





















- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 视频嵌入链接 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
3.张建-Intel® 端到端AI 优化包助力人工智能“民主化
展开查看详情
1 .
2 .Intel® 端到端AI优化包助力人工 智能“民主化” 张建,人工智能软件工程经理,英特尔 Jian Zhang, AI software engineering manager, Intel September 2022
3 .Agenda Background and motivation Recommendation System case study AI Democratization Intel® End-to-End AI Optimization Kit Performance results Summary
4 . 背景与动机 Background and Motivation
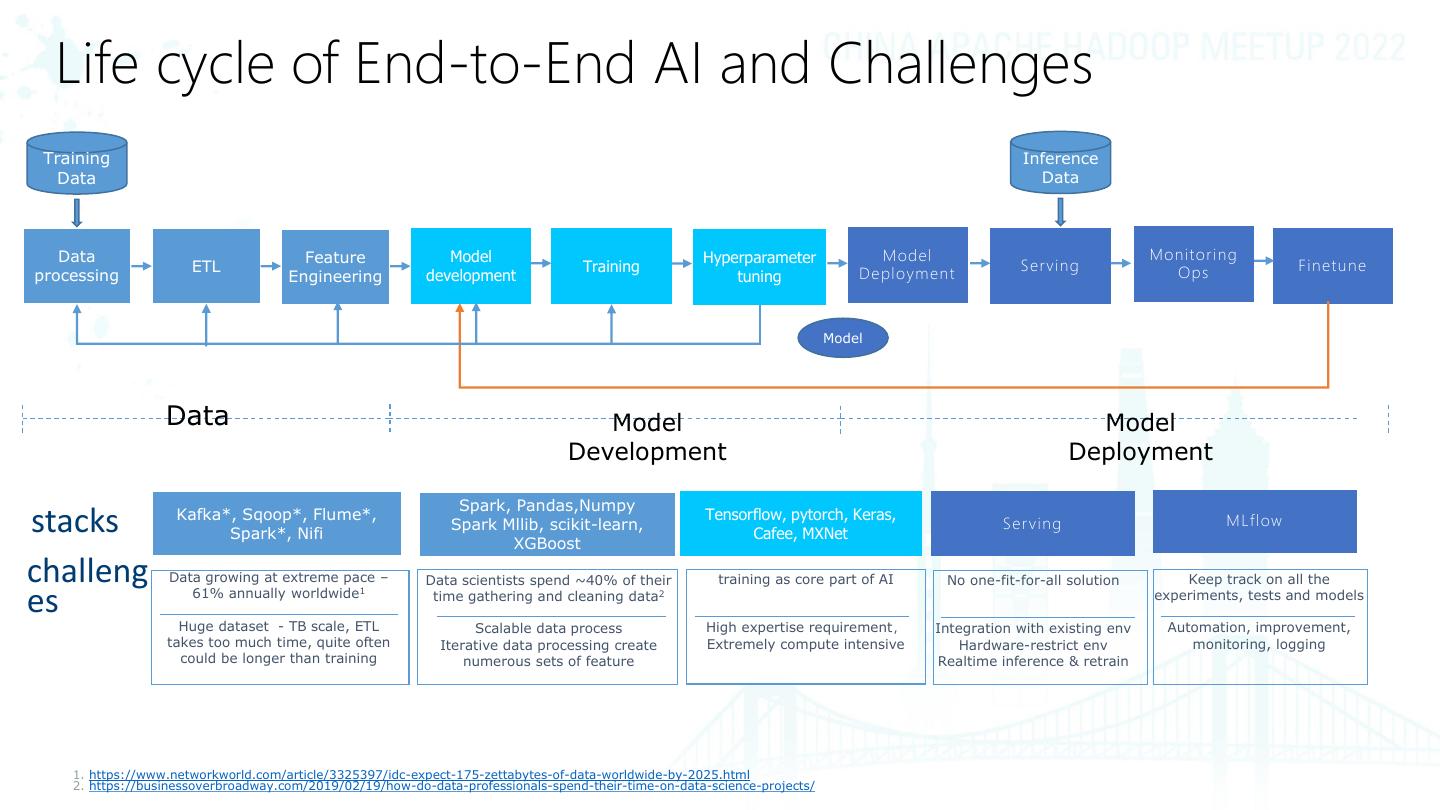
5 . Life cycle of End-to-End AI and Challenges Training Inference Data Data Data Feature Model Hyperparameter Model Monitor ing ETL Training Serving Ops Finetune processing Engineering development tuning Deploym en t Model Data Model Model Development Deployment Spark, Pandas,Numpy Kafka*, Sqoop*, Flume*, Tensorflow, pytorch, Keras, stacks Spark*, Nifi Spark Mllib, scikit-learn, XGBoost Cafee, MXNet S er ving MLflow challeng Data growing at extreme pace – 61% annually worldwide1 Data scientists spend ~40% of their training as core part of AI No one-fit-for-all solution Keep track on all the es time gathering and cleaning data2 experiments, tests and models Huge dataset - TB scale, ETL Scalable data process High expertise requirement, Integration with existing env Automation, improvement, takes too much time, quite often Iterative data processing create Extremely compute intensive Hardware-restrict env monitoring, logging could be longer than training numerous sets of feature Realtime inference & retrain 1. https://www.networkworld.com/article/3325397/idc-expect-175-zettabytes-of-data-worldwide-by-2025.html 2. https://businessoverbroadway.com/2019/02/19/how-do-data-professionals-spend-their-time-on-data-science-projects/
6 .Problem Statement E2E AI is computationally expensive • Overparameterized DL models size & HW growth gap becomes increasingly larger • Compute intensive model is hard to deploy in resource constraint environment Complexity hinders deployment/usage • Complex software stacks to deploy, too many parameters to tune • Extremely time-consuming for model optimization • Requested expertise creates an entry-barrier for novice & citizen DS • Lack of click to run workflows that can be easily deployed and tested • On the Opportunities and Risks of Foundation Models
7 .案例分析 Case Study
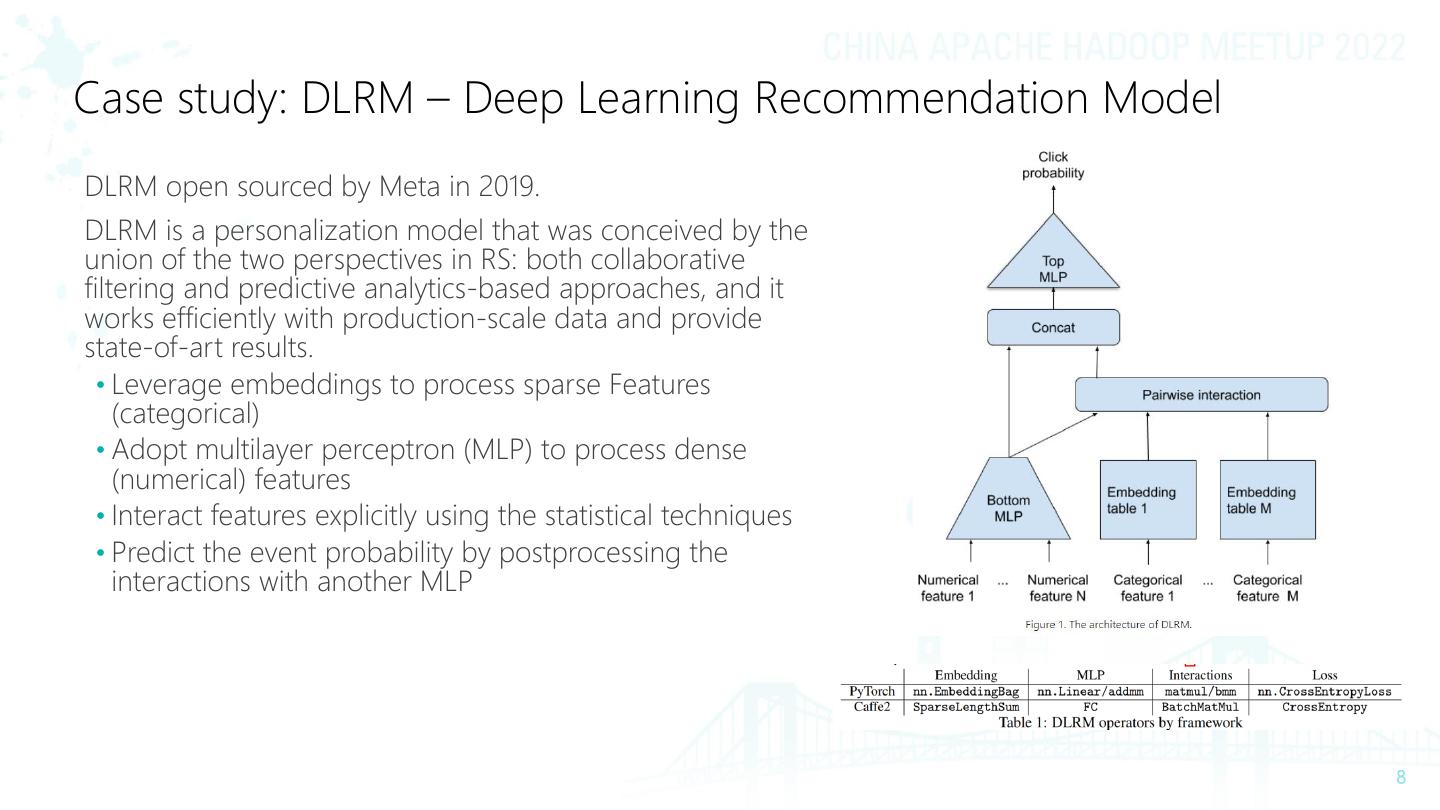
8 .Case study: DLRM – Deep Learning Recommendation Model DLRM open sourced by Meta in 2019. DLRM is a personalization model that was conceived by the union of the two perspectives in RS: both collaborative filtering and predictive analytics-based approaches, and it works efficiently with production-scale data and provide state-of-art results. • Leverage embeddings to process sparse Features (categorical) • Adopt multilayer perceptron (MLP) to process dense (numerical) features • Interact features explicitly using the statistical techniques • Predict the event probability by postprocessing the interactions with another MLP
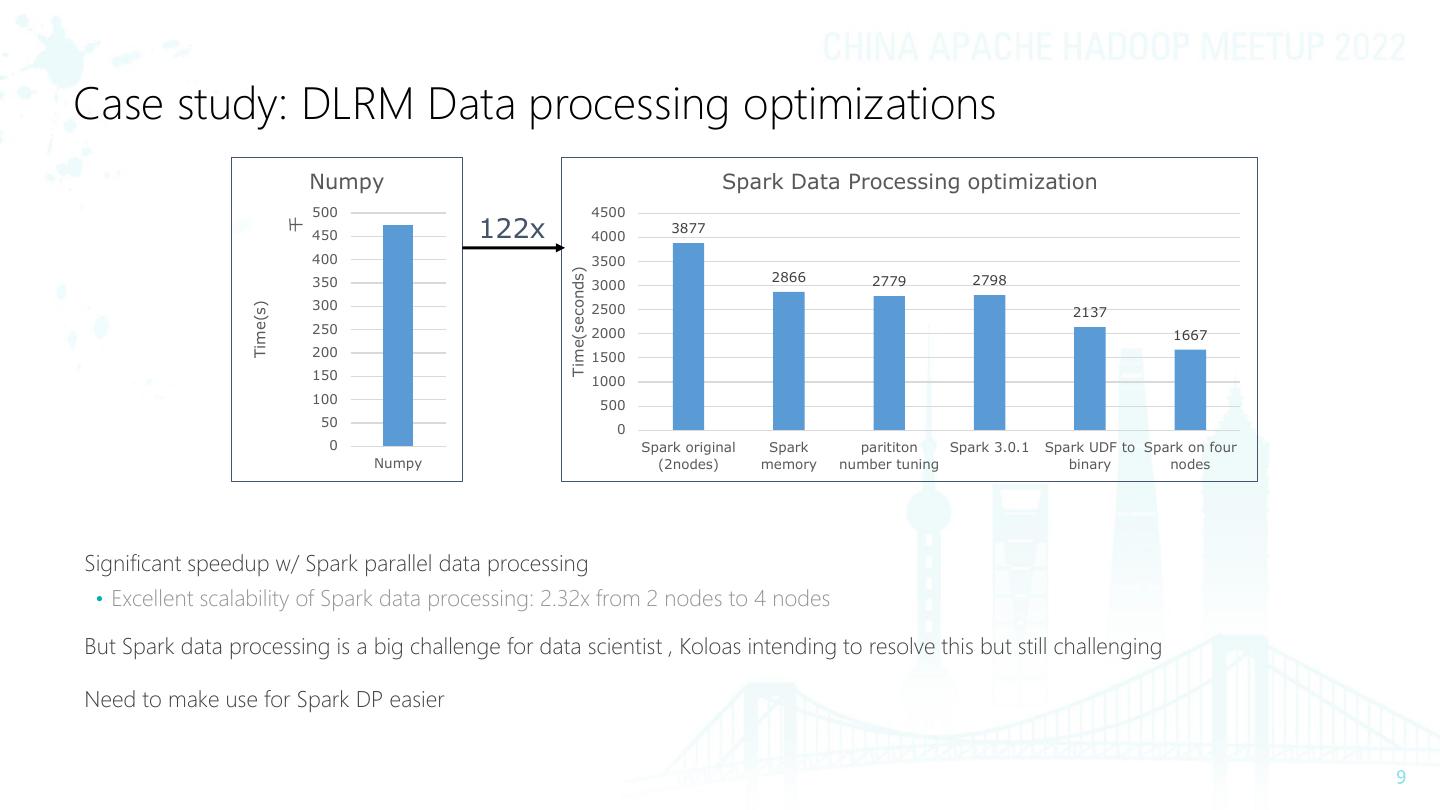
9 .Case study: DLRM Data processing optimizations Numpy Spark Data Processing optimization 500 4500 122x 千 3877 450 4000 400 3500 Time(seconds) 350 2866 2779 2798 3000 300 Time(s) 2500 2137 250 2000 1667 200 1500 150 1000 100 500 50 0 0 Spark original Spark parititon Spark 3.0.1 Spark UDF to Spark on four Numpy (2nodes) memory number tuning binary nodes Significant speedup w/ Spark parallel data processing • Excellent scalability of Spark data processing: 2.32x from 2 nodes to 4 nodes But Spark data processing is a big challenge for data scientist , Koloas intending to resolve this but still challenging Need to make use for Spark DP easier
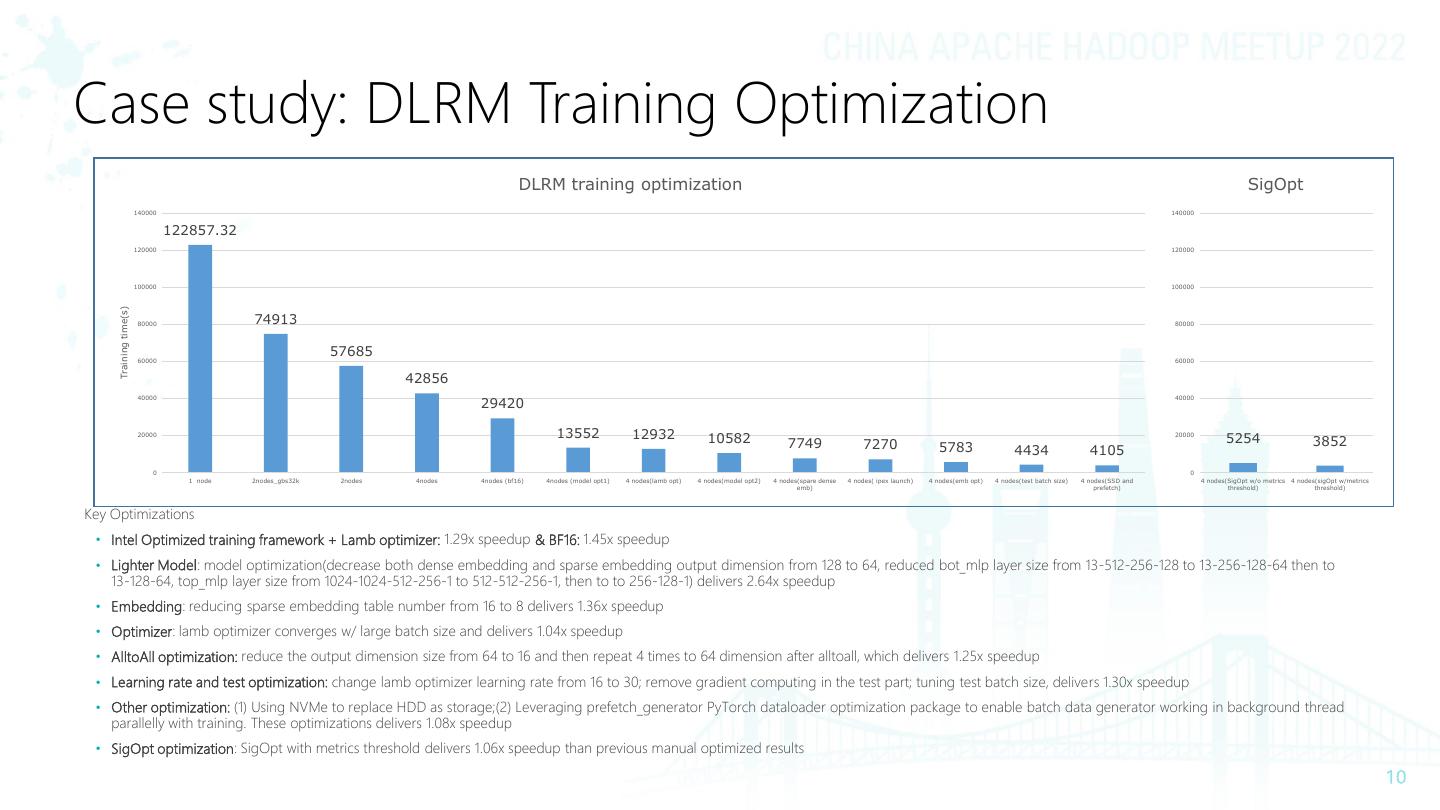
10 .Case study: DLRM Training Optimization DLRM training optimization SigOpt 140000 140000 122857.32 120000 120000 100000 100000 Training time(s) 80000 74913 80000 57685 60000 60000 42856 40000 40000 29420 20000 13552 12932 10582 20000 5254 7749 7270 5783 3852 4434 4105 0 0 1 node 2nodes_gbs32k 2nodes 4nodes 4nodes (bf16) 4nodes (model opt1) 4 nodes(lamb opt) 4 nodes(model opt2) 4 nodes(spare dense 4 nodes( ipex launch) 4 nodes(emb opt) 4 nodes(test batch size) 4 nodes(SSD and 4 nodes(SigOpt w/o metrics 4 nodes(sigOpt w/metrics emb) prefetch) threshold) threshold) Key Optimizations • Intel Optimized training framework + Lamb optimizer: 1.29x speedup & BF16: 1.45x speedup • Lighter Model: model optimization(decrease both dense embedding and sparse embedding output dimension from 128 to 64, reduced bot_mlp layer size from 13-512-256-128 to 13-256-128-64 then to 13-128-64, top_mlp layer size from 1024-1024-512-256-1 to 512-512-256-1, then to to 256-128-1) delivers 2.64x speedup • Embedding: reducing sparse embedding table number from 16 to 8 delivers 1.36x speedup • Optimizer: lamb optimizer converges w/ large batch size and delivers 1.04x speedup • AlltoAll optimization: reduce the output dimension size from 64 to 16 and then repeat 4 times to 64 dimension after alltoall, which delivers 1.25x speedup • Learning rate and test optimization: change lamb optimizer learning rate from 16 to 30; remove gradient computing in the test part; tuning test batch size, delivers 1.30x speedup • Other optimization: (1) Using NVMe to replace HDD as storage;(2) Leveraging prefetch_generator PyTorch dataloader optimization package to enable batch data generator working in background thread parallelly with training. These optimizations delivers 1.08x speedup • SigOpt optimization: SigOpt with metrics threshold delivers 1.06x speedup than previous manual optimized results
11 .人工智能“民主化” AI Democratization
12 . Solution: E2E AI Democratization • Enabling scale-up/out on CPU with Intel optimized framework and toolkits Making AI • Delivering popular lighter DL Models with close enough AUC and higher inference throughput Faster • Reducing E2E time on CPU to acceptable range through full pipeline optimization • Automating E2E democratization pipeline with click to run workflows and AutoML Making AI • Simplified toolkits for data processing, feature engineering, simplifying distributed training Easier • Providing independent pluggable components complements current toolkits and easily integrated with 3rd party ML solutions/platforms • Bring complex DL to commodity HW – commodity CPU & ethernet Making AI • Built-in democratized models through parameterized models generated by smart democratization advisor (SDA) more accessible • Domain specific compact networks constructed by compact network constructor (train-free NAS)
13 .What to Democratize? Data accessibility & quality • Make data access easier & simpler & faster • Democratize the data management - Data ingestion, data warehouses and data lakes -> explore & visualize & processing Storage & compute platforms • The Infrastructure E2E AI runs on: Cloud computing, auto-scaling, GPU vs. CPU • Democratize the HW – scalable infrastructure on commodity hardware Algorithms • The use, development and sharing of ML & DL algorithms • Democratize the algorithms - Reduce entry barriers, automatic model searching, AutoML, improve explanation of the results Model development • Select the most suitable models • Democratize the end-to-end model development, training and deployment Marketplace • Access to the models • Democratize the use, exchange, and monetization of data, algorithms, models and outcomes
14 .Intel® 端到端AI优化包 Intel® End to End AI optimization Kit
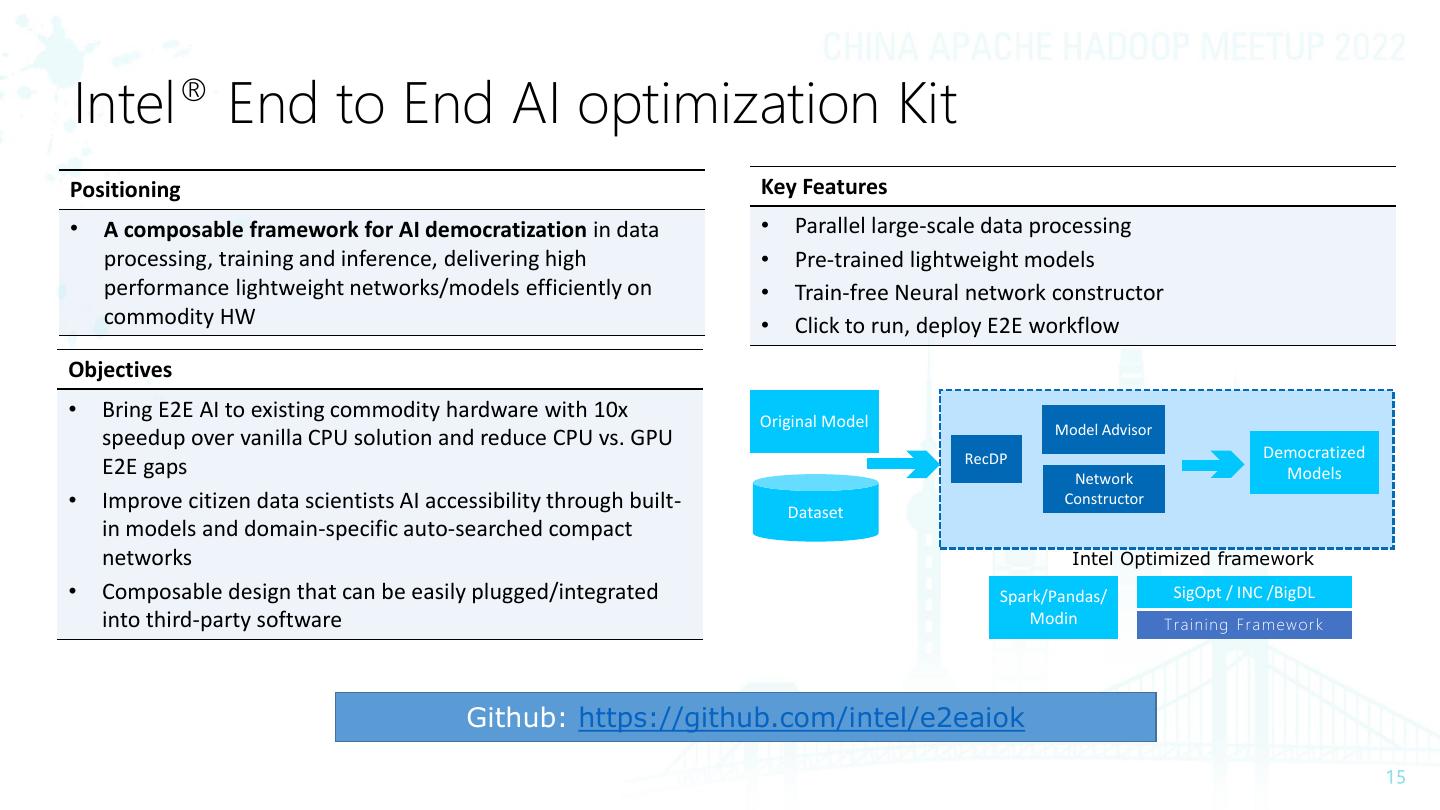
15 .Intel® End to End AI optimization Kit Positioning Key Features • A composable framework for AI democratization in data • Parallel large-scale data processing processing, training and inference, delivering high • Pre-trained lightweight models performance lightweight networks/models efficiently on • Train-free Neural network constructor commodity HW • Click to run, deploy E2E workflow Objectives • Bring E2E AI to existing commodity hardware with 10x Original Model Model Advisor speedup over vanilla CPU solution and reduce CPU vs. GPU RecDP Democratized E2E gaps Network Models • Improve citizen data scientists AI accessibility through built- Dataset Constructor in models and domain-specific auto-searched compact networks Intel Optimized framework • Composable design that can be easily plugged/integrated Spark/Pandas/ SigOpt / INC /BigDL into third-party software Modin Tr aining Fr amewor k Github: https://github.com/intel/e2eaiok
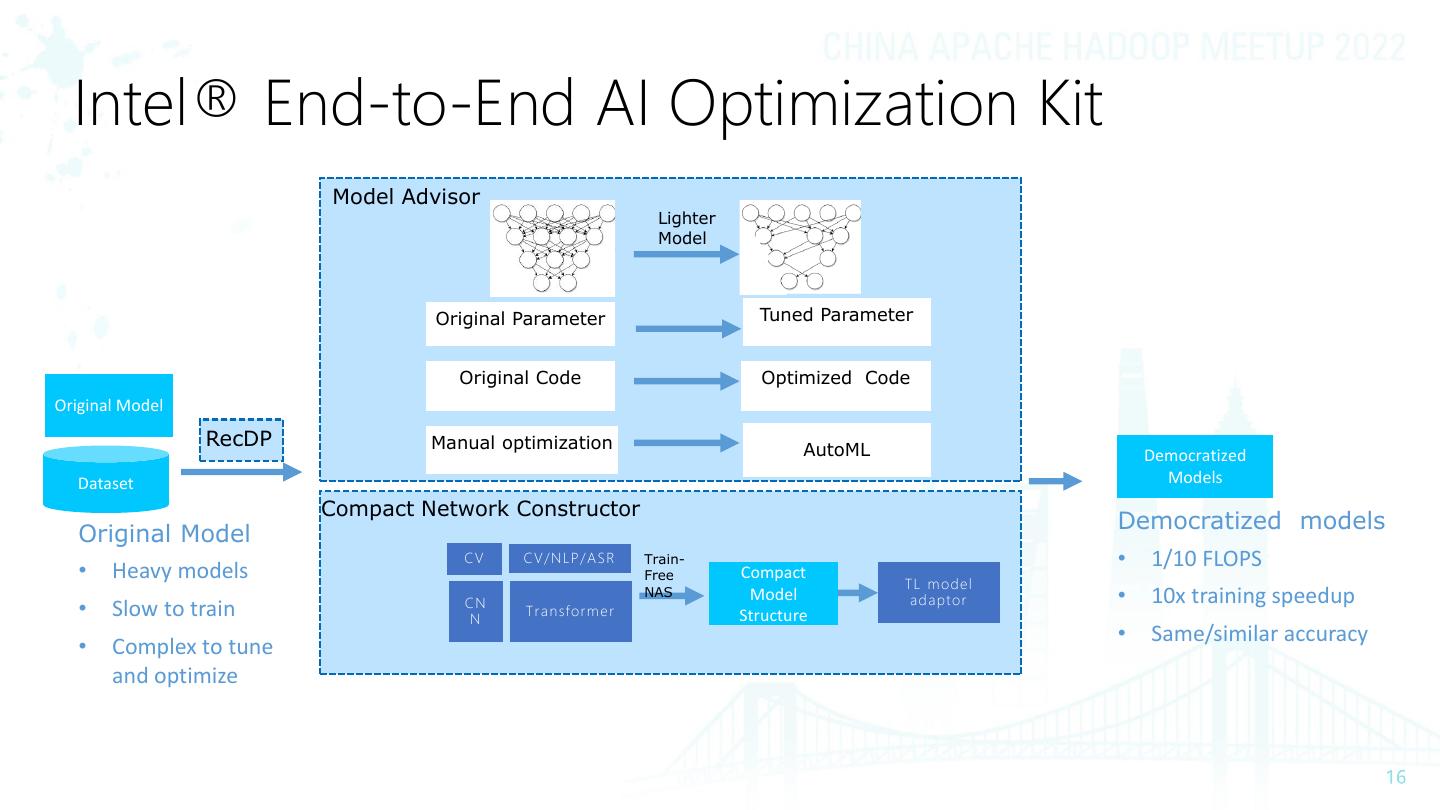
16 . Intel® End-to-End AI Optimization Kit Model Advisor Lighter Model Original Parameter Tuned Parameter Original Code Optimized Code Original Model RecDP Manual optimization AutoML Democratized Dataset Models Compact Network Constructor Democratized models Original Model CV C V / NL P / A S R Train- • 1/10 FLOPS • Heavy models Free Compact TL m ode l CN NAS Model a d a p t or • 10x training speedup • Slow to train N Tr a n sf or m e r Structure • Same/similar accuracy • Complex to tune and optimize
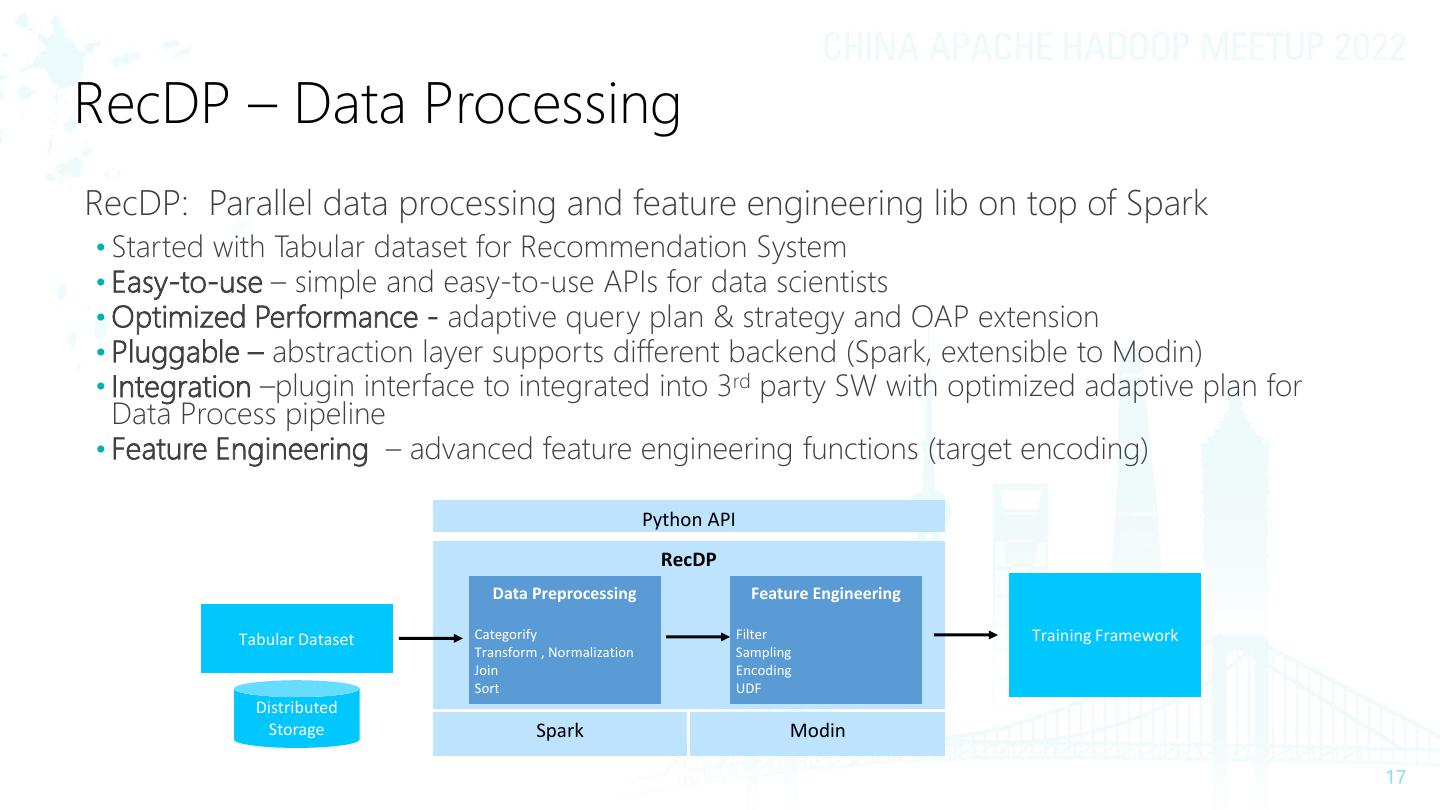
17 .RecDP – Data Processing RecDP: Parallel data processing and feature engineering lib on top of Spark • Started with Tabular dataset for Recommendation System • Easy-to-use – simple and easy-to-use APIs for data scientists • Optimized Performance - adaptive query plan & strategy and OAP extension • Pluggable – abstraction layer supports different backend (Spark, extensible to Modin) • Integration –plugin interface to integrated into 3rd party SW with optimized adaptive plan for Data Process pipeline • Feature Engineering – advanced feature engineering functions (target encoding) Python API RecDP Data Preprocessing Feature Engineering Tabular Dataset Categorify Filter Training Framework Transform , Normalization Sampling Join Encoding Sort UDF Distributed Storage Spark Modin
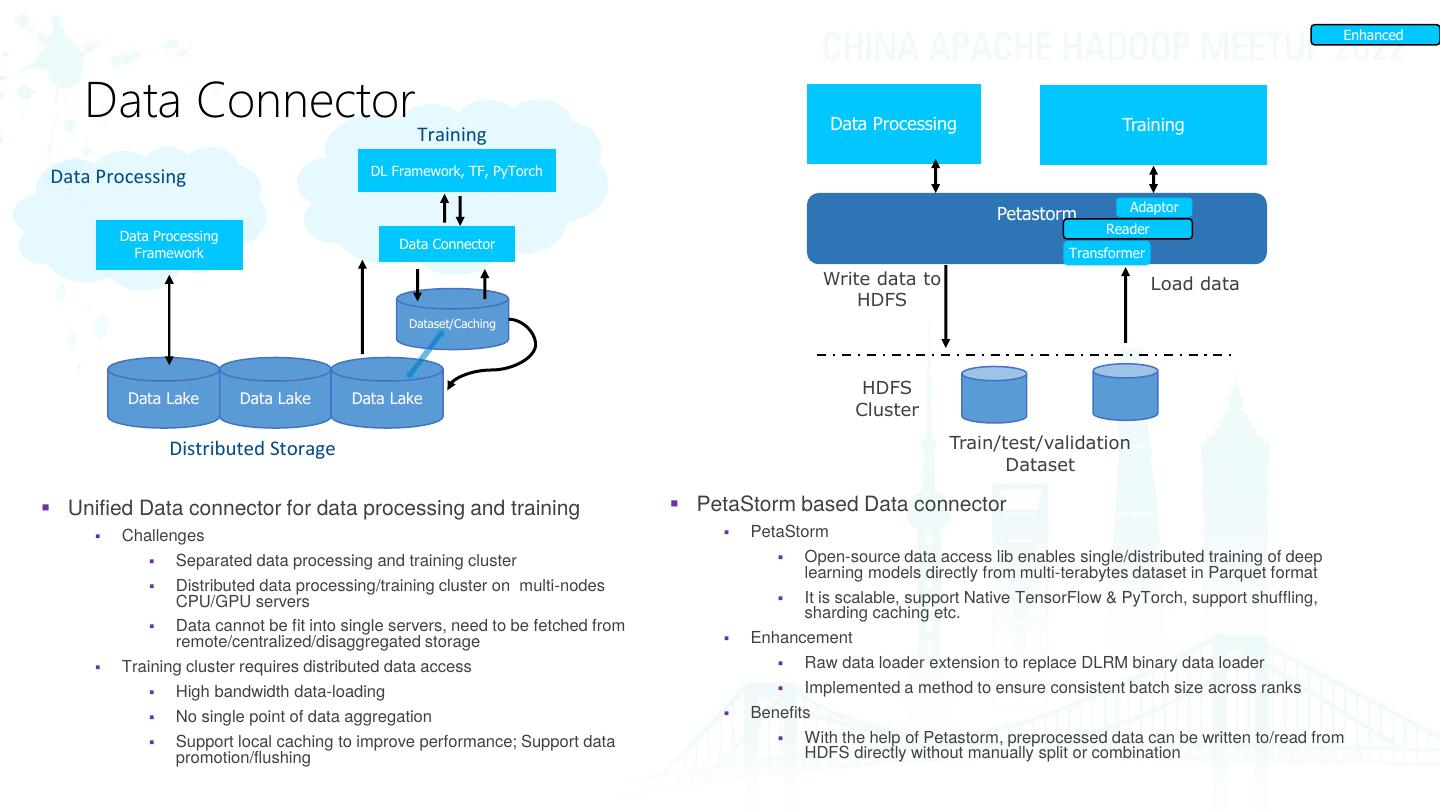
18 . Enhanced Data Connector Data Processing Training Training DL Framework, TF, PyTorch Data Processing Adaptor Petastorm Reader Data Processing Data Connector Framework Transformer Write data to Load data HDFS Dataset/Caching HDFS Data Lake Data Lake Data Lake Cluster Distributed Storage Train/test/validation Dataset ▪ Unified Data connector for data processing and training ▪ PetaStorm based Data connector ▪ Challenges ▪ PetaStorm ▪ Separated data processing and training cluster ▪ Open-source data access lib enables single/distributed training of deep learning models directly from multi-terabytes dataset in Parquet format ▪ Distributed data processing/training cluster on multi-nodes CPU/GPU servers ▪ It is scalable, support Native TensorFlow & PyTorch, support shuffling, sharding caching etc. ▪ Data cannot be fit into single servers, need to be fetched from remote/centralized/disaggregated storage ▪ Enhancement ▪ Training cluster requires distributed data access ▪ Raw data loader extension to replace DLRM binary data loader ▪ High bandwidth data-loading ▪ Implemented a method to ensure consistent batch size across ranks ▪ No single point of data aggregation ▪ Benefits ▪ Support local caching to improve performance; Support data ▪ With the help of Petastorm, preprocessed data can be written to/read from promotion/flushing HDFS directly without manually split or combination
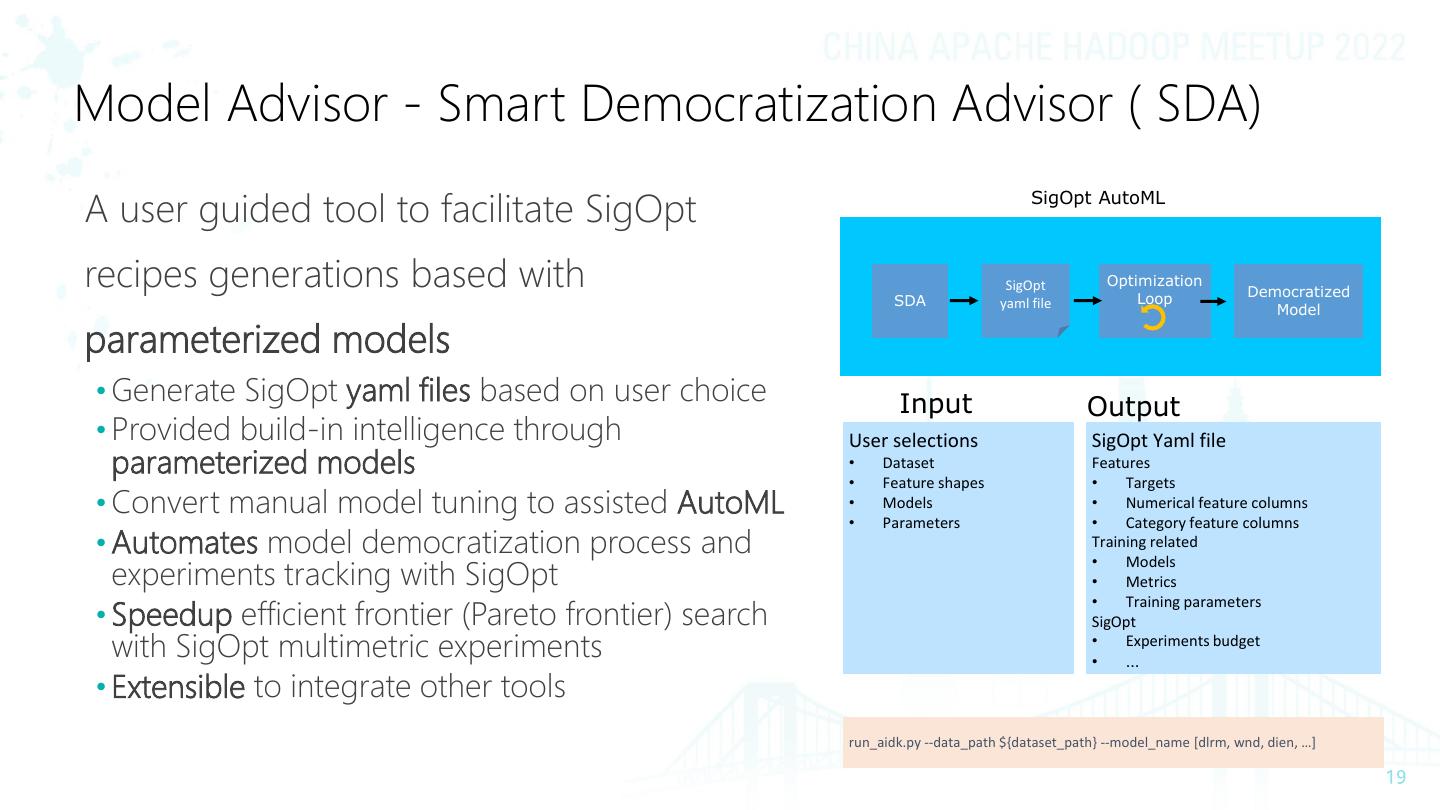
19 .Model Advisor - Smart Democratization Advisor ( SDA) A user guided tool to facilitate SigOpt SigOpt AutoML recipes generations based with SigOpt Optimization Loop Democratized SDA yaml file Model parameterized models • Generate SigOpt yaml files based on user choice Input Output • Provided build-in intelligence through User selections SigOpt Yaml file parameterized models • Dataset Features • Feature shapes • Targets • Convert manual model tuning to assisted AutoML • • Models Parameters • • Numerical feature columns Category feature columns • Automates model democratization process and Training related • experiments tracking with SigOpt Models • Metrics • • Speedup efficient frontier (Pareto frontier) search Training parameters SigOpt with SigOpt multimetric experiments • • Experiments budget … • Extensible to integrate other tools run_aidk.py --data_path ${dataset_path} --model_name [dlrm, wnd, dien, …]
20 .Network Constructor A lightweight Neural Architecture Search solution to deliver domain-specific democratized neural networks on CPU in given budget with transfer-learning model adaptor Candidate Architecture 𝜜 ∈ 𝓐 Pre-Trained Models Search Performance Estimation Democratized Search Strategy Networks & Models Space 𝓐 Strategy Raw Data Scoring 𝜜 Data B AIDK TLK FineTune Customized ▪ Improved Accuracy Data A Tuner model ▪ Accelerated training speed DE-NAS/Pre-trained Model AIDK TLK Distiller ▪ Reduced model size Smaller Model ▪ Increased Inference throughput Distiller ▪ Deployment in resource constraint device Domain AIDK TLK Adaptor ▪ Improved Accuracy Source domain Untrained Target Target Data Model Domain Adaptor Model ▪ Reduced data labeling cost Target Domain labeled data Data Label-free data
21 .性能数据 Performance
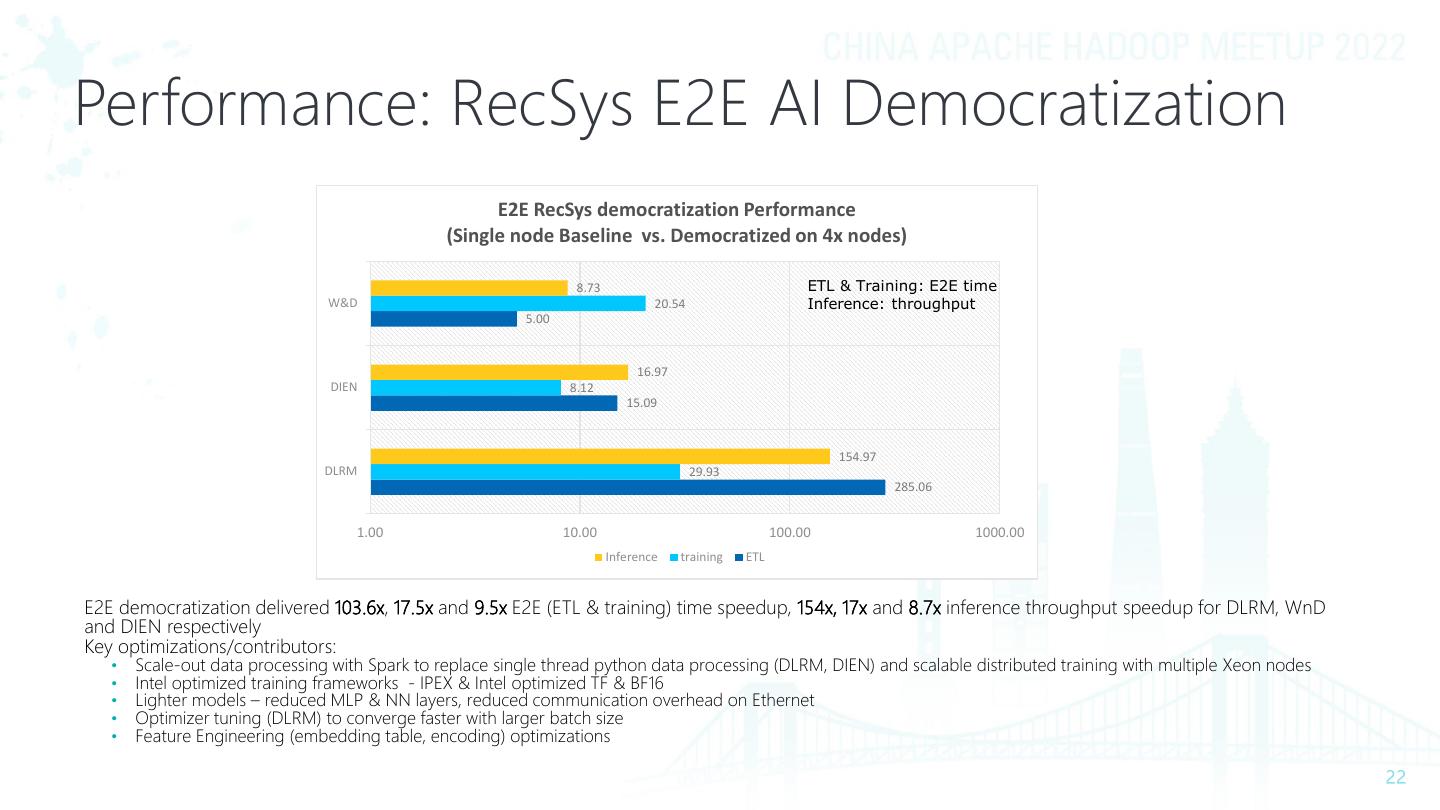
22 .Performance: RecSys E2E AI Democratization E2E RecSys democratization Performance (Single node Baseline vs. Democratized on 4x nodes) 8.73 ETL & Training: E2E time W&D 20.54 Inference: throughput 5.00 16.97 DIEN 8.12 15.09 154.97 DLRM 29.93 285.06 1.00 10.00 100.00 1000.00 Inference training ETL E2E democratization delivered 103.6x, 17.5x and 9.5x E2E (ETL & training) time speedup, 154x, 17x and 8.7x inference throughput speedup for DLRM, WnD and DIEN respectively Key optimizations/contributors: • Scale-out data processing with Spark to replace single thread python data processing (DLRM, DIEN) and scalable distributed training with multiple Xeon nodes • Intel optimized training frameworks - IPEX & Intel optimized TF & BF16 • Lighter models – reduced MLP & NN layers, reduced communication overhead on Ethernet • Optimizer tuning (DLRM) to converge faster with larger batch size • Feature Engineering (embedding table, encoding) optimizations
23 .Performance: SDA enhanced HPO DLRM Performance 80000 73128 0.9 70000 0.8025 0.8025 0.8025 0.8025 0.80250.8 60000 0.7 Training Time(s) 0.6 50000 5.2x 0.5 AUC 40000 0.4 30000 0.3 20000 5.4x 14051 13385 0.2 10000 0.1 2126 2460 0 0 GPU SDA Original DLRM SigOptAutoML SigOptAutoML (5 + SDA (5 experiments) experiments) Training Time AUC Enhanced SigOpt hyper-parameter tuning with SDA • Transform manual optimization to AutoML • Reduced total time to get the desired model, 5.2x speedup • Multimetrics optimization future reduce single experiments time
24 . RecSys Challenge 2022 • RecSys Challenge 2022: organized by Dressipi • Challenge: • This year ’s challenge focuses on fashion recommendations. When given user sessions, purchase data and content data about items, can you accurately predict which fashion item will be bought at the end of the session? • DataSet: • A public dataset of 1.1 million online retail sessions(18 months) that resulted in a purchase. The dataset is sampled and anonymized. Usage in SIHG4SR • Parameter tuning for stage1: Drop out ratio, learning rate, embedding dimension, layers, weight-decay • Optimizer tuning for stage2 : Change optimizer setting for second stage works better • Optimizer type: • SGD → works better for V1_cat • Adam→ works better for V1, V2 Base Optimized V1 Model 0.20048 0.20145 SIHG4SR - Side Information Heterogeneous Graph for Session Recommender V2 Model 0.2024 0.20343 V3 model 0.2048 0.2059
25 .总结 Summary
26 .Summary End-to-End AI is a complex process involve multiple stages and posed lots of challenges for today’s data platform infrastructure A unified data platform specifically optimized for End-to-End AI helps to improve performance and reduce cost AI democratization makes AI accessible & affordable to everyone Based on opensource frameworks/solutions, Intel® End-to-End AI optimization Kit complements the Data platform for E2E AI democratization • It delivers E2E AI optimization kits from data processing, feature engineering, data connector, model creation & optimization, hyper-parameter optimization • Preliminary results with Recommendation systems demonstrated very promising results Welcome to download Intel® End-to-End AI optimization kit (https://github.com/intel/e2eaiok ) and share with us your feedbacks!
27 .
28 .Notices and Disclaimers Performance varies by use, configuration and other factors. Learn more at www.Intel.com/PerformanceIndex. Performance results are based on testing as of dates shown in configurations and may not reflect all publicly available updates. See backup for configuration details. No product or component can be absolutely secure. Your costs and results may vary. Intel technologies may require enabled hardware, software or service activation. © Intel Corporation. Intel, the Intel logo, and other Intel marks are trademarks of Intel Corporation or its subsidiaries. Other names and brands may be claimed as the property of others.
29 .Configuration Details BaseLine: Test by Intel as of 2021/10. 1-node, 2x Intel® Xeon® Gold 6240 Processor, 18 cores HT On Turbo ON Total Memory 384 GB (12 slots/ 32GB/ 2666 MHz), BIOS: SE5C620.86B.0X.02.0094.102720191711 (ucode:0x500002C), Fedora 29, 5.3.11-100.fc29.x86_64, pytorch, tensorflow, spark 3, DLRM, WnD, DIEN Democratization Config: Test by Intel as of 2021/10. 4-nodes, 2x Intel® Xeon® Gold 6240 Processor, 18 cores HT On Turbo ON Total Memory 384 GB (12 slots/ 32GB/ 2666 MHz), BIOS: SE5C620.86B.0X.02.0094.102720191711 (ucode:0x500002C), Fedora 29, 5.3.11- 100.fc29.x86_64, pytorch, IPEX, Intel optimized tensorflow, horovod, spark 3, modified DLRM, WnD, DIEN workloads 29
3秒后跳转登录页面
去登陆

