展开查看详情
1 .Alibaba Cloud MongoDB
looks inside
2018.12.01
�
2 .Agenda
u What’s the pain in MongoDB & best practice
u MongoDB improvement at AliCloud
u Valuable Services at AliCloud
�
3 . About Me
{
"name": " ",
"company": "Alibaba Aliyun",
"title": "NoSQL database developer",
"work": "MongoDB kernel develop and services",
"interests": ["MongoDB", "MySQL", "Rocksdb", ”TiDB"],
"team": {
"responsibility": "support public & internal NoSQL database",
"contributes": "over 15 pull requests and issue in 2016"
},
"find_me": "https://www.facebook.com/michaelliuxin"
}
�
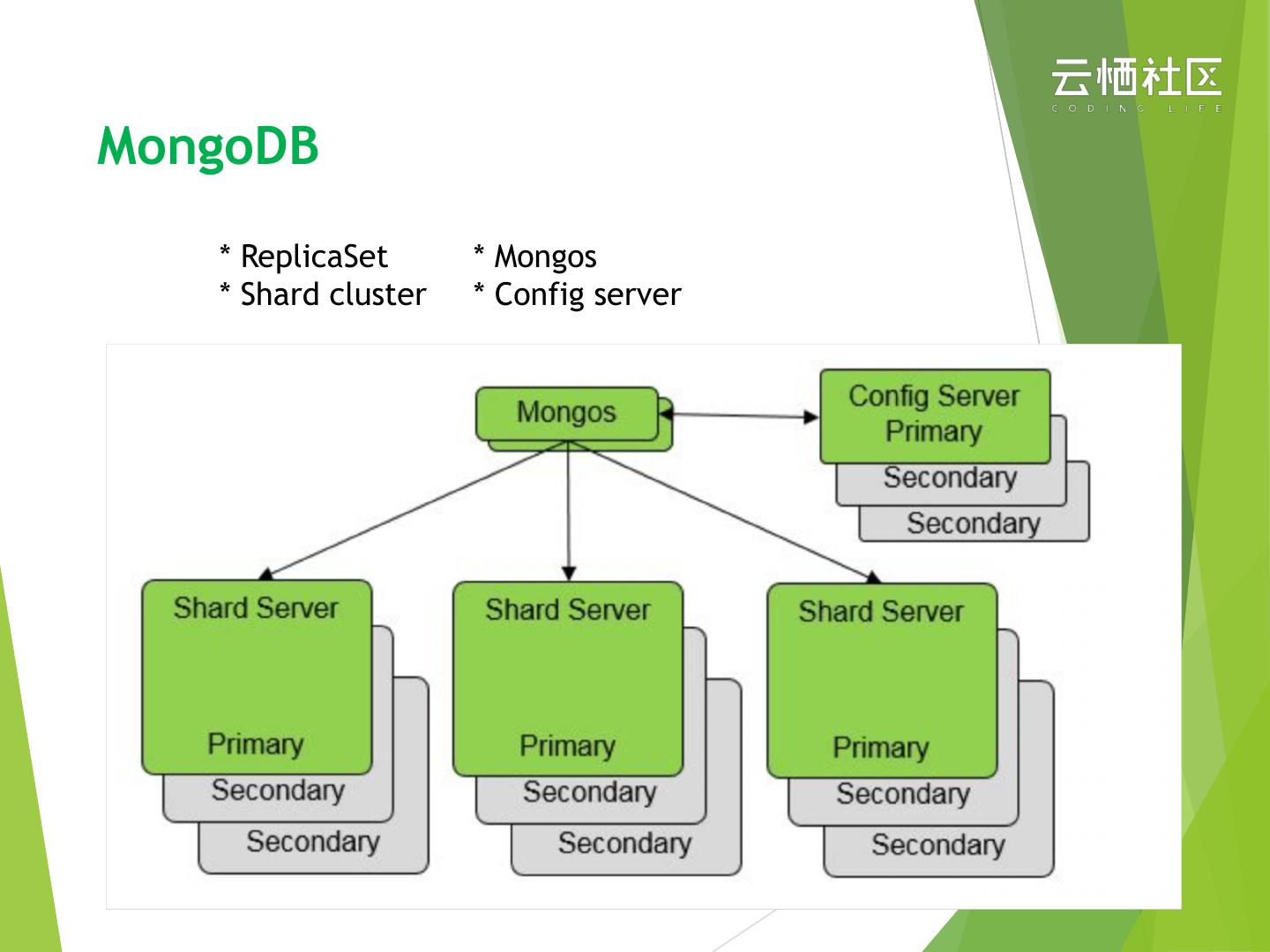
5 .MongoDB
* ReplicaSet * Mongos
* Shard cluster * Config server
�
7 .Painful
u Short connection
u hard to optimize & Too much Parameters:
directoryPerDB cacheSizeGB
journal.enabled, oplogSize
u Read(Write)Preference / Read(Write)Majority
�
8 .Improvements
u Rewrite AUTH logical code. abandon /dev/urandom usages
u DON’T use local & admin & config
u cacheSize uses fixed size
u journal is always true
u WriteMajority for significant data. ReadMajority for non-rollback data
�
9 .Painful – how to deploy (long-term)
u Why to using ReplicaSet ? Why Sharding ?
u Evaluation: capacity, IO, CPUs
u Correct MongoDB connection string
u Use WiredTiger as default engine or else
Feature wiredtiger mmapv1
Lock granularity Document level Collection level
Write performance Excellent Good
Read performance Excellent Excellent
Compression Yes (snappy, zlib…) No
support
�
10 .Improvements & Suggestion
u Use Shard cluster only if you need
u Secondary / Hidden / Arbiter best usages
u WiredTiger can support 95% workload. Forget MMap please
u Make specification upgrade easier than easy
u connection string use vip to avoid updating configuration
u oplog adaptive size (conform to replication)
�
11 .Painful – how to scale
u Efficient Hash or Range sharding
u How to choose a proper ShardKey
u Add secondary
�
12 .Improvements & Suggestion
u Think seriously about Hash or Range. (Hot Server)
u ShardKey => cardinality & frequency. (avoid balancing)
u Adding new Secondary via recovery. from backup
u Rebuild a exist Secondary via recovery. from backup
�
13 .Painful – Understand your Query
u Explain()
u update, delete, find
u which indexes were used
u covered index (for projection)
u slow Query stats
u Optimizer
u IDHack, Fetcher, IXScan, CollScan
�
14 .Improvements & Suggestion
u No more fields should be fetched than exactly you need
u Collects slow queries and monitoring
u Indexing analyze. Remove non-used indexes for IO/Optimizer
�
15 .Painful – Profiling your DB
u Monitor
u hardware
u conn, driver, read queue
u replication
u storage (cache, session)
u Audit
u CRUD, DDL, Authentic
u Statement & latency & Time
�
16 .Suggestion
u Inspect everything you should care about
u Prometheus or Grafana integration
u Indexing analyze. only DON’T create useless index
(write sensitive)
�
17 .Painful – Backup your data
u Tools : restore, dump
u Full-Backup & Incremental-Backup
u Physical and Logical Backup
u Hot & Cold
�
18 .Improvements & Suggestion
u fine grained backup policy
u mongodump “—oplog” is always set.
u mongorestore can be resume for large dataset.
u Hot-Physical backup’s performance is 3x~100x faster:
u 1). WiredTiger checkpoint. physical files copy.
u 2). Improve official checkpoint performance.
�
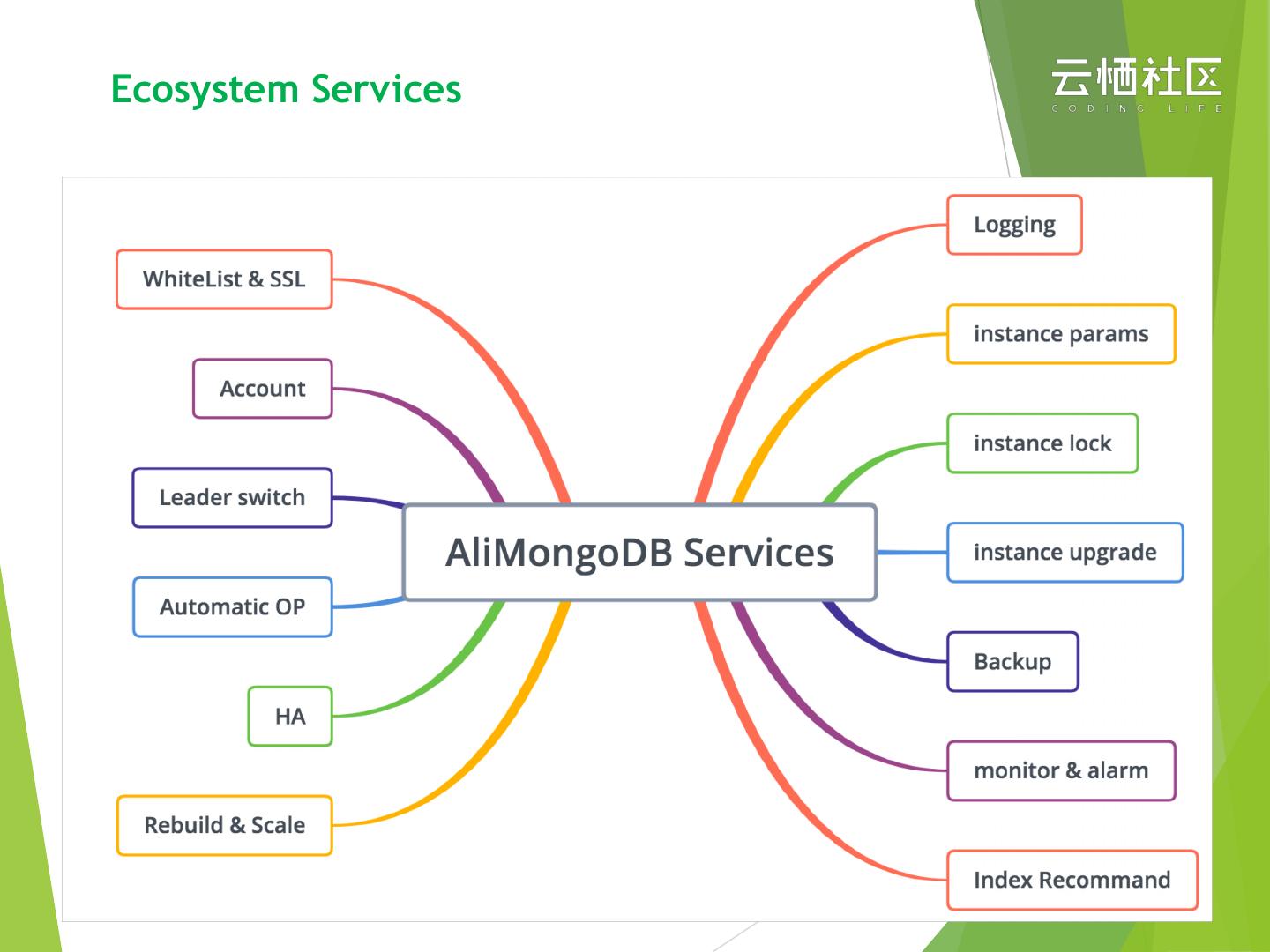
19 .MongoDB Cloud Services
�
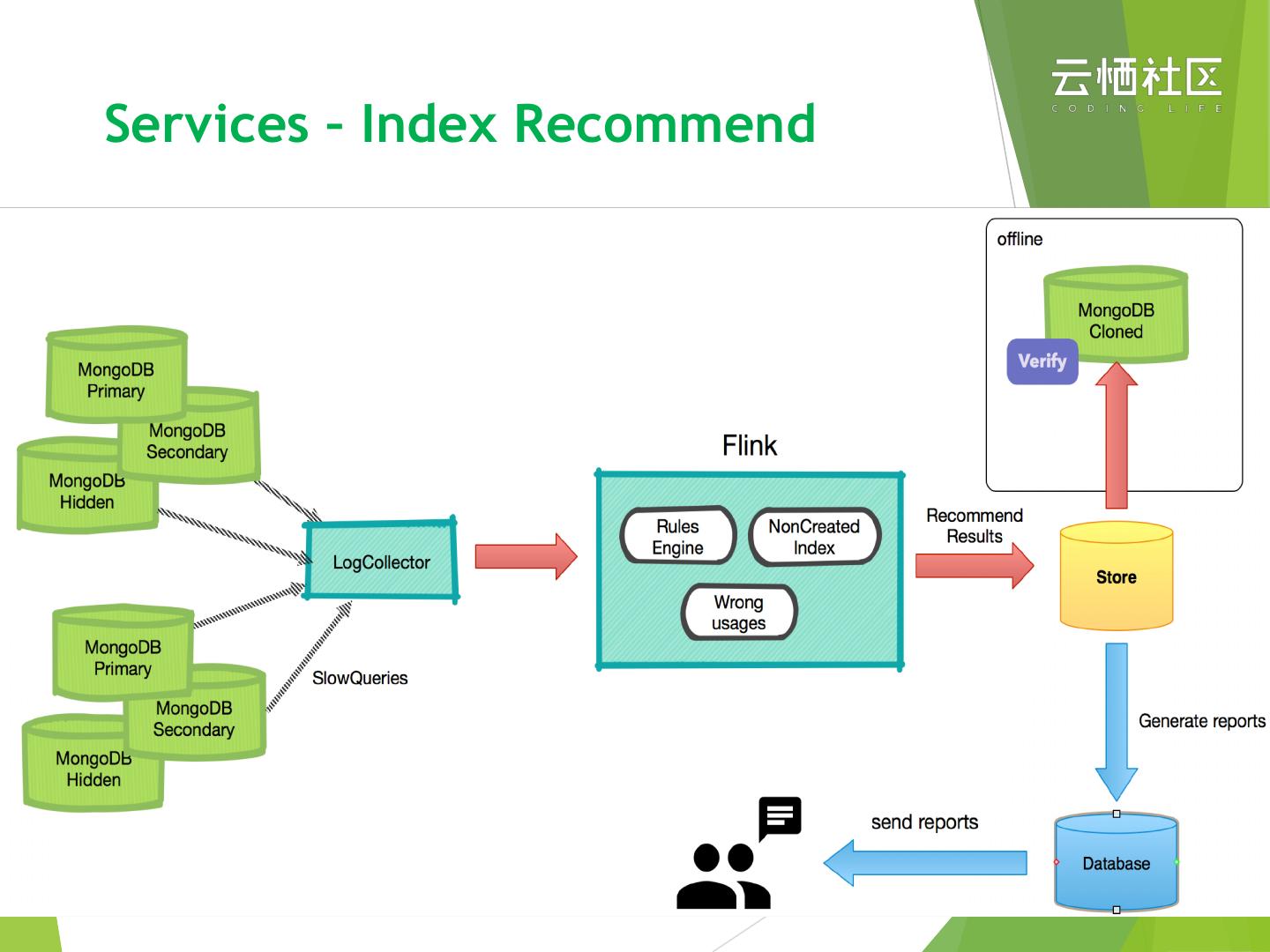
21 .Services – Index Recommend
https://help.aliyun.com/document_detail/98239.html
u Collects slow quires as sample
u Rules based indexing analyze
u Generate detail reports and the clear recommends
u Without build indexes automatically
�
22 .Services – Index Recommend
�
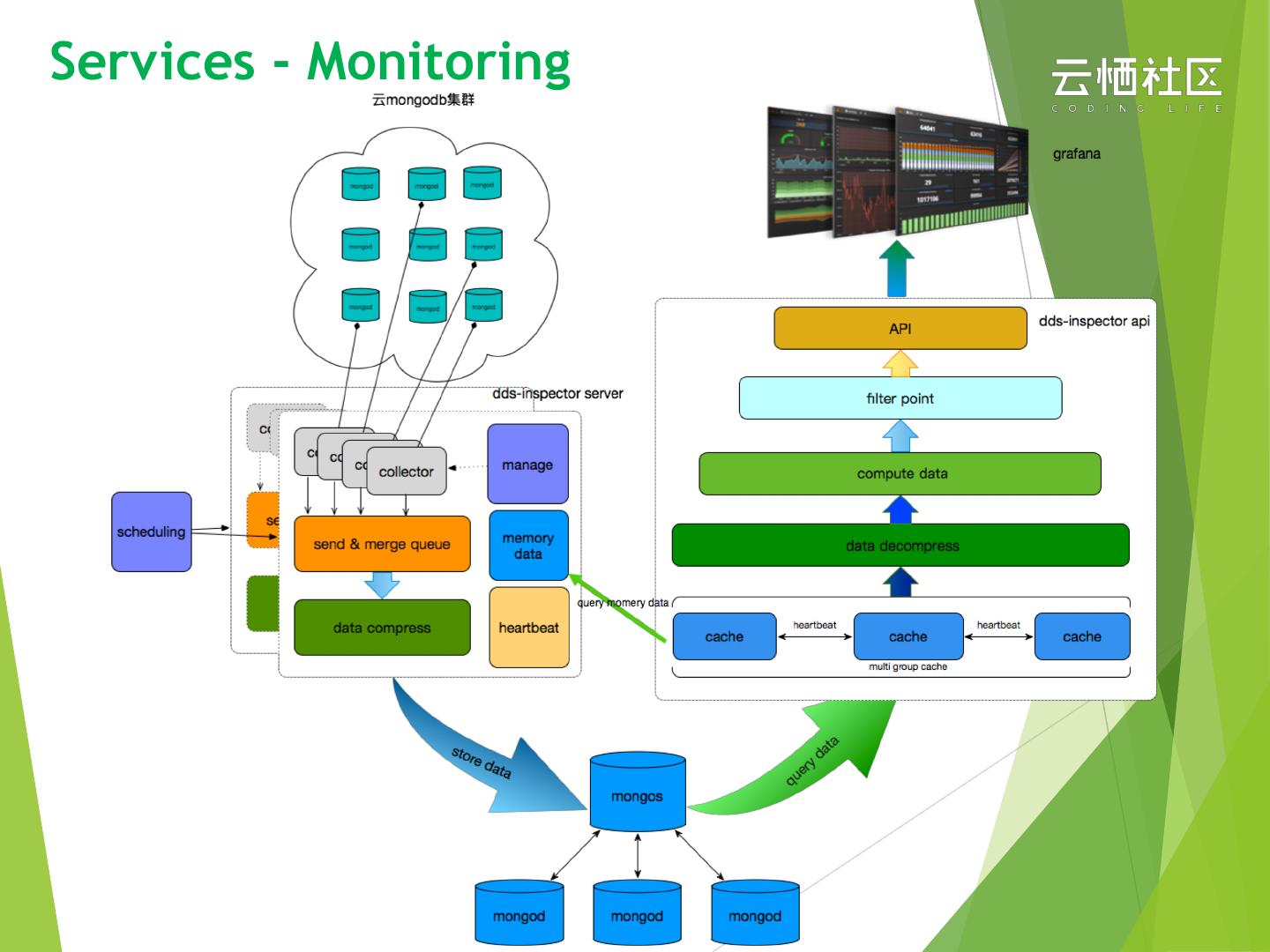
23 .Services - Monitoring
u 1s granularity. can be shrink to 2s, 5s, 15s, 1m as well
u Metrics : mongo, wiredTiger, cpu, memory …
u Metrics aggregate & Integrate with alarm policy
�
24 .Services - Monitoring
�
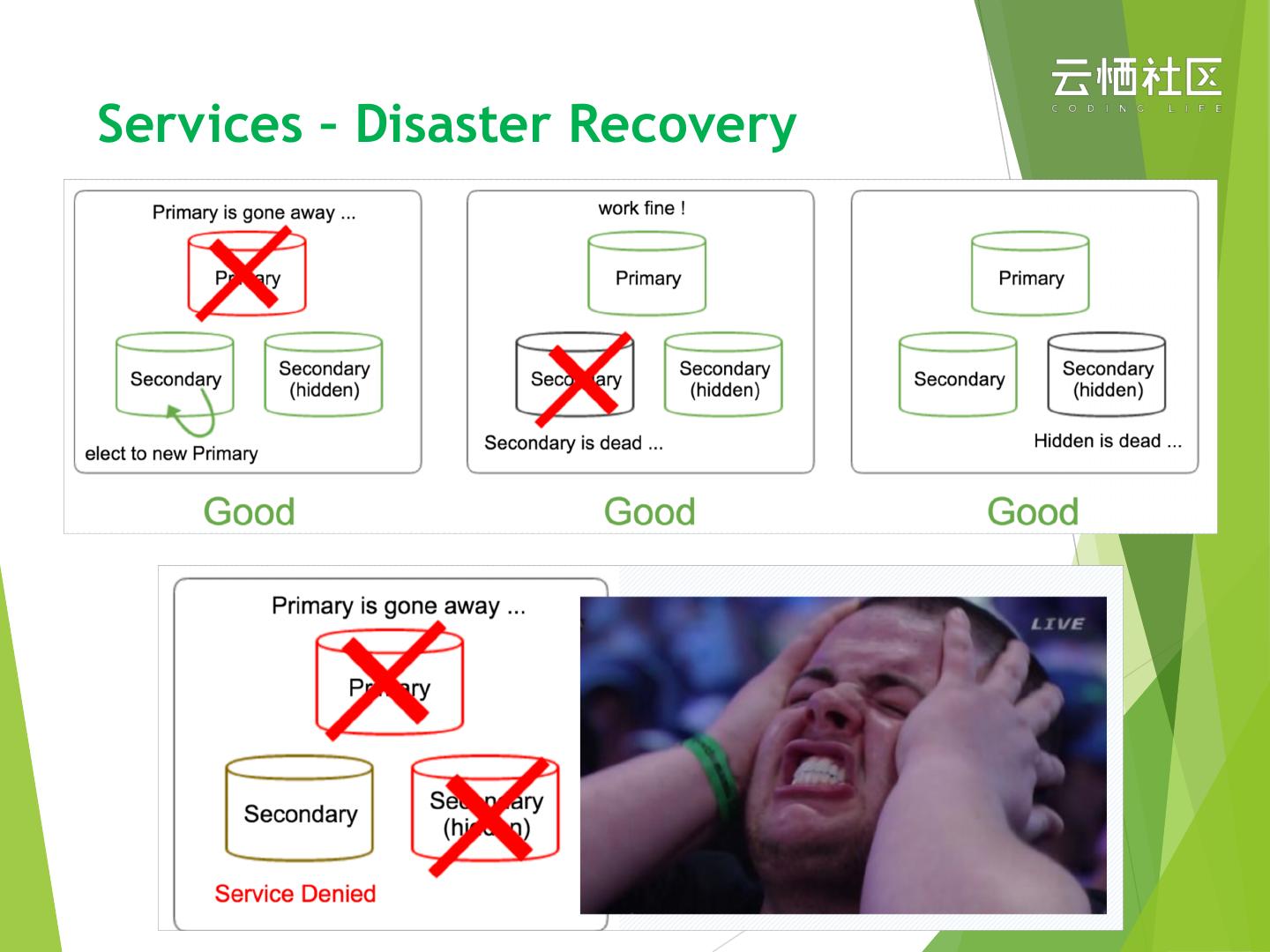
25 .Services – Disaster Recovery
�
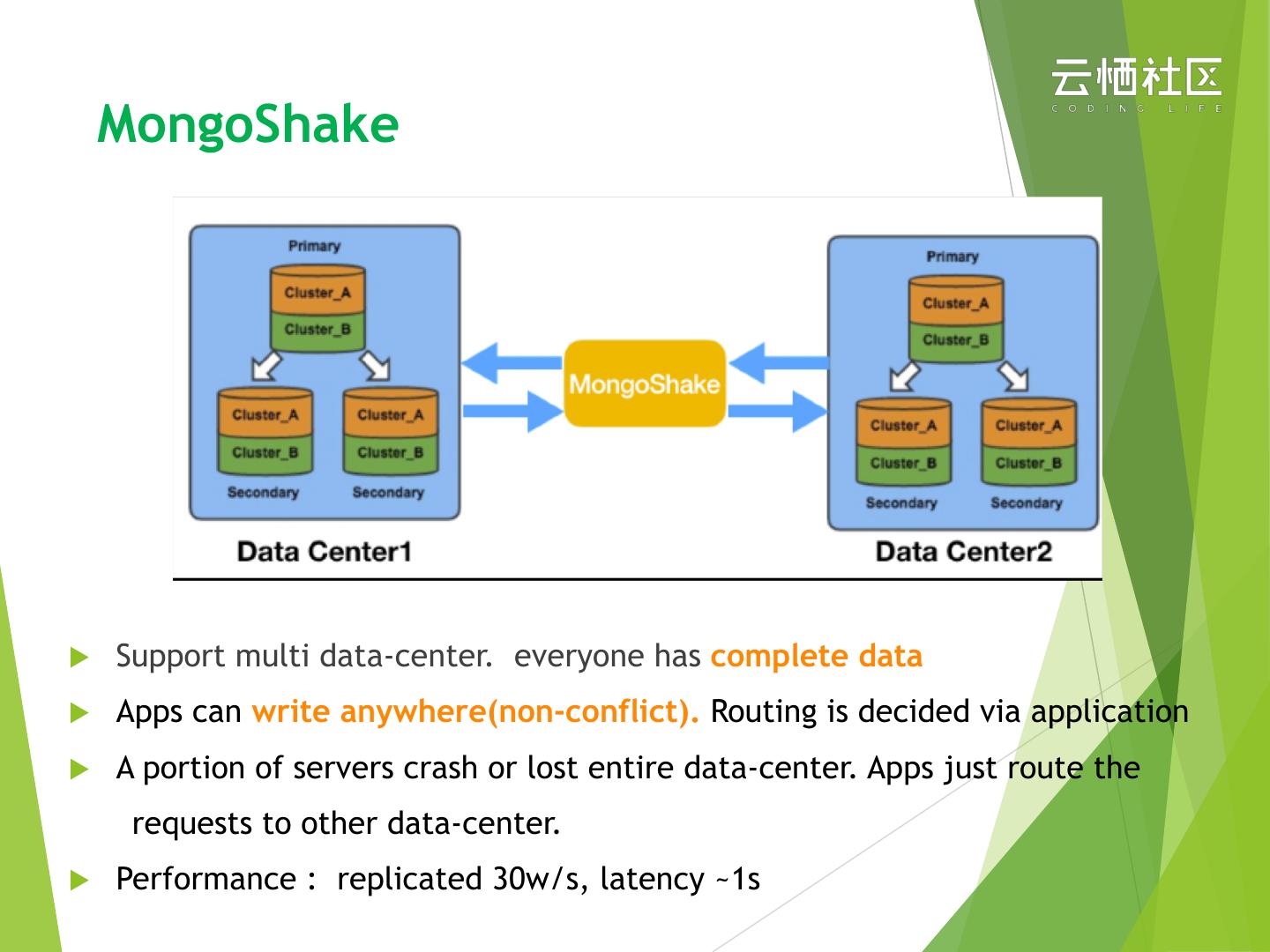
26 . MongoShake
u Support multi data-center. everyone has complete data
u Apps can write anywhere(non-conflict). Routing is decided via application
u A portion of servers crash or lost entire data-center. Apps just route the
requests to other data-center.
u Performance : replicated 30w/s, latency ~1s
�
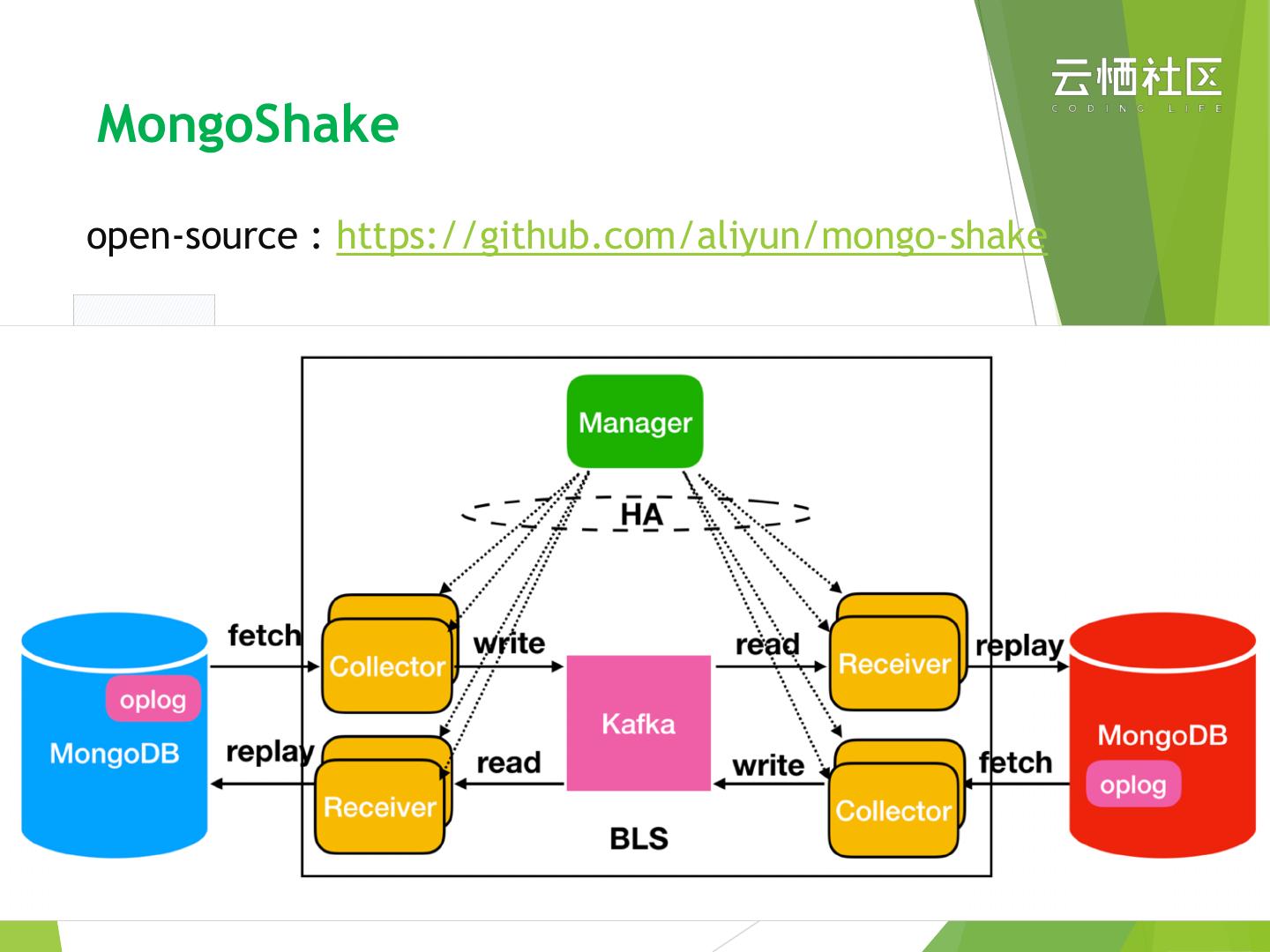
27 .MongoShake
open-source : https://github.com/aliyun/mongo-shake
�