


























- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 视频嵌入链接 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
4.顾荣-Fluid—面向云原生数据密集型应用的高效开源支撑平台
展开查看详情
1 .
2 .Fluid—云原生环境下数据密集型应用 的高效支撑平台 顾荣 南京大学 gurong@nju.edu.cn https://github.com/fluid-cloudnative/fluid
3 .目录 1 项目背景 2 架构理念 3 效果展示 4 近期发展
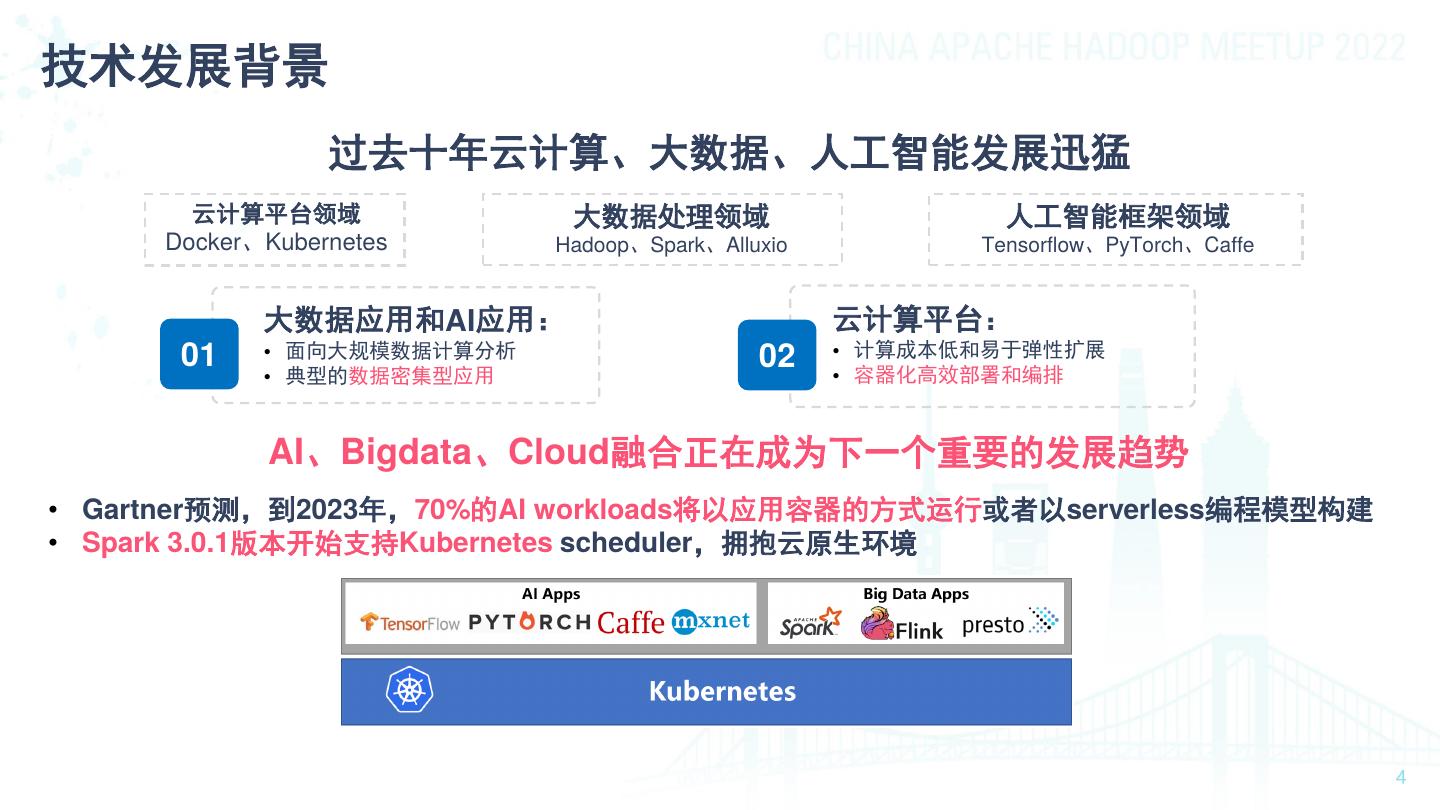
4 .技术发展背景 过去十年云计算、大数据、人工智能发展迅猛 云计算平台领域 大数据处理领域 人工智能框架领域 Docker、Kubernetes Hadoop、Spark、Alluxio Tensorflow、PyTorch、Caffe 大数据应用和AI应用: 云计算平台: 01 • 面向大规模数据计算分析 02 • 计算成本低和易于弹性扩展 • 典型的数据密集型应用 • 容器化高效部署和编排 AI、Bigdata、Cloud融合正在成为下一个重要的发展趋势 • Gartner预测,到2023年,70%的AI workloads将以应用容器的方式运行或者以serverless编程模型构建 • Spark 3.0.1版本开始支持Kubernetes scheduler,拥抱云原生环境
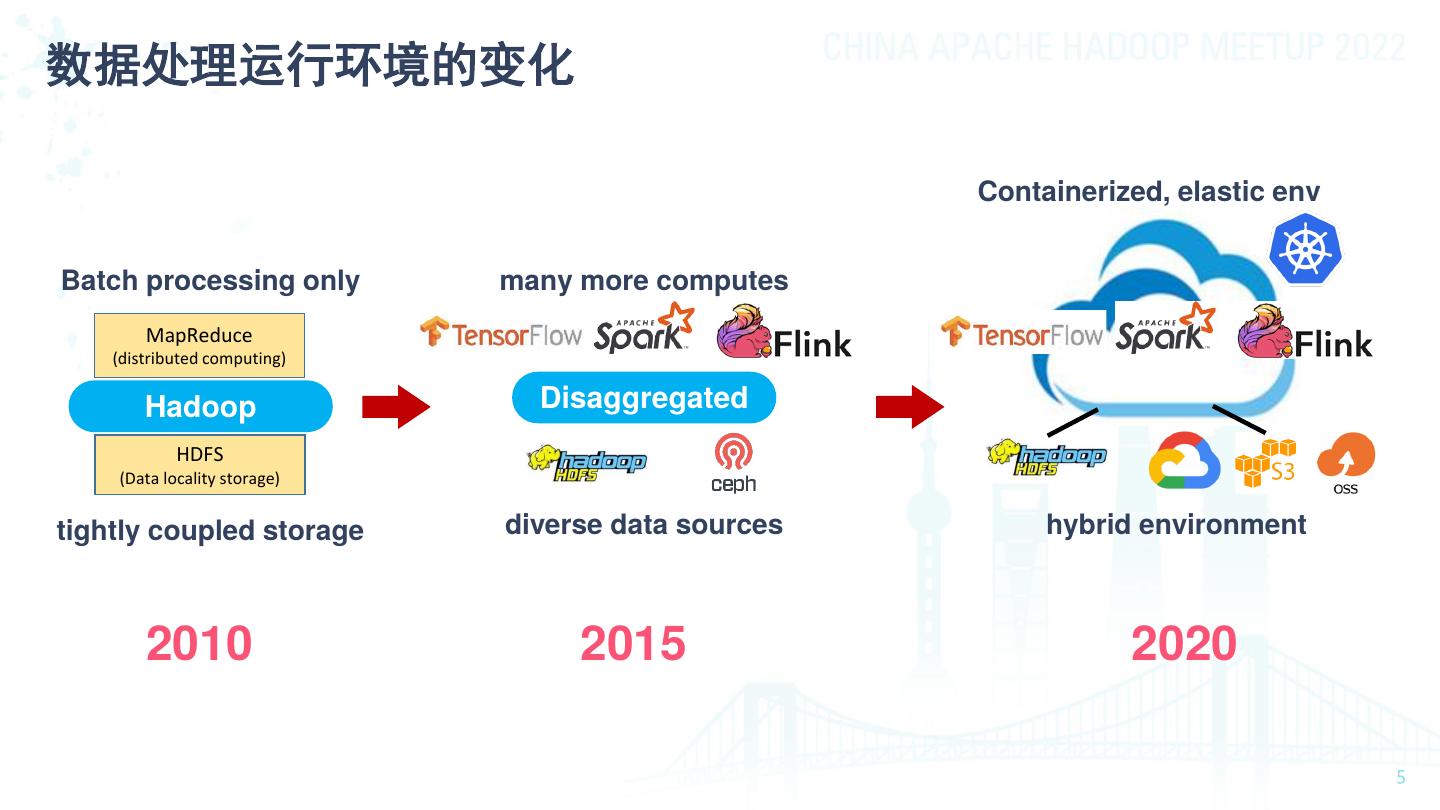
5 .数据处理运行环境的变化 Containerized, elastic env Batch processing only many more computes MapReduce (distributed computing) Hadoop Disaggregated HDFS (Data locality storage) tightly coupled storage diverse data sources hybrid environment 2010 2015 2020
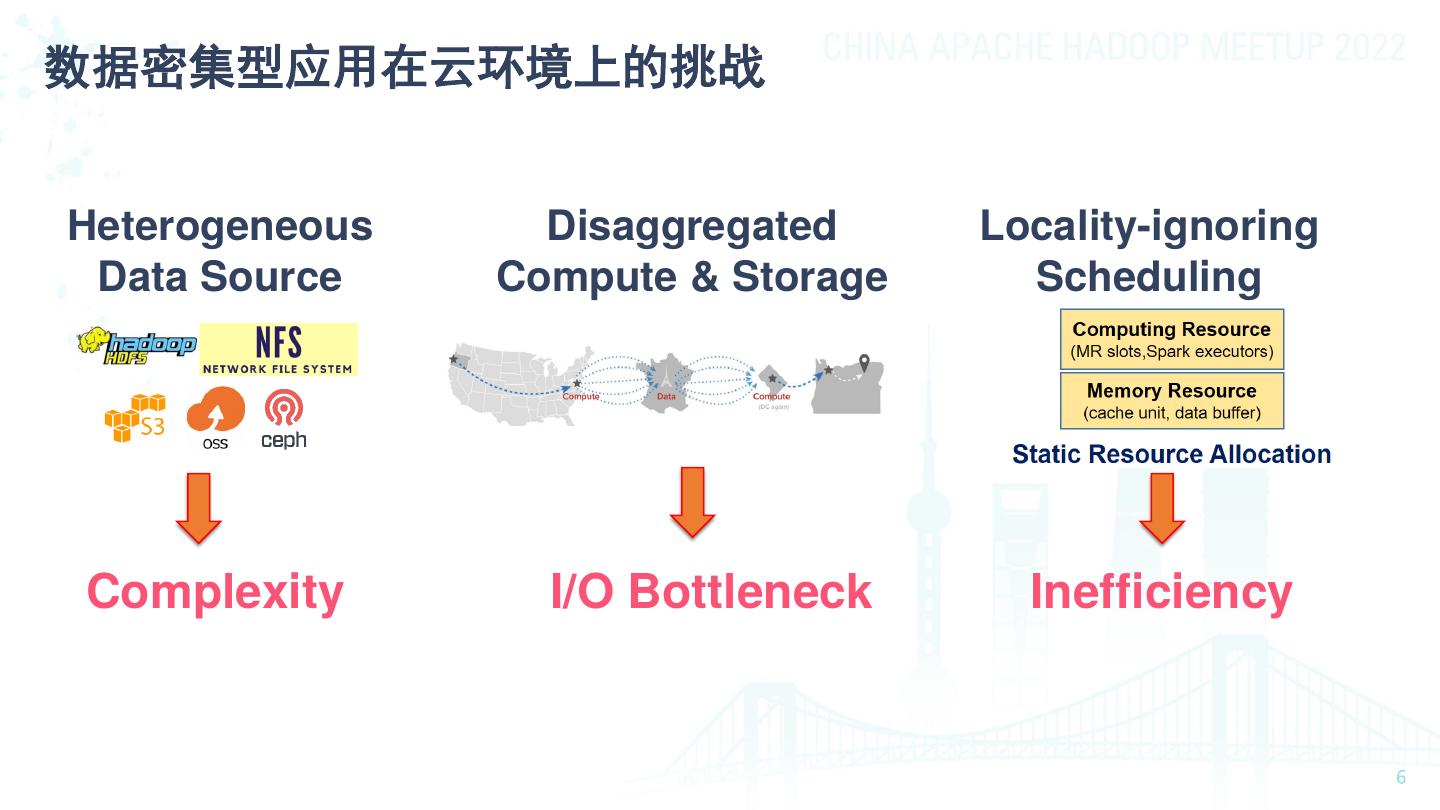
6 .数据密集型应用在云环境上的挑战 Heterogeneous Disaggregated Locality-ignoring Data Source Compute & Storage Scheduling Complexity I/O Bottleneck Inefficiency
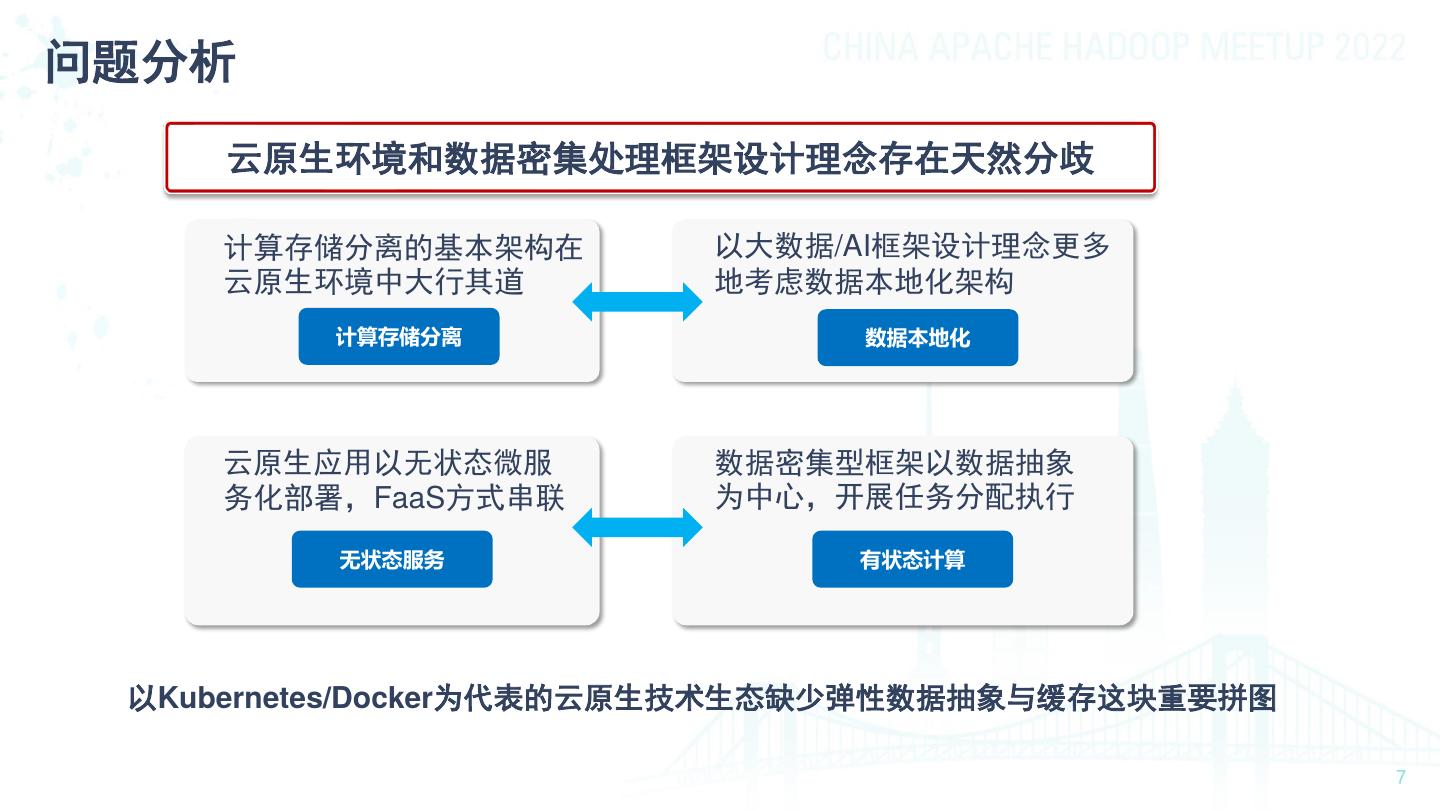
7 .问题分析 云原生环境和数据密集处理框架设计理念存在天然分歧 计算存储分离的基本架构在 以大数据/AI框架设计理念更多 云原生环境中大行其道 地考虑数据本地化架构 计算存储分离 数据本地化 云原生应用以无状态微服 数据密集型框架以数据抽象 务化部署,FaaS方式串联 为中心,开展任务分配执行 无状态服务 有状态计算 以Kubernetes/Docker为代表的云原生技术生态缺少弹性数据抽象与缓存这块重要拼图
8 .Kubernetes生态中缺失的一块抽象 01 02 Kubernetes现有的抽象: 云原生其他存储的抽象: • 计算抽象成了Pod • Rook:对于Ceph生命周期管理 • 存储抽象成了PVC • ChubaoFS:面向数据持久化存储,同 • 网络抽象成了Service 时提供对象和文件存储 缺乏以应用为中心的数据抽象及其生命周期管理
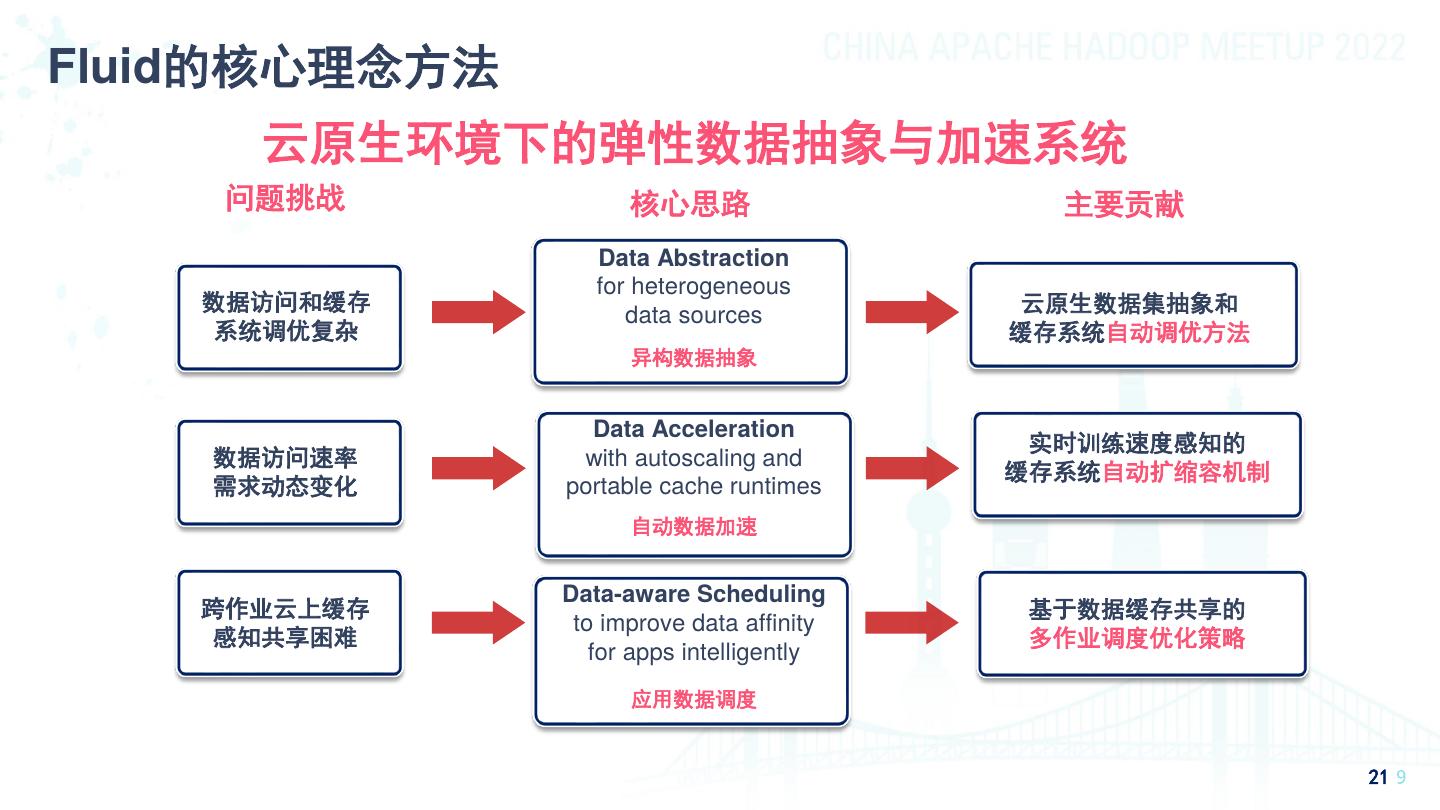
9 .Fluid的核心理念方法 云原生环境下的弹性数据抽象与加速系统 问题挑战 核心思路 主要贡献 Data Abstraction for heterogeneous 数据访问和缓存 云原生数据集抽象和 data sources 系统调优复杂 缓存系统自动调优方法 异构数据抽象 Data Acceleration 实时训练速度感知的 数据访问速率 with autoscaling and 缓存系统自动扩缩容机制 需求动态变化 portable cache runtimes 自动数据加速 Data-aware Scheduling 跨作业云上缓存 基于数据缓存共享的 to improve data affinity 感知共享困难 多作业调度优化策略 for apps intelligently 应用数据调度 21
10 .Fluid的核心理念方法 01 提供云平台数据集抽象的原生支持 数据密集型应用所需基础支撑能力功能化,实现数据高效访问并降低多维成本 基于容器调度管理的智能数据集编排 02 通过数据集缓存引擎与Kubernetes容器调度和扩缩容能力的相互配合,实现 数据集可迁移性 面向云上数据本地化的应用调度 03 Kubernetes调度器通过与缓存引擎交互获得节点的数据缓存信息,将使用该数据的应用以透 明的方式调度到包含数据缓存的节点,最大化缓存本地性的优势
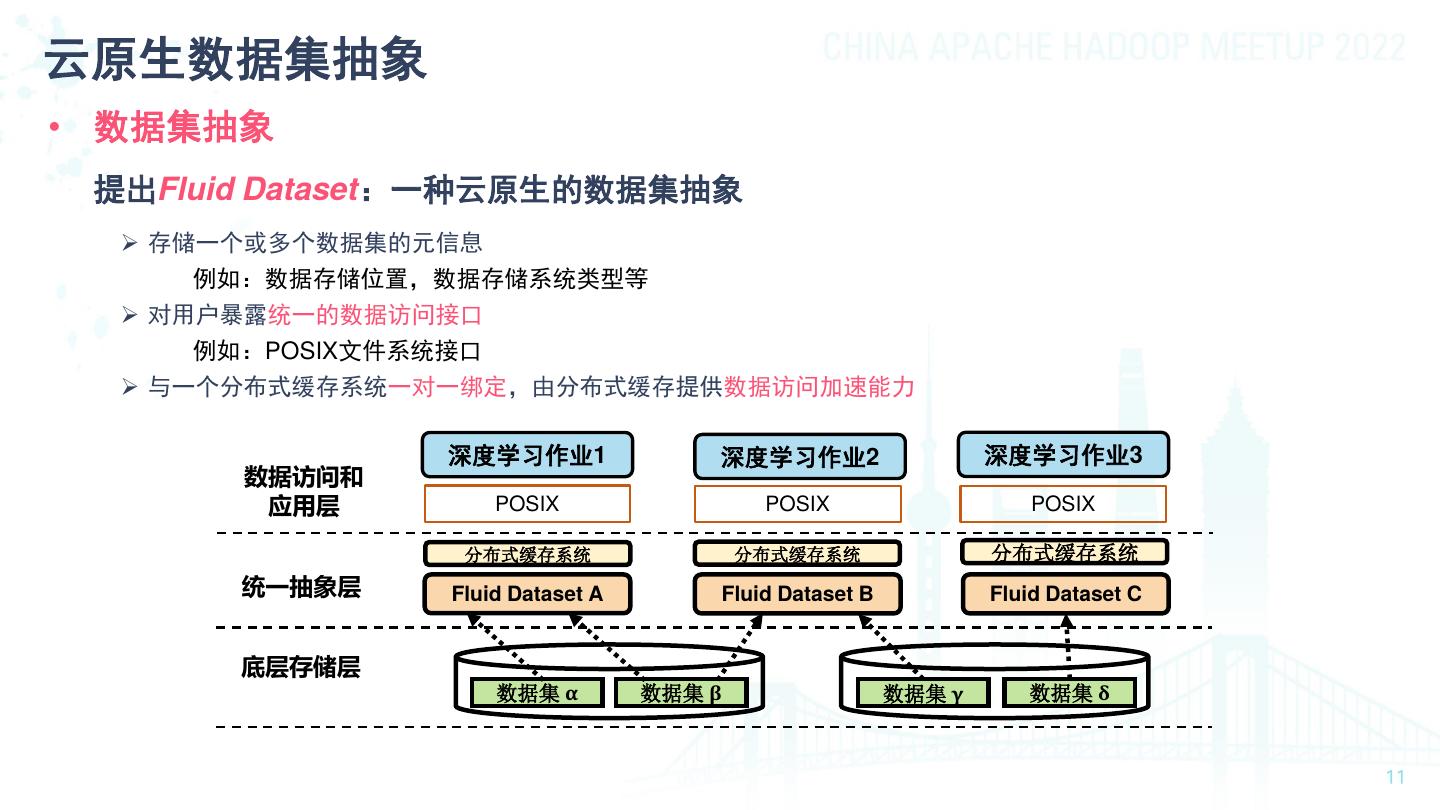
11 .云原生数据集抽象 • 数据集抽象 提出Fluid Dataset:一种云原生的数据集抽象 ➢ 存储一个或多个数据集的元信息 例如:数据存储位置,数据存储系统类型等 ➢ 对用户暴露统一的数据访问接口 例如:POSIX文件系统接口 ➢ 与一个分布式缓存系统一对一绑定,由分布式缓存提供数据访问加速能力 深度学习作业1 深度学习作业2 深度学习作业3 数据访问和 应用层 POSIX POSIX POSIX 分布式缓存系统 分布式缓存系统 分布式缓存系统 统一抽象层 Fluid Dataset A Fluid Dataset B Fluid Dataset C 底层存储层 数据集 α 数据集 β 数据集 γ 数据集 δ
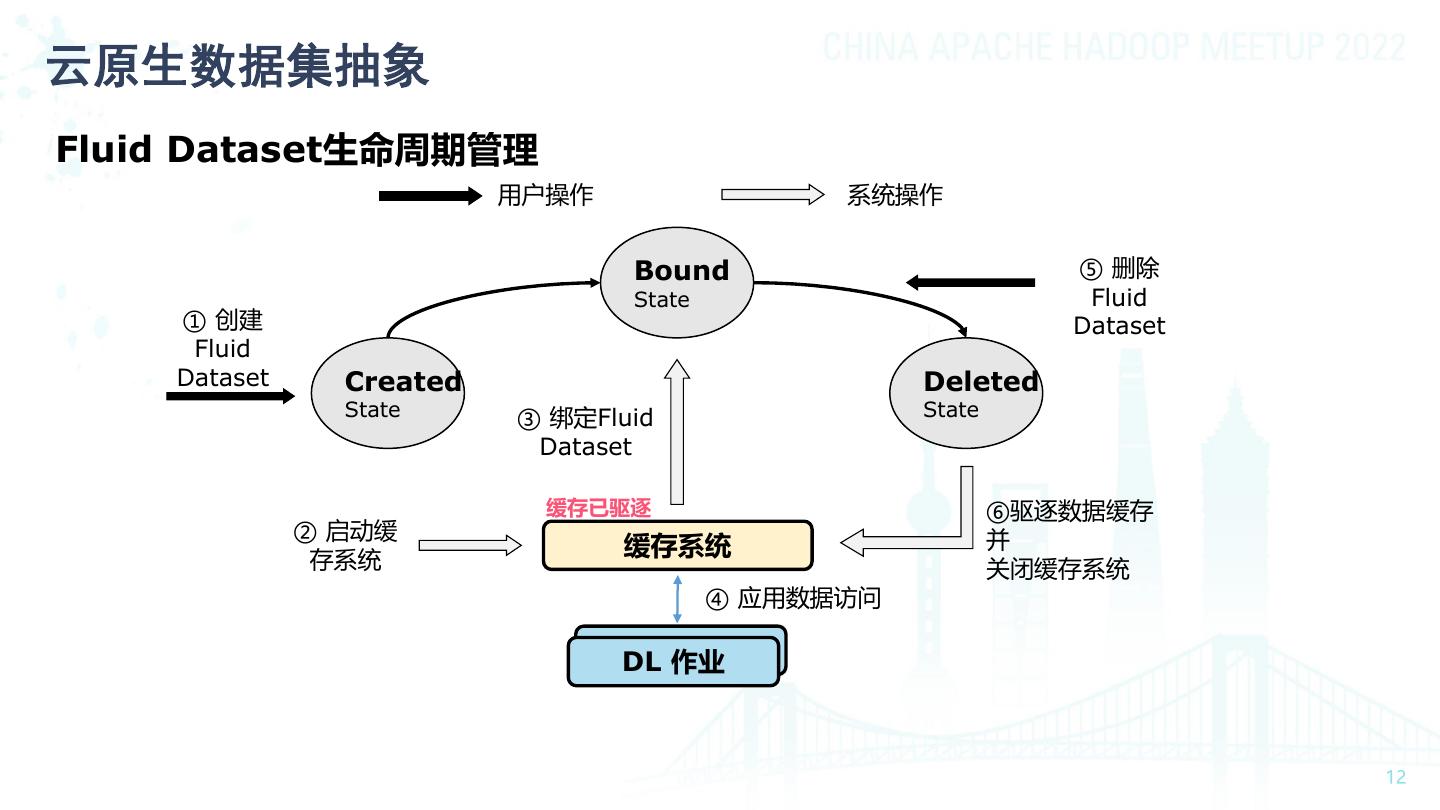
12 .云原生数据集抽象 Fluid Dataset生命周期管理 用户操作 系统操作 Bound ⑤ 删除 State Fluid ① 创建 Dataset Fluid Dataset Created Deleted State ③ 绑定Fluid State Dataset 缓存已驱逐 ⑥驱逐数据缓存 ② 启动缓 并 存系统 缓存系统 关闭缓存系统 ④ 应用数据访问 DL 作业 DL Jobs
13 .Fluid的功能概念 Fluid不是全存储加速和管理,而是应用使用的数据集加速和管理 • Concept 01 Dataset: 数据集是逻辑上相关的一组数据的集合,一致的文件特性,会被同一运算引擎使用 Runtime: 02 实现数据集安全性,版本管理和数据加速等能力的执行引擎的接口,定义了一系列生命周期的 方法。 03 AlluxioRuntime: 来自Alluixo社区,是支撑Dataset数据管理和缓存的执行引擎高效实现
14 .实时数据消费速度感知的缓存系统弹性扩缩容机制 新增DL Worker 缓存系统弹性扩缩容运行流程 DL Job 7 2 1 DL DL DL Worker Worker Worker 请求训练样例数量 =3 受TCP拥塞控制启发的扩缩容机制 Cache System AutoScaler Cache System 3 5 7 2 1 4 6 8 Cache Worker Cache Worker 1 扩容 & 预取 7 2 增大滑动窗口大小 数据预取 新增缓存系统 Storage Worker 14
15 .基于数据缓存共享的作业调度策略 • 基于数据缓存共享的作业优先级排序 作业优先级排序 ⚫ 调度决策时考虑集群内数据集缓存状态信息,对作业的调度顺序进行重排序 优化 • 观察:数据集规模(例:数据集大小、文件数量)影响着一个作业的整体运行时间 小规模数据集 ⇒ 训练迭代次数更少 ⇒ 作业运行时间更短 • 策略:优先调度基于小规模数据集进行训练的作业 • 优势:短作业优先调度,缓解Head-of-blocking带来的作业饥饿问题
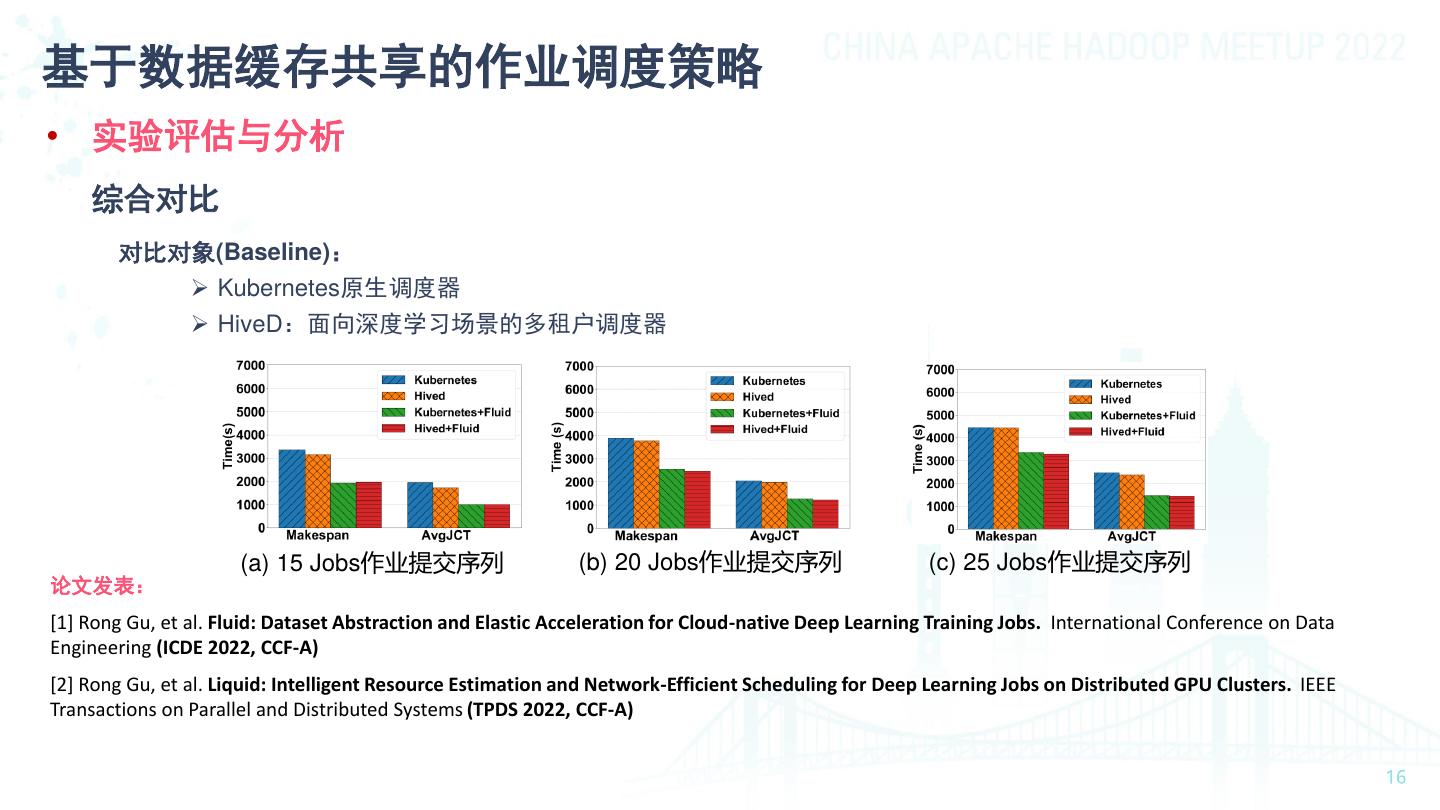
16 .基于数据缓存共享的作业调度策略 • 实验评估与分析 综合对比 对比对象(Baseline): ➢ Kubernetes原生调度器 ➢ HiveD:面向深度学习场景的多租户调度器 (a) 15 Jobs作业提交序列 (b) 20 Jobs作业提交序列 (c) 25 Jobs作业提交序列 论文发表: [1] Rong Gu, et al. Fluid: Dataset Abstraction and Elastic Acceleration for Cloud-native Deep Learning Training Jobs. International Conference on Data Engineering (ICDE 2022, CCF-A) [2] Rong Gu, et al. Liquid: Intelligent Resource Estimation and Network-Efficient Scheduling for Deep Learning Jobs on Distributed GPU Clusters. IEEE Transactions on Parallel and Distributed Systems (TPDS 2022, CCF-A)
17 .系统架构 Architecture Cloud-native & Open Source Building Blocks Kubernetes-native Alluxio Runtime PV/PVC by CSI CRD, Operators, Controllers Scheduler plugin Helm Charts 系统实现特点小结 • 基于Kubernetes实现:使用Alluxio作为 缓存系统实现 • 容器化: 所有组件均运行在Kubernetes Pod中,以Kubernetes原生方式接入 • 低侵入性:基于Kubernetes的扩展插件实 现,不对Kubernetes生态进行改动
18 .Fluid使用示例——Create a “Dataset” Edit “dataset.yaml” and run apiVersion: data.fluid.io/v1alpha1 kind: Dataset “kubectl apply -f dataset.yaml” metadata: name: imagenet spec: /data mounts: - mountPoint: s3://imagenet/train s3 s3://imagenet/train train validation pvc://ceph name: train - mountPoint: pvc://ceph name: validation ceph train1 train2 validation1 validation2 nodeAffinity: required: - nodeSelectorTerms: - matchExpressions: -key: GPU In GPU operator: In values: nodes - "true"
19 .Fluid使用示例—— Run Apps with Data Affinity Create “pod.yaml” and run “kubectl create –f pod.yaml” 2.Find the cacheable Node 1. Create Pod client Kubernetes Fluid Scheduler Scheduler 3.Order the nodes by the cache capabilities apiVersion: v1 kind: Pod Fluid Runtime 4.Start pod in N1 metadata: Service name: resnet50 spec: containers: - name: train image: resnet50 Alluxio Alluxio volumeMounts: Pod - mountPath: /data name: imagenet 10G Cached 5G Cached volumes: - name: imagenet N1 N2 N3 persistentVolumeClaim: claimName: imagenet Dataset Name
20 .系统演示Demo 20 https://github.com/fluid-cloudnative/fluid#quick-demo
21 .性能评估与分析 对比场景: 云作业加速的原因分析 • Cold Start: 无任何缓存数据时运行作业 • Fluid+Cold Start: 无任何缓存时运行作业+Fluid弹性扩缩容机制 结论:缓存系统自动扩缩容通过预取数据,减少I/O时间花销,加速训练过程 21
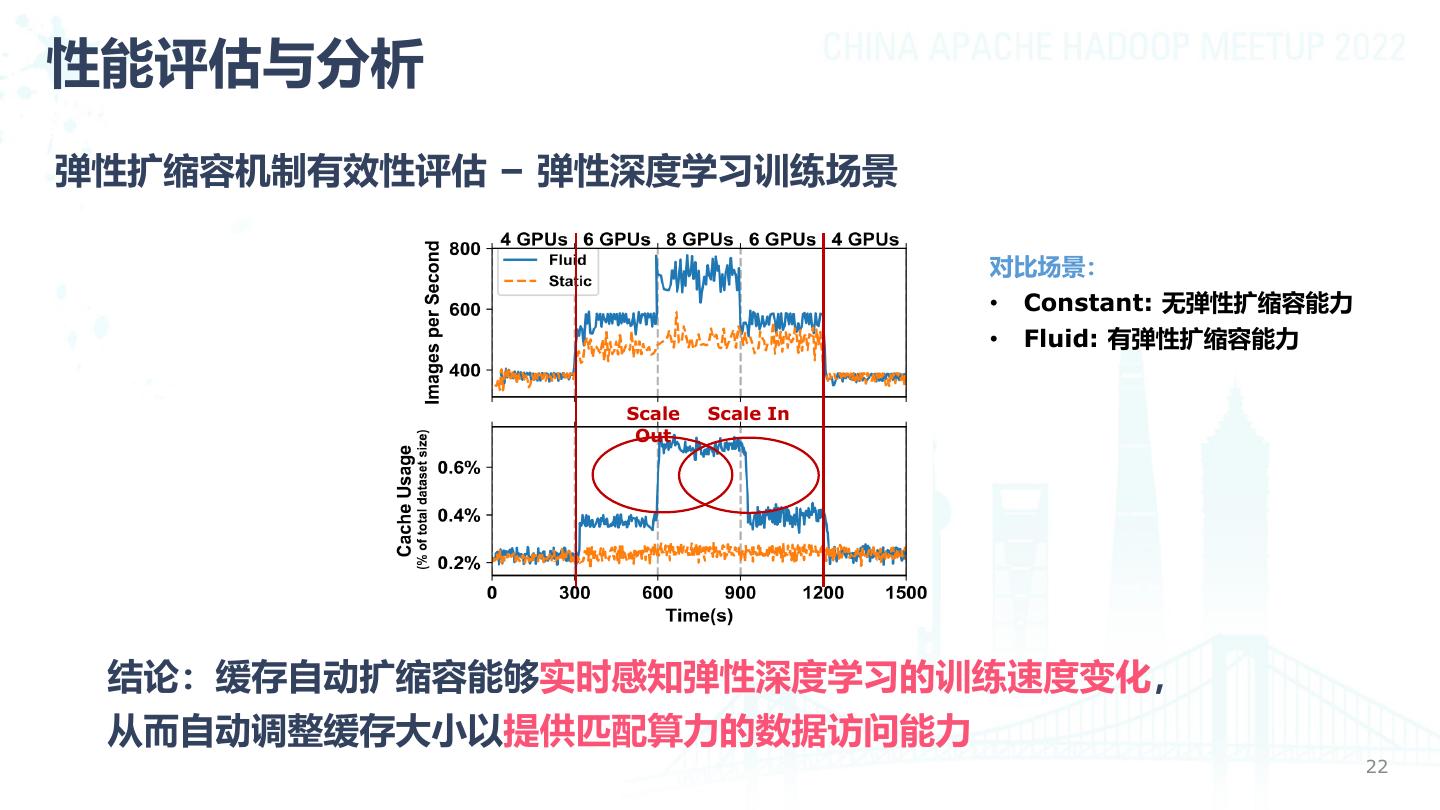
22 .性能评估与分析 弹性扩缩容机制有效性评估 – 弹性深度学习训练场景 对比场景: • Constant: 无弹性扩缩容能力 • Fluid: 有弹性扩缩容能力 Scale Scale In Out 结论:缓存自动扩缩容能够实时感知弹性深度学习的训练速度变化, 从而自动调整缓存大小以提供匹配算力的数据访问能力 22
23 .性能评估与分析 调度策略性能评估 对比对象 • Kubernetes -32% • HiveD: 多租户云原生AI平台调度 器 -38% 评价指标 • Makespan: 作业序列总运行时间 • AvgJCT: 平均作业完成时间 Scheduling Performance on 30-job synthetic trace 结论:Fluid系统能有效降低多作业的整体运行时间(Makespan)和平均作业的完成时间 (AvgJCT) 23
24 .私有云案例: 新浪微博 Background • 业务场景: 微博深度学习平台(多媒体内容理解、CTR 任务优化、推荐系统) • 存算分离架构: Kubernetes GPU Cluster, hundreds of nodes each 4 V100 GPUs • 数据存储: Data is stored on HDFS, 4 TB data in production Problems • 计算存储分离架构数据访问高延时,导致训练慢 • Kubernetes 调度器数据缓存无感知,同一数据源多次运行访问依旧慢 • HDFS 成为数据并发访问的瓶颈点,稳定性挑战大 Benefits • 在多机多卡分布式训练的情况下,可以将模型训练的速度提升 18 倍 • 过去需要 两周才能完成的训练缩减到了 16 个小时 • 减少HDFS压力,提升稳定性,将 训练作业成功率从 37.1%提升至 98.3%
25 .项目/社区发展情况 系统开源情况 • ~82,000 lines of code, written in Go and yaml. • 1359 commits, 1309 PRs, 656 Github topic discussion • 1100+ Github标星关注, 393 forks, 8 releases since Aug. 2020 • https://github.com/fluid-cloudnative/fluid 开源社区发展 • 技术委员会: Currently 5 maintainers • 贡献者分布: 近300位 contributors 来自: https://fluid-cloudnative.github.io/
26 .社区活动 Fluid社区交流钉钉群 Fluid技术微信公众号 (300多人) 每双周四晚上社区定期交流会
27 .Fluid v0.8 新特性 支持 ARM64 架构处理器运行平台 01 • Fluid 的多架构支持 为了支持 Fluid 在多平台的部署,在 v0.8 版本中提供了 ARM64 和 AMD64 两种架构的 Docker Hub 镜像。 Serverless 场景支持优化的持续探索 • Fluid 的 Serverless 离线化任务支持 02 离线任务场景下,当 Pod 的业务容器完成任务并退出后,注入的 Fuse 容器也随之主动退出。 • Fluid 支持的 Serverless Kubernetes 平台上线,以及完全的 Serverless 化支持 将 Fluid 与 Serverless 平台相结合,在业界内提供 Serverless 平台上数据的加速访问能力。
28 .Fluid v0.8 新特性 完善对生产环境灵活性、高可用的支持 • Runtime Controller 的动态开启 无需再在安装时就配置支持的 Runtime 类型,支持实际使用时创建对应的 Runtime,从而实现开箱即用。 03 • Runtime 支持容器网络能力 新版本中不但支持了容器网络,也可以在容器网络环境下识别出在同一个节点上的缓存 Runtime worker 和 FUSE 组件并且对其进行短路读。 • 新版本中实现了内部组件的高可用部署支持 High Availability 对内部 Webhook 和 Controllers 组件的高可用支持。
29 .Presto on Fluid初探 背景介绍 • 得益于容器化带来的高效部署、敏捷迭代,以及云计算在资源成本和弹性扩展方面的 天然优势,以 Kubernetes 为代表的云原生编排框架吸引着越来越多的大数据查询应 用(如Presto)在其上部署和运行。 • 但是Presto在云上部署仍然存在着不小的挑战: – 部署环境复杂 – 手动调整缓存集群的各项参数 – ...... 利用Fluid提供端到端、自动化集群部署、弹性扩缩容等功能简化Presto集群部 署,加速Presto集群运行
3秒后跳转登录页面
去登陆

