



















- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 视频嵌入链接 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板

基于NVIDIA Triton Inference Server端到端部署LLM serving-卢翔龙
基于NVIDIA Triton Inference Server端到端部署LLM serving-卢翔龙
基于NVIDIA Triton Inference Server端到端部署LLM serving-卢翔龙

卢翔龙-NVIDIA资深解决方案架构师
NVIDIA资深解决方案架构师, 本科毕业于华中科技大学,硕士毕业于美国亚利桑那州立大学。负责为消费互联网行业提供GPU计算加速解决方案。专注技术方向包括Triton Inference Server, TensorRT模型推理加速,以及LLM inference优化等。
分享介绍:
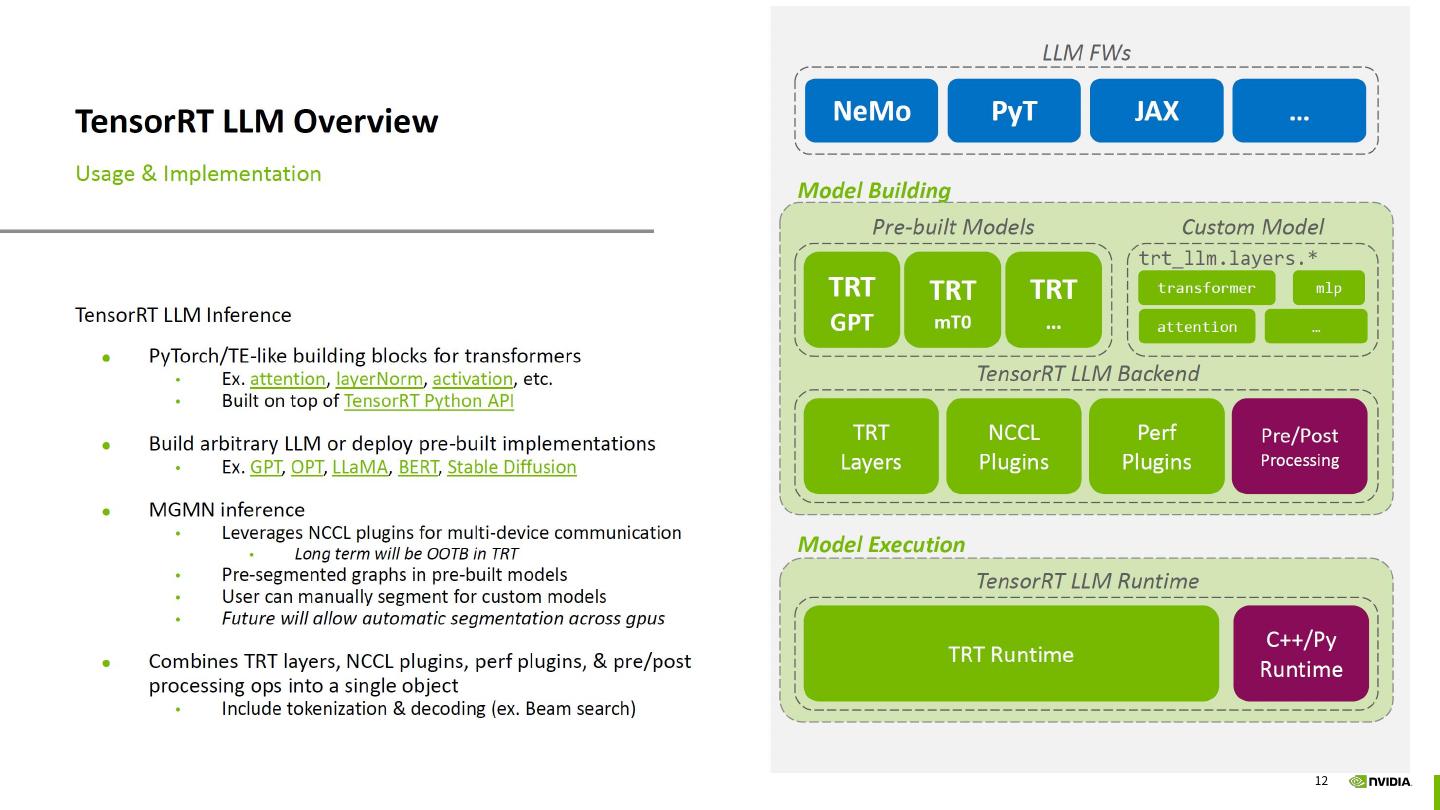
介绍NVIDIA大型语言模型(LLM)推理加速库TensorRT-LLM的任务调度方案in-flight batching的基础原理;并分享基于NVIDIA Triton Inference Server端到端部署LLM的完整解决方案。
展开查看详情
1 .基于NVIDIA Triton Inference Server 端 到端部署LLM Serving 卢翔龙 – 英伟达资深解决方案架构师 1
2 . Agenda • Serving Basics and In-flight Batching Mechanism • Triton TensorRT-LLM Backend • End to End Serving Practice 2
3 .Serving Basics and In-flight Batching Mechanism 3
4 . Triton Inference Server Open-source inference serving software for fast, scalable, simplified inference serving Any Framework Any Query Type Any Platform DevOps/MLOps Ready High Performance Optimized for Real Time X86 CPU | Arm CPU | Microservice in Kubernetes, Multiple DL/ML Optimized for High and Batch Requests NVIDIA GPUs | MIG KServe Frameworks e.g., GPU/CPU Utilization, TensorFlow, PyTorch, Throughput & Low Latency Audio & Video Streaming Linux | Windows | Available Across All Major TensorRT, XGBoost, ONNX, Virtualization Cloud AI Platforms Python & More Model Ensembles Public Cloud, Data Center Integration with major Multi-GPU Multi-Node and Edge/Embedded MLOPS solutions Inference for Large Language Models (Jetson) Large scale Model Orchestration 4
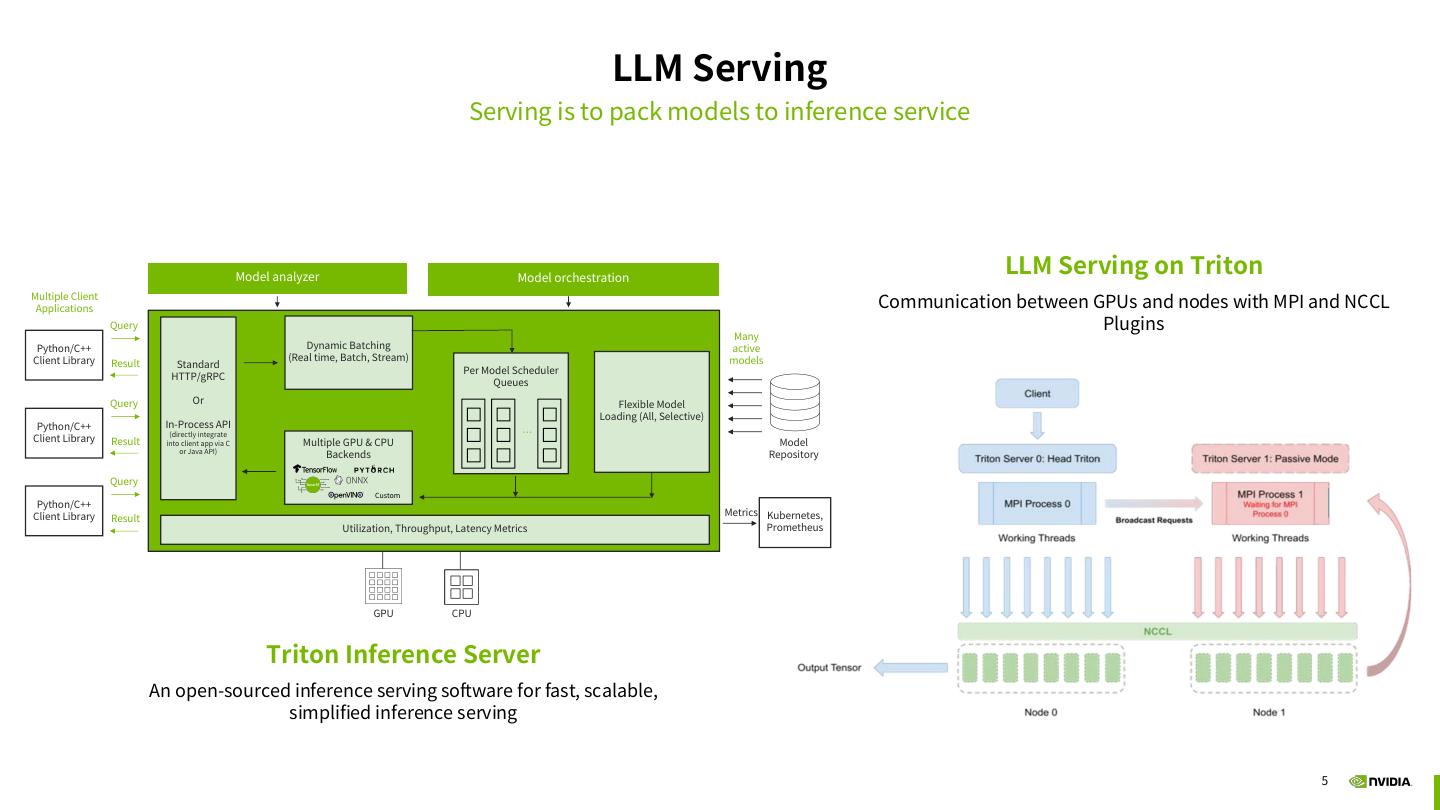
5 . LLM Serving Serving is to pack models to inference service Model analyzer Model orchestration LLM Serving on Triton Multiple Client Applications Communication between GPUs and nodes with MPI and NCCL Query Plugins Many Python/C++ Dynamic Batching active Client Library (Real time, Batch, Stream) models Result Standard Per Model Scheduler HTTP/gRPC Queues Query Or Flexible Model Loading (All, Selective) Python/C++ In-Process API … Client Library Result (directly integrate into client app via C Multiple GPU & CPU Model or Java API) Backends Repository Query Custom Python/C++ Client Library Metrics Kubernetes, Result Utilization, Throughput, Latency Metrics Prometheus GPU CPU Triton Inference Server An open-sourced inference serving software for fast, scalable, simplified inference serving 5
6 . GPT Inference Basics Context / Generation Phase and KV Cache Input 并非所有英雄都披着斗篷 seqlen: Context 并非所有英雄都披着斗篷 -> 但 并非所有英雄都披着斗篷 ,但-> 全部 Generator 并非所有英雄都披着斗篷,但全部 -> 恶棍 并非所有英雄都披着斗篷,但全部恶棍 -> 做 ... Output 但全部恶棍做... seqlen: Challenge: Repeatedly computing Key and Value in each generation step costs time waste 6
7 . GPT Inference Phase 1: Context phase Context phase K/V matrix embedding K0 Context-decoder Size (n, b, ah, size_per_head, s) V0 Size (n, b, ah, size_per_head, s) In-Context • Compute K/V matrix based on input sequence and saved in K/V Cache • Just do once Will be used to generate every output token • Will be used in the iteration of generating every output token 7
8 . GPT Inference Phase 2: Generation Phase K/V cache Generate phase Output (i-1)th token K0_1_ …_(i-1) V0_1_..._(i-1) Decoder_layer Out_(i-1) X 96 Generate (i-1)th output token Update K/V cache K(i-1) • Use fuseQKV masked attention V(i-1) • Generate 1 token at one step • Iterate 96 times for GPT3 with 96 decoder_layer • Will Update K/V cache 8
9 . Batched LLM Inference Challenges • Need to do batched inference to improve GPU utilization, as well as inference throughput. • Inputs are padded to make them uniform for batching. • Multiple inputs are batched together all the way along the generation process. • For generative LLMs, requests are very varied in size – padding leads to: • wasted FLOPs (higher cost/lower throughput) • long queue wait times (longer time to first token) 9
10 . In-flight Batching • Idea: Fuse context phase and generation phase Request Waiting Pool • A request waiting pool to hold all incoming requests; • Multiple requests are grabbed from pool and batched together • Newly arrived requests are incorporated into batch execution immediately; newly completed requests are removed immediately • Context phase and generation phase are executed respectively when new requests join; afterwards all requests do generation phase together. 10
11 .In-flight Batching Architecture 11
12 .12
13 .Triton TensorRT-LLM Backend 13
14 . Triton TensorRT LLM Backend Request Waiting Pool Triton tensorrt llm backend Tensorrt llm runtime • Triton TensorRT LLM Backend is GA released now https://github.com/triton-inference-server/tensorrtllm_backend • The goal of TensorRT-LLM Backend is to let you serve TensorRT-LLM models with Triton Inference Server • The inflight_batcher_llm directory contains the C++ implementation of the backend supporting inflight batching, paged attention and more • Supports streaming decode and early stopping 14
15 .End to End Serving Practice 15
16 . End to End Serving Practice Step 1 – build TensorRT LLM backend and TensorRT LLM engines To build TensorRT LLM backend To build TensorRT LLM engines • Run the docker container • Building via the build.py script in server repo • Build via docker Please refer to documentation for further details Do not forget to lock frequency 16
17 . End to End Serving Practice Step 2 – create model repository • "preprocessing": This model is used for tokenizing, meaning the conversion from prompts(string) to input_ids(list of ints) • "tensorrt_llm": This model is a wrapper of your TensorRT-LLM model and is used for inferencing • "postprocessing": This model is used for de-tokenizing, meaning the conversion from output_ids(list of ints) to outputs(string) • "ensemble": This model is used to chain the three models above together: preprocessing -> tensorrt_llm -> postprocessing Ensemble Models 17
18 .End to End Serving Practice Step 3 – modify model configurations 18
19 . End to End Serving Practice Step 4 – launch server | benchmarking | kill server End2end test To launch Triton Server docker run --rm -it --net host --shm-size=1g --ulimit memlock=-1 --ulimit stack=67108864 --gpus='"'device=0'"' -v $(pwd)/triton_model_repo:/triton_model_repo tritonserver:w_trt_llm_backend /bin/bash -c "tritonserver --model- repository=/triton_model_repo“ To kill Triton Server Remember to kill the server before you launch another one • ps -ef | grep 'tritonserver' | grep -v grep | awk '{print $2}' | xargs -r kill -9 • (or) pkill -9 tritonserver In flight batcher LLM client Identity test 19
20 .20 20
3秒后跳转登录页面
去登陆

