展开查看详情
2 .蚂蚁集团技术风险智能监控数据中台
欢迎您的加入
公众号:蚂蚁智能运维 微信号:wf_zxz
手机号:18051001760
�
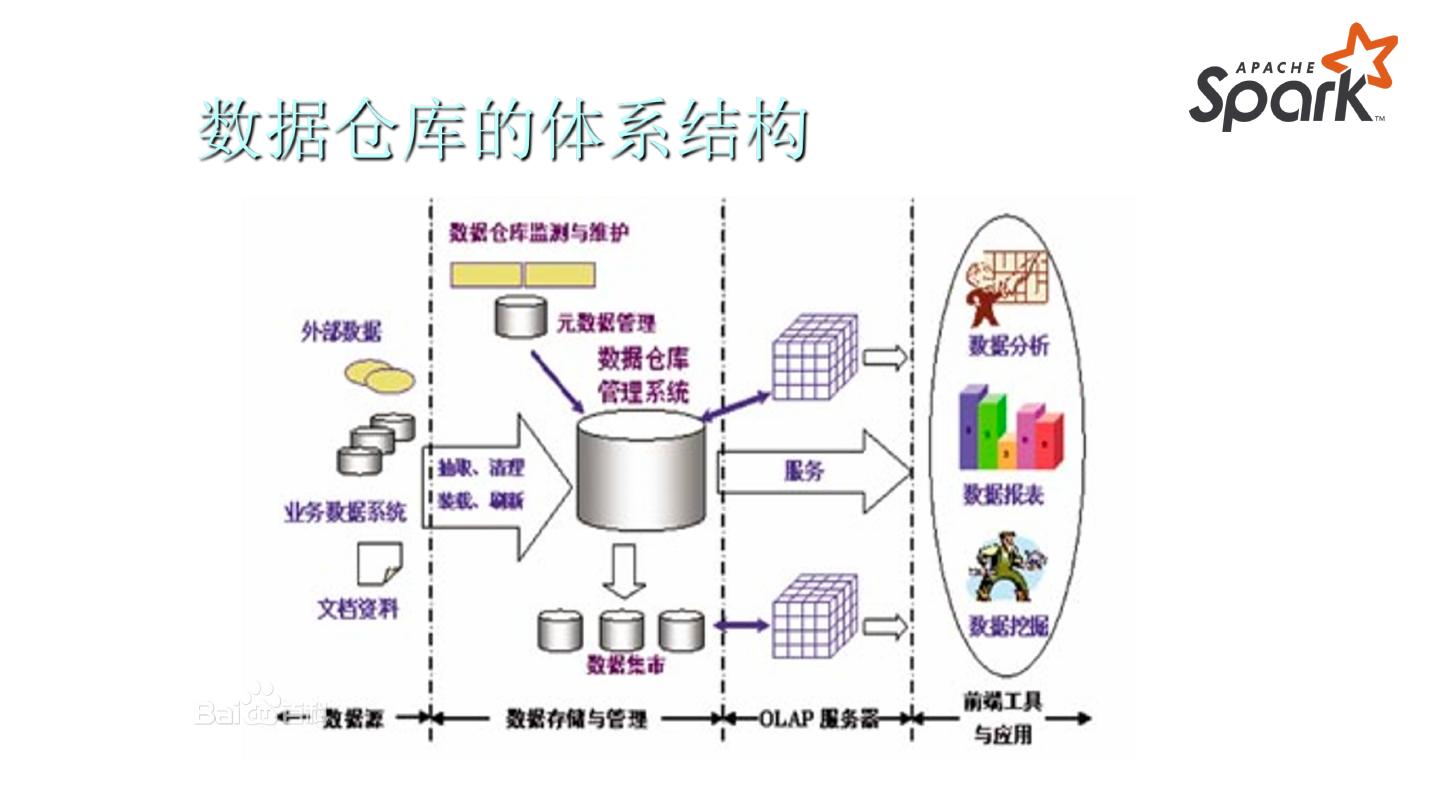
4 .通过本课程期望大家能够对以下问题有基础概念:
1. 数据仓库解决了什么业务问题,它和传统数据库的区别是什么?
2. 对数据仓库的基础架构有大致的了解。
3. 使用 Spark 可以构建数据仓库的哪些核心能力?
4. 如何使用 Spark Core/Streaming 扩展数据源?
5. 如何使用 Spark 进行 OLAP?
�
5 .01
Apache Flink : ververica.cn
© Apache Flink Community China
�
6 .概念
• 数据仓库(Data Warehouse)是一个面向主题的(Subject Oriented)、集成的
(Integrated)、相对稳定的(Non-Volatile)、反映历史变化(Time Variant)的数据集
合,用于支持管理决策(Decision Making Support)。
—— 数据仓库之父比尔·恩门
�
7 .面向主题(Subject Oriented)
• 传统数据库使用的是OLTP(联机事务处理方式),进行数据组织时只需要考虑每一笔业务的情况,
例如订单创建、付款;
• 数据仓库使用的是OLAP(联机分析处理方式),进行数据分析时,已主题为单位组织数据,例如商
品、用户等;
• 面向主题的数据组织方式要求将数据按照一定的主题域进行关联,通过建模的方式将数据关联起来;
如用户行为(浏览、交易、论坛等)通过用户ID将数据关联起来进行数据组织,分析用户特征,进
行风险识别、商品推荐;各个主题域之间有明确的界定,各个主体域内部需要包含分析处理所要求
的一些数据(完备性)。
�
8 .数据源集成( Integrated )
• 数据仓库是将多个不同的数据源,如数据库、日志、一般性数据文件,集成在一起;
• 多个系统数据进行计算、整理,保证数仓中对数据的定义是全局的、统一的,确保数据的一致性;
�
9 .相对稳定的( Non-Volatile )
• 数据操作的方式主要是插入和查询,修改和删除操作很少;
• 数仓的数据与生产环境的生产数据是分离的,不需要生产操作环境下的事务处理和并发控制;
• 数据时效性要求不高,常用与T+1的离线分析场景;(当前的数据分析对时效性越来越高,衍生出
很多新的数据架构,如 Lambda/ Kappa 架构)
反映历史变化( Time Variant ):
• 数据仓库记录从过去某一个时间点到当前的各个阶段信息,通过这些信息,可以分析出企业发展过
程中的发展趋势,并对未来做出定量分析和预判;
• 数据仓库的数据隐式的包含了时间元素,随着时间的累加,数据长期积累 ,数据量也越来越大;
• 定期进行数据归档,按天/周/月进行数据归档,降低历史数据分析的成本;
�
10 .数据决策( Decision Making Support )
• 整合公司所有业务数据,建立统一的数据中心;
• 生产数据报表,用于决策,也可为运营提供数据上的支持;
• 分析用户行为数据,通过数据挖掘来降低投入成本,提高投入效果
�
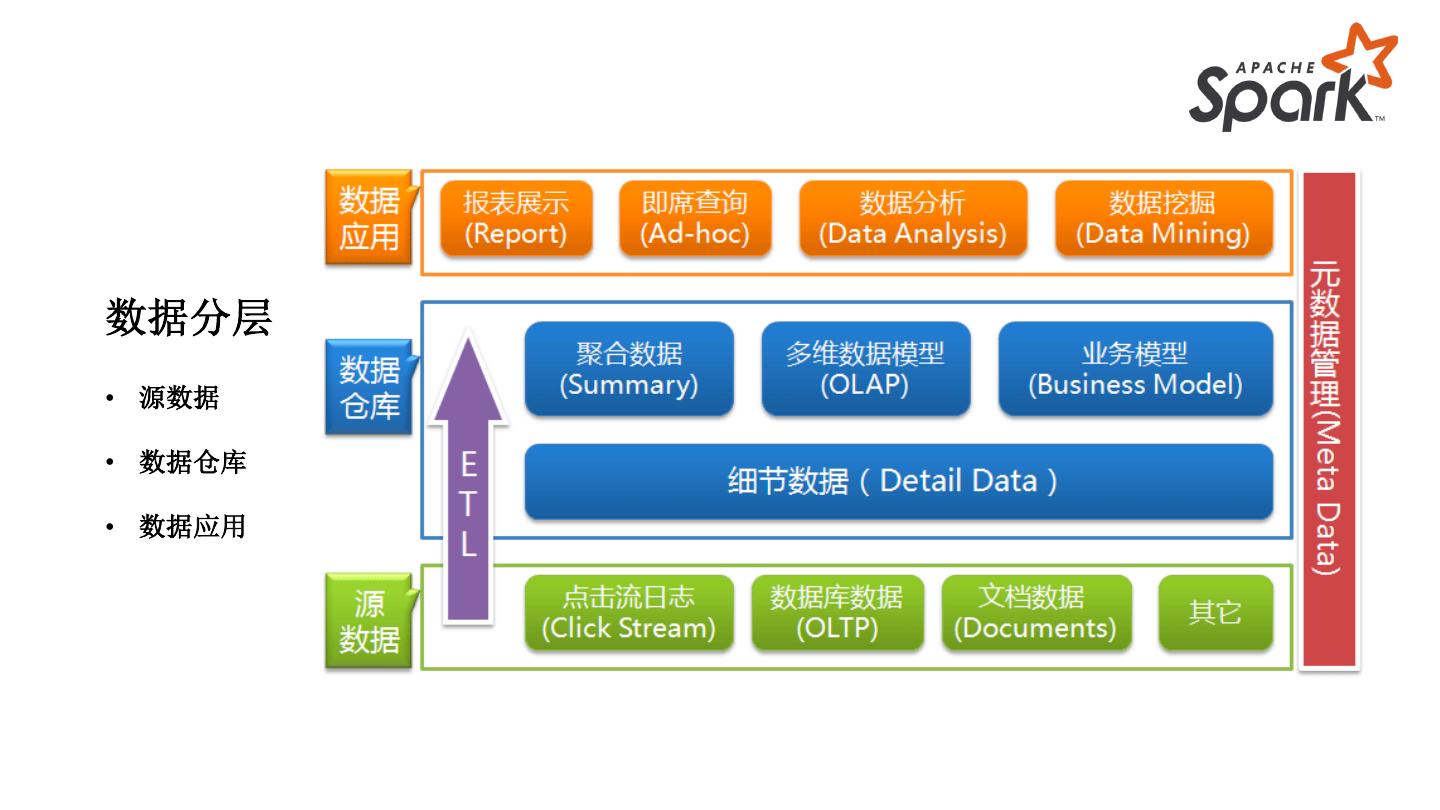
11 .数据分层
• 源数据
• 数据仓库
• 数据应用
�
12 .数据分层
• ADM Application Data Mart,面向应用的数据集市层,承担个性化指标加工,以及基于应用需要的
数据组装,主要是大宽表。
• DWS Data Warehouse Summary,数据仓库汇总数据层:构建命名规范、口径一致的公共统计指标;
• DWD Data Warehouse Detail,数据仓库明细数据层:基于维度建模,建设明细表,复用频繁关联,
减少数据扫描;
• DIM Dimension,维度表,包含分析数据的维度和属性:建立一致性维度,降低数据计算口径不统
一的风险;
• ODS Operational Data Store,操作型数据存储:1、承担结构化数据增量或者全量同步到数据仓库系
统;2、非结构化数据结构化并存储到数据仓库系统;3、保存历史数据和清洗数据;
�
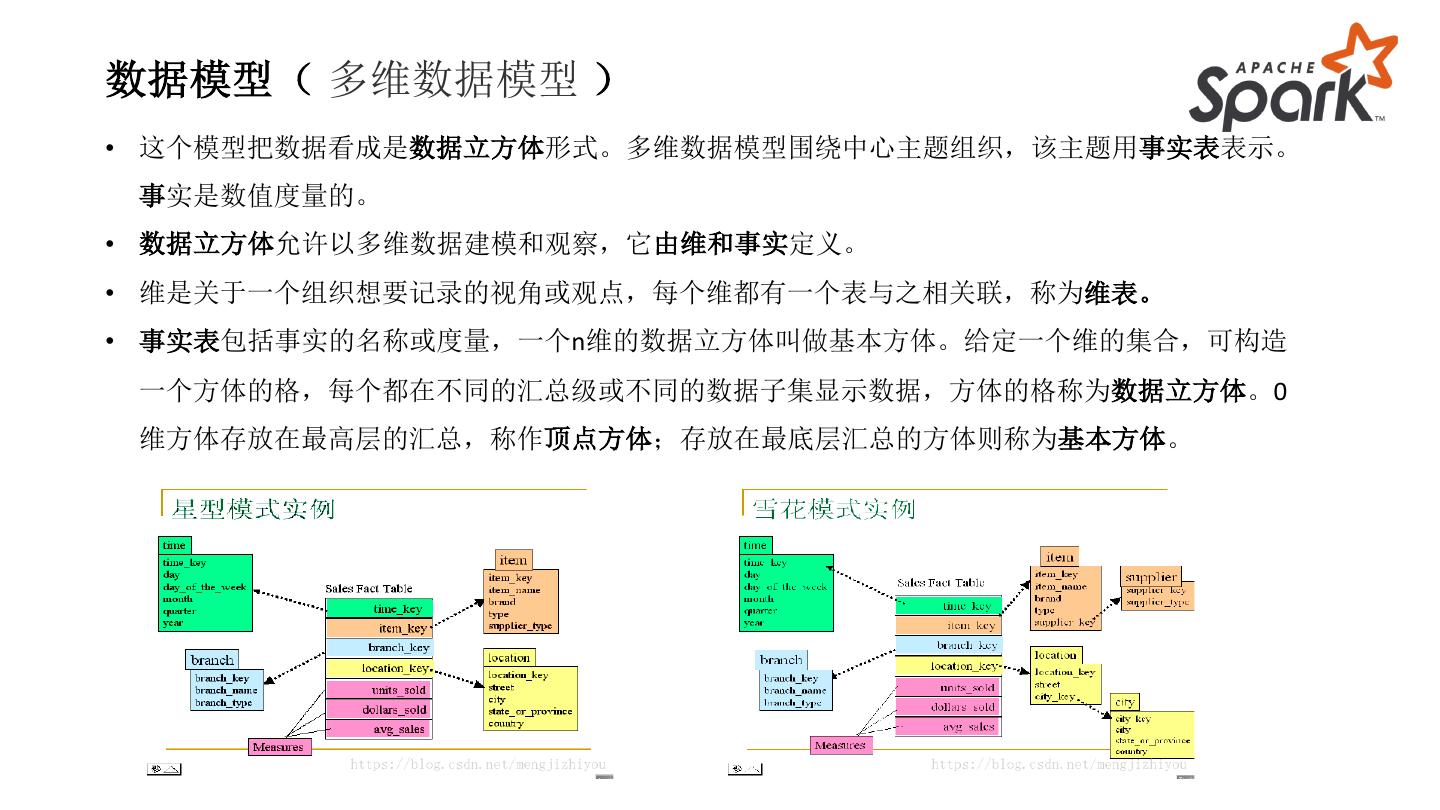
13 .数据模型( 多维数据模型 )
• 这个模型把数据看成是数据立方体形式。多维数据模型围绕中心主题组织,该主题用事实表表示。
事实是数值度量的。
• 数据立方体允许以多维数据建模和观察,它由维和事实定义。
• 维是关于一个组织想要记录的视角或观点,每个维都有一个表与之相关联,称为维表。
• 事实表包括事实的名称或度量,一个n维的数据立方体叫做基本方体。给定一个维的集合,可构造
一个方体的格,每个都在不同的汇总级或不同的数据子集显示数据,方体的格称为数据立方体。0
维方体存放在最高层的汇总,称作顶点方体;存放在最底层汇总的方体则称为基本方体。
�
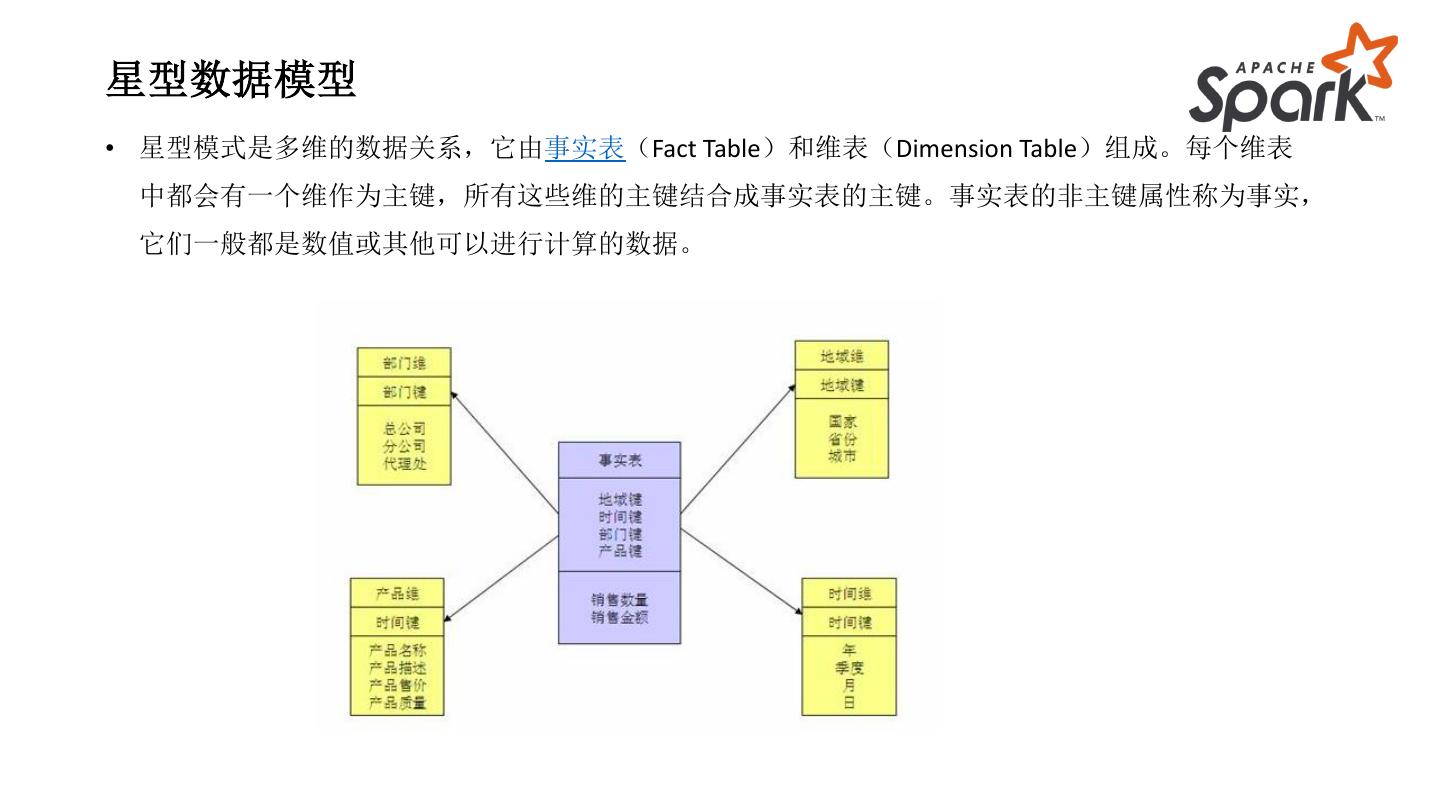
14 .星型数据模型
• 星型模式是多维的数据关系,它由事实表(Fact Table)和维表(Dimension Table)组成。每个维表
中都会有一个维作为主键,所有这些维的主键结合成事实表的主键。事实表的非主键属性称为事实,
它们一般都是数值或其他可以进行计算的数据。
�
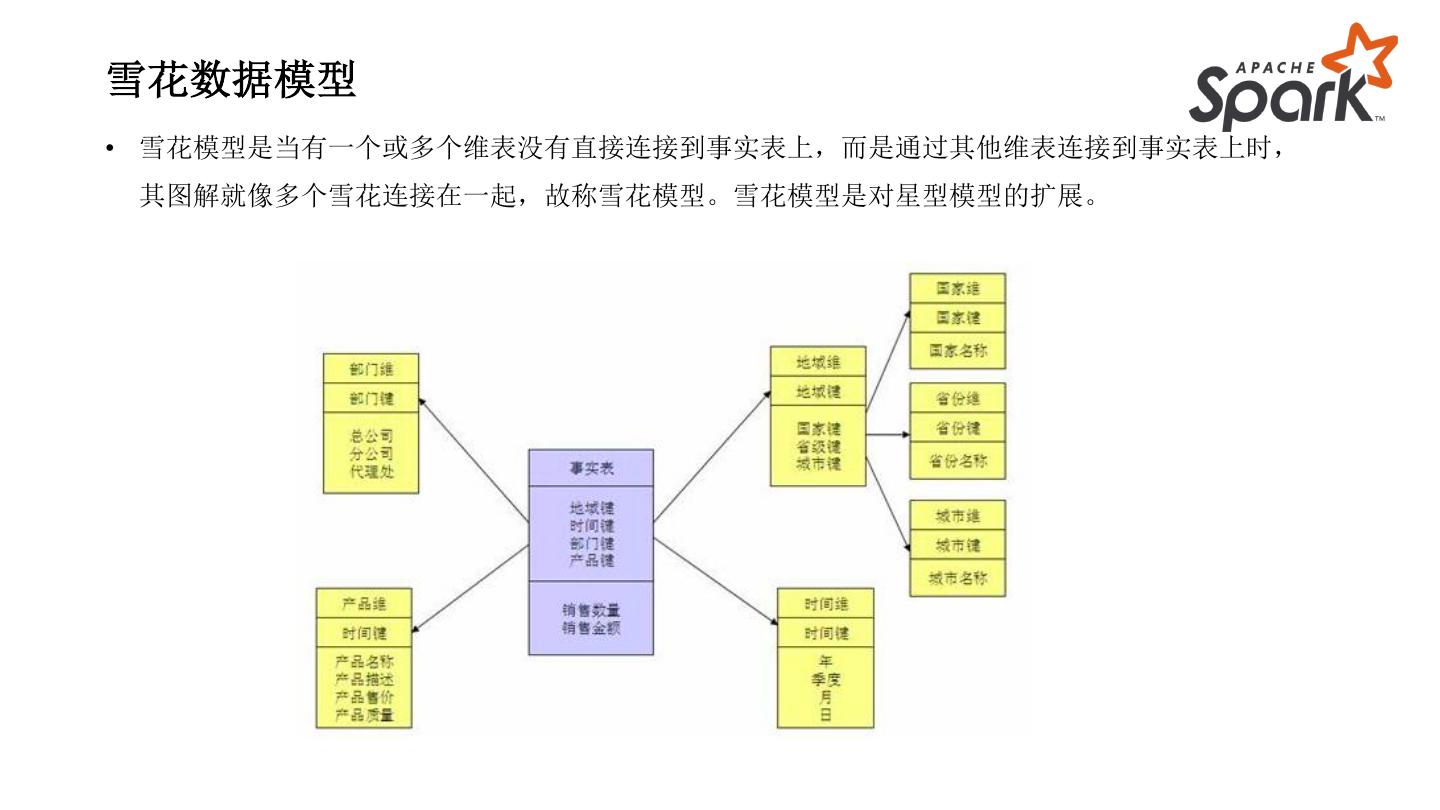
15 .雪花数据模型
• 雪花模型是当有一个或多个维表没有直接连接到事实表上,而是通过其他维表连接到事实表上时,
其图解就像多个雪花连接在一起,故称雪花模型。雪花模型是对星型模型的扩展。
�
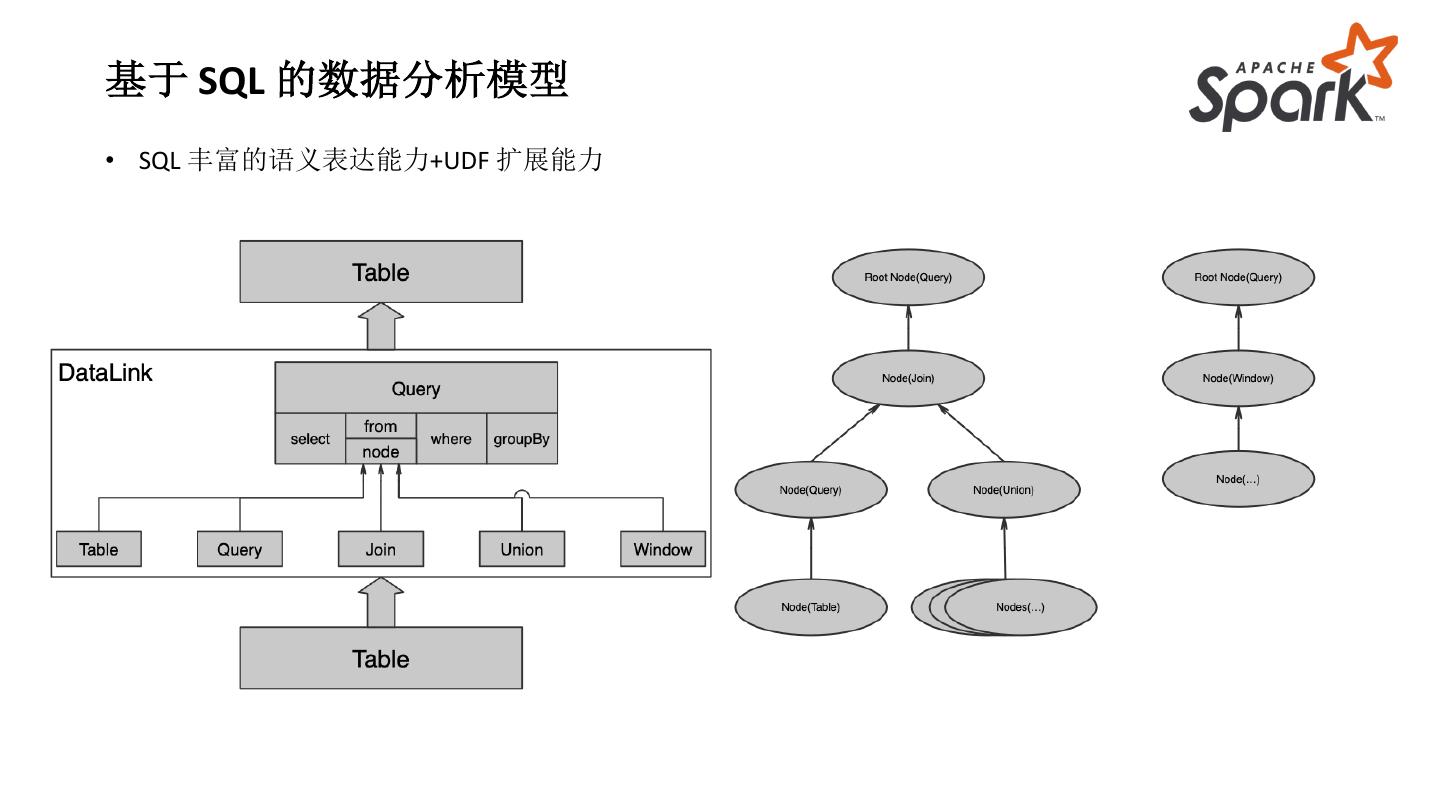
16 .基于 SQL 的数据分析模型
• SQL 丰富的语义表达能力+UDF 扩展能力
�
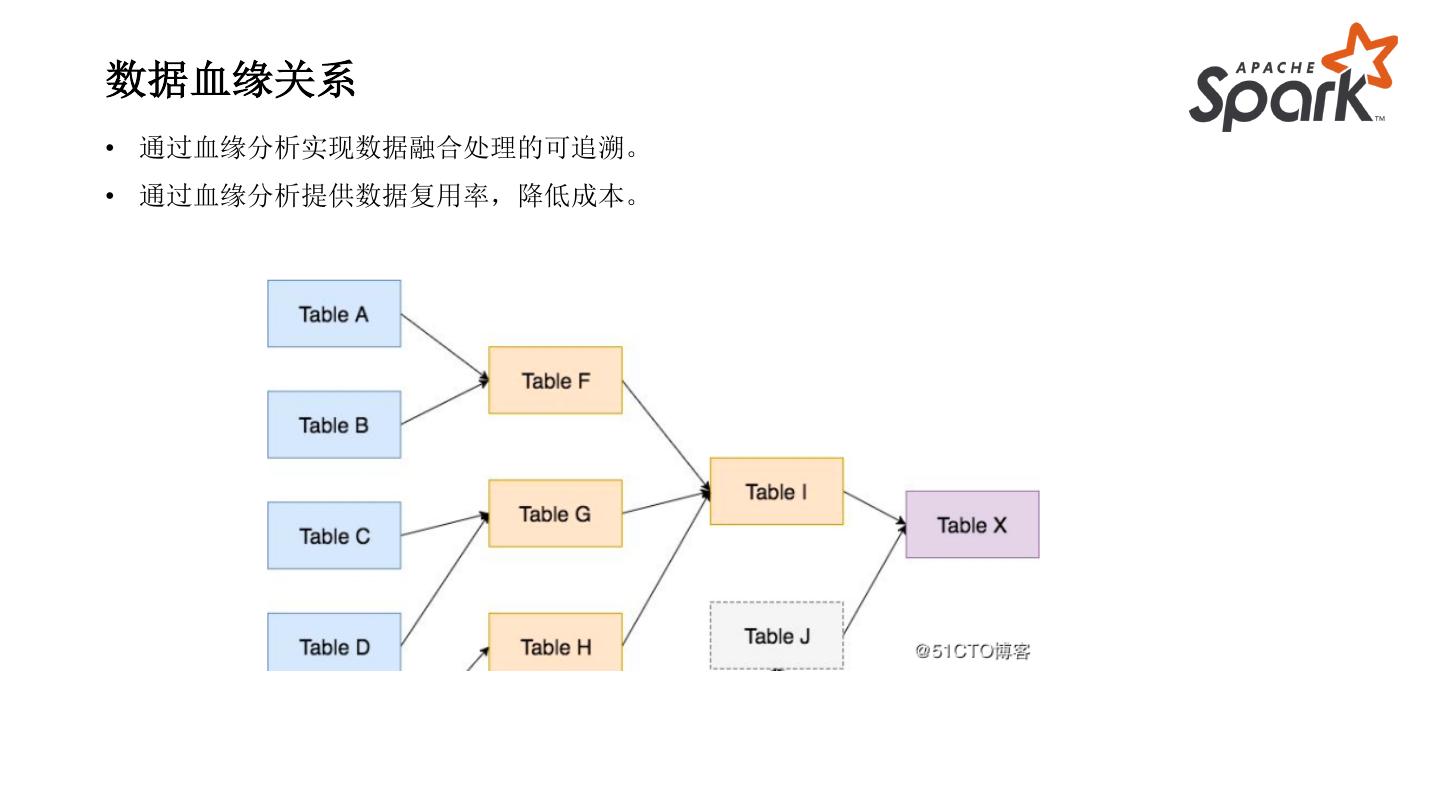
17 .数据血缘关系
• 通过血缘分析实现数据融合处理的可追溯。
• 通过血缘分析提供数据复用率,降低成本。
�
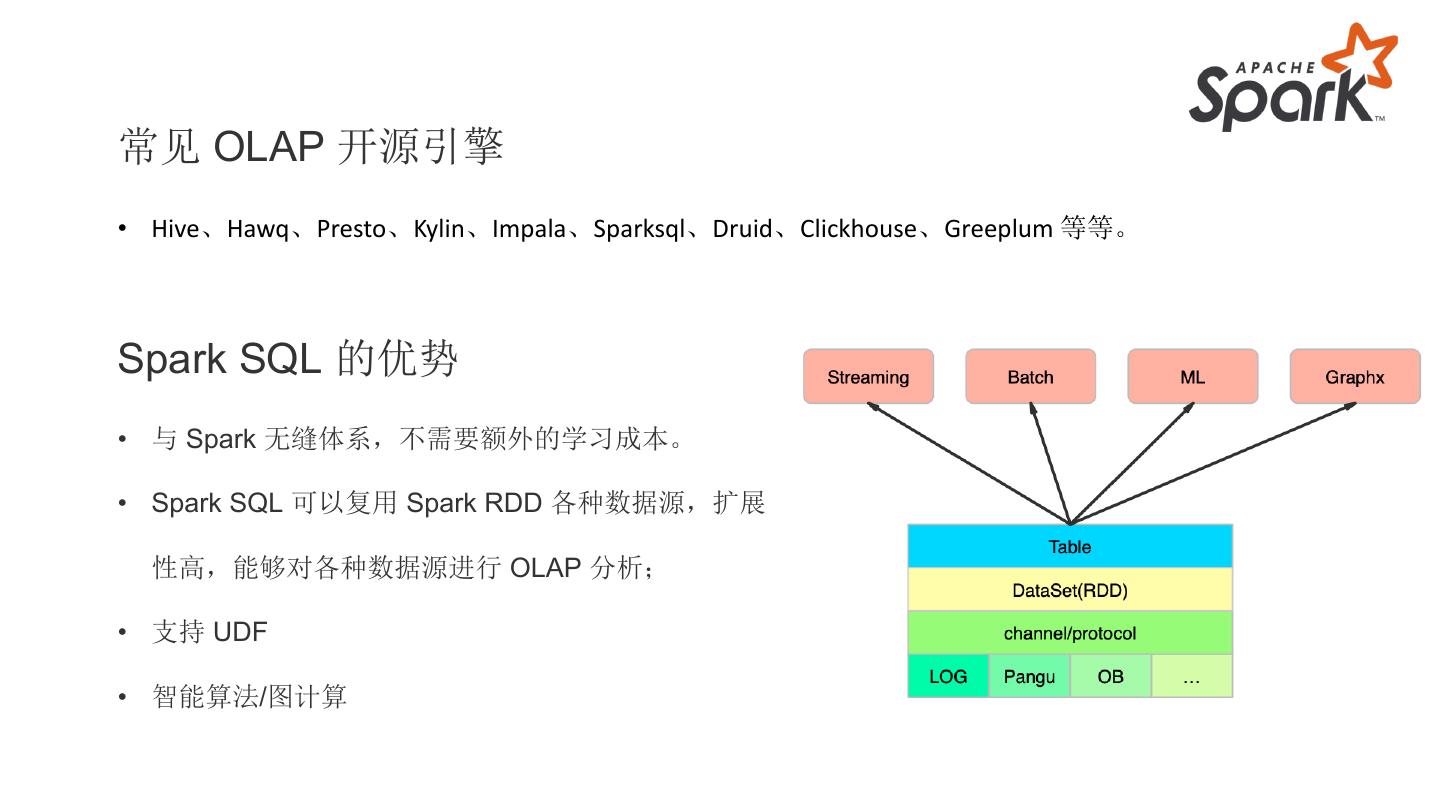
20 .与数据仓库 Match 的 Spark 技术栈(ETL/SQL/OLAP)
�
21 .02
Apache Flink : ververica.cn
© Apache Flink Community China
�
22 .E(Extract) T(Transform) L(Load)
• E:数据抽取,将数据从原始数据中抽取出来;
• T:数据转换,对数据进行结构化;
• L:数据加载,将数据加载到目的端(存储);
�
27 .RDD 如何抽取数据(Jdbc RDD):
�
28 .RDD 如何抽取数据:
• org.apache.spark.rdd.JdbcRDD#getPartitions
• 构建数据分片信息
• org.apache.spark.rdd.JdbcRDD#compute
• 根据分片信息加载对应分片的数据
• Org.apache.spark.rdd.RDD#getPreferredLocations
• 根据分区信息选择合适的执行节点(executor)
�
29 .自定义 RDD:
• N个分区
• 每个分区返回 100*partitionId~ 100*partitionId-1 之间的数据集合
�