





















































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 视频嵌入链接 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
3.范文臣-What's new in Apache Spark 3.2 & 3.3
范文臣,Databricks 开源组技术主管,Apache Spark PMC member,Spark社区最活跃的贡献者之一。从2013年开始参与Spark的研发,2015年加入Databricks,目前主要负责Spark Core/SQL 的设计开发和开源社区管理。
介绍Spark新版本的新特性和功能改进
展开查看详情
1 .Deep Dive into the New Features of Apache Spark 3.2 and 3.3 Wenchen Fan cloud-fan © 2021 Databricks Inc. — All rights reserved 1
2 . Award Growth Community Updates © 2021 Databricks Inc. — All rights reserved 2
3 .2022 ACM SIGMOD Systems Award “Recognize system with significant impact on the theory and practice of large scale data systems” “Apache Spark is an innovative, widely- used, open-source, unified data processing system encompassing relational, streaming, and machine-learning workloads.”
4 . 45 Millions Monthly downloads (maven and PyPI) © 2021 Databricks Inc. — All rights reserved 4
5 . 2020 2022 Developer Developer Survey Survey Salary increase based on frameworks known Top paying technologies Over global average salary ($54,491 USD) Backbone.js +48.7% Apache Spark $87,948 Cocoa +34.6% Apache Kafka $83,182 Ruby on Rails +29.6% Hadoop $76,000 Spark +29.4% Tidyverse $74,651 Struts +19.3% .NET $70,920 Hugging Face .NETCore +10.7% Transformers $70,920 React +8.7% Uno Platforms $70,385 ASP +7.4% Pandas $67,409 Vue.js +6.3% NumPy $66,600 Angular JS +3.7% Torch/PyTorch $66,480 JSF +2.2% Spring +1.2% Django +1.0% ExpressJS +0.1%
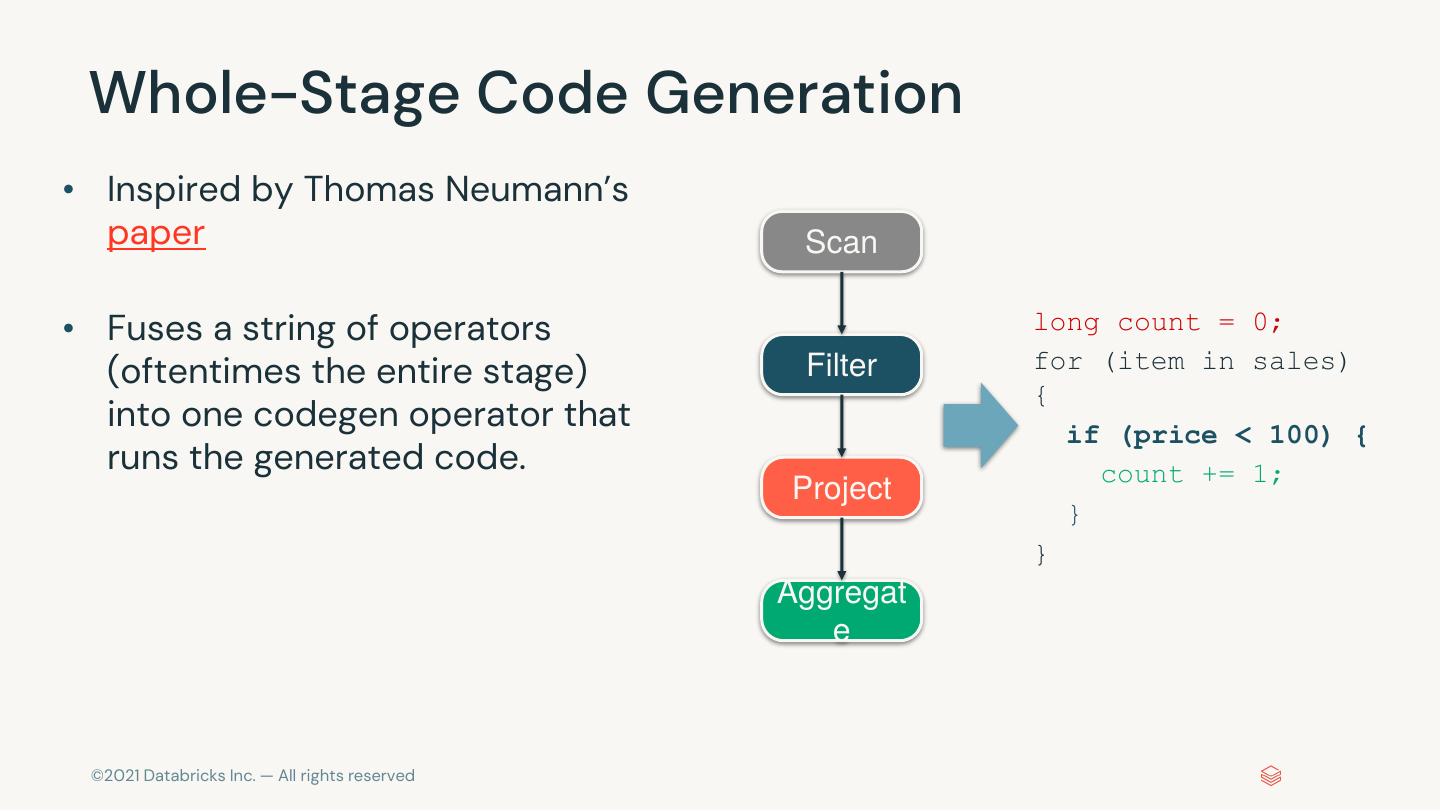
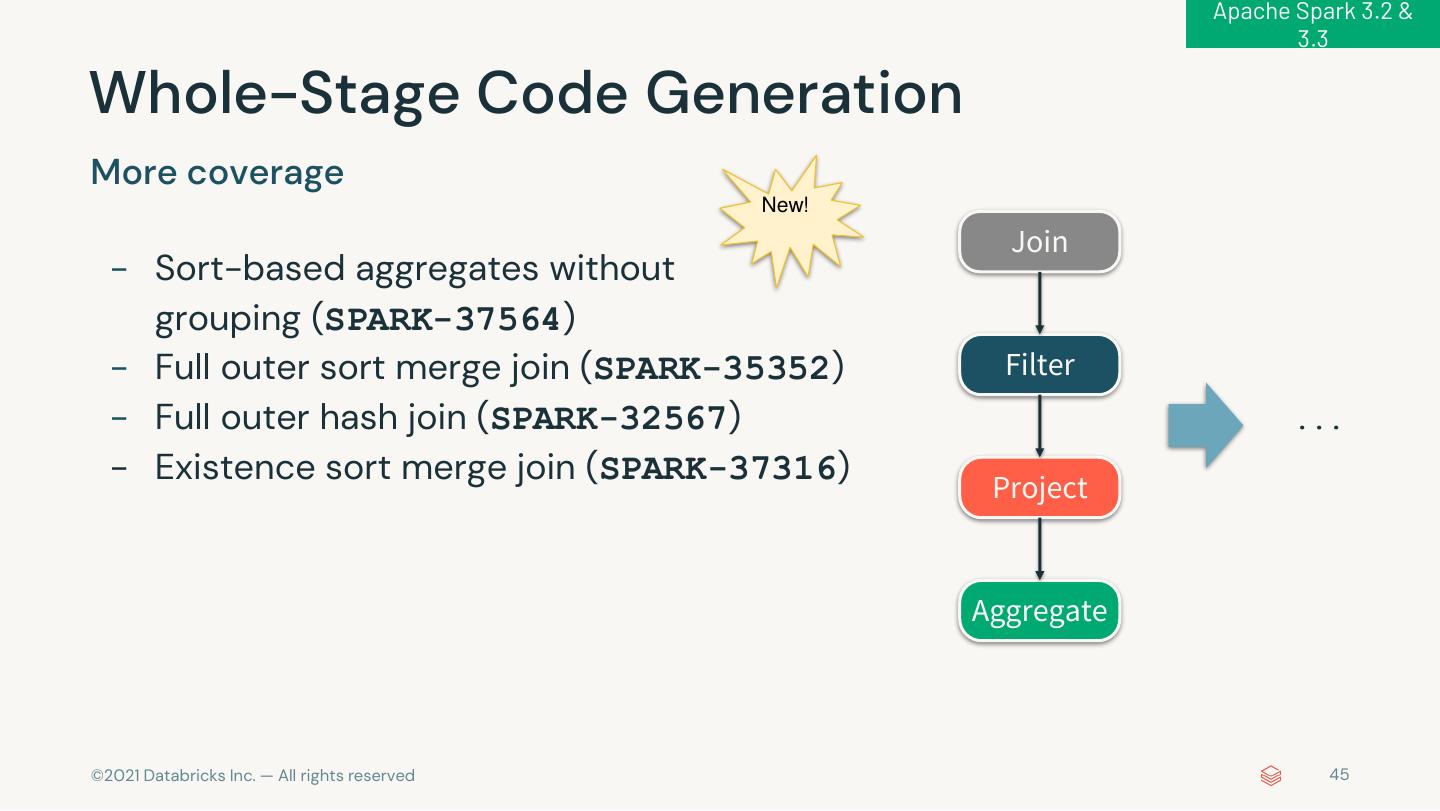
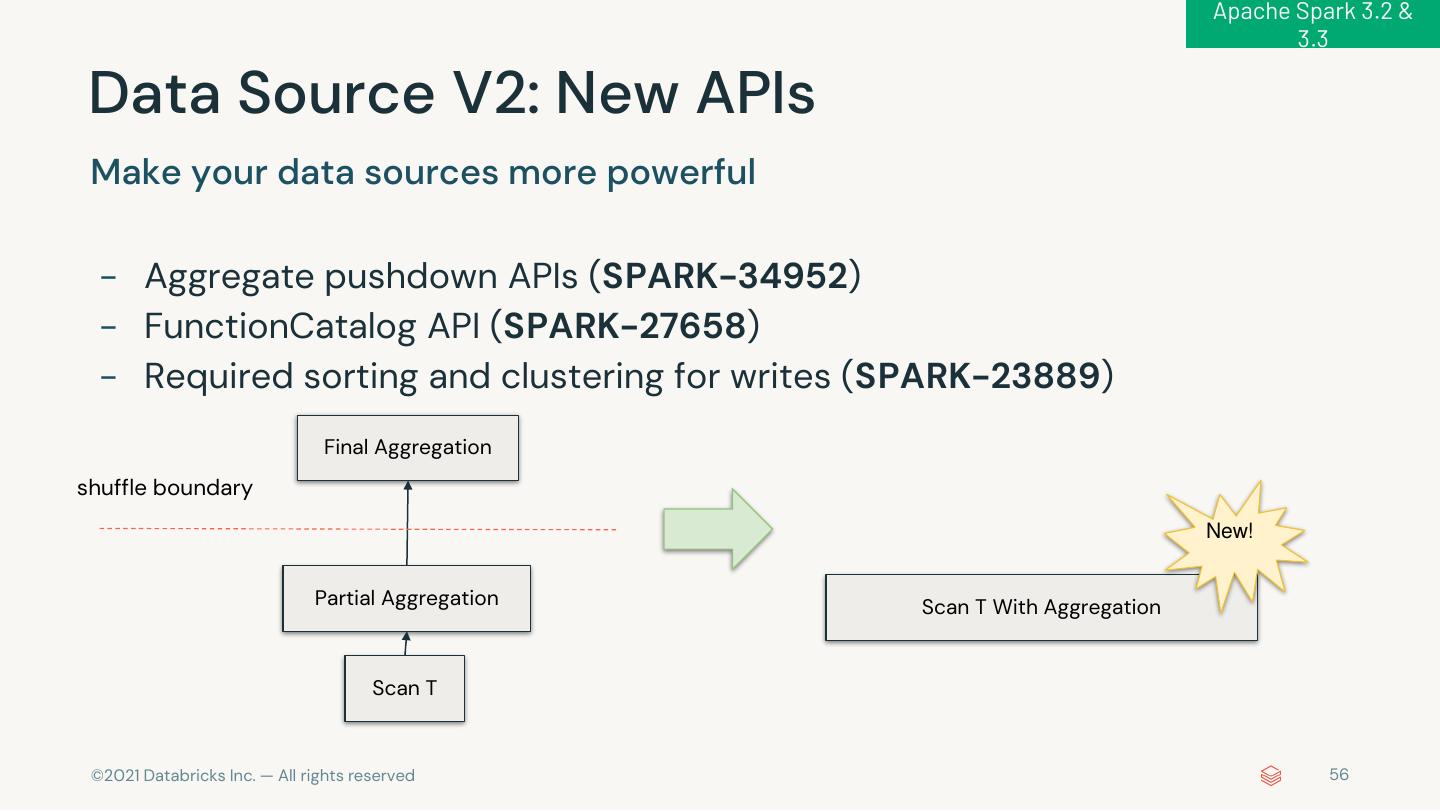
6 . 1,600+ JIRAs in Apache Spark 3.3 Feature Performanc s e ANSI Trigger Built-in Hidden File Runtime Whole-stage QO/AQE Customized Enhancements AvailableNow Functions Metadata Filtering codegen Enhancements K8S Scheduler Pytho Usabilit n y Python/Pandas timedelta pandas API Error SQL Configs Python String Inline Type mapInArrow UDF Profiler Support Coverage Message in Spark UI Formatter Hints Improvement Extension Mor s s e Parquet DSV2 Hive Bucket Apple New Doc for DSV2 APIs Java 17 Log4J 2 Vectorized Reader Pushdown Writing Silicon SparkR © 2021 Databricks Inc. — All rights reserved
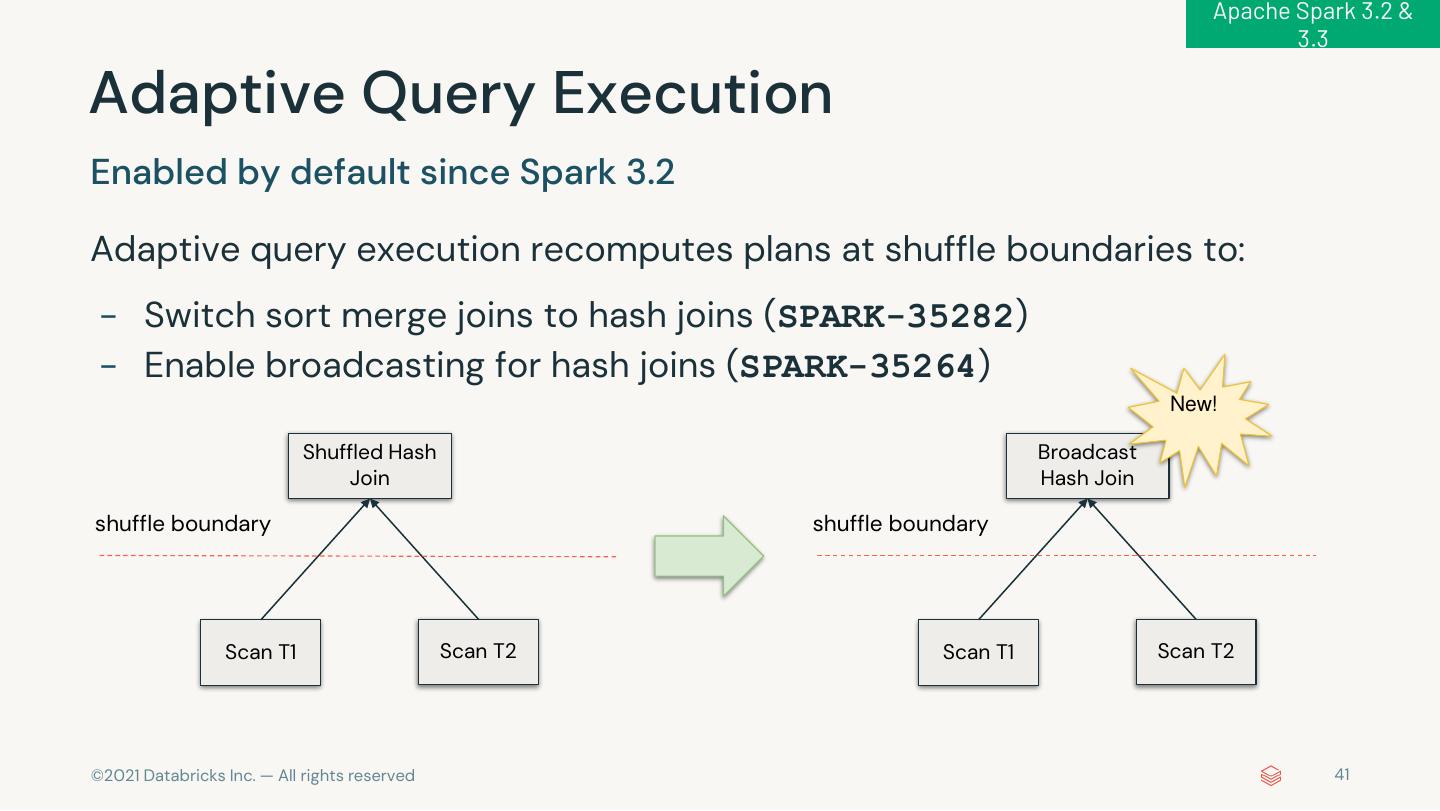
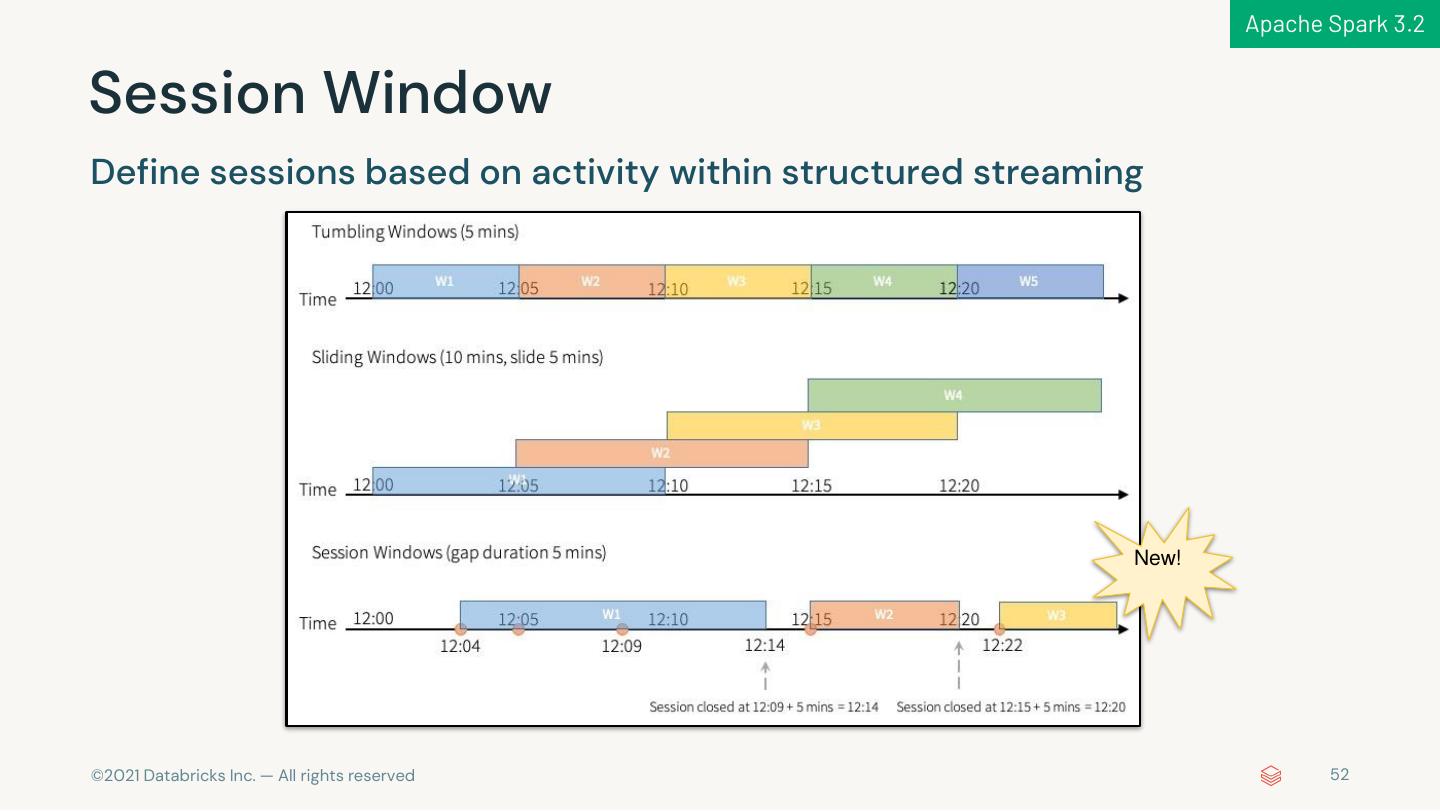
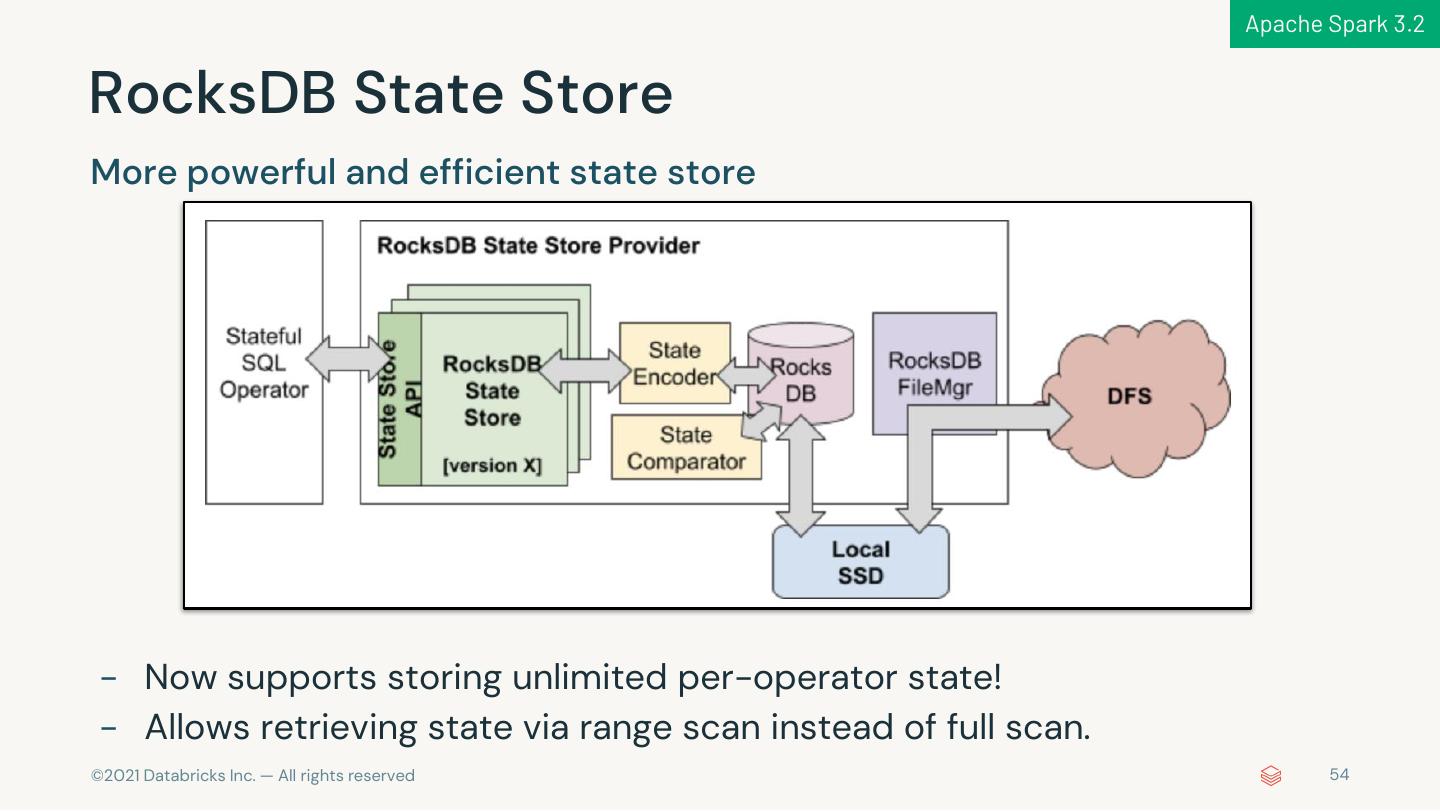
7 . 1,700+ JIRAs in Apache Spark 3.2 ANSI SQL Extension Compliance s ANSI Mode Implicit Type DSV2 API Parquet 1.12 Complex Type Lateral Join Interval Type DSV2 Metrics (Column Index) Support in ORC GA Cast Enhancements Pytho Streamin n g Visualization Pythonic Richer RocksDB Session State Store pandas APIs Kafka 2.8 and Plotting Error Input/Output State Store Window APIs Handling Performanc Mor e e Compiler Latency Adaptive Whole-stage Explicit Error Push-based Java 17 Scala 2.13 AQE + DPP Reduction Optimization codegen Classes Shuffle Beta Beta GA © 2021 Databricks Inc. — All rights reserved
8 . Apache Spark 3.2 2021: pandas APIs on Spark © 2021 Databricks Inc. — All rights reserved
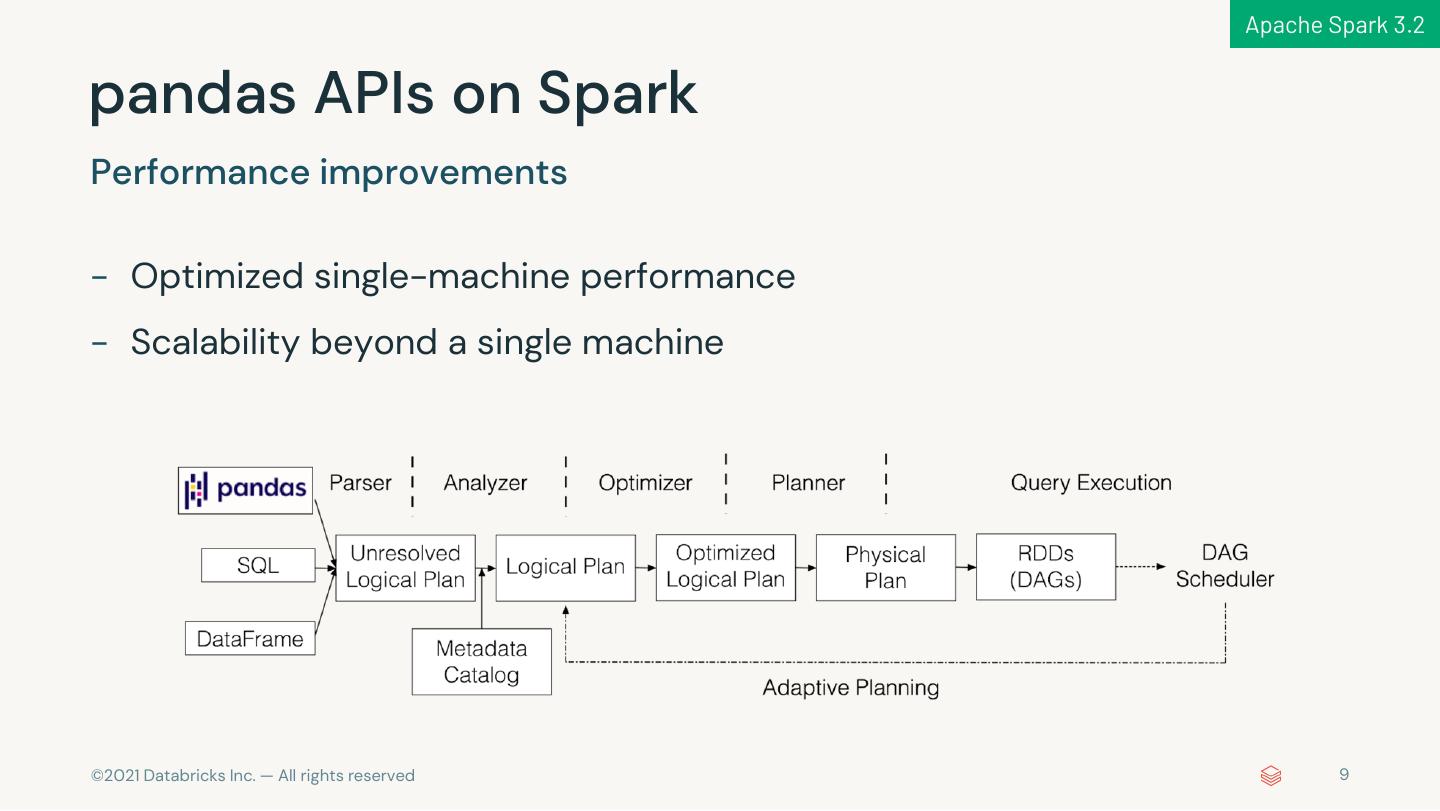
9 . Apache Spark 3.2 pandas APIs on Spark Performance improvements - Optimized single-machine performance - Scalability beyond a single machine © 2021 Databricks Inc. — All rights reserved 9
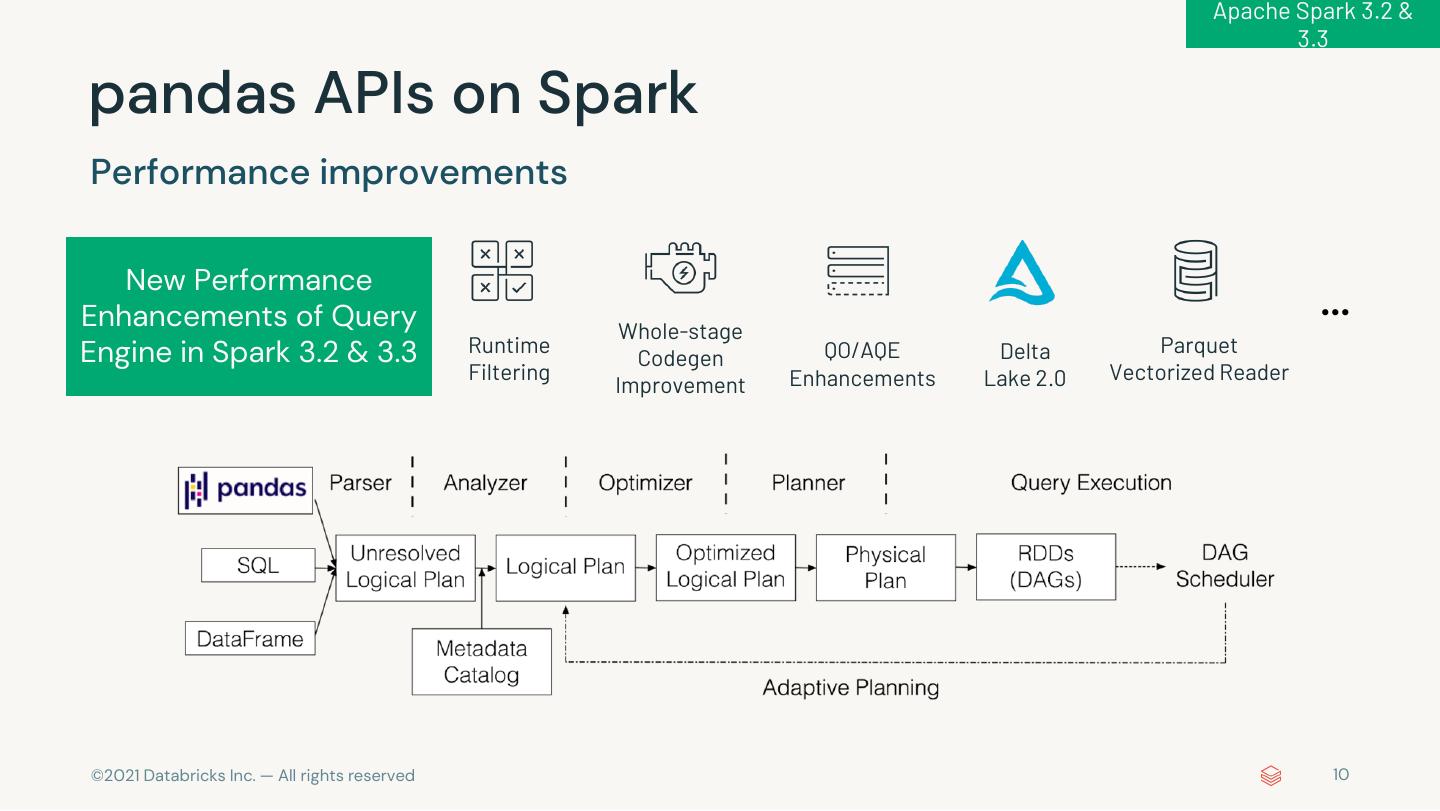
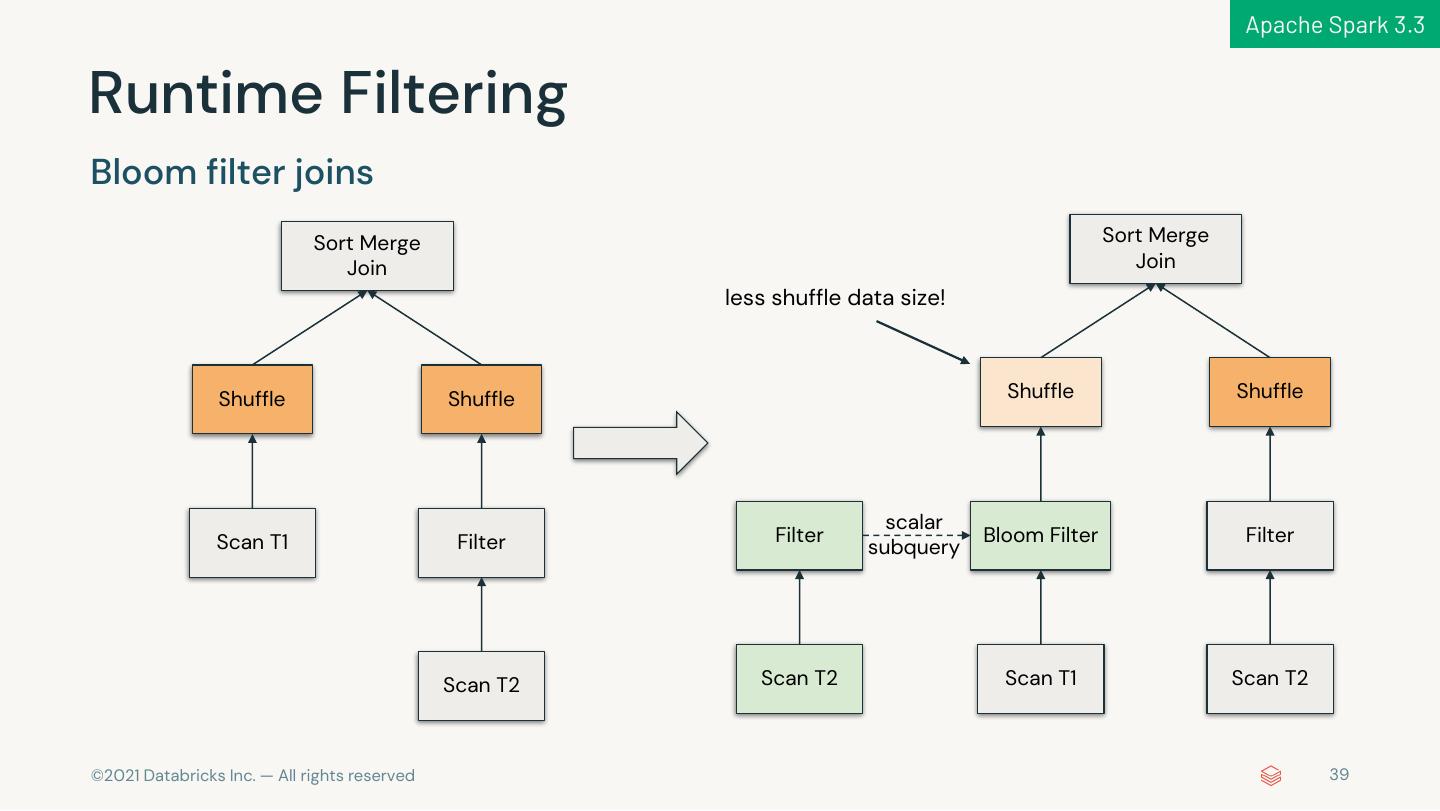
10 . Apache Spark 3.2 & 3.3 pandas APIs on Spark Performance improvements New Performance Enhancements of Query Whole-stage … Engine in Spark 3.2 & 3.3 Runtime QO/AQE Delta Parquet Codegen Filtering Enhancements Lake 2.0 Vectorized Reader Improvement © 2021 Databricks Inc. — All rights reserved 10
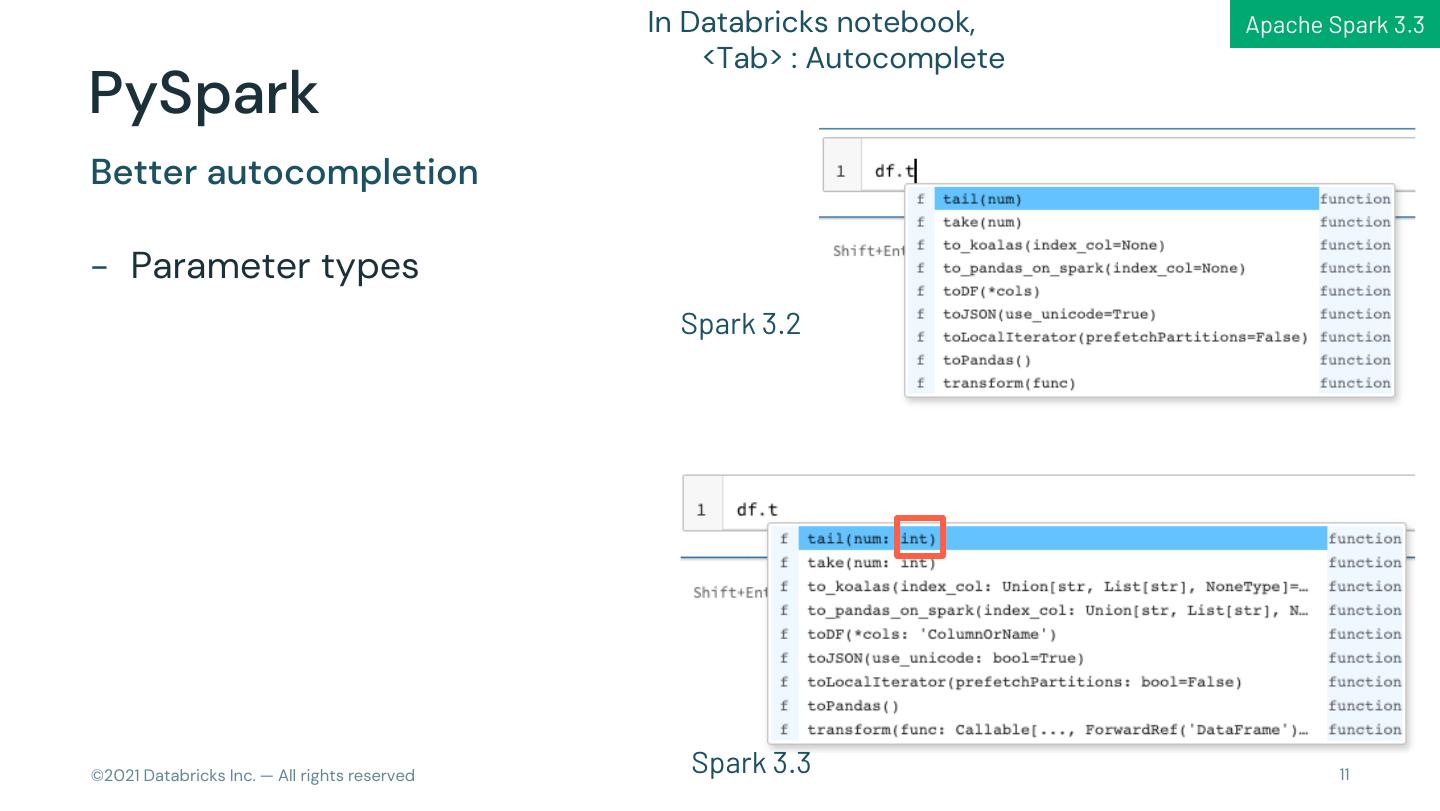
11 . In Databricks notebook, Apache Spark 3.3 <Tab> : Autocomplete PySpark Better autocompletion - Parameter types Spark 3.2 © 2021 Databricks Inc. — All rights reserved Spark 3.3 11
12 . In Databricks notebook, Apache Spark 3.3 <Shift> + <Tab> : Docstring PySpark Better documentation - Parameter types Spark 3.2 - Return types Spark 3.3 © 2021 Databricks Inc. — All rights reserved 12
13 .ANSI Mode Lateral Implicit Type GA Subqueries Cast Error Class Interval Type ANSI SQL Compliance © 2021 Databricks Inc. — All rights reserved 13
14 . Apache Spark 3.2 Lateral Subqueries To cross-reference the preceding from_items in the same FROM clause. Such a construct is called a correlated or dependent join. A correlated join cannot be a RIGHT OUTER JOIN or a FULL OUTER JOIN. SELECT * FROM tab1, LATERAL ( SELECT * FROM tab2 WHERE tab1.id = tab2.id ) © 2021 Databricks Inc. — All rights reserved
15 . Apache Spark 3.2 Lateral Subqueries Also, make your queries simpler and more efficient, like CTE Before After SELECT SELECT a1 + a2 + b3 + b4, sumAB, sumA * sumB, udf1(sumAB) (a1 + a2) * (b3 + b4), FROM tab1, LATERAL (SELECT udf1(a1 + a2 + b3 + b4) (a1 + a2) as sumA), FROM tab1 LATERAL (SELECT (b3 + b4) as sumB), LATERAL (SELECT (sumA + sumB) as sumAB) © 2021 Databricks Inc. — All rights reserved
16 . Apache Spark 3.3 Interval Type Represents intervals of time either on a scale of seconds or months ● day-time interval SELECT INTERVAL -'200:13:50.3' HOUR TO SECOND; SELECT CAST('11 23:4:0' AS INTERVAL DAY TO SECOND); ● year-month interval SELECT INTERVAL '100-00' YEAR TO MONTH; SELECT INTERVAL '-3600' MONTH; ● Examples SELECT * FROM tab WHERE date1 - date2 > INTERVAL 2 DAYS SELECT (now() - INTERVAL '3 hours 20 minutes' - INTERVAL '1 year') © 2021 Databricks Inc. — All rights reserved
17 . Apache Spark 3.3 ANSI Mode spark.sql.ansi.enabled Why it matters? (default: false) Follows the SQL ● Data quality and application sanity standard in how it deals with certain ● Reduce lock-in/improved portability arithmetic operations and type conversions, similar to most ● Ease of integration with BI and external tools databases and data warehouses. Following this standard promotes better data quality, integrity, and portability. 17 © 2021 Databricks Inc. — All rights reserved
18 .Operator Description Example ANSI_MODE ANSI_MODE = Apache Spark 3.3 = true false dividend / Returns dividend divided by 1/0 Runtime error NULL divisor divisor. - expr Returns the negated value of expr. -(-128y) Runtime error -128y (Overflow) Returns the subtraction of expr2 expr1 - expr2 -128y - 1y Runtime error 127y (Overflow) from expr1. Returns the sum of expr1 and expr1 + expr2 127y + 1y Runtime error -128y (Overflow) expr2. What’s changing? dividend % Returns the remainder after divisor dividend / divisor. 1%0 Runtime error NULL - Operators multiplier * Returns multiplier multiplied by 100y * Runtime error 16y (Overflow) multiplicand multiplicand. 100y Returns the element of an Invalid arrayExpr[index] Runtime error NULL arrayExpr at index. array index Returns the value of mapExpr for Invalid map mapExpr[key] Runtime error NULL key. key divisor div Returns the integral part of the 18 © 2021 Databricks Inc. — All rights reserved 1 div 0 Runtime error NULL dividend division of divisor by dividend.
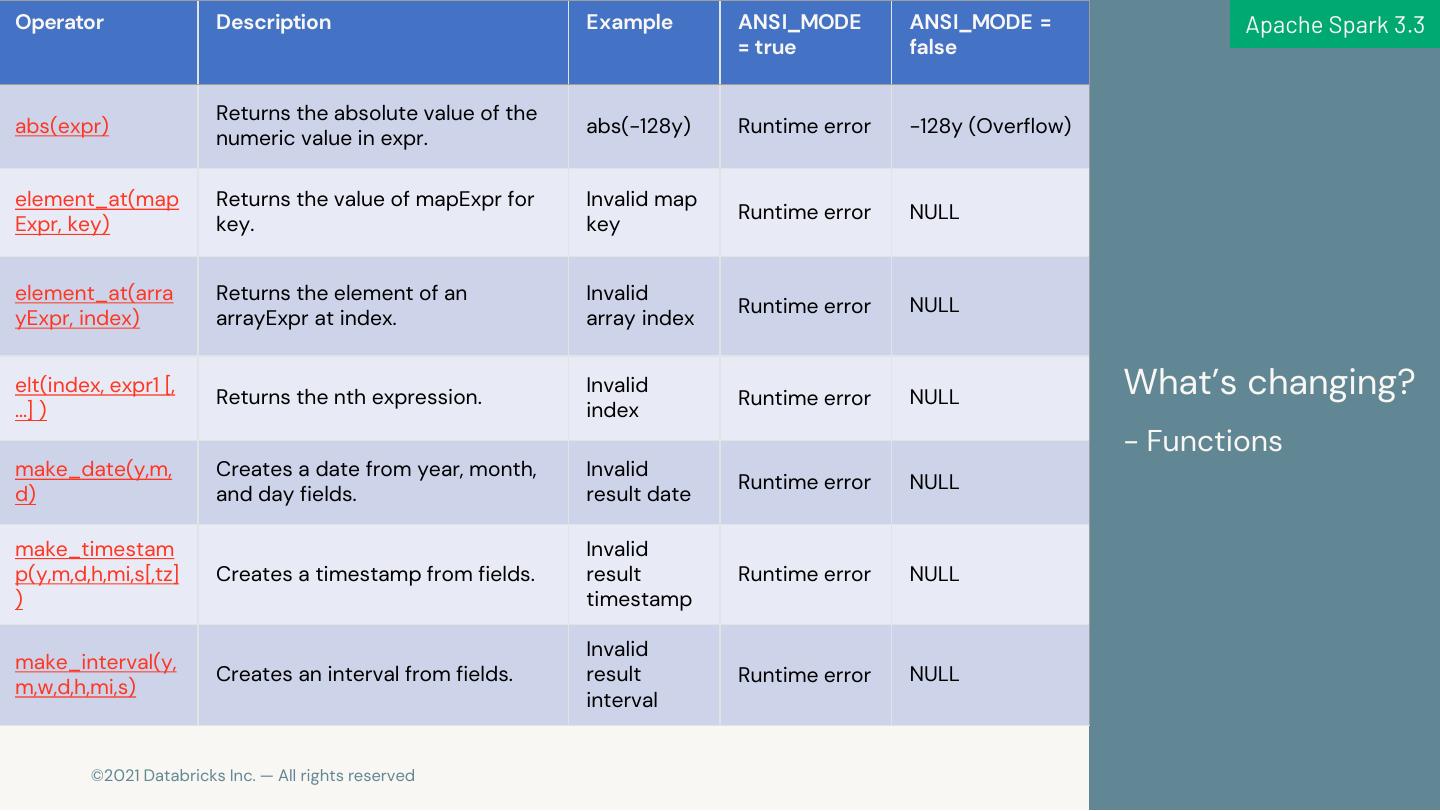
19 .Operator Description Example ANSI_MODE ANSI_MODE = Apache Spark 3.3 = true false Returns the absolute value of the abs(expr) abs(-128y) Runtime error -128y (Overflow) numeric value in expr. element_at(map Returns the value of mapExpr for Invalid map Runtime error NULL Expr, key) key. key element_at(arra Returns the element of an Invalid Runtime error NULL yExpr, index) arrayExpr at index. array index elt(index, expr1 [, Returns the nth expression. Invalid Runtime error NULL What’s changing? …] ) index - Functions make_date(y,m, Creates a date from year, month, Invalid Runtime error NULL d) and day fields. result date make_timestam Invalid p(y,m,d,h,mi,s[,tz] Creates a timestamp from fields. result Runtime error NULL ) timestamp Invalid make_interval(y, Creates an interval from fields. result Runtime error NULL m,w,d,h,mi,s) interval 19 © 2021 Databricks Inc. — All rights reserved
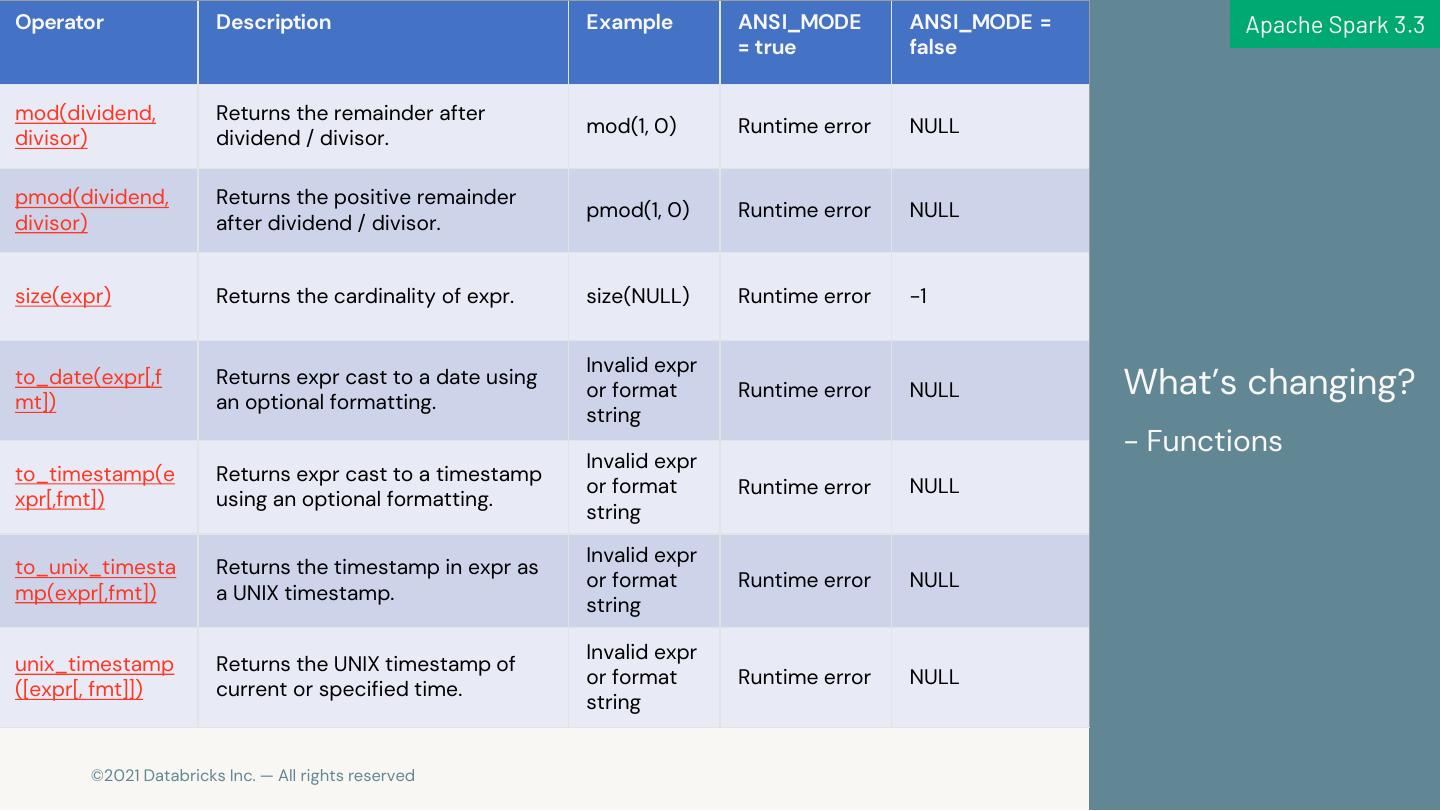
20 .Operator Description Example ANSI_MODE ANSI_MODE = Apache Spark 3.3 = true false mod(dividend, Returns the remainder after mod(1, 0) Runtime error NULL divisor) dividend / divisor. pmod(dividend, Returns the positive remainder pmod(1, 0) Runtime error NULL divisor) after dividend / divisor. size(expr) Returns the cardinality of expr. size(NULL) Runtime error -1 Invalid expr to_date(expr[,f mt]) Returns expr cast to a date using an optional formatting. or format Runtime error NULL What’s changing? string - Functions Invalid expr to_timestamp(e Returns expr cast to a timestamp or format Runtime error NULL xpr[,fmt]) using an optional formatting. string Invalid expr to_unix_timesta Returns the timestamp in expr as or format Runtime error NULL mp(expr[,fmt]) a UNIX timestamp. string Invalid expr unix_timestamp Returns the UNIX timestamp of or format Runtime error NULL ([expr[, fmt]]) current or specified time. string 20 © 2021 Databricks Inc. — All rights reserved
21 .Source type Target type Example ANSI_MODE = true ANSI_MODE = false Apache Spark 3.3 1970-01-01 Boolean Timestamp cast(TRUE AS TIMESTAMP) Compile time error 00:00:00.000001 UTC cast(DATE'2001-08-09' Date Boolean Compile time error NULL AS BOOLEAN) cast(TIMESTAMP'1970-01- Timestamp Boolean 01 00:00:00Z' AS Compile time error FALSE BOOLEAN) Integral binary Binary cast(15 AS BINARY) Compile time error numeric representation What’s changing? - Compile-time casting rules 21 © 2021 Databricks Inc. — All rights reserved
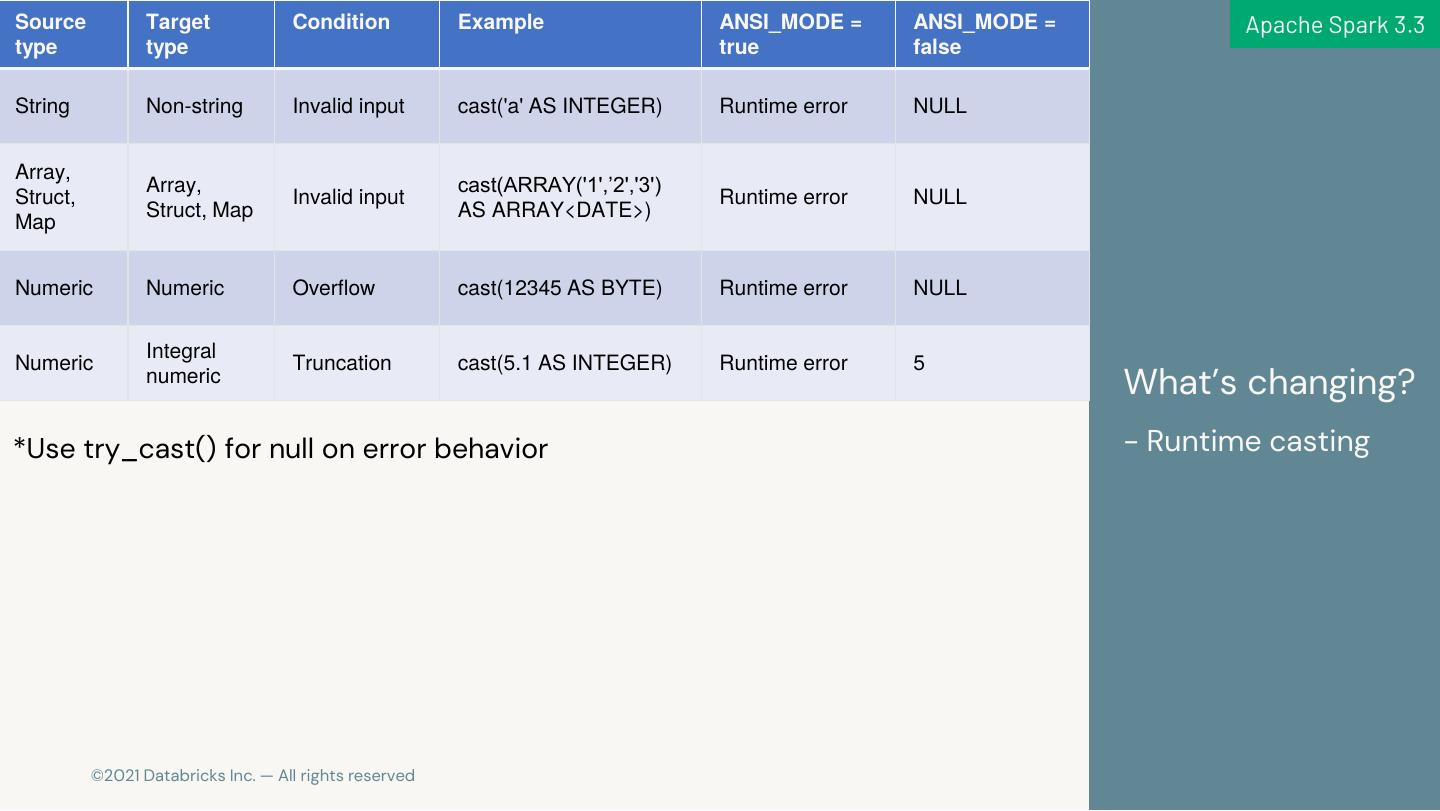
22 .Source Target Condition Example ANSI_MODE = ANSI_MODE = Apache Spark 3.3 type type true false String Non-string Invalid input cast('a' AS INTEGER) Runtime error NULL Array, Array, cast(ARRAY('1',’2','3') Struct, Invalid input Runtime error NULL Struct, Map AS ARRAY<DATE>) Map Numeric Numeric Overflow cast(12345 AS BYTE) Runtime error NULL Integral Numeric Truncation cast(5.1 AS INTEGER) Runtime error 5 numeric What’s changing? *Use try_cast() for null on error behavior - Runtime casting 22 © 2021 Databricks Inc. — All rights reserved
23 . Apache Spark 3.3 What’s changing Casting Rules - implicit type coercion SELECT 5 = '5.1'; ● Non ANSI mode: true ● ANSI mode: throw SparkNumberFormatException: [CAST_INVALID_INPUT] The value '5.1' of the type "STRING" cannot be cast to "BIGINT" because it is malformed. Correct the value as per the syntax, or change its target type. Use `try_cast` to tolerate malformed input and return NULL instead. If necessary set "spark.sql.ansi.enabled" to "false" to bypass this error. == SQL(line 1, position 8) == select 5 = '5.1' 23 ^^^^^^^^^ © 2021 Databricks Inc. — All rights reserved
24 . Apache Spark 3.3 ANSI Mode © 2021 Databricks Inc. — All rights reserved
25 . In Development Error Framework Actionable, stable, documented A structured protocol and API to pass error structures and retrieve formatted output. Instead of a Java exception dump. • Better error context exposed to users in common runtime cases • Error Message Docs • Example: DIVIDE_BY_ZERO © 2021 Databricks Inc. — All rights reserved 25
26 . In Development What happened? © 2021 Databricks Inc. — All rights reserved 26
27 . In Development How can I fix it? © 2021 Databricks Inc. — All rights reserved 27
28 . In Development © 2021 Databricks Inc. — All rights reserved 28
29 . Java 17 Scala 2.13 Log4J 2 Apple Silicon Beta Beta New Website for New Doc for Docker Image Spark SparkR Documentation and Environments © 2021 Databricks Inc. — All rights reserved 29
3秒后跳转登录页面
去登陆

