






















- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 视频嵌入链接 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
4.李呈祥-哔哩哔哩如何基于Trino+Iceberg打造高效湖仓一体平台(2)
李呈祥,哔哩哔哩OLAP平台负责人。目前在哔哩哔哩负责OLAP平台的建设,有多年丰富的大数据内核和平台的研发经验。在此之前,他曾在阿里云,唯品会,Intel等多家公司负责或参与大数据平台和组件的研发工作,他是Apache Hive和Flink项目的committer。
湖仓一体是近年来哔哩哔哩大数据平台一个重要的演进方向,如何基于湖仓一体降低数据分析的开发和查询成本,提升效率是我们持续探索的方向。本次分享主要介绍哔哩哔哩湖仓一体的技术架构,平台功能的建设,以及我们在数据管理服务,Trino引擎和Iceberg存储方向的技术探索。
展开查看详情
1 .
2 .哔哩哔哩如何基于Trino+Iceberg 打造高效湖仓一体平台 李呈祥
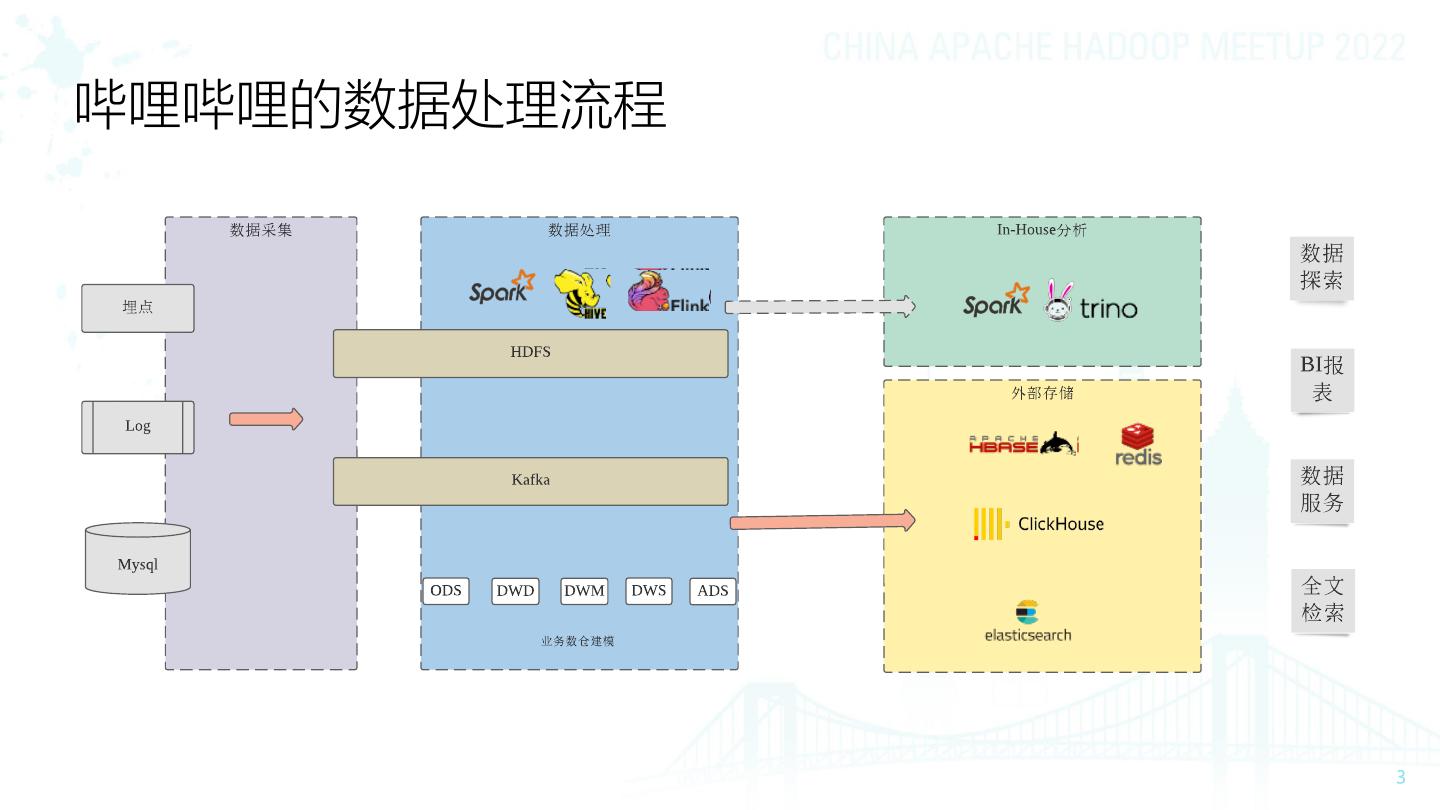
3 .哔哩哔哩的数据处理流程
4 .为什么需要引入湖仓一体? 好处: 1. 降本增效,提升In-House分析的 查询效率。 2. 减少需要同步到外部存储的场景, 简化数据处理流程。 3. 透明兼容已有大数据开发平台工具 问题: 链。 • Hive->其他存储,需要额外的数据同步 和存储成本。 • 数据孤岛,跨源查询的成本过高。 • 数据质量/血缘/安全/元数据的管理成本。
5 .如何构建秒级响应的湖仓一体平台?
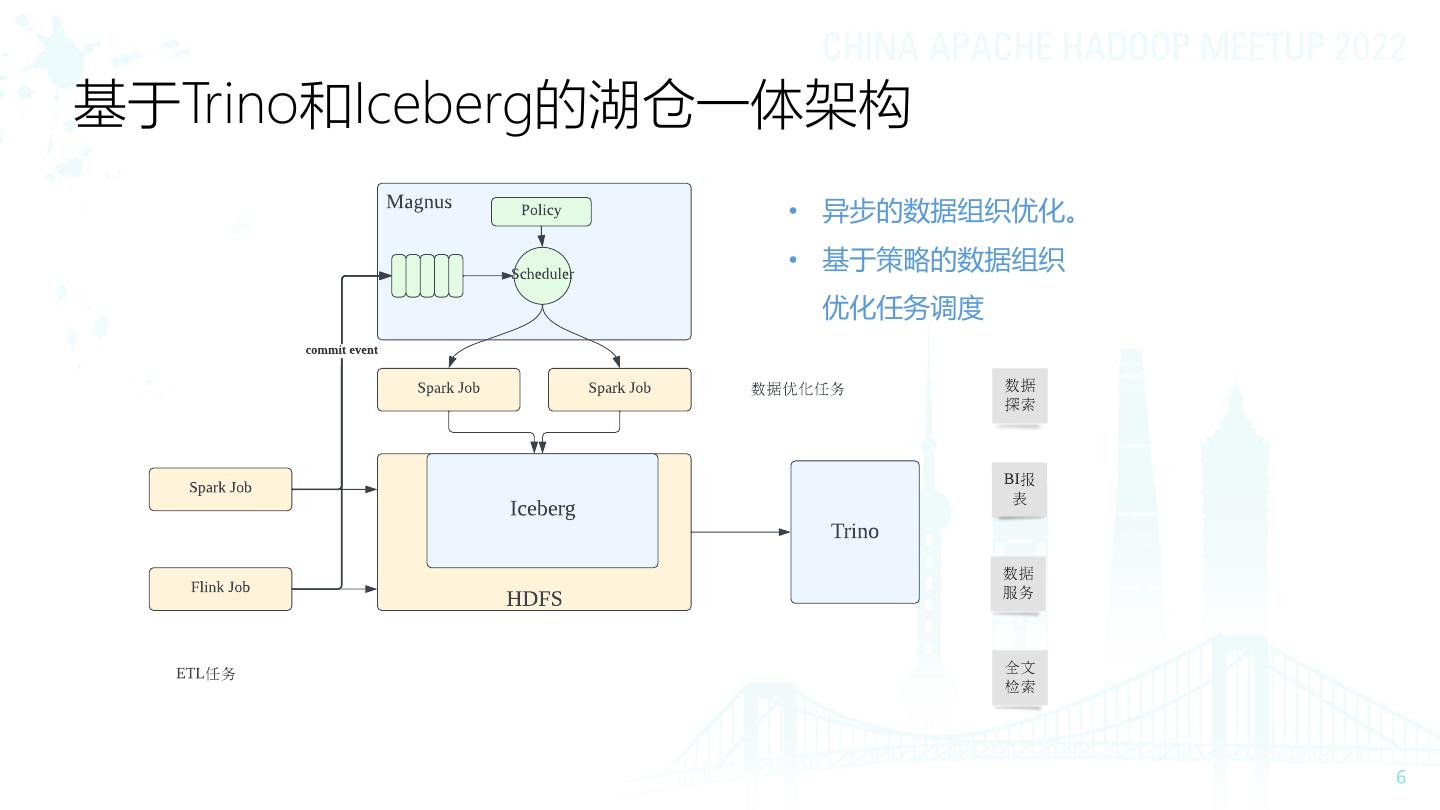
6 .基于Trino和Iceberg的湖仓一体架构 • 异步的数据组织优化。 • 基于策略的数据组织 优化任务调度
7 .如何构建秒级响应的湖仓一体平台? 为什么可以做到: 为什么不是毫秒级: 1. 基于规范化数据的SPJA(SELECT PROJECT 1. 存储在分布式文件系统上引入的网络开销和低 JOIN AGGREGATE)查询场景。 SLA保证。 2. 排序/索引/预计算等数仓技术可以大大降低实 2. Iceberg文件级别的元数据管理。 际需要扫描的数据量。 3. 开放查询引擎Trino本身的执行效率。 3. Iceberg的事务支持使得我们可以安全地对数 据进行合理地重新组织。 可预期的数据扫描量 + 可控的计算复杂度 = 如何只访问查询逻辑上需要的数据? 可预期的查询响应时间
8 .典型多维分析场景 投影 过滤 关联 聚合 过滤条件: 过滤字段: 1. 等值过滤: =, IN等 1. 高基数字段 2. 范围过滤: >, >=, <, <=, BETWEEN AND等 2. 低基数字段
9 .Trino和Iceberg的Data Skipping相关技术 Trino: /logdate=20220919/ /logdate=20220919/ Age OBD Name Age OBD Name 16 1 Alice 16 1 Alice Filter Push Down 18 2 Bob file1 16 4 Ivy file1 17 1 Candy 16 2 Meg Iceberg: 19 4 Daisy 16 3 Polly Age OBD Name Age OBD Name 1. Partition Prunning 16 4 Ivy 17 1 Candy 18 3 Jim 17 3 Eric file2 file2 2. 文件级别的所有字段MinMax索引 17 2 Kathy 17 2 Kathy 17 4 Lynn 17 4 Lynn 3. Order By/Sort By数据排序支持 Age OBD Name Age OBD Name 16 2 Meg 18 2 Bob 18 4 Nell file3 file3 18 1 Gill 19 1 Olive 18 3 Jim 16 3 Polly 18 4 Nell SELECT * FROM t WHERE logdate=20220919 AND age = 16 Age OBD Name Age OBD Name 17 3 Eric 19 4 Daisy file4 19 2 Frank file4 19 2 Frank 18 1 Gill 19 3 Helen 19 3 Helen 19 1 Olive /logdate=20220920/ /logdate=20220920/ … …
10 .Data Clustering 文件间数据组织: Hash Distribution ALTER TABLE employee WRITE Range Distribution DISTRIBUTED BY age, city WITH ZORDER SORT BY age; Zorder Distribution HibertCurve Distribution 文件内数据组织: Sort By
11 .Data Clustering - ZOrder 多维数据没有天然的有序性,需要将多维数据映射成一维 数据进行比较,映射的一维数据如何保证各个原始维度数 据的聚集性,决定了Data Clustering的效果。 通过数据组织加速大规模数据分析
12 .Data Clustering – HIBERT CURVE
13 .Data Clustering
14 .索引 BloomRangeFilter BloomFilter Index BitMap Index Index 适合高基数字段等值查询 适合高基数字段范围值查询,多 适合高基数字段范围值查询 过滤条件 索引文件小 索引文件较小/过滤效果较好 索引文件较大/过滤效果好
15 .BitMap索引 范围过滤需要访问 每个基数都要存储 lo_ordtotalprice 0 1 2 3 4 5 6 7 8 计算大量Bitmap, 对应的Bitmap, 2 0 0 1 0 0 0 0 0 0 影响查询效率 存储代价太大 18 0 1 0 0 1 0 0 0 0 20 1 0 0 0 0 0 0 0 0 33 0 0 0 1 0 1 1 0 0 50 0 0 0 0 0 0 0 0 1 lo_ordtotalprice 0 1 2 3 4 5 6 7 8 188 0 0 0 0 0 0 0 1 0 (Comp 0) - 0 1 1 1 0 1 0 0 1 1 Bitmap索引:Equality Encode 1 1 1 1 1 1 1 1 1 1 (Comp 1) - 0 1 0 0 1 0 1 1 1 0 1 1 1 1 1 1 1 1 1 1 lo_ordtotalprice 0 1 2 3 4 5 6 7 8 O(n) O(log(n)) (Comp 2) - 0 0 1 1 1 1 1 1 0 1 2 0 0 1 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 (Comp 3) - 0 1 1 1 1 1 1 1 0 1 18 0 1 1 0 1 0 0 0 0 1 1 1 1 1 1 1 1 1 1 20 1 1 1 0 1 0 0 0 0 (Comp 4) - 0 0 0 1 1 0 1 1 0 0 33 1 1 1 1 1 1 1 0 0 1 1 1 1 1 1 1 1 1 1 50 1 1 1 1 1 1 1 0 1 (Comp 5) - 0 1 1 1 0 1 0 0 0 0 188 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 (Comp 6) - 0 1 1 1 1 1 1 1 1 1 通过索引加速湖仓一体分析 BitMap索引:Range Encoded Bitmap 1 1 1 1 1 1 1 1 1 1 (Comp 7) - 0 1 1 1 1 1 1 1 0 1 1 1 1 1 1 1 1 1 1 1 B(n) = RB(n) andNot RB(n-1) B(<n) = RB(n) B(>n) = RB(max) andNot RB(n) BitMap索引:Comp-2 Bit-Slice Range Encoded Bitmap
16 .BloomRangeFilter Piecewise-Monotone Hashing:分段单调有序哈希函数 interval bits bit array size Dyadic Trace-Tree 实际使用中索引大小大概是Bitmap的1/10 bloomRF: On Performing Range-Queries with Bloom-Filters based on Piecewise-Monotone Hash Functions and Dyadic Trace-Trees
17 .Trino如何使用索引 Phase1: Coordinator在获取表的inputSplits时,通过过滤 条件使用manifest中的low/upper bounds或index过滤不 需要的文件。 Phase2: Source Task在收到coordinator分配的inputSplit后, 通过index文件判断是否实际需要读取对应inputSplit数据。
18 .关联列 投影 过滤 关联 聚合 Record-Preserved Join orderkey custkey orderdate price custkey name city 满足Record-Preserved Join的条件: 0 0 20220919 100 0 Tom SH 1. LEFT JOIN + UniqueKey 1 2 20220920 32.5 1 Bob HZ 2 1 20220920 78 2 Alice BJ 2. LEFT/INNER JOIN + PKFK 3 2 20220920 43 customer 4 1 20220922 230.4 5 2 20220923 18 order orderkey custkey orderdate price c_city • Hash/Range/Zorder/HibertCurve Distribution On 0 0 20220919 100 SH Correlated Columns. 1 2 20220920 32.5 BJ 2 1 20220920 78 HZ • MinMax/BloomFilter/BitMap/BloomRangeFilter Index on 3 2 20220920 43 BJ Correlated Columns. 4 1 20220922 230.4 HZ 5 2 20220923 18 BJ order with correlated-column
19 . 关联列 New Trino Optimizer Rule: ApplyCorrelatedColumnFilter SELECT * FROM order, customer WHERE order.custkey = customer.custkey AND city = ‘SH’ LIMIT 10; orderkey custkey orderdate price c_city orderkey custkey orderdate price c_city 0 0 20220919 100 SH 3 2 20220920 43 BJ file1 1 2 20220920 32.5 BJ 1 2 20220920 32.5 BJ file1 2 1 20220920 78 HZ 5 2 20220923 18 BJ 3 2 20220920 43 BJ 2 1 20220920 78 HZ file2 4 1 20220922 230.4 HZ file2 4 1 20220922 230.4 HZ 5 2 20220923 18 BJ 0 0 20220919 100 SH
20 .预计算 投影 过滤 关联 聚合 1. 通过Iceberg metadata直接响应表/分区 级别的count/min/max聚合查询。 2. Partial Pre-Aggregation进行中
21 .哔哩哔哩湖仓一体平台现状 Trino集群 查询量/天 总数据量 5376c 70K 2PB 平均扫描数据量 P90/P95/P99响应时间 2GB 1.9S/2.7s/7.5s
22 .
3秒后跳转登录页面
去登陆

