2.廖登宏-openLooKeng的批处理特性探索
分享
点赞
0
收藏
0
下载 8
-
快召唤伙伴们来围观吧
-
微博
QQ
QQ空间
贴吧
-
视频嵌入链接
文档嵌入链接
- 复制
-
-
微信扫一扫分享
-
已成功复制到剪贴板
廖登宏,华为高级工程师,长期参与openLooKeng项目的需求分析、方案设计、代码开发等工作,致力于大数据领域的高性能查询场景的优化,对openLooKeng的解决方案及其行业应用有深入理解。
ETL批处理是数据湖数据处理过程中的重要组成部分,对于长时间运行的任务,在失败时通过自动重试查询进行任务恢复,对于下游的业务来说非常重要。本议题将主要分享openLooKeng在批处理上面所做的一些探索,包括operator leve snapshot与task level snapshot等不同级别的容错恢复机制,并分享关于批处理的设计思考。
展开查看详情
2 .openLooKeng的批处理特性
探索
廖登宏 华为高级工程师
�
3 .openLooKeng-面向大数据的融合分析引擎
安平 政府 金融 运营商 大企业
警务大数据 政务大数据 金融数据湖 运营商大数据 企业数据湖
数据源 数据集成 数据开发 数据治理 虚拟数仓 管理
数据使能
关系型数据
查询引擎 AI 安全管理
批计算 流计算 融合分析 图计算 搜索
日志数据 机 深 推
器 度 理
计算引擎 Hive Spark Flink openLooKeng
GraphBase GeoMesa
ElasticSearch
学
习
学
习
引
擎
租户管理
HBase
外部数据
YARN
配置管理
传感器(IoT)
数据管理 数据目录 Catalog 数据安全 Security 性能管理
WEB
入湖
社交媒体 故障管理
HDFS 分布式存储
数据存储 数据存储
TXT | ORC | Parquet | Carbon FS-HDFS | 对象 | 文件
3rd party
鲲鹏服务器 X86服务器 虚拟机 云主机
�
4 .统一高效的数据虚拟化引擎,让大数据变简单
统一入口,化繁为简,单一引擎支持多场景
openLooKeng 统一数据访问接口
SQL ODBC JDBC REST
引擎内核 内核增强,高性能查询
融合分析 跨源索引 动态过滤 算子下推 AA 高可用
统一数据源连接框架
Data Source Connector Data Center Connector
跨源关联分析,数据消费零搬移
MySQL Kafka Hive Parquet ……
PostgreSQL HBase CarbonData ORC
跨域协同计算,广域网的部署,局域网的体验
数据中心A 数据中心B 数据中心C
�
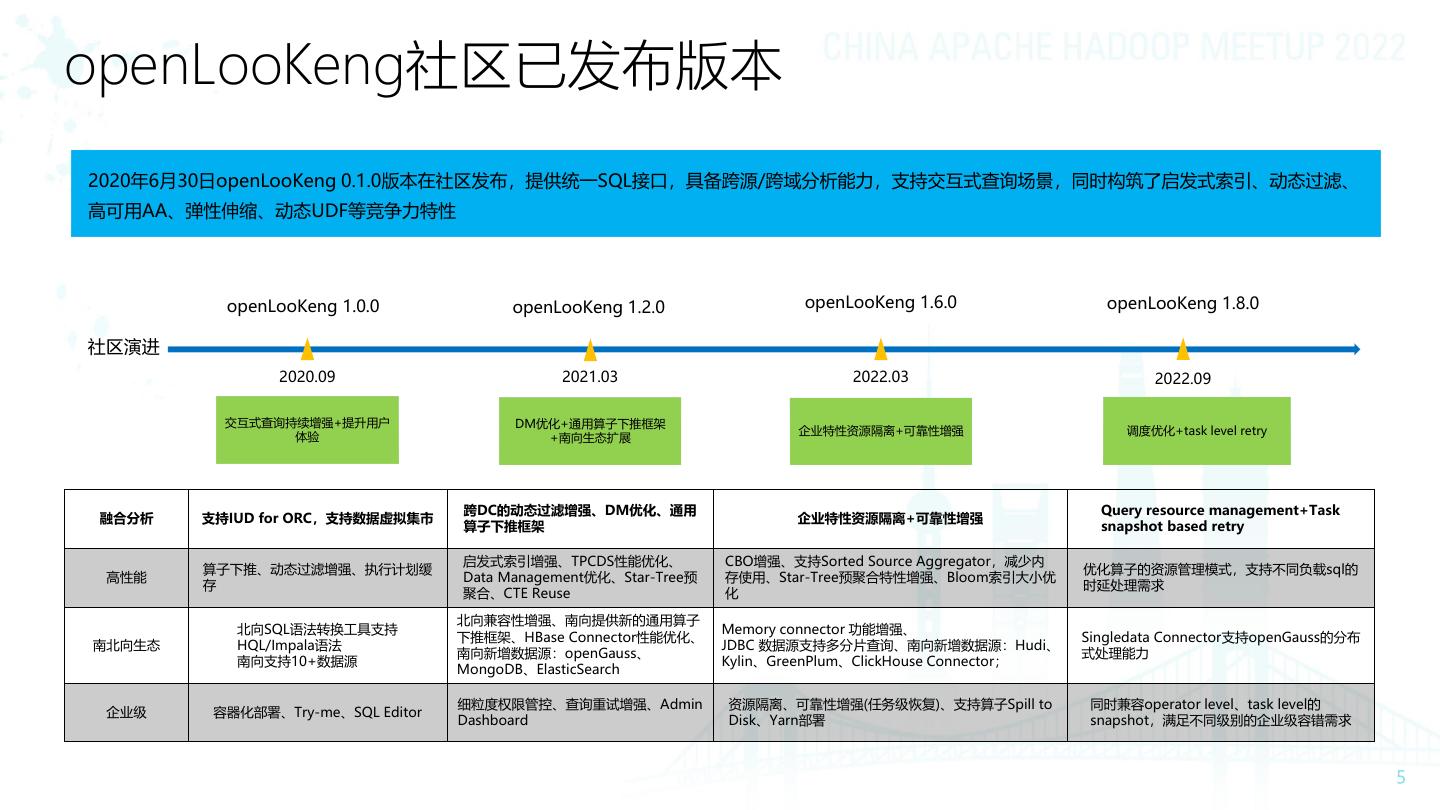
5 .openLooKeng社区已发布版本
2020年6月30日openLooKeng 0.1.0版本在社区发布,提供统一SQL接口,具备跨源/跨域分析能力,支持交互式查询场景,同时构筑了启发式索引、动态过滤、
高可用AA、弹性伸缩、动态UDF等竞争力特性
openLooKeng 1.0.0 openLooKeng 1.2.0 openLooKeng 1.6.0 openLooKeng 1.8.0
社区演进
2020.09 2021.03 2022.03 2022.09
交互式查询持续增强+提升用户 DM优化+通用算子下推框架
企业特性资源隔离+可靠性增强 调度优化+task level retry
体验 +南向生态扩展
跨DC的动态过滤增强、DM优化、通用 Query resource management+Task
融合分析 支持IUD for ORC,支持数据虚拟集市 企业特性资源隔离+可靠性增强
算子下推框架 snapshot based retry
启发式索引增强、TPCDS性能优化、 CBO增强、支持Sorted Source Aggregator,减少内
算子下推、动态过滤增强、执行计划缓 优化算子的资源管理模式,支持不同负载sql的
高性能 Data Management优化、Star-Tree预 存使用、Star-Tree预聚合特性增强、Bloom索引大小优
存 时延处理需求
聚合、CTE Reuse 化
北向兼容性增强、南向提供新的通用算子
北向SQL语法转换工具支持 Memory connector 功能增强、
下推框架、HBase Connector性能优化、 Singledata Connector支持openGauss的分布
南北向生态 HQL/Impala语法 JDBC 数据源支持多分片查询、南向新增数据源:Hudi、
南向新增数据源:openGauss、 式处理能力
南向支持10+数据源 Kylin、GreenPlum、ClickHouse Connector;
MongoDB、ElasticSearch
细粒度权限管控、查询重试增强、Admin 资源隔离、可靠性增强(任务级恢复)、支持算子Spill to 同时兼容operator level、task level的
企业级 容器化部署、Try-me、SQL Editor
Dashboard Disk、Yarn部署 snapshot,满足不同级别的企业级容错需求
�
6 .openLooKeng Batch Overview
• 资源管理优化
• query级别资源监控
• Spilling for right outer & full join
• Spilling加速
• Kryo serialization
• Compression and encryption
• 失败重试
• Pipeline operator State Snapshot
• Exchange materialization as Task Snapshot
�
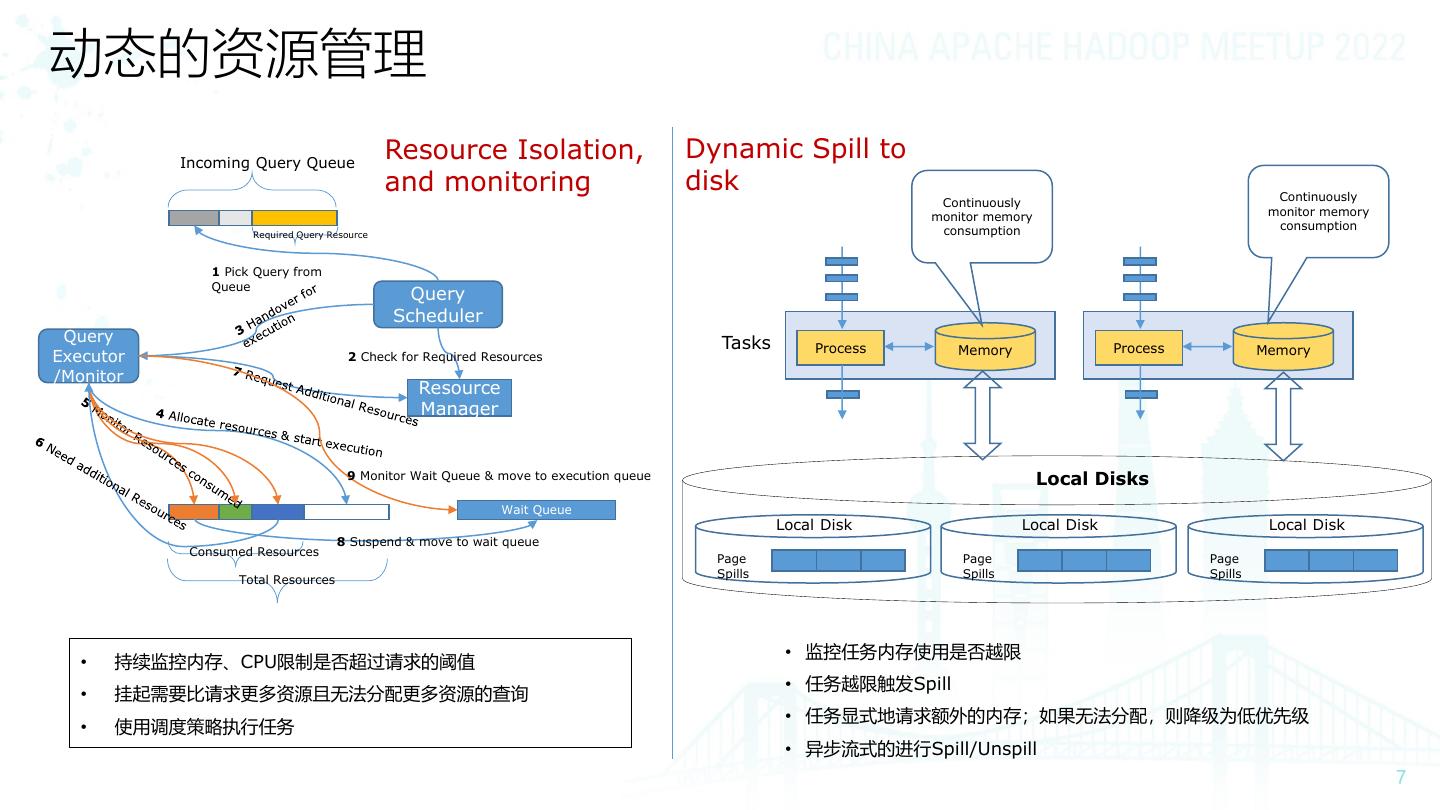
7 .动态的资源管理
Incoming Query Queue
Resource Isolation, Dynamic Spill to
and monitoring disk Continuously
Continuously
monitor memory monitor memory
consumption consumption
Required Query Resource
1 Pick Query from
Queue
Query
Scheduler
Query Tasks Process Memory Process Memory
Executor 2 Check for Required Resources
/Monitor
Resource
Manager
9 Monitor Wait Queue & move to execution queue Local Disks
Wait Queue
Local Disk Local Disk Local Disk
8 Suspend & move to wait queue
Consumed Resources
Page Page Page
Spills Spills Spills
Total Resources
• 监控任务内存使用是否越限
• 持续监控内存、CPU限制是否超过请求的阈值
• 任务越限触发Spill
• 挂起需要比请求更多资源且无法分配更多资源的查询
• 任务显式地请求额外的内存;如果无法分配,则降级为低优先级
• 使用调度策略执行任务
• 异步流式的进行Spill/Unspill
�
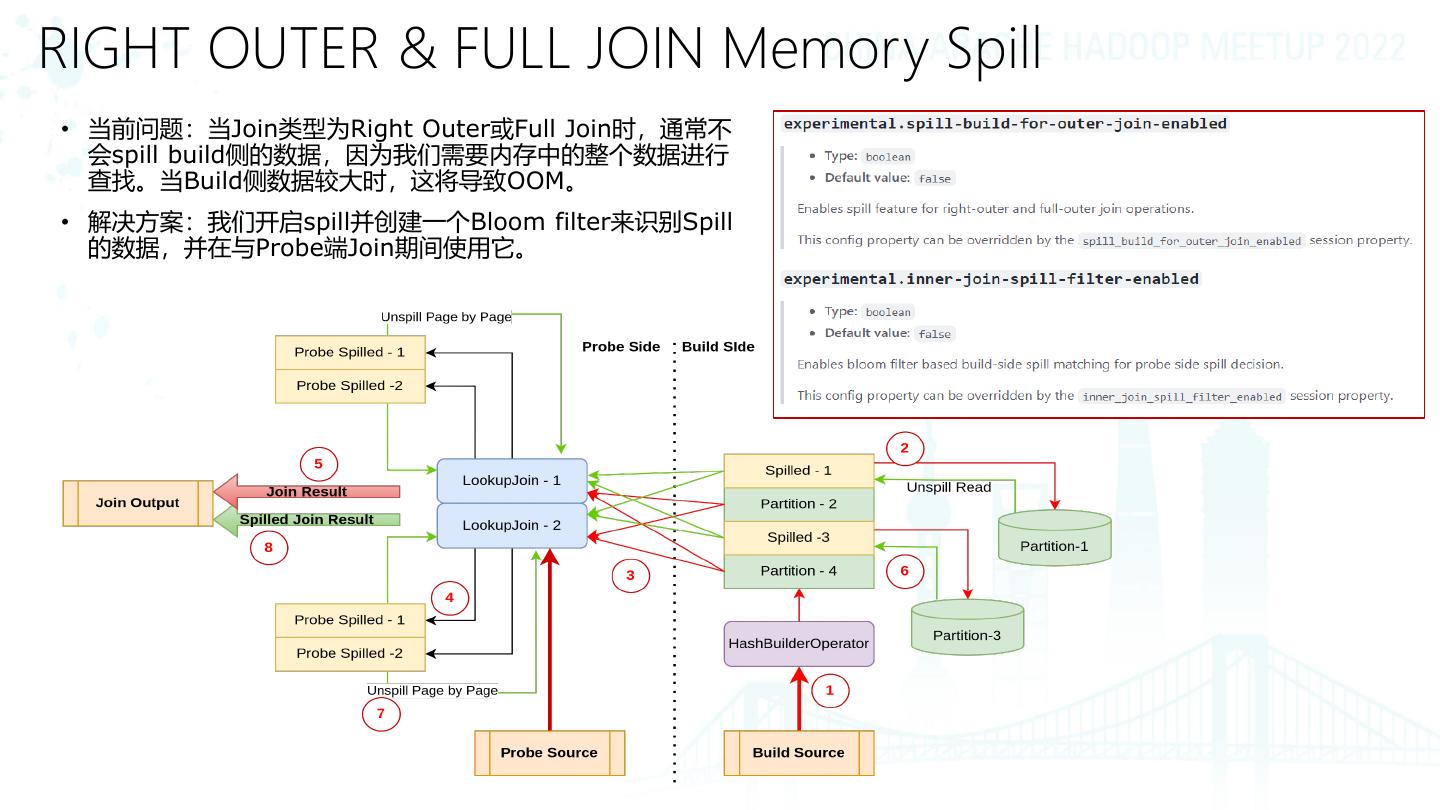
8 .RIGHT OUTER & FULL JOIN Memory Spill
• 当前问题:当Join类型为Right Outer或Full Join时,通常不
会spill build侧的数据,因为我们需要内存中的整个数据进行
查找。当Build侧数据较大时,这将导致OOM。
• 解决方案:我们开启spill并创建一个Bloom filter来识别Spill
的数据,并在与Probe端Join期间使用它。
�
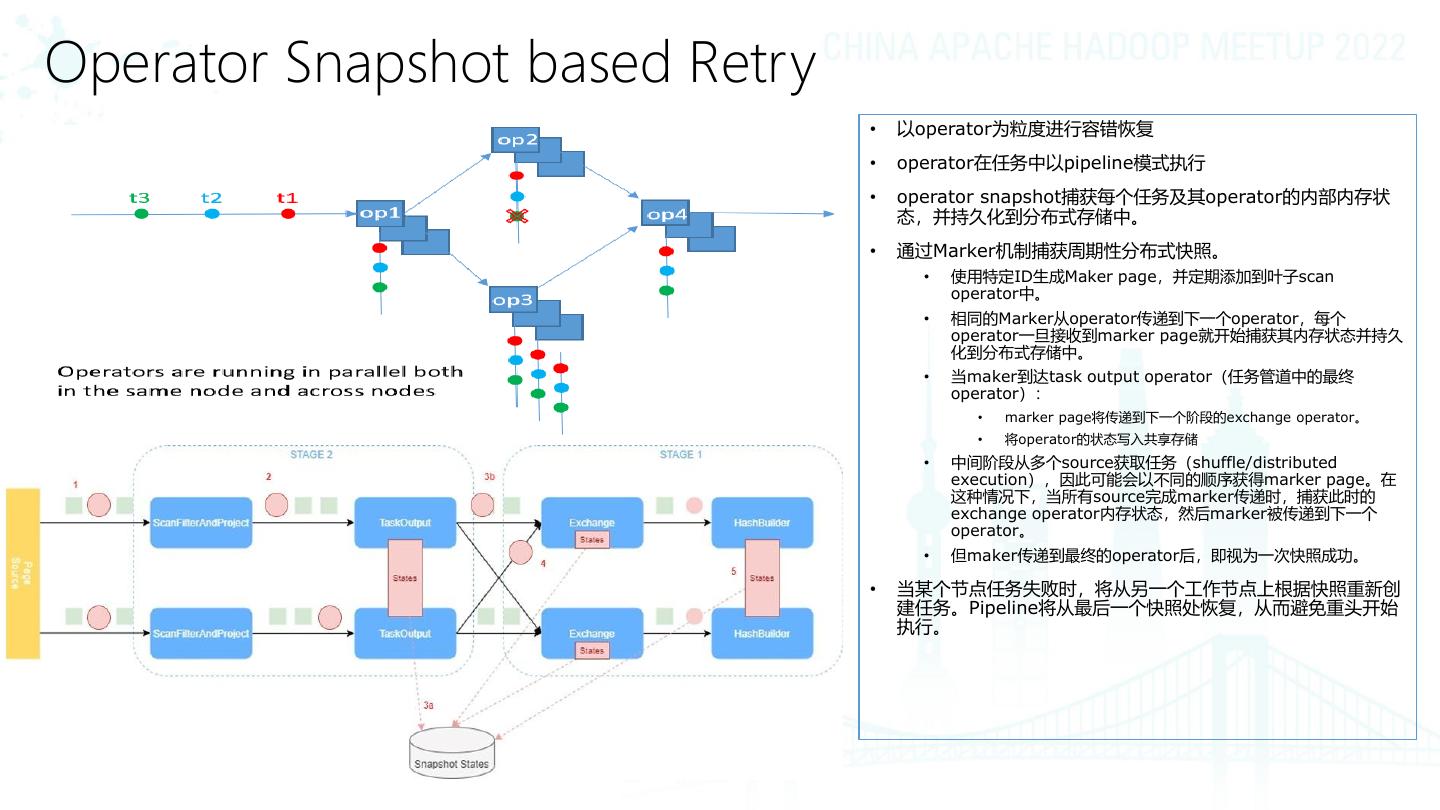
9 .Operator Snapshot based Retry
• 以operator为粒度进行容错恢复
• operator在任务中以pipeline模式执行
• operator snapshot捕获每个任务及其operator的内部内存状
态,并持久化到分布式存储中。
• 通过Marker机制捕获周期性分布式快照。
• 使用特定ID生成Maker page,并定期添加到叶子scan
operator中。
• 相同的Marker从operator传递到下一个operator,每个
operator一旦接收到marker page就开始捕获其内存状态并持久
化到分布式存储中。
• 当maker到达task output operator(任务管道中的最终
operator):
• marker page将传递到下一个阶段的exchange operator。
• 将operator的状态写入共享存储
• 中间阶段从多个source获取任务(shuffle/distributed
execution),因此可能会以不同的顺序获得marker page。在
这种情况下,当所有source完成marker传递时,捕获此时的
exchange operator内存状态,然后marker被传递到下一个
operator。
• 但maker传递到最终的operator后,即视为一次快照成功。
• 当某个节点任务失败时,将从另一个工作节点上根据快照重新创
建任务。Pipeline将从最后一个快照处恢复,从而避免重头开始
执行。
�
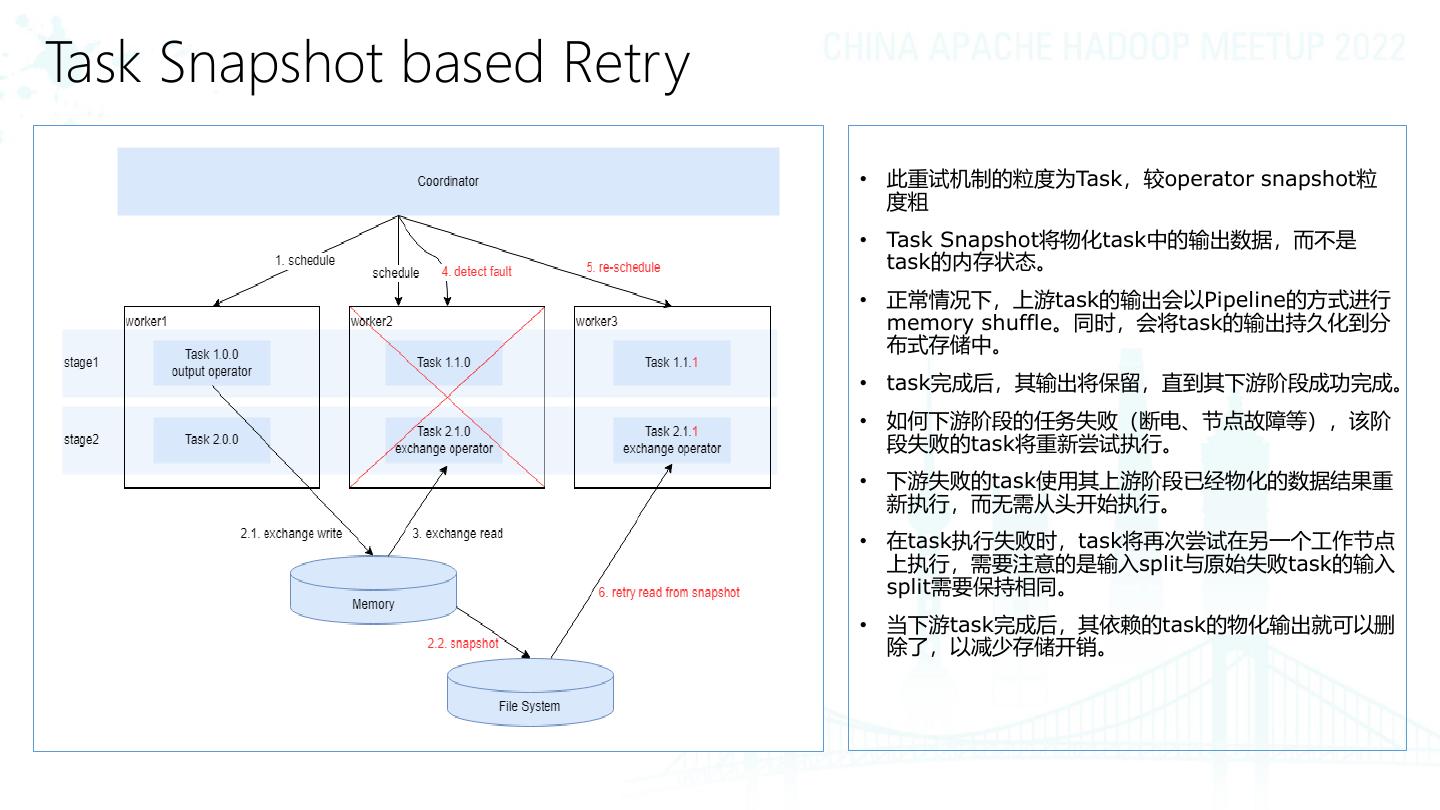
10 .Task Snapshot based Retry
• 此重试机制的粒度为Task,较operator snapshot粒
度粗
• Task Snapshot将物化task中的输出数据,而不是
task的内存状态。
• 正常情况下,上游task的输出会以Pipeline的方式进行
memory shuffle。同时,会将task的输出持久化到分
布式存储中。
• task完成后,其输出将保留,直到其下游阶段成功完成。
• 如何下游阶段的任务失败(断电、节点故障等),该阶
段失败的task将重新尝试执行。
• 下游失败的task使用其上游阶段已经物化的数据结果重
新执行,而无需从头开始执行。
• 在task执行失败时,task将再次尝试在另一个工作节点
上执行,需要注意的是输入split与原始失败task的输入
split需要保持相同。
• 当下游task完成后,其依赖的task的物化输出就可以删
除了,以减少存储开销。
�