








- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 视频嵌入链接 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
高效的数据优化在腾讯的实践应用-刘献杨

刘献杨-腾讯高级工程师
就职于腾讯实时湖仓团队,参与数据湖的构建和优化,活跃于Apache Iceberg/Spark/Parquet社区。
分享介绍:
在腾讯,目前日均约40万亿的数据通过不同的方式流入到Iceberg中。我们围绕Iceberg的表管理构建了数据湖的优化服务,提供了小文件合并,索引构建,优化文件组织结构,文件生命周期管理,列的生命周期管理,表优化参数建议,垃圾文件清理等优化服务。在生产实践中,我们发现随着文件量的不断增加,表管理所需要的计算成本也不断增加,因此本次分享中我们将重点介绍我们如何结合文件的本身特点实现高效的数据优化,大幅降低优化服务所需的计算成本。
展开查看详情
1 .高效数据优化在腾讯的实践应用 刘献杨-腾讯高级软件工程师 1
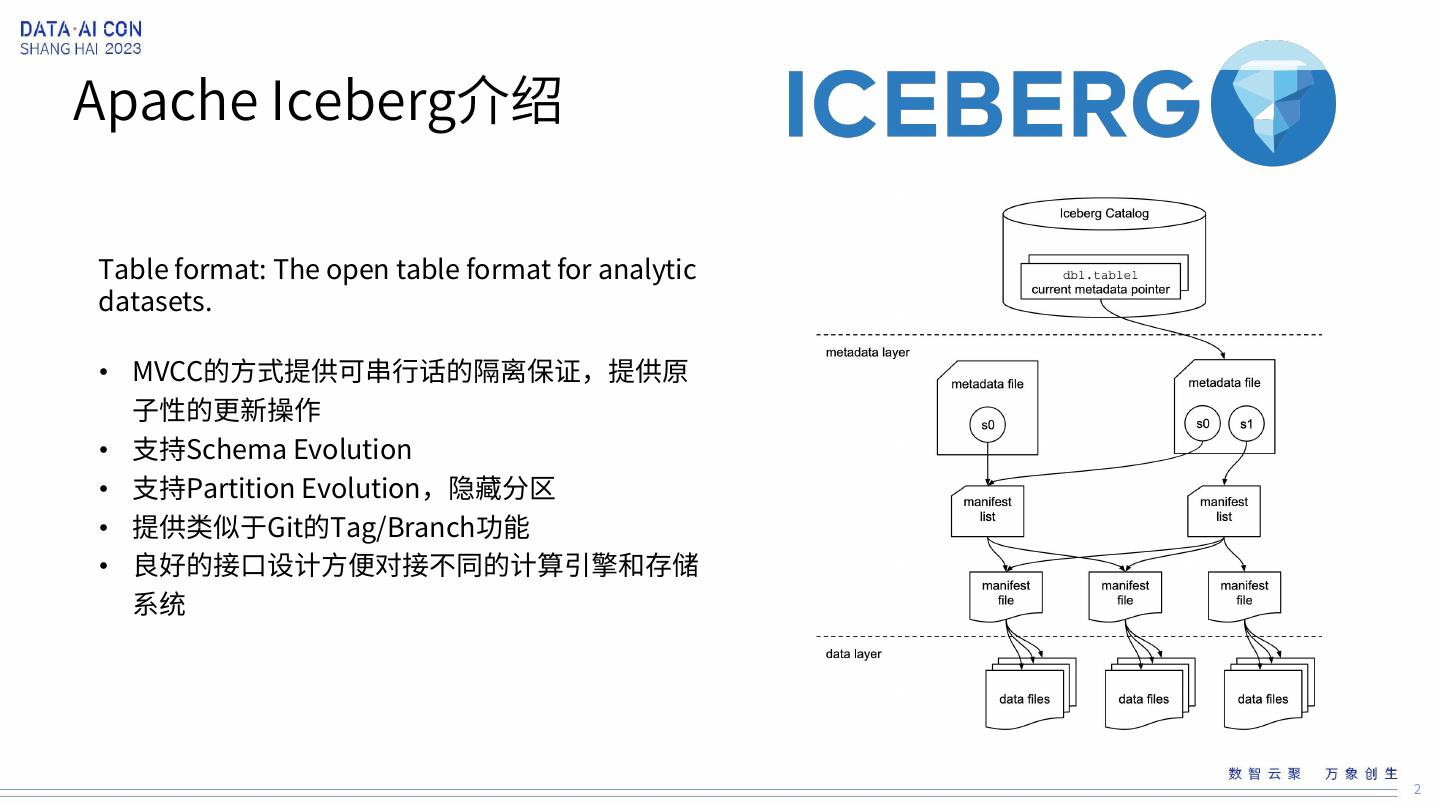
2 .Apache Iceberg介绍 Table format: The open table format for analytic datasets. • MVCC的方式提供可串行话的隔离保证,提供原 子性的更新操作 • 支持Schema Evolution • 支持Partition Evolution,隐藏分区 • 提供类似于Git的Tag/Branch功能 • 良好的接口设计方便对接不同的计算引擎和存储 系统 2
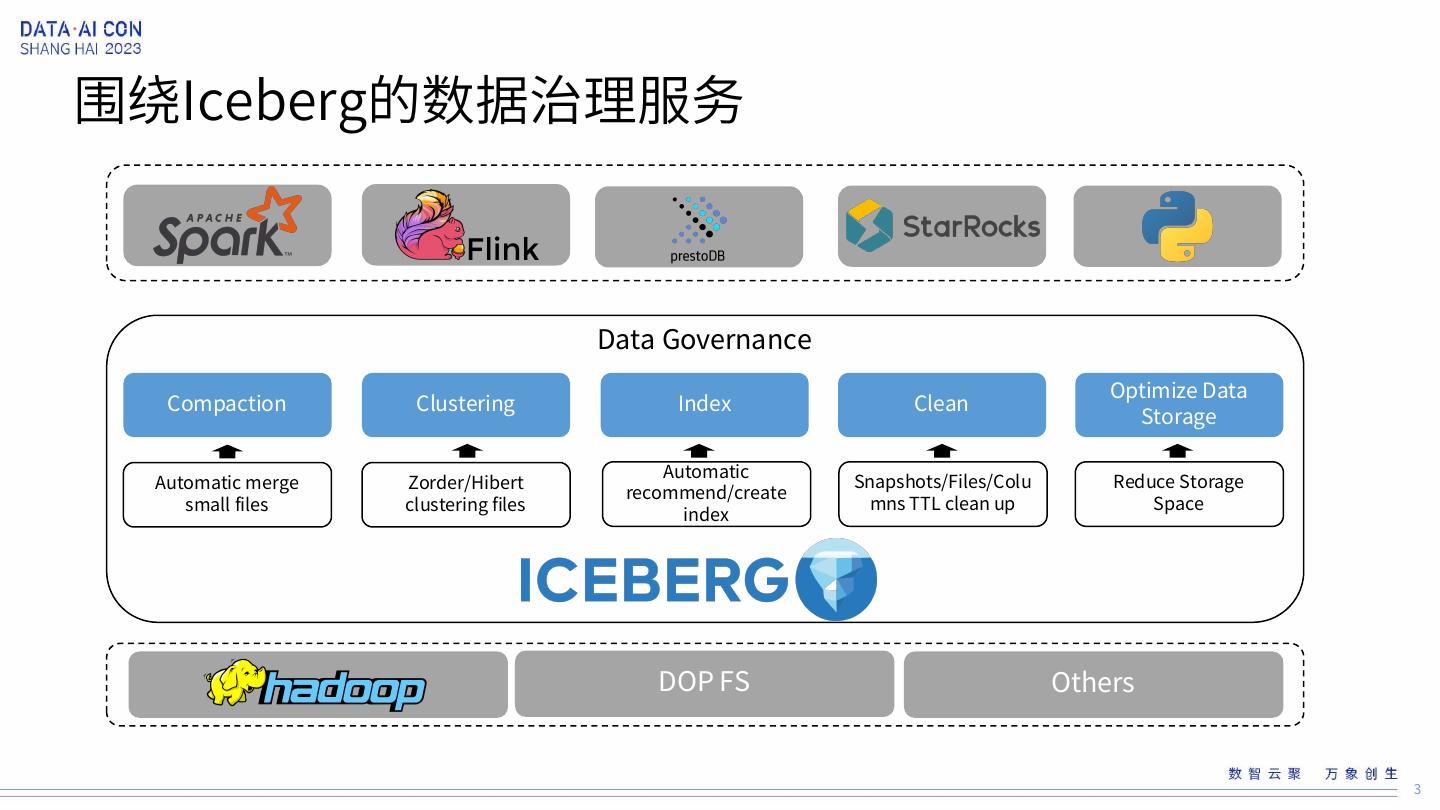
3 .围绕Iceberg的数据治理服务 Data Governance Optimize Data Compaction Clustering Index Clean Storage Automatic Automatic merge Zorder/Hibert Snapshots/Files/Colu Reduce Storage recommend/create small files clustering files mns TTL clean up Space index DOP FS Others 3
4 .列的生命周期 Data Governance column times id 1000 name 900 Scan Metrics address 500 dog_color 7 Table Others Owner 4
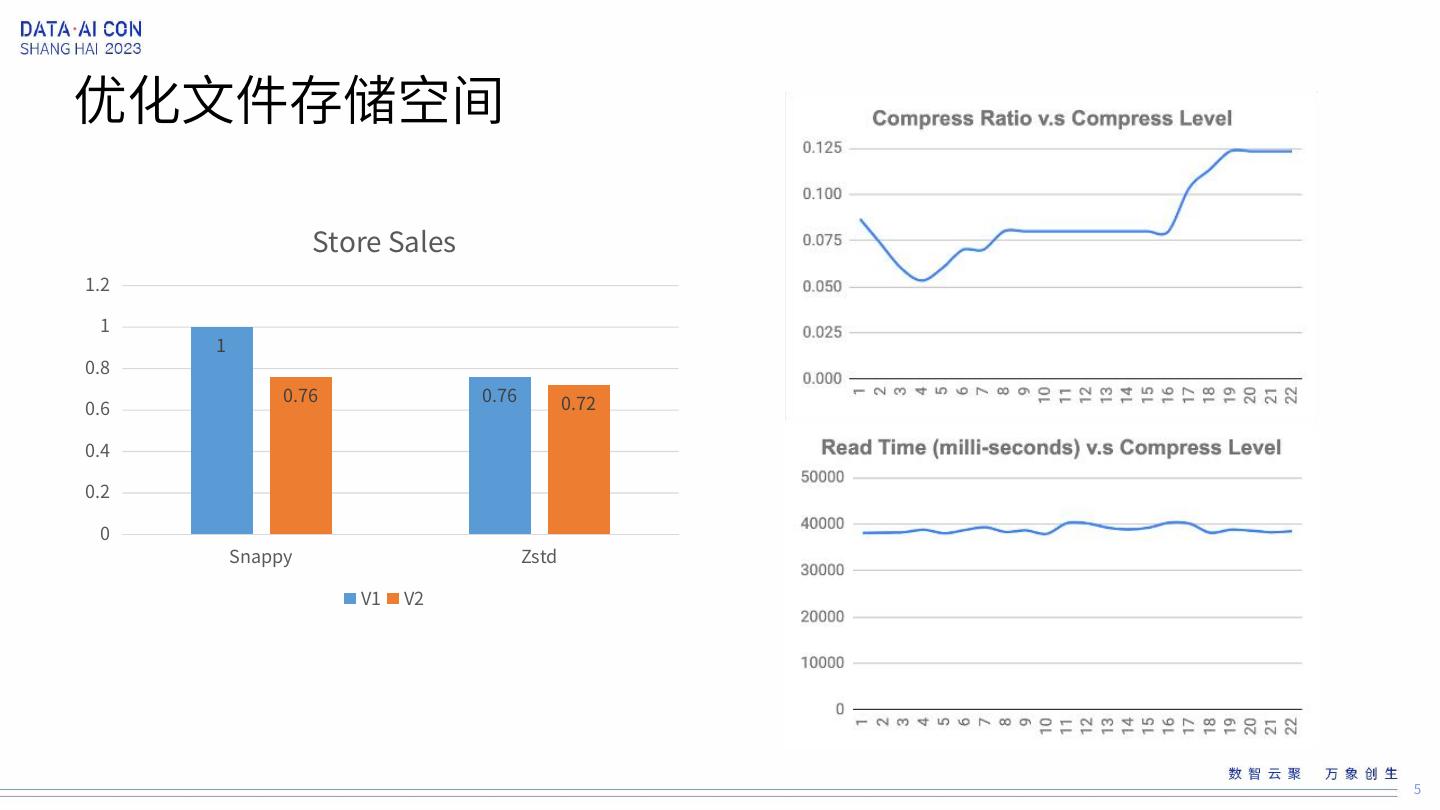
5 .优化文件存储空间 Store Sales 1.2 1 1 0.8 0.76 0.76 0.72 0.6 0.4 0.2 0 Snappy Zstd V1 V2 5
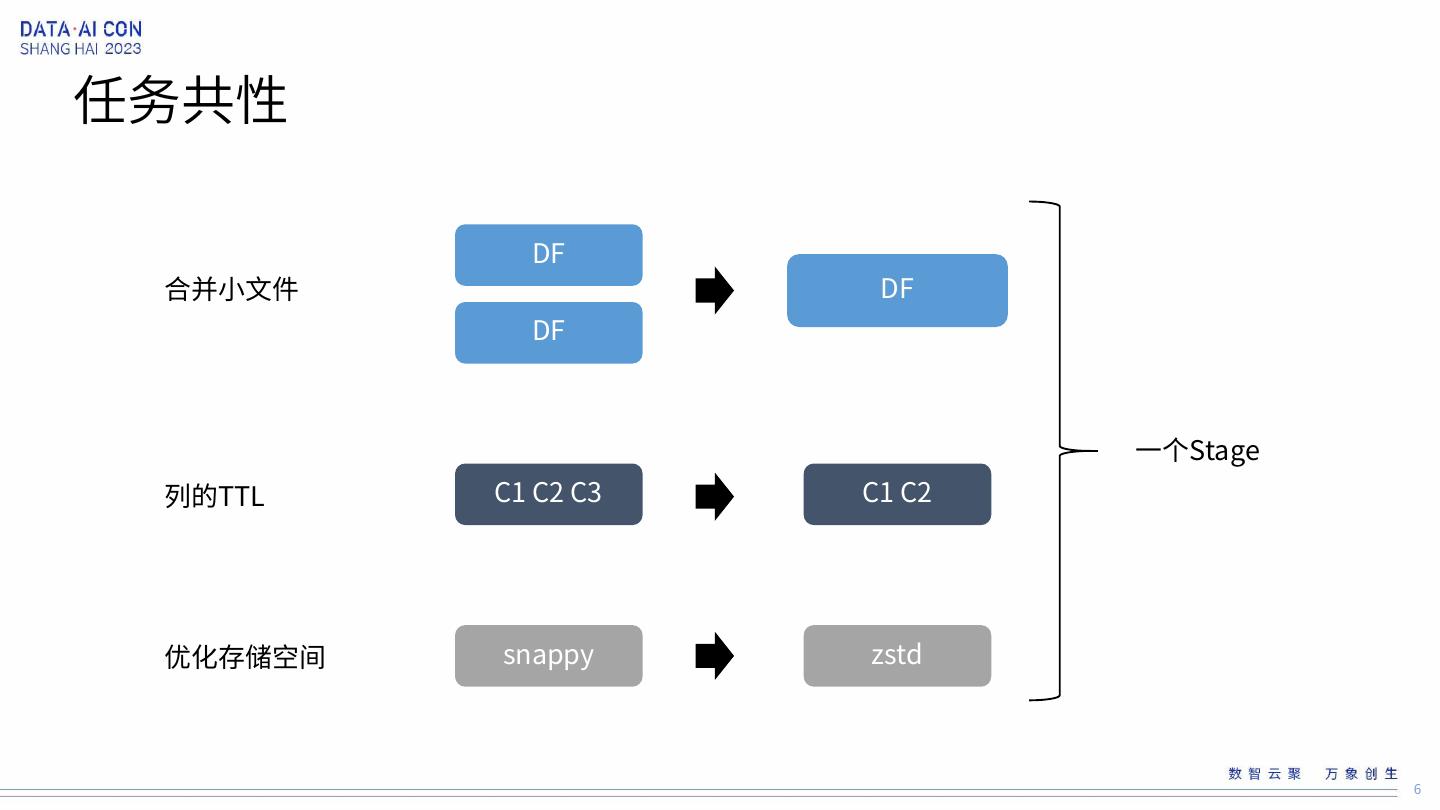
6 .任务共性 DF 合并小文件 DF DF 一个Stage 列的TTL C1 C2 C3 C1 C2 优化存储空间 snappy zstd 6
7 .Rewrite Data Files CALL catalog_name.system.rewrite_data_files( table => 'db.sample’, strategy => ‘binpack’, where => 'id = 3') Planning Read files and Replace and commit generate new files DF1 NDF1 DF2 NDF1 DF3 DF3 NDF2 DF4 NDF2 DF5 7
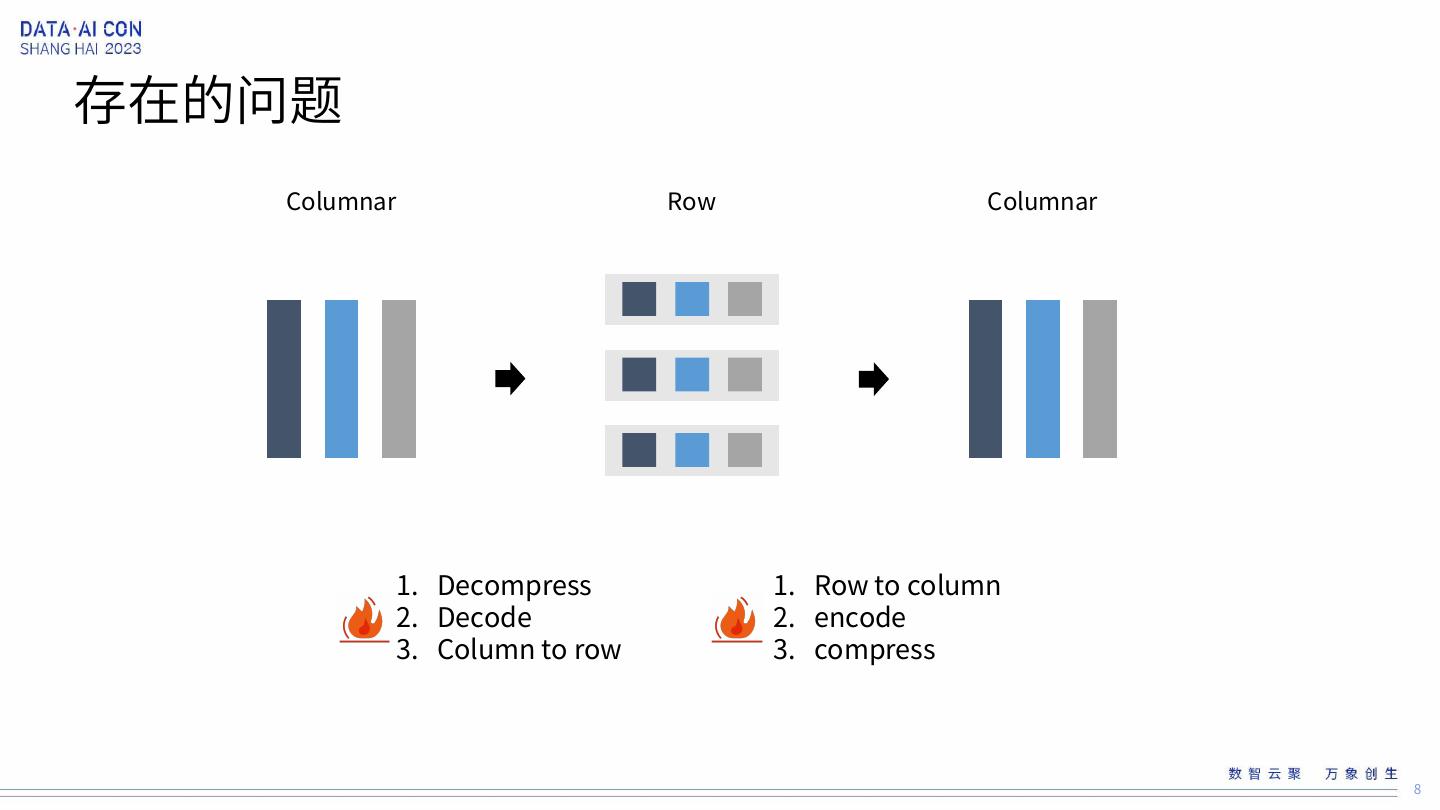
8 .存在的问题 Columnar Row Columnar 1. Decompress 1. Row to column 2. Decode 2. encode 3. Column to row 3. compress 8
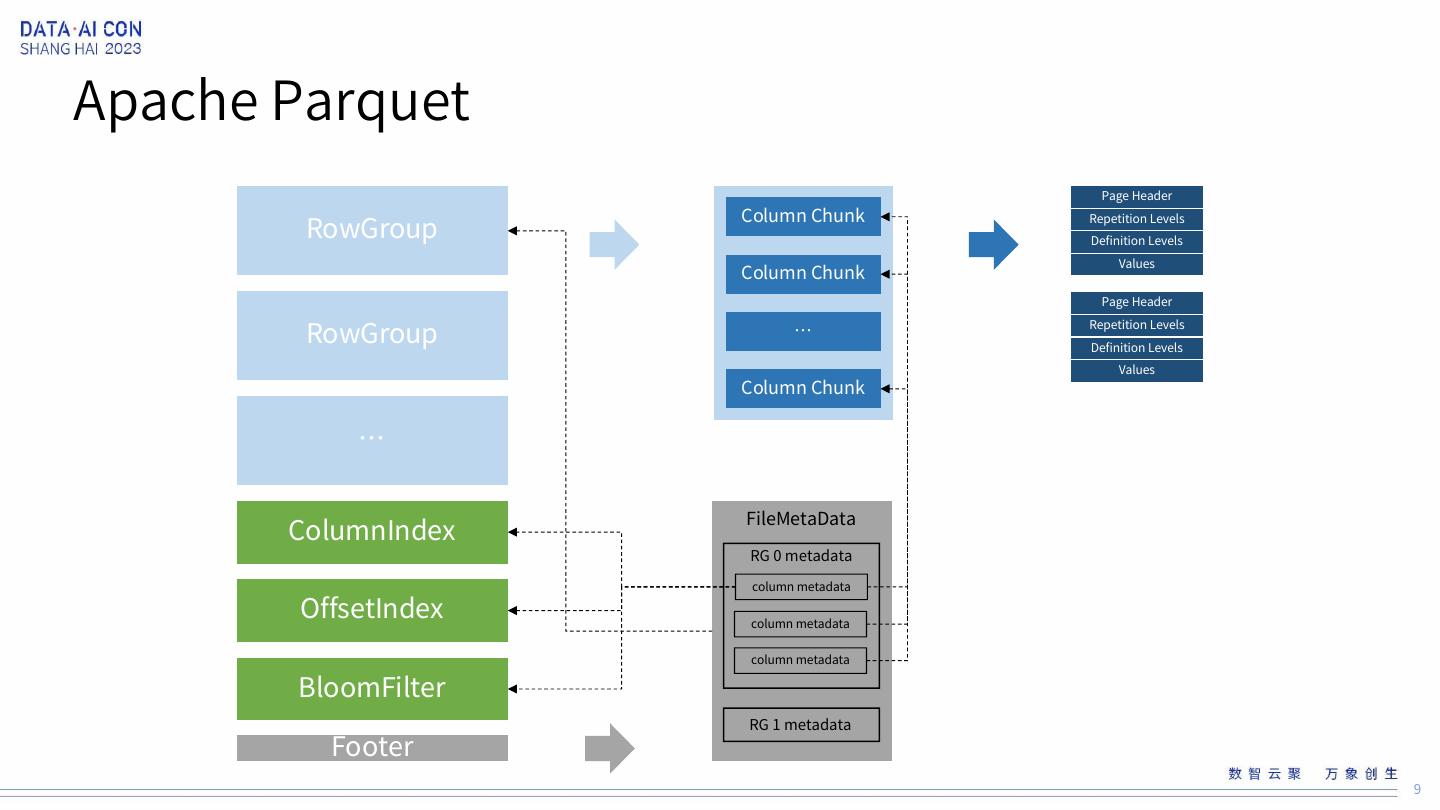
9 .Apache Parquet Page Header Column Chunk RowGroup Repetition Levels Definition Levels Values Column Chunk Page Header RowGroup … Repetition Levels Definition Levels Values Column Chunk … ColumnIndex FileMetaData RG 0 metadata column metadata OffsetIndex column metadata column metadata BloomFilter RG 1 metadata Footer 9
10 .优化方向 Parquet文件的特点和Rewrite Data File任务的特点: BinPack Rewrite Data File是单个Stage的Job,读取文件写出文件,不涉及Shuffle/Sort Table Schema/Partition的变动是小范围的 Parquet 数据和Metadata分开存储 尽可能的减少解压缩/解码/行列转换 RowGroup级别的优化 Page列别的优化 Row级别的优化 10
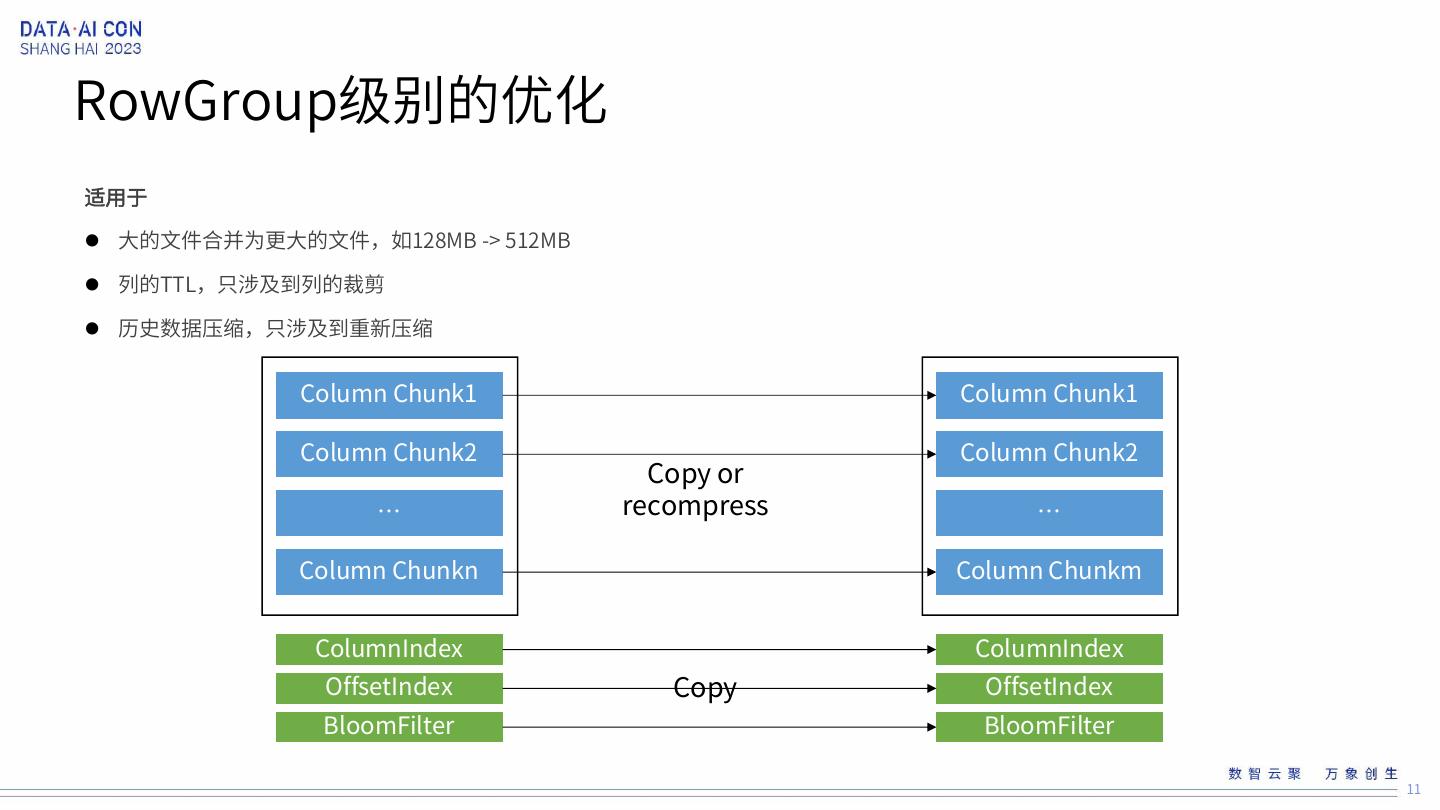
11 .RowGroup级别的优化 适用于 大的文件合并为更大的文件,如128MB -> 512MB 列的TTL,只涉及到列的裁剪 历史数据压缩,只涉及到重新压缩 Column Chunk1 Column Chunk1 Column Chunk2 Column Chunk2 Copy or … recompress … Column Chunkn Column Chunkm ColumnIndex ColumnIndex OffsetIndex Copy OffsetIndex BloomFilter BloomFilter 11
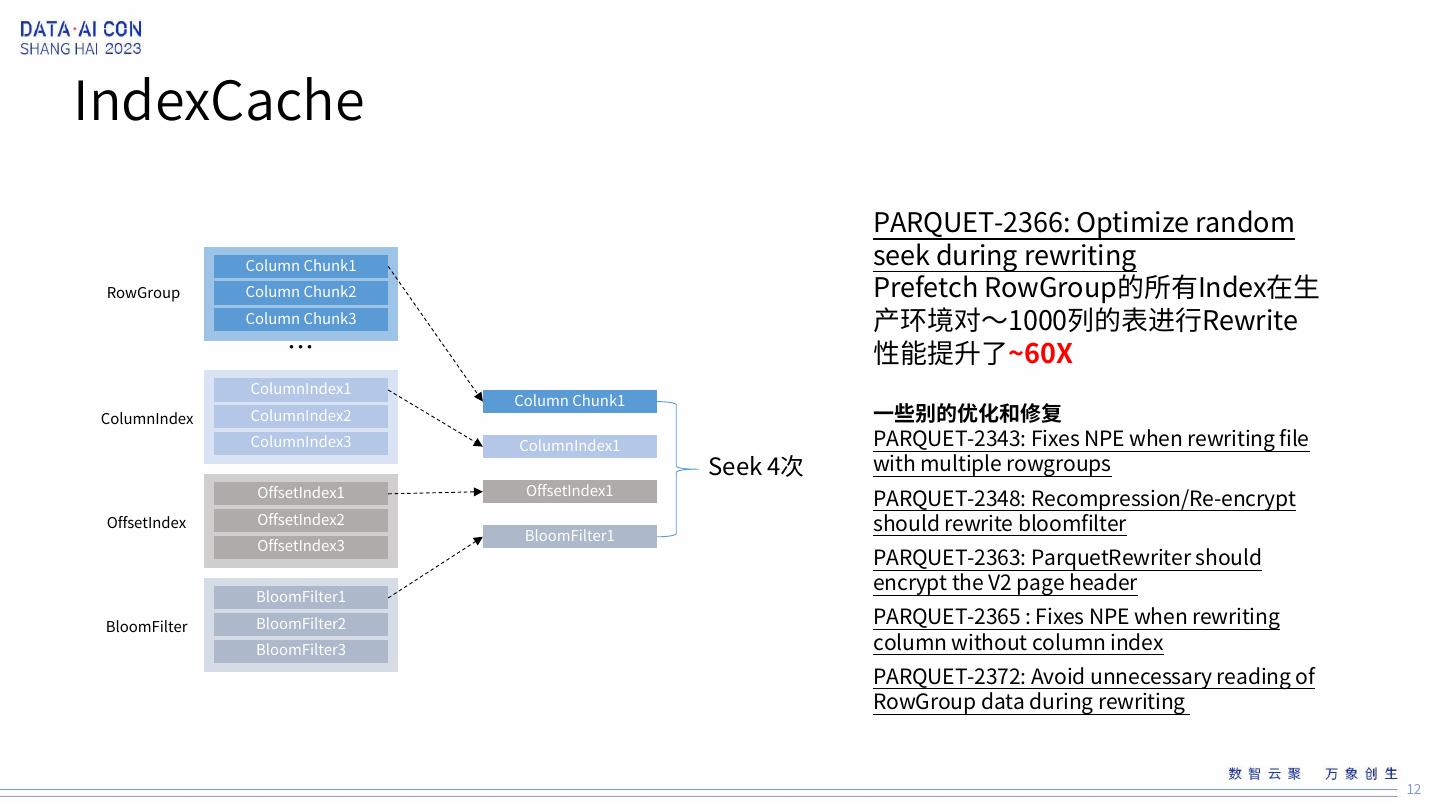
12 .IndexCache PARQUET-2366: Optimize random Column Chunk1 seek during rewriting RowGroup Column Chunk2 Prefetch RowGroup的所有Index在生 Column Chunk3 产环境对~1000列的表进行Rewrite … 性能提升了~60X ColumnIndex1 Column Chunk1 ColumnIndex ColumnIndex2 一些别的优化和修复 ColumnIndex3 ColumnIndex1 PARQUET-2343: Fixes NPE when rewriting file Seek 4次 with multiple rowgroups OffsetIndex1 OffsetIndex1 PARQUET-2348: Recompression/Re-encrypt OffsetIndex OffsetIndex2 BloomFilter1 should rewrite bloomfilter OffsetIndex3 PARQUET-2363: ParquetRewriter should encrypt the V2 page header BloomFilter1 BloomFilter BloomFilter2 PARQUET-2365 : Fixes NPE when rewriting BloomFilter3 column without column index PARQUET-2372: Avoid unnecessary reading of RowGroup data during rewriting 12
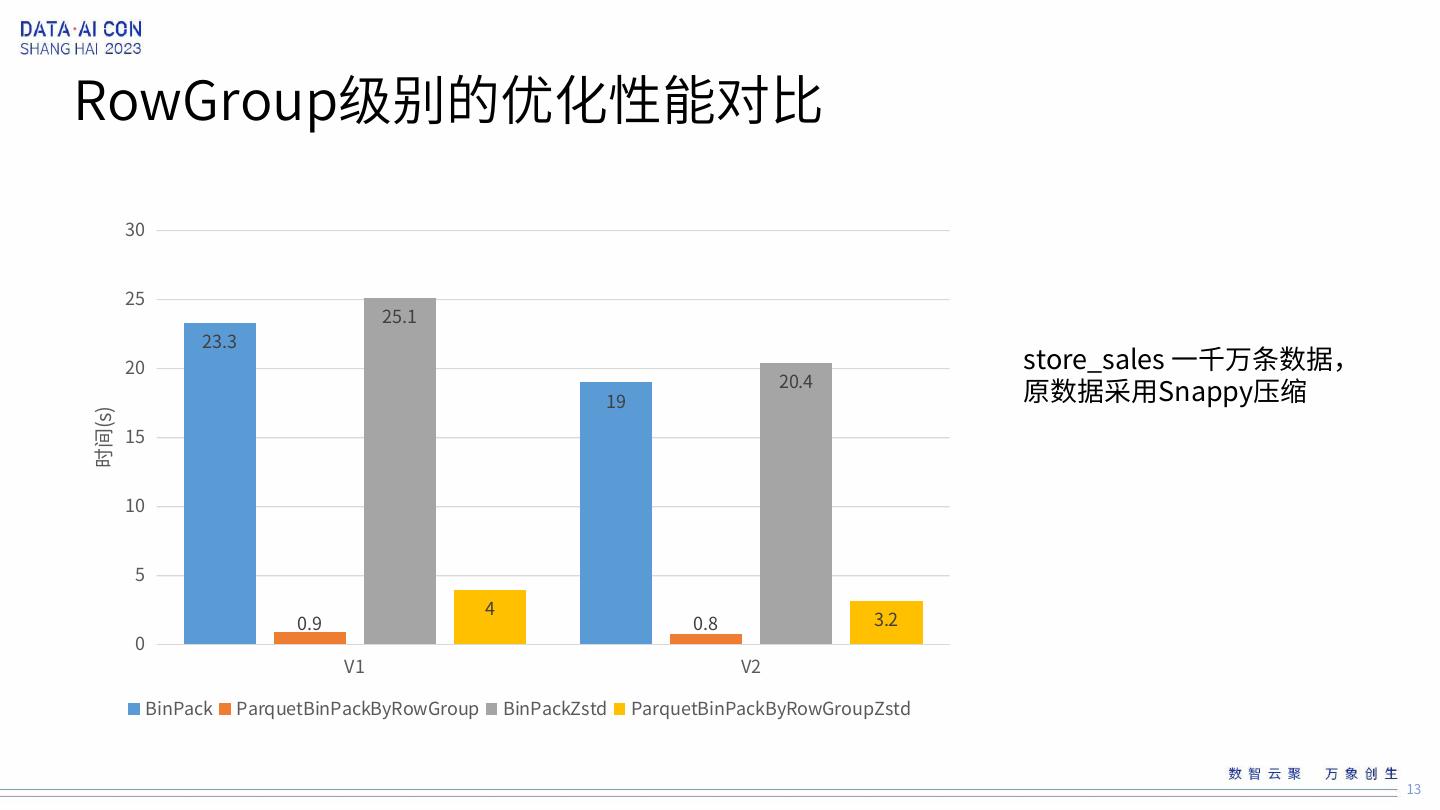
13 .RowGroup级别的优化性能对比 30 25 25.1 23.3 20 store_sales 一千万条数据, 19 20.4 原数据采用Snappy压缩 时间(s) 15 10 5 4 0.9 0.8 3.2 0 V1 V2 BinPack ParquetBinPackByRowGroup BinPackZstd ParquetBinPackByRowGroupZstd 13
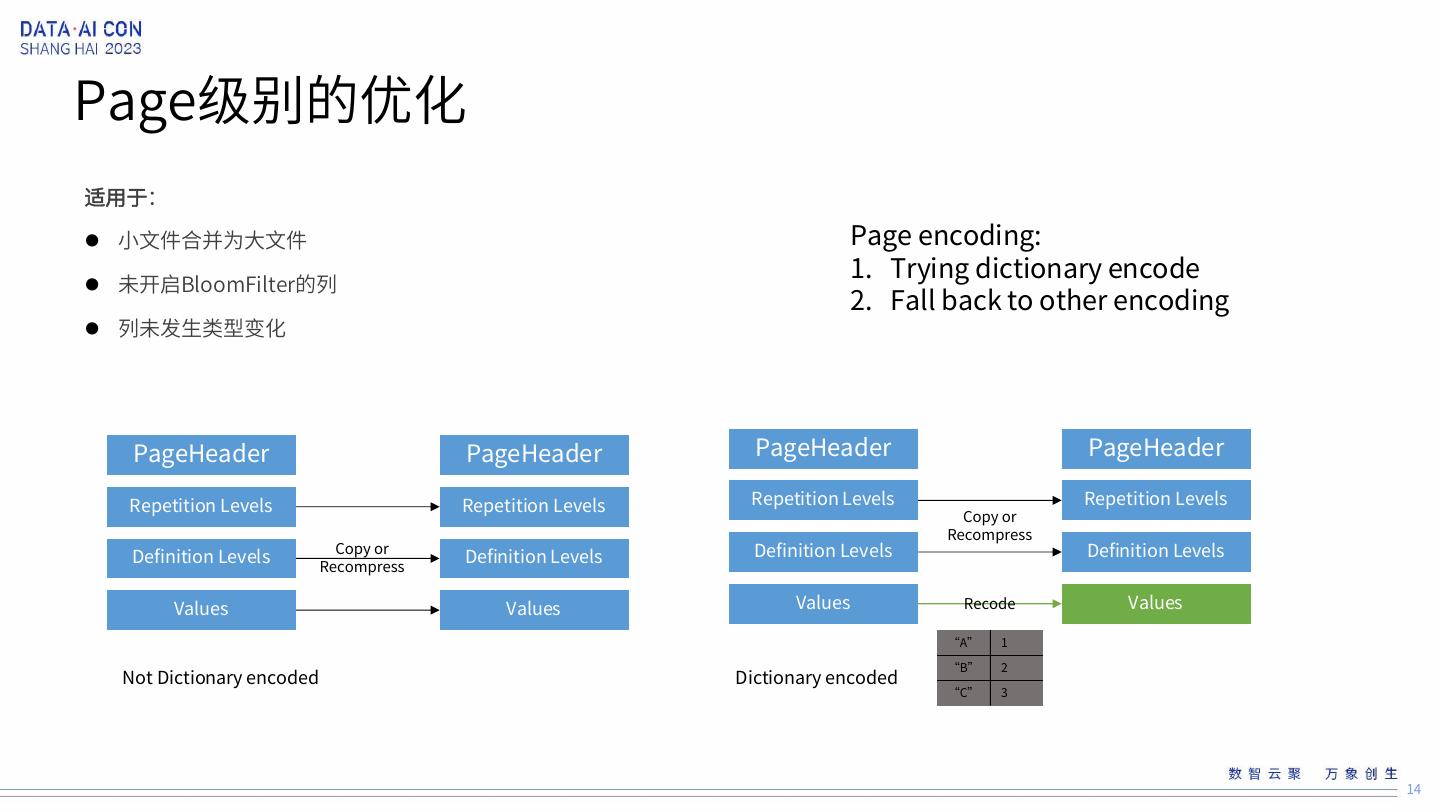
14 .Page级别的优化 适用于: 小文件合并为大文件 Page encoding: 1. Trying dictionary encode 未开启BloomFilter的列 2. Fall back to other encoding 列未发生类型变化 PageHeader PageHeader PageHeader PageHeader Repetition Levels Repetition Levels Repetition Levels Repetition Levels Copy or Recompress Definition Levels Copy or Definition Levels Definition Levels Definition Levels Recompress Values Values Values Recode Values “A” 1 “B” 2 Not Dictionary encoded Dictionary encoded “C” 3 14
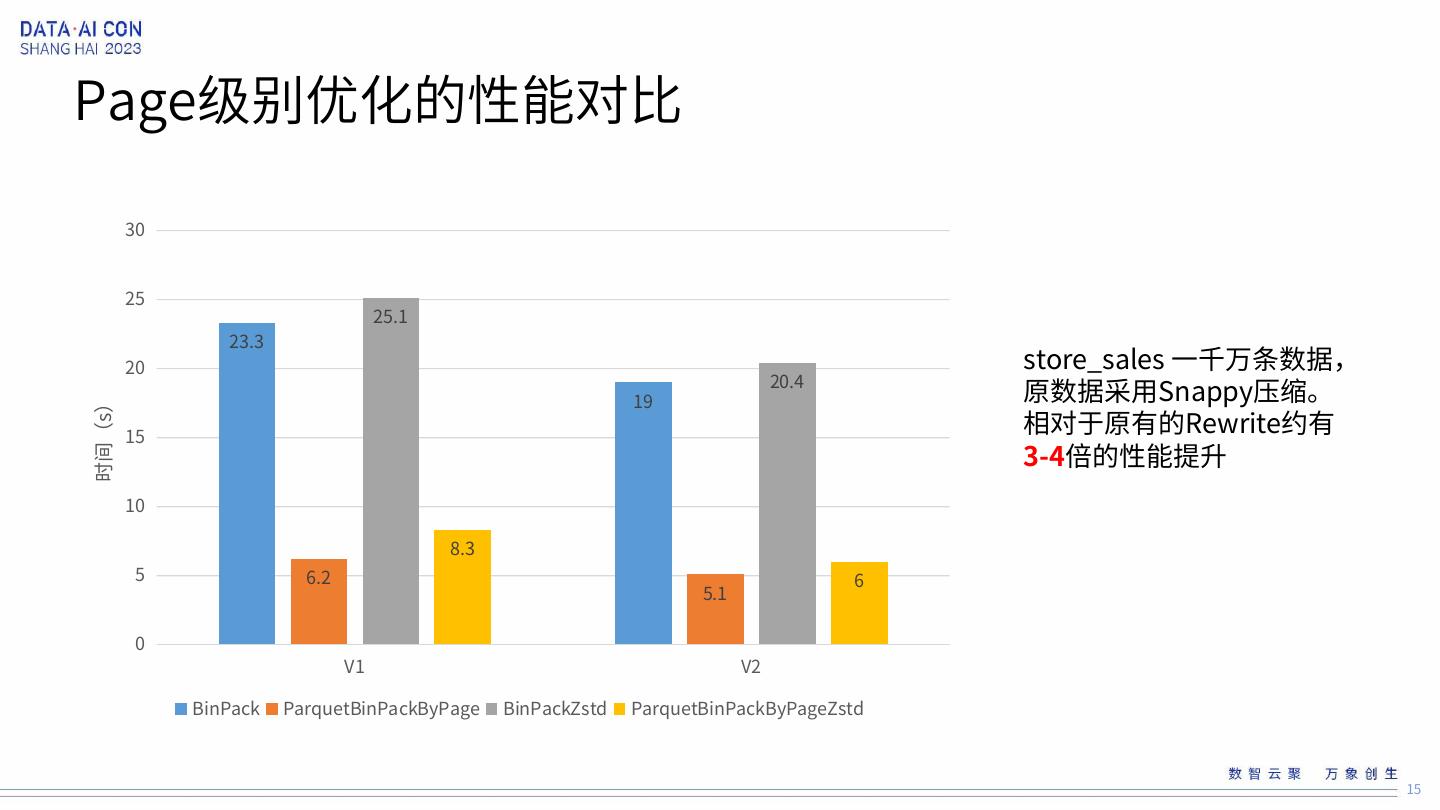
15 .Page级别优化的性能对比 30 25 25.1 23.3 20 store_sales 一千万条数据, 19 20.4 原数据采用Snappy压缩。 相对于原有的Rewrite约有 时间(s) 15 3-4倍的性能提升 10 8.3 5 6.2 6 5.1 0 V1 V2 BinPack ParquetBinPackByPage BinPackZstd ParquetBinPackByPageZstd 15
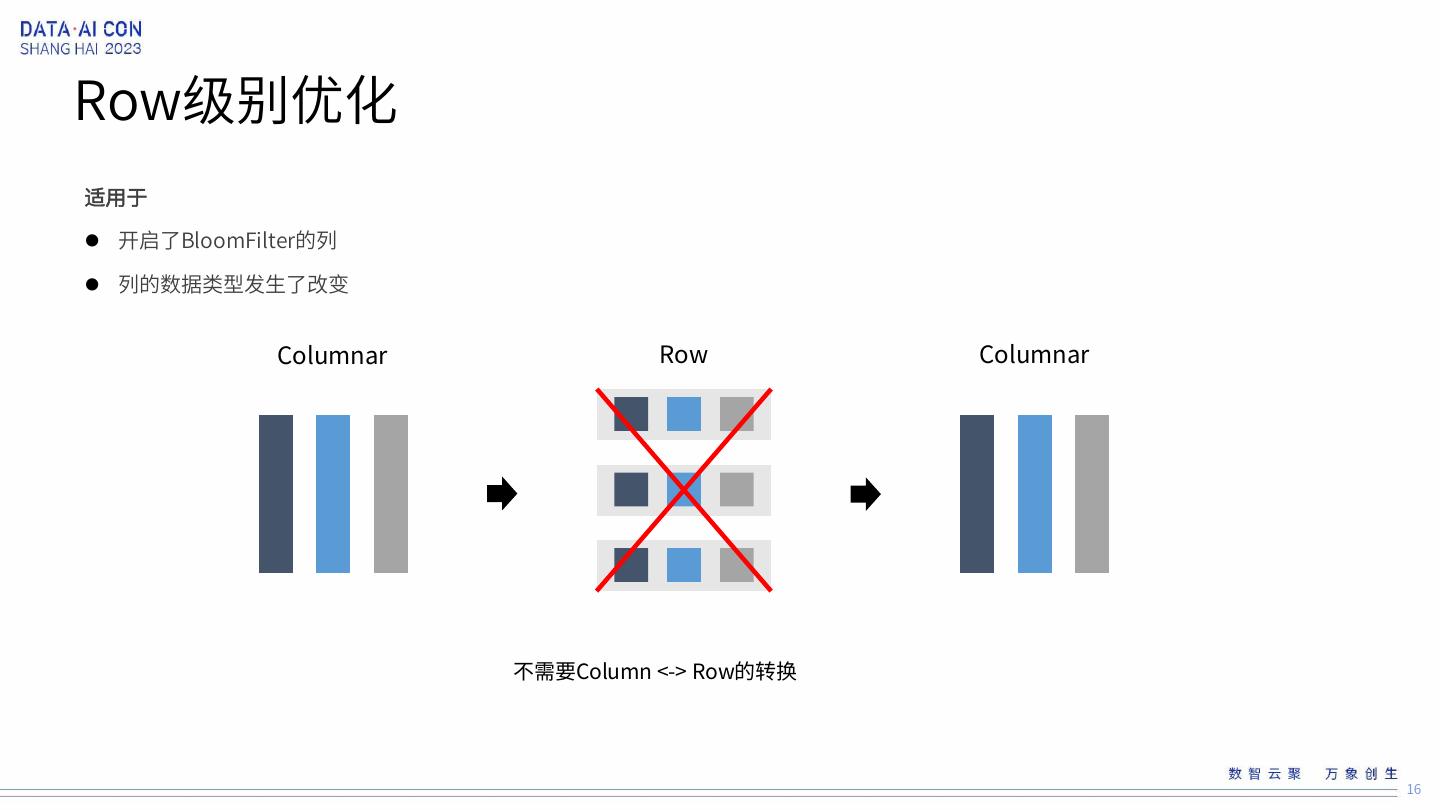
16 .Row级别优化 适用于 开启了BloomFilter的列 列的数据类型发生了改变 Columnar Row Columnar 不需要Column <-> Row的转换 16
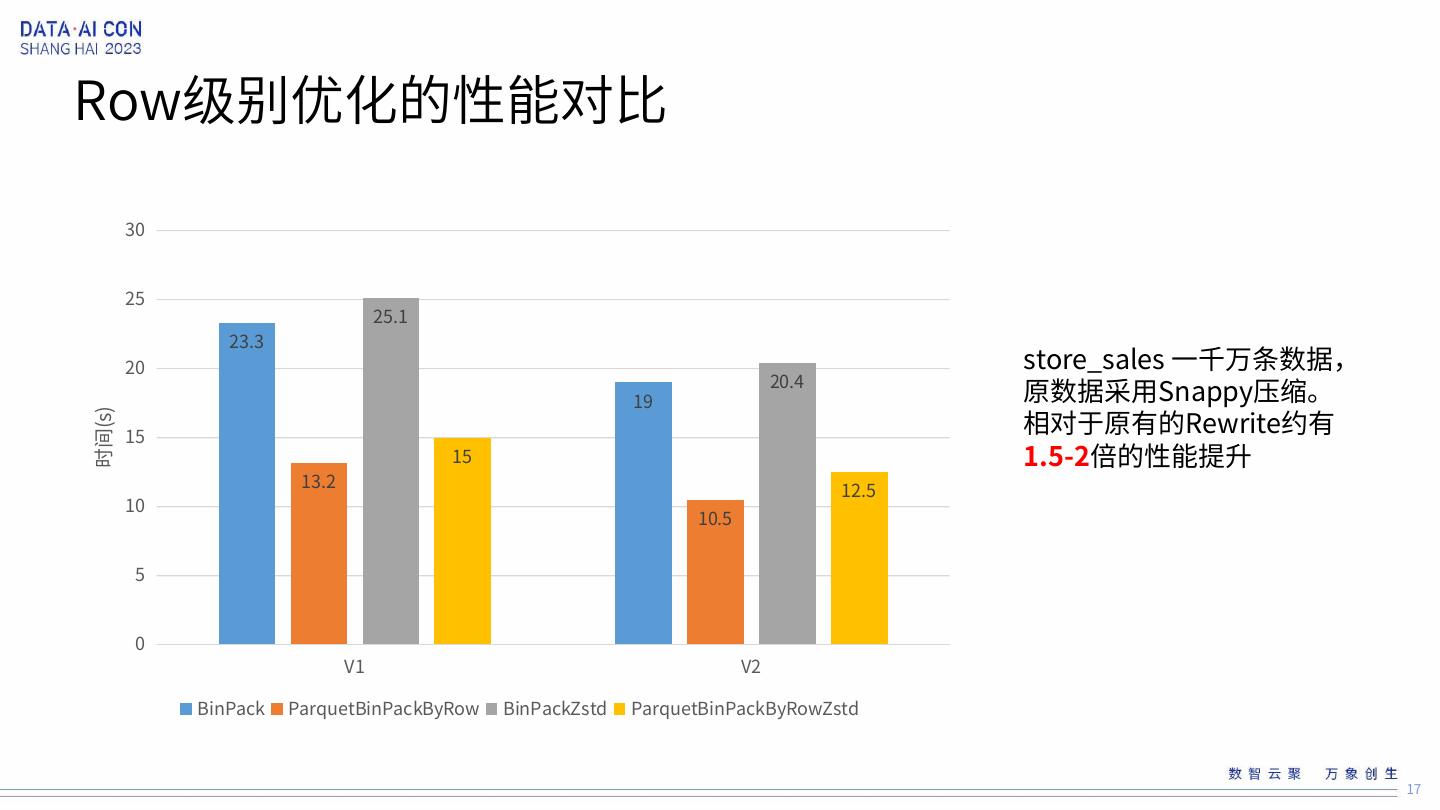
17 .Row级别优化的性能对比 30 25 25.1 23.3 20 store_sales 一千万条数据, 19 20.4 原数据采用Snappy压缩。 相对于原有的Rewrite约有 时间(s) 15 15 1.5-2倍的性能提升 13.2 12.5 10 10.5 5 0 V1 V2 BinPack ParquetBinPackByRow BinPackZstd ParquetBinPackByRowZstd 17
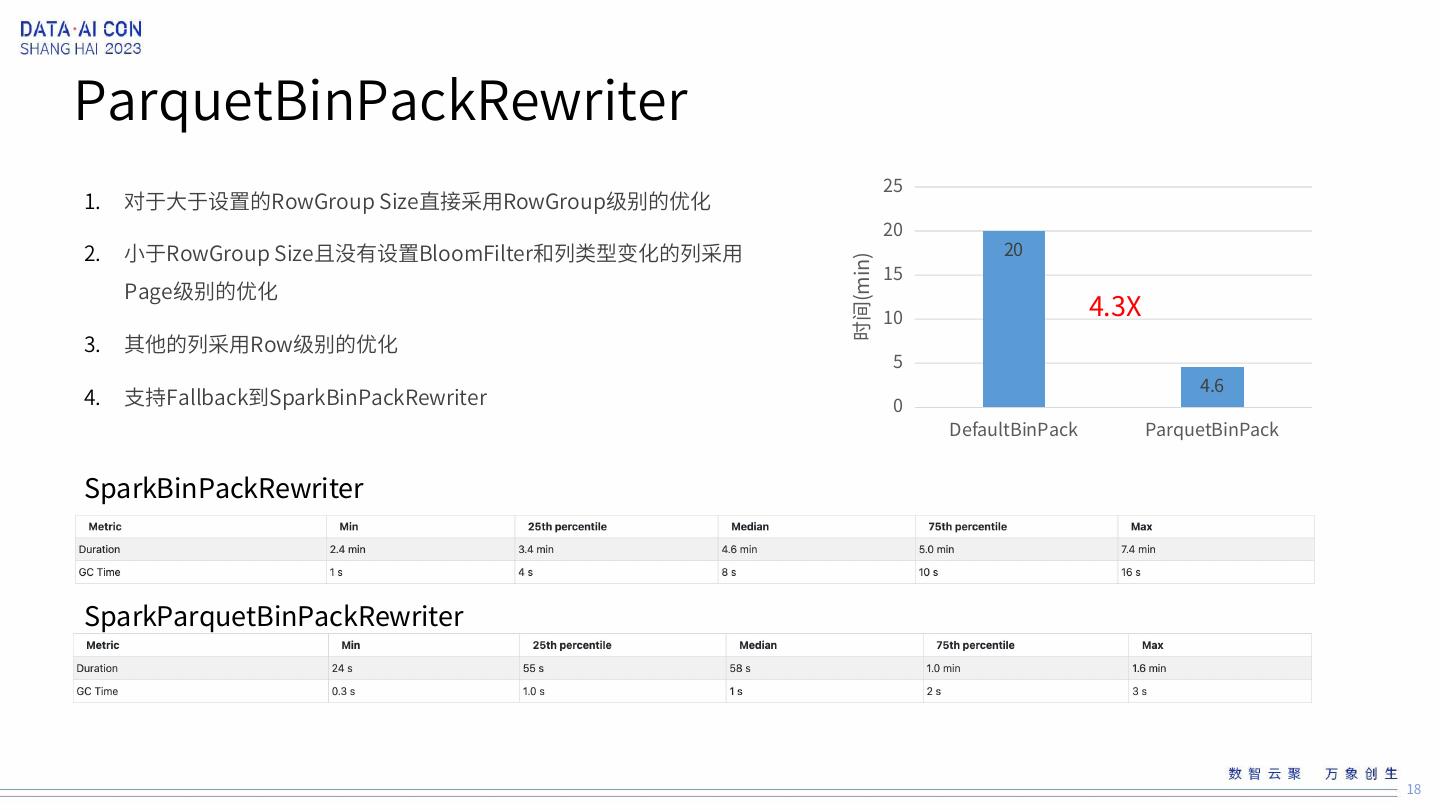
18 .ParquetBinPackRewriter 25 1. 对于大于设置的RowGroup Size直接采用RowGroup级别的优化 20 2. 小于RowGroup Size且没有设置BloomFilter和列类型变化的列采用 20 15 时间(min) Page级别的优化 10 4.3X 3. 其他的列采用Row级别的优化 5 4.6 4. 支持Fallback到SparkBinPackRewriter 0 DefaultBinPack ParquetBinPack SparkBinPackRewriter SparkParquetBinPackRewriter 18
19 .未来优化 1. MOR/COW同样存在于很多不必要的数据处理操作 2. Native加速Parquet解码 19
20 .20
3秒后跳转登录页面
去登陆

