展开查看详情
2 .更易用、更强劲的大数据分析平台
- Kylin 5.0 社区路线一览
俞霄翔
Apache Kylin PMC member
�
3 .Agenda
• 今天的 Apache Kylin
• 下一代 Kylin 的开发路线介绍
• 开源时间预告
�
5 .Apache Kylin 是什么
Analytical Data Warehouse For Big Data
Apache Kylin™ 是一个开源的分布式数据仓库分析引擎,为 Hadoop 等大型分布式分析平台之上的超大规
模数据集通过标准 SQL 查询及多维分析 ( OLAP ) 功能,提供亚秒级的交互式分析能力。
�
6 .Apache Kylin 的基本原理
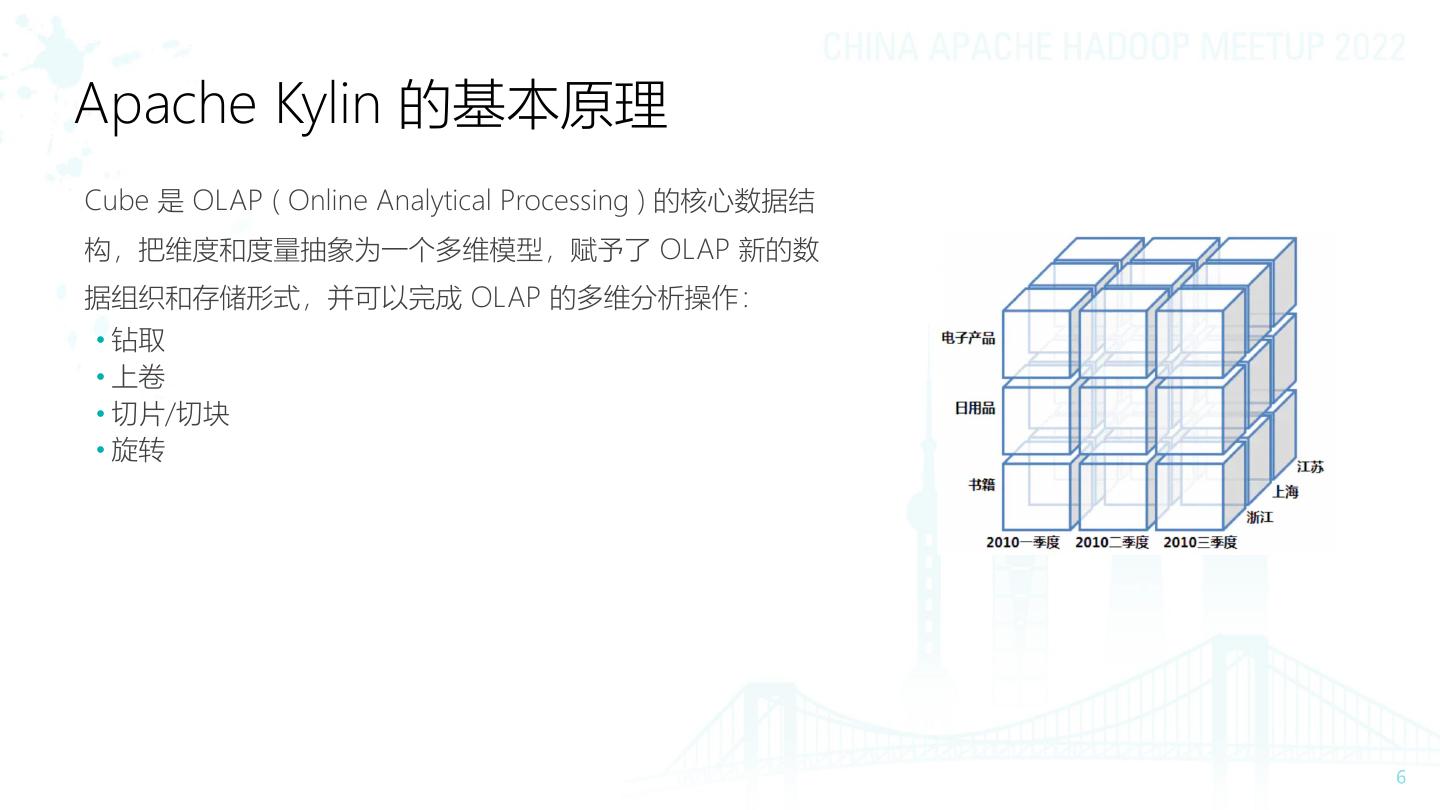
Cube 是 OLAP ( Online Analytical Processing ) 的核心数据结
构,把维度和度量抽象为一个多维模型,赋予了 OLAP 新的数
据组织和存储形式,并可以完成 OLAP 的多维分析操作:
• 钻取
• 上卷
• 切片/切块
• 旋转
�
7 .Apache Kylin 的基本原理
Cuboid:一种维度组合
Cube:所有的维度组合
每个 Cuboid 可以从上层 Cuboid 聚合计算而来
Kylin 会选择满足条件的最小的 Cuboid 回答查询
�
8 .Apache Kylin 的基本原理
Sort Sort
Agg Filter <a,b,c>
有预计算,基于 Cube 出结果, <a,b>
Filter
I/O 少,计算少,延迟低
Cube <a,c>
Join 预聚合数据 <a>
时间复杂度 O(1)
<c>
Table Table
时间复杂度 O(N)
�
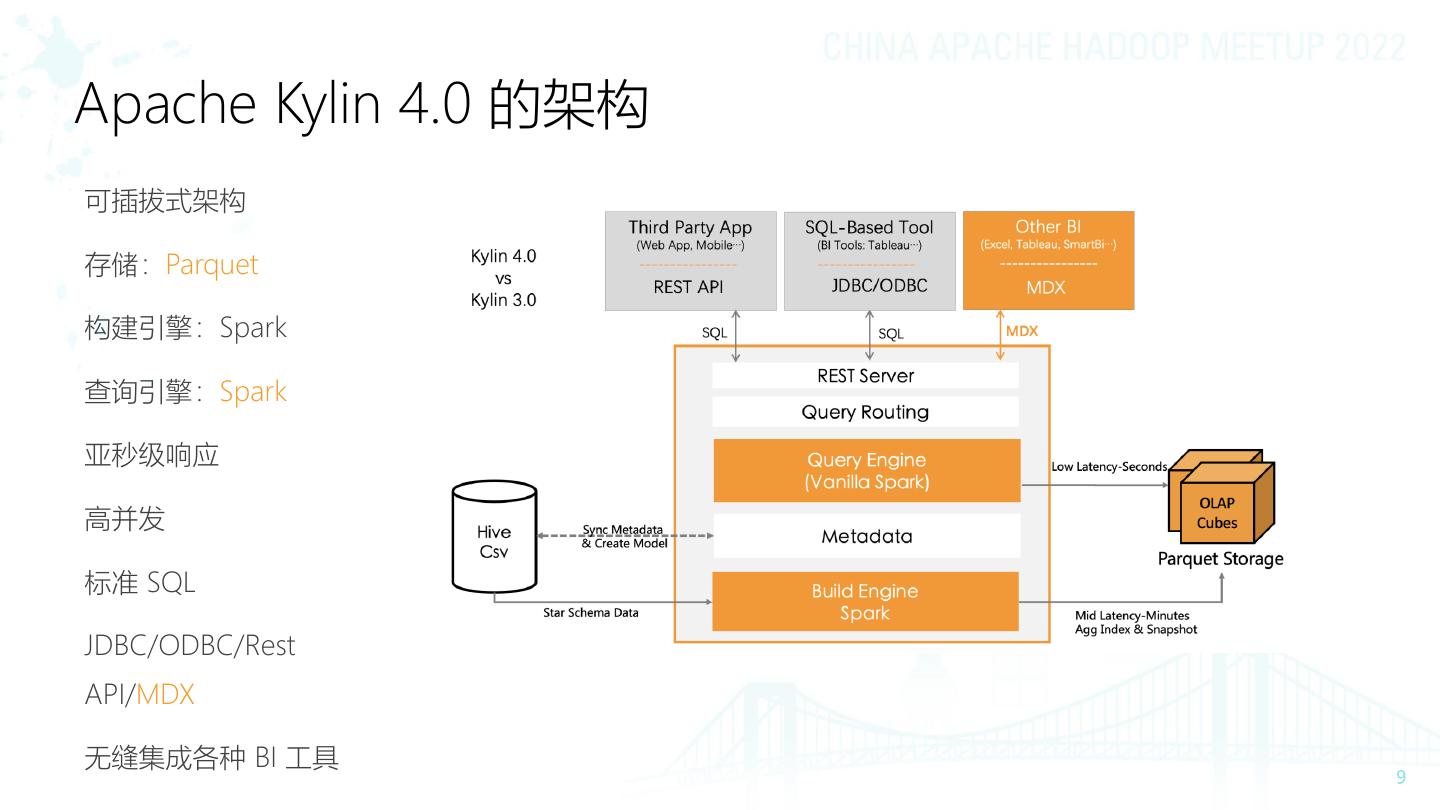
9 .Apache Kylin 4.0 的架构
可插拔式架构
存储:Parquet
构建引擎:Spark
查询引擎:Spark
亚秒级响应
高并发
标准 SQL
JDBC/ODBC/Rest
API/MDX
无缝集成各种 BI 工具
�
11 .如何在 Excel 对大数据进行分析
MDX for Kylin 是一个支持 Apache Kylin 的 MDX 计算引擎,支持对接
Excel、Power BI、Tableau
爱的番茄的业务场景中,MDX for Kylin 使得运营人员可以使用 Excel 进
行自助数据分析,助力中小企业减少大量研发成本
• Before:运营同学熟悉 Excel,但是不熟悉 SQL,也不了解字段的业
务含义,只能求助数据开发同学写 SQL ,以跨团队的方式完成取数
过程
• Now:数据开发同学基于大家沟通的共识,构建好完备的数据集,定
义好运营同学看得懂的维度和指标,然后运营可以轻松地通过 Excel
完成自助取数和多维数据分析,不再需要沟通需求和等待
• 支持大量典型业务查询场景,例如 YTD 等
• 使用体验接近 SSAS
�
13 .Kylin 4.0 的局限性
维度数量有上限,最多支持 63 个维度
模型变更限制多,不能随意添加维度和度量
Cube 元数据限制多,无法灵活管理索引,例如无法添加或者刷新部分索引
查询性能仍有提升空间,没有利用向量加速、指令级优化等技术
长期使用后元数据存储膨胀,造成元数据读取性能下降
当前的元数据同步机制下,偶尔出现集群节点元数据不一致的情况
�
14 .Kylin 5.0 社区路线一览
核心功能升级
• 元数据重新设计 • Gluten
• 元数据拆分和结 • 支持可计算列 • Datafusion
构化 • 支持模型灵活变
更
• 增加索引类型
元数据升级 计算引擎升级
�
15 .Kylin 5.0 社区路线一览
统一灵活、高性能、可扩展、云原生的大数
据分析平台
对接多种数据源(Hive/JDBC/Kafka)
支持多种查询接口(SQL & MDX/DAX)
支持多种计算引擎(Vanilla Spark vs Native
Spark )
面向业务的指标管理平台的底座
支持部署 K8s
�
17 .当前元数据的弊端
建模过程操作冗长,用户体验不佳
模型修改会造成大量计算浪费
Table 元数发生改变必须重新建模,重新构建
索引管理不灵活
元数据管理较为混乱
�
19 .元数据 Schema 改造升级
合并 Model 和 CubeDesc
新增 Index 和 Layout
引入 IndexPlan
改造 CubeInstance 为 DataFlow
�
20 .元数据审计和查询历史
新增元数据审计日志,可以用于元数据操作审计和元数据同步机制
新增查询历史日志,可以用于索引优化
�
21 .元数据同步机制
Epoch Store 记录了谁可以处理一
个项目内部的事务
Job Server 时刻尝试续约已有
Epoch,并且争夺尚未有合法
Owner 的 Epoch
�
22 .元数据同步机制
元数据更新操作只发生在取得
epoch 的 Job Server
Standby 节点通过 Replay Audit
Log方式获取元数据更新
�
23 .元数据改造升级带来的收益
模型管理和索引管理的分离
更加精细、灵活的索引管理:索引可以有多种 Layout
突破维度数量限制
支持多种类型的索引
支持 Schema Change
支持 可计算列
�
24 .全新的前端交互
前端技术栈升级到 Vue.js
优化用户操作,通过画布完成建模
页面元素现代化
�
26 .元数据改造升级(Table Index)
明细查询一直是 Kylin 的短板
通过物化 Join 加速明细查询
可以根据查询语句,通过 ShardBy 和 SortBy 来优
化性能,从而可以回答一些高基数列的过滤的查询
�
27 .元数据改造升级(Computed Column)
通过在模型上定义表达式,从而支持轻量 ETL
可以把新的表达式当做普通的列,基于表达式定义新的维度
和度量
�
28 .灵活的索引
支持明细索引和聚合索引
只构建部分索引构建的能力
查看每个索引的统计数据(Hit count/storage)
每个索引可以有自己的 Layout(ShardBy Key,SortBy Columns)
索引管理策略的可扩展能力,方便开发基于成本的索引优化器
�