Tablestore&Spark的云上流批一体大数据架构
分享
点赞
17
收藏
7
下载 15
-
快召唤伙伴们来围观吧
-
微博
QQ
QQ空间
贴吧
-
视频嵌入链接
文档嵌入链接
- 复制
-
-
微信扫一扫分享
-
已成功复制到剪贴板
议题:
Tablestore结合Spark的云上流批一体大数据架构
直播间直达(回看)链接:
https://developer.aliyun.com/live/1716
简介:
传统Lambda架构组件多运维复杂,如何使用一套存储和一套计算来实现流批架构充分享受技术红利?以Delta Lake为代表的新型数据湖方案越来越流行,传统的Lambda架构如何向数据湖架构进行扩展?以及结构化数据结合Delta Lake的最佳解决方案是什么。本次分享将会结合理论讲解和实际场景为您一一解答。
讲师:
王卓然 花名琸然 阿里云存储服务技术专家
时间:
2019年11月28日 19:00-20:00
阿里巴巴开源大数据EMR技术团队成立Apache Spark中国技术社区,定期打造国内Spark线上线下交流活动。请持续关注。
钉钉群号:21784001
团队群号:HPRX8117
微信公众号:Apache Spark技术交流社区
展开查看详情
1 .Tablestore结合Spark的云上流批一体大数据架构
阿里云存储服务技术专家 琸然
�
2 . 01 大数据处理的挑战
Contents
02 大数据处理架构
目录
03 云上Lambda plus架构
04 海量结构化数据 Delta Lake 架构
�
4 .大数据简介
• 4V+1C
Volume, Velocity, Variety, Value, Complexity
• Storage
分布式存储,高性能,高可用, 低成本
• Processing
分布式调度、弹性扩展、多计算模式融合
• Etc...
涉及的子领域广泛:存储、计算、调
度、元数据服务、安全、运维(智能
化)、应用开发 等等。
�
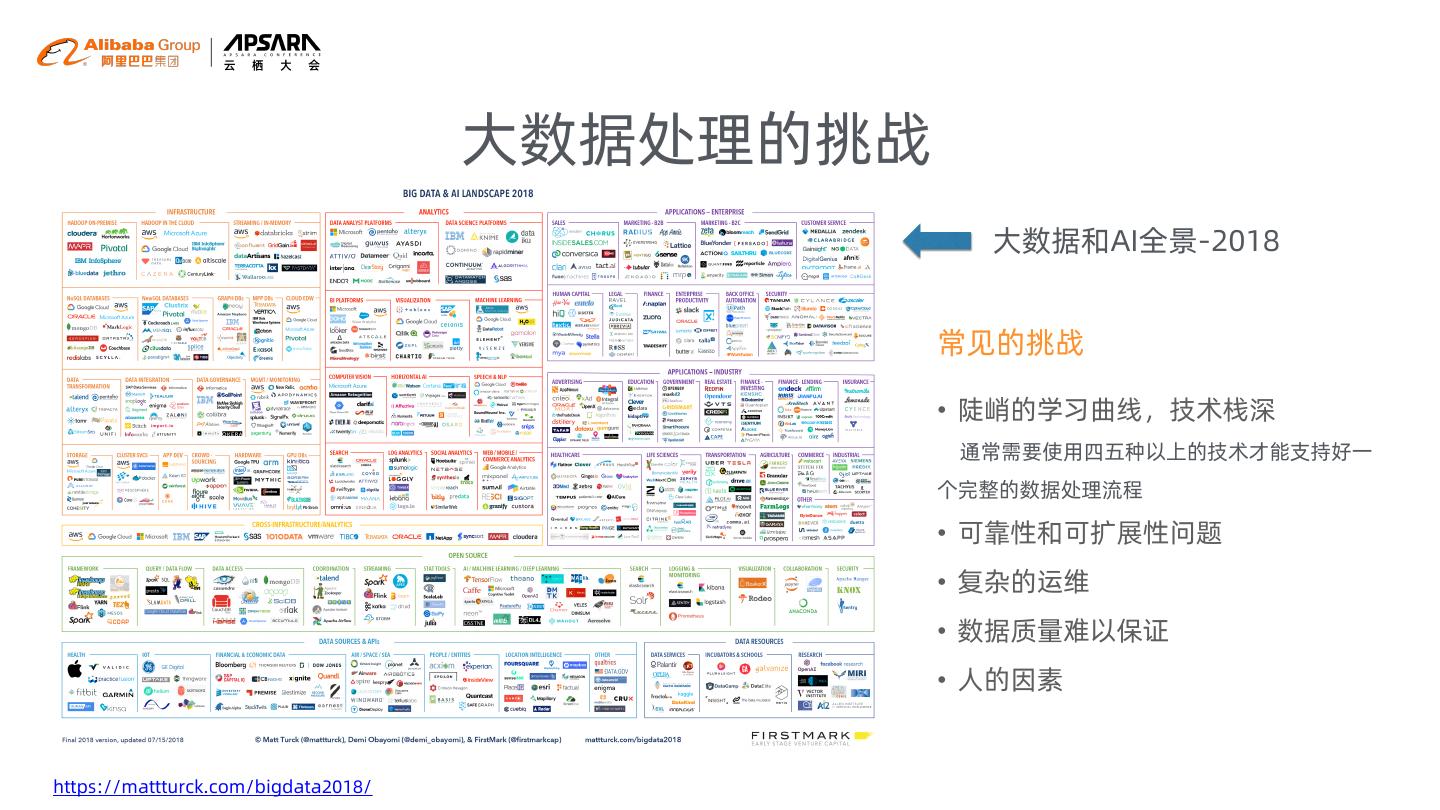
5 . 大数据处理的挑战
大数据和AI全景-2018
常见的挑战
• 陡峭的学习曲线,技术栈深
通常需要使用四五种以上的技术才能支持好一
个完整的数据处理流程
• 可靠性和可扩展性问题
• 复杂的运维
• 数据质量难以保证
• 人的因素
https://mattturck.com/bigdata2018/
�
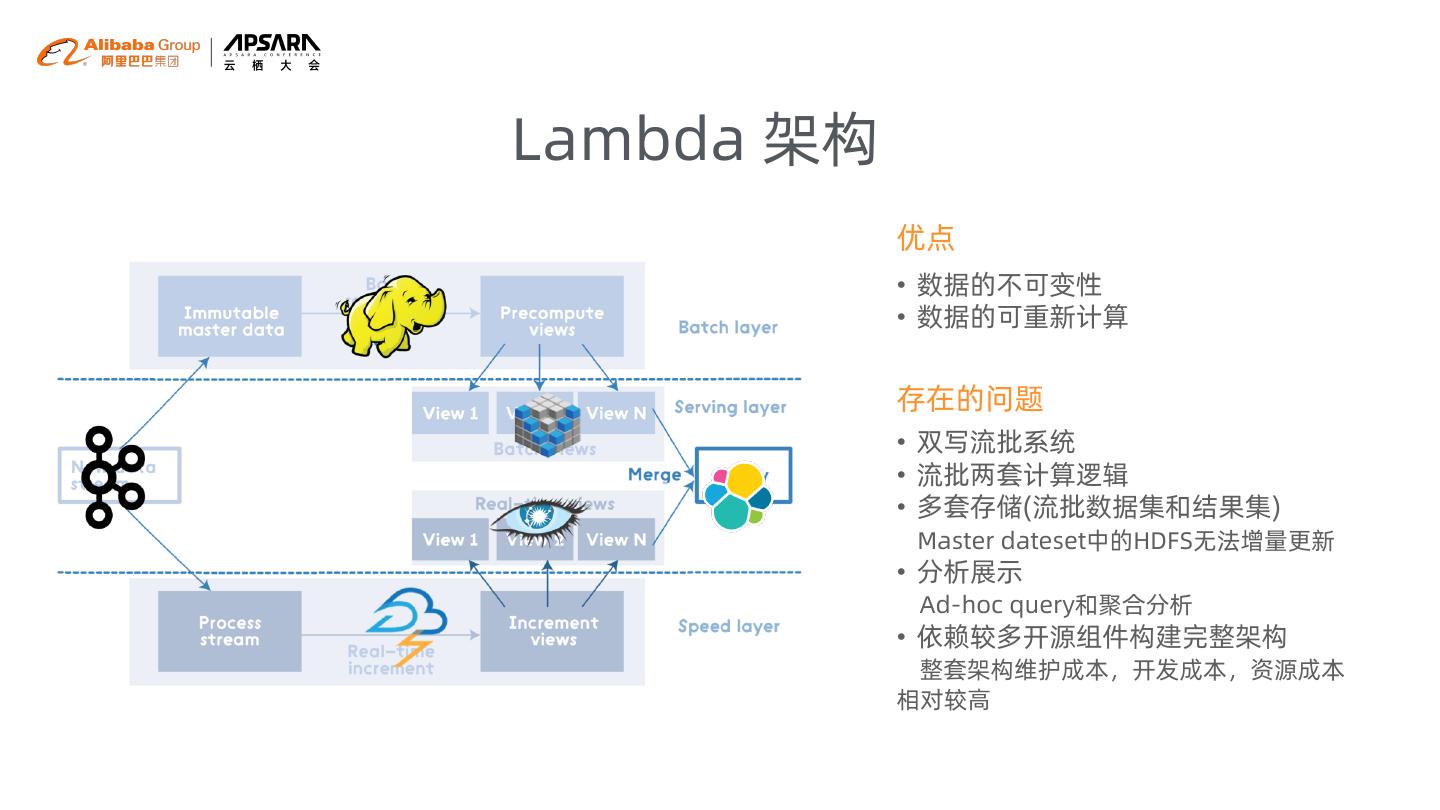
7 .Lambda 架构
优点
• 数据的不可变性
• 数据的可重新计算
存在的问题
• 双写流批系统
• 流批两套计算逻辑
• 多套存储(流批数据集和结果集)
Master dateset中的HDFS无法增量更新
• 分析展示
Ad-hoc query和聚合分析
• 依赖较多开源组件构建完整架构
整套架构维护成本,开发成本,资源成本
相对较高
�
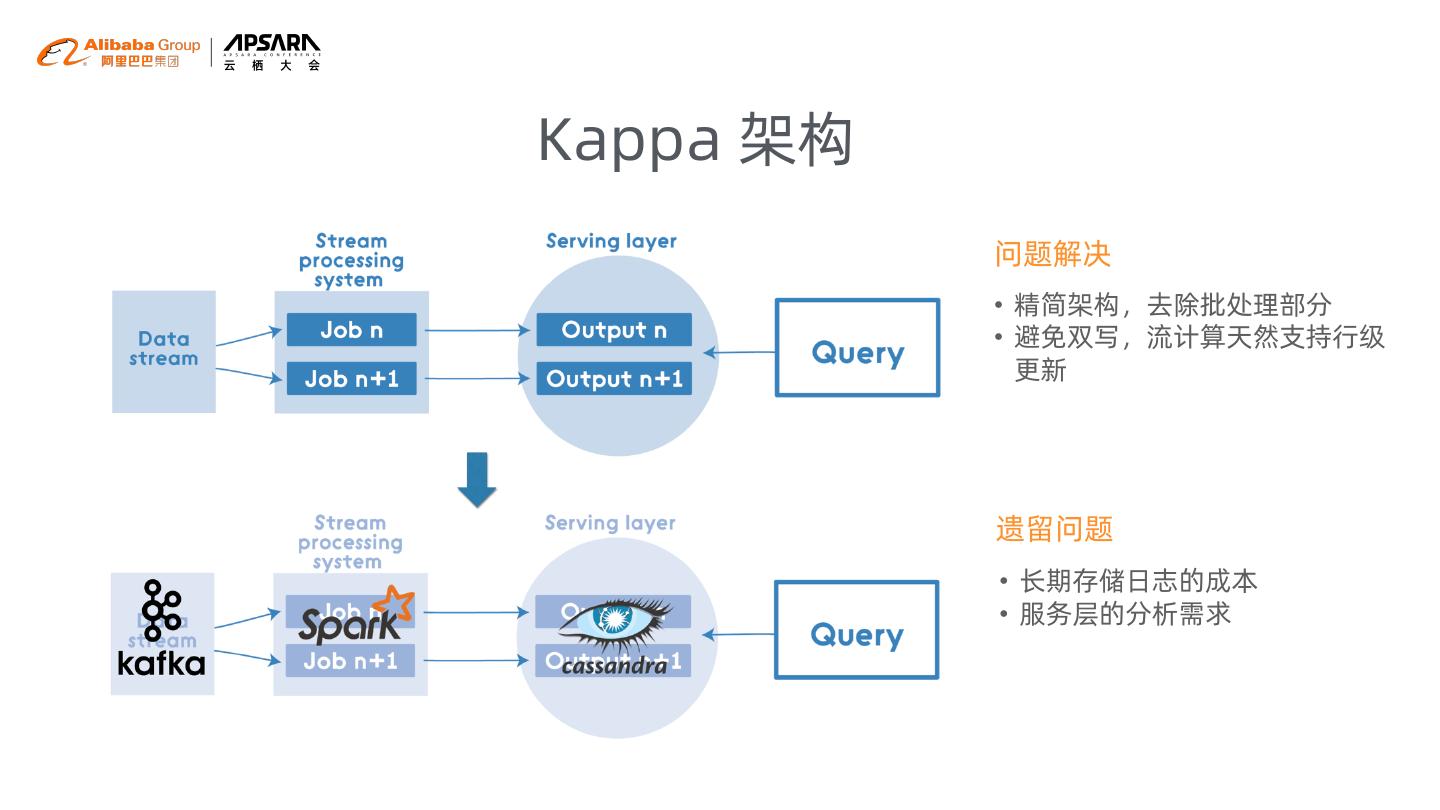
8 .Kappa 架构
问题解决
• 精简架构,去除批处理部分
• 避免双写,流计算天然支持行级
更新
遗留问题
• 长期存储日志的成本
• 服务层的分析需求
�
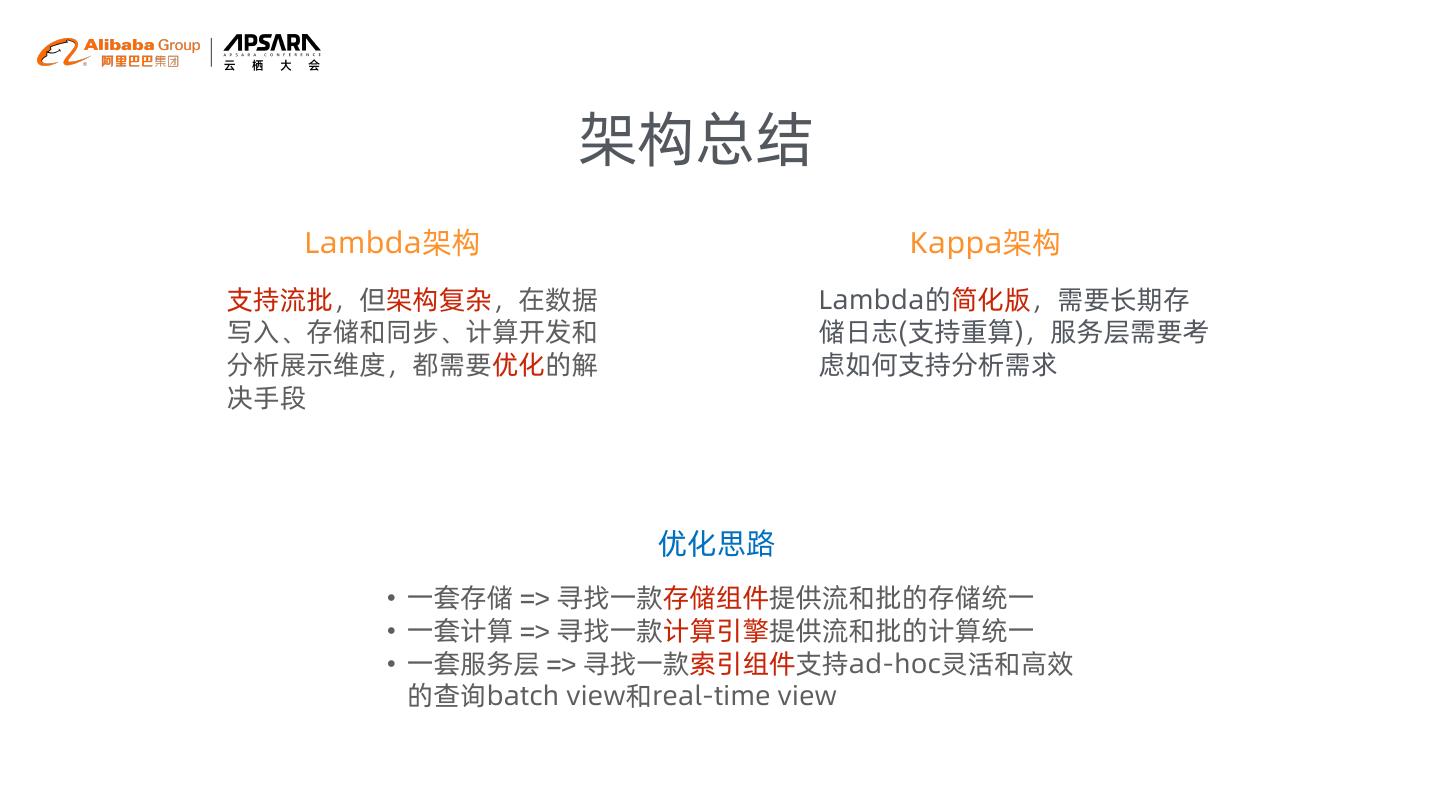
9 . 架构总结
Lambda架构 Kappa架构
支持流批,但架构复杂,在数据 Lambda的简化版,需要长期存
写入、存储和同步、计算开发和 储日志(支持重算),服务层需要考
分析展示维度,都需要优化的解 虑如何支持分析需求
决手段
优化思路
• 一套存储 => 寻找一款存储组件提供流和批的存储统一
• 一套计算 => 寻找一款计算引擎提供流和批的计算统一
• 一套服务层 => 寻找一款索引组件支持ad-hoc灵活和高效
的查询batch view和real-time view
�
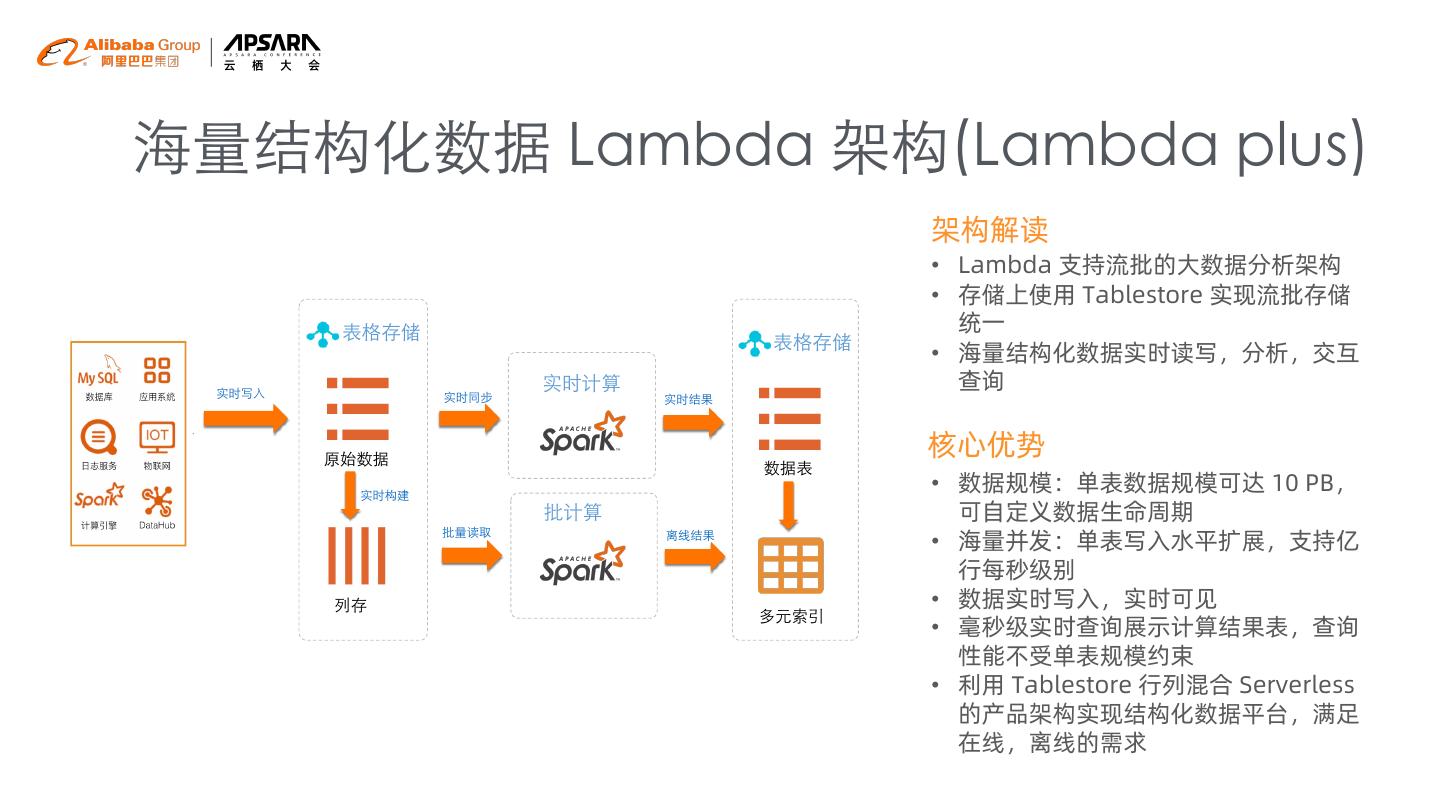
11 .海量结构化数据 Lambda 架构(Lambda plus)
架构解读
• Lambda 支持流批的大数据分析架构
• 存储上使用 Tablestore 实现流批存储
统一
• 海量结构化数据实时读写,分析,交互
查询
核心优势
• 数据规模:单表数据规模可达 10 PB,
可自定义数据生命周期
• 海量并发:单表写入水平扩展,支持亿
行每秒级别
• 数据实时写入,实时可见
• 毫秒级实时查询展示计算结果表,查询
性能不受单表规模约束
• 利用 Tablestore 行列混合 Serverless
的产品架构实现结构化数据平台,满足
在线,离线的需求
�
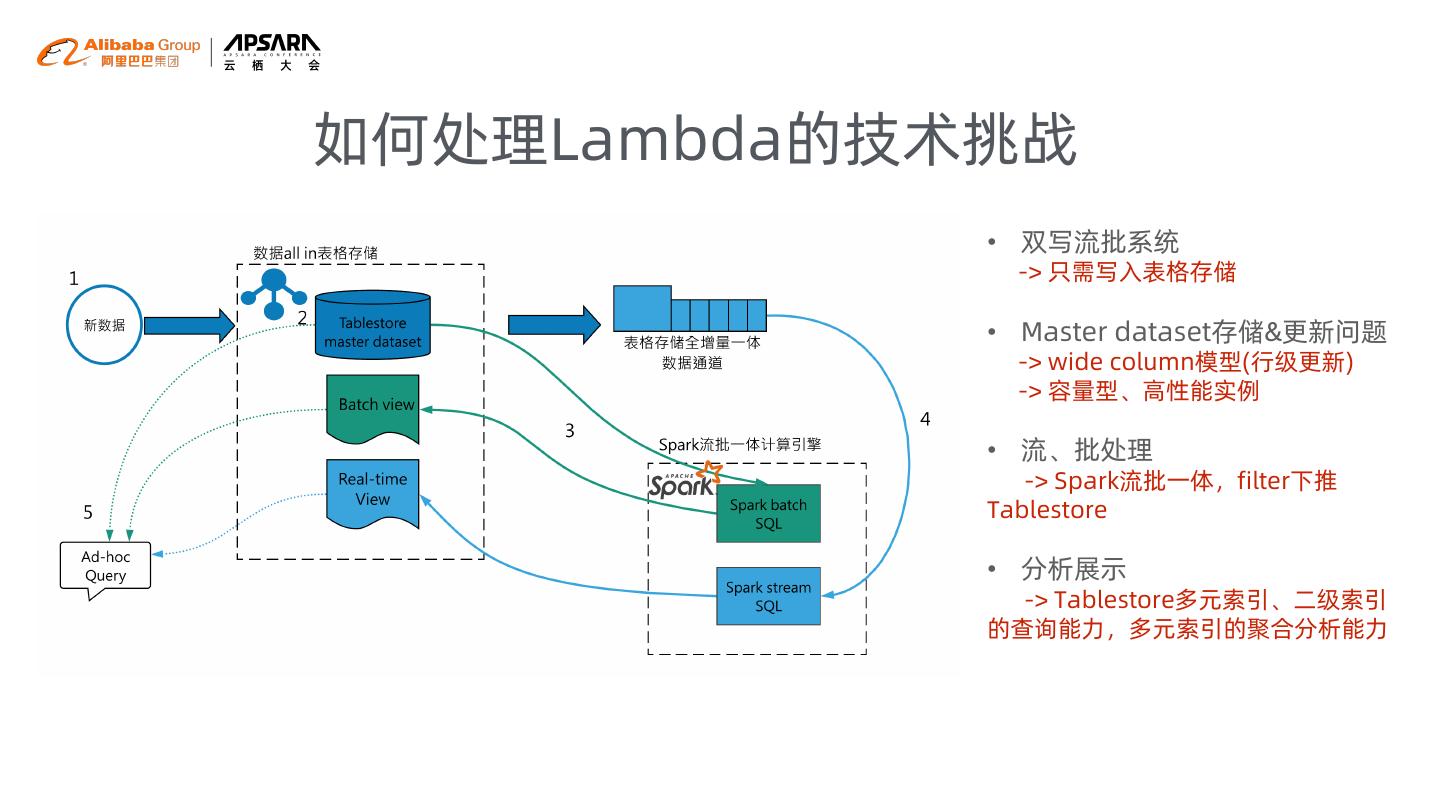
12 .如何处理Lambda的技术挑战
• 双写流批系统
-> 只需写入表格存储
• Master dataset存储&更新问题
-> wide column模型(行级更新)
-> 容量型、高性能实例
• 流、批处理
-> Spark流批一体,filter下推
Tablestore
• 分析展示
-> Tablestore多元索引、二级索引
的查询能力,多元索引的聚合分析能力
�
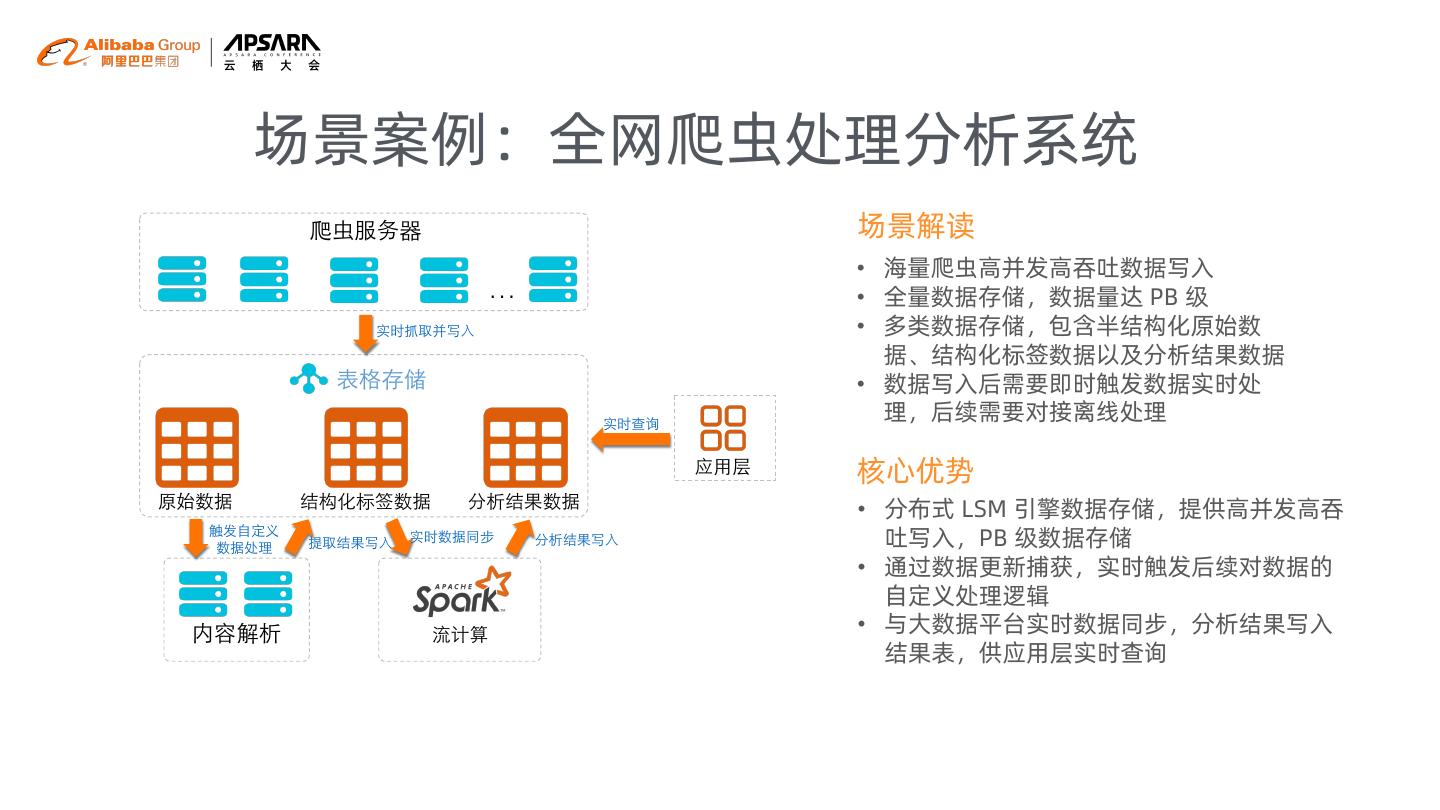
13 .场景案例:全网爬虫处理分析系统
场景解读
• 海量爬虫高并发高吞吐数据写入
… • 全量数据存储,数据量达 PB 级
• 多类数据存储,包含半结构化原始数
据、结构化标签数据以及分析结果数据
• 数据写入后需要即时触发数据实时处
理,后续需要对接离线处理
核心优势
• 分布式 LSM 引擎数据存储,提供高并发高吞
吐写入,PB 级数据存储
• 通过数据更新捕获,实时触发后续对数据的
自定义处理逻辑
• 与大数据平台实时数据同步,分析结果写入
结果表,供应用层实时查询
�
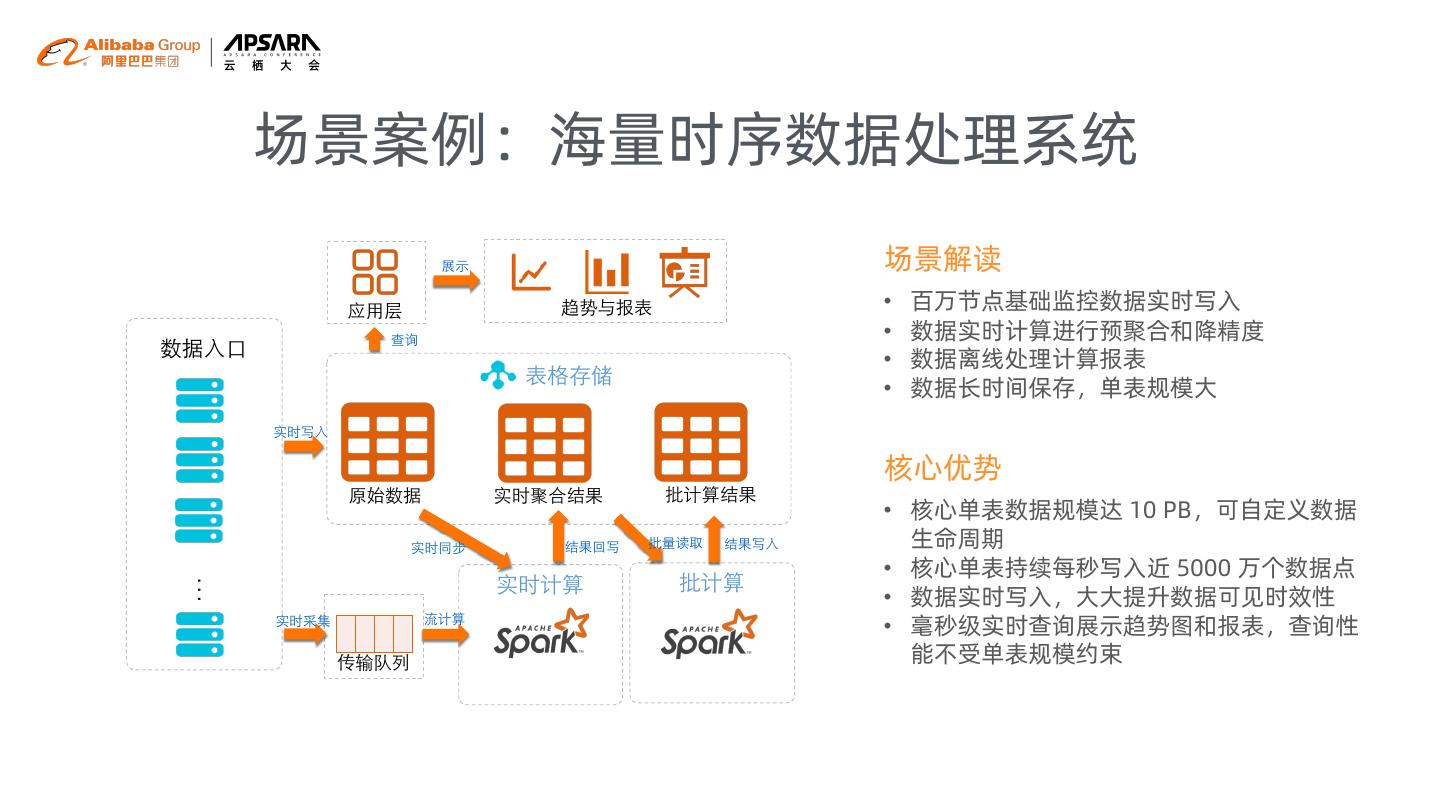
14 . 场景案例:海量时序数据处理系统
场景解读
• 百万节点基础监控数据实时写入
• 数据实时计算进行预聚合和降精度
• 数据离线处理计算报表
• 数据长时间保存,单表规模大
核心优势
• 核心单表数据规模达 10 PB,可自定义数据
生命周期
• 核心单表持续每秒写入近 5000 万个数据点
…
• 数据实时写入,大大提升数据可见时效性
• 毫秒级实时查询展示趋势图和报表,查询性
能不受单表规模约束
�
15 .海量结构化数据 Delta Lake 架构
04
�
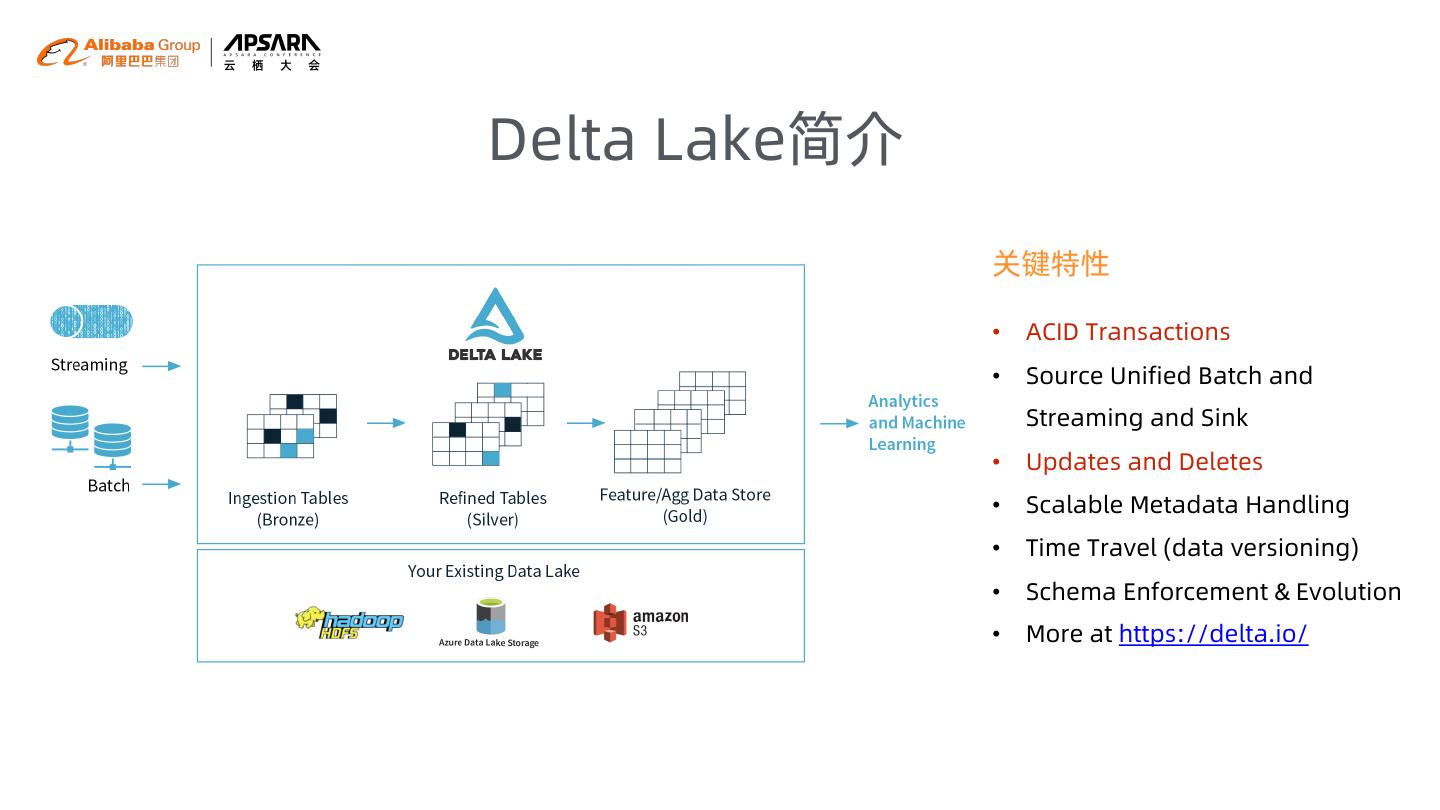
16 .Delta Lake简介
关键特性
• ACID Transactions
• Source Unified Batch and
Streaming and Sink
• Updates and Deletes
• Scalable Metadata Handling
• Time Travel (data versioning)
• Schema Enforcement & Evolution
• More at https://delta.io/
�
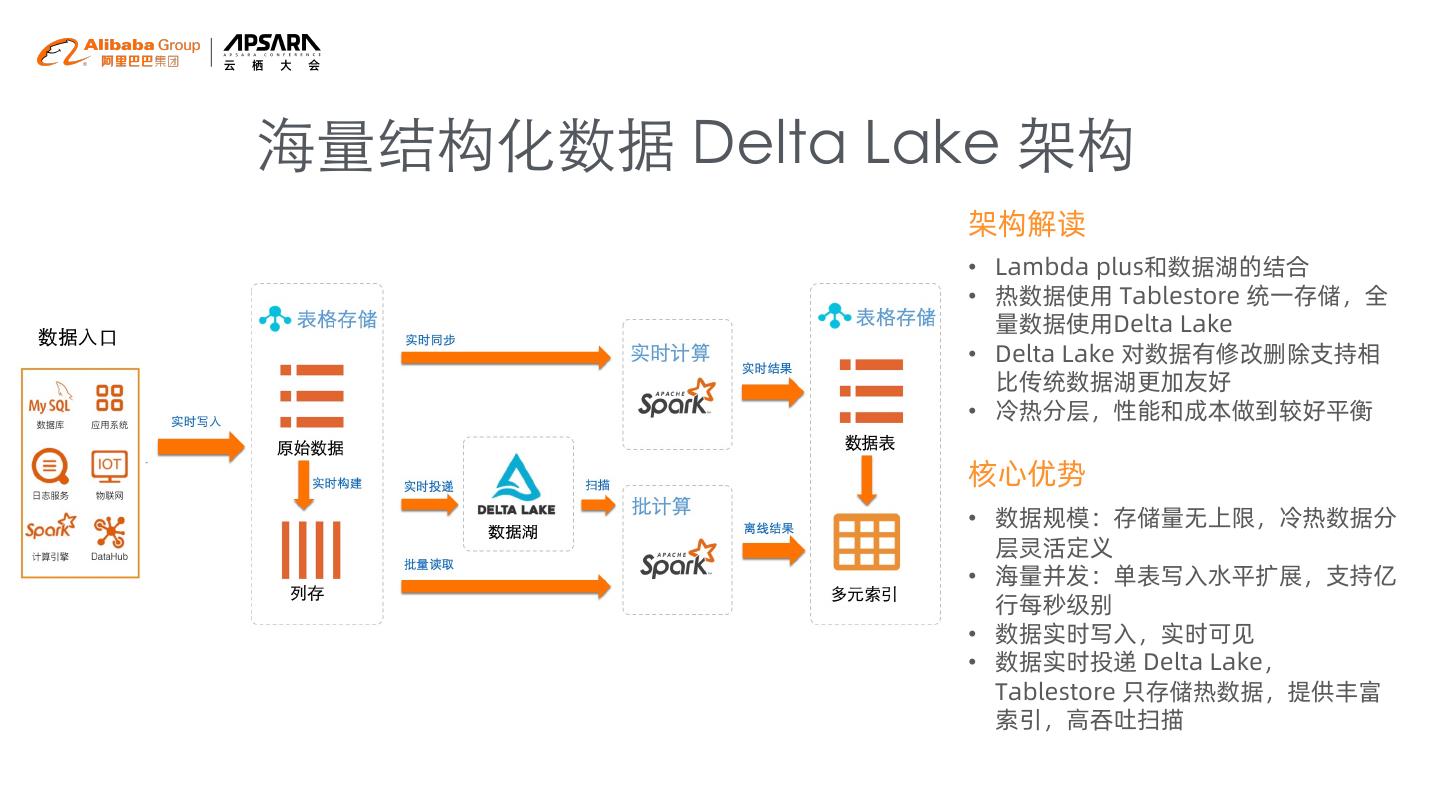
17 .海量结构化数据 Delta Lake 架构
架构解读
• Lambda plus和数据湖的结合
• 热数据使用 Tablestore 统一存储,全
量数据使用Delta Lake
• Delta Lake 对数据有修改删除支持相
比传统数据湖更加友好
• 冷热分层,性能和成本做到较好平衡
核心优势
• 数据规模:存储量无上限,冷热数据分
层灵活定义
• 海量并发:单表写入水平扩展,支持亿
行每秒级别
• 数据实时写入,实时可见
• 数据实时投递 Delta Lake,
Tablestore 只存储热数据,提供丰富
索引,高吞吐扫描
�
18 . Delta Lake 对接细节
前置条件
• Source: Tablestore已实现批流
Connector的全面对接
• Sink: Delta原生支持
实际处理
• 一段简单的UDF:解析Tablestore CDC log,
供Delta Sink逻辑使用
• DataStreamWriter.foreachBatch + Delta
Lake Merge:对于每个微批的数据可以灵活
的组合操作(Update, Delete, Insert)
• 批流处理逻辑统一
�
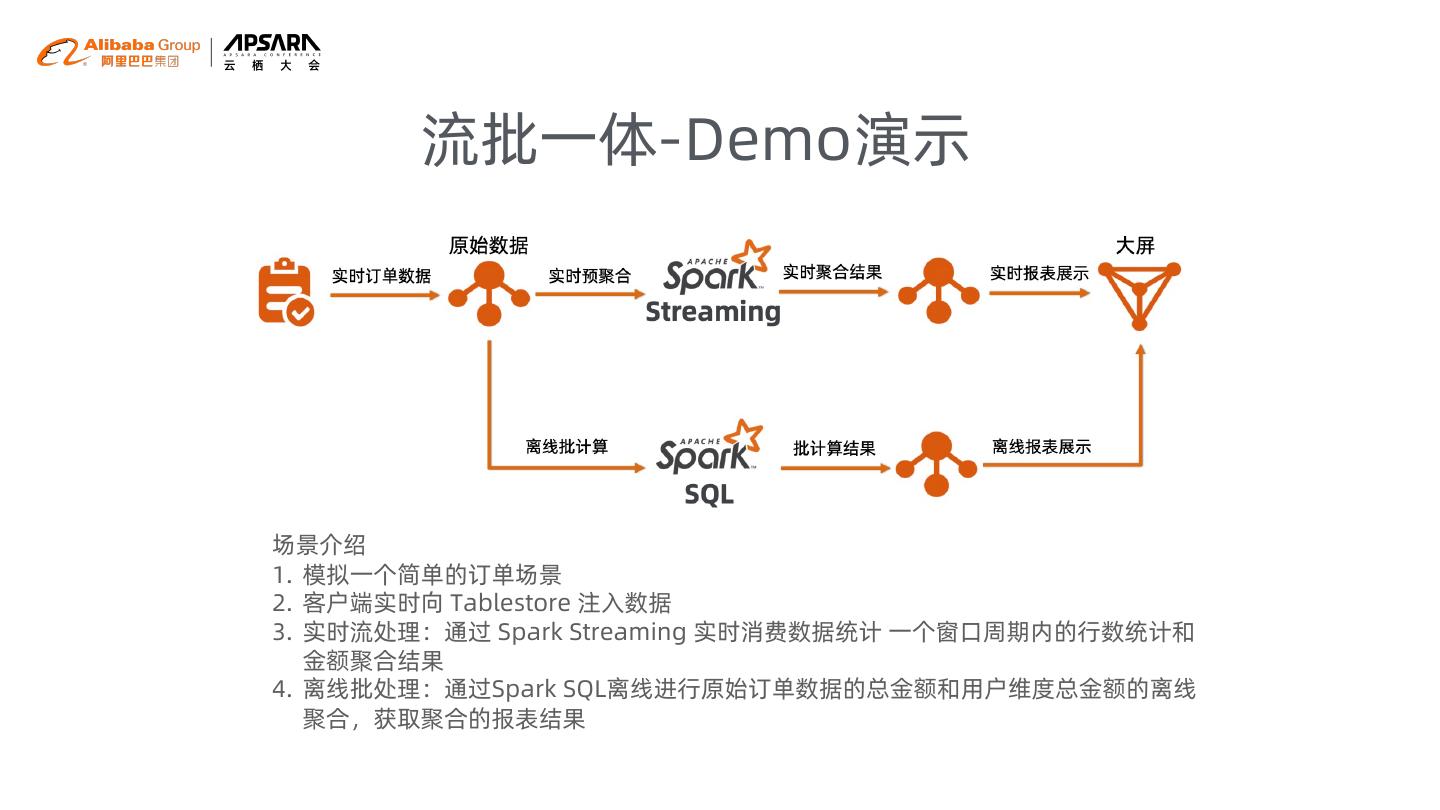
19 . 流批一体-Demo演示
场景介绍
1. 模拟一个简单的订单场景
2. 客户端实时向 Tablestore 注入数据
3. 实时流处理:通过 Spark Streaming 实时消费数据统计 一个窗口周期内的行数统计和
金额聚合结果
4. 离线批处理:通过Spark SQL离线进行原始订单数据的总金额和用户维度总金额的离线
聚合,获取聚合的报表结果
�
20 .表格存储 Tablestore 结构化数据统一存储平台
表格存储技术交流群 Apache Spark 中国社区交流群
�