











- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 视频嵌入链接 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板

Right-sizes compute for cost efficient AI applications-孙开本
Right-sizes compute for cost efficient AI applications-孙开本
Right-sizes compute for cost efficient AI applications-孙开本

孙开本-Ampere Computing中国区产品市场总监
展开查看详情
1 .Ampere® AI Right-Sizes Your AI Applications Kaiben Sun, Product Marketing Director 1
2 . A MODERN SEMICONDUCTOR COMPANY BUILDING THE FIRST CLOUD-NATIVE PROCESSORS FOR THE SUSTAINABLE CLOUD 2
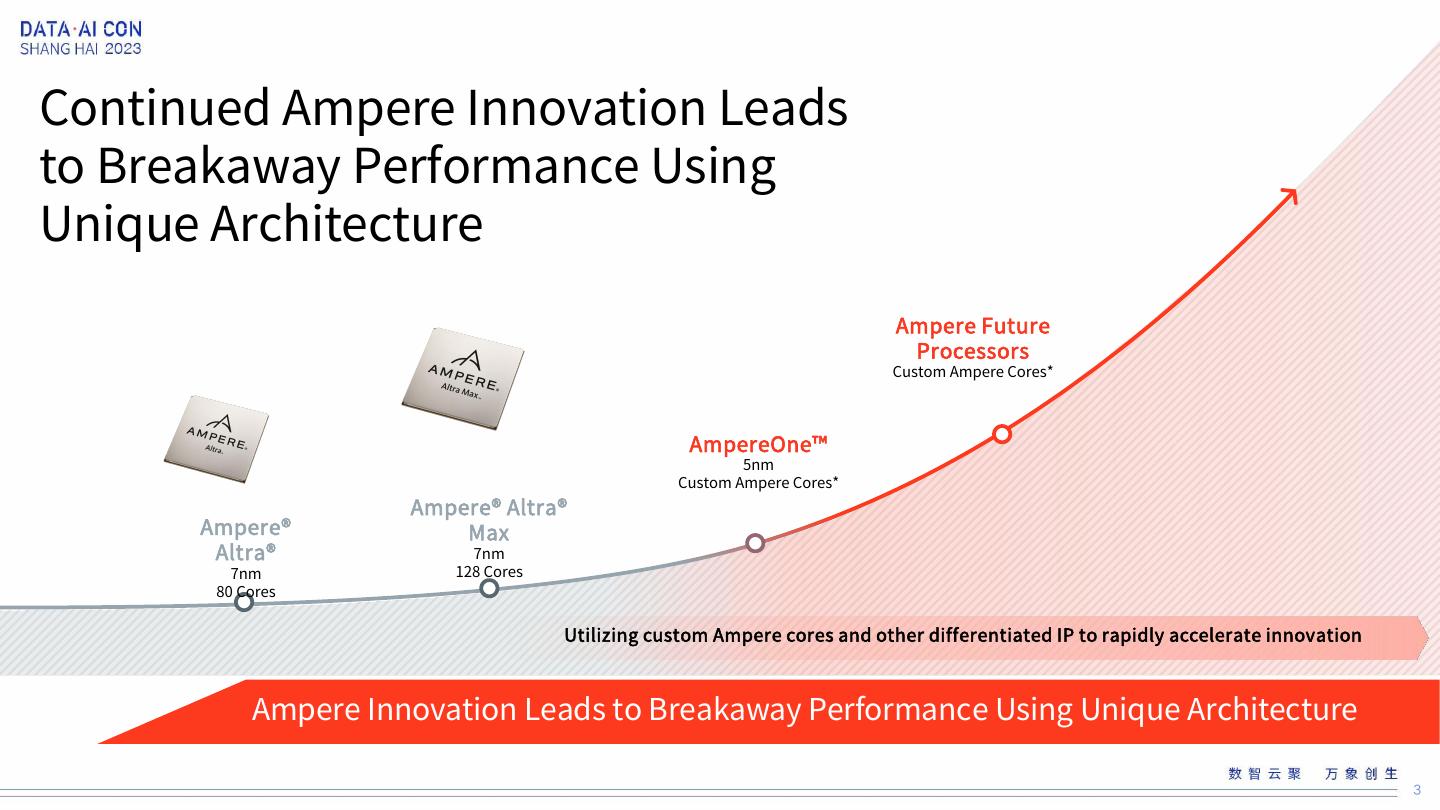
3 .Continued Ampere Innovation Leads to Breakaway Performance Using Unique Architecture Ampere Future Processors Custom Ampere Cores* AmpereOne™ 5nm Custom Ampere Cores* Ampere® Altra® Ampere® Max Altra® 7nm 7nm 128 Cores 80 Cores Utilizing custom Ampere cores and other differentiated IP to rapidly accelerate innovation Ampere Innovation Leads to Breakaway Performance Using Unique Architecture 3
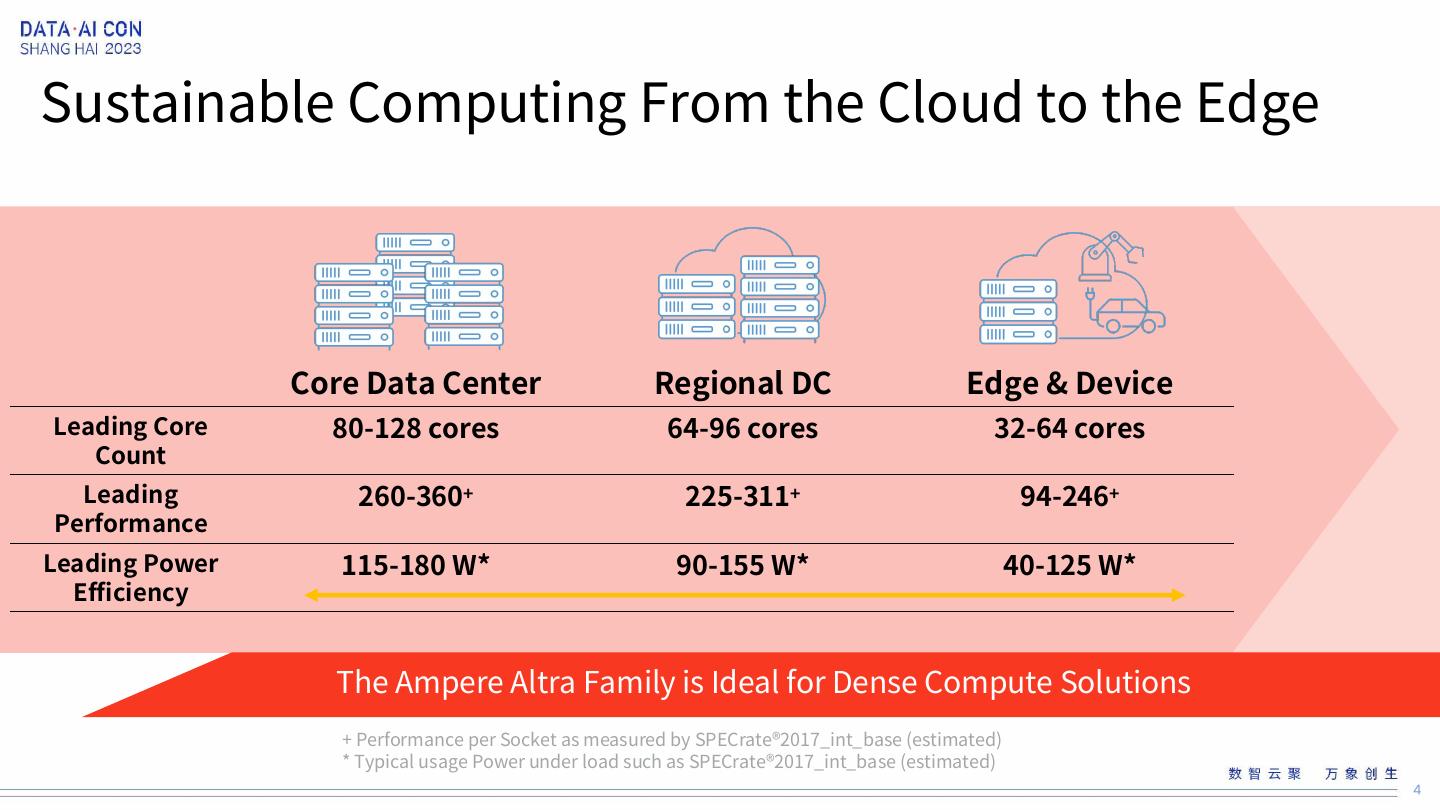
4 .Sustainable Computing From the Cloud to the Edge Core Data Center Regional DC Edge & Device Leading Core 80-128 cores 64-96 cores 32-64 cores Count Leading 260-360+ 225-311+ 94-246+ Performance Leading Power 115-180 W* 90-155 W* 40-125 W* Efficiency The Ampere Altra Family is Ideal for Dense Compute Solutions + Performance per Socket as measured by SPECrate®2017_int_base (estimated) * Typical usage Power under load such as SPECrate®2017_int_base (estimated) 4
5 .The Market’s First Cloud Native Processors Cloud Native Applications & Workloads Run Best on Ampere 5
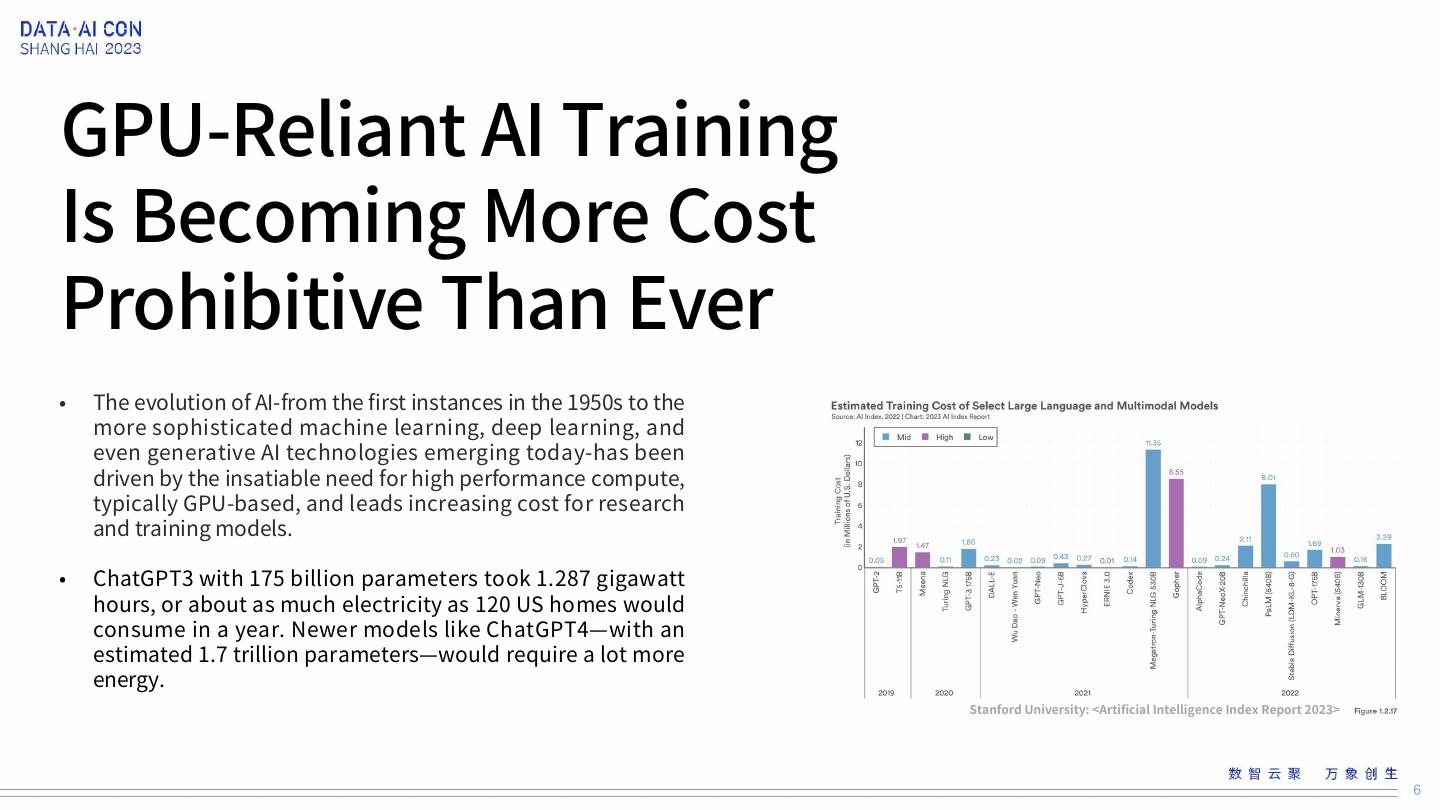
6 .GPU-Reliant AI Training Is Becoming More Cost Prohibitive Than Ever • The evolution of AI-from the first instances in the 1950s to the more sophisticated machine learning, deep learning, and even generative AI technologies emerging today-has been driven by the insatiable need for high performance compute, typically GPU-based, and leads increasing cost for research and training models. • ChatGPT3 with 175 billion parameters took 1.287 gigawatt hours, or about as much electricity as 120 US homes would consume in a year. Newer models like ChatGPT4—with an estimated 1.7 trillion parameters—would require a lot more energy. Stanford University: <Artificial Intelligence Index Report 2023> 6
7 . Mass Adoption of AI Technology In Business Is Not That GPU-Reliant • In many edge applications, especially in mobile and IoT markets, the CPUs do not have the necessary compute power or memory and require some account of hardware acceleration like GPU. • AI inference alone does not represent the complete application. Incoming data needs pre-processing, formatting, and scheduling. These tasks are all performed better by CPUs • CPUs running in data center servers today are extremely powerful, multi-core processors, running at over 3GHz clocks, with large on- chip caches as well as DRAM capacity at their disposal. Stanford University: <Artificial Intelligence Index Report 2023> 7
8 .Right-Sizing Meets Compute and Efficiency Demands • Build AI inference application with CPU-only platform. With the performance gains of Ampere’s Cloud Native Processors, you may be able to deploy as CPU-only for a wider range of AI workloads than with GPU or legacy x86 processors. • Combine GPU with the power efficient Cloud Native Processors for heavier AI training or LLM inferencing workloads. 8
9 . Build More Cost-Effective AI Inference with Ampere CPU-Only • More Efficient:Higher processor usage efficiency, specially for small batch processing • More Flexible:More flexible for SW design and deployment cross-platforms; no dependency Performance on 3rd – party’s HW and SW • Lower Complexity:Simpler OS, driver, Heavy AI workloads Ampere + A/H100 GPU AI Inference Server runtime SW stack Ampere + T4/L4/A10 • High Scalable:Seamless integration with GPU Optimized Inference With Ampere CPU Only other software stacks and microservices architecture paradigms for horizontal scalability Power usages Training • High Perf/$: AI model algorithms continue to Inference innovate On CPU, providing high throughput close to that of GPUs, but at a much lower cost 9
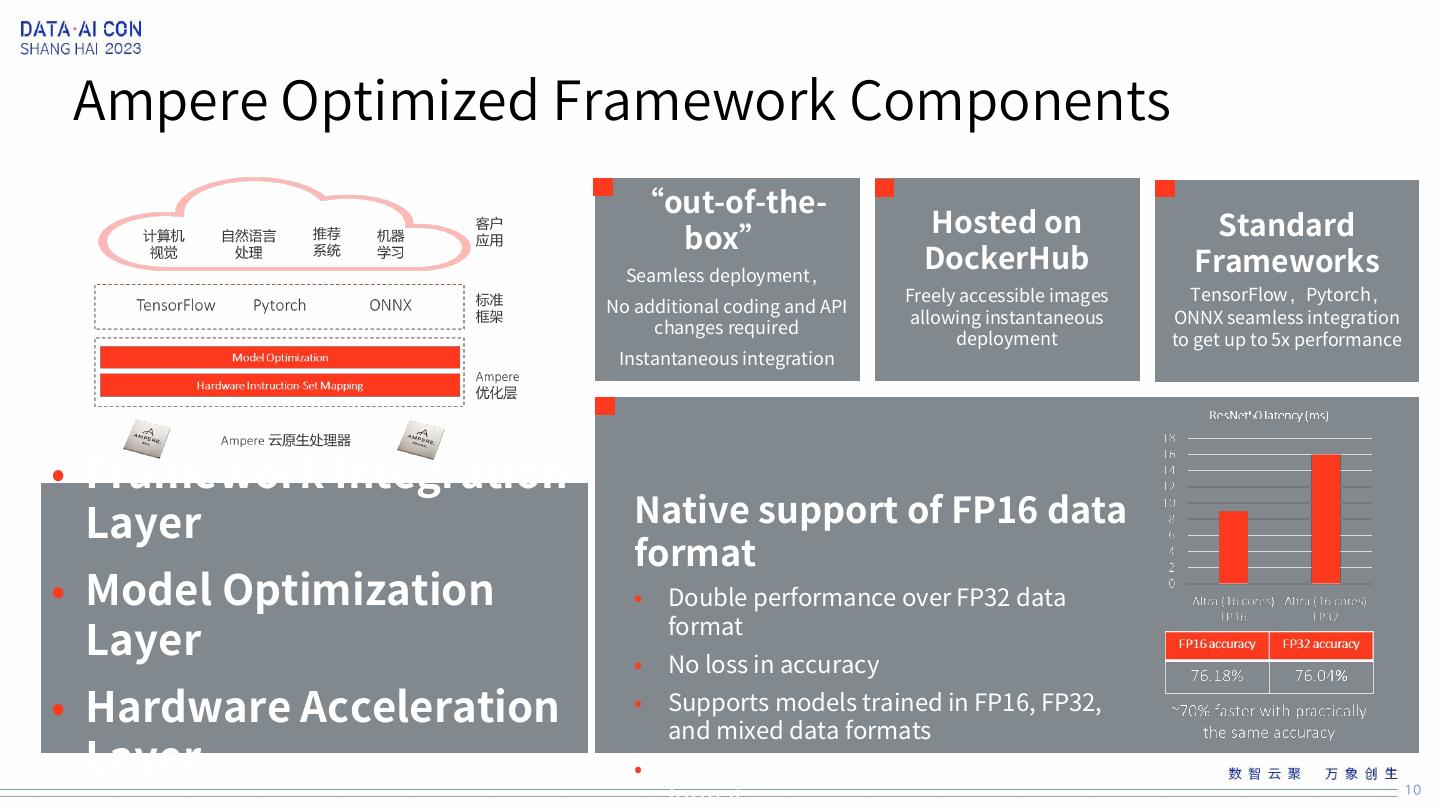
10 .Ampere Optimized Framework Components “out-of-the- Hosted on Standard box” Seamless deployment, DockerHub Frameworks Freely accessible images TensorFlow,Pytorch, No additional coding and API allowing instantaneous ONNX seamless integration changes required deployment to get up to 5x performance Instantaneous integration • Framework Integration Layer Native support of FP16 data format • Model Optimization • Double performance over FP32 data Layer • format No loss in accuracy • Hardware Acceleration • Supports models trained in FP16, FP32, and mixed data formats Layer • Seamless conversion from the FP32 data format 10
11 . Ampere AI Case Studies and Testimonials “Lightly.ai’s customers can achieve over 3x cost reduction "Switching to Ampere-optimized Tensorflow running on running on Ampere T2A instances on GCP using Ampere AI OCI A1 instances has enabled us to achieve a 75 percent software solutions for AI Inference. Ampere instances also provide cost saving for the training of the algorithms for our the best-in-class solution for data preparation and data curation. plastics and fabrics identification machines, while Our customers have optimized costs and used the savings to lowering our CO2 emissions - thanks to Ampere Altra’s invest further in development of their AI applications.” – Igor high energy efficiency." -Martin Holicky, CEO, Matoha Susmelj, Co-Founder, Lightly.ai Advantage Advantage Instance Run-time Cost per Cost($) 30% shorter workload execution hour time GCP T2A 48vCPU 59.3 1.848 $1.83 75% cost reduction mins More predictable performance AWS g4n.2xlarge (T4 + 8 465.1 0.752 $5.83 vCPU) Sustainable mins AI Inference for the Production Phase of AI 11
12 . Ampere AI Case Studies and Testimonials “This breakthrough Wallaroo/Ampere solution allows "Using Ampere A1 instances on OCI with integrated Ampere enterprises to improve inference performance, increase Optimized AI library, we managed to right-size compute energy efficiency, and balance their ML workloads across providing price-performance advantage on deep learning available compute resources much more effectively, all of inferencing relative to GPUs and to other CPUs. We found an which is critical to meeting the huge demand for AI order of magnitude or more reduction in cloud resource costs, computing resources today also while addressing the measured at 4 operating points for 2 cloud vendors, while sustainability impact of the explosion in AI.“ - Vid Jain, CEO, avoiding operational complexity for changes in model serving Wallaroo.AI resource needs and cloud offerings." -Madhuri Yechuri, CEO, Advantage Elotl Advantage P.99 Latency 6X Improvement in execution Model P.99 Latency x86 Ampere time vgg16 27 ms 45 ms More predictable performance squeezenet1_1 26.7 ms 42 ms Sustainable AI Inference for the Production Phase of AI 12
13 .Ampere’s Continuum of Products Ampere® Altra® Family AmpereOne™ Family Cores 32 64 80 96 128 136 144 160 176 192 L2 Private Cache 1MB/Core 2MB/Core Memory Config 8 Channel DDR4 8 Channel DDR5 IO Config 128 Lanes PCIe Gen4 128 Lanes PCIe Gen5 Usage Power 40-180W 200-370W Cloud Native • Single Threaded Cores + • Performance Consistency • Consistent Frequency Mesh Congestion Management Features • • Large Private L2 Cache • Memory & SLC QoS Enforcement • 2x128b Vector Units, FP16, Int16, Int8 • Nested Virtualization • Interrupt & IO Virtualization • Scalable Management • Fine Grained Power Management • Advanced Droop Detection • Process Aging Monitors • Security • Secure Virtualization • Single-Key Memory Encryption • Memory Tagging • FP/AI: Bfloat16, I8MM 13
14 .Ampere GPU-Free AI Inference More Performance Value Ampere GPU- Reliant AI Training Same Performance, Lower Power 14
15 .Follow Us On WeChat 15
16 .16
3秒后跳转登录页面
去登陆

