




























- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
ApsaraDB-HBase介绍及案例例分析
知名过往记忆博主吴阳平,分享了关于阿里的ApsaraDB-HBase及案例。在企业数据快速膨胀,海量数据需要挖掘与存储的今天,对于数据处理的要求越来越严苛,面对新的挑战,阿里云HBase在开源版本上做出了重要改进,对比传统数据库更灵活,分析能力更强。
分析层:⽀支持复杂分析、算⼦子下推
多模式层:提供各种模型转换,贴切业务
索引引擎:提供索引⽀支持,基于 Lucene
存储引擎:提供 KV ⽀支持,基于LSM
分布式⽂文件层:保障低成本、与上层分离、共享降低成本
展开查看详情
1 .ApsaraDB-HBase介绍及案例例分析 ⽀支持多模式-SQL、Graph、时序、时空、分析 多模型数据库组 吴阳平 明慧
2 . ⽬目录 / Contents 01 基本介绍 02 企业级特性 03 HBase ⽣生态 04 典型案例例
3 .基本介绍
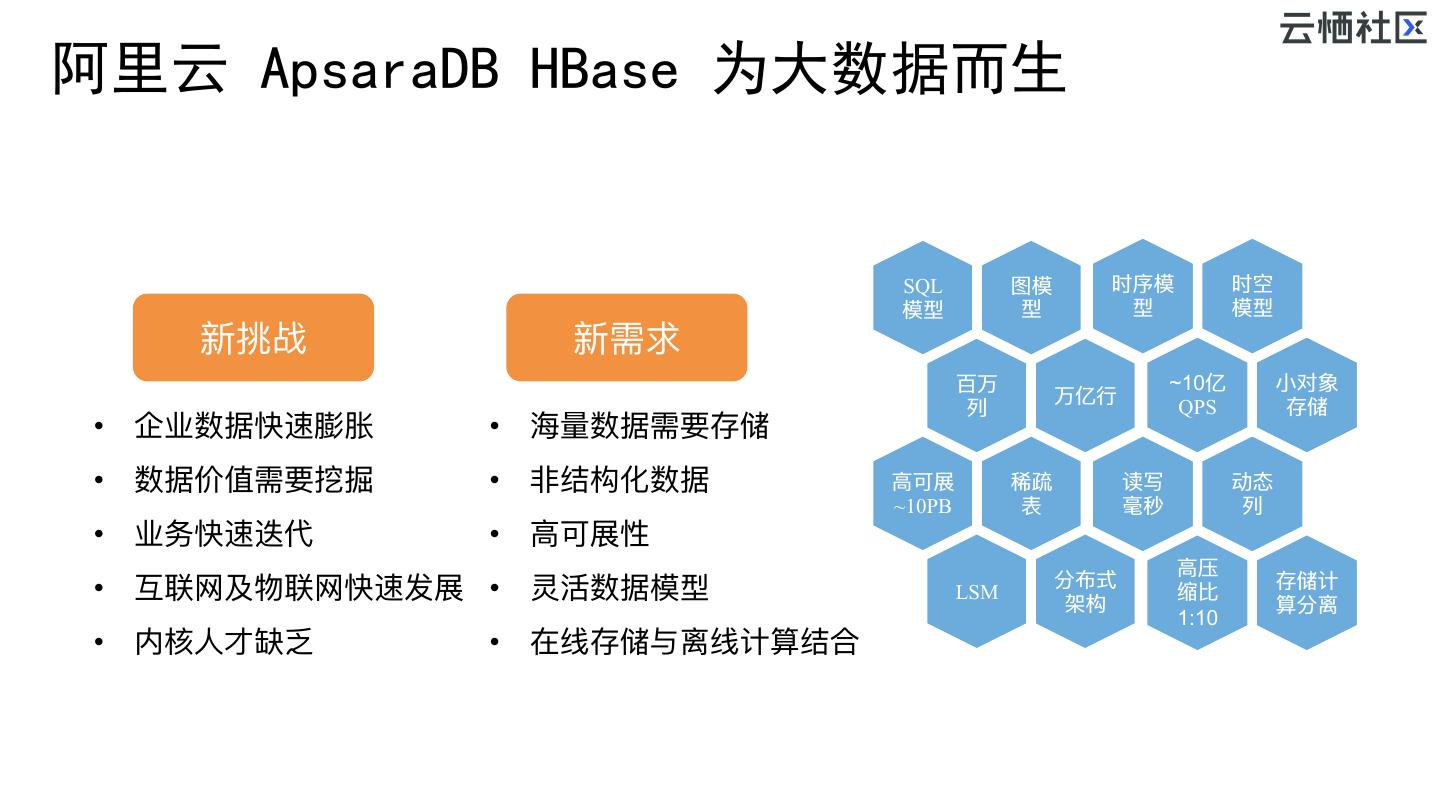
4 .阿里云 ApsaraDB HBase 为大数据而生 SQL 图模 时序模 时空 模型 型 型 模型 新挑战 新需求 百万 ~10亿 ⼩小对象 万亿⾏行行 列列 QPS 存储 • 企业数据快速膨胀 • 海海量量数据需要存储 • 数据价值需要挖掘 • ⾮非结构化数据 ⾼高可展 稀疏 读写 动态 ~10PB 表 毫秒 列列 • 业务快速迭代 • ⾼高可展性 ⾼高压 分布式 存储计 • 互联⽹网及物联⽹网快速发展 • 灵活数据模型 LSM 架构 缩⽐比 算分离 1:10 • 内核⼈人才缺乏 • 在线存储与离线计算结合
5 .阿里云 ApsaraDB HBase VS 传统数据库 全栈式 融合流、分析能⼒力力 ApsaraDB HBase 功能 传统关系数据库 分布式云 HBase 数据模型 关系模型 多数据模型-关系、时序、时空、图 多模式 多种数据模型、灵活 ApsaraDB HBase 数据规格 ~ 1T,~亿⾏行行 ~ 10PB,~万亿⾏行行 服务能⼒力力 ~100K TPS ~1000M TPS ⾃自动分区、运维简单 NewSQL 技术架构 主备 集群架构、存储计算分离,扩展性强 ⽆无需定义、完全动态 Schema 较少修改 修改对服务可⽤用性⽆无影响 超过单机数据量量及TPS 分库分表 引⼊入运维复杂性、扩展不不平滑 ERP、CRM、BOSS、 数据量量⼤大、并发⾼高 - 物联⽹网、⻋车联⽹网、 主要场景 交易易等强事务场景 互联⽹网、历史数据等数据驱动的场景 基本CURD需求 单机数据库
6 .阿里云 ApsaraDB HBase 云数据库HBase版是基于Apache HBase深度优化的全托管云数据库,⽀支持多种模 式 (SQL、⼆二级索引、全⽂文查询、图、时序、时空、分析),在物联⽹网、⻋车联⽹网、 ⽤用户画像、对象存储、AI、Feeds等场景有⼴广泛应⽤用。 多模式 服务化 稳定可靠 计算 Wide column(宽表) 开箱即⽤用 独享CPU、memory稳定 平台内置Spark引擎 SQL(关系) SLA 保障 单⾏行行写 0.2k 99.9⽑毛刺刺 < 3ms Spark算⼦子下推到HBase Time series(时序) 全球部署\全可⽤用区开放 单⾏行行写 0.2k 平均 < 1ms ⽀支持流计算、离线计算 Geo (时空) 全托管 单集群 SLA 99.9% 服务化 Graph (图) 资源独享 双集群容灾 SLA 99.99% Document (⽂文档) 多语⾔言⽀支持 数据可靠性9个9 (覆盖⼤大部分语⾔言Python\C++\Go……) ⾃自动负载均衡、热点迁移 ⽀支持备份恢复 ⼩小版本在线热升级
7 .阿里云 ApsaraDB HBase 产品架构 Spark OLAP/SQL/流/ 分析层:⽀支持复杂分析、算⼦子下推 MLlib Graph 批 备份 恢复 SQL KV Graph 时空 时序 (Phoenix) (HBase (HGraphD (GeoMesa) (OpenTSD 多模式层:提供各种模型转换,贴切业务 API) B) B) 索引引擎:提供索引⽀支持,基于 Lucene 安全 Solr HBase 存储引擎:提供 KV ⽀支持,基于LSM 全⽂文索引/⼆二级索引 双活 分布式⽂文件层: SSD HDD OSS …… 保障低成本、与上层分离、共享降低成本
8 .企业级特性
9 .数据备份恢复 l 误操作 l 备份对集群没有影响 l 可以完整恢复⼀一个新的集群 l 软件问题 l 备份延迟:最⻓长1⼩小时(后续改进为1m) 恢复时间:⼤大部分⼀一天内,最⻓长3天 l 磁盘设备问题 l l 单表备份恢复(规划之中) l …… 备份 全量量 增量量
10 .实时数据同步 Spark l 多RDS可以同步到⼀一个HBase集群 l 异步实时同步,平均延迟⼩小于200ms RDS MySQL 复杂 l ⽀支持跨可⽤用区、异地实时同步 分析 l 指标监控、可视化 RDS SQL Server l 在线配置即可⽣生效 异步实时同步 ApsaraDB RDS HBase&Phoenix l ⾃自动同步到HBase: PostgreSQL u ⽀支持RDS 插⼊入、修改、删除操作 …… u ⽀支持RDS 加列列、删列列
11 .冷热分离 元 ⾼高效云盘 VS OSS 1GB/⽉月 成本对 0.8 ⽐比 HBase 0.7 0.7 0.6 成本下降 0.5 3.5倍 存储计算分离 0.4 0.3 0.2 ⾼高效云盘(热数据) OSS(冷数据) 0.2 0.1 0 2副本云盘 OSS • 读写API完全不不变 建表DDL: • 满⾜足数百TB数据的冷数据 • 写⼊入QPS > 20W ,读单台QPS低 < 50 create ‘test',"info", CONFIGURATION=>{'HFILE_STORAGE_POLICY'=>'CO • Get平均延迟< 20ms,满⾜足实时写⼊入及读取 LD'}
12 .主备\多活\异地容灾 业务 l 提⾼高服务可⽤用性 l 满⾜足集群级别的容灾 l 可以通过单集群组装为多集群 HBase HBase l 备集群 可以满⾜足分析的需求 Z Z K 互为主备 K HDFS HDFS l 异步同步,最终⼀一致性 集群1 集群2 l 延迟 200ms以内 同城 l 异地容灾(待⽀支持)
13 .延迟 类型 停顿时间 频率 l 通过HBase本身来分配和回收主要内存 YGC 100ms+ 5s CMS 100~500ms 5min l BucketCacheV2 , CCSMap FGC 20s-180s 7 ~ 60 Days l 新的GC算法:ZenGC l 对象重⽤用 类型 停顿时间 频率 YGC 10ms 5s CMS 100ms 5H FGC N/A N/A 详情参⻅见: https://yq.aliyun.com/articles/277268
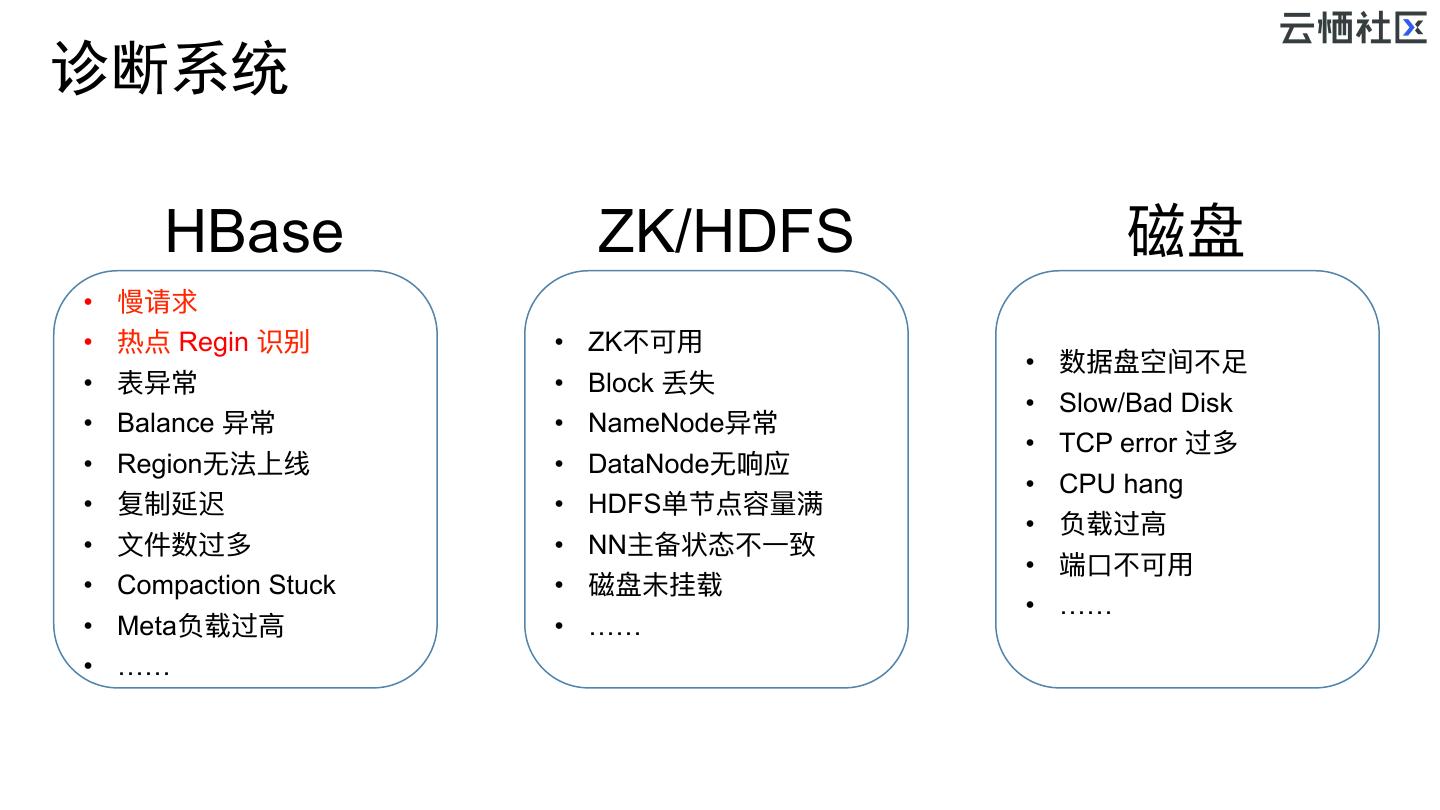
14 .诊断系统 HBase ZK/HDFS 磁盘 • 慢请求 • 热点 Regin 识别 • ZK不不可⽤用 • 数据盘空间不不⾜足 • 表异常 • Block 丢失 • Slow/Bad Disk • Balance 异常 • NameNode异常 • TCP error 过多 • Region⽆无法上线 • DataNode⽆无响应 • CPU hang • 复制延迟 • HDFS单节点容量量满 • 负载过⾼高 • ⽂文件数过多 • NN主备状态不不⼀一致 • 端⼝口不不可⽤用 • Compaction Stuck • 磁盘未挂载 • …… • Meta负载过⾼高 • …… • ……
15 .在线迁移服务 2、迁移 Schema同步 源HBase集群 HFile同步 HLog同步 阿⾥里里云 0.9x <100ms延迟 HBase集群 1.x 数据抽样校验 最终⼀一致 3、切换 1、访问原集群 业务系统 切换有短暂<1s 的不不⼀一致,最终是⼀一致的 ⼯工具的优势: l 使⽤用⽅方便便:⼀一键式迁移数据上云、UI实时任务实时监控、兼容不不同版本、不不需要业务双写; l ⾼高性能迁移:分布式迁移架构,极⼤大提升迁移的处理理性能,基本可以打满⽹网络,最⾼高⼏几⼗十GB/s; l ⾼高容错:任务出错重试、未完成任务⾃自动恢复、HFile拷⻉贝过程中Region⽬目录变化⾃自动处理理; l 数据⾃自动校验:迁移完成后,⽀支持数据⾃自动校验; l 限流控速:在业务⾼高峰期 可以限制迁移的速度,不不影响业务。 https://help.aliyun.com/document_detail/57695.html
16 .HBase⽣生态
17 .Phoenix–SQL on HBase 源表 - Source Table ⼆二级索引 – Global index id name score address name id 1 王⼆二 100 北北京海海淀 李李四 2 2 李李四 99 北北京朝阳 王⼆二 1 …… 张百亿 100000000 …… 100000000 张百亿 69 北北京海海淀 倒排索引 - Inverted index(待⽀支持) add id SQL引擎 海海淀 1, 100000000 朝阳 2 存储引擎 索引引擎 北北京 1,2, 100000000 …… ……
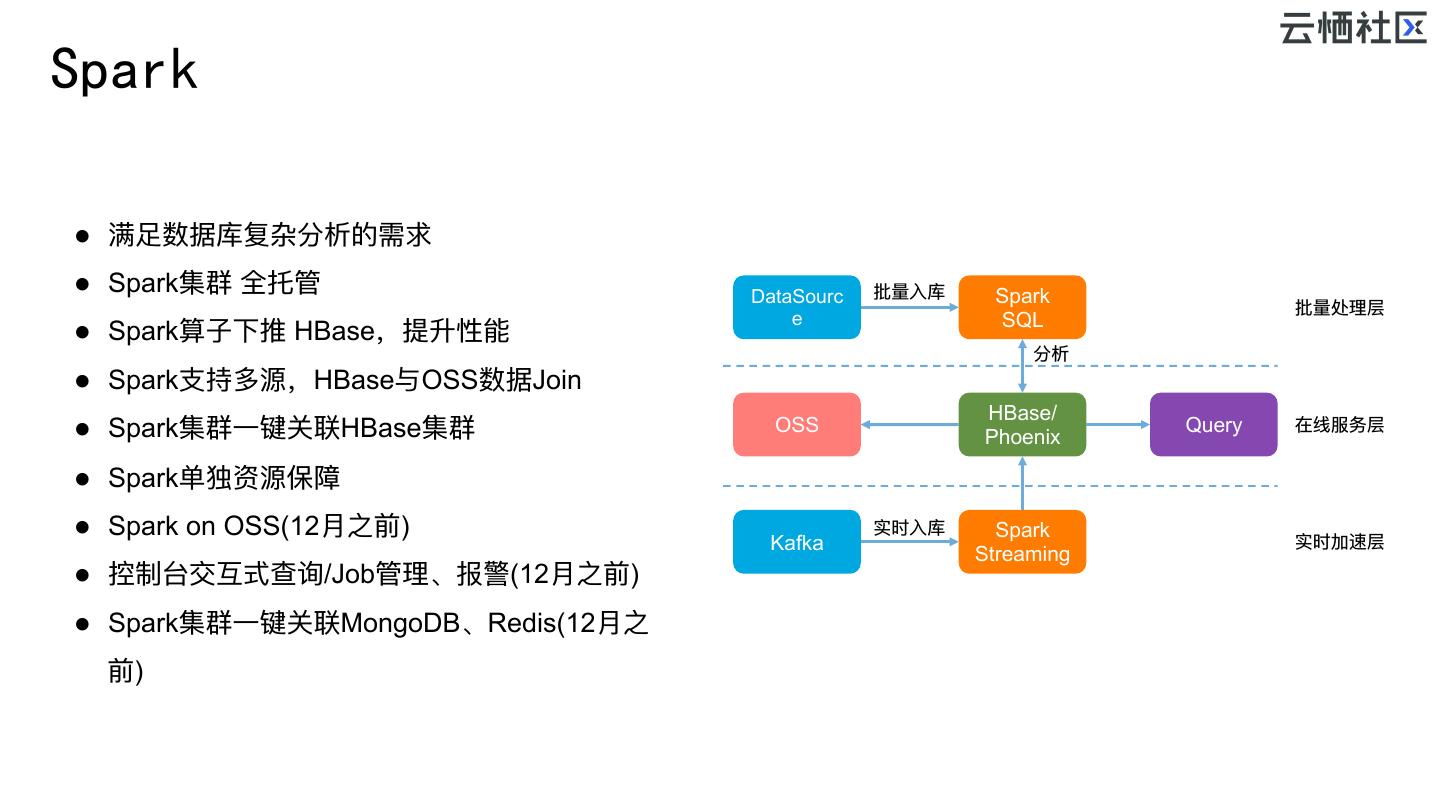
18 .Spark l 满⾜足数据库复杂分析的需求 l Spark集群 全托管 DataSourc 批量量⼊入库 Spark 批量量处理理层 e SQL l Spark算⼦子下推 HBase,提升性能 分析 l Spark⽀支持多源,HBase与OSS数据Join HBase/ l Spark集群⼀一键关联HBase集群 OSS Query 在线服务层 Phoenix l Spark单独资源保障 l Spark on OSS(12⽉月之前) 实时⼊入库 Spark Kafka 实时加速层 Streaming l 控制台交互式查询/Job管理理、报警(12⽉月之前) l Spark集群⼀一键关联MongoDB、Redis(12⽉月之 前)
19 .OpenTSDB-时序 proc.loadavg.1m 1436333416 0.42 host=web42 l 主要满⾜足物联⽹网:传感器器、监控、⾦金金融K线等时序应⽤用场景 pool=static proc.loadavg.5m 1436333416 0.26 host=web42 l 压缩节约存储空间 - 包括多⾏行行边⼀一⾏行行及多列列压为⼀一列列 pool=static proc.loadavg.1m 1436333417 0.49 host=web42 l 混合部署、HBase与OpenTSDB共享资源 pool=static proc.loadavg.5m 1436333417 0.30 host=web42 l Salt机制保障没有热点 pool=static proc.loadavg.1m 1436333418 0.39 host=web42 l ⽀支持Spark分析 pool=static Column Family: t Row Key proc.loadavg.5m 1436333418 0.23 host=web42 l 更更多性能及稳定性的优化 +0 +15 pool=static +20 … +1816 … +3600 0.69 0.51 0.42 0.99 0.72 55 9c ae 50 0 5 2 =1436331600+1816 0 0 1 0 0 1 0 4 5 0 0 1 } } } } } } put proc.loadavg.1m 1436333416 0.42 host=web42 pool=static
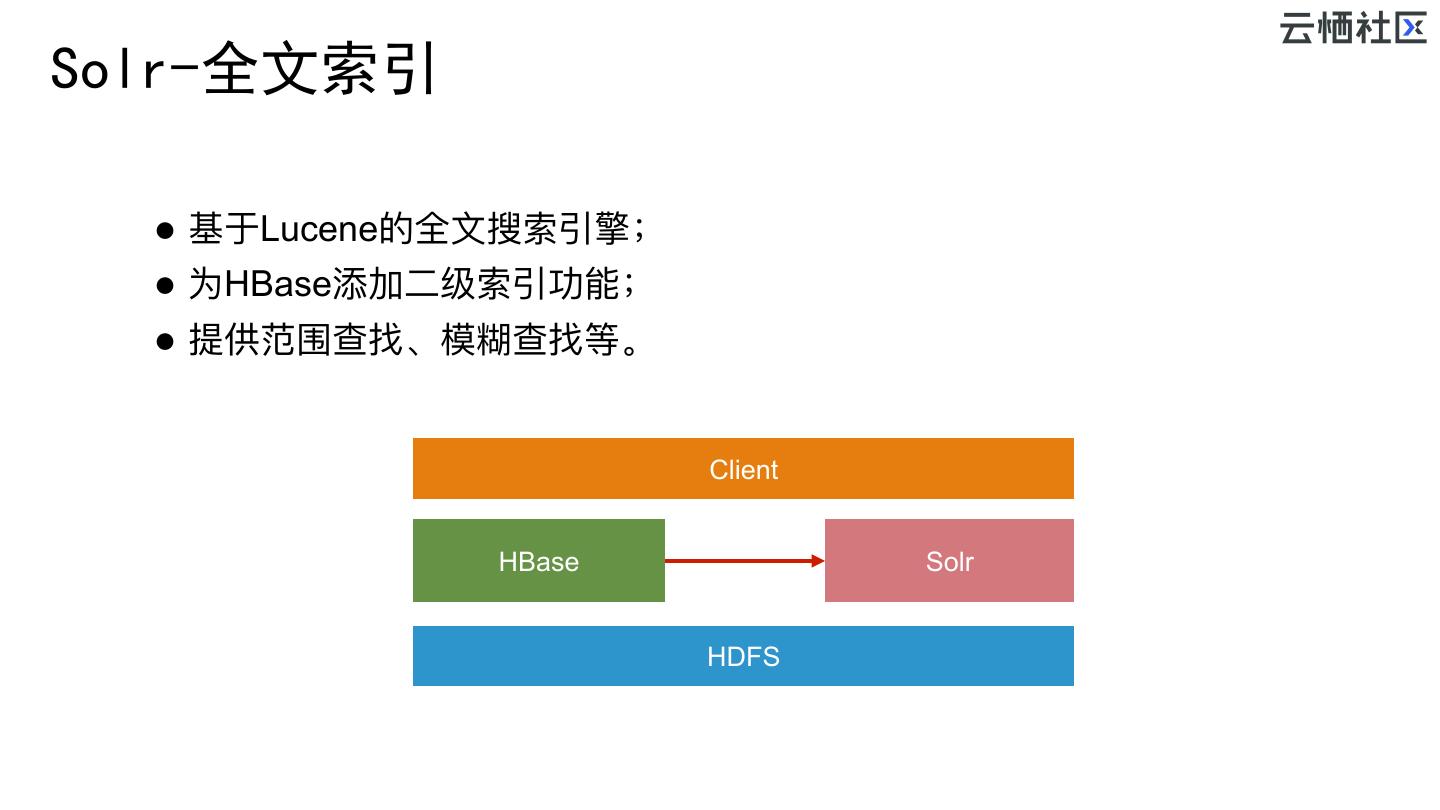
20 .Solr-全文索引 l 基于Lucene的全⽂文搜索引擎; l 为HBase添加⼆二级索引功能; l 提供范围查找、模糊查找等。 Client 索引同步 HBase Solr HDFS
21 . GeoMesa-提供时空能力 l ⾼高效时空索引,⽀支持点、线、⾯面等空间要素存储,百亿 级数据实现毫秒(ms)级响应; l 提供基于Spark SQL、REST、GeoJSON、OGC服务等 多种操作⽅方式,⽅方便便地理理信息互操作; l 提供轨迹查询、区域分布统计、区域查询、密度分析、 聚合、OD分析等常⽤用的时空分析功能; l ⽀支持物联⽹网流式数据接⼊入,物联⽹网中时空维度的查询简 单有效。
22 .HGraphDB-图 l HgraphDB实现了了图模型,上层业务开箱即⽤用,易易于上 ⼿手,使⽤用图特有语⾔言查询gremlin实现图遍历 图计算 图遍历-gremlin PageRan l HGraphDB底层基于hbase,容量量可⽆无限扩展,⽆无论多⼤大 最短路路径 联通⼦子图 k 实时推荐 K跳查询 的图都能存 OLAP l 内置了了常⽤用的图算法⼯工具,与Spark GraphFrames集成, Spark ⽤用户还可⾃自定义图分析算法 OLTP GraphFrames 导⼊入性能(单 图计算 容量量 1跳查询 机) Neo4j Y 单节点 1.4w/s 21ms JanusGraph N 可扩展 0.1w/s 27.2ms HGraphDB Y 可扩展 6w/s 20ms HBase HGraphDB BulkLoad/实时接⼝口 应⽤用:依托图关联技术,帮助⾦金金融机构有效识别 接⼊入层 隐藏在⽹网络中的⿊黑⾊色信息,在团伙欺诈、⿊黑中介 识别等。 外部数据集 CSV⽂文件
23 .典型案例例
24 . 大数据 消息中间件 数据接收层 物联⽹网套件 消息中间件 流式分析: 预聚合、ETL、报警 Spark Streaming Phoenix OpenTSDB GeoMesa HGraphDB 数据库 RDS Redis MongoDB HBase Solr 数据同步 数据驱动 交易易驱动 事后分析 报表、查询、数据清洗 Spark 离线数仓 Meta OSS
25 .HBase应用场景 时序类 ⻛风控类 报表类 ⽇日志类 报表类 推荐类 轨迹类 …… ⻋车联⽹网 电⼦子商务 聊天应⽤用 新闻 ⾦金金融 ⼴广告 …… 物联⽹网 HBase
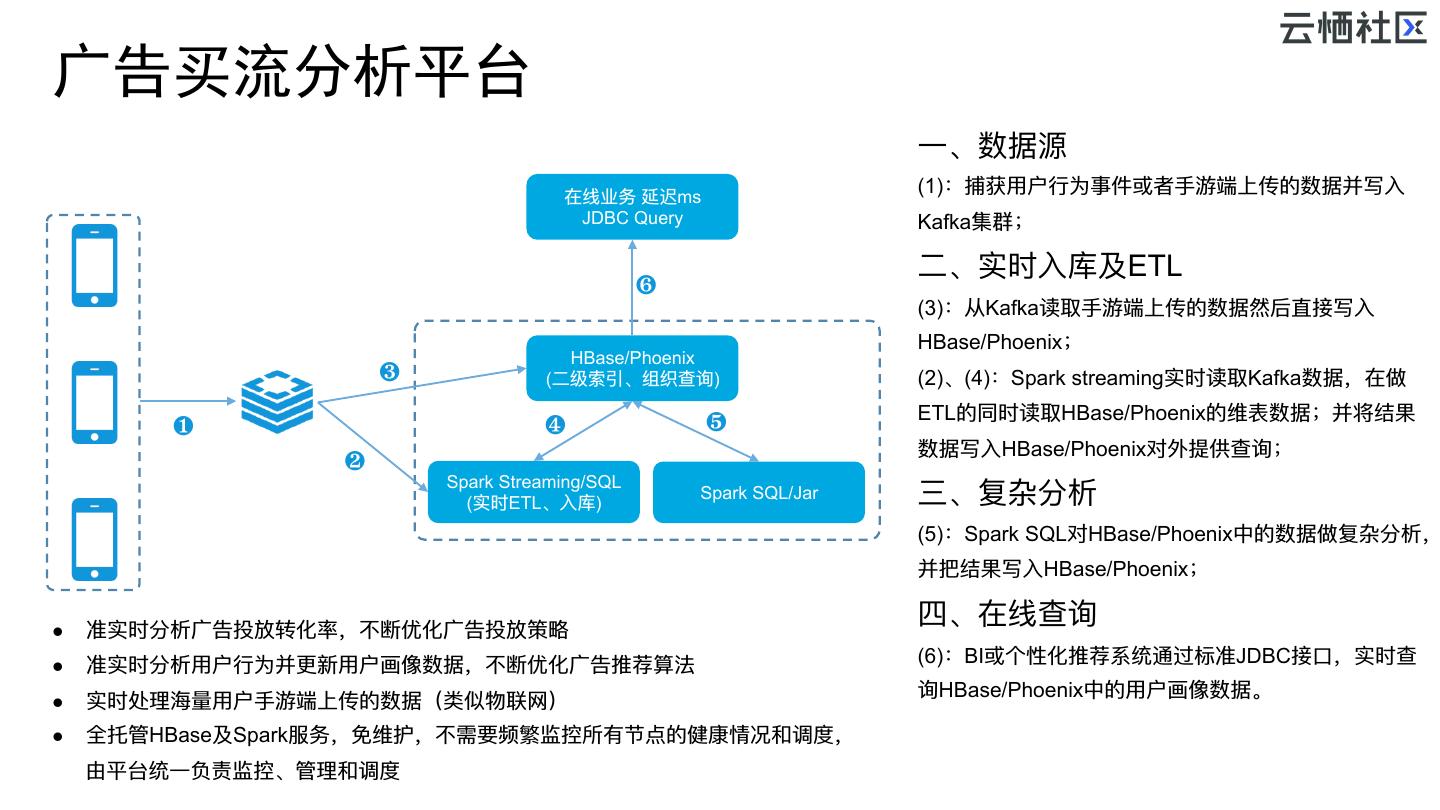
26 .广告买流分析平台 ⼀一、数据源 在线业务 延迟ms (1):捕获⽤用户⾏行行为事件或者⼿手游端上传的数据并写⼊入 JDBC Query Kafka集群; ⼆二、实时⼊入库及ETL ❻ (3):从Kafka读取⼿手游端上传的数据然后直接写⼊入 HBase/Phoenix; HBase/Phoenix ❸ (⼆二级索引、组织查询) (2)、(4):Spark streaming实时读取Kafka数据,在做 ETL的同时读取HBase/Phoenix的维表数据;并将结果 ❶ ❹ ❺ 数据写⼊入HBase/Phoenix对外提供查询; ❷ Spark Streaming/SQL (实时ETL、⼊入库) Spark SQL/Jar 三、复杂分析 (5):Spark SQL对HBase/Phoenix中的数据做复杂分析, 并把结果写⼊入HBase/Phoenix; l 准实时分析⼴广告投放转化率,不不断优化⼴广告投放策略略 四、在线查询 l 准实时分析⽤用户⾏行行为并更更新⽤用户画像数据,不不断优化⼴广告推荐算法 (6):BI或个性化推荐系统通过标准JDBC接⼝口,实时查 询HBase/Phoenix中的⽤用户画像数据。 l 实时处理理海海量量⽤用户⼿手游端上传的数据(类似物联⽹网) l 全托管HBase及Spark服务,免维护,不不需要频繁监控所有节点的健康情况和调度, 由平台统⼀一负责监控、管理理和调度
27 .实时广告 – 兑吧 云HBase存储: ⽤用户在不不同⼴广告上的曝光,点击,参与等数据, 记录⽤用户的相应属性 ⽤用户对哪类⼴广告⽐比较感兴趣,⽤用户的年年龄,性别,职业,爱好等特征 Flink/Storm/流式处理理引擎 云HBase 推荐⼴广告 Spark Streaming 存储⽤用户画像 存储结果 实际场景: 集群规模:4 * 8核32G 4*200G SSD存储 QPS:⾼高峰期写40w, 读20w,⽬目前存储600G数据 延迟:平均读写延迟⼩小于2ms 999的延迟 <80ms(延迟敏敏感型) 具体参考兑吧⼴广告案例例:https://yq.aliyun.com/articles/601483 存储与QPS可以⽆无缝⽆无限扩容 低延迟:https://yq.aliyun.com/articles/618575
28 .小对象实时存取(10MB内) 场景:读取每个组的全量量数据 1、其中 45% 左右的组含有1张⼈人脸 2、45%左右的组含有 2 ~ 9张⼈人脸数据 业务 业务 3、其余的组⼈人脸数范围为 10 ~ 10019 4、其中每个脸2.4k 宽表存储,⼀一次性读取⼀一⾏行行 1、查询元数据 2、查询⼩小对象 MySQL OSS 性能提升 500+倍 云HBase 当⼀一个组,含有1000个脸时,读的性能20ms 当⼀一个组,含有1000个脸时,读的性能10s 当⼀一个组,含有10000个脸时,读的性能 200ms
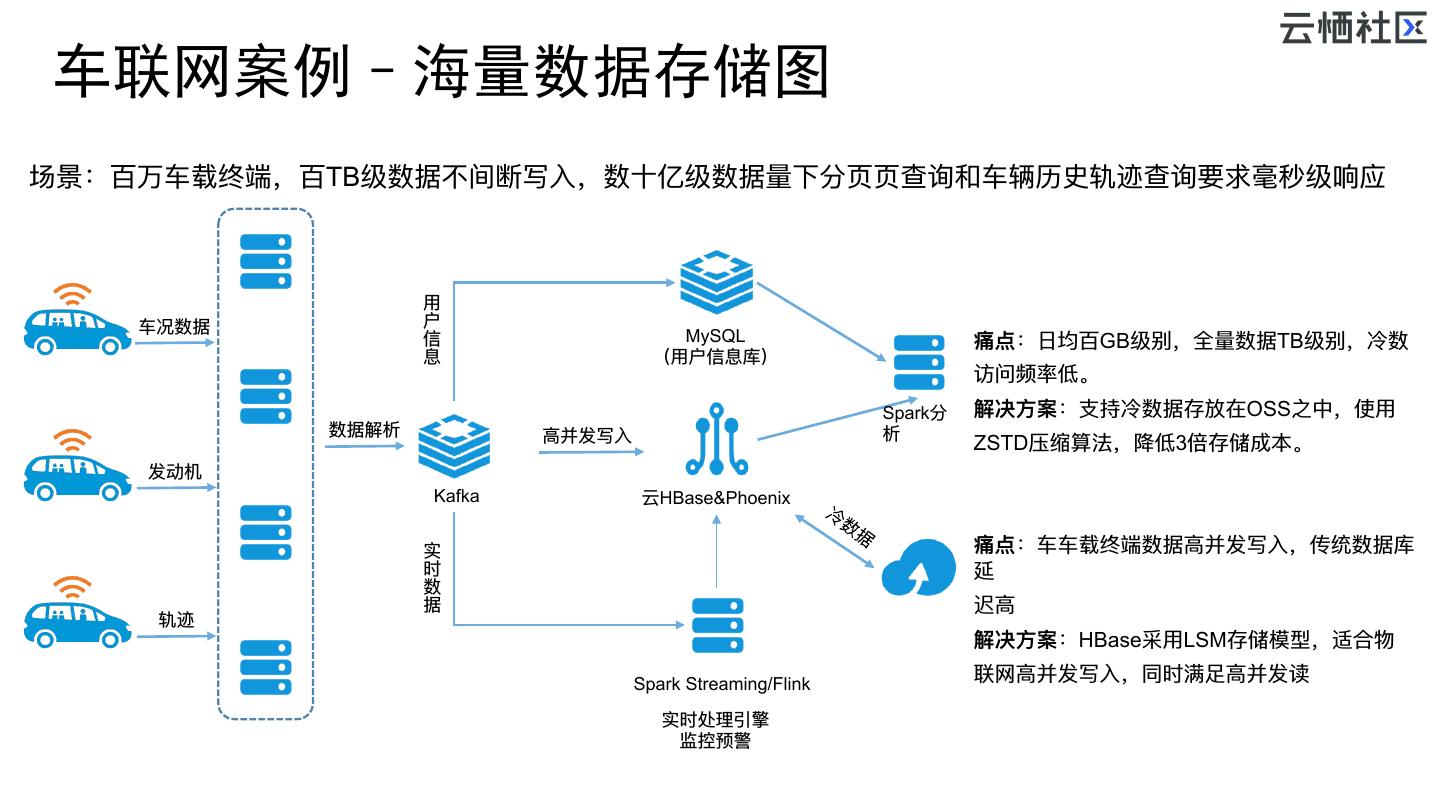
29 . 车联网案例–海量数据存储图 场景:百万⻋车载终端,百TB级数据不不间断写⼊入,数⼗十亿级数据量量下分⻚页⻚页查询和⻋车辆历史轨迹查询要求毫秒级响应 ⽤用 ⻋车况数据 户 信 MySQL 痛点:⽇日均百GB级别,全量量数据TB级别,冷数 息 (⽤用户信息库) 访问频率低。 Spark分 解决⽅方案:⽀支持冷数据存放在OSS之中,使⽤用 数据解析 ⾼高并发写⼊入 析 ZSTD压缩算法,降低3倍存储成本。 发动机 Kafka 云HBase&Phoenix 实 痛点:⻋车⻋车载终端数据⾼高并发写⼊入,传统数据库 时 延 数 据 迟⾼高 轨迹 解决⽅方案:HBase采⽤用LSM存储模型,适合物 Spark Streaming/Flink 联⽹网⾼高并发写⼊入,同时满⾜足⾼高并发读 实时处理理引擎 监控预警
相关推荐
3秒后跳转登录页面
去登陆

