2 . Alluxio 技术发展历程
源自2014年美国伯克利大学AMPLab的开源项目
数据爆炸 云采用 深度学习和AI
大数据和分析的兴起 单云到混合云、多云,跨区域 大模型训练和部署
支持千亿小文件
9/10 头部互联网公司
部署 Alluxio
7/10 头部互联网公司
部署 Alluxio
1000+节点
百度最大部署规模 10亿文件
由Alluxio2.0版本支持
知乎LLM
1000+ 模型训练,Alluxio提供支持
AliPay
开源贡献者
源自美国伯克利 80% 模型训练
100% Presto @
大学AMPLab
Meta
与Alluxio全面集成
1000+ 参会人
数据编排峰会
2014 2019 2023
�
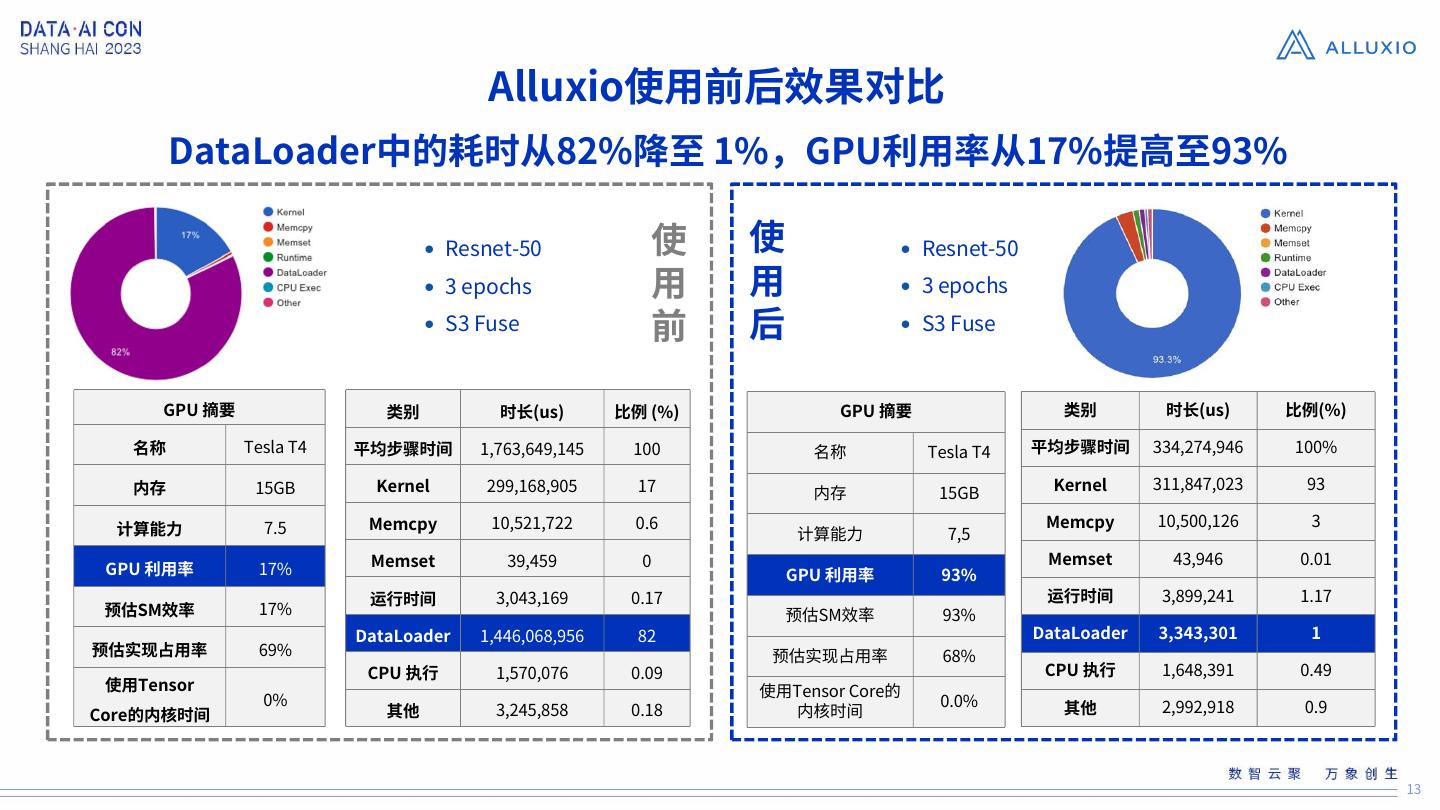
13 . Alluxio使用前后效果对比
DataLoader中的耗时从82%降至 1%,GPU利用率从17%提高至93%
• Resnet-50 使 使 • Resnet-50
• 3 epochs 用 用 • 3 epochs
• S3 Fuse 前 后 • S3 Fuse
GPU 摘要 类别 时长(us) 比例 (%) GPU 摘要 类别 时长(us) 比例(%)
名称 Tesla T4 平均步骤时间 1,763,649,145 100 名称 Tesla T4 平均步骤时间 334,274,946 100%
内存 15GB Kernel 299,168,905 17 Kernel 311,847,023 93
内存 15GB
计算能力 7.5 Memcpy 10,521,722 0.6 Memcpy 10,500,126 3
计算能力 7,5
Memset 39,459 0 Memset 43,946 0.01
GPU 利用率 17% GPU 利用率 93%
运行时间 3,043,169 0.17 运行时间 3,899,241 1.17
预估SM效率 17% 预估SM效率 93%
DataLoader 1,446,068,956 82 DataLoader 3,343,301 1
预估实现占用率 69% 预估实现占用率 68%
CPU 执行 1,570,076 0.09 CPU 执行 1,648,391 0.49
使用Tensor 使用Tensor Core的
0% 0.0% 其他 2,992,918 0.9
Core的内核时间 其他 3,245,858 0.18 内核时间
13
�