:https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/HdfsDesign.html
7
�
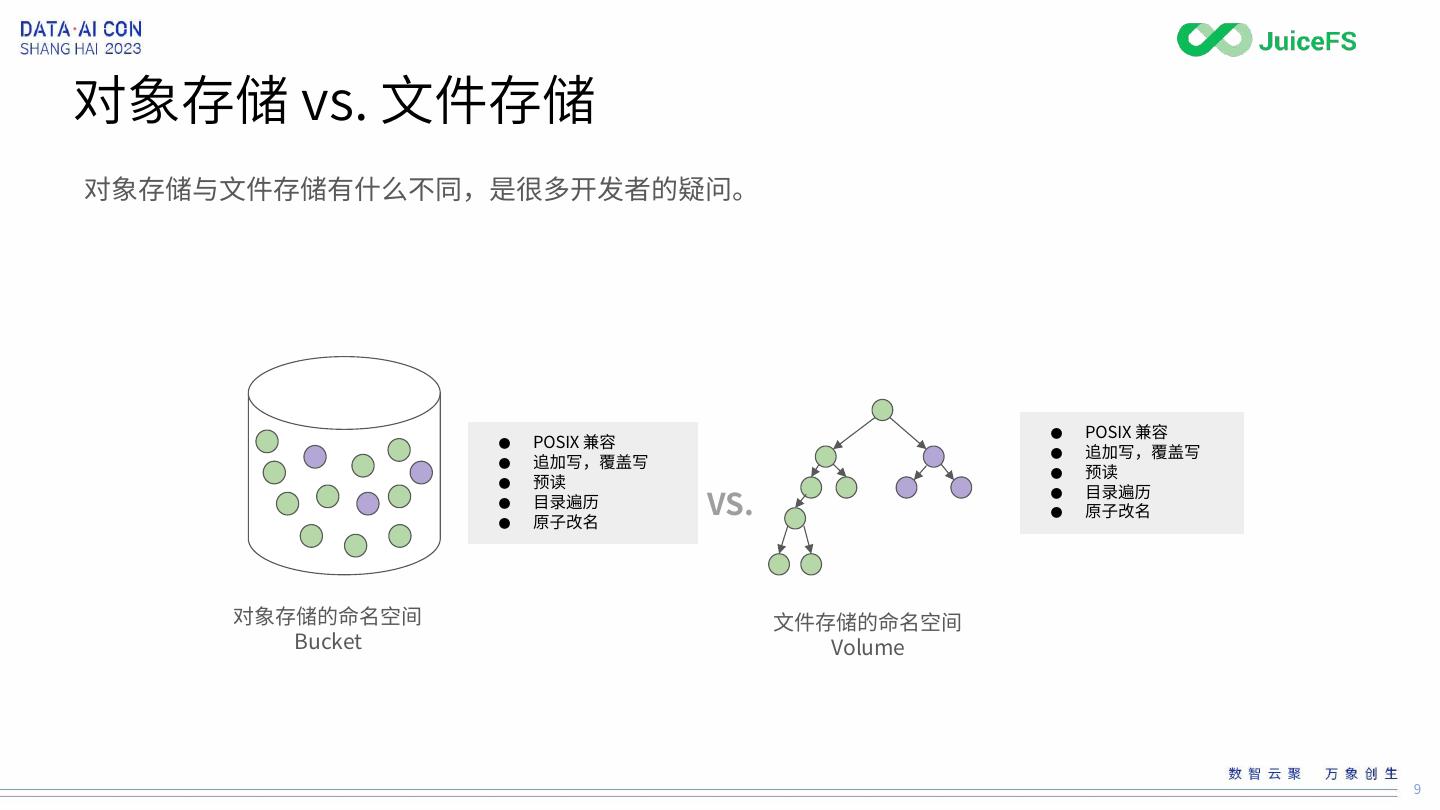
8 .对象存储 vs. 文件存储
对象存储与文件存储有什么不同,是很多开发者的疑问。
VS.
对象存储的命名空间 文件存储的命名空间
Bucket Volume
8
�
9 .对象存储 vs. 文件存储
对象存储与文件存储有什么不同,是很多开发者的疑问。
● POSIX 兼容 ✅︎
● POSIX 兼容 ❌
● 追加写,覆盖写 ✅︎
● 追加写,覆盖写❌
● 预读 ✅︎
预读 ❌
VS.
●
● 目录遍历 ✅︎
● 目录遍历 ❌
● 原子改名 ✅︎
● 原子改名 ❌
对象存储的命名空间 文件存储的命名空间
Bucket Volume
9
�
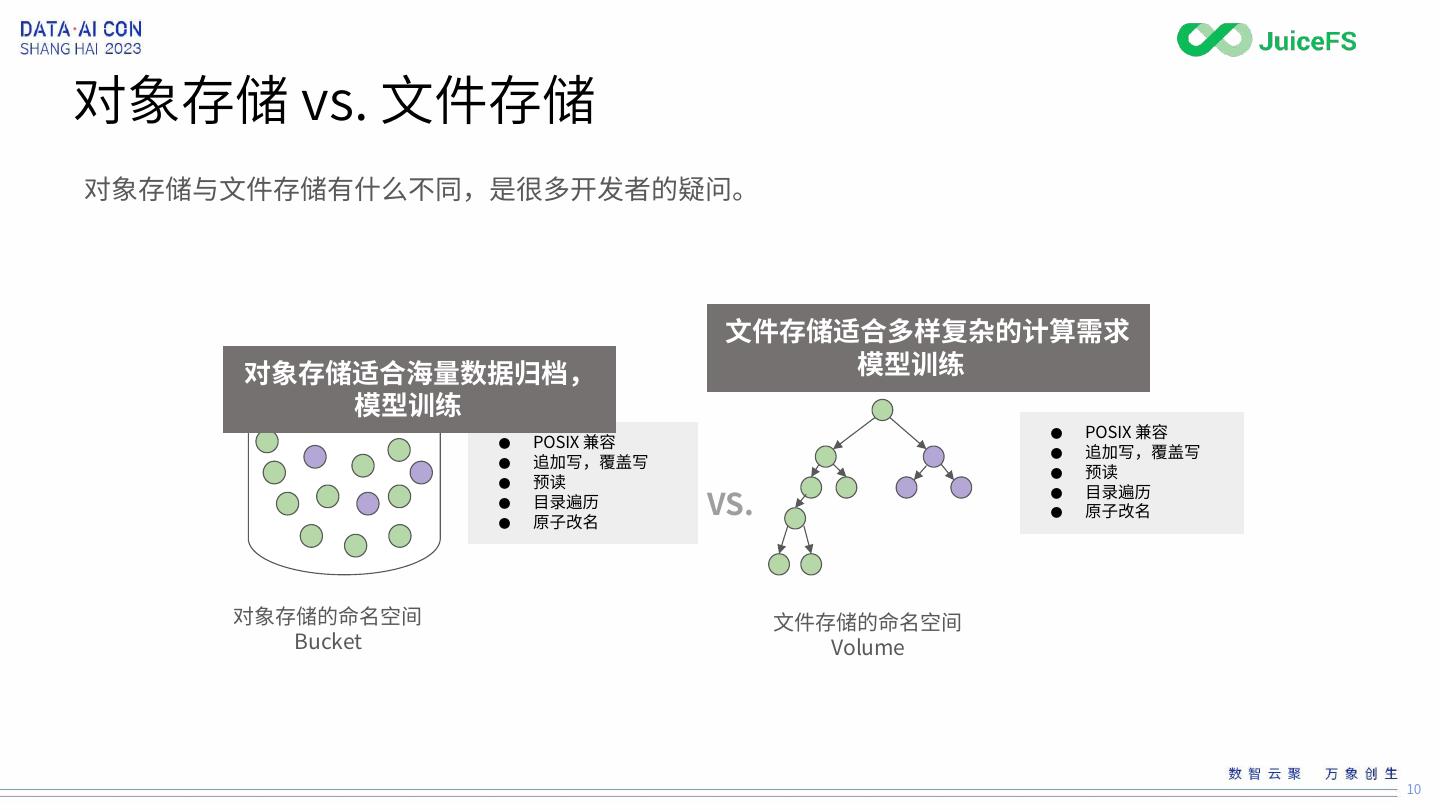
10 .对象存储 vs. 文件存储
对象存储与文件存储有什么不同,是很多开发者的疑问。
文件存储适合多样复杂的计算需求
对象存储适合海量数据归档, 模型训练 ✅︎
模型训练 ❌
● POSIX 兼容 ✅︎
● POSIX 兼容 ❌
● 追加写,覆盖写 ✅︎
● 追加写,覆盖写❌
● 预读 ✅︎
预读 ❌
VS.
●
● 目录遍历 ✅︎
● 目录遍历 ❌
● 原子改名 ✅︎
● 原子改名 ❌
对象存储的命名空间 文件存储的命名空间
Bucket Volume
10
�
11 .很多 AI 用户的无奈选择
计算集群 - 对象存储 解决海量数据低成本存储
- 高性能文件系统 解决训练时的高吞吐需求
但是,两套系统之间的数据管理会随着使
高性能文件存储
-
用规模的增加变得越来越麻烦
对象存储
11
�
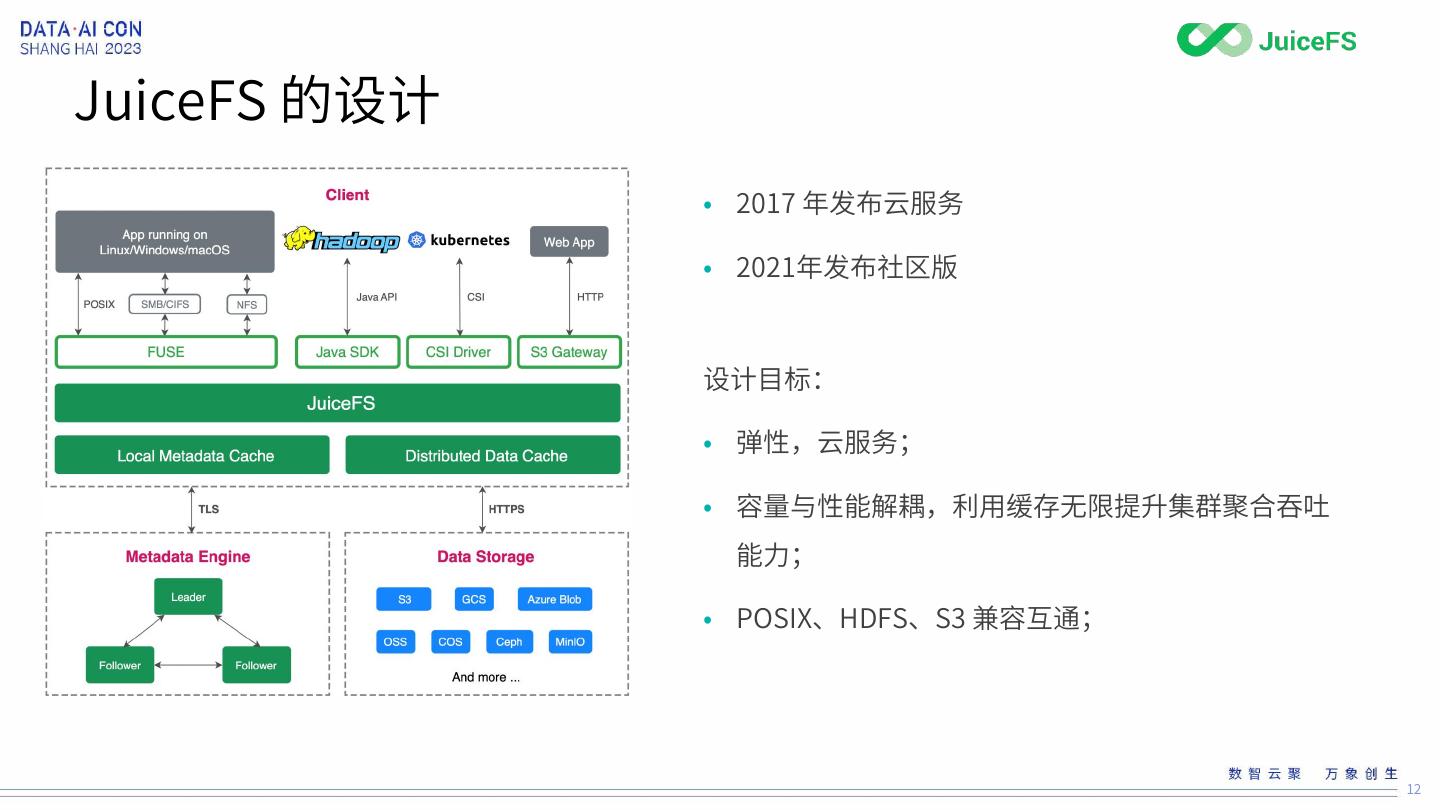
12 .JuiceFS 的设计
• 2017 年发布云服务
• 2021年发布社区版
设计目标:
• 弹性,云服务;
• 容量与性能解耦,利用缓存无限提升集群聚合吞吐
能力;
• POSIX、HDFS、S3 兼容互通;
12
�
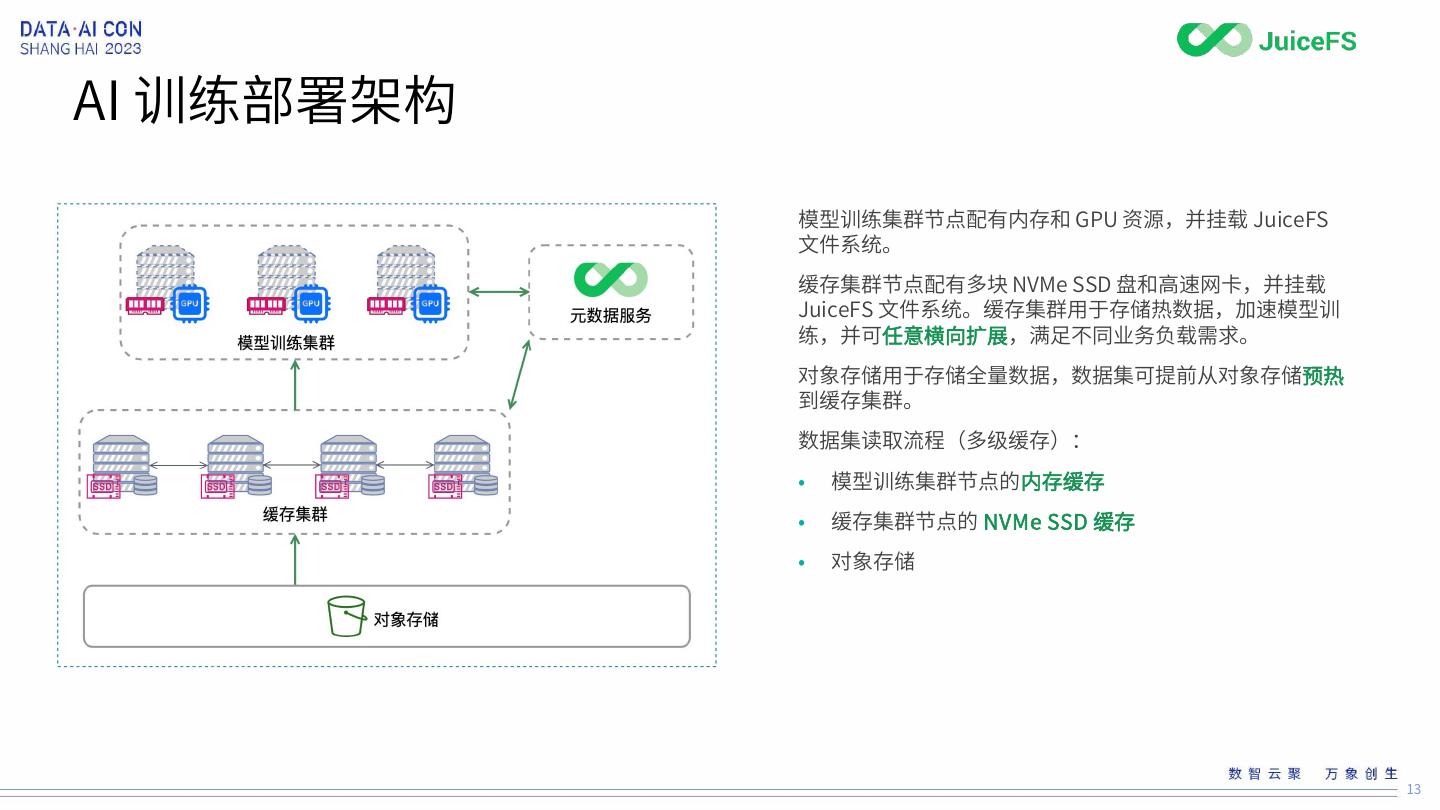
13 .AI 训练部署架构
模型训练集群节点配有内存和 GPU 资源,并挂载 JuiceFS
文件系统。
缓存集群节点配有多块 NVMe SSD 盘和高速网卡,并挂载
JuiceFS 文件系统。缓存集群用于存储热数据,加速模型训
练,并可任意横向扩展,满足不同业务负载需求。
对象存储用于存储全量数据,数据集可提前从对象存储预热
到缓存集群。
数据集读取流程(多级缓存):
• 模型训练集群节点的内存缓存
• 缓存集群节点的 NVMe SSD 缓存
• 对象存储
13
�
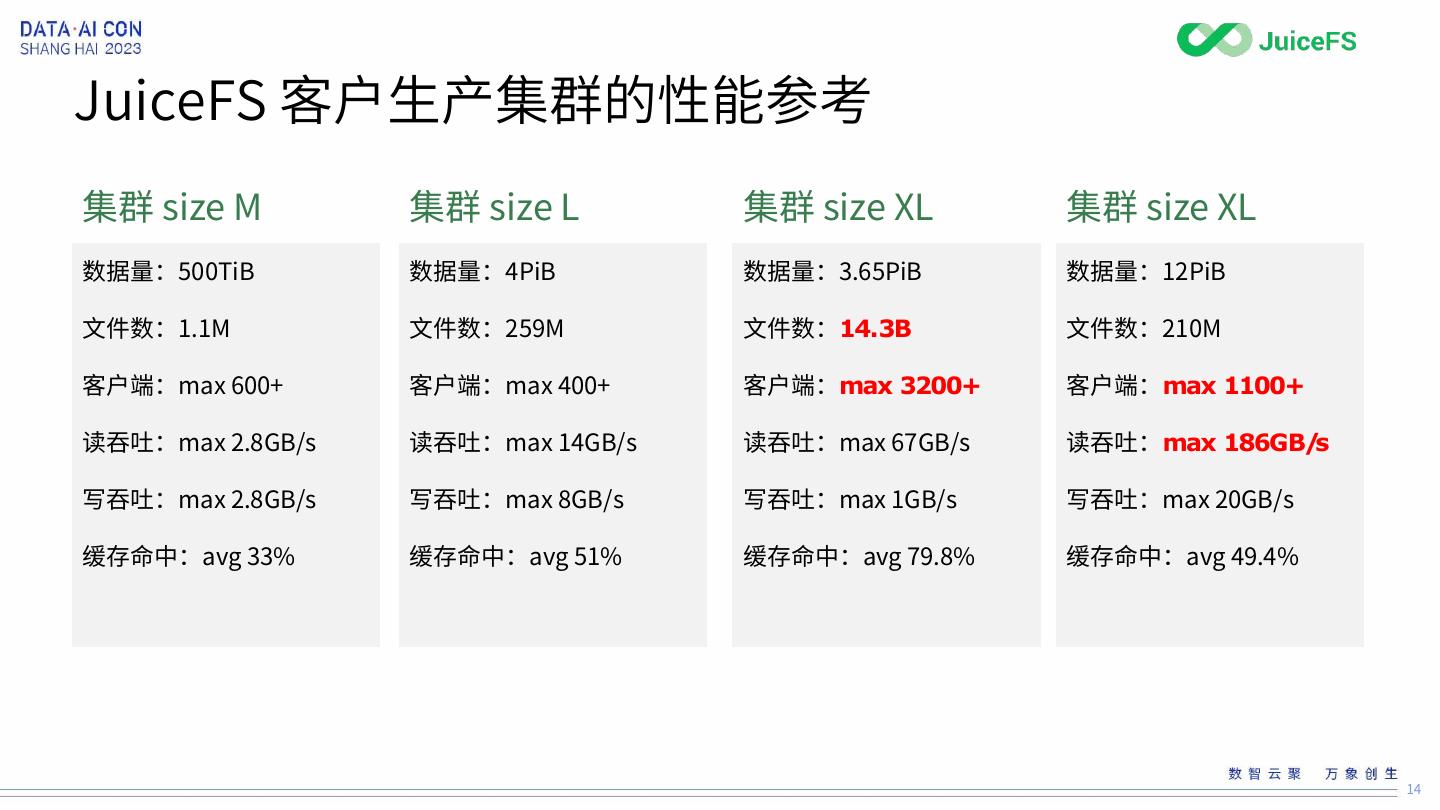
14 .JuiceFS 客户生产集群的性能参考
集群 size M 集群 size L 集群 size XL 集群 size XL
数据量:500TiB 数据量:4PiB 数据量:3.65PiB 数据量:12PiB
文件数:1.1M 文件数:259M 文件数:14.3B 文件数:210M
客户端:max 600+ 客户端:max 400+ 客户端:max 3200+ 客户端:max 1100+
读吞吐:max 2.8GB/s 读吞吐:max 14GB/s 读吞吐:max 67GB/s 读吞吐:max 186GB/s
写吞吐:max 2.8GB/s 写吞吐:max 8GB/s 写吞吐:max 1GB/s 写吞吐:max 20GB/s
缓存命中:avg 33% 缓存命中:avg 51% 缓存命中:avg 79.8% 缓存命中:avg 49.4%
14
�
15 .今天,GPU 稀缺的日子,
多云成了 AI 业务的必选项,
多云数据管理也是必须要解决的问题
15
�
16 .多云算力与多云数据管理
5 维护两套不同的并行文件系统 此外,也有容量限制,文件数限制,
子目录挂载,并发吞吐等限制
计算集群 4 手动扩容 计算集群
6 热数据也要做手工同步
PFS1 PFS2
2 手工复制 3 手工删除
1 手工同步
S3 OSS
云A 云B
16
�
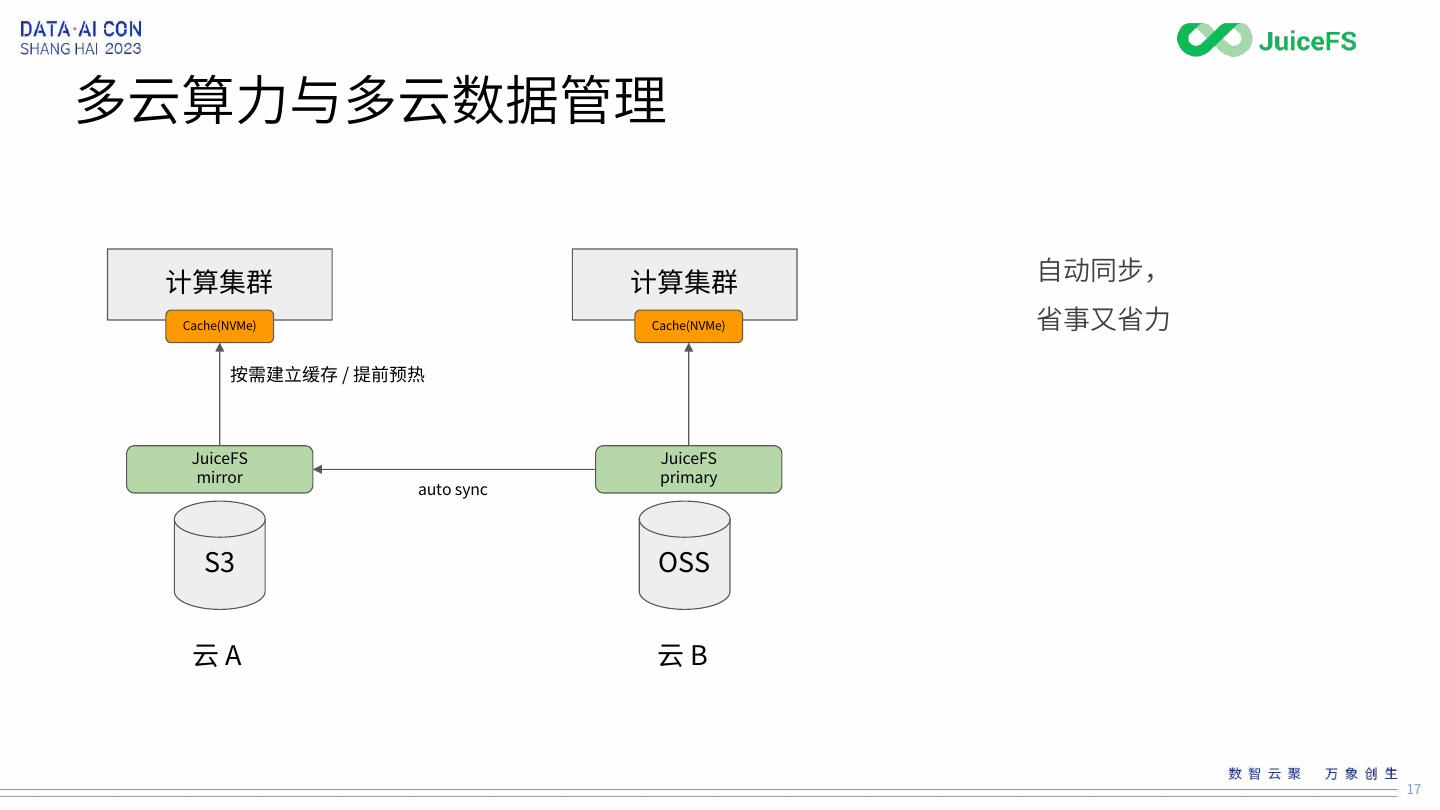
17 .多云算力与多云数据管理
计算集群 计算集群 自动同步,
Cache(NVMe) Cache(NVMe) 省事又省力 �
按需建立缓存 / 提前预热
JuiceFS JuiceFS
mirror primary
auto sync
S3 OSS
云A 云B
17
�