















- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 视频嵌入链接 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
HDFS在B站的演进-陈世云

陈世云-哔哩哔哩资深开发工程师
2018年加入B站,开始参与维护Hadoop离线平台基础建设工作,目前在B站负责HDFS,Alluxio等存储场景。
分享介绍:
1、HDFS 读请求缓存方法,多租户优先级实践方案等,2、HDFS结合Alluxio cache存储加速方案实践,3、HDFS namenode 锁竞争优化实践。
展开查看详情
1 .HDFS 在B站的演进 陈世云-Bilibili资深开发工程师 1
2 .B站大数据简介 2
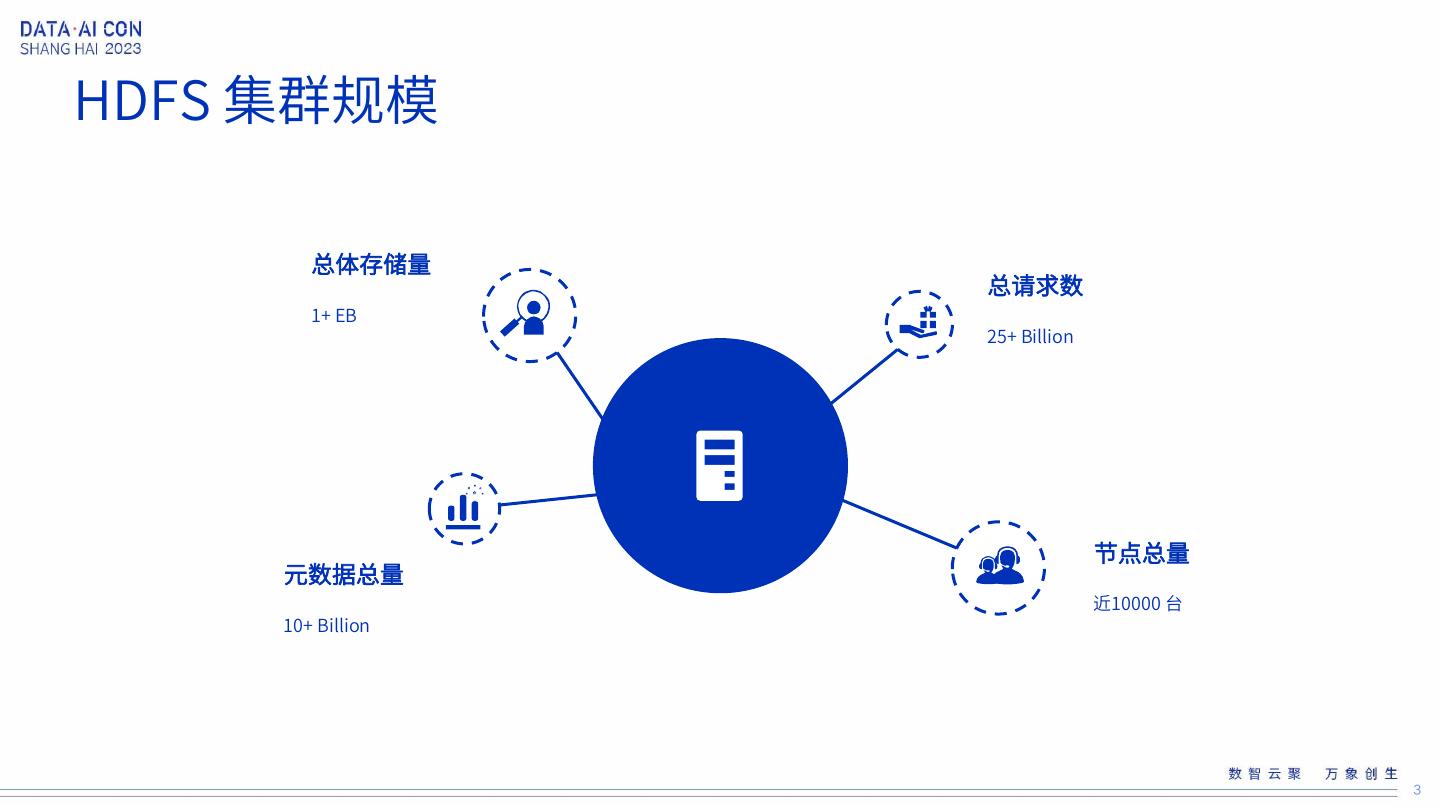
3 .HDFS 集群规模 总体存储量 总请求数 1+ EB 25+ Billion 节点总量 元数据总量 近10000 台 10+ Billion 3
4 .HDFS在B站的演进 4
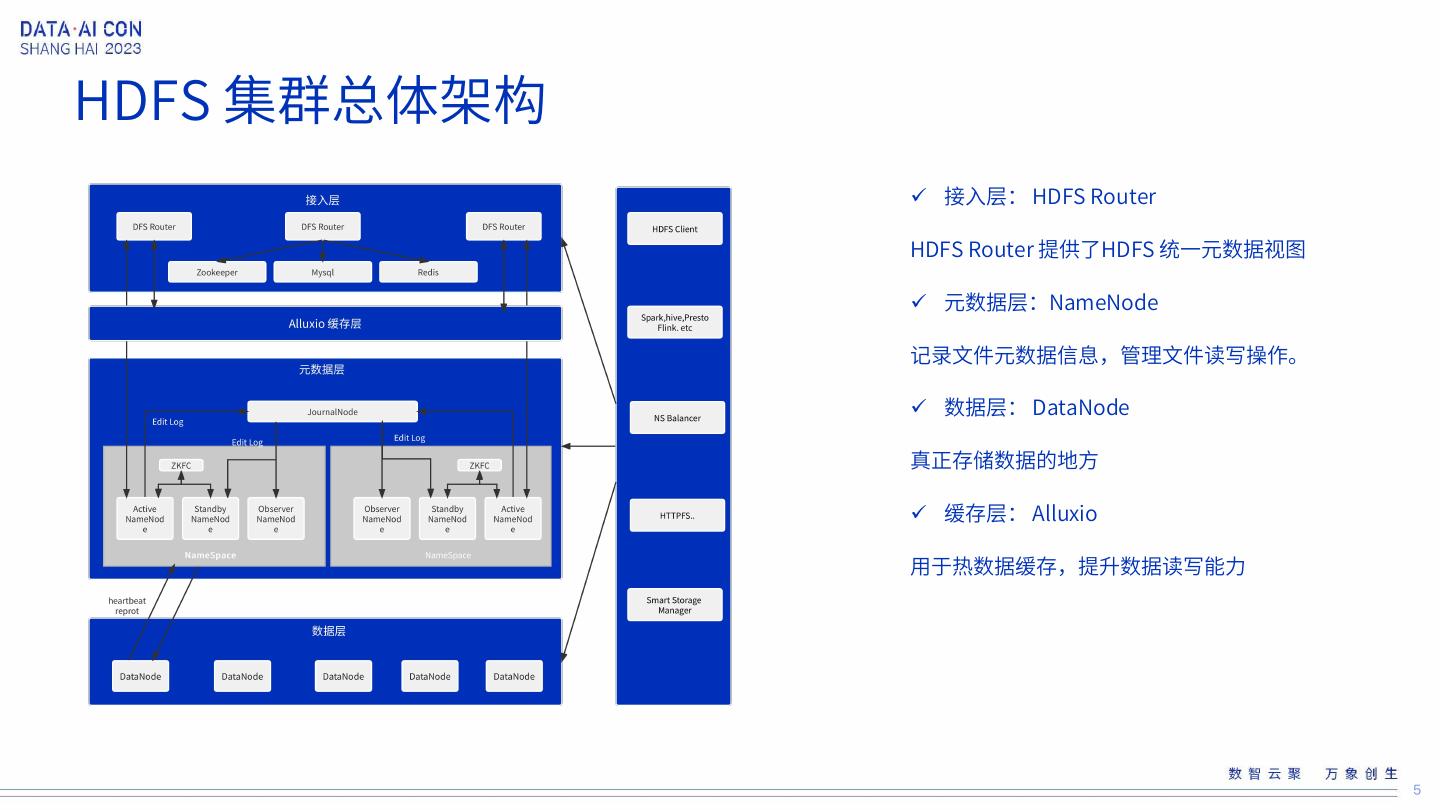
5 .HDFS 集群总体架构 接入层: HDFS Router HDFS Router 提供了HDFS 统一元数据视图 元数据层:NameNode 记录文件元数据信息,管理文件读写操作。 数据层: DataNode 真正存储数据的地方 缓存层: Alluxio 用于热数据缓存,提升数据读写能力 5
6 .HDFS在B站的演进 稳定性 成本 性能 6
7 .HDFS稳定性演进 1 HDFS NameNode 优先级保障策略 2 HDFS DataNode 优先级保障策略 HDFS 基于业务等级 进行分级保障 3 HDFS 重要数据灾备策略 4 HDFS Decomission优化策略 7
8 .HDFS分级保障背景 1、流量突增 大型活动流量突增,导致HDFS部份NameSpace系统过载 2、数据分布 整体集群中存在约5%的数据相比于其他数据具有更高的影响力,对业务的影响更大 3、业务发展 资源和业务之间增长不同步,保障各种突发情况下高优先机数据和相关作业的读写效率 4、降本增效 统一制定数据优先级,任务优先级,减少低优先级数据存储和读写成本 8
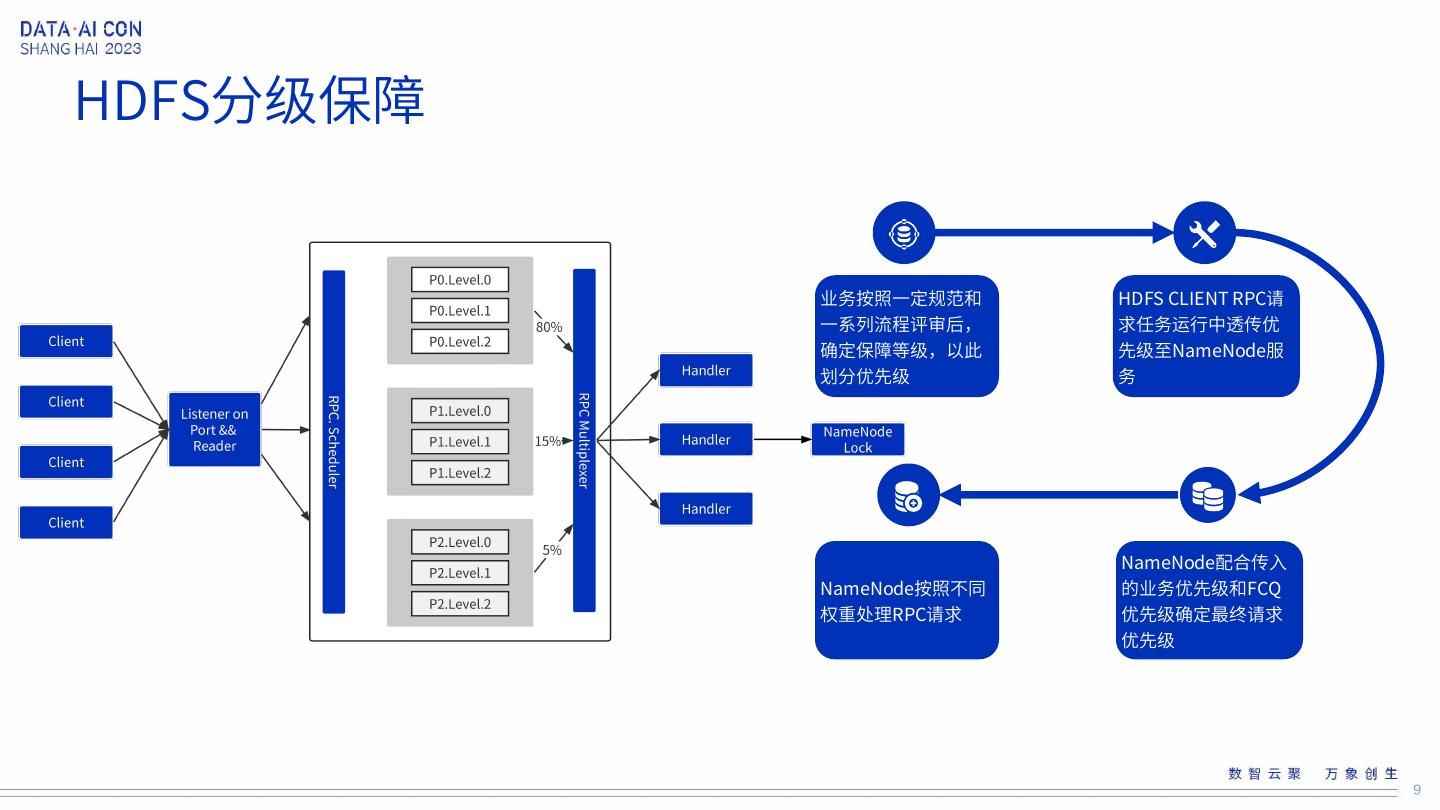
9 .HDFS分级保障 业务按照一定规范和 HDFS CLIENT RPC请 一系列流程评审后, 求任务运行中透传优 确定保障等级,以此 先级至NameNode服 划分优先级 务 NameNode配合传入 NameNode按照不同 的业务优先级和FCQ 权重处理RPC请求 优先级确定最终请求 优先级 9
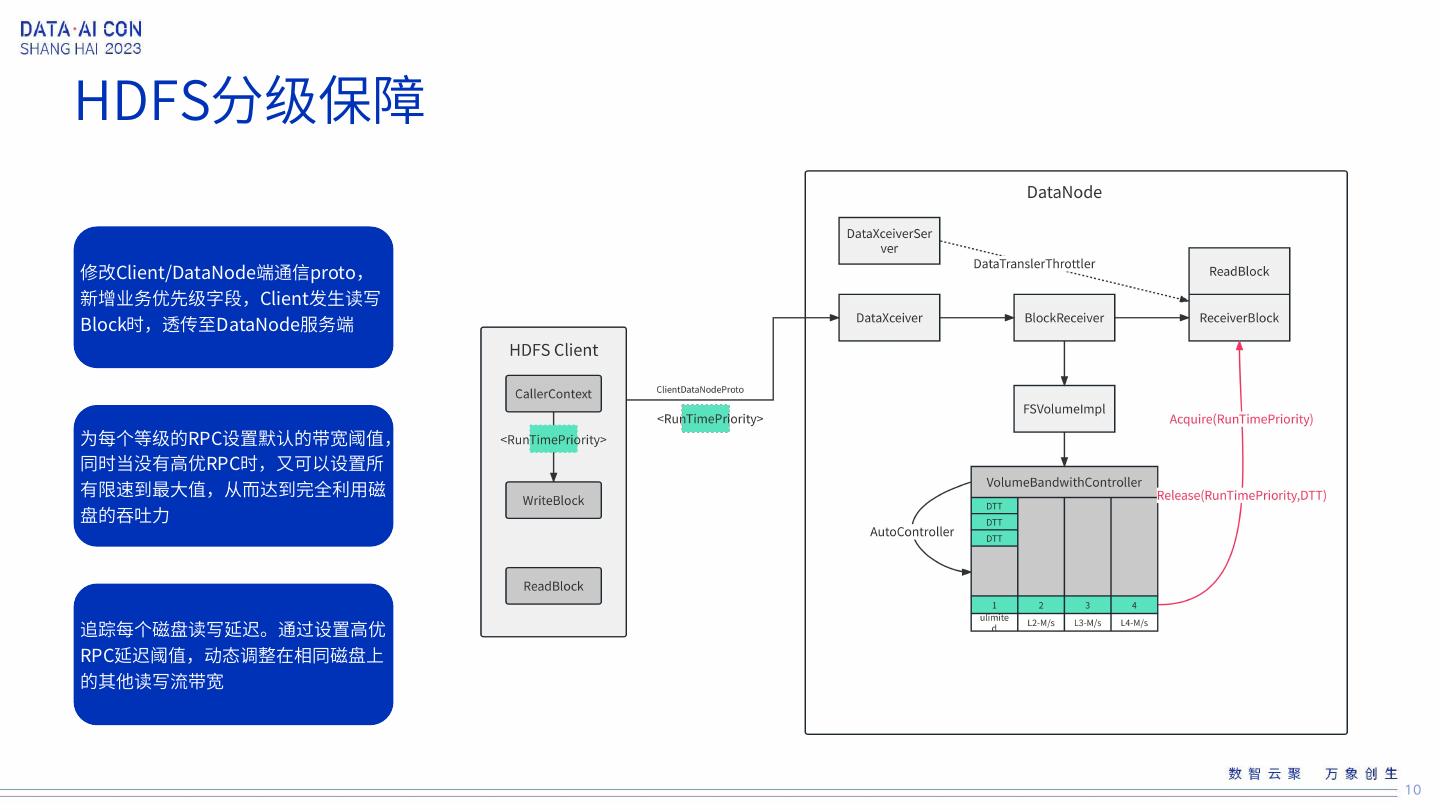
10 .HDFS分级保障 修改Client/DataNode端通信proto, 新增业务优先级字段,Client发生读写 Block时,透传至DataNode服务端 为每个等级的RPC设置默认的带宽阈值, 同时当没有高优RPC时,又可以设置所 有限速到最大值,从而达到完全利用磁 盘的吞吐力 追踪每个磁盘读写延迟。通过设置高优 RPC延迟阈值,动态调整在相同磁盘上 的其他读写流带宽 10
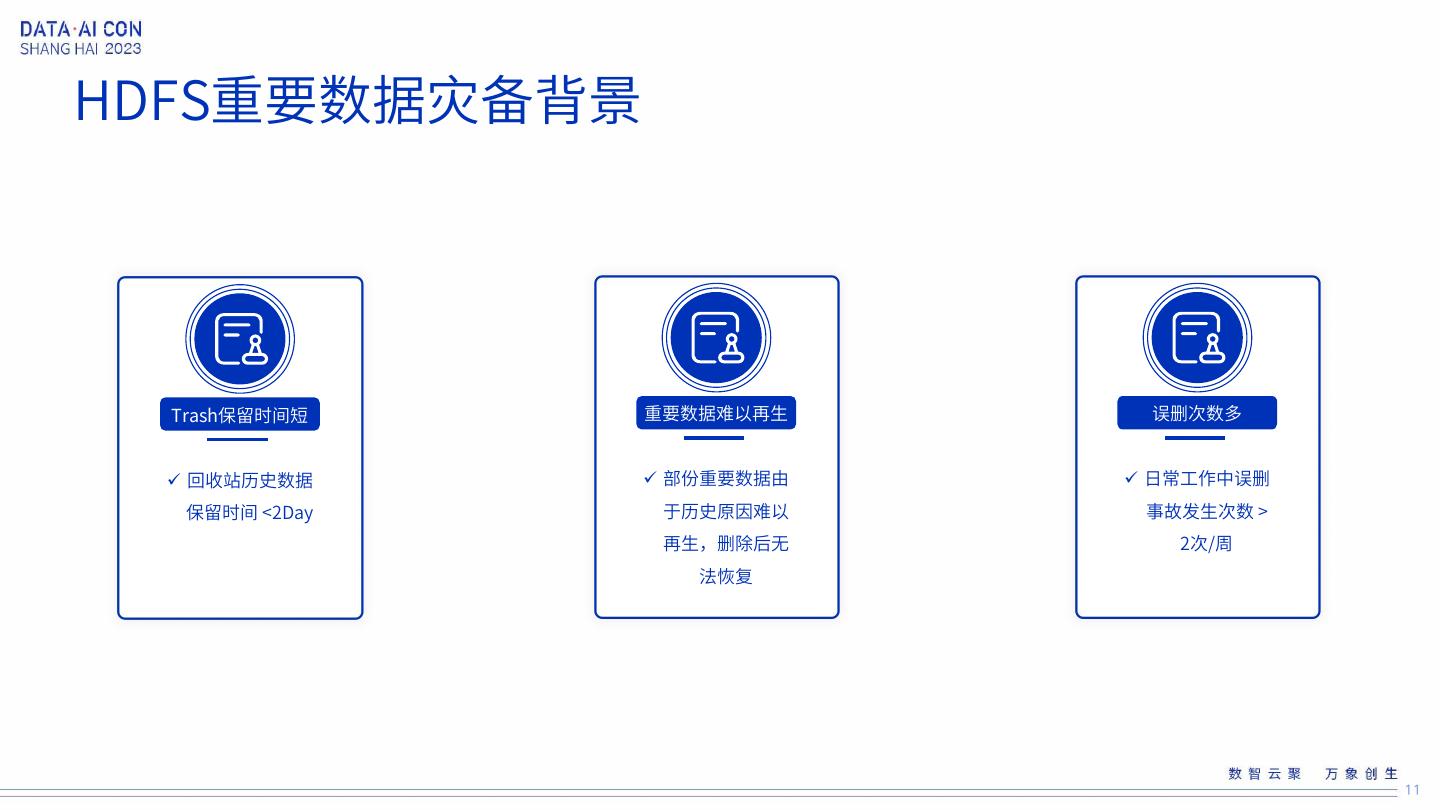
11 .HDFS重要数据灾备背景 Trash保留时间短 重要数据难以再生 误删次数多 回收站历史数据 部份重要数据由 日常工作中误删 保留时间 <2Day 于历史原因难以 事故发生次数 > 再生,删除后无 2次/周 法恢复 11
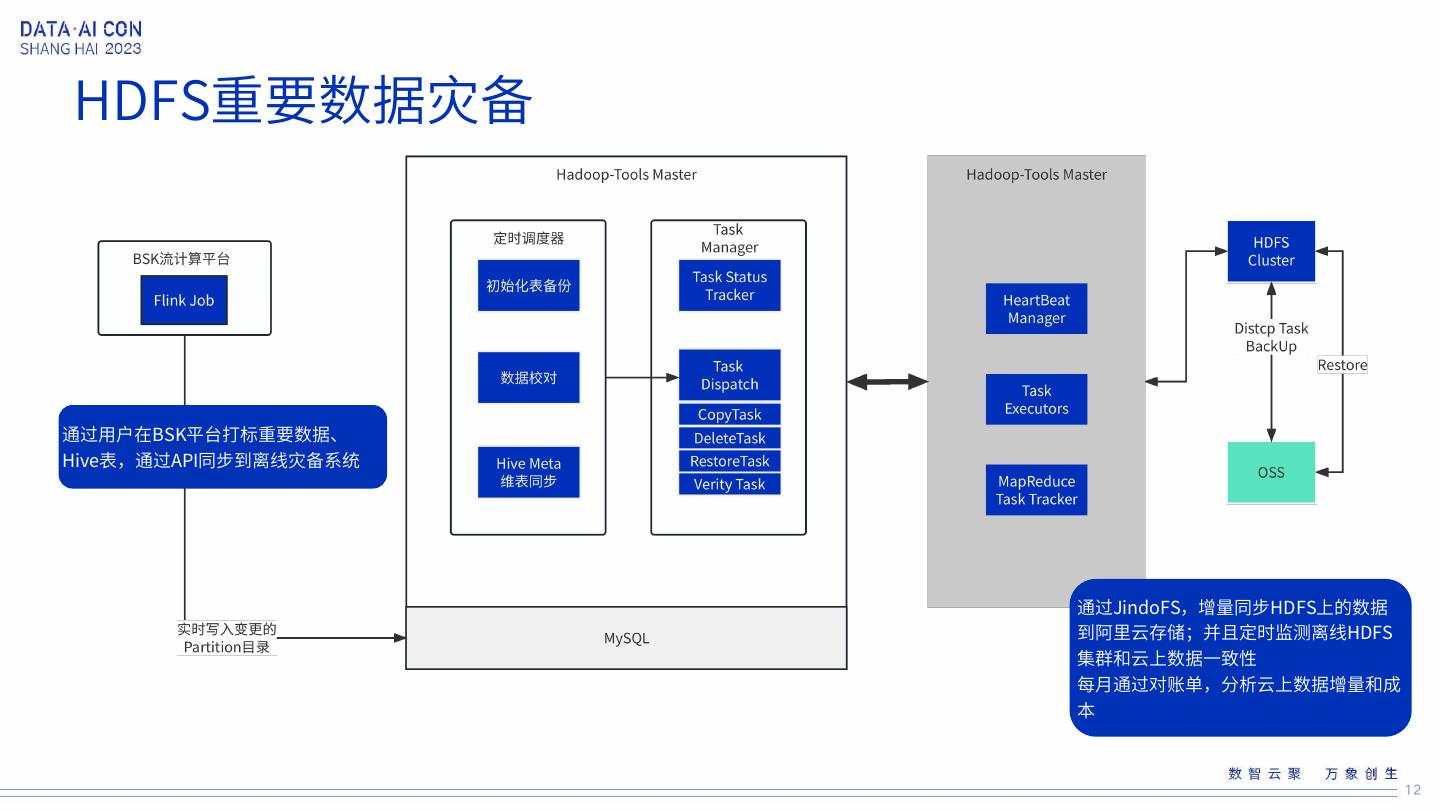
12 .HDFS重要数据灾备 通过用户在BSK平台打标重要数据、 Hive表,通过API同步到离线灾备系统 通过JindoFS,增量同步HDFS上的数据 到阿里云存储;并且定时监测离线HDFS 集群和云上数据一致性 每月通过对账单,分析云上数据增量和成 本 12
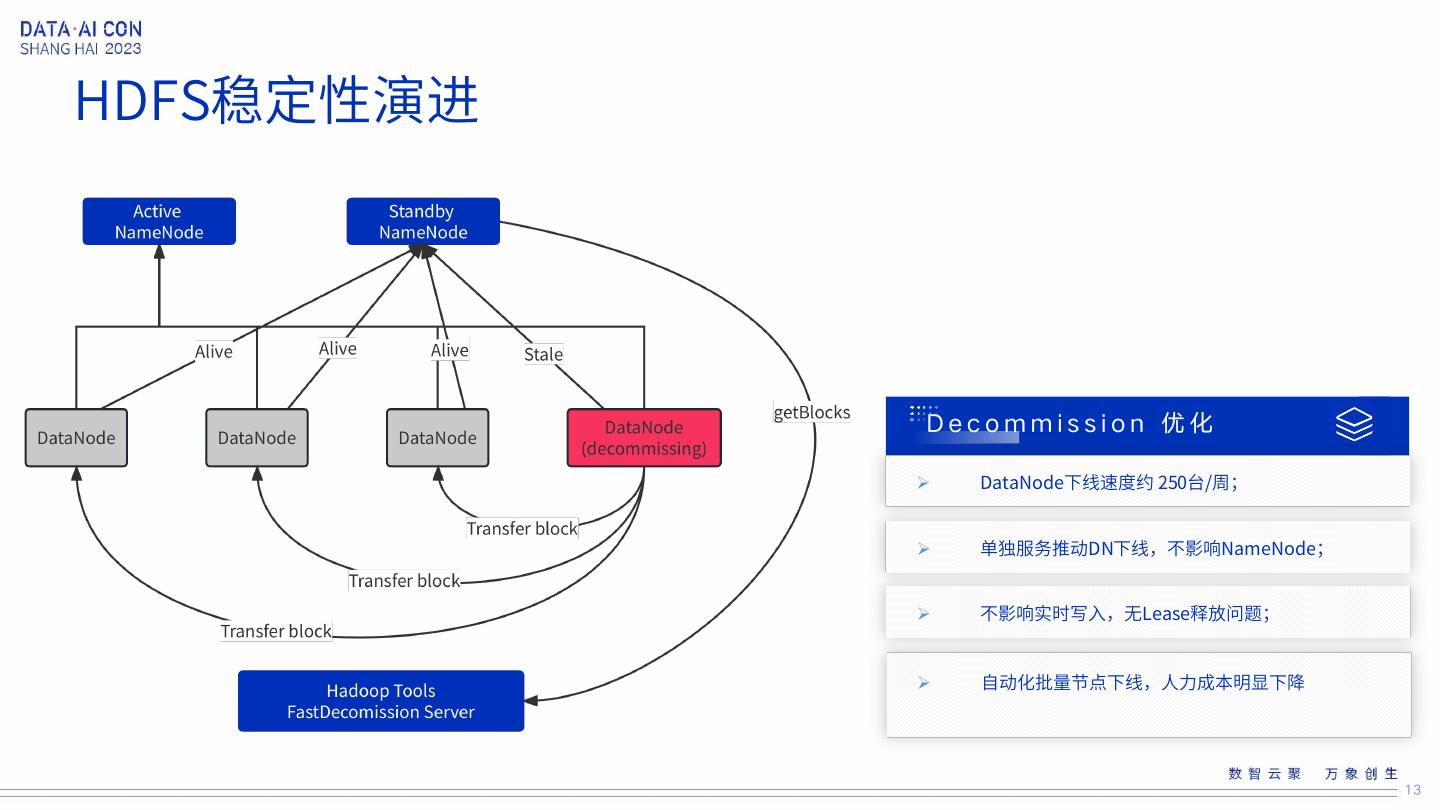
13 .HDFS稳定性演进 Decommission 优化 DataNode下线速度约 250台/周; 单独服务推动DN下线,不影响NameNode; 不影响实时写入,无Lease释放问题; 自动化批量节点下线,人力成本明显下降 13
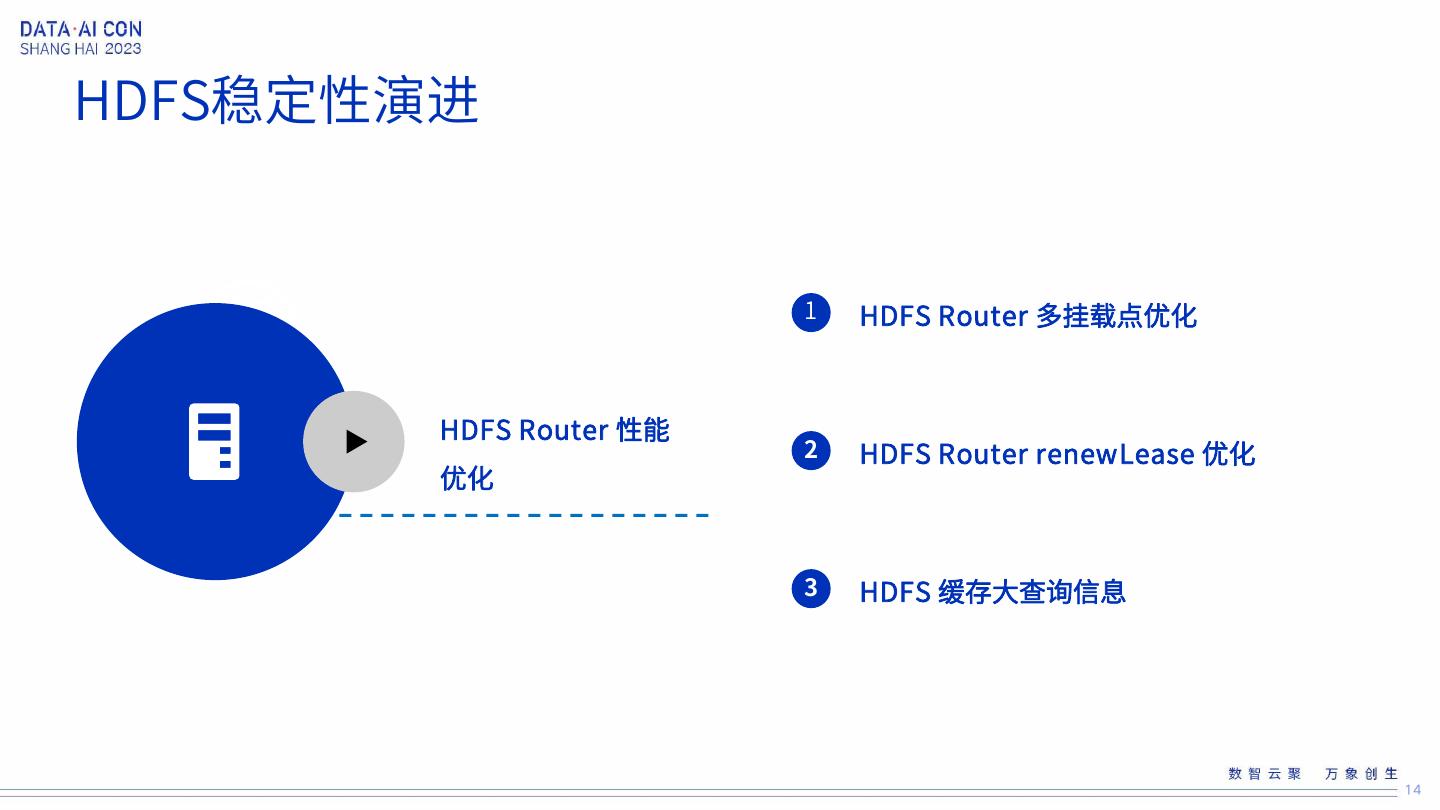
14 .HDFS稳定性演进 1 HDFS Router 多挂载点优化 HDFS Router 性能 2 HDFS Router renewLease 优化 优化 3 HDFS 缓存大查询信息 14
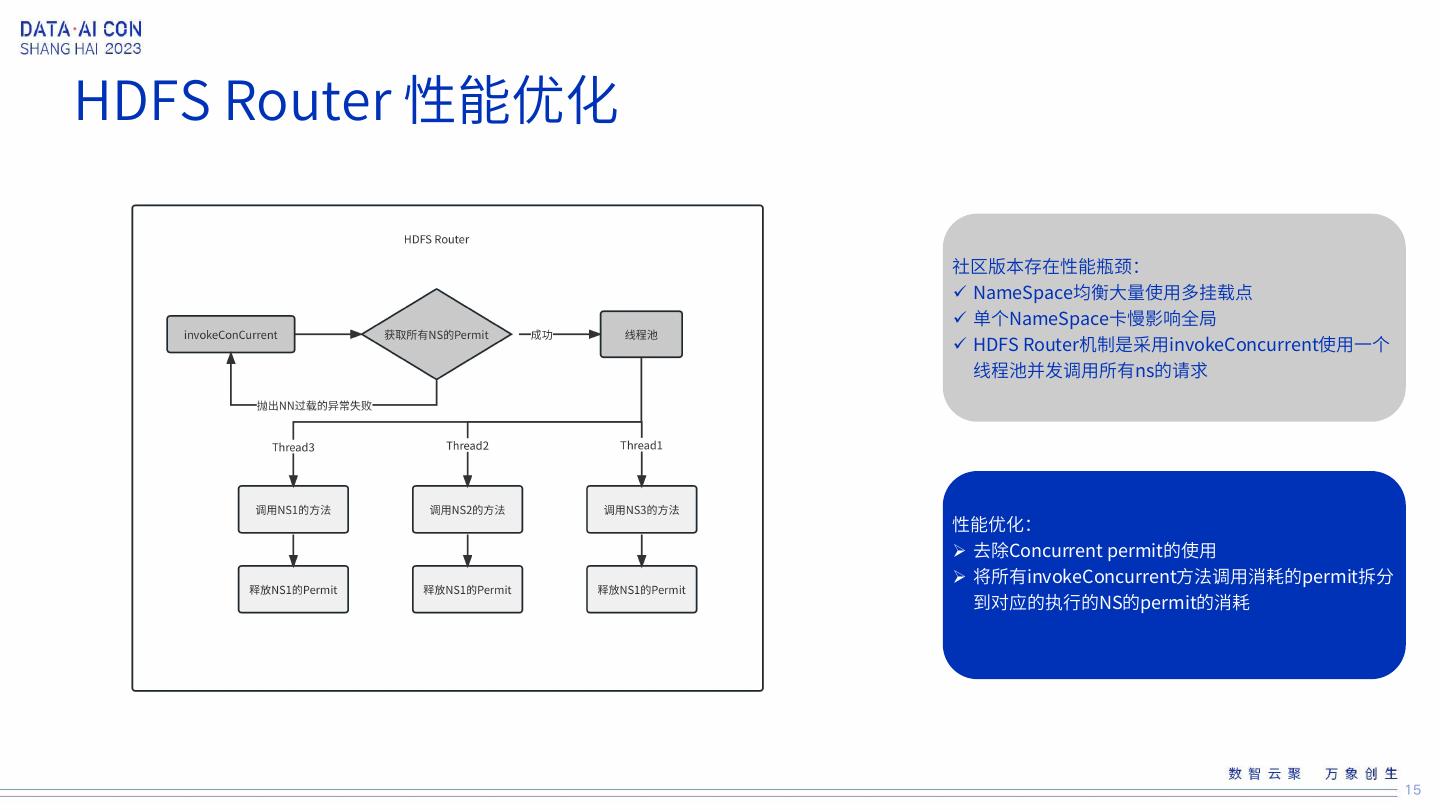
15 .HDFS Router 性能优化 社区版本存在性能瓶颈: NameSpace均衡大量使用多挂载点 单个NameSpace卡慢影响全局 HDFS Router机制是采用invokeConcurrent使用一个 线程池并发调用所有ns的请求 性能优化: 去除Concurrent permit的使用 将所有invokeConcurrent方法调用消耗的permit拆分 到对应的执行的NS的permit的消耗 15
16 .HDFS Router 性能优化 社区版本性能瓶颈: HDFS Client RenewLease方法需要广播所有 NS,局部NS慢影响全局 性能优化: 引入Redis HDFS Router 维护Client和NS之间mapping关系 Client的renewLease请求转发到对应NS HDFS Client RenewLease 耗时: 10s -> 100ms 16
17 .HDFS Router 性能优化 HDFS Router 缓存大查询信息 性能优化: 引入Redis缓存大目录getListing请求 缓存 topK( ( item_cnt / 1000 ) * query_cnt ) 个数目录 信息 3天自然过期 & 增删改主动过期 效果: 缓存的查询占总查询的38%左右,访问缓存的成功率 达到99.9%。 整体getListing 耗时均值下降 22ms -> 14ms 17
18 .HDFS在B站的演进 稳定性 成本 性能 18
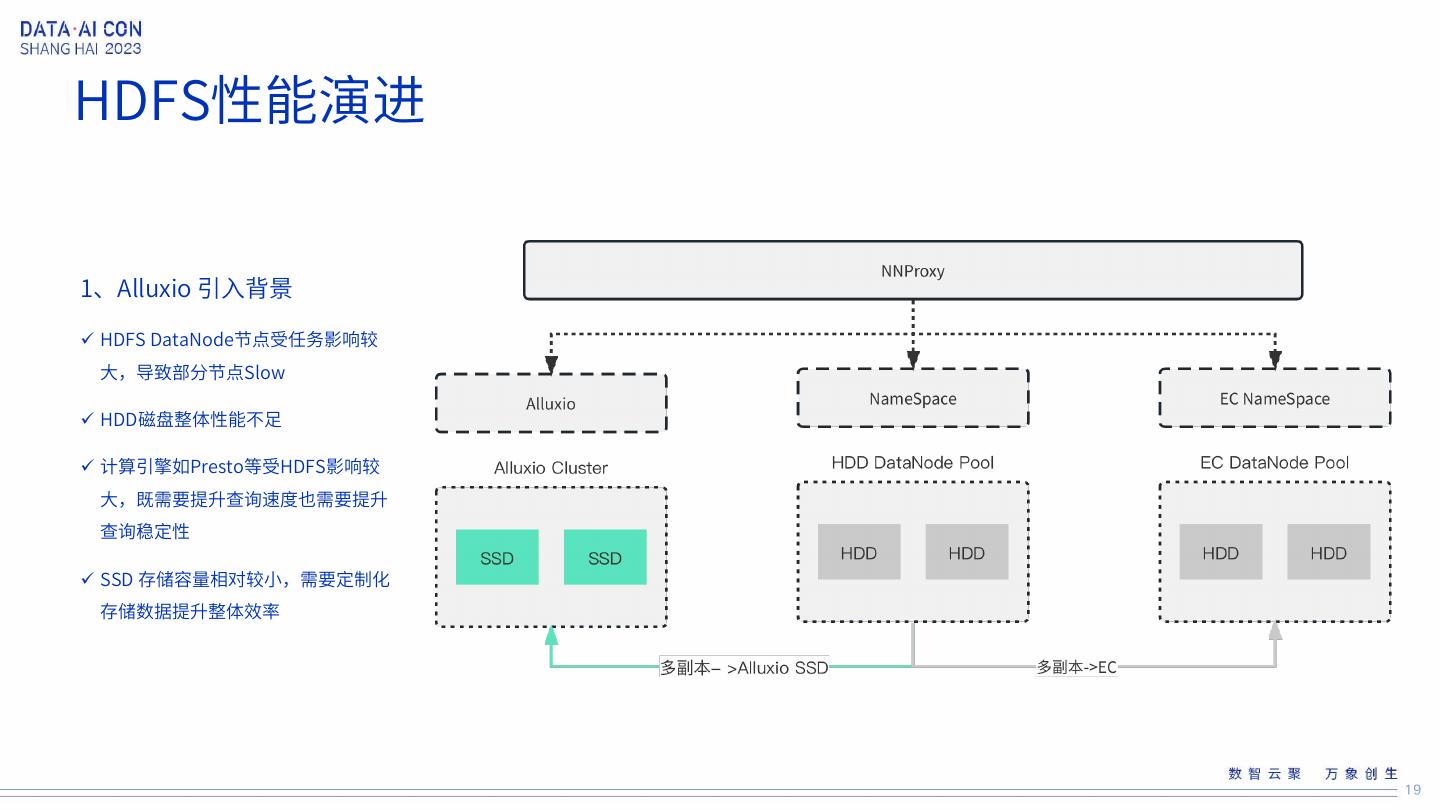
19 .HDFS性能演进 1、Alluxio 引入背景 HDFS DataNode节点受任务影响较 大,导致部分节点Slow HDD磁盘整体性能不足 计算引擎如Presto等受HDFS影响较 大,既需要提升查询速度也需要提升 查询稳定性 SSD 存储容量相对较小,需要定制化 存储数据提升整体效率 19
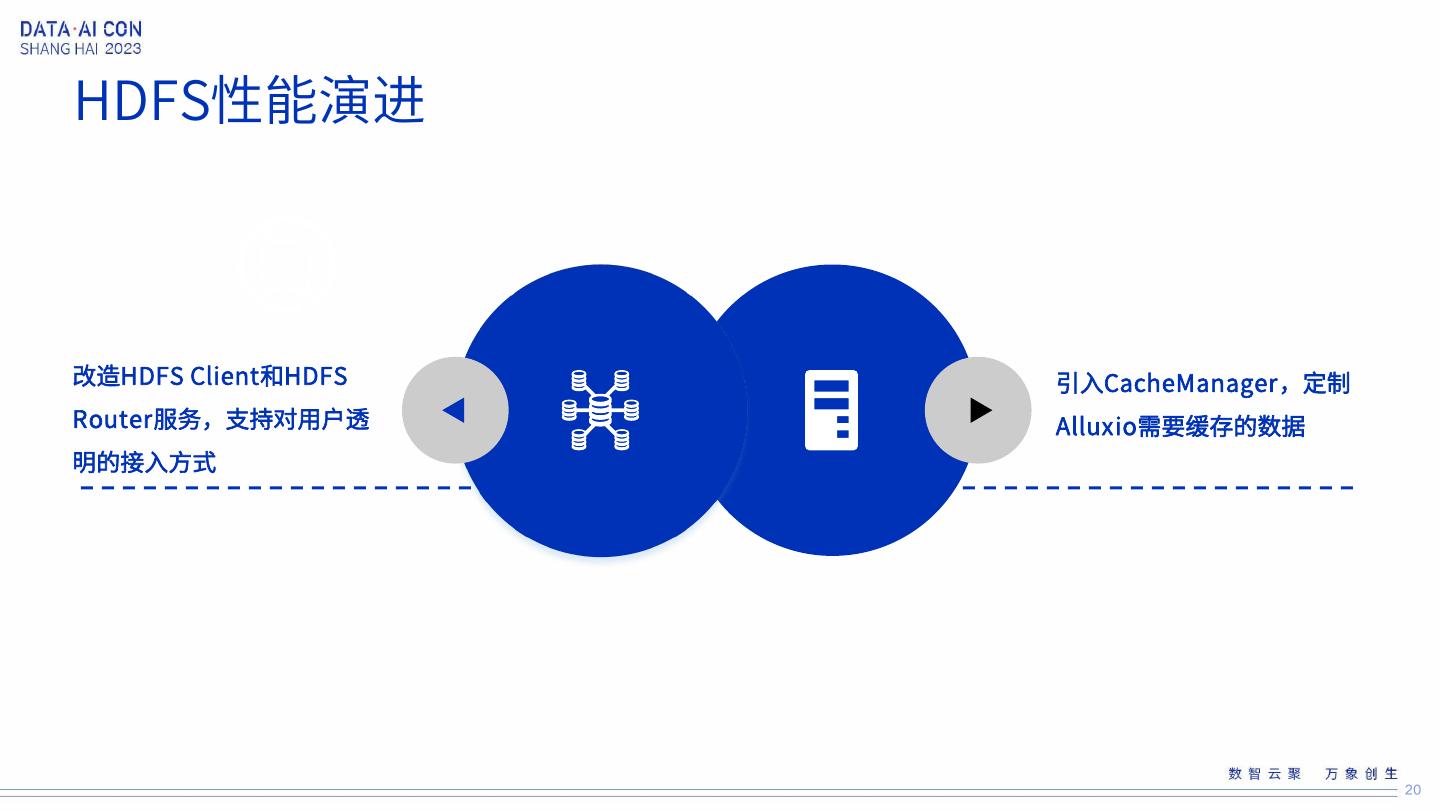
20 .HDFS性能演进 改造HDFS Client和HDFS 引入CacheManager,定制 Router服务,支持对用户透 Alluxio需要缓存的数据 明的接入方式 20
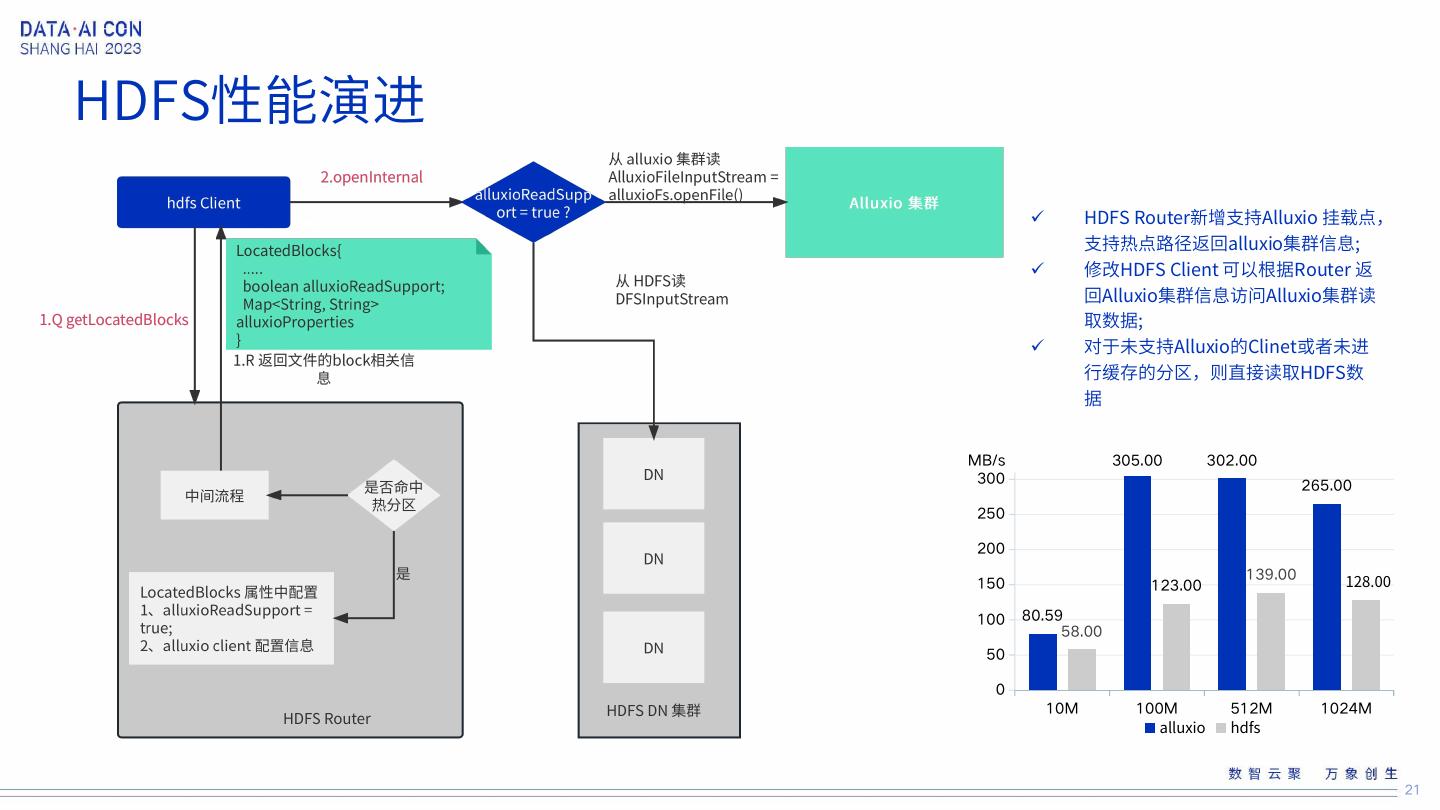
21 .HDFS性能演进 HDFS Router新增支持Alluxio 挂载点, 支持热点路径返回alluxio集群信息; 修改HDFS Client 可以根据Router 返 回Alluxio集群信息访问Alluxio集群读 取数据; 对于未支持Alluxio的Clinet或者未进 行缓存的分区,则直接读取HDFS数 据 MB/s 305.00 302.00 300 265.00 250 200 128.00 139.00 150 123.00 100 80.59 58.00 50 0 10M 100M 512M 1024M alluxio hdfs 21
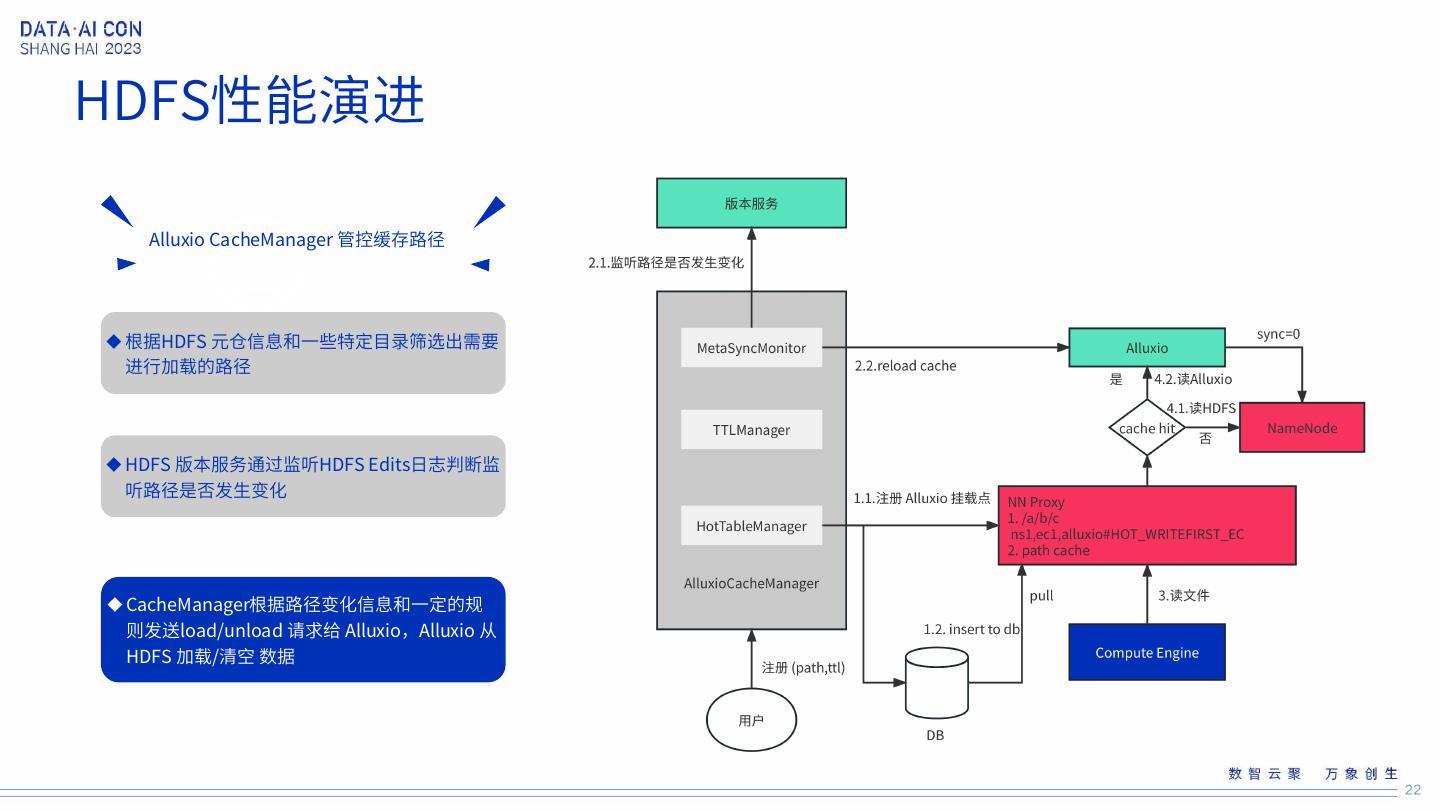
22 .HDFS性能演进 Alluxio CacheManager 管控缓存路径 根据HDFS 元仓信息和一些特定目录筛选出需要 进行加载的路径 HDFS 版本服务通过监听HDFS Edits日志判断监 听路径是否发生变化 CacheManager根据路径变化信息和一定的规 则发送load/unload 请求给 Alluxio,Alluxio 从 HDFS 加载/清空 数据 22
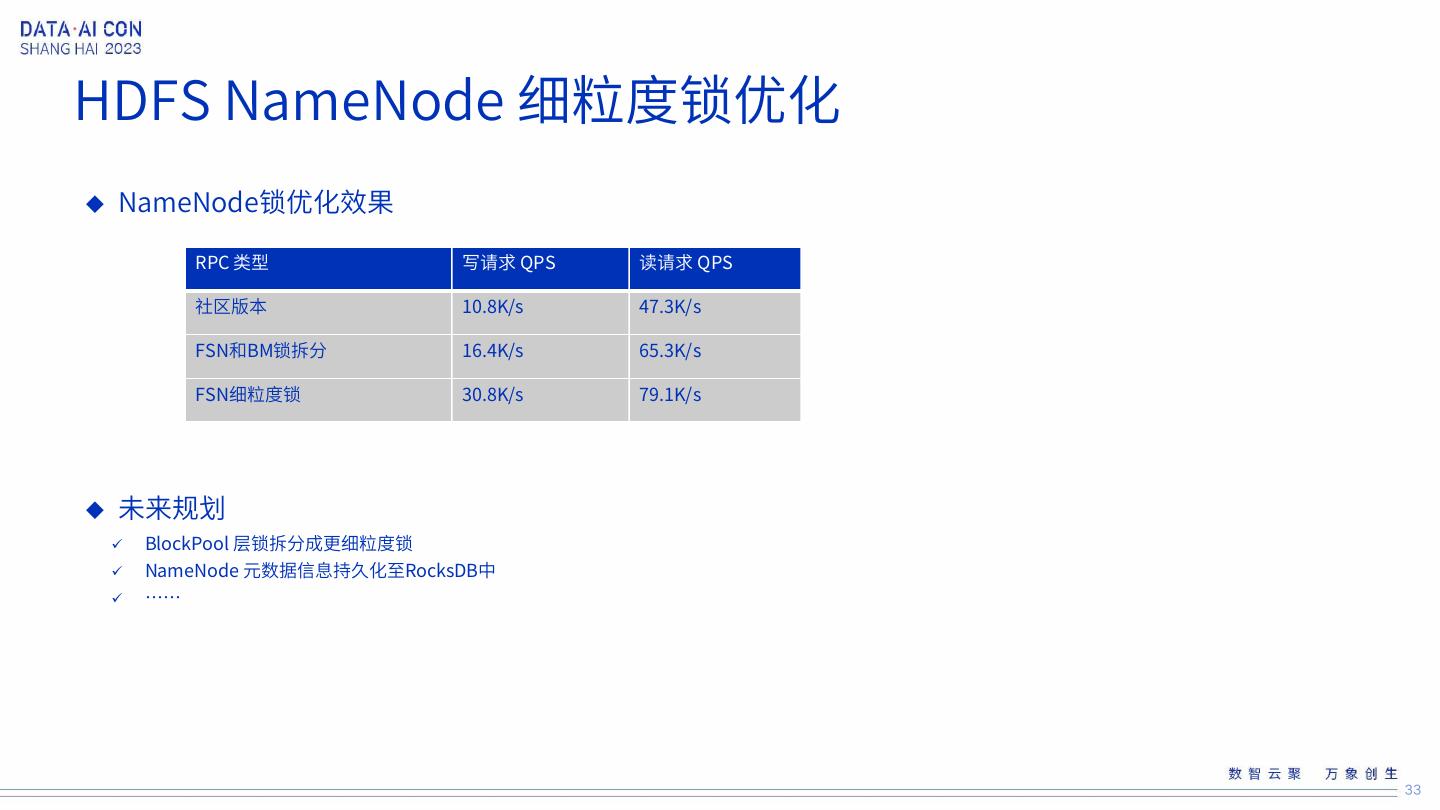
23 .HDFS性能演进 1 HDFS NameNode FSN层和BM层锁拆分 HDFS NameNode 细粒度锁优化 3 HDFS NameNode FSN层细粒度锁拆分 23
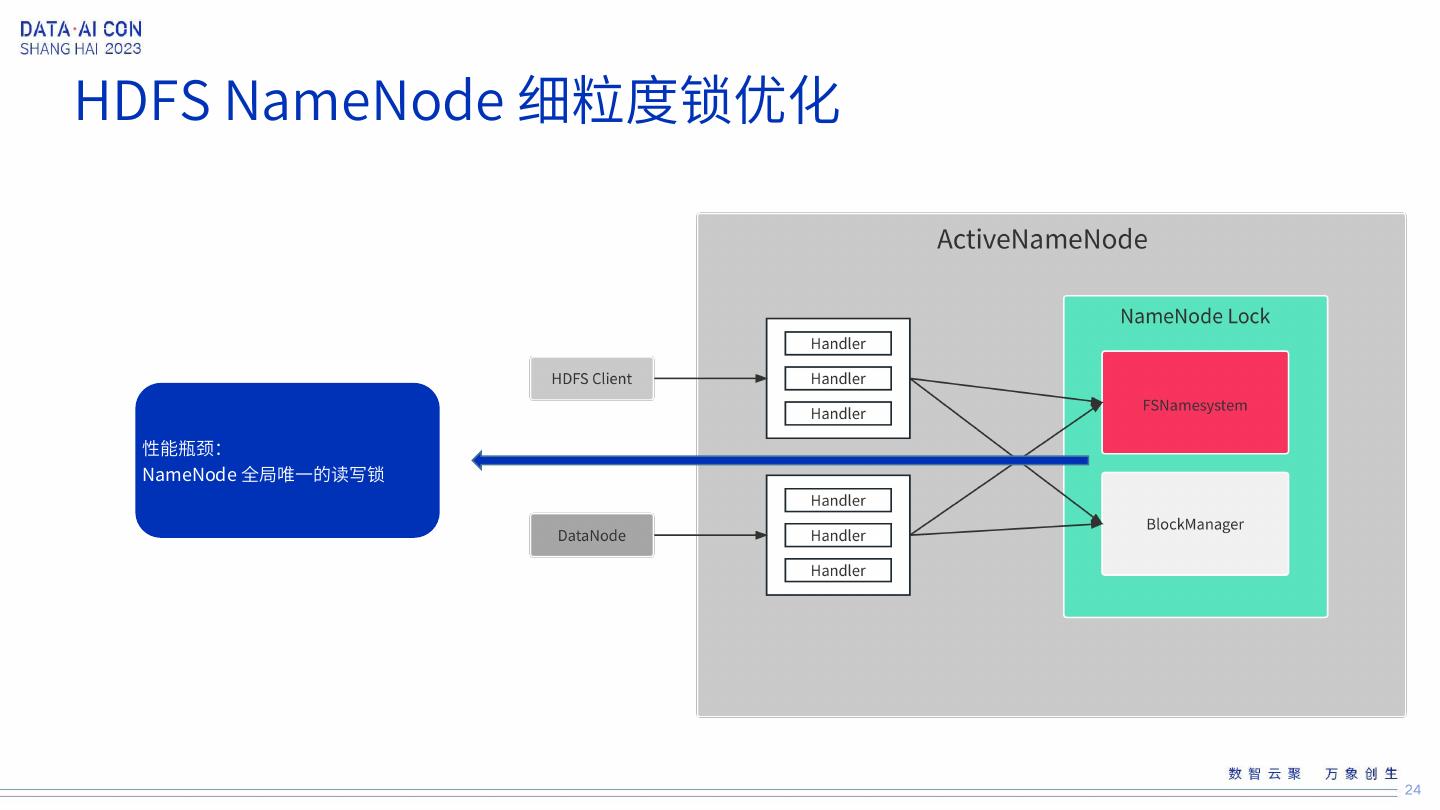
24 .HDFS NameNode 细粒度锁优化 性能瓶颈: NameNode 全局唯一的读写锁 24
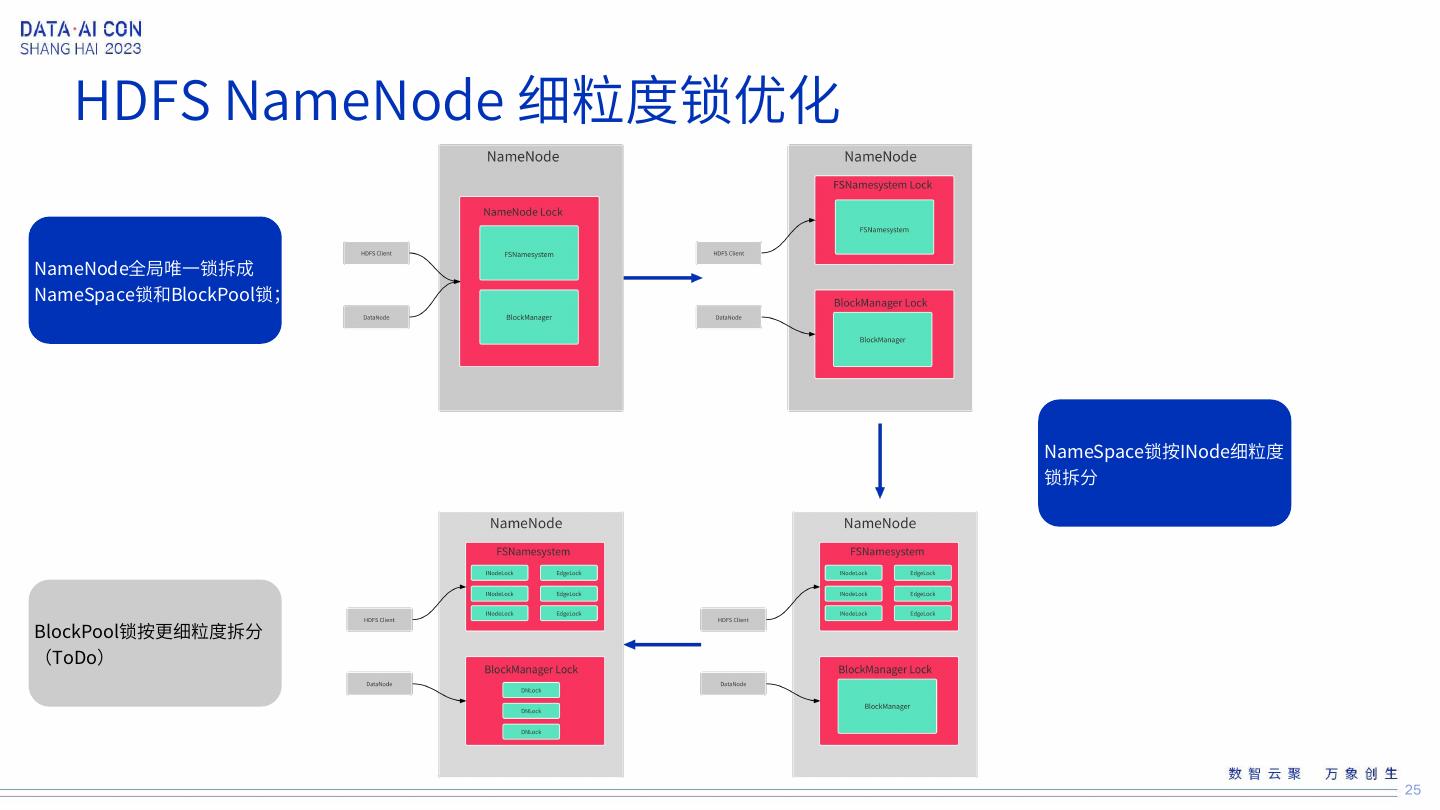
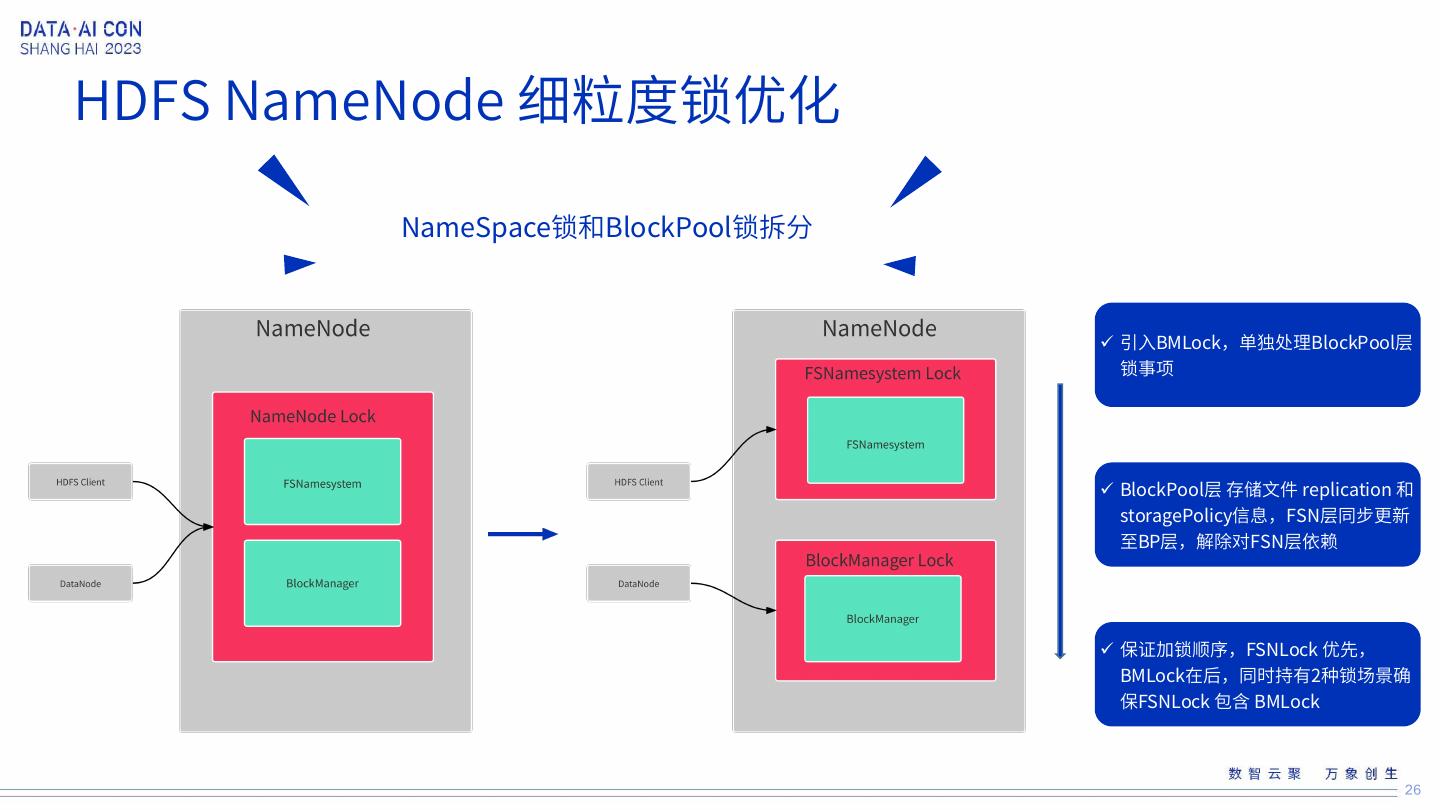
25 . HDFS NameNode 细粒度锁优化 NameNode全局唯一锁拆成 NameSpace锁和BlockPool锁; NameSpace锁按INode细粒度 锁拆分 BlockPool锁按更细粒度拆分 (ToDo) 25
26 .HDFS NameNode 细粒度锁优化 NameSpace锁和BlockPool锁拆分 引入BMLock,单独处理BlockPool层 锁事项 BlockPool层 存储文件 replication 和 storagePolicy信息,FSN层同步更新 至BP层,解除对FSN层依赖 保证加锁顺序,FSNLock 优先, BMLock在后,同时持有2种锁场景确 保FSNLock 包含 BMLock 26
27 .HDFS NameNode 细粒度锁优化 NameSpace锁和BlockPool锁拆分 单独访问FSN层或者BM层的请求并发执行 访问FSN层+BM层的的请求,确保FSNLock包含BMLock 保证加锁顺序,FSNLock 优先,BMLock在后 27
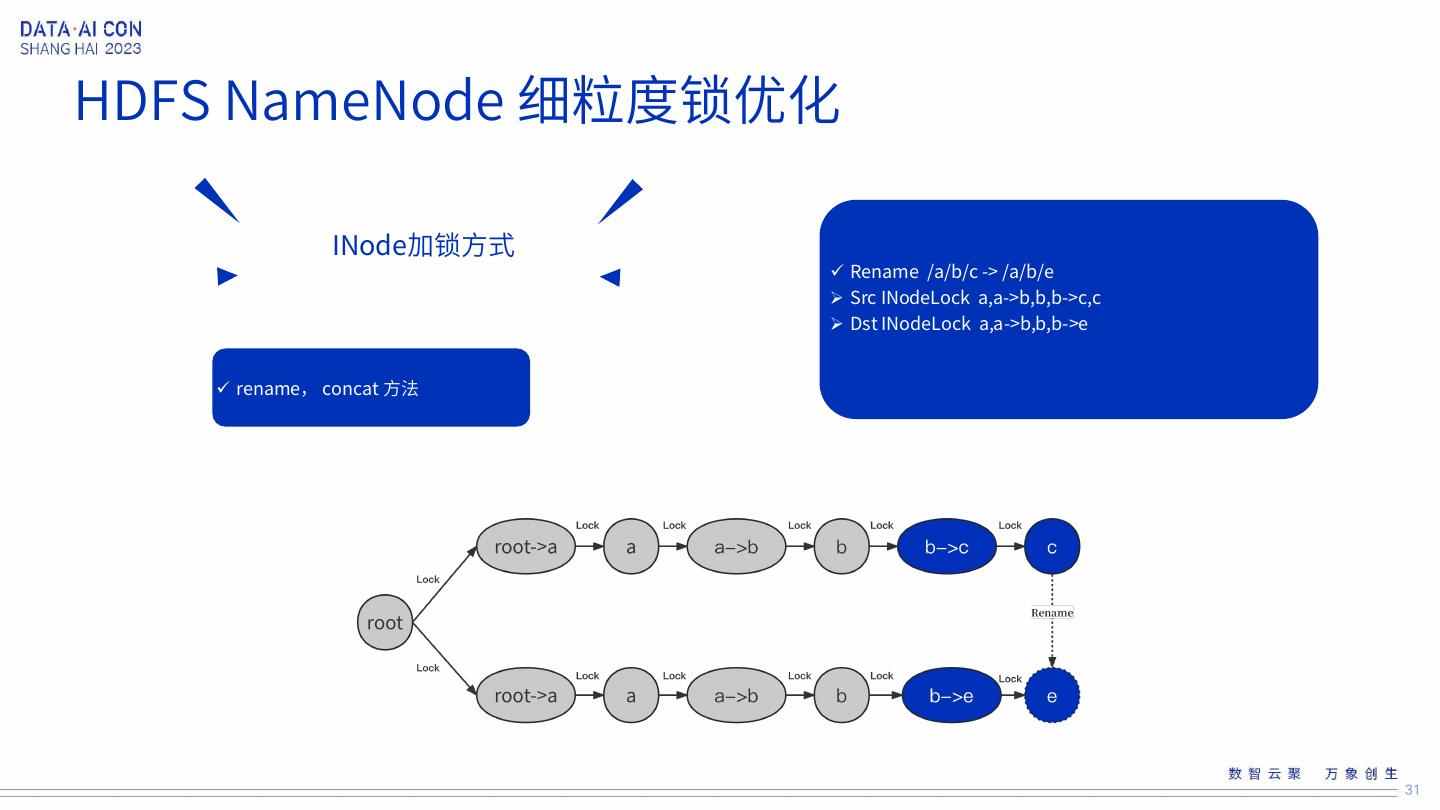
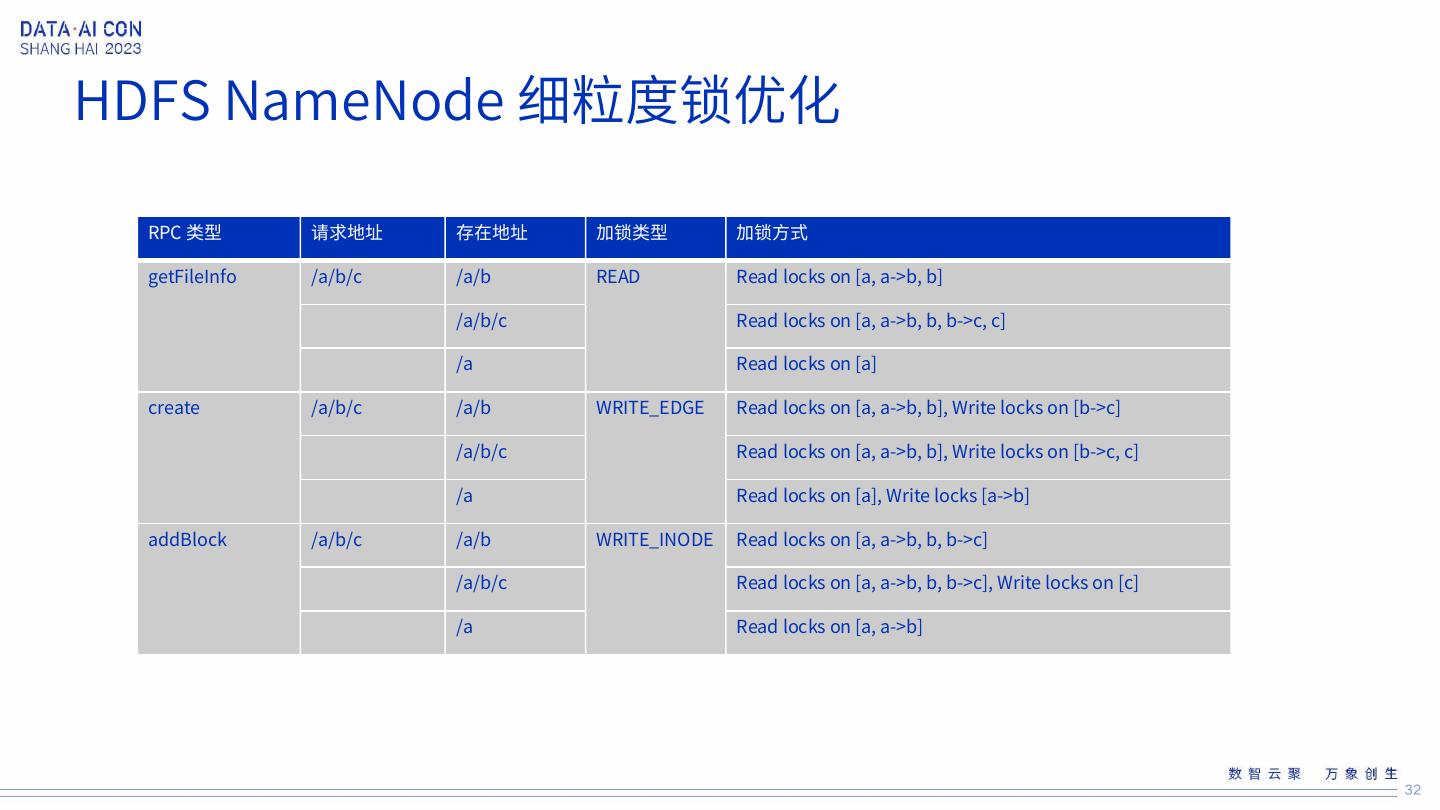
28 .HDFS NameNode 细粒度锁优化 28
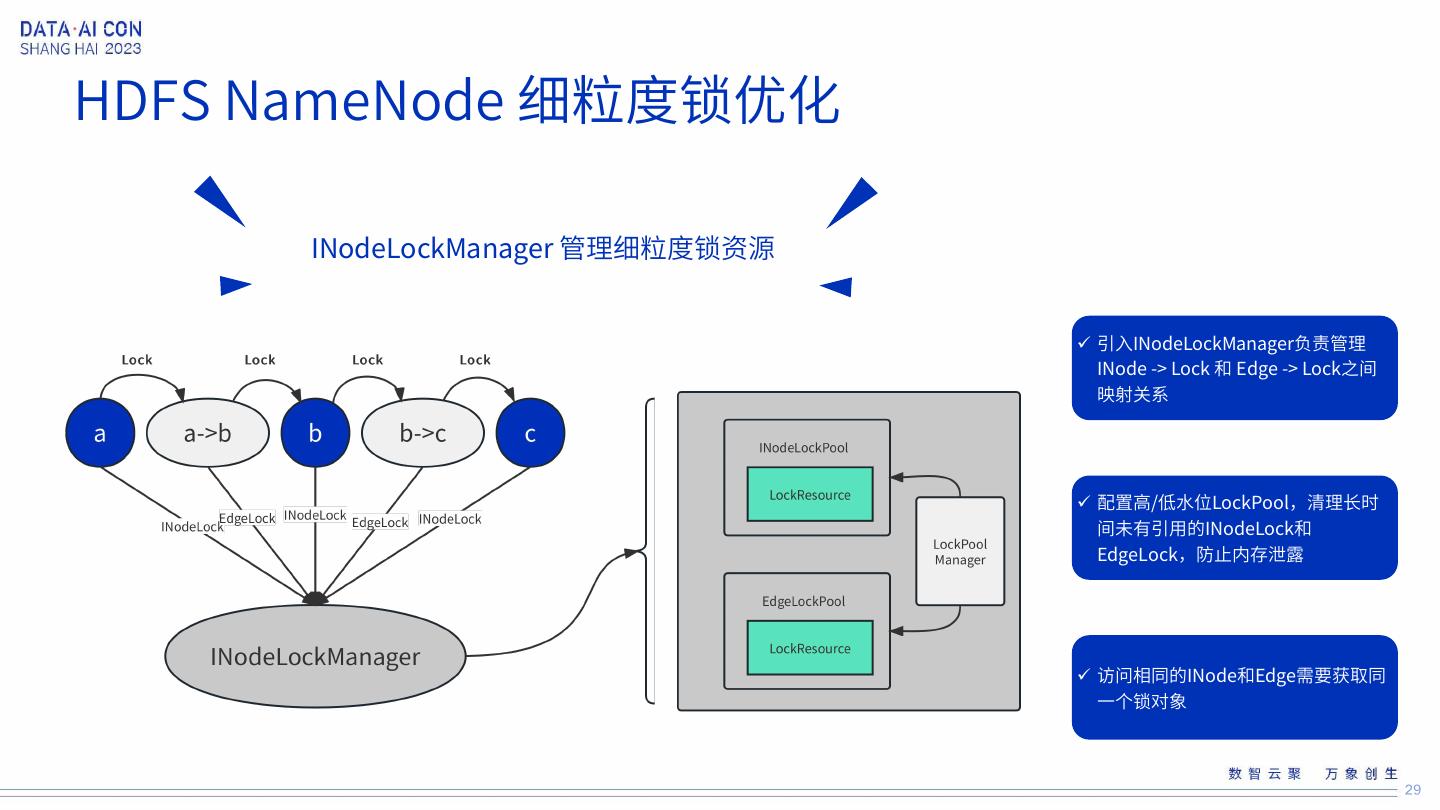
29 .HDFS NameNode 细粒度锁优化 INodeLockManager 管理细粒度锁资源 引入INodeLockManager负责管理 INode -> Lock 和 Edge -> Lock之间 映射关系 配置高/低水位LockPool,清理长时 间未有引用的INodeLock和 EdgeLock,防止内存泄露 访问相同的INode和Edge需要获取同 一个锁对象 29
3秒后跳转登录页面
去登陆

