展开查看详情
2 .MLflow实践与Project Hydrogen最新进展
阿⾥里里云-E-MapReduce 江宇
2019.6.19
�
3 .内容
1 2
MLflow Project Hydrogen
�
5 .MLflow
机器器学习流程和挑战
MLflow解决⽅方式
MLflow组件构成
MLflow系统演示
�
6 .MLflow
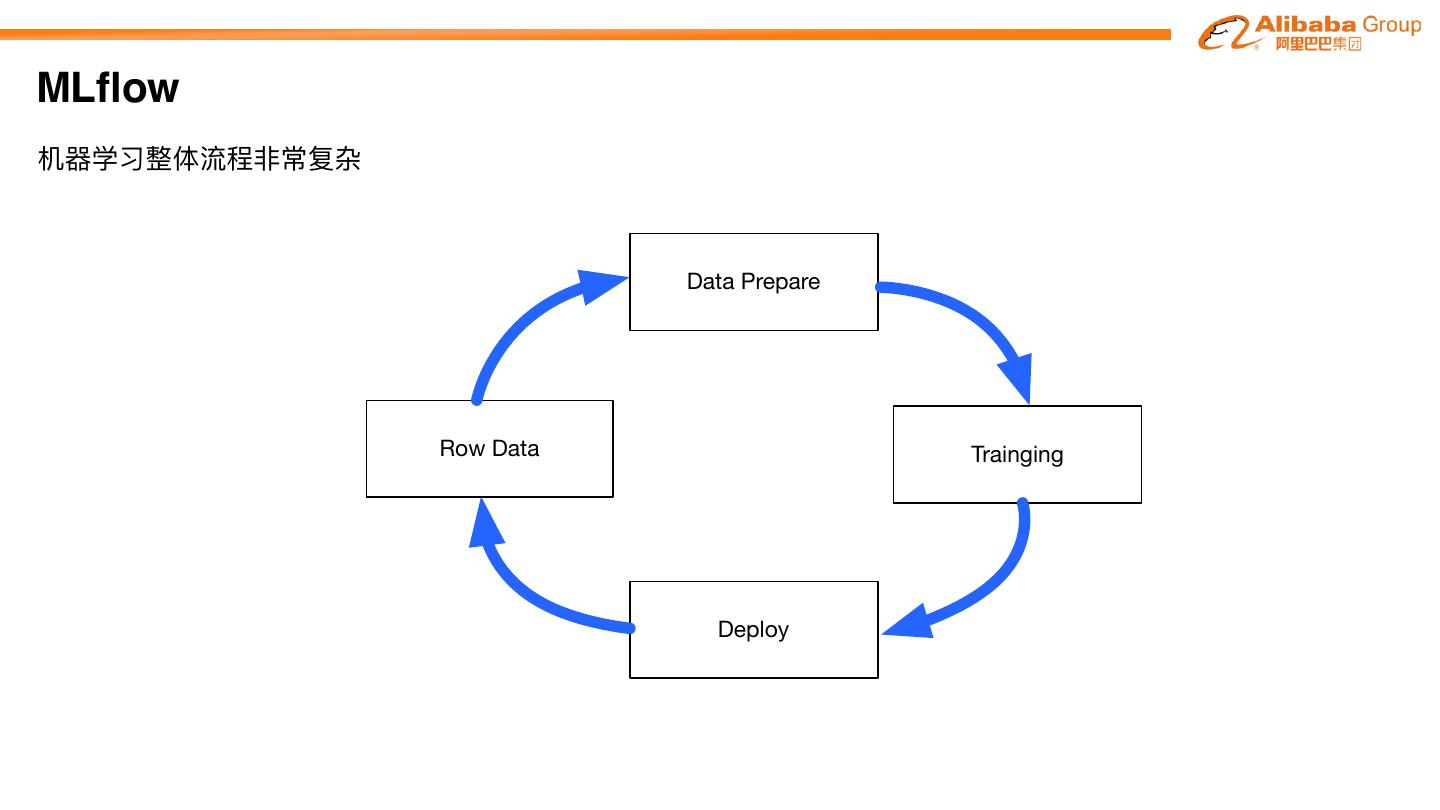
机器器学习整体流程⾮非常复杂
Data Prepare
Row Data Trainging
Deploy
�
7 .MLflow
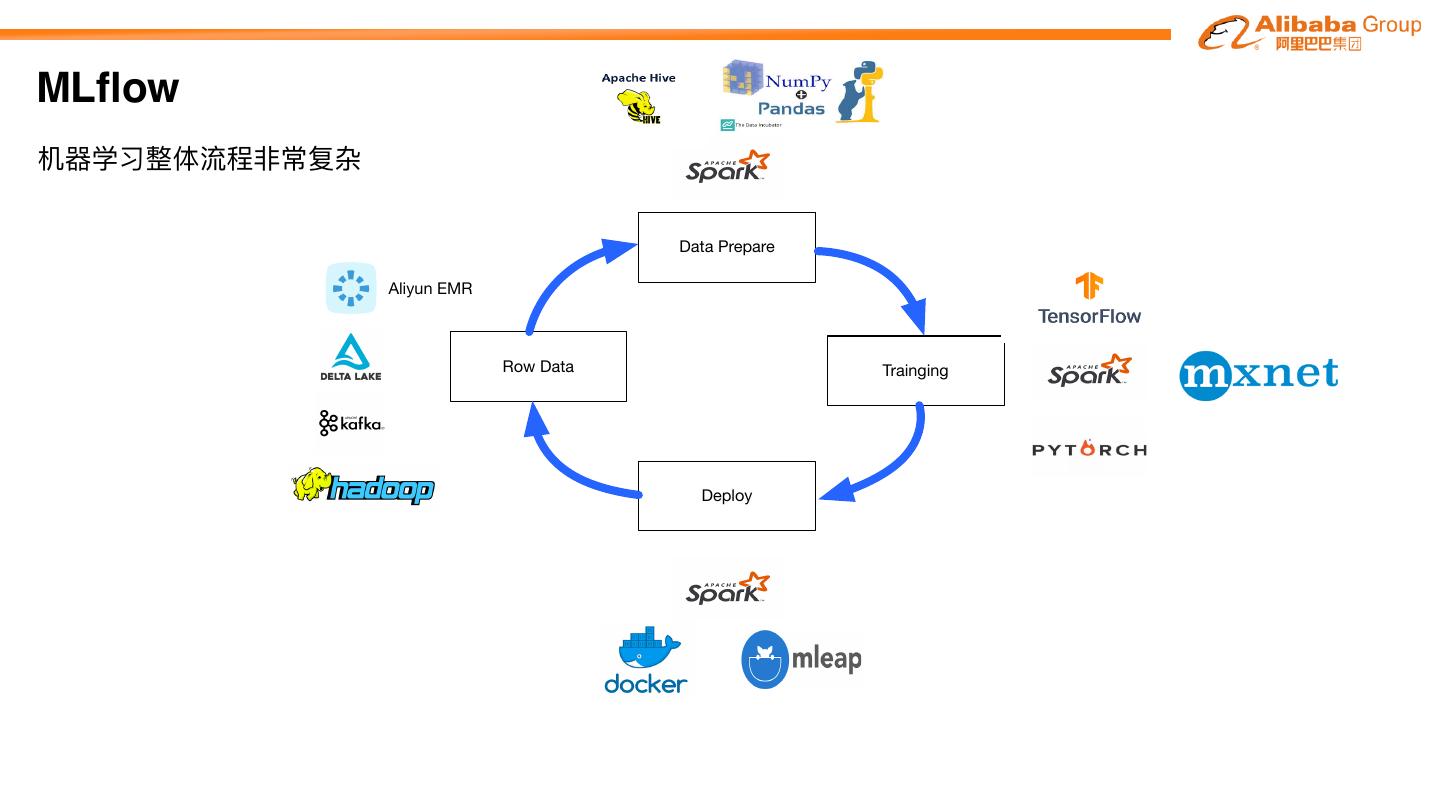
机器器学习整体流程⾮非常复杂
Data Prepare
Aliyun EMR
Row Data Trainging
Deploy
�
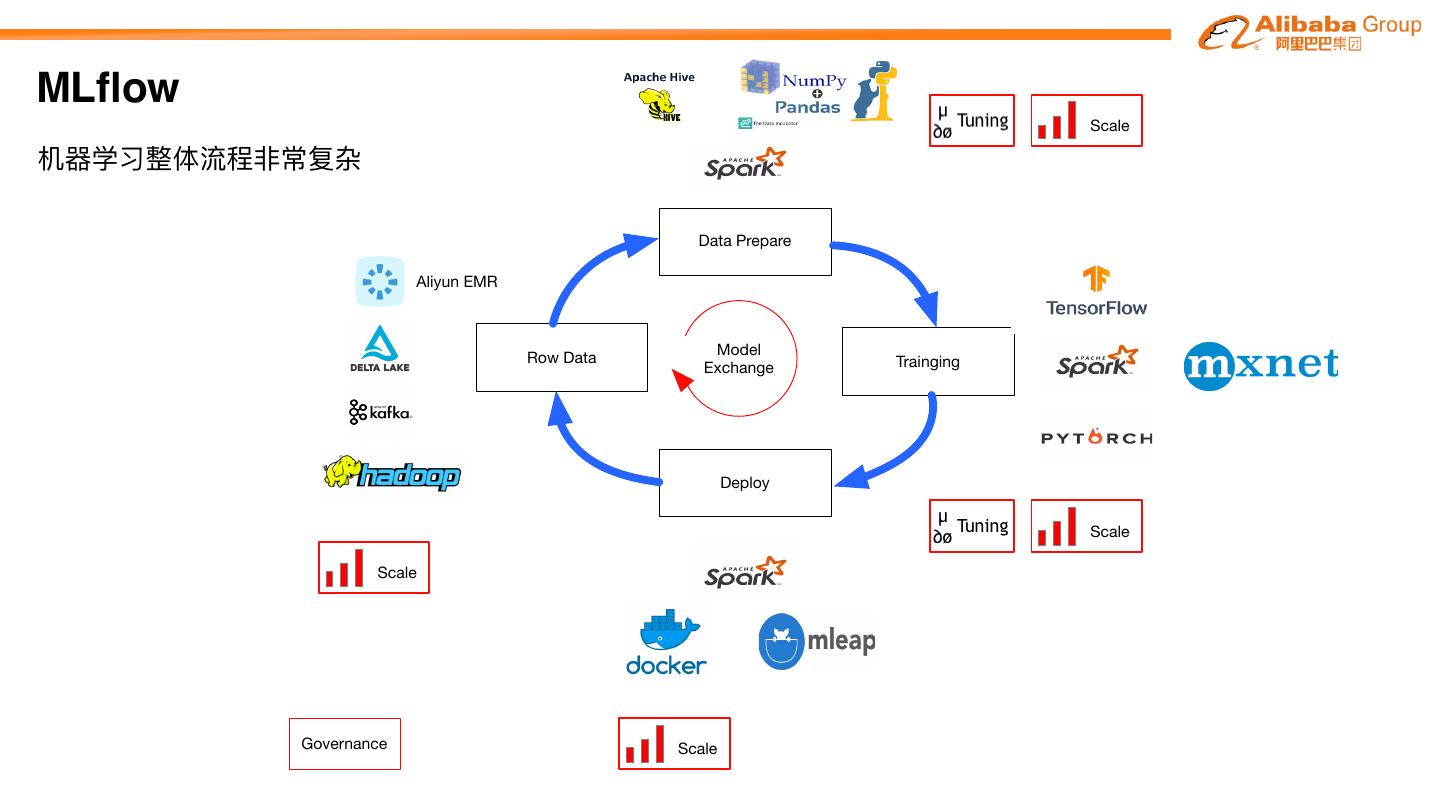
8 .MLflow
Scale
机器器学习整体流程⾮非常复杂
Data Prepare
Aliyun EMR
Model
Row Data Trainging
Exchange
Deploy
Scale
Scale
Governance Scale
�
9 .MLflow
机器器学习整体流程⾮非常复杂
hidden technical debt in machine learning systems
�
10 .MLflow
成熟的ML平台
Facebook FBLearner, Uber Michelangelo, Google TFX
+ 成熟的流程、包含了了从数据处理理、训练、部署的全流程
- 与公司的基础架构紧密结合,有限的算法
- 闭源
�
11 .MLflow
MLflow介绍
开源的机器器学习平台
‣ 兼容各种ML library和各种编程语⾔言 Python, Java, R
‣ 统⼀一的运⾏行行环境,可以运⾏行行任何地⽅方(⽐比如阿⾥里里云中)
‣ 设计时考虑到各种规模⽤用户,1或者1000+⼈人公司
发展历史
‣ 2018年年6⽉月开源
‣ 2019年年4⽉月 Spark AI⼤大会发布 1.0
�
13 .MLflow
MLflow — Tracking
MLflow import mlflow
with mlflow.start_run():
Tracking mlflow.log_param("x", 1)
mlflow.log_metric("y", 2)
with mlflow.start_run():
Record and Query for epoch in range(0, 3):
experiments:code, configs, mlflow.log_metric(key="quality", value=2*epoch, step=epoch)
results, parameters
…etc mlflow.log_artifact('/root/mlflow_tracking_example.py')
�
14 .MLflow
MLflow — Tracking 基本概念
• Code Version
• Start Time
• Source
• Parameters
• Metrics
• Artifacts
�
15 .MLflow
MLflow — Tracking
DEMO
�
16 .MLflow
MLflow — Tracking 存储
Backend Store
• File Store
• Database-backend Store
Artifact Store
• Aws S3
• Azure Blob Storage
• Google Cloud Storage
• FTP Server
• SFTP Server
• NFS
• HDFS
�
17 .MLflow
MLflow — Project
Local Execution
MLflow
Project
Packaging format Aliyun EMR
for reproducible runs Remote Execution
on any platform
Code Config Data
�
18 .MLflow
MLflow — Project
定义ml项⽬目的⽬目录结构
• 本地⽬目录或者Github仓库
• 可选的MLproject⽂文件⽤用于整个项⽬目配置
定义项⽬目的环境依赖
• Conda(Docker..)等依赖
• 可以在⼏几乎所有环境进⾏行行重复运⾏行行
通过API在本地或者远程运⾏行行
• mlflow run (cli)
• mlflow.projects.run() (API)
�
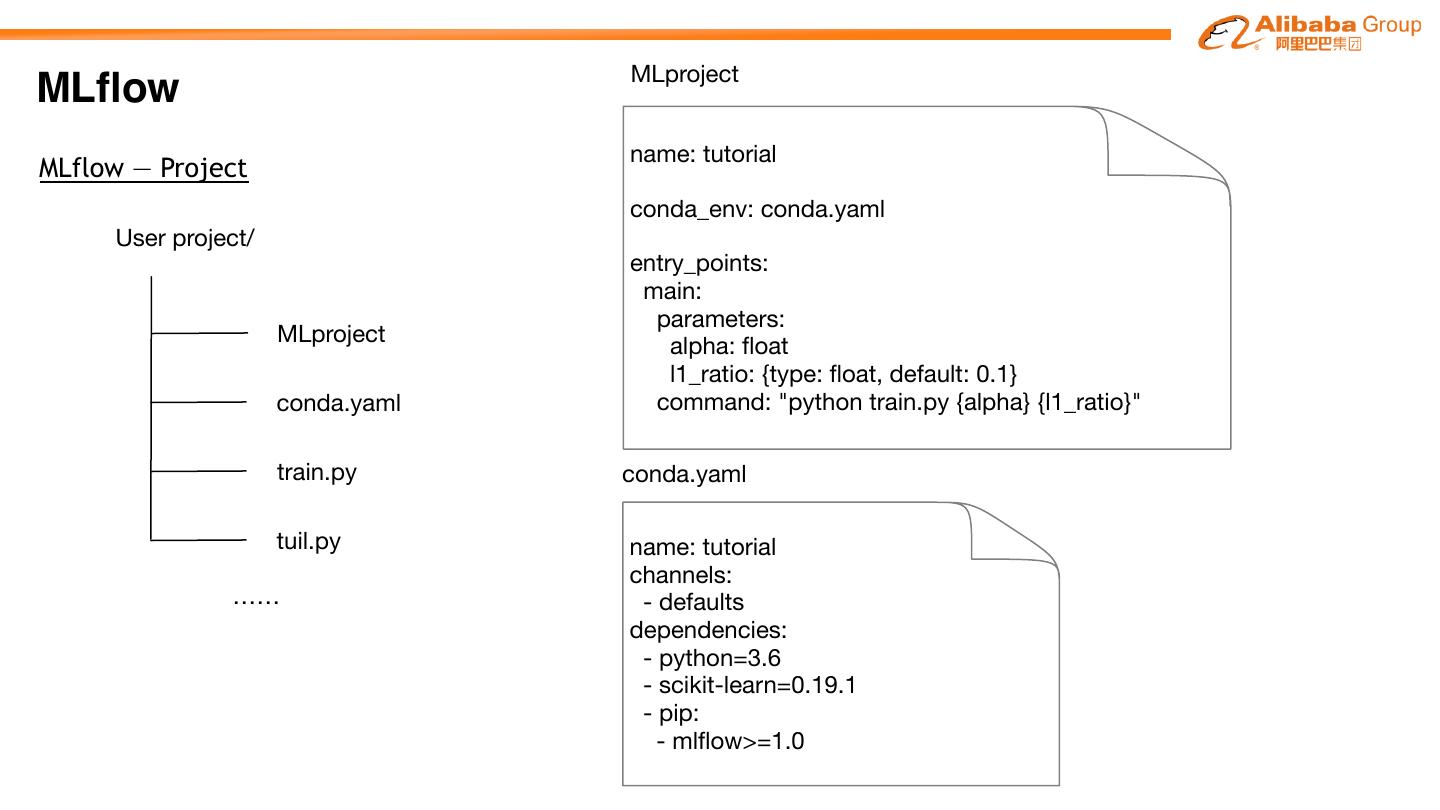
19 . MLproject
MLflow
name: tutorial
MLflow — Project
conda_env: conda.yaml
User project/
entry_points:
main:
parameters:
MLproject
alpha: float
l1_ratio: {type: float, default: 0.1}
conda.yaml command: "python train.py {alpha} {l1_ratio}"
train.py conda.yaml
tuil.py name: tutorial
channels:
…… - defaults
dependencies:
- python=3.6
- scikit-learn=0.19.1
- pip:
- mlflow>=1.0
�
20 .MLflow
MLflow — Project
DEMO
�
21 .MLflow
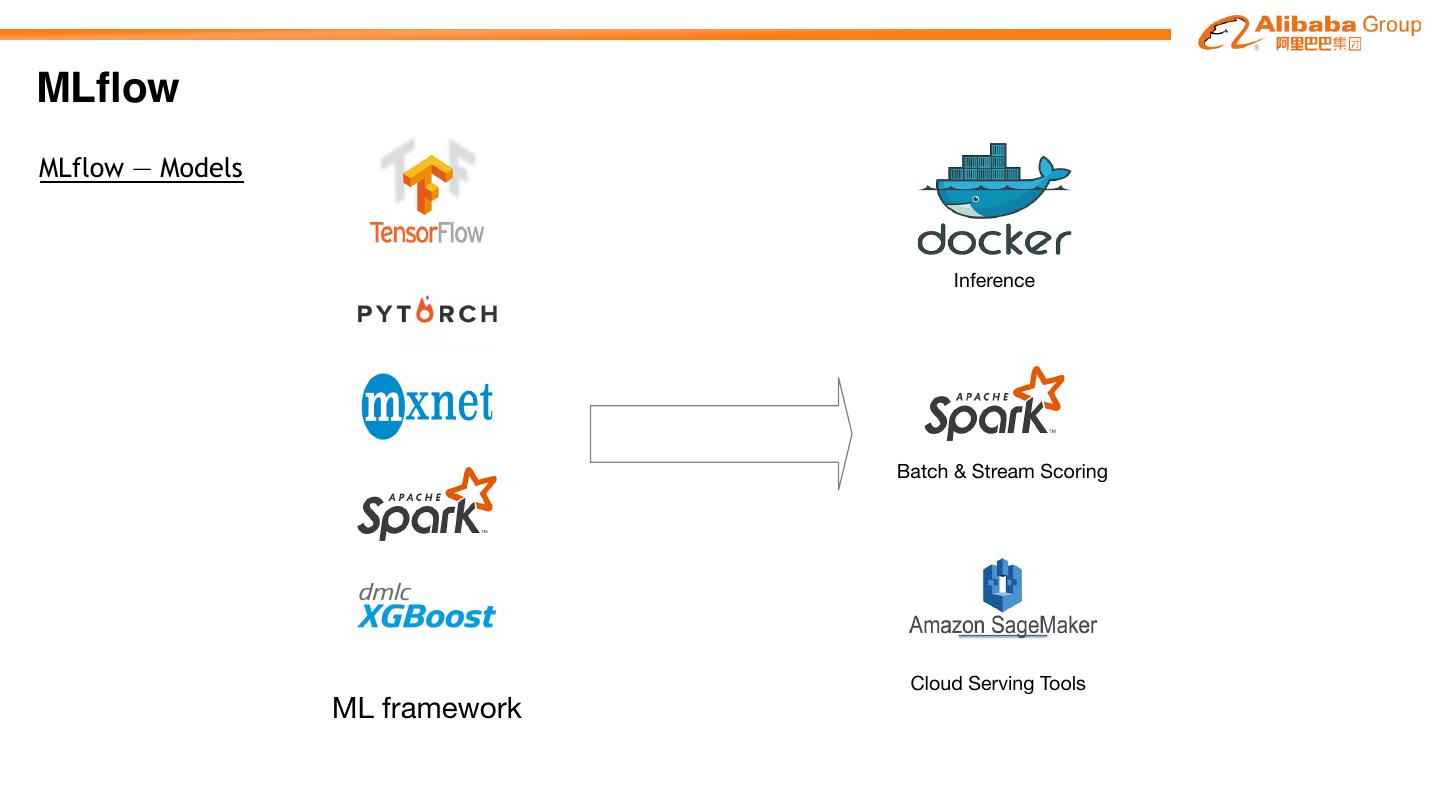
MLflow — Models
Inference
Batch & Stream Scoring
Cloud Serving Tools
ML framework
�
22 .MLflow
MLflow — Models
Inference
Mlflow
Model Format
Flavor 1 Flavor 1 Batch & Stream Scoring
sklearn TF
Cloud Serving Tools
ML framework
�
23 .MLflow
MLflow — Models
定义模型存储格式
• 根据MLmodel⽂文件来定义各种
• 不不同框架具有不不同flavors(格式)
定义项⽬目的环境依赖
• Conda(Docker..)等依赖
• 可以在⼏几乎所有环境进⾏行行重复运⾏行行
通过API在本地或者远程运⾏行行
• mlflow server(cli)
• mlflow.sklearn.load() (API)
�
24 .MLflow MLmodel
flavors:
MLflow — Model python_function:
data: model.pkl
env: conda.yaml
loader_module: mlflow.sklearn
User_model / python_version: 3.6.5
sklearn:
pickled_model: model.pkl
serialization_format: cloudpickle
MLmodel
sklearn_version: 0.19.1
utc_time_created: '2019-06-17 02:46:05.185724'
conda.yaml
model.pkl conda.yaml
channels:
……
- defaults
dependencies:
- python=3.6.5
- scikit-learn=0.19.1
- pip:
- mlflow
- cloudpickle==0.5.3
name: mlflow-env
�
25 .MLflow
MLflow — Model
• Python Function (generic)
• R Function
• H20
• Keras
• MLeap
• PyTorch
• SKlearn
• Spark MLlib
• TensorFlow
• ONNX
�
26 .MLflow
MLflow — Model
DEMO
�
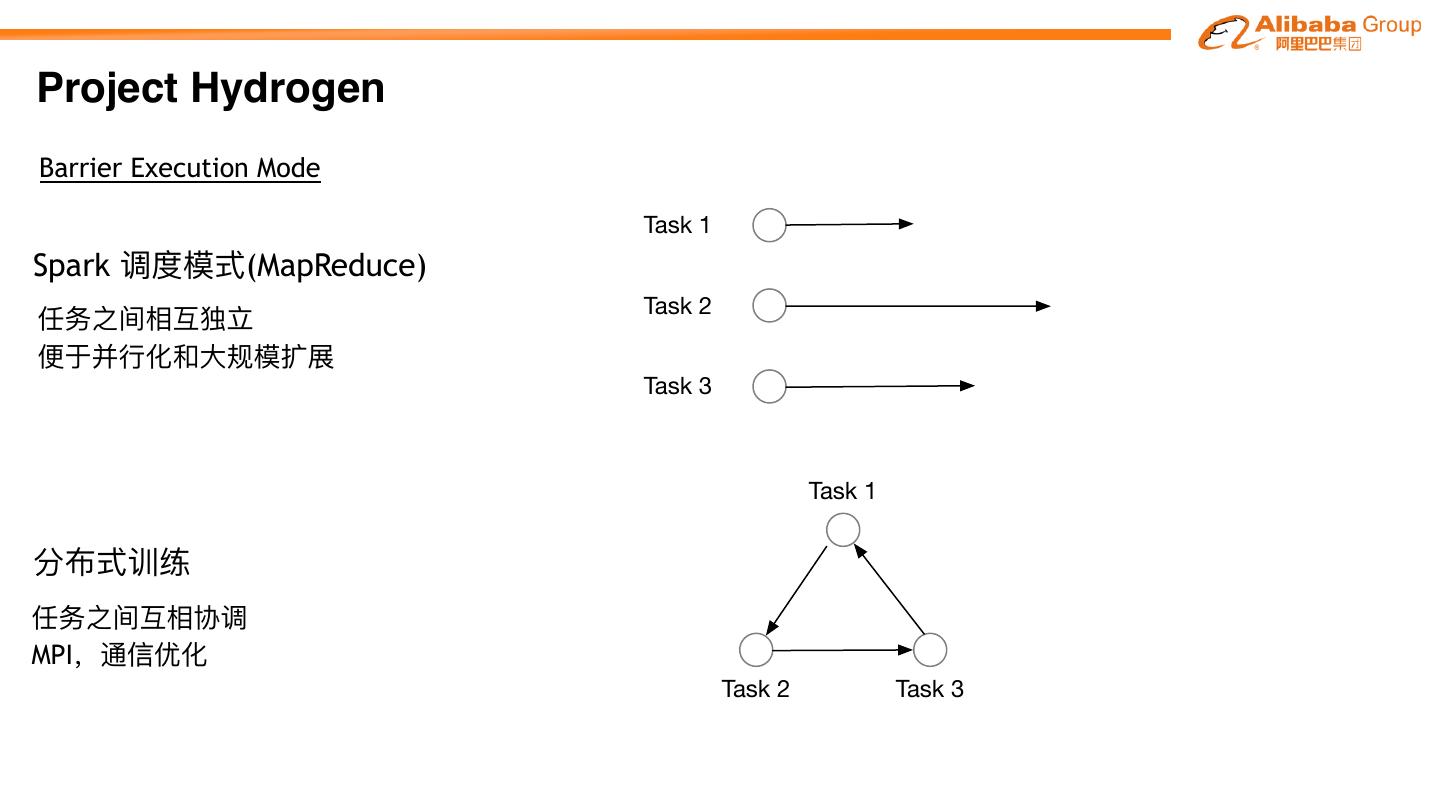
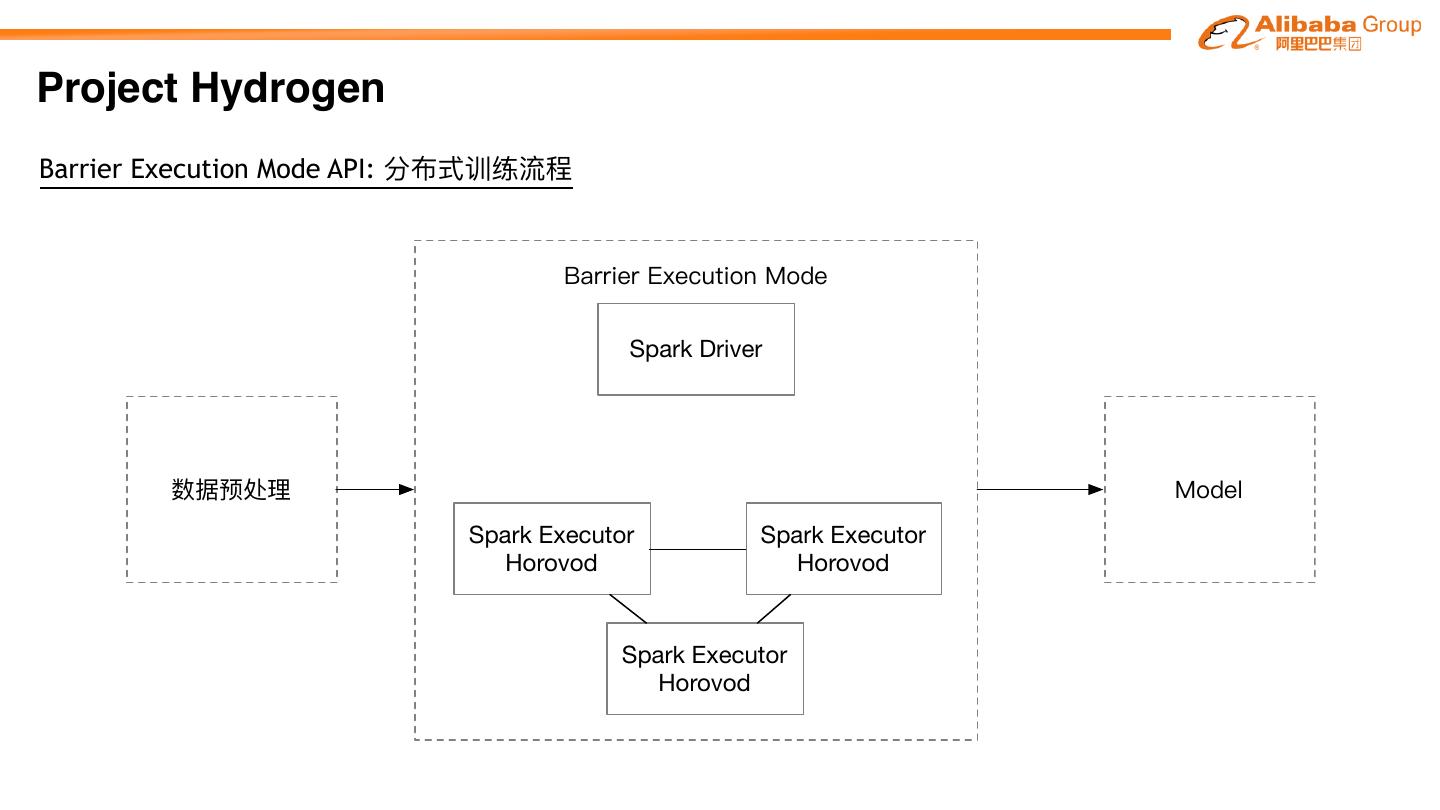
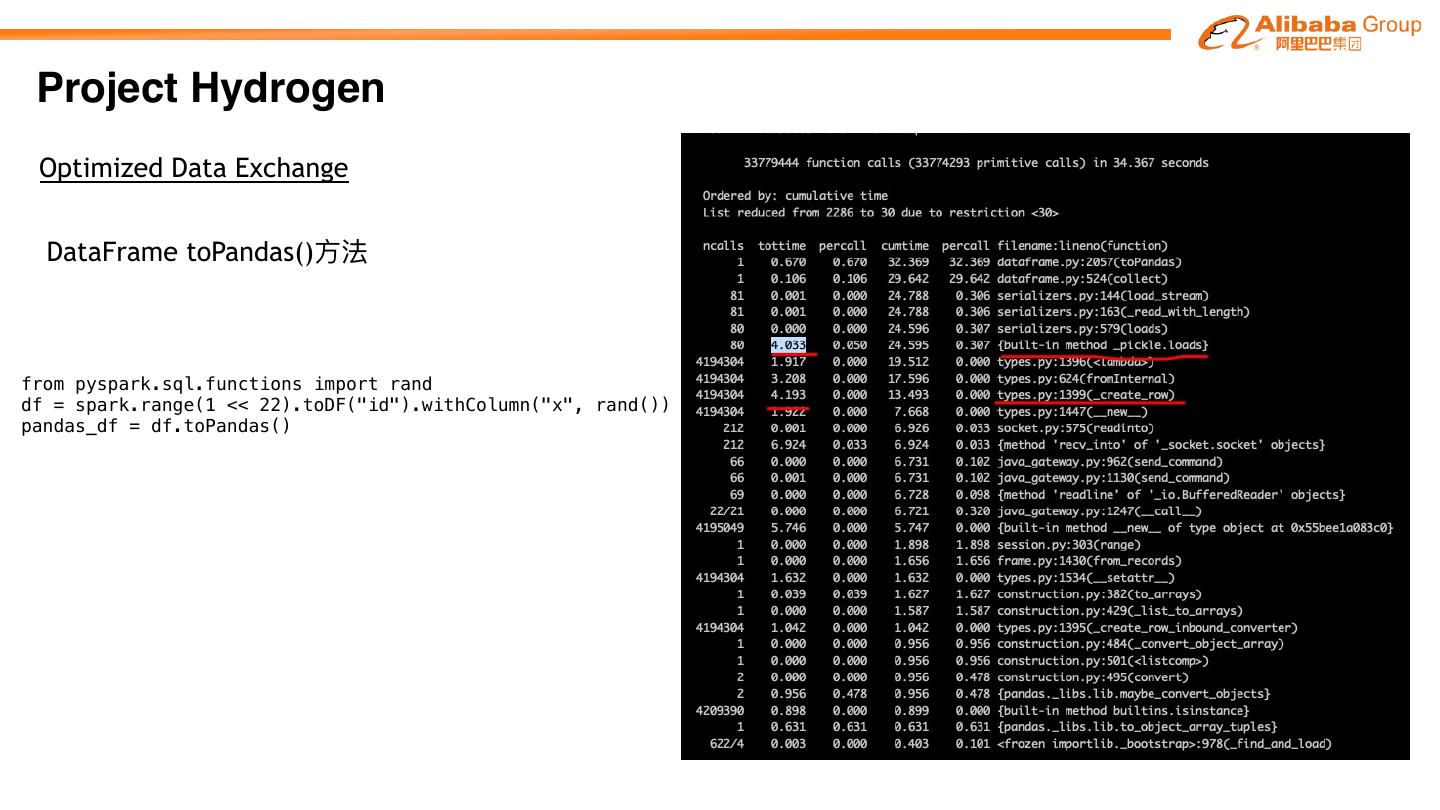
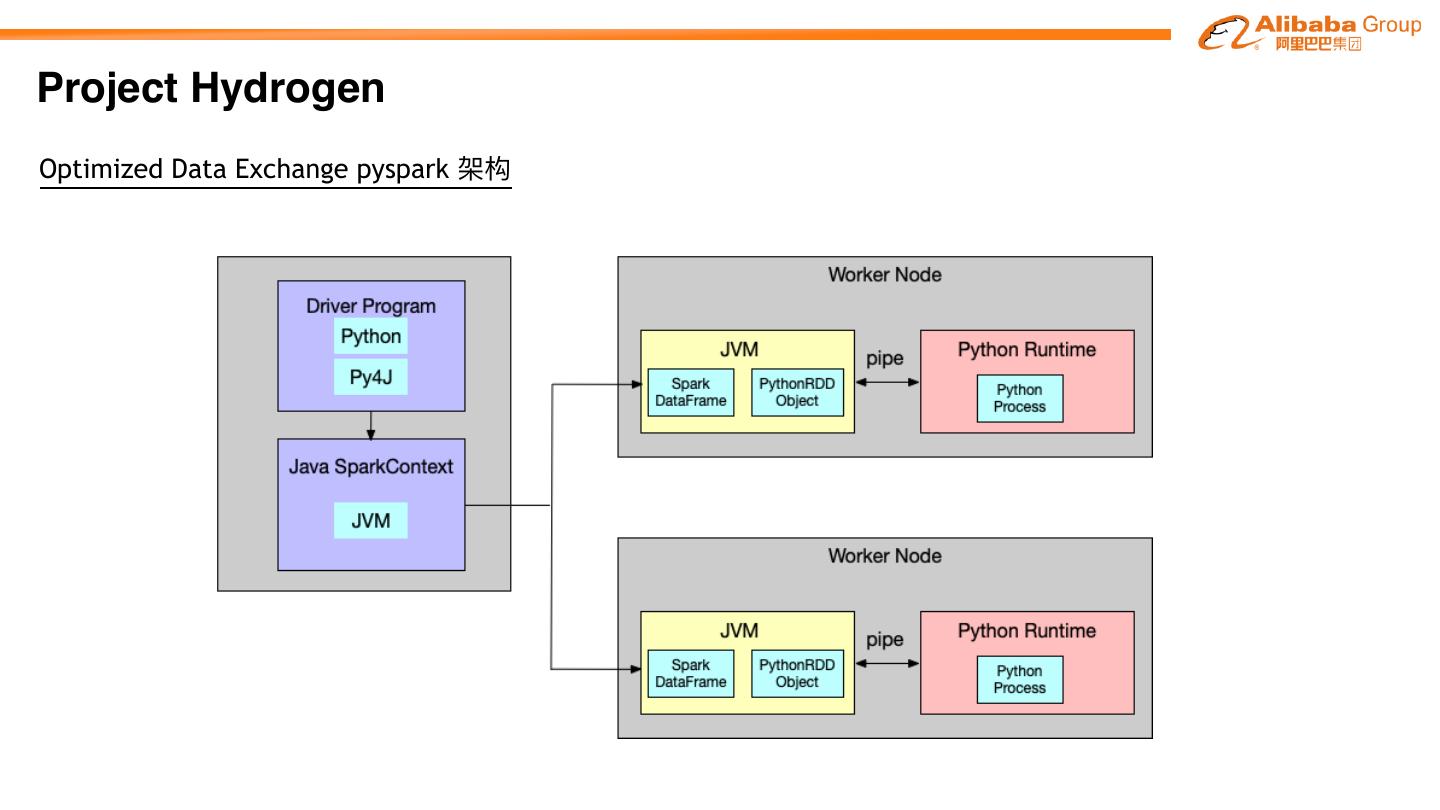
27 .Project Hydrogen
Part II
�
28 .Project Hydrogen
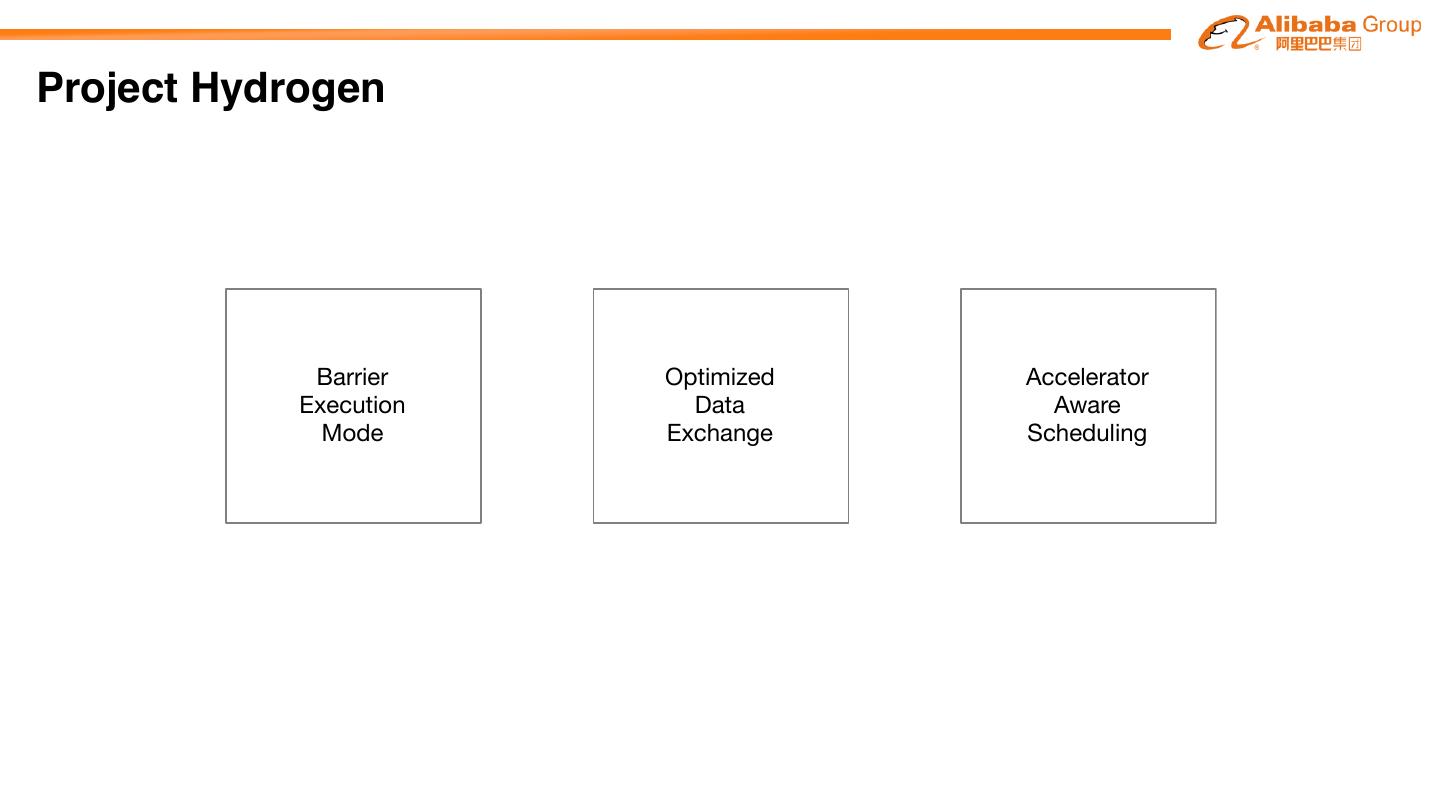
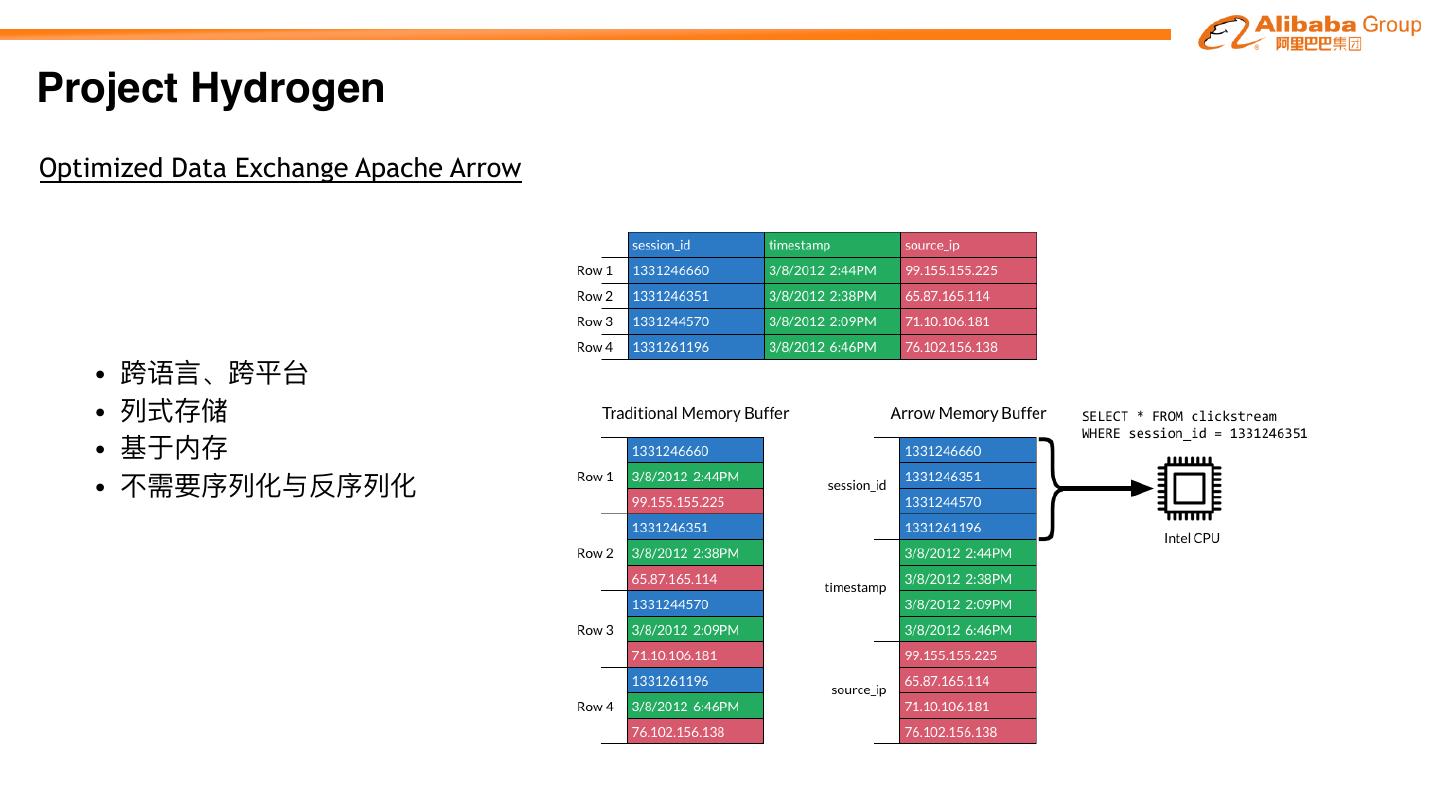
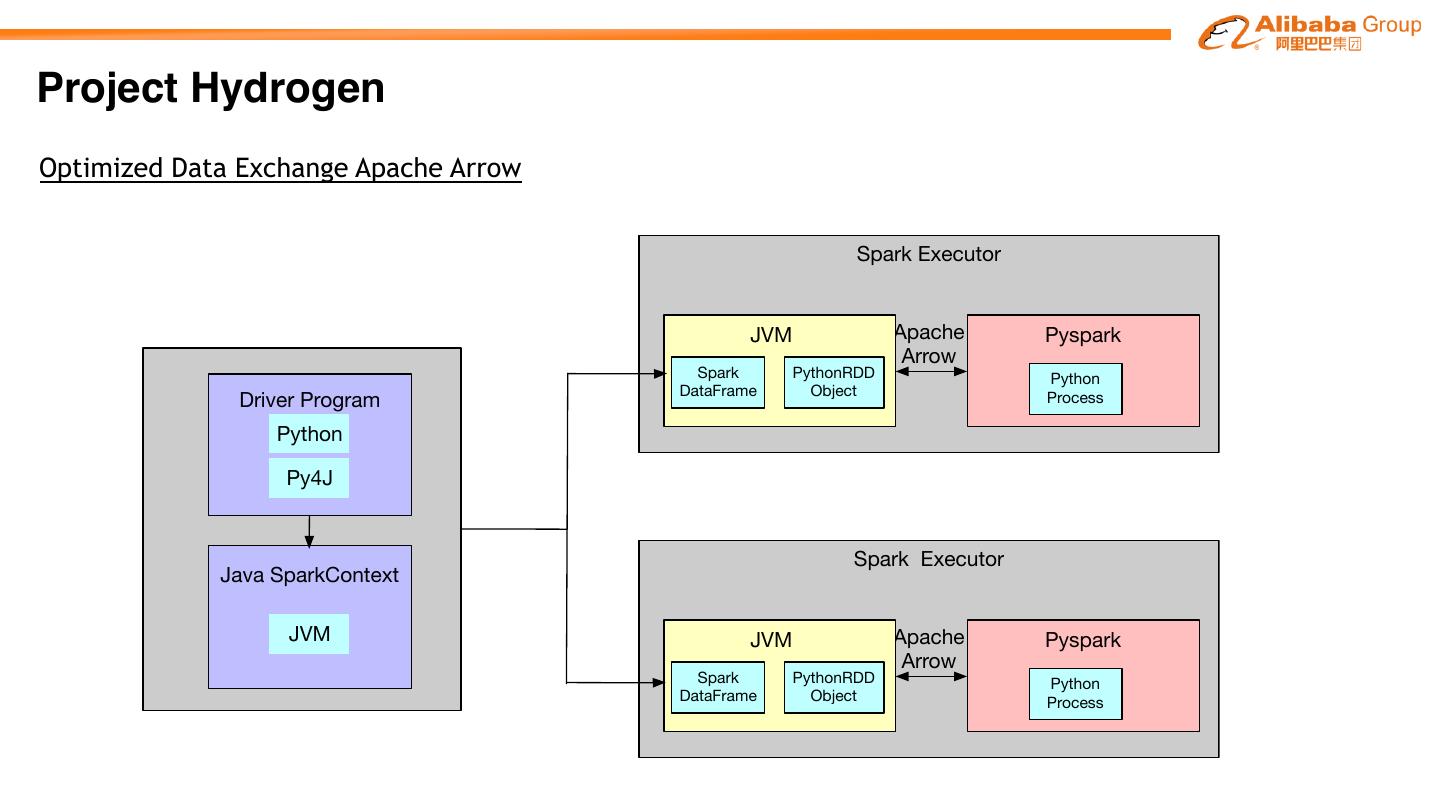
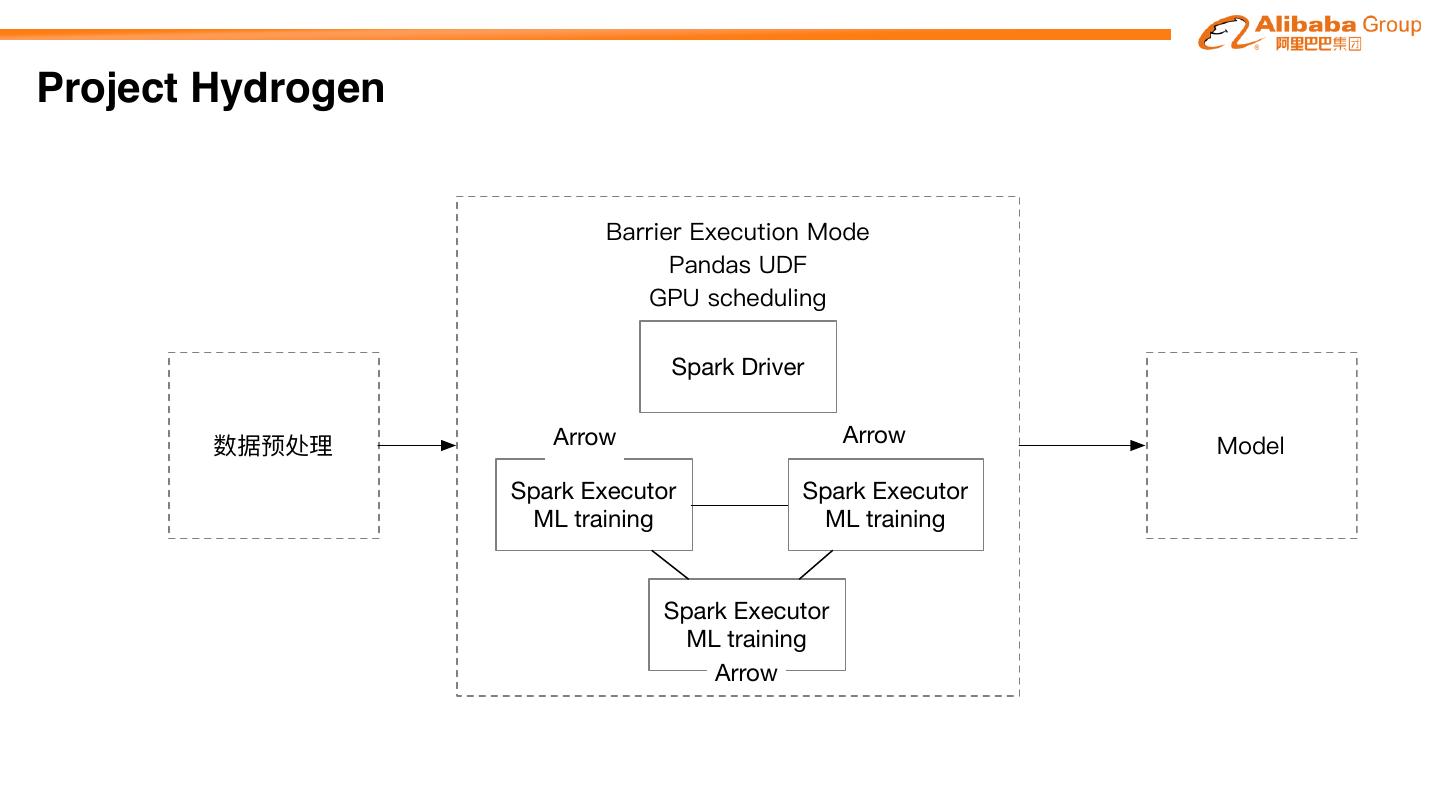
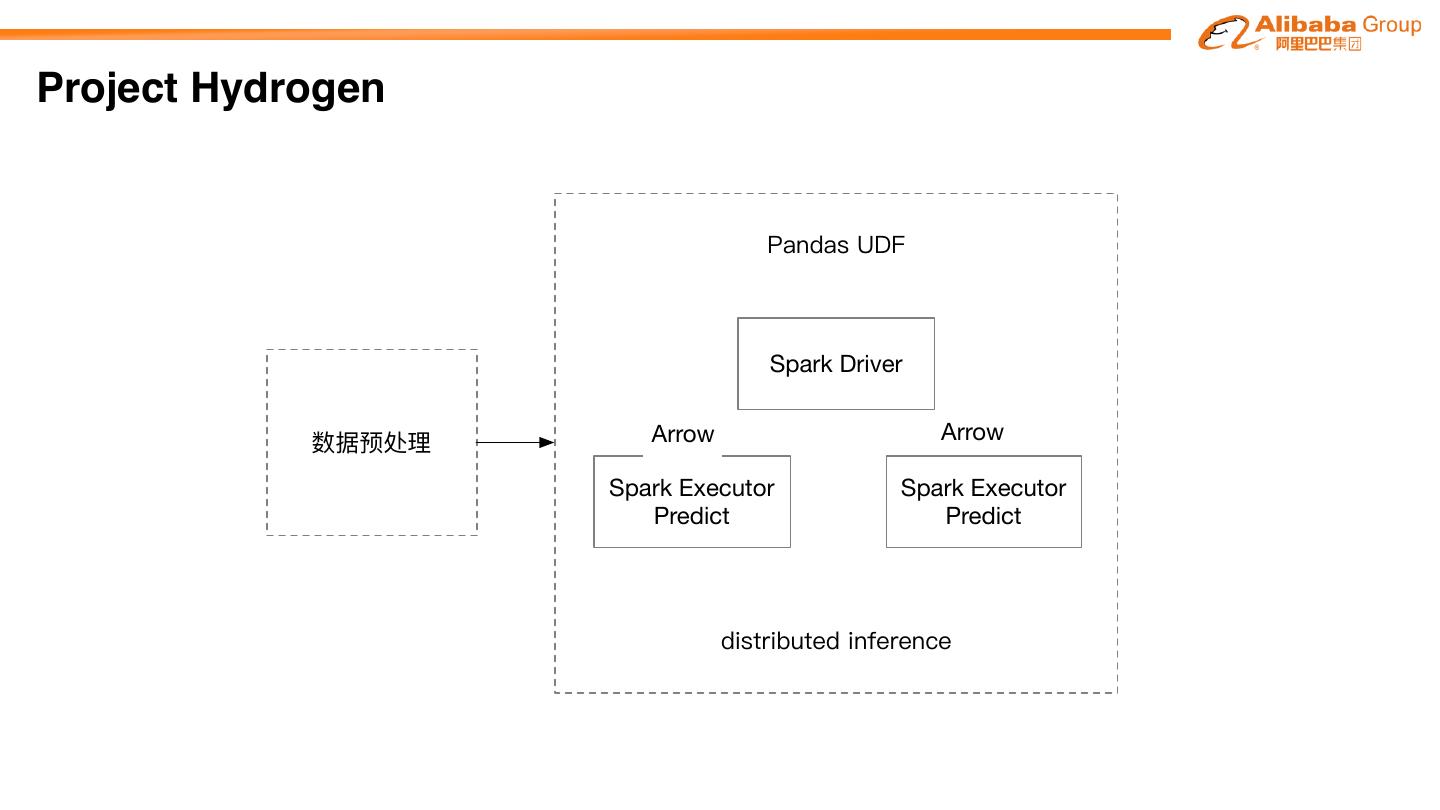
Project Hydrogen aims at enabling first-class support for all distributed machine learning
frameworks on Apache SparkTM, by substantially improving the performance and fault-recovery of
distributed deep learning and machine learning frameworks on Spark
Barrier Optimized Accelerator
Execution Data Aware
Mode Exchange Scheduling
�
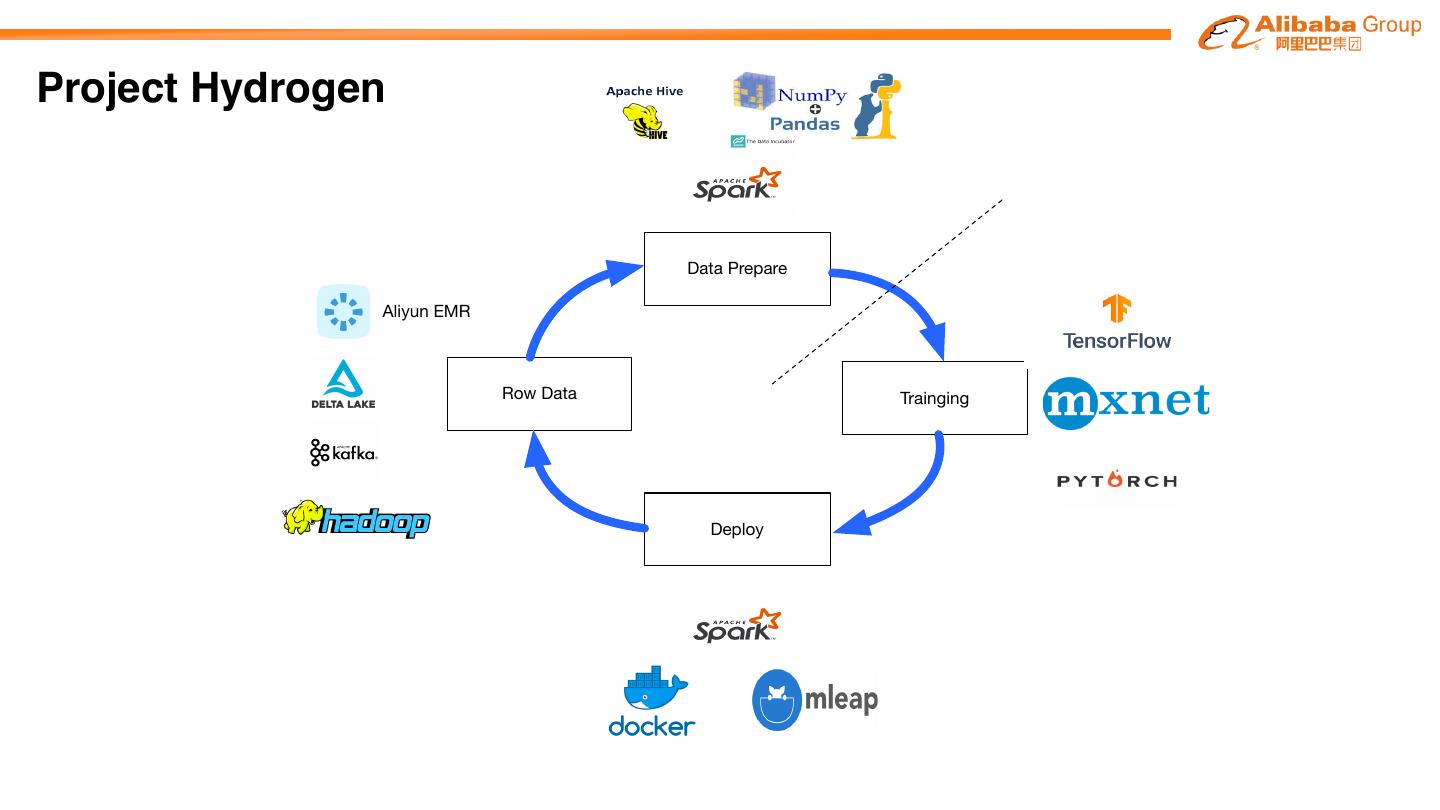
29 .Project Hydrogen
Data Prepare
Aliyun EMR
Row Data Trainging
Deploy
�