




























- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 视频嵌入链接 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
第五讲-delta lake 初步使用
分享
点赞
3
收藏
2
第 5 讲 :Using Delta lake
介绍Delta Lake的用户场景,如何创建、追加和更新数据到数据湖,如何使用 Delta Lake 构建一个数据分析管道等内容。
主讲嘉宾 辛现银,阿里巴巴技术专家。
加入钉钉群了解更多技术信息

展开查看详情
1 .Delta Lake 使⽤初步 ⾟现银(⾟庸) · 阿⾥巴巴 / 技术专家
2 . 01 什么是 Delta Lake 02 CONTENT Delta Lake 基本功能 ⽬录 >> 03 使⽤ Delta Lake 构建分析管道 04 Delta Lake ⾼级功能
3 . 01 什么是 Delta Lake Apache Flink 中⽂学习⽹站: ververica.cn © Apache Flink Community China 严禁商业⽤途
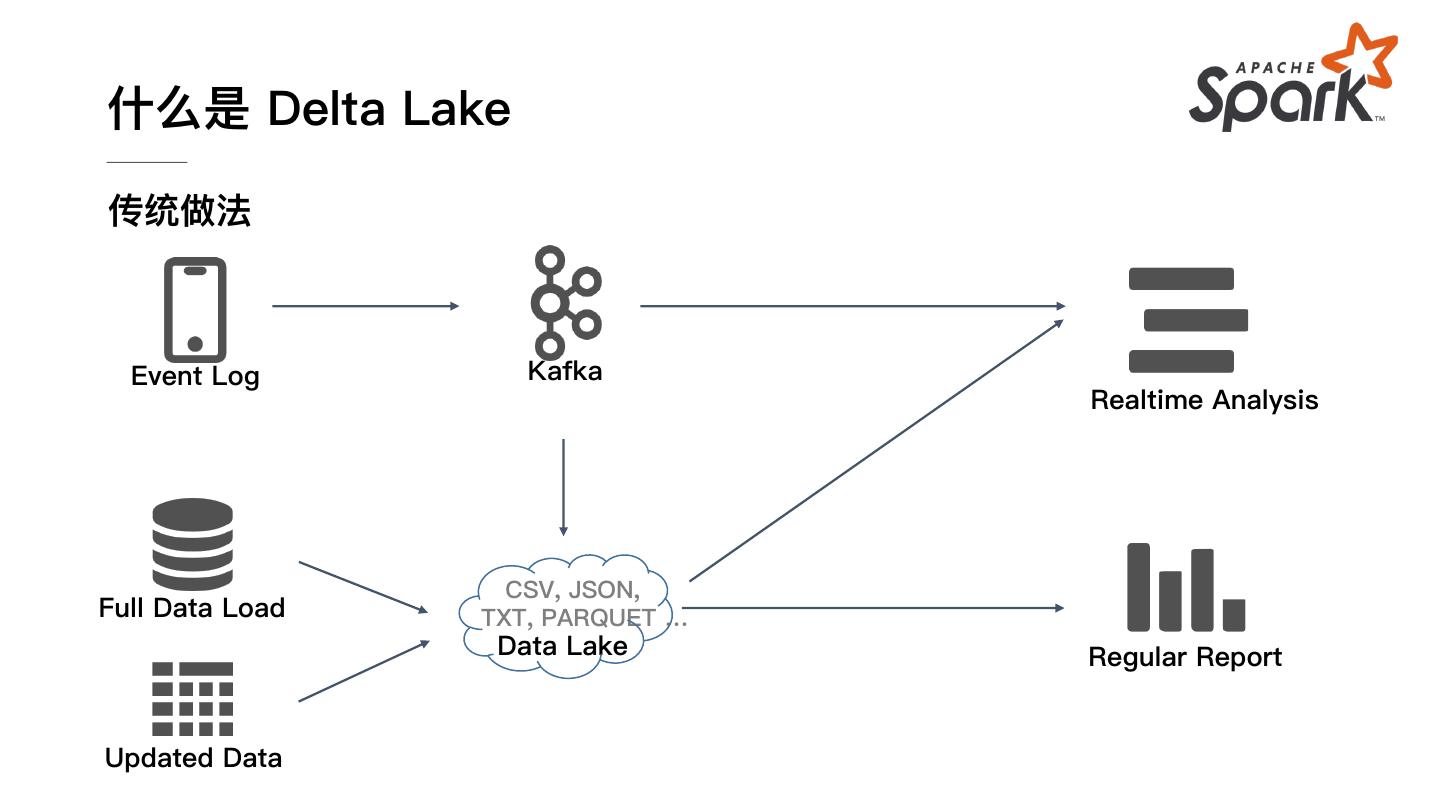
4 .什么是 Delta Lake 传统做法 Event Log Kafka Realtime Analysis CSV, JSON, Full Data Load TXT, PARQUET … Data Lake Regular Report Updated Data
5 .什么是 Delta Lake ⾯临的问题 数据⼀致性 数据演化 作业失败、多任务并发 Schema 变化 数据质量保证 流批割裂 脏数据的处理 Lambda 架构 vs 流批⼀体架构
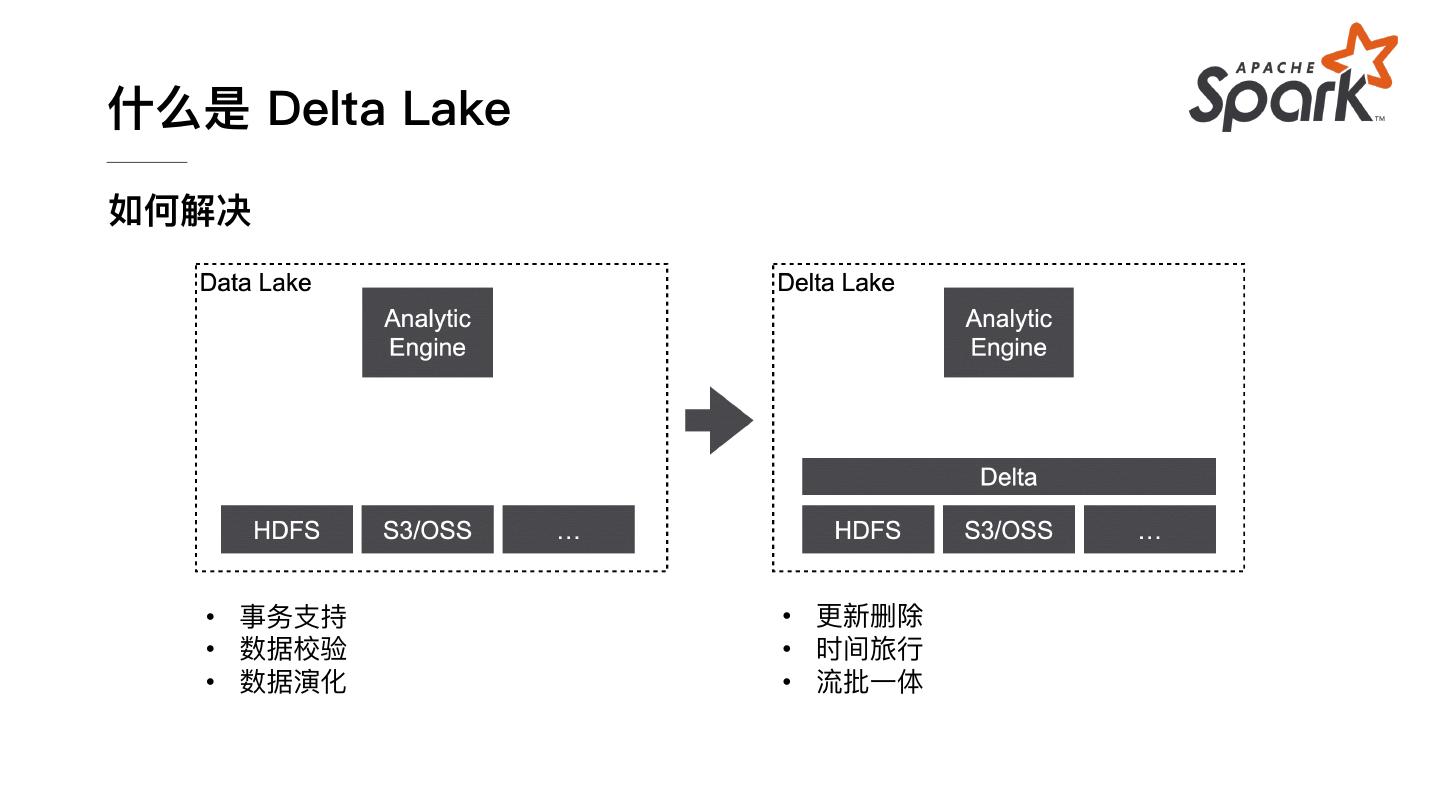
6 .什么是 Delta Lake 如何解决 • 事务⽀持 • 更新删除 • 数据校验 • 时间旅⾏ • 数据演化 • 流批⼀体
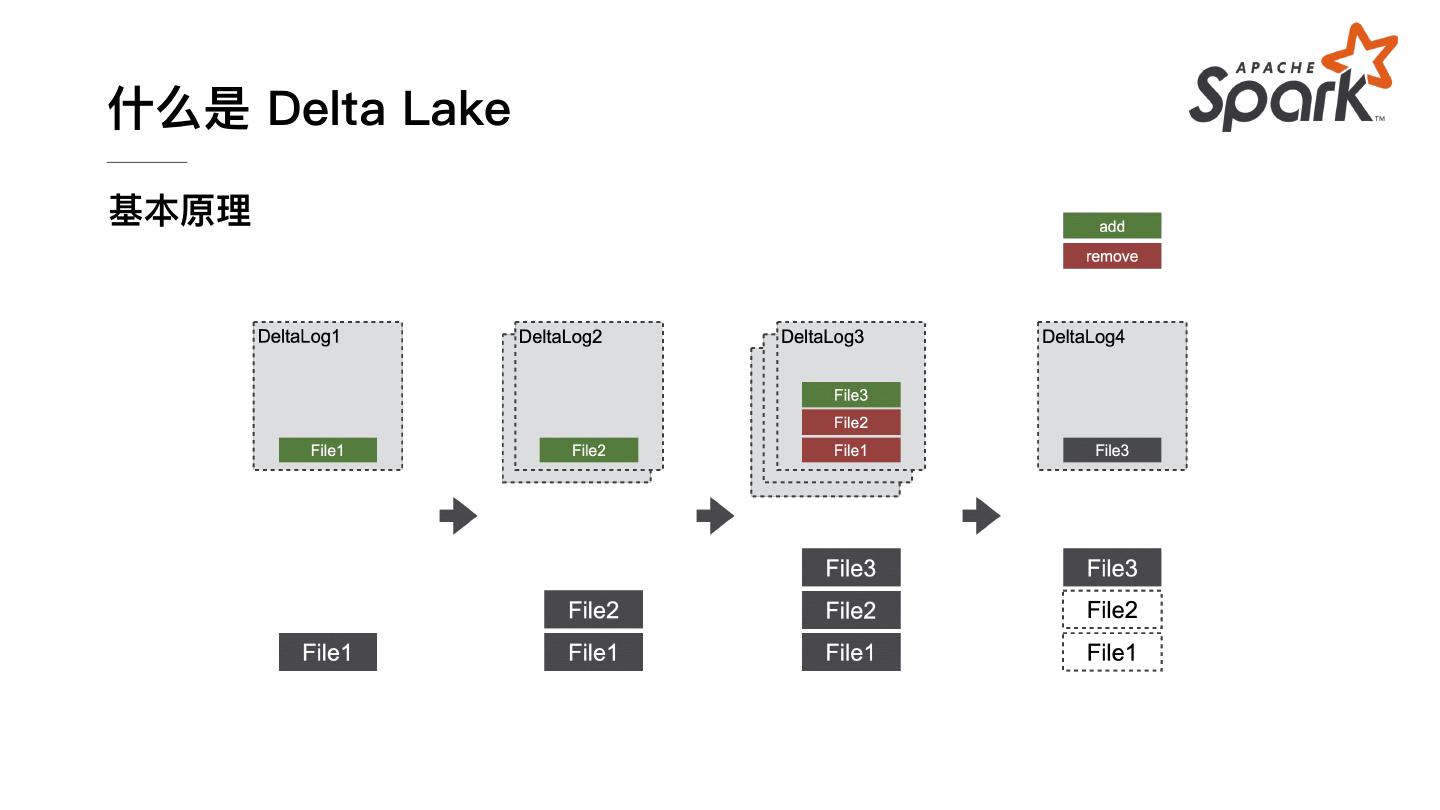
7 .什么是 Delta Lake 基本原理
8 .什么是 Delta Lake 基本原理 /path/to/delta/base /_checkpoint / /_delta_log /00000000000000000000.json /00000000000000000001.json /... /part=0 /part-<taskId>-<jobId>-c<bucketId>.snappy.parquet /... /part=1 /part-<taskId>-<jobId>-c<bucketId>.snappy.parquet /... ...
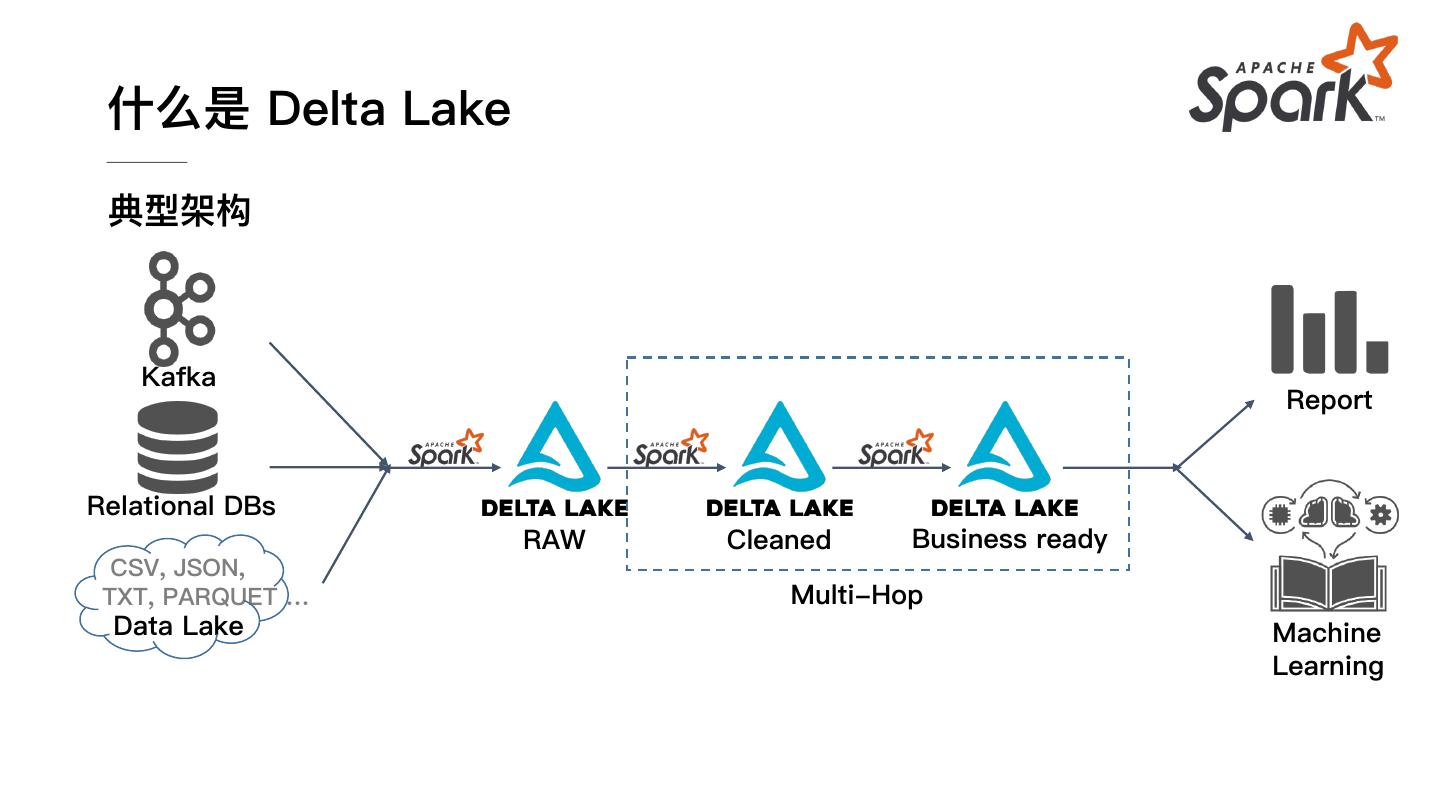
9 . 什么是 Delta Lake 典型架构 Kafka Report Relational DBs RAW Cleaned Business ready CSV, JSON, TXT, PARQUET … Multi-Hop Data Lake Machine Learning
10 . 02 Delta Lake 基本功能 Apache Flink 中⽂学习⽹站: ververica.cn © Apache Flink Community China 严禁商业⽤途
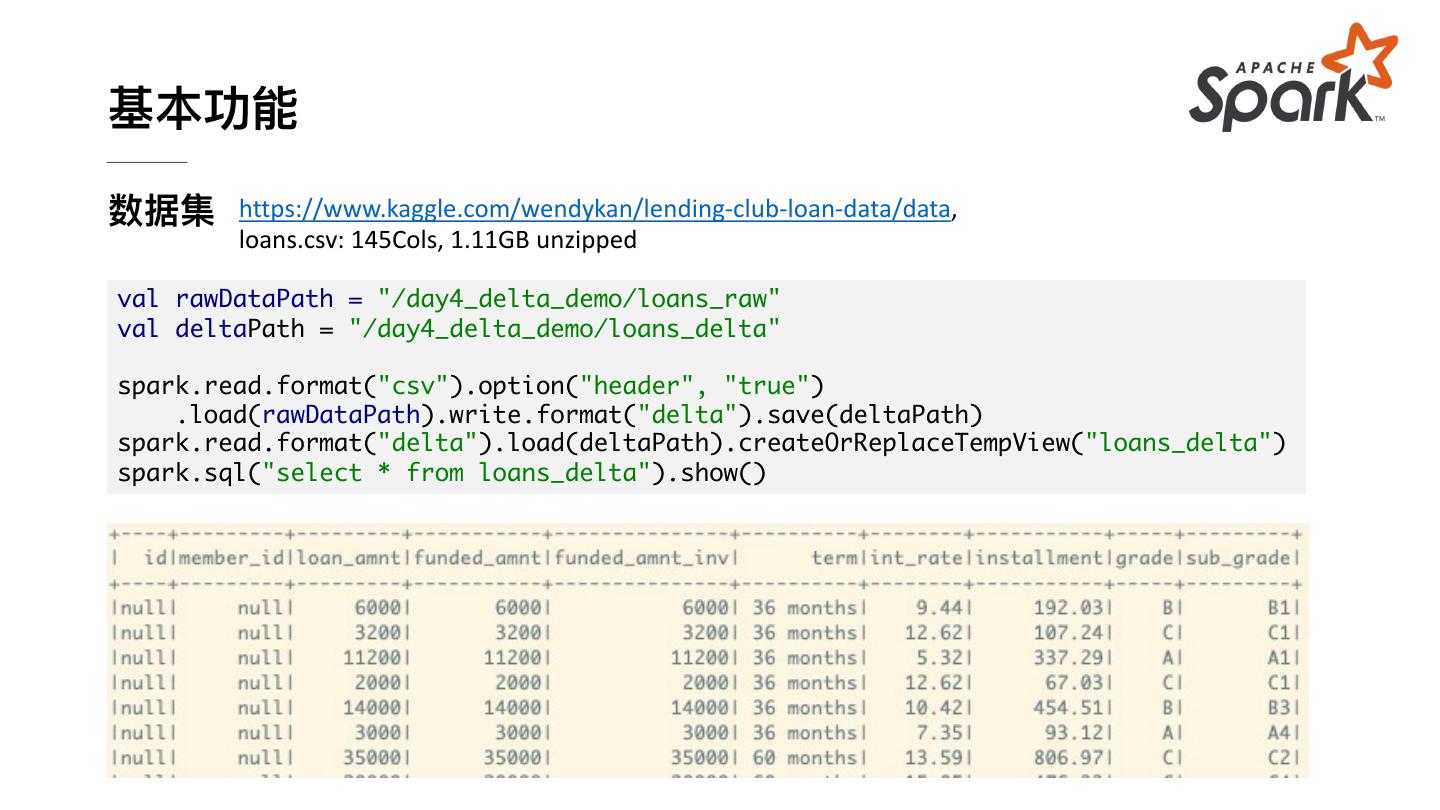
11 .基本功能 数据集 https://www.kaggle.com/wendykan/lending-club-loan-data/data, loans.csv: 145Cols, 1.11GB unzipped val rawDataPath = "/day4_delta_demo/loans_raw" val deltaPath = "/day4_delta_demo/loans_delta" spark.read.format("csv").option("header", "true") .load(rawDataPath).write.format("delta").save(deltaPath) spark.read.format("delta").load(deltaPath).createOrReplaceTempView("loans_delta") spark.sql("select * from loans_delta").show()
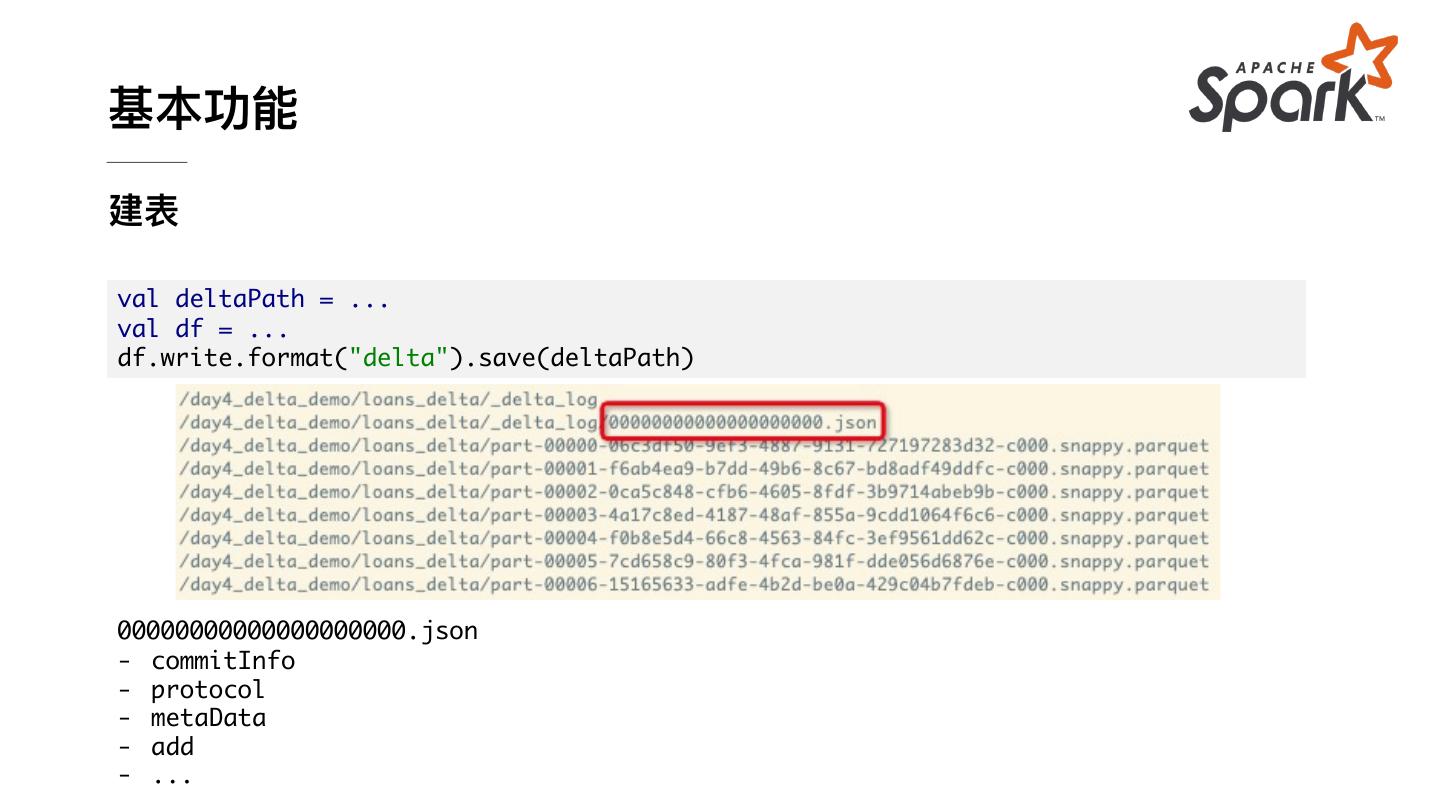
12 .基本功能 建表 val deltaPath = ... val df = ... df.write.format("delta").save(deltaPath) 00000000000000000000.json - commitInfo - protocol - metaData - add - ...
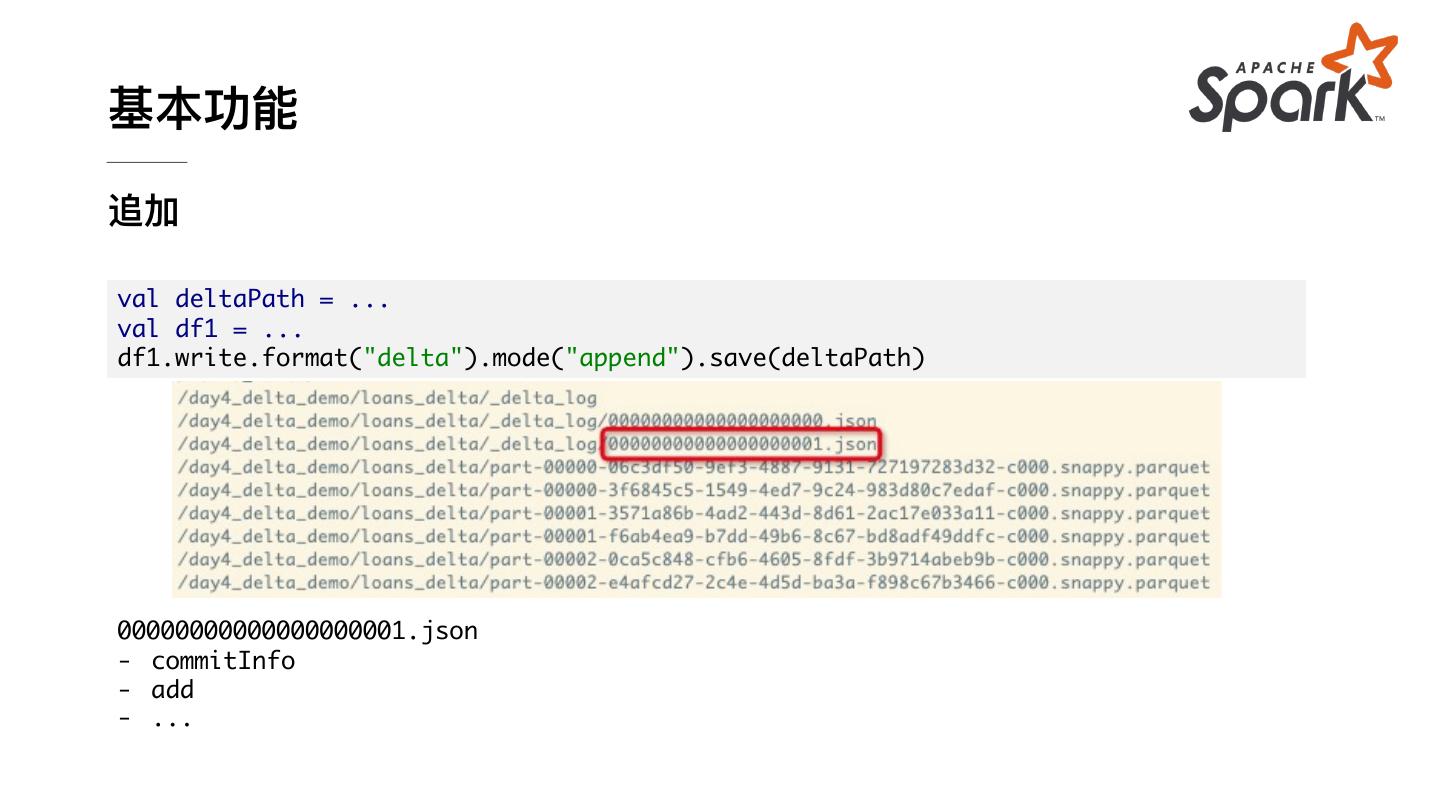
13 .基本功能 追加 val deltaPath = ... val df1 = ... df1.write.format("delta").mode("append").save(deltaPath) 00000000000000000001.json - commitInfo - add - ...
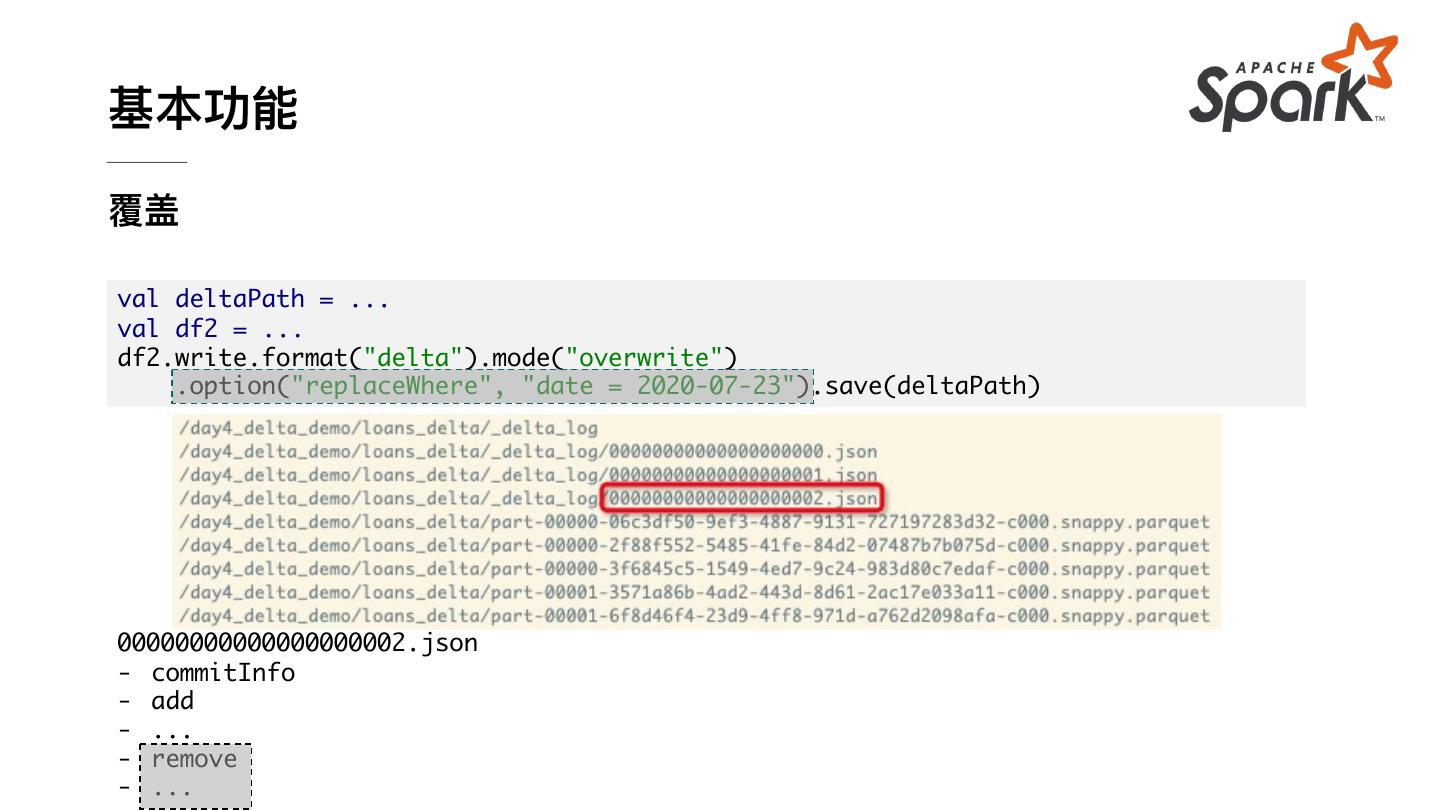
14 .基本功能 覆盖 val deltaPath = ... val df2 = ... df2.write.format("delta").mode("overwrite") .option("replaceWhere", "date = 2020-07-23").save(deltaPath) 00000000000000000002.json - commitInfo - add - ... - remove - ...
15 .基本功能 Delta Lake API:删除、更新、合并 val deltaPath = ... import io.delta.tables._ val deltaTable = DeltaTable.forPath(spark, deltaPath) deltaTable.delete("loan_status = 'Fully Paid'") deltaTable.updateExpr("member_id = '123456'", Map("home_ownership" -> "'OWN'")) import org.apache.spark.sql.functions._ import spark.implicits._ deltaTable.delete(col("loan_status") < "Fully Paid") deltaTable.update(col("member_id") === "123456", Map("home_ownership" -> lit("OWN")))
16 .基本功能 Delta Lake API:删除、更新、合并 val deltaPath = ... import io.delta.tables._ val deltaTable = DeltaTable.forPath(spark, deltaPath) val updatesDF = ... deltaTable.as("target") .merge(updatesDF.as("updates"), "member_id = updates.member_id") .whenMatched .updateExpr(Map("xxx" -> "updates.xxx", ...)) .whenNotMatched .insertExpr(Map("yyy" -> "updates.yyy", ...)) .execute()
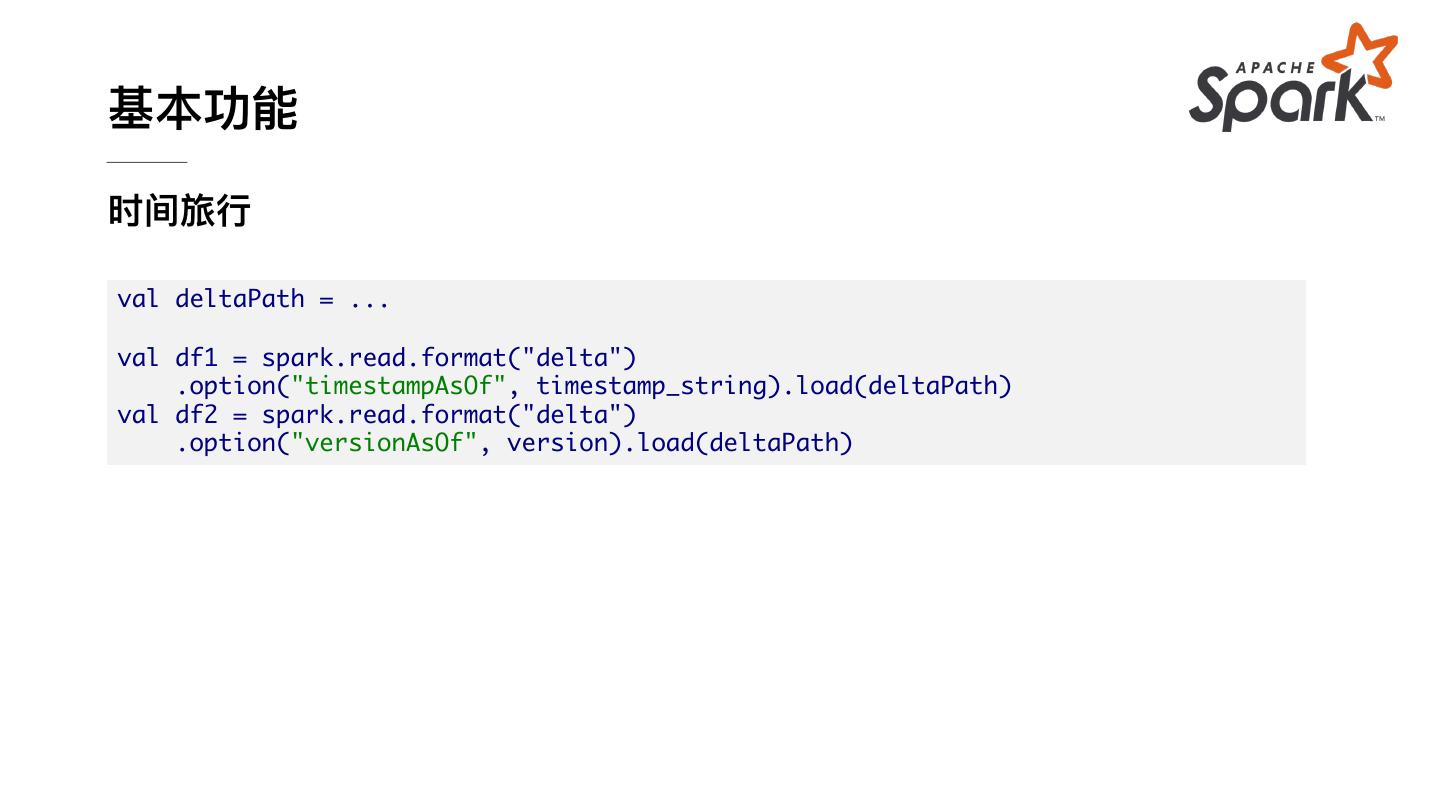
17 .基本功能 时间旅⾏ val deltaPath = ... val df1 = spark.read.format("delta") .option("timestampAsOf", timestamp_string).load(deltaPath) val df2 = spark.read.format("delta") .option("versionAsOf", version).load(deltaPath)
18 .使⽤ Delta Lake 构建分析管道 流读 val deltaPath = ... spark.readStream .format("delta") .option("xxx", "yyy") .load(deltaPath) options: - maxFilesPerTrigger - maxBytesPerTrigger - ignoreDeletes - ignoreChanges
19 .使⽤ Delta Lake 构建分析管道 流写 val deltaPath = ... val checkPointLocation = ... val df = ... df.writeStream .format("delta") .outputMode("xxx") .option("checkpointLocation", checkPointLocation) .start(deltaPath) outputMode: - append - complete
20 . 03 使⽤ Delta Lake 构建分析管道 Apache Flink 中⽂学习⽹站: ververica.cn © Apache Flink Community China 严禁商业⽤途
21 .使⽤ Delta Lake 构建分析管道 ⽬标 • 将 DB 中的表实时同步⾄数据湖(⼊湖) • 对数据湖中的数据计算实时结果并实时更新线上缓存(实时计算) DTS MySQL
22 .使⽤ Delta Lake 构建分析管道 ⼊湖 1. 利⽤ Debeziumn/Canal/DTS 等⼯具读取 MySQL binlog 并实时同步⾄ Kafka 2. 编写解析 binlog 格式的 UDF(格式与 binlog 同步⼯具有关) 3. 利⽤ Spark Streaming 结合编写的 UDF 读取 Kafka binlog 并实时同步⾄ Delta Lake
23 .使⽤ Delta Lake 构建分析管道 Binlog 格式(⼯具相关) 例:DTS binlog 格式: recordid // 记录 id source // 源数据库信息 dbtable // 源 db 和 表 recordtype // 记录类型,有 INIT/INSERT/DELETE/UPDATE 等 recordtimestamp // 记录时间戳 extratags // 标签 fields // 列信息 beforeimages // 原值,key 与 value 为 json 格式 afterimages // 更新后的值
24 .使⽤ Delta Lake 构建分析管道 Binlog 格式解析 UDF class DTSBinlogParserUDF extends GenericUDTF { override def initialize( argIOs: Array[ObjectInspector]): StructObjectInspector = { ... } override def process(args: Array[AnyRef]): Unit = { ... } override def close(): Unit = {} } spark.sql("CREATE FUNCTION dts_binlog_parser AS DTSBinlogParserUDF USING JAR <compiled_jar>")
25 .使⽤ Delta Lake 构建分析管道 ⼊湖任务 spark.readStream .format("kafka") .option("kafka.bootstrap.servers", "192.168.XX.XX:9092") .option("subscribe", "sales") .option("startingOffsets", "earliest") .option("maxOffsetsPerTrigger", 1000) .option("failOnDataLoss", value = false) .load() .createTempView("incremental") val dataStream = spark.sql( """ |SELECT dts_binlog_parser(value) |AS (recordID, source, dbTable, recordType, recordTimestamp, |extraTags, fields, beforeImages, afterImages) |FROM incremental """.stripMargin)
26 .使⽤ Delta Lake 构建分析管道 ⼊湖任务 val task = dataStream.writeStream .option("checkpointLocation", "/delta/sales_checkpoint") .foreachBatch( (ops, id) => { val mergeDf = ops.select(...) val mergeCond = "target.id = source.before_id" DeltaTable.forPath(spark, "/delta/sales").as("target") .merge(mergeDf.as("source"), mergeCond) .whenMatched("source.recordType='UPDATE'").updateExpr(...) .whenMatched("source.recordType='DELETE'").delete() .whenNotMatched("source.recordType='INSERT' OR source.recordType='UPDATE'").insertExpr().execute() } ).start() task.awaitTermination()
27 .使⽤ Delta Lake 构建分析管道 实时计算 val deltaPath = ... val query = df .writeStream val source = spark .outputMode("update") .readStream .foreachBatch { .format("delta") (batchDF: DataFrame, batchId: Long) => .option("ignoreChanges", batchDF.write "true") .format("org.apache.spark.sql.redis") .load(deltaPath) .option("table", "output") .createTempView("tbl") .mode(SaveMode.Append) .save() val df = // calculation } .start() query.awaitTermination()
28 . 04 Delta Lake ⾼级功能 Apache Flink 中⽂学习⽹站: ververica.cn © Apache Flink Community China 严禁商业⽤途
29 .Delta Lake ⾼级功能 Schema 校验 • Schema 校验是⾃动进⾏的,需满⾜如下条件,否则抛出异常 • 被写⼊ DataFrame 的列必须在表中存在 • 被写⼊的数据列类型必须与表对应列类型匹配 • 被写⼊的数据列名与表对应列必须相符(⼤⼩写不敏感) • ⽬前尚没有对于异常数据忽略处理的机制
3点赞
2收藏
3秒后跳转登录页面
去登陆

