展开查看详情
2 .Automatic Spark Version Upgrade at Scale in eBay
Wang, Fei
Software Engineer @ eBay Hadoop Team
Apache Kyuubi PPMC Member
�
3 .Agenda
• Spark 3 Migration Challenges
• Automatic Spark Upgrade Solution
• Results & Future Plans
• Q&A
�
4 .Part 1 - Spark 3 Migration Challenges
�
5 .Upgrade from Spark 2.3 to Spark 3.1
~20k ETL SQL Jobs
~110 accounts
Spark 2.3 5k+ commits
Spark 3.1
�
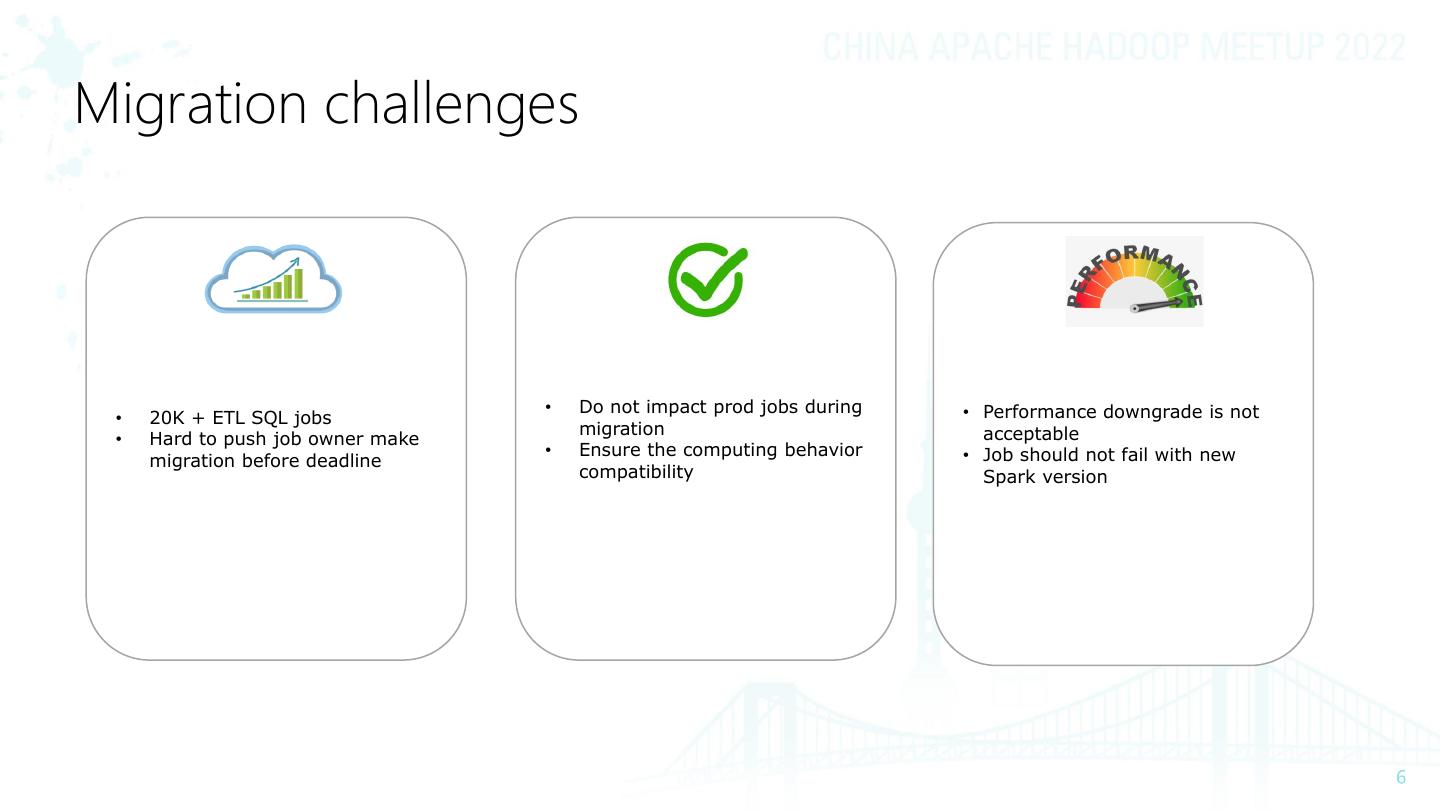
6 .Migration challenges
• Do not impact prod jobs during • Performance downgrade is not
• 20K + ETL SQL jobs
migration acceptable
• Hard to push job owner make
• Ensure the computing behavior • Job should not fail with new
migration before deadline
compatibility Spark version
�
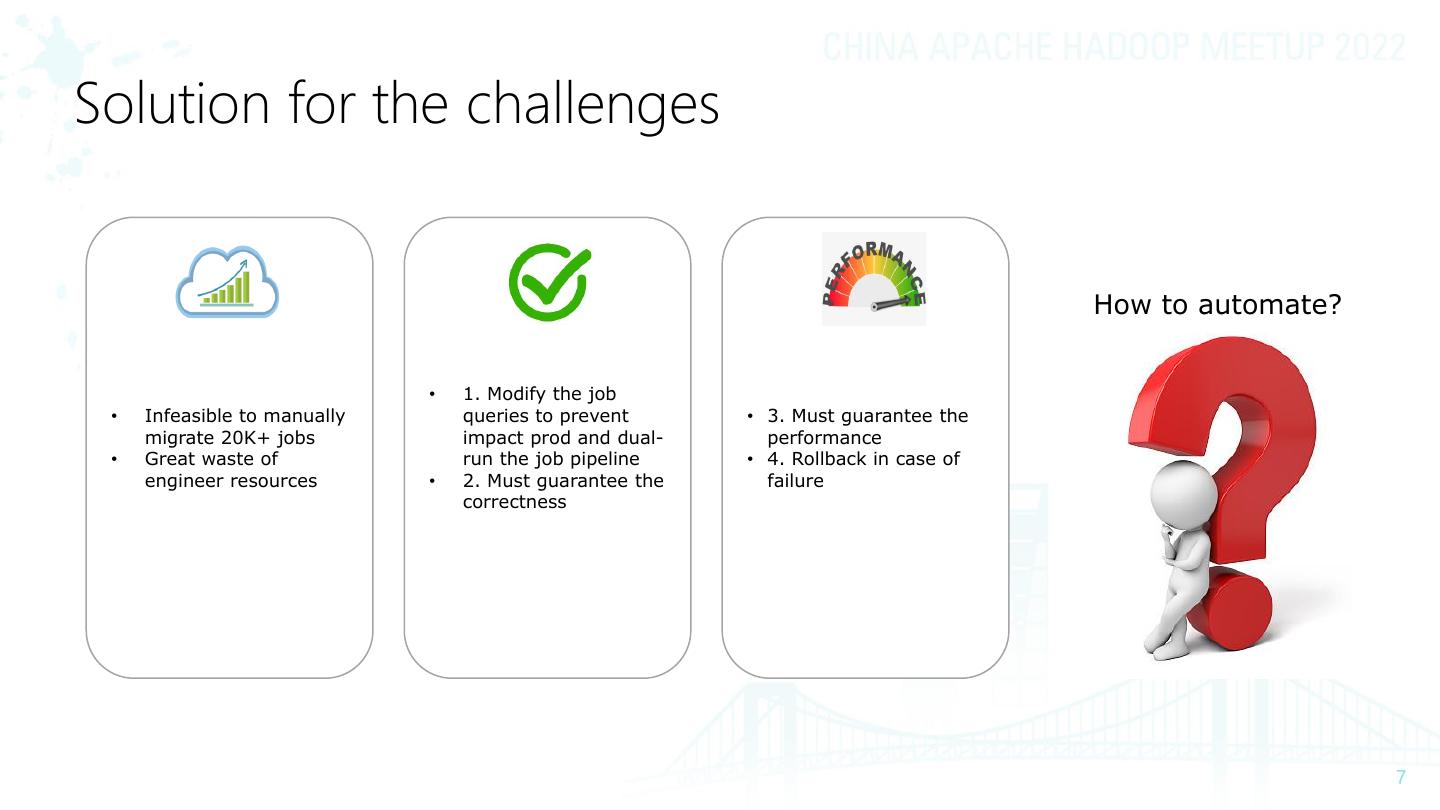
7 .Solution for the challenges
How to automate?
• 1. Modify the job
• Infeasible to manually queries to prevent • 3. Must guarantee the
migrate 20K+ jobs impact prod and dual- performance
• Great waste of run the job pipeline • 4. Rollback in case of
engineer resources • 2. Must guarantee the failure
correctness
�
8 .Part2 – Automatic Spark Upgrade Solution
�
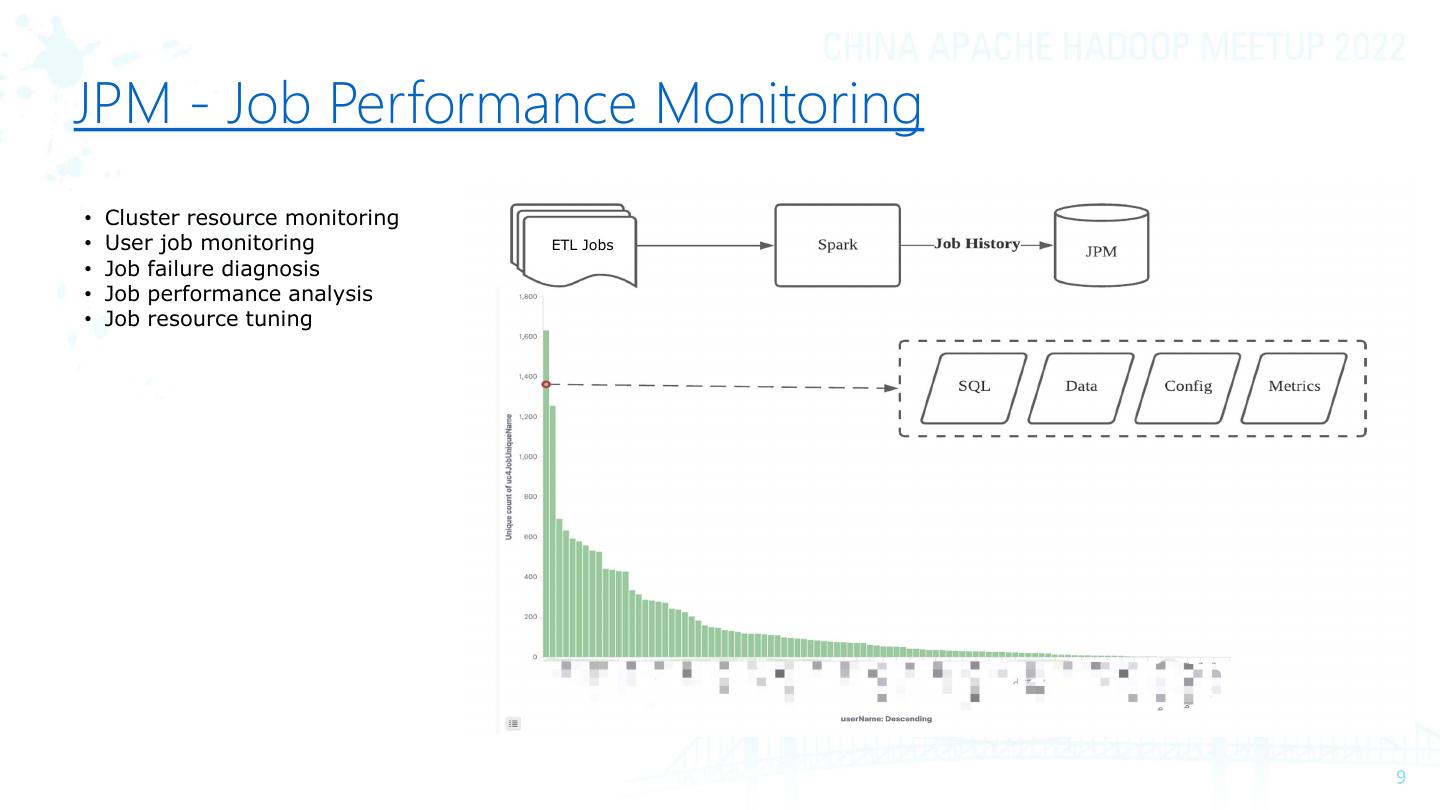
9 .JPM - Job Performance Monitoring
• Cluster resource monitoring
• User job monitoring ETL Jobs
• Job failure diagnosis
• Job performance analysis
• Job resource tuning
�
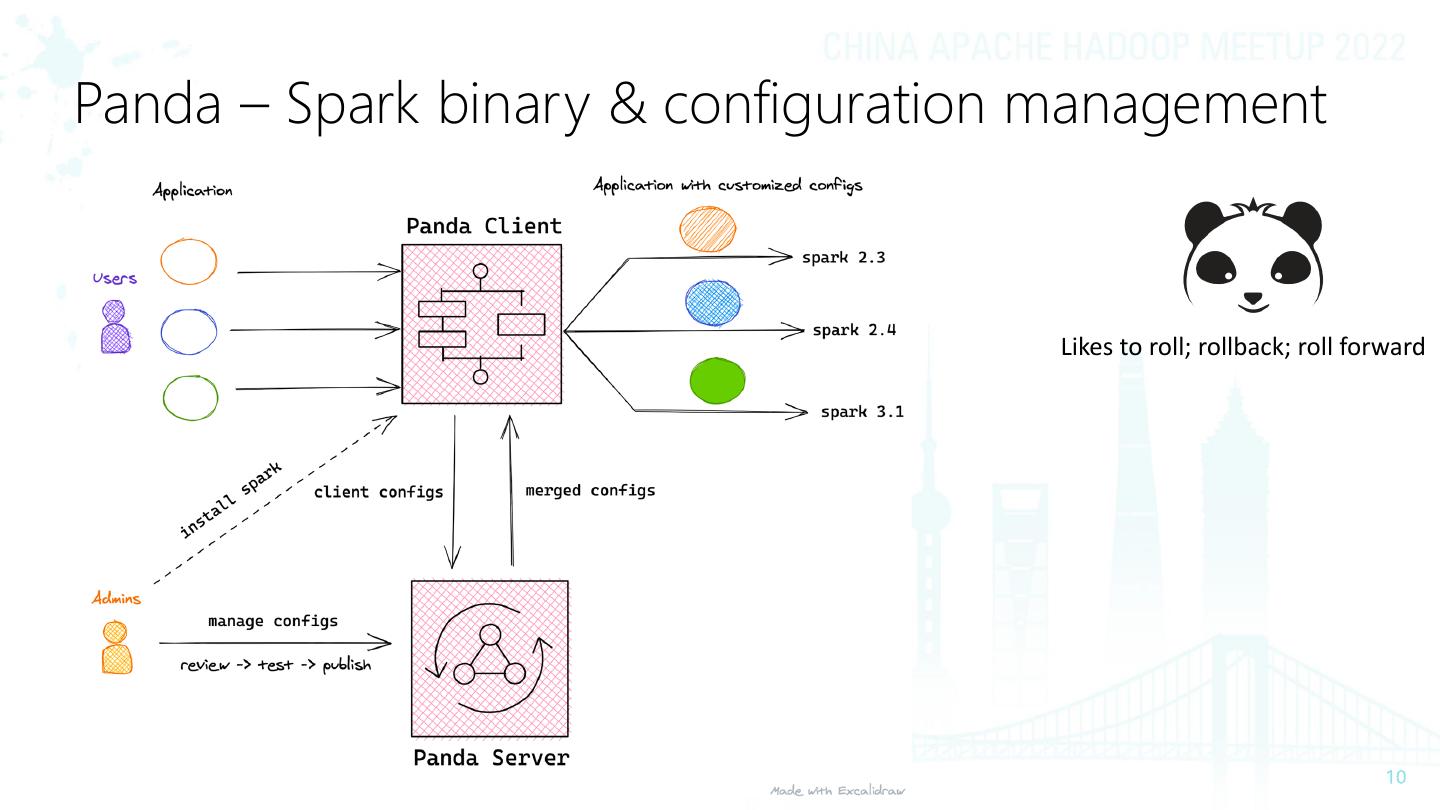
10 .Panda – Spark binary & configuration management
Likes to roll; rollback; roll forward
�
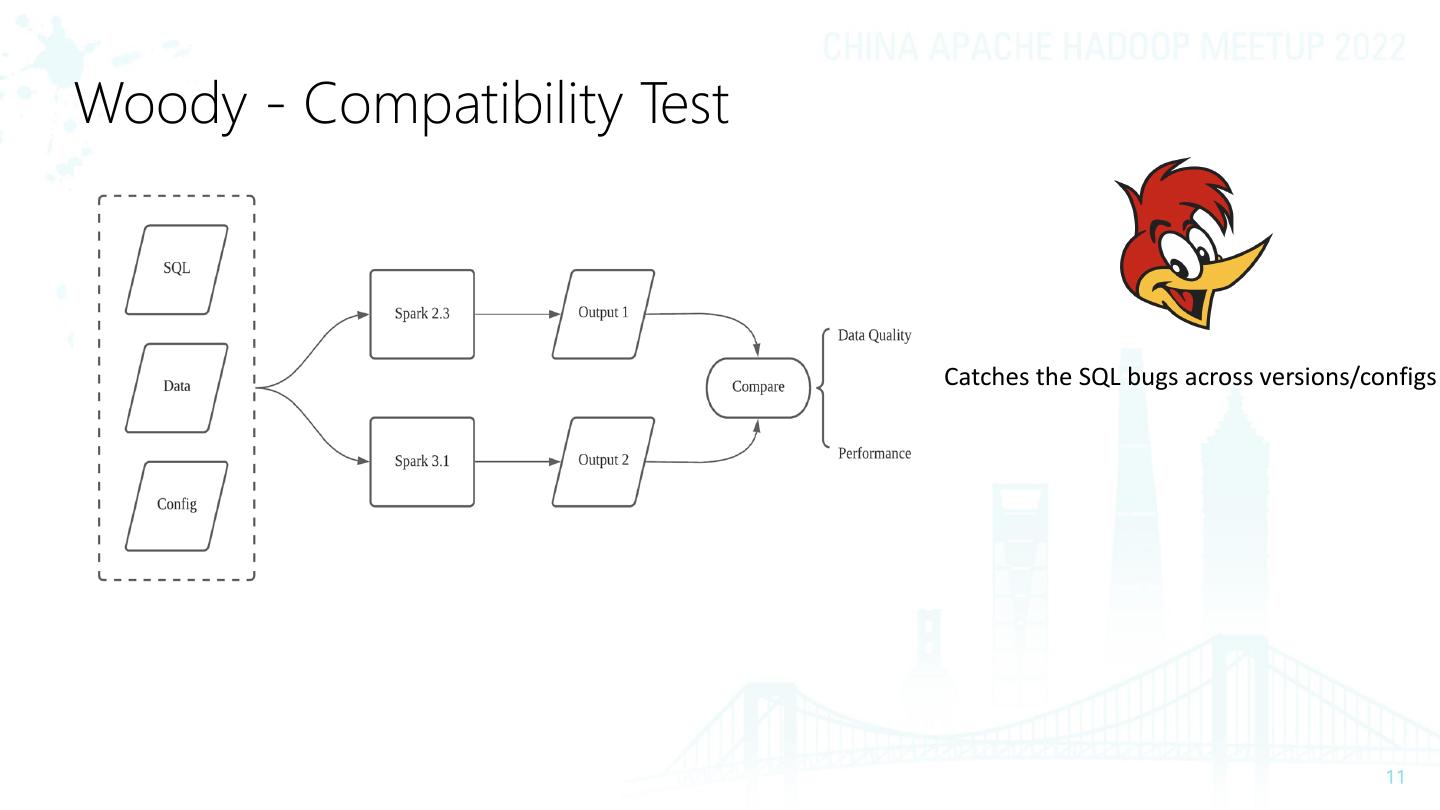
11 .Woody - Compatibility Test
Catches the SQL bugs across versions/configs
�
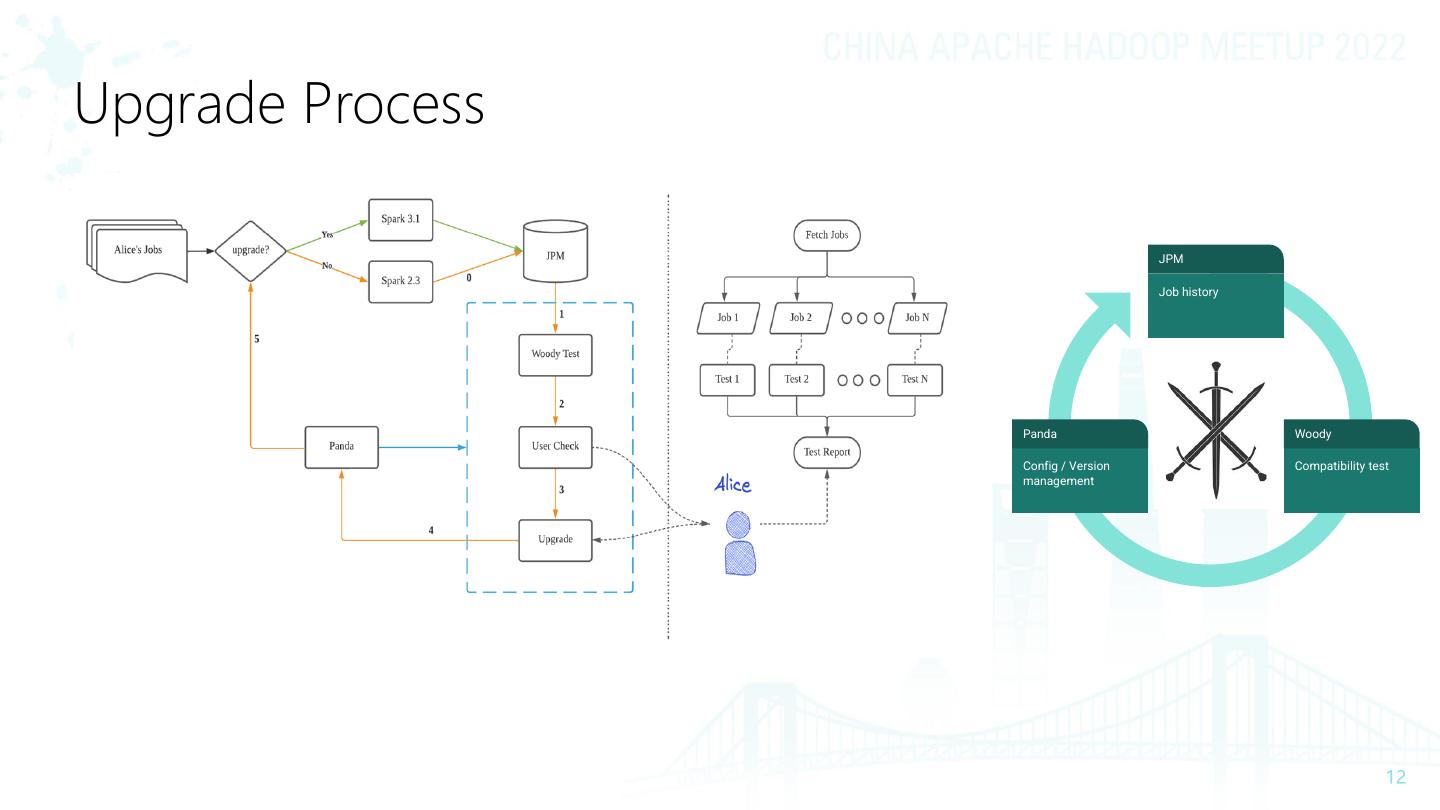
12 .Upgrade Process
JPM
Job history
Panda Woody
Config / Version Compatibility test
management
�
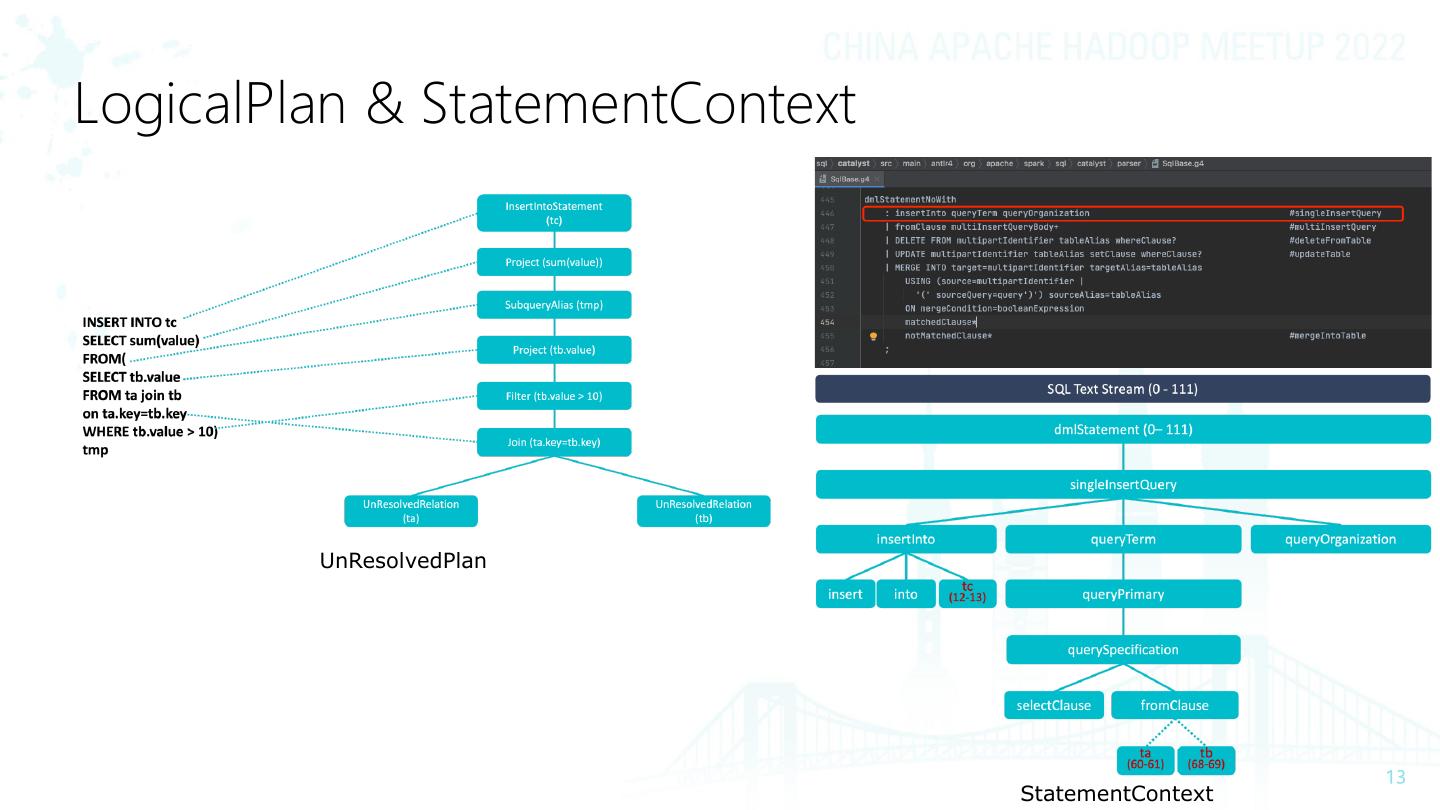
13 .LogicalPlan & StatementContext
UnResolvedPlan
StatementContext
�
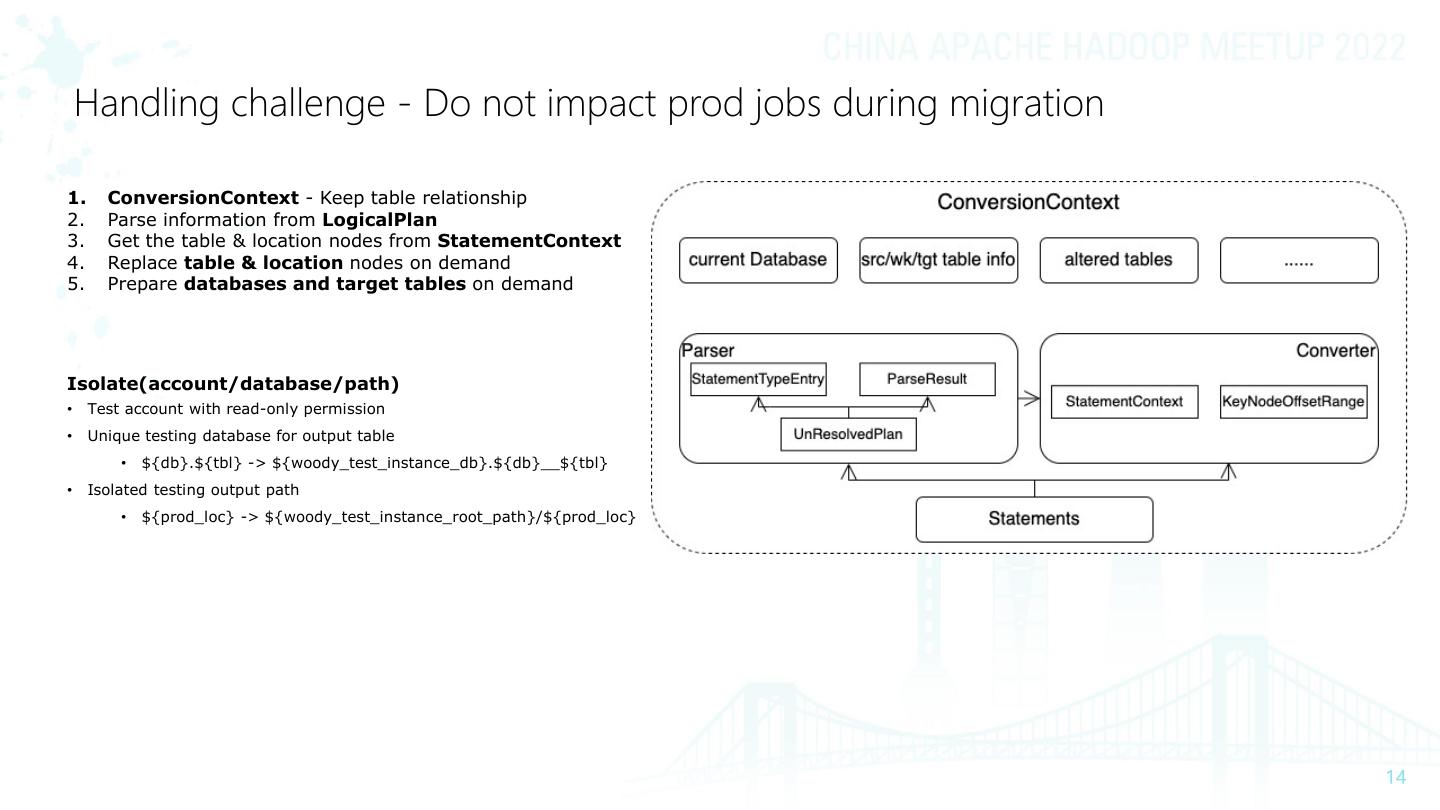
14 . Handling challenge - Do not impact prod jobs during migration
1. ConversionContext - Keep table relationship
2. Parse information from LogicalPlan
3. Get the table & location nodes from StatementContext
4. Replace table & location nodes on demand
5. Prepare databases and target tables on demand
Isolate(account/database/path)
• Test account with read-only permission
• Unique testing database for output table
• ${db}.${tbl} -> ${woody_test_instance_db}.${db}__${tbl}
• Isolated testing output path
• ${prod_loc} -> ${woody_test_instance_root_path}/${prod_loc}
�
15 .Making queries safe to test
Before After
use demo; create database if not exists ${woody_test_db} location ${woody_test_db_loc};
drop table if exists tc; drop table if exists ${woody_test_db}.demo__tc;
create table tc(id int) using parquet location ’/apps/demo/loc’; create table ${woody_test_db}.demo_tc(id int) using parquet location
insert into tc select ta.key from ta join tb on ta.id=tb.id; ’${woody_test_db_loc}/apps/demo/loc’;
Insert into td select tc.* from tc join td on tc.id=te.id; insert into ${woody_test_db}.demo_tc select ta.key from demo.ta join demo.tb on ta.id=tb.id;
Insert into ${woody_test_db}.demo_td select demo_tc.* from ${woody_test_db}.demo_tc
join demo.te on tc.id=te.id;
�
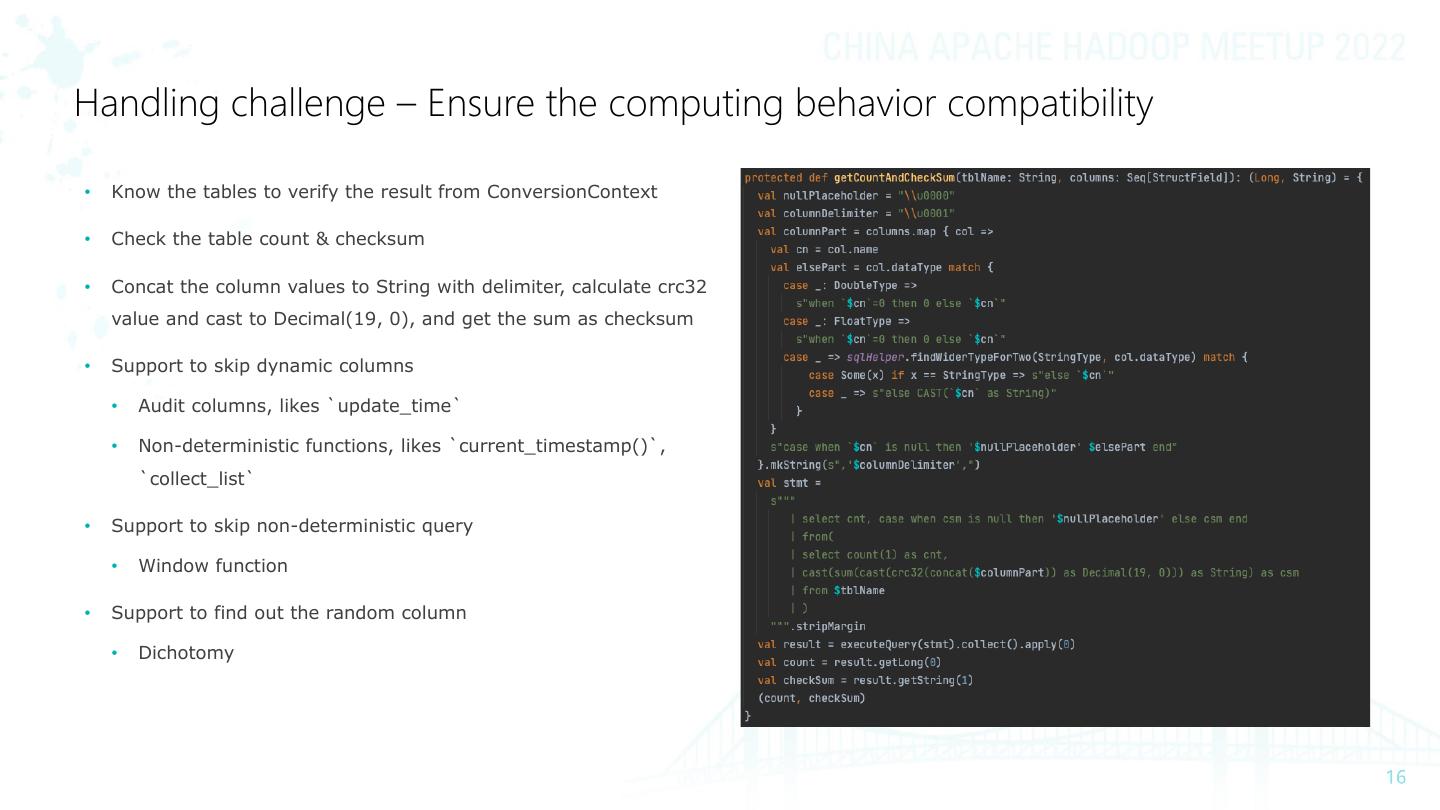
16 .Handling challenge – Ensure the computing behavior compatibility
• Know the tables to verify the result from ConversionContext
• Check the table count & checksum
• Concat the column values to String with delimiter, calculate crc32
value and cast to Decimal(19, 0), and get the sum as checksum
• Support to skip dynamic columns
• Audit columns, likes `update_time`
• Non-deterministic functions, likes `current_timestamp()`,
`collect_list`
• Support to skip non-deterministic query
• Window function
• Support to find out the random column
• Dichotomy
�
17 .Guarantee the correctness and performance
• Correctness
• Count & Checksum
• Sample data
• Performance(from JPM)
• HCU(Hadoop Compute UNIT)
• 1HCU=1GB*Second
�
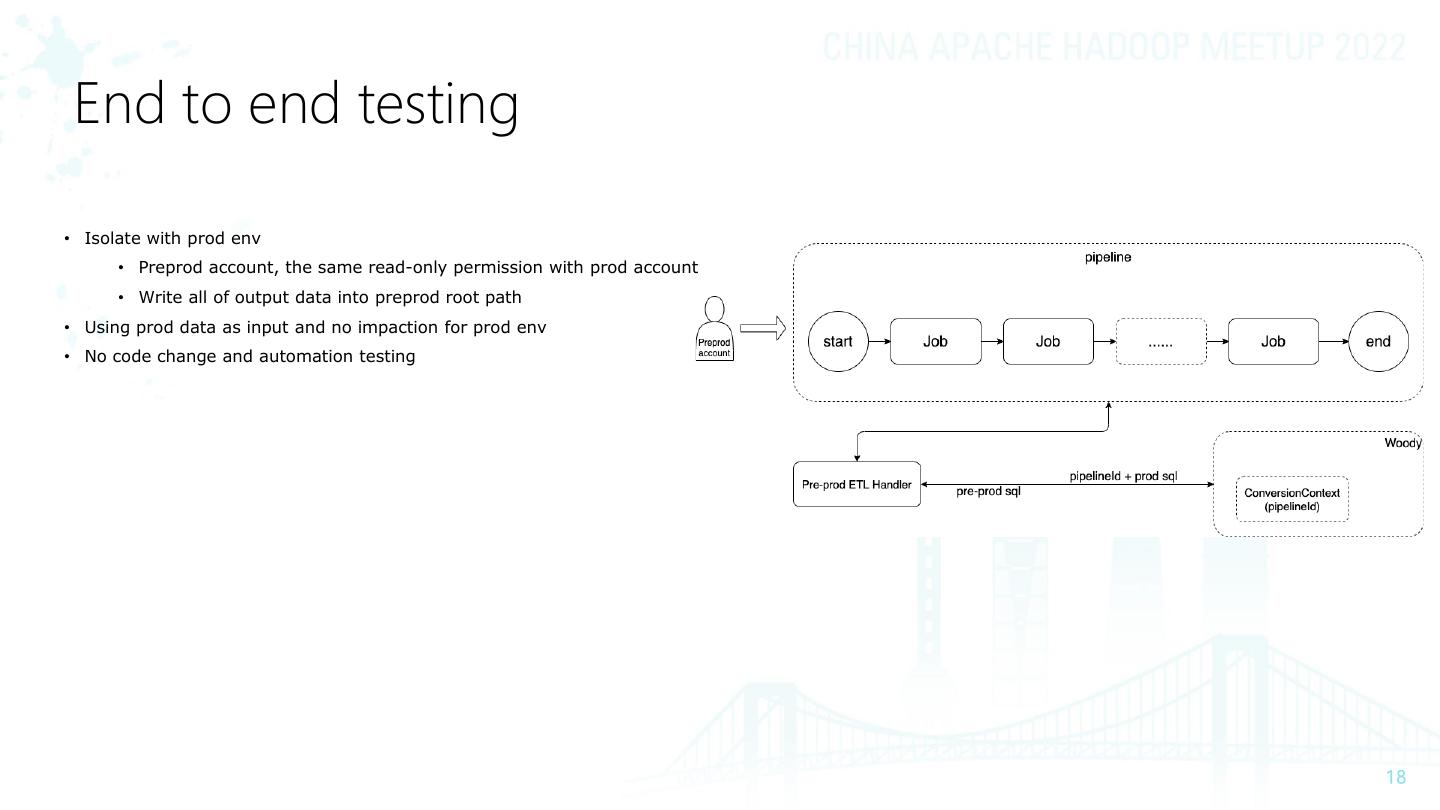
18 . End to end testing
• Isolate with prod env
• Preprod account, the same read-only permission with prod account
• Write all of output data into preprod root path
• Using prod data as input and no impaction for prod env
• No code change and automation testing
�
19 .Part3 – Results & Future Plans
�
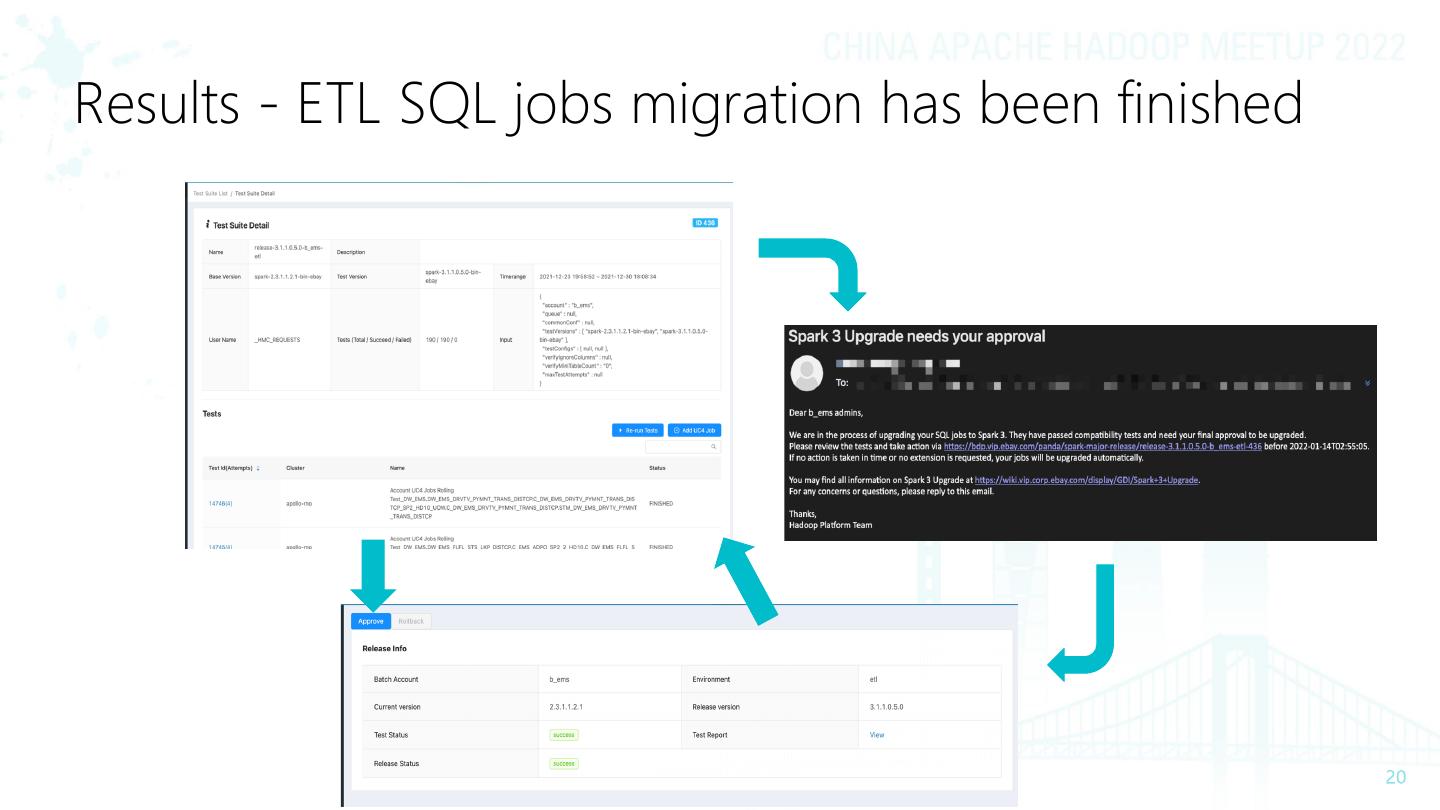
20 .Results - ETL SQL jobs migration has been finished
�
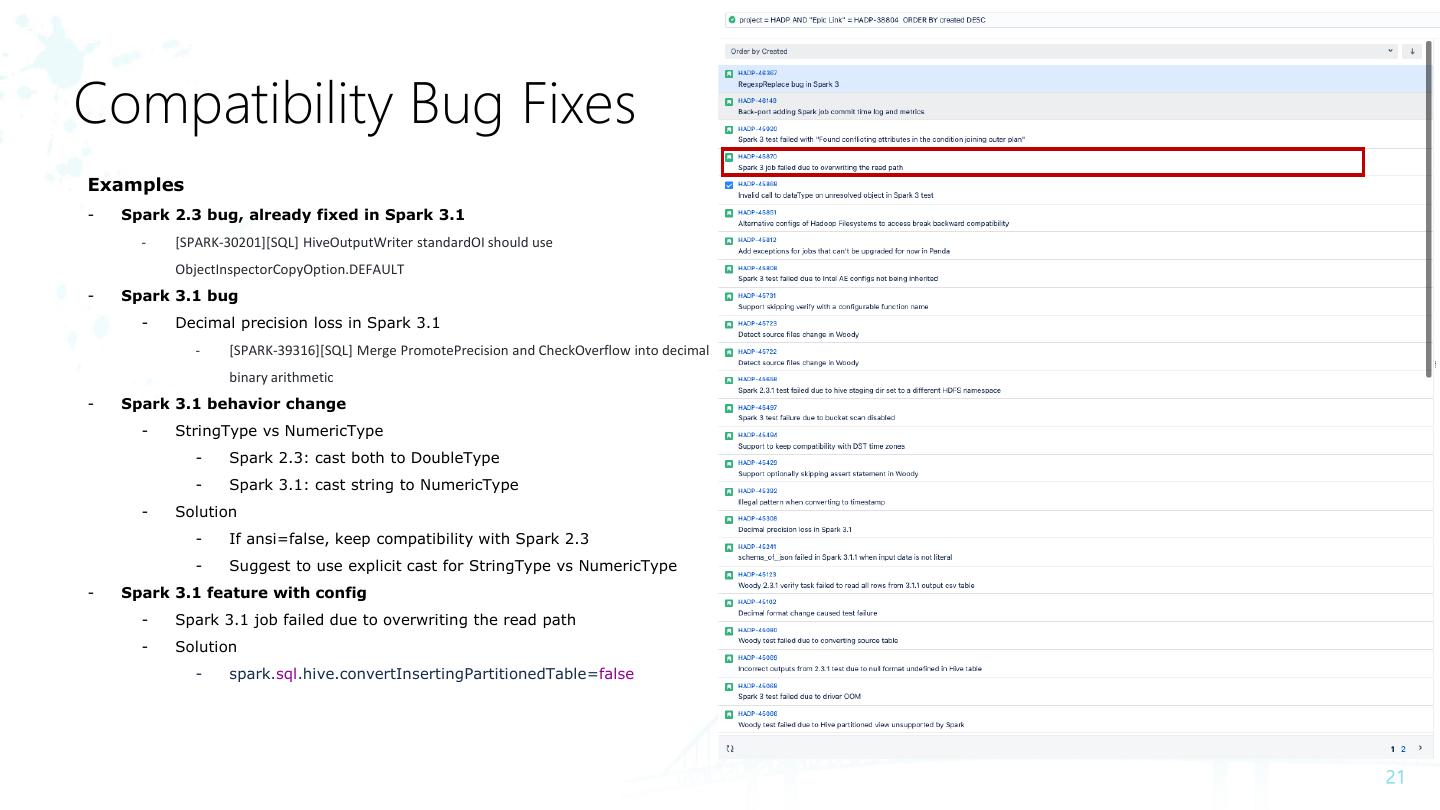
21 .Compatibility Bug Fixes
Examples
- Spark 2.3 bug, already fixed in Spark 3.1
- [SPARK-30201][SQL] HiveOutputWriter standardOI should use
ObjectInspectorCopyOption.DEFAULT
- Spark 3.1 bug
- Decimal precision loss in Spark 3.1
- [SPARK-39316][SQL] Merge PromotePrecision and CheckOverflow into decimal
binary arithmetic
- Spark 3.1 behavior change
- StringType vs NumericType
- Spark 2.3: cast both to DoubleType
- Spark 3.1: cast string to NumericType
- Solution
- If ansi=false, keep compatibility with Spark 2.3
- Suggest to use explicit cast for StringType vs NumericType
- Spark 3.1 feature with config
- Spark 3.1 job failed due to overwriting the read path
- Solution
- spark.sql.hive.convertInsertingPartitionedTable=false
�
22 .Future Plans
• Push Spark Scala jobs migration
• Push pyspark jobs migration
• Has provided portable python environment for Spark3
• Job tunning
�