

































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 视频嵌入链接 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
6.田原-工业物联网时序数据库Apache IoTDB
田原,Apache IoTDB PMC。硕士毕业于清华大学软件学院,Apache IoTDB PMC,2019年起参与IoTDB社区,Github累计贡献度排名第三,目前致力于Apache IoTDB MPP查询计算引擎的开发。
介绍时序数据库与其他数据库的区别,IoTDB的整体框架设计,底层开放的对时序数据优化的文件格式TsFIle,与其它开源生态组件的集成。
展开查看详情
1 .工业物联网时序数据库 Apache IoTDB 田原 Apace IoTDB PMC Member
2 .项目发展
3 .Apache IoTDB 产品介绍
4 .产品架构 数据库引擎 分析引擎 IoTDB-CLI Grafana-连接器 I/E Tool 命令行交互工具 可视化平台 数据导入导出工具 Session IoTDB-Server Flink 异常检测 原生读写接口 数据库管理引擎 连接器 Flink/ Spark 数据库文件层 TsFile TsFile TsFile Spark/ 机器学习 连接器 Hive 开源数据 TsFile-load/remove 处理平台 TsFile 加载、卸载 TsFile-API TsFile Hive 提供对TsFile的读写操作 时间序列文件格式 数据分析 连接器 时序文件
5 .部署形态 单机部署 边云协同部署 双活部署 分布式部署 IoTDB IoTDB IoTDB IoTDB IoTDB IoTDB IoTDB IoTDB IoTDB 一键安装 低网络流量 低成本 数据分区 数据安全 高稳定 实时同步 高可靠 动态扩缩容 高可用 高性能 批量同步 实时同步 并行计算 高性能
6 .时序数据库 是什么定义了不同类型的数据库? 磁盘存储格式?读写性能?架构?
7 .时序数据库 关系模型 -> 关系数据库 key value 键值模型 ->键值数据库 图模型 -> 图数据库 时序模型 -> 时序数据库 T V T V T V T V 数据模型:如何看待数据,如何操作数据
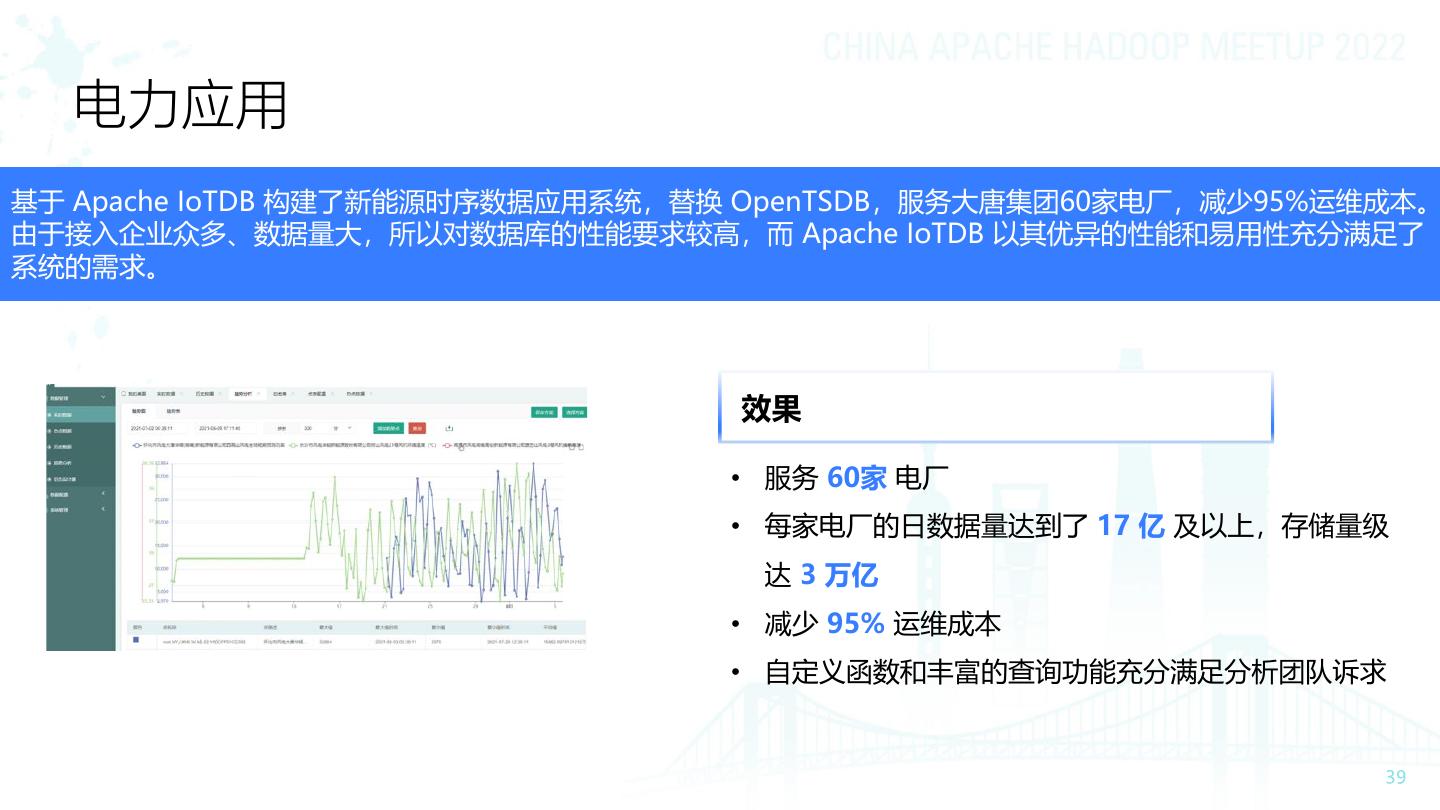
8 .应用场景 ➢ 集团公司 ➢ 风场 ➢ 风力发电 ➢ 功率 ➢ 电压值 ➢ 电流值 ➢ 风速 ➢ 角速度
9 .应用场景 ➢ 汽车品牌 ➢ 产地 ➢ 批次 ➢ 车辆id ➢ 车速 ➢ 转数 ➢ 胎压 ➢ 经度 ➢ 纬度
10 .应用场景 ➢ 国家 ➢ 省份 ➢ 城市 ➢ 桥梁名称 ➢ 支座位移 ➢ 动态应变 ➢ 静态应变 ➢ 挠度 ➢ 振动
11 .时序数据模型 ➢ 测点 / 物理量 / 工况 / 字段 / 变量 ➢ 如:功率、电压值、电流、支座位移、风速、车速、经度、纬度 ➢ 实体 / 设备:拥有多个物理量的设备或装置 ➢ 设备+物理量=时间序列/时间线 物理量 时间 风速传感器 (实体/设备)
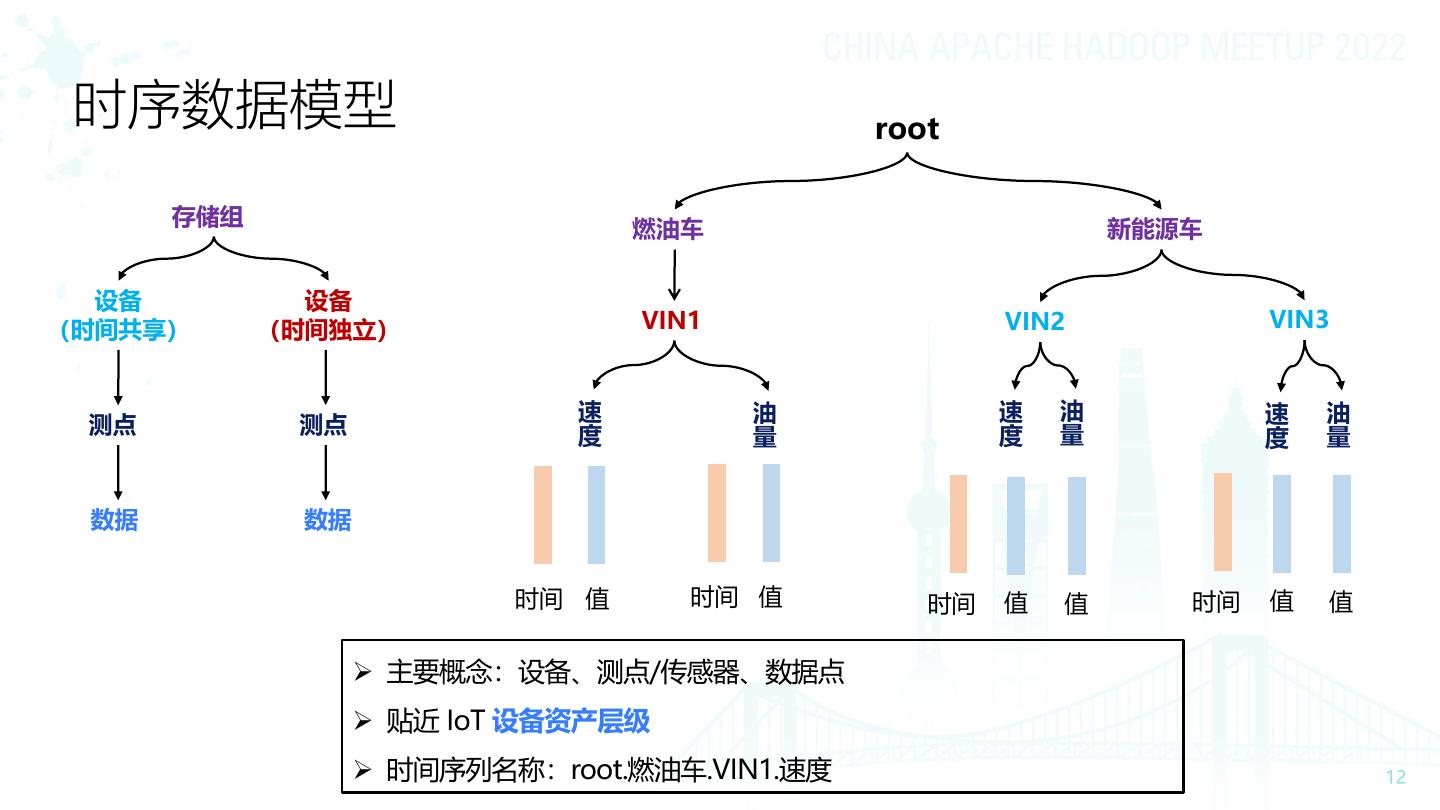
12 . 时序数据模型 root 存储组 燃油车 新能源车 设备 设备 (时间共享) (时间独立) VIN1 VIN2 VIN3 速 油 速 油 速 油 测点 测点 度 度 量 量 量 度 数据 数据 时间 值 时间 值 时间 值 值 时间 值 值 ➢ 主要概念:设备、测点/传感器、数据点 ➢ 贴近 IoT 设备资产层级 ➢ 时间序列名称:root.燃油车.VIN1.速度
13 .时序数据模型:海量时间线管理 大型发电机组可达 数万 时间序列 关系型数据库 Apache IoTDB 无法进行便捷存储,达到存储上限。如 容纳的时间序列数量无上限,满足拥有超 MySQL InnoDB 为1017列,至多存储 多测点的高端装备的管理需求。 1017时间序列,无法满足要求。 垂直分表方案造成额外工作量且性能低。
14 .时序数据模型:支持边缘设备迭代更新 边缘设备快速迭代升级与加速联网,会带来相关变化 • 新增测点:如加装传感器 • 格式变化:如协议升级 • 全新模式:如接入新型号设备 关系型数据库 Apache IoTDB:云端适配边缘侧 手动创建、更改,大额工作量。 数据模式从后台定义到边缘设备定义,自动化创建 树形元数据。节省大量工作量,低成本应对工业场 景多设备的复杂数据资产管理。
15 . 模型转化 标签模型 IoTDB 模型:tag值为路径 Tag 物理量 Tag Tag Tag Field Field 时间 温度 车间 产线 单元 温度 产量 A1 B1 C1 产量 1 A1 B1 C1 16.9 142 root 温度 1 A1 B1 C1 16.5 108 B2 C2 产量 A2 2 A2 B2 C2 13.0 130 温度 B3 C3 3 A2 B3 C3 13.5 80 产量 select 温度, 产量 from table where 车间=A1 select 温度, 产量 from root.A1.*.* select 温度, 产量 from table where 车间=A1 and 单元=C1 select 温度, 产量 from root.A1.*.C1
16 .存储引擎 tLSM 最大刷盘时间 新写入 乱序空间 顺序空间 内存 磁盘 L0 WAL L2 跨空间合并 直达最高层
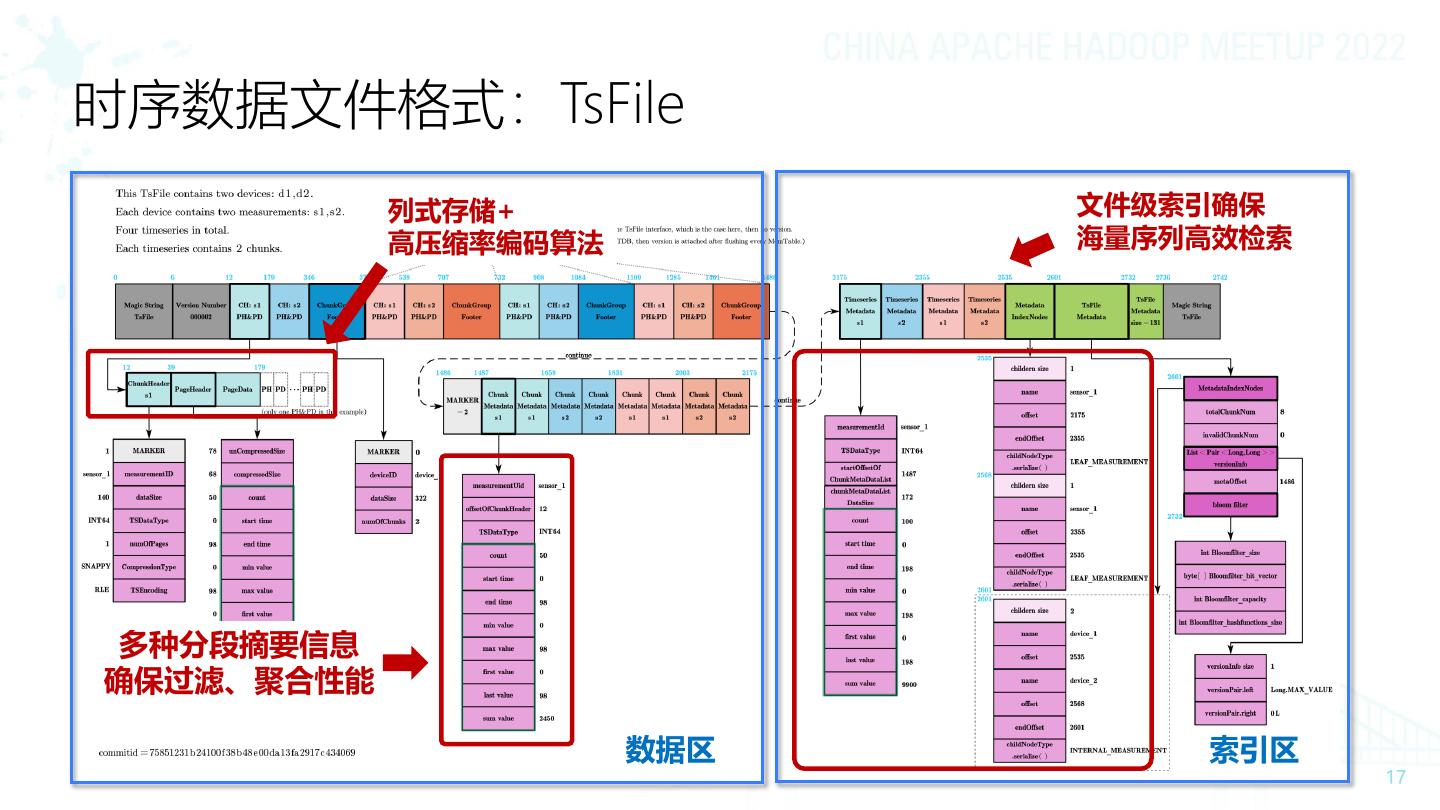
17 .时序数据文件格式:TsFile 列式存储+ 文件级索引确保 高压缩率编码算法 海量序列高效检索 多种分段摘要信息 确保过滤、聚合性能 数据区 索引区
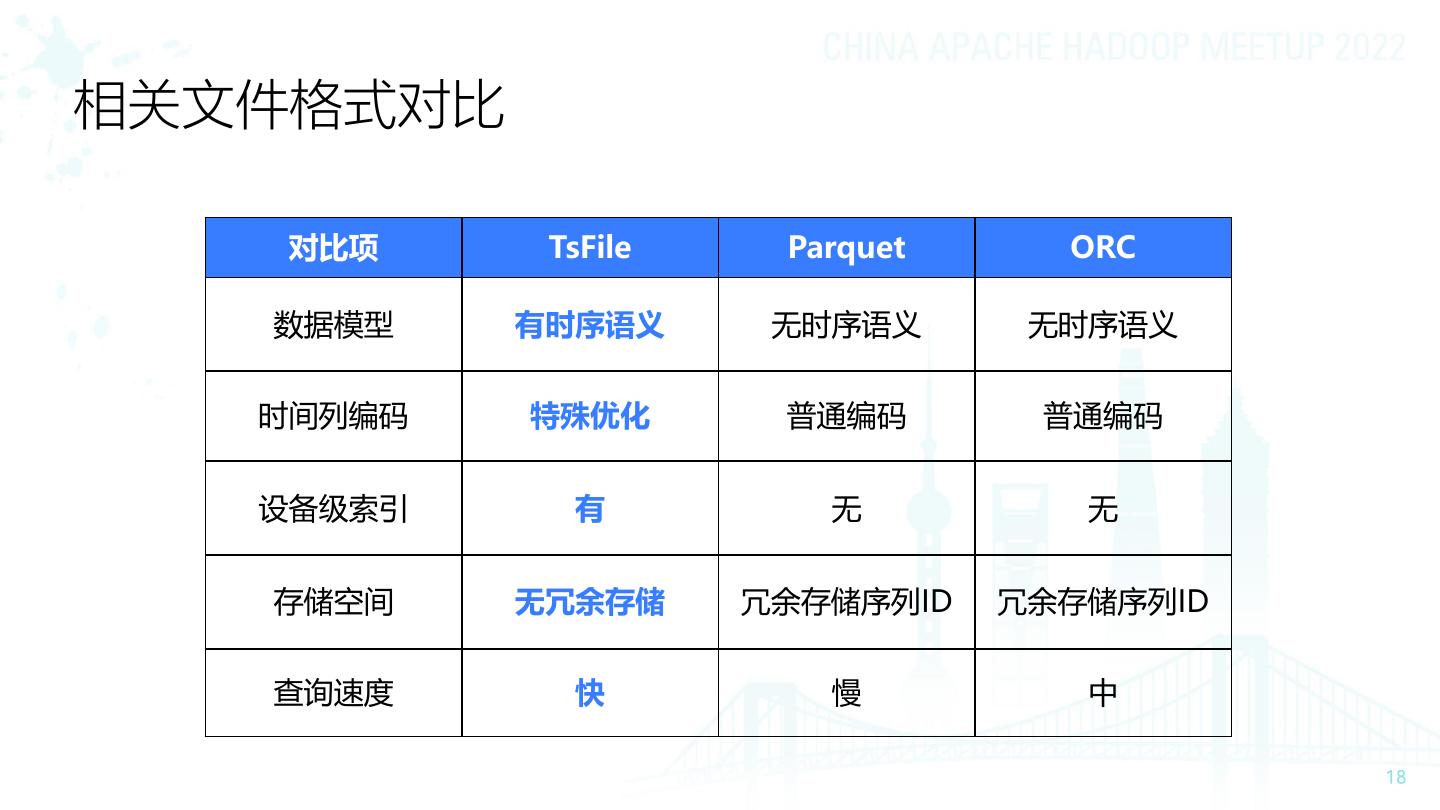
18 .相关文件格式对比 对比项 TsFile Parquet ORC 数据模型 有时序语义 无时序语义 无时序语义 时间列编码 特殊优化 普通编码 普通编码 设备级索引 有 无 无 存储空间 无冗余存储 冗余存储序列ID 冗余存储序列ID 查询速度 快 慢 中
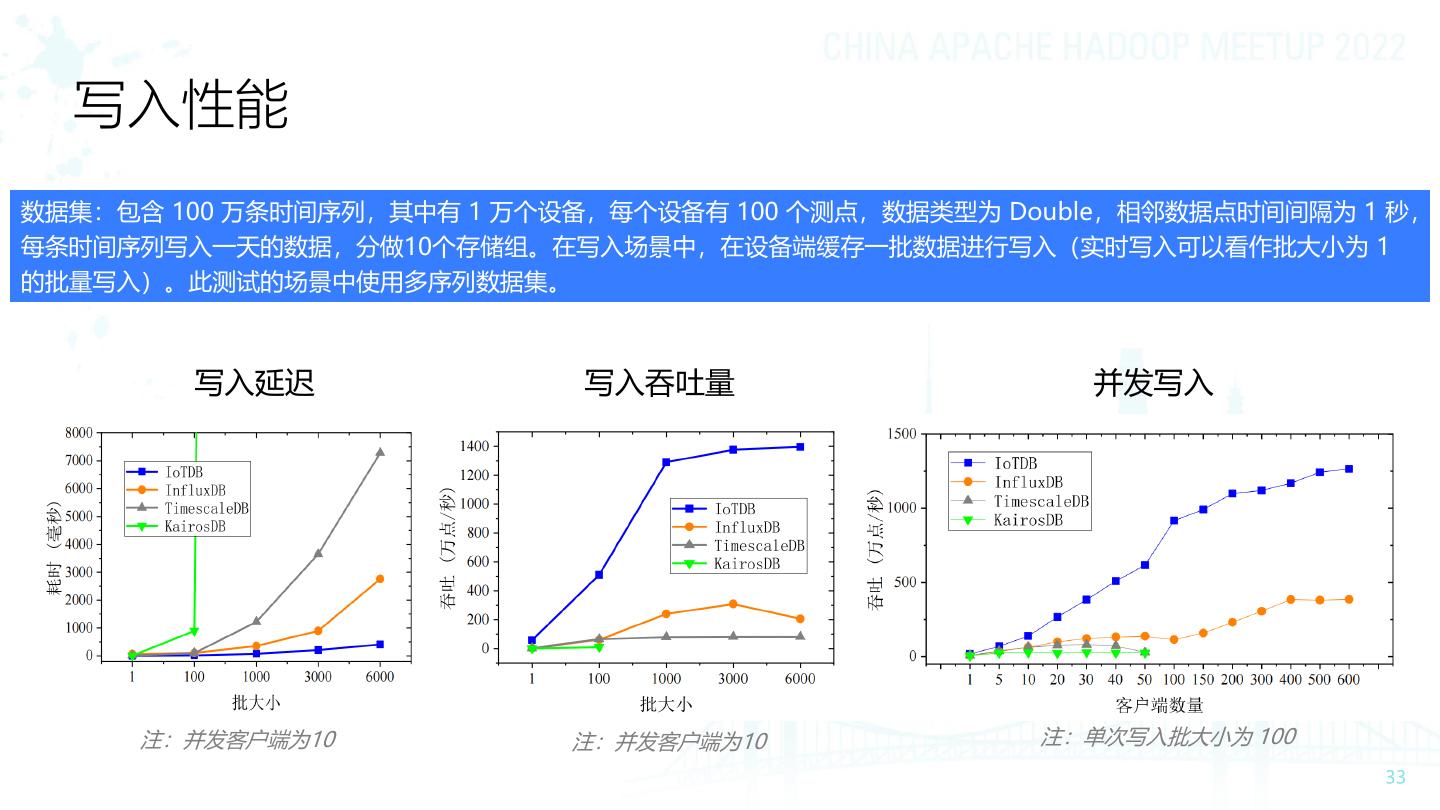
19 .数据写入:支持超高采样频率 核电监控数据采集频率可达 25000Hz 关系型数据库 Apache IoTDB 易达到1000万行的单表存储上限。 容纳PB级别数据。且数据写入、数据查询 水平分表分库等方案造成额外工作量且 速率不随数据量增长而下降,维持稳定高 运维复杂。 速水平。
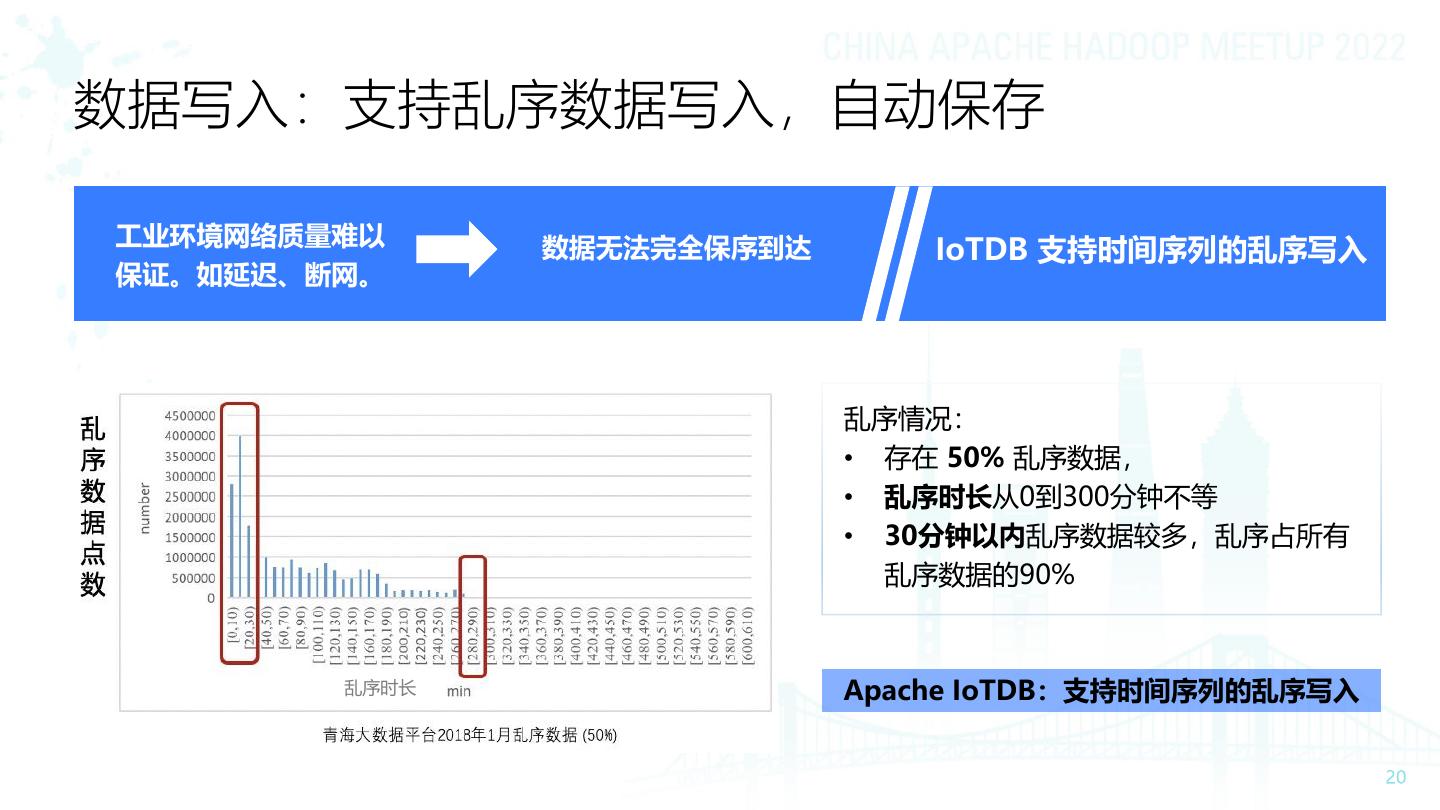
20 .数据写入:支持乱序数据写入,自动保存 工业环境网络质量难以 数据无法完全保序到达 IoTDB 支持时间序列的乱序写入 保证。如延迟、断网。 乱序情况: • 存在 50% 乱序数据, • 乱序时长从0到300分钟不等 • 30分钟以内乱序数据较多,乱序占所有 乱序数据的90% 乱序时长 Apache IoTDB:支持时间序列的乱序写入
21 .数据删除 方式一:手动删除 ➢ 删除任意时间范围的数据 ➢ 同步打标记,后台异步清理释放空间 方式二:自动过期清理(TTL) ➢ 可设置数据的保留时间,过期数据定时清理 ➢ 带来的优势 ➢ 无需手动清理,减少运维成本 ➢ 控制 IoTDB 占用的总磁盘空间,以避免出现磁盘写满等异常
22 .查询功能丰富 ➢ 降采样成每分钟1个数据点 SELECT ✓ 按设备对齐 last_value(left_temp) ➢ LAST_VALUE ✓ 按时间对齐 FROM 更 ➢ 多序列按时间进行数据对齐 多 ✓ 逐测点浏览 root.device1 查 ✓ 过滤空值 ➢ JOIN GROUP BY 询 ✓ 按设备聚合 ( [ now() – 10h, now()),1m) ➢ 修补缺失的数据 ✓ 按时间聚合 FILL ➢ FILL (ALL[PREVIOUS, 5m]) ✓ … 速度 实线为处理前不规整的时间序列 虚线为处理后规整的时间序列 时间
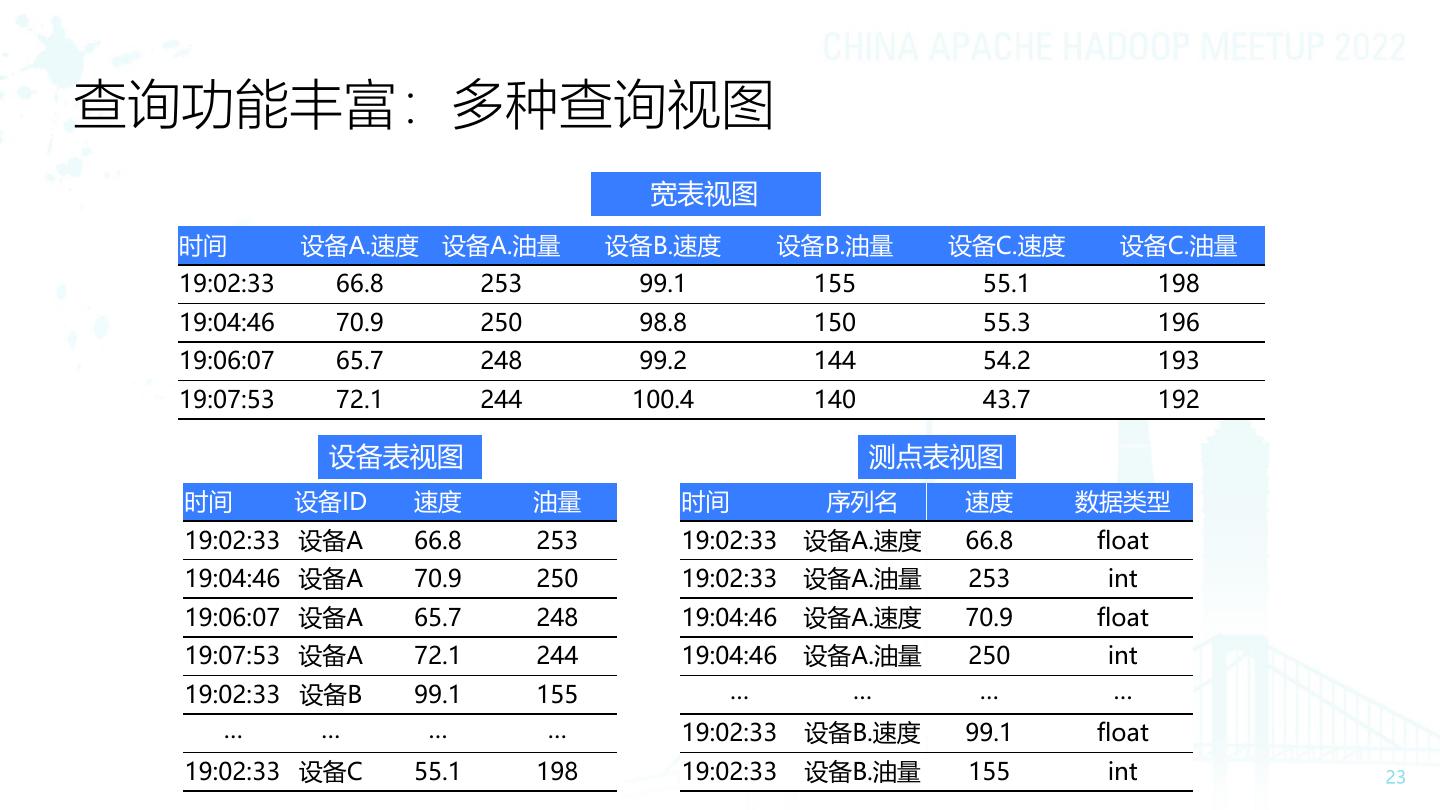
23 .查询功能丰富:多种查询视图 宽表视图 时间 设备A.速度 设备A.油量 设备B.速度 设备B.油量 设备C.速度 设备C.油量 19:02:33 66.8 253 99.1 155 55.1 198 19:04:46 70.9 250 98.8 150 55.3 196 19:06:07 65.7 248 99.2 144 54.2 193 19:07:53 72.1 244 100.4 140 43.7 192 设备表视图 测点表视图 时间 设备ID 速度 油量 时间 序列名 速度 数据类型 19:02:33 设备A 66.8 253 19:02:33 设备A.速度 66.8 float 19:04:46 设备A 70.9 250 19:02:33 设备A.油量 253 int 19:06:07 设备A 65.7 248 19:04:46 设备A.速度 70.9 float 19:07:53 设备A 72.1 244 19:04:46 设备A.油量 250 int 19:02:33 设备B 99.1 155 … … … … … … … … 19:02:33 设备B.速度 99.1 float 19:02:33 设备C 55.1 198 19:02:33 设备B.油量 155 int
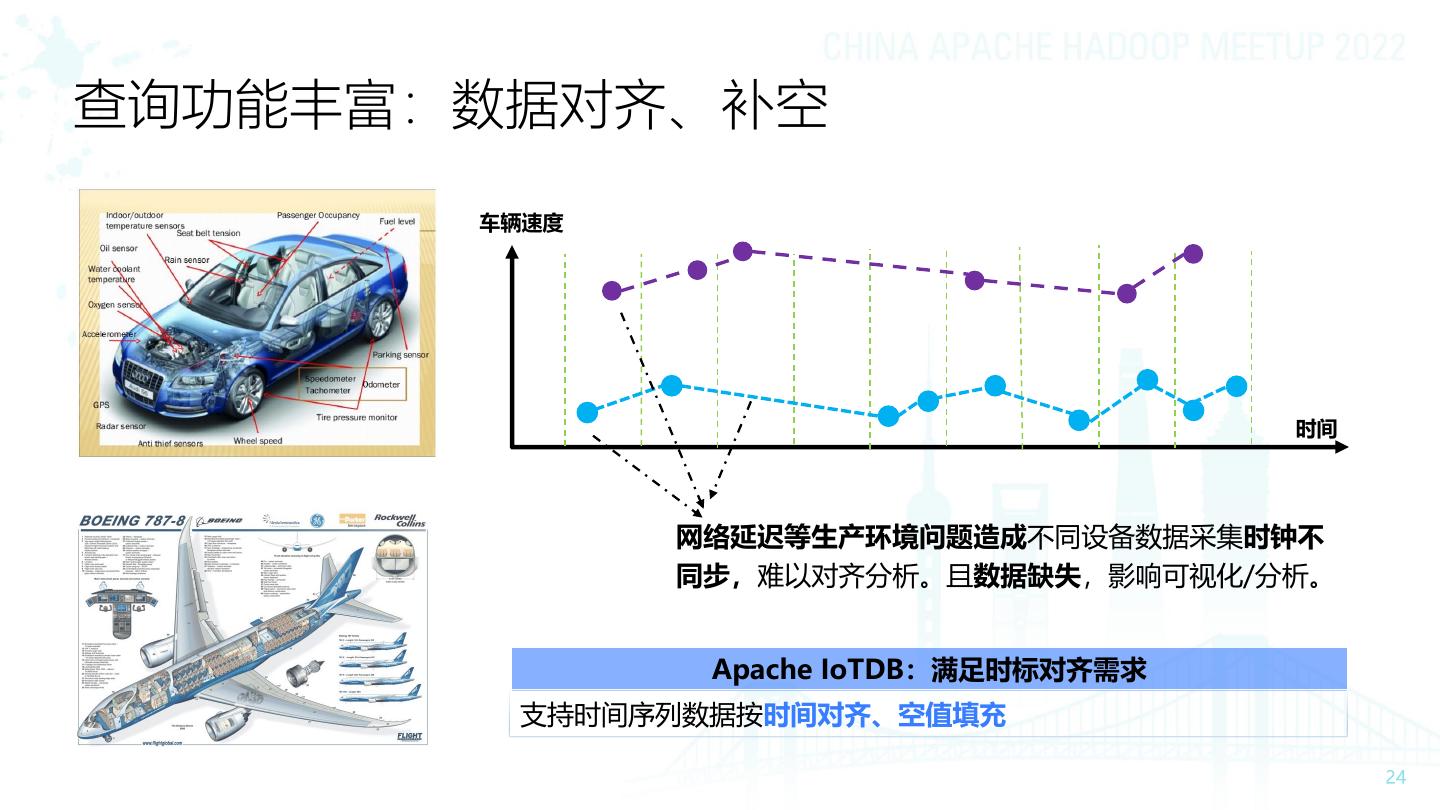
24 .查询功能丰富:数据对齐、补空 车辆速度 时间 网络延迟等生产环境问题造成不同设备数据采集时钟不 同步,难以对齐分析。且数据缺失,影响可视化/分析。 Apache IoTDB:满足时标对齐需求 支持时间序列数据按时间对齐、空值填充
25 .高级数据处理:UDF ➢用户可通过自行开发、创建自定义函数来满足定制化的计算需求 ➢同时,目前已内置 11 类 UDF 库,共 75个 函数 函数类型 函数名称 ACF, Distinct, Histogram, Integral, IntegralAvg, Mad, Median, MinMax, Mode, MvAvg, PACF, 数据画像(22) Percentile, Period, QLB, Resample, Sample, Segment, Skew, Spline, Spread, Stddev, ZScore 数据质量(4) Completeness, Consistency, Timeliness, Validity 数据修复(3) ValueFill, TimestampRepair, ValueRepair 数据匹配(10) Cov, Dtw, PtnSym, Pearson, SeriesAlign, SeriesSimilarity, ValueAlign, Xcorr, MAE, RMSE 异常检测(6) IQR, Ksigma, LOF, MissDetect, Range, TwoSidedFilter 频域相关(7) Conv, Deconv, DWT, FFT, HighPass, IFFT, LowPass 序列发现(2) ConsecutiveSequences, ConsecutiveWindows 字符串处理(4) RegexMatch, RegexReplace, RegexSplit, StrReplace 数据平滑(5) EMA, DEMA, TEMA, TRIX, RSI 数据预测(5) Decompose, STL, AR, SARIMAX, Holt-Winters 复杂事件处理(7) AND, EvenetMatching, EvenetNameRepair, EventTag, EventTimeRepair, MissingEventRecovery, SEQ
26 .自定义触发器:Trigger ➢ 功能说明 ➢ 触发器提供了一种侦听序列数据变动的机制 ➢ 配合用户自定义逻辑,可完成告警、数据清洗、数据转 发等功能 ➢ 带来的优势 ➢ 按照自定义规则,在数据写入时,进行实时计算与判断 ➢ 例1:数据写入时判断速度是否为负值,是负值的话, 数据改为0 ➢ 例2:设置温度超过100摄氏度为异常值阈值,超过100 摄氏度,即进行实时报警
27 .物化视图:select into select avg(设备A.速度, 设备B.速度) into 设备A和设备B速度的平均值 select 查询, 将结果写回数据集, 获得设备A和设备B的速度值,并进行函数计算,获得结果 后续使用无需读原始数据,避免重复计算 设备A和设备B 时间 设备A.速度 设备A.油量 设备B.速度 设备B.油量 速度的平均值 19:02:33 66.8 253 99.1 155 82.95 19:04:46 70.9 250 98.8 150 84.85 19:06:07 65.7 248 99.2 144 82.45 19:07:53 72.1 244 100.4 140 86.25
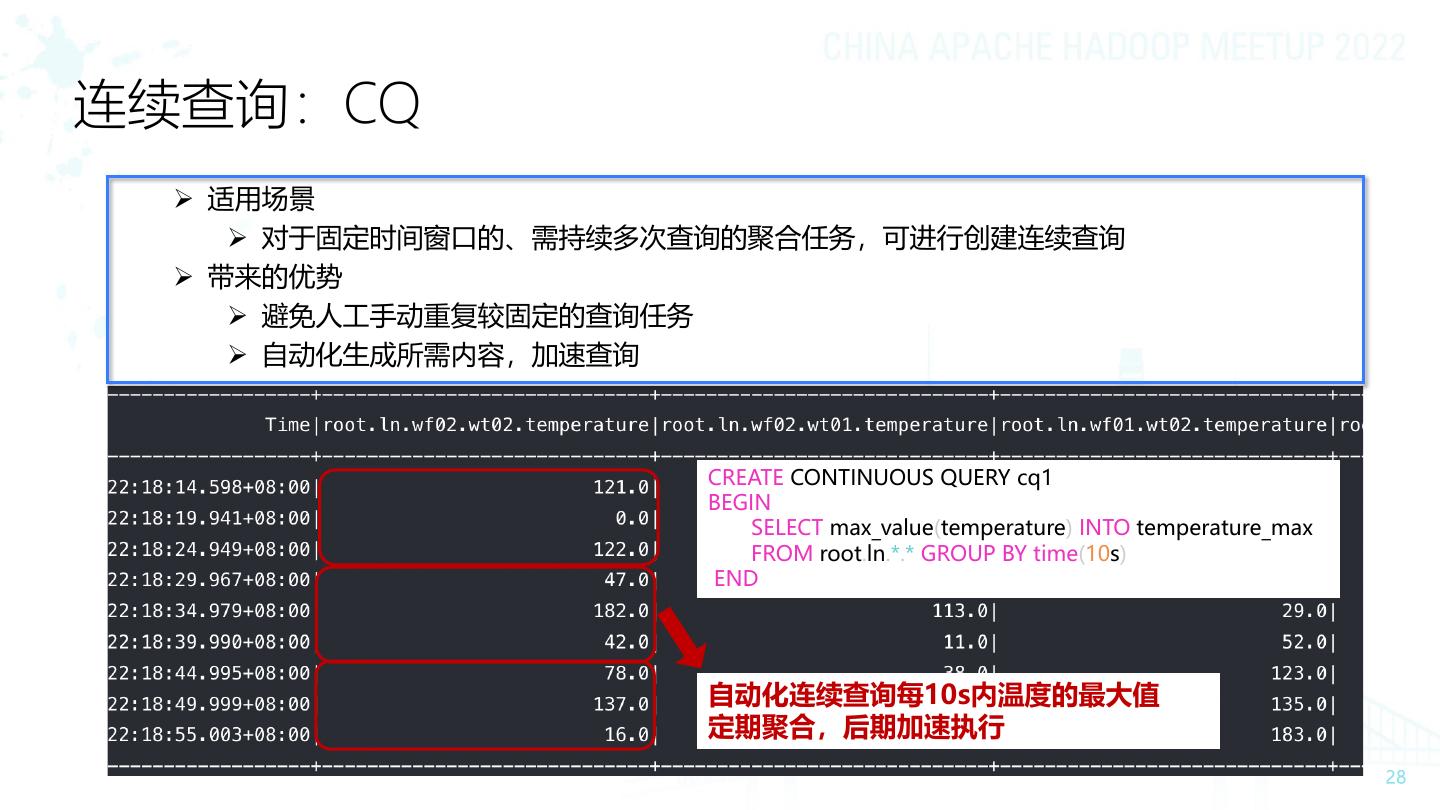
28 .连续查询:CQ ➢ 适用场景 ➢ 对于固定时间窗口的、需持续多次查询的聚合任务,可进行创建连续查询 ➢ 带来的优势 ➢ 避免人工手动重复较固定的查询任务 ➢ 自动化生成所需内容,加速查询 CREATE CONTINUOUS QUERY cq1 BEGIN SELECT max_value(temperature) INTO temperature_max FROM root.ln.*.* GROUP BY time(10s) END 自动化连续查询每10s内温度的最大值 定期聚合,后期加速执行
29 .Apache IoTDB 生态集成
3秒后跳转登录页面
去登陆

