
































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 视频嵌入链接 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Migration to Apache Spark
分享
点赞
10
收藏
3
5月29日【Migration to Apache Spark】
讲师:宋军,花名嵩林,阿里云EMR技术专家。从事Spark内核优化,对SparkCore/SprakSQL有深入了解,Spark Contributor
内容简介:Spark因其统一引擎、性能、易用性等特点备受青睐,将大数据处理引擎迁移到Spark已经成为一种趋势(比如将Hive迁移到SparkSQL),很多大公司也正在实践。
本次分享将围绕Hive迁移到SparkSQL进行展开,内容包括介绍大公司迁移流程、遇到的问题以及对Spark做的一些反馈优化。
阿里巴巴开源大数据EMR技术团队成立Apache Spark中国技术社区,定期打造国内Spark线上线下交流活动。请持续关注。
钉钉群号:21784001
团队群号:HPRX8117
微信公众号:Apache Spark技术交流社区
展开查看详情
1 .7点开始 Apache Spark中国技术社区
2 .Migration to Apache Spark 阿⾥里里云-E-MapReduce 嵩林林 2019.05.29
3 .内容 1 2 3 为什什么要迁移 怎么迁移 公司案例例
4 .为什什么要迁移 Part I
5 .为什什么要迁移 数据仓库系统 ETL Data DW OLAP Analytics
6 .为什什么要迁移 ETL • 多数据源⽀支持 外部数据源经过数据清洗/规范化加载到DW • 丰富的UDF • SQL⽀支持度 OLAP • 周边⼯工具 提供⾼高性能的查询 ROLAP/MOLAP/HOLAP • 社区活跃度 • ⽣生态 • ⾼高性能查询
7 .为什什么要迁移 Hive vs SparkSQL • 多数据源⽀支持 Hive SparkSQL Hive StorageHandlers Hive StorageHandlers https://cwiki.apache.org/confluence/display/Hive/StorageHandlers HBase/Kafka/Druid/JDBC/… HBase/Kafka/Druid/JDBC/… + https://spark-packages.org/?q=tags%3A%22Data%20Sources%22 + MaxCompute/tablestore/… https://github.com/aliyun/aliyun-emapreduce-sdk
8 .为什什么要迁移 Hive vs SparkSQL • 丰富的UDF Hive SparkSQL 内置UDF 基本实现所有的Hive UDF, 性能好 ⾃自定义Hive UDF 可以使⽤用⾃自定义Hive UDF, 有可能会有 多线程/性能问题,Facebook有⼀一些分享
9 .为什什么要迁移 Hive vs SparkSQL • SQL⽀支持度 Hive SparkSQL TPC-DS 99 queries TPC-DS 99 queries
10 .为什什么要迁移 Hive vs SparkSQL • 周边⼯工具 Hive SparkSQL hive -f / -e spark-sql -f / -e JDBC API JDBC API HiveServer2 SparkThriftServer Hue Hue Zeppelin Zeppelin Ranger Livy Ranger https://issues.apache.org/jira/browse/RANGER-2128
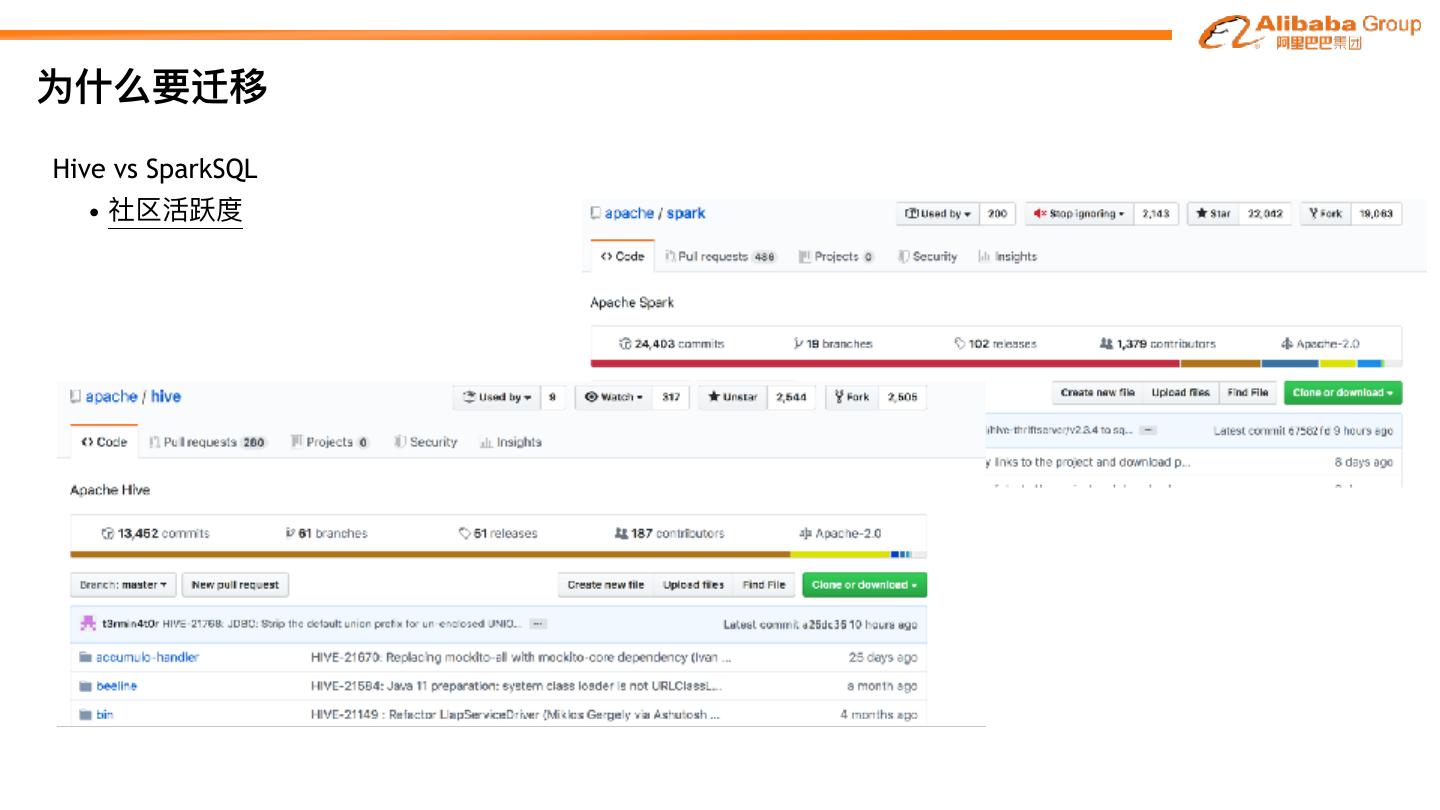
11 .为什什么要迁移 Hive vs SparkSQL • 社区活跃度
12 .为什什么要迁移 Hive vs SparkSQL • 社区活跃度 SparkSQL
13 .为什什么要迁移 Hive vs SparkSQL • 社区活跃度 SparkSQL
14 .为什什么要迁移 Hive vs SparkSQL • 社区活跃度 SparkSQL
15 .为什什么要迁移 Hive vs SparkSQL • ⽣生态 SparkSQL Hive 统⼀一引擎 ⽀支持批处理理/流计算/机器器学习等 批处理理 SQ StructStreaming MLlib SparkR GraphX DataFrame/DataSet SparkCore DataSource
16 .为什什么要迁移 Hive vs SparkSQL • ⾼高性能查询 Hive SparkSQL Hive on MR Catalyst查询优化器器优化 Hive on Tez shuffle优化 Relational Cache(物化视图/cube) Hive on Spark PK/FK约束优化
17 .为什什么要迁移 Hive vs SparkSQL • ⾼高性能查询 减少数据量量 DataSkipping / Runtime Filter / GroupBy Placement / … 减少计算 Relational Cache 预计算/空间换时间 利利⽤用PK/FK join 消除 主键是distinct可以消除 More JoinReorder / shuffle
18 .为什什么要迁移 Hive vs SparkSQL 总结 • 多数据源⽀支持 • 丰富的UDF • SQL⽀支持度 • 周边⼯工具 • 社区活跃度 • ⽣生态 • ⾼高性能查询
19 .内容 1 2 3 为什什么要迁移 怎么迁移 公司案例例
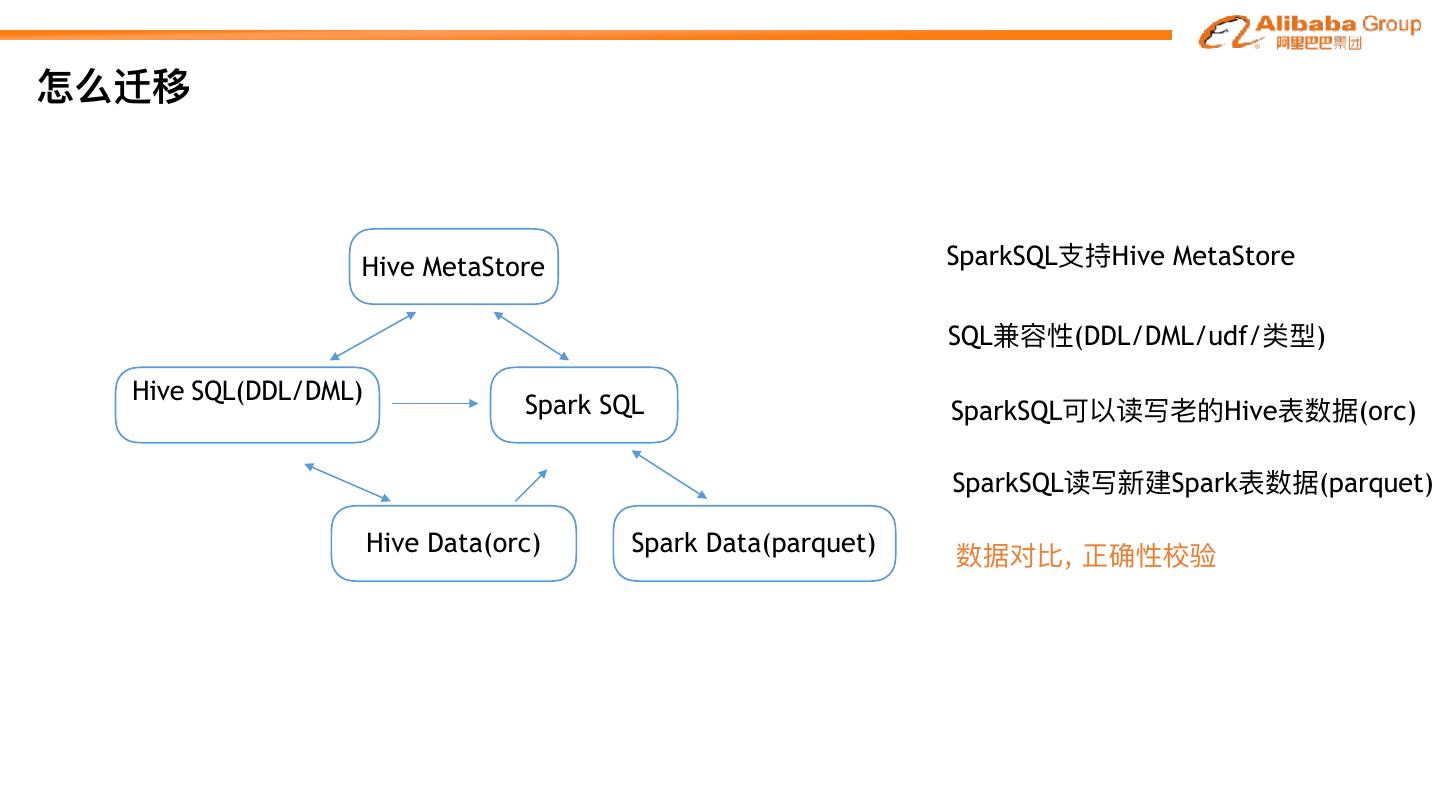
20 .怎么迁移 Hive MetaStore SparkSQL⽀支持Hive MetaStore SQL兼容性(DDL/DML/udf/类型) Hive SQL(DDL/DML) Spark SQL SparkSQL可以读写⽼老老的Hive表数据(orc) SparkSQL读写新建Spark表数据(parquet) Hive Data(orc) Spark Data(parquet) 数据对⽐比, 正确性校验
21 .怎么迁移 SparkSQL⽀支持Hive MetaStore val spark = SparkSession .builder() .appName("Spark Hive Example") .enableHiveSupport() .getOrCreate() spark.sql(“select * from test”) spark.sql(“create table test1(a string, b int) using parquet”) spark-submit: 将hive-site.xml放到spark-conf⽬目录下 yarn-cluster模式需要—files /path/to/hive-site.xml spark-sql/SparkThriftServer: 将hive-site.xml放到spark-conf⽬目录下
22 .怎么迁移 SQL兼容性(DDL/DML/udf/类型) DDL(create table /create table as / alter table) sqlbase.g4 Spark DDL create table t1(a string,b int) partitioned by(a) using parquet; Hive DDL ok! create table t2(c string,d int) partitioned by(e string) using parquet;
23 .怎么迁移 SQL兼容性(DDL/DML/udf/类型) DML select / insert / update /delete /merge /explain SparkSQL开源版本不不⽀支持update/delete/merge操作, EMR参考Hive实现了了⼀一套逻辑。 ⽬目前⽀支持parquet格式,如果有需求兼容Hive的事物表(orc),可以联系我们
24 .怎么迁移 SQL兼容性(DDL/DML/udf/类型) SparkSQL事务 场景 流程 存储Layout 数据删除/订正 insert/select并发控制
25 .怎么迁移 SQL兼容性(DDL/DML/udf/类型) DML select * from A join B on when a.user_id is null then concat('x',rand() ) else a.user_id end = b.user_id Error in query: nondeterministic expressions are only allowed in Project, Filter, Aggregate or Window, found: work around select * from (select *, a.user_id is null then concat('x',rand() ) else a.user_id end as z from A) C join B on C.z= b.user_id ⼿手⼯工改写 / 反馈社区 / 提给我们
26 .怎么迁移 SQL兼容性(DDL/DML/udf/类型) UDF Hive内置的⼤大部分UDF,SparkSQL都内部重新实现,性能更更优 同时⽀支持Hive UDF的jar注册函数 add jar hdfs://emr-header-1:9000/tmp/xx.jar create function func_1 as ‘com.test.aliyun.xxx’
27 .怎么迁移 SQL兼容性(DDL/DML/udf/类型) 类型 hive> CREATE TABLE parquet_struct_type ( • INYINT > id int, • SMALLINT > st1 struct<f1:int, f2:string>, • INT > st2 struct<f1:int, f3:string> • BIGINT > ) STORED AS PARQUET; • BOOLEAN • FLOAT • DOUBLE • STRING • BINARY • TIMESTAMP • DATE • ARRAY<> • MAP<> • STRUCT<> SparkSQL查询兼容
28 .怎么迁移 SparkSQL可以读写⽼老老的Hive表数据(orc) Native vectorized ORC reader • Native ORC reader is on by default [SPARK-23456] • Update ORC from 1.4.1 to 1.5.2 [SPARK-24576] 对orc做了了很多性能优化 可以读写Hive的orc表 • Turn on ORC filter push-down by default [SPARK-21783] • Use native ORC reader to read Hive serde tables by default [SPARK-22279] • Avoid creating reader for all ORC files [SPARK-25126]
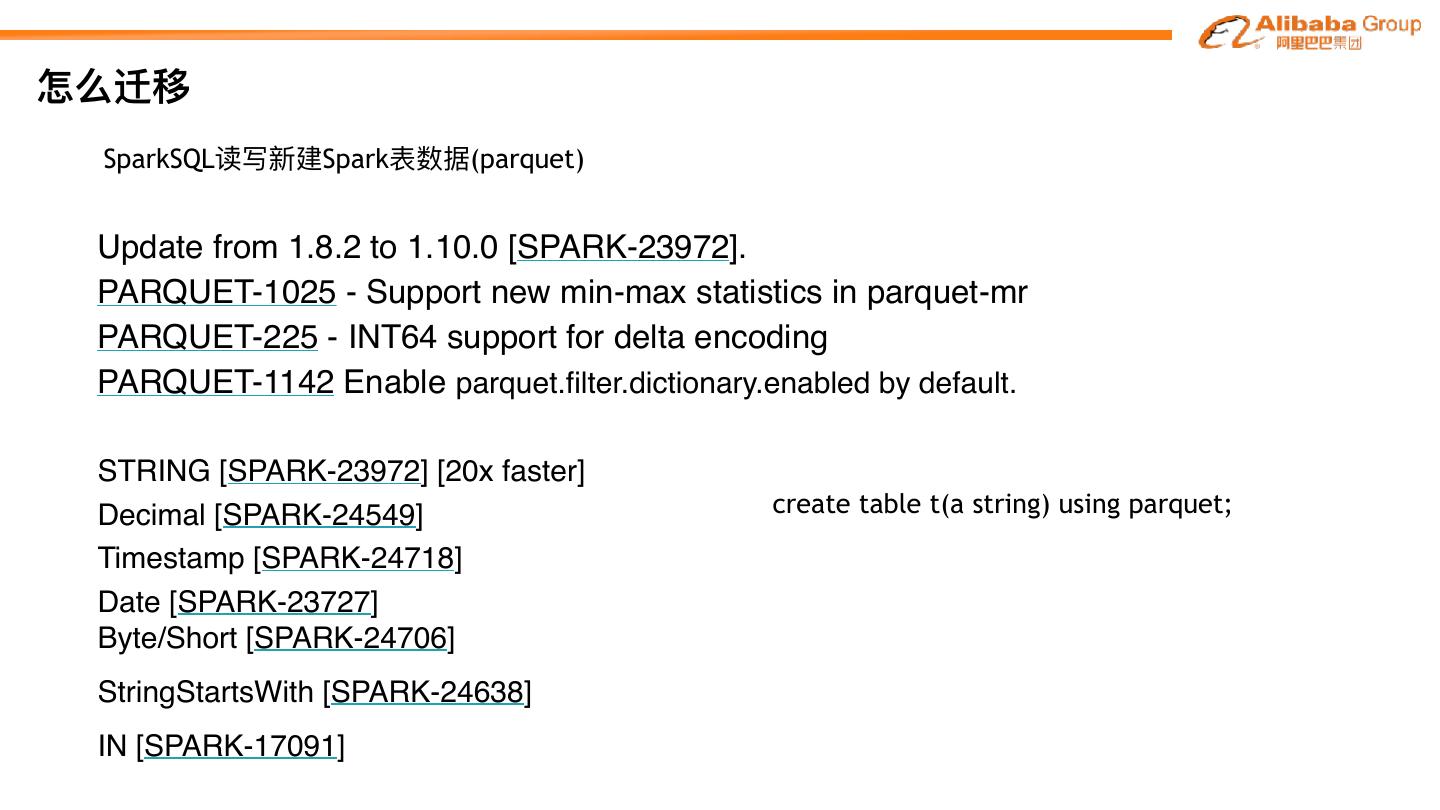
29 .怎么迁移 SparkSQL读写新建Spark表数据(parquet) Update from 1.8.2 to 1.10.0 [SPARK-23972]. PARQUET-1025 - Support new min-max statistics in parquet-mr PARQUET-225 - INT64 support for delta encoding PARQUET-1142 Enable parquet.filter.dictionary.enabled by default. • STRING [SPARK-23972] [20x faster] • Decimal [SPARK-24549] create table t(a string) using parquet; • Timestamp [SPARK-24718] • Date [SPARK-23727] • Byte/Short [SPARK-24706] • StringStartsWith [SPARK-24638] • IN [SPARK-17091]
10点赞
3收藏
3秒后跳转登录页面
去登陆

