展开查看详情
1 .Structured Streaming进阶与实践
阿⾥里里巴巴计算平台事业部EMR
云魄
�
2 . 内容概要
• Structured Streaming简介
• ⼯工作原理理
• Spark 2.4新特性
• Stateful操作
• 使⽤用场景
�
3 . Part 1
Structured Streaming简介
�
4 .流式处理理的难点
• 数据复杂性
• 多种数据源
• 多种数据格式,json、avro等
• 数据清洗
• 设计与使⽤用
• Low-level APIs,Map、Reduce等
• 与ML、批处理理结合
• failover
�
5 .Structured Streaming特点
• 丰富的数据源⽀支持
• 多种数据源
• 内建avro⽀支持,schema信息
• 数据去重,event time
• 设计与使⽤用
• high level APIs, DataFrame
• 交互式查询、在线ML
• exactly once语义
�
6 . Part 2
Structured Streaming⼯工作原理理
�
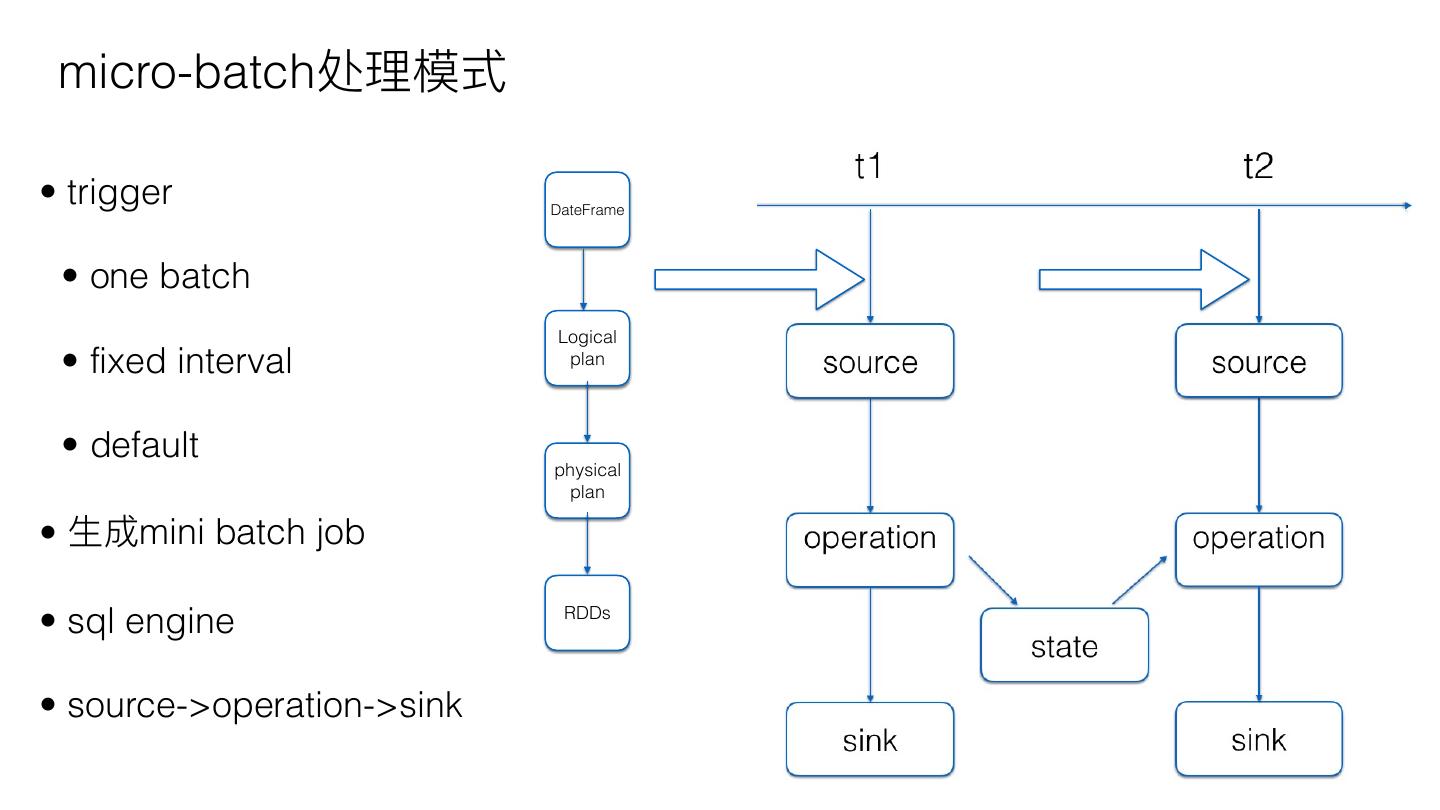
7 . micro-batch处理理模式
• trigger DateFrame
• one batch
Logical
• fixed interval plan
• default
physical
plan
• ⽣生成mini batch job
• sql engine RDDs
• source->operation->sink
�
8 .continuous处理理模式
• Continuous trigger DateFrame
source source
• DataFrame->RDDs
Logical
• 各partition log running task plan
operation operation
• source->operation->sink physical
plan
RDD sink sink
�
9 .exactly once — source
• Source get offset
• WAL before execution
operation
source
• Sink commit input sink output
• 出错、重启后重新执⾏行行
available commit
offset log
StreamExecution
�
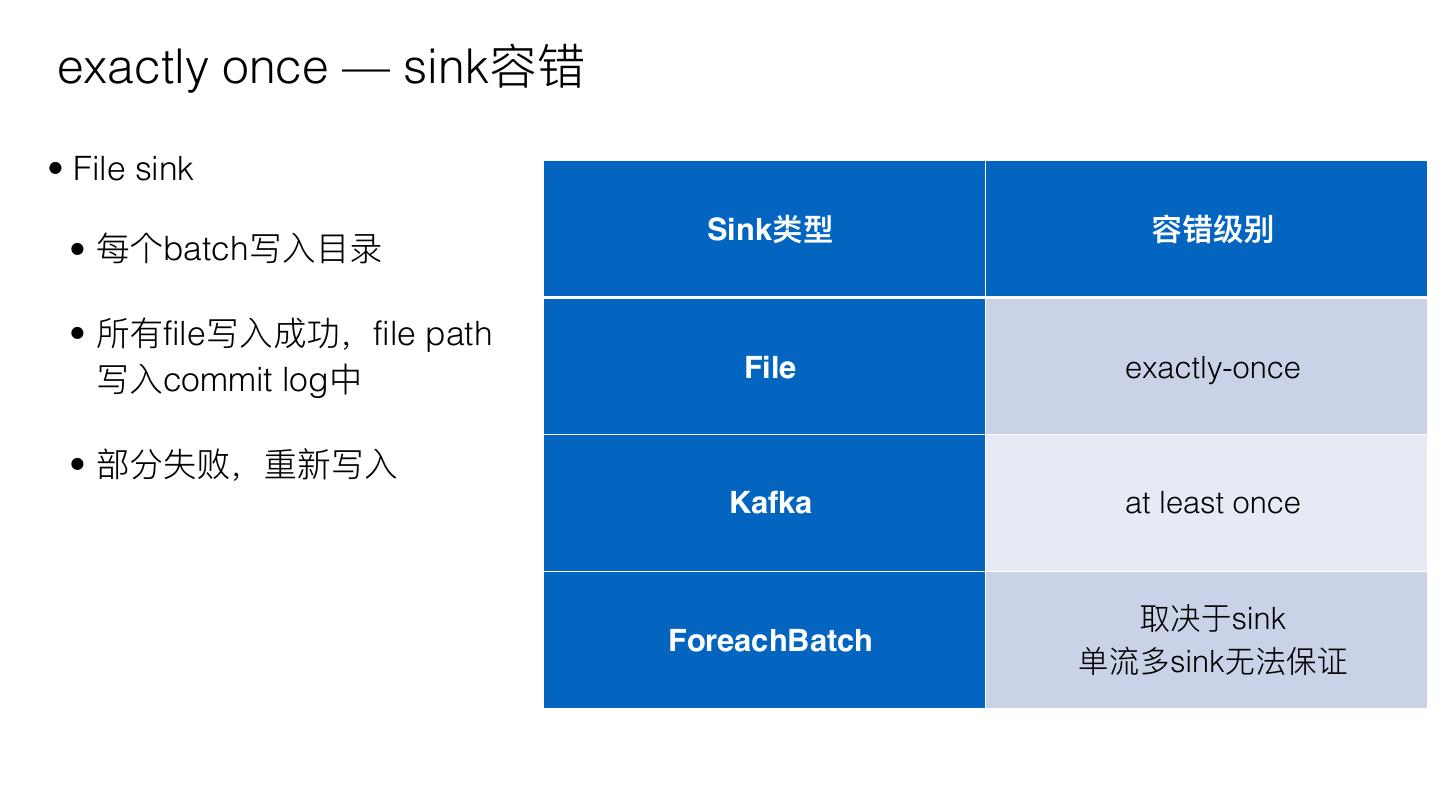
10 .exactly once — sink容错
• File sink
Sink类型 容错级别
• 每个batch写⼊入⽬目录
• 所有file写⼊入成功,file path
写⼊入commit log中 File exactly-once
• 部分失败,重新写⼊入
Kafka at least once
取决于sink
ForeachBatch
单流多sink⽆无法保证
�
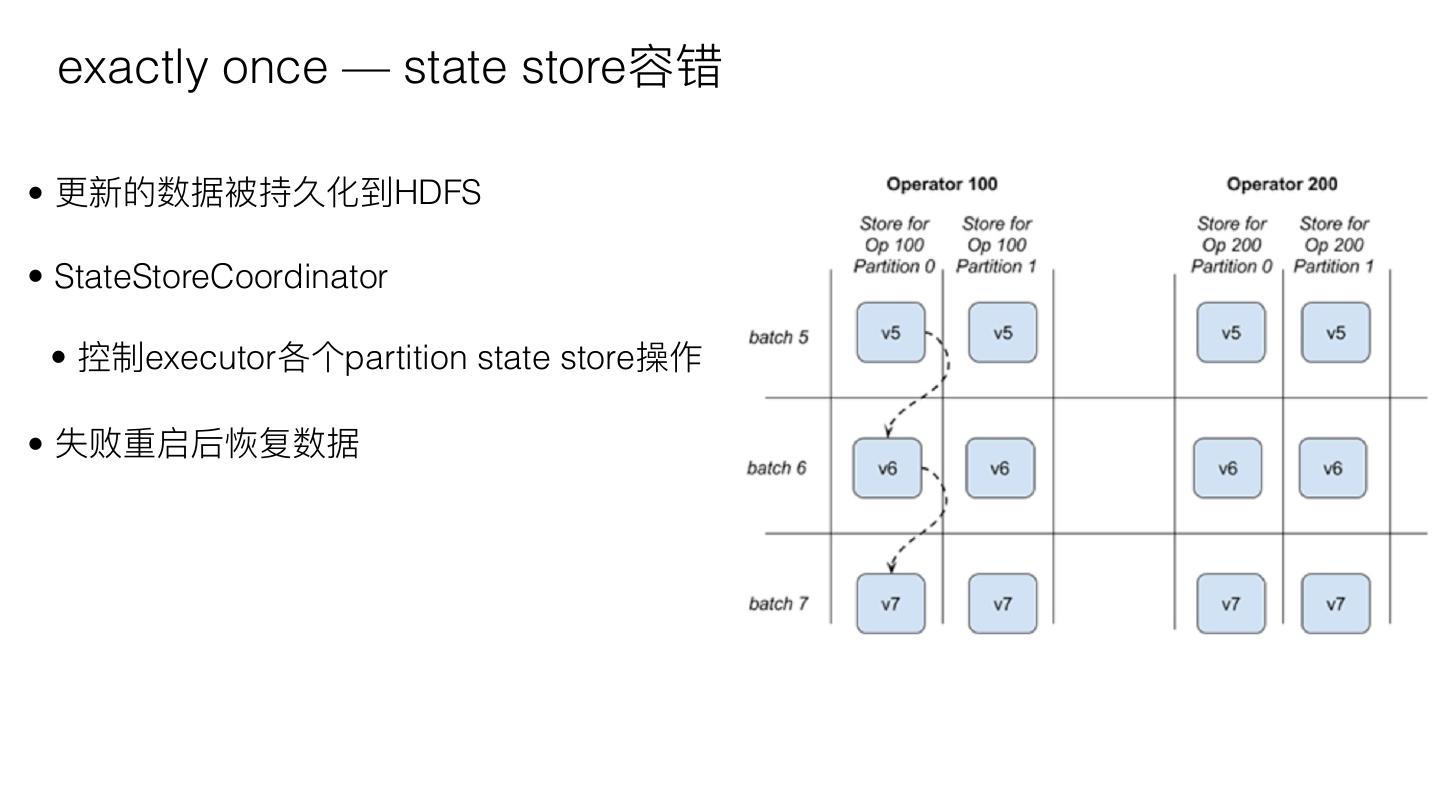
11 . exactly once — state store容错
• 更更新的数据被持久化到HDFS
• StateStoreCoordinator
• 控制executor各个partition state store操作
• 失败重启后恢复数据
�
13 .Spark 2.4 新特性
• [SPARK-24662] Support the LIMIT operator for streams in Append or Complete
mode
⽀支持complete/append模式
• [SPARK-24565] Exposed the output rows of each microbatch as a DataFrame
using foreachBatch
⽀支持⼀一些rdd操作:在线ML
output写⼊入多个location
对于continuous作业,foreach
�
14 .Spark 2.4 新特性
[SPARK-24763] Remove redundant key data from value in streaming
aggregation
[SPARK-25399] Fixed a bug where reusing execution threads from
continuous processing for microbatch streaming can result in a correctness
issue
[SPARK-24730] Support for choosing either the min or max watermark when
there are multiple input streams in a query
�
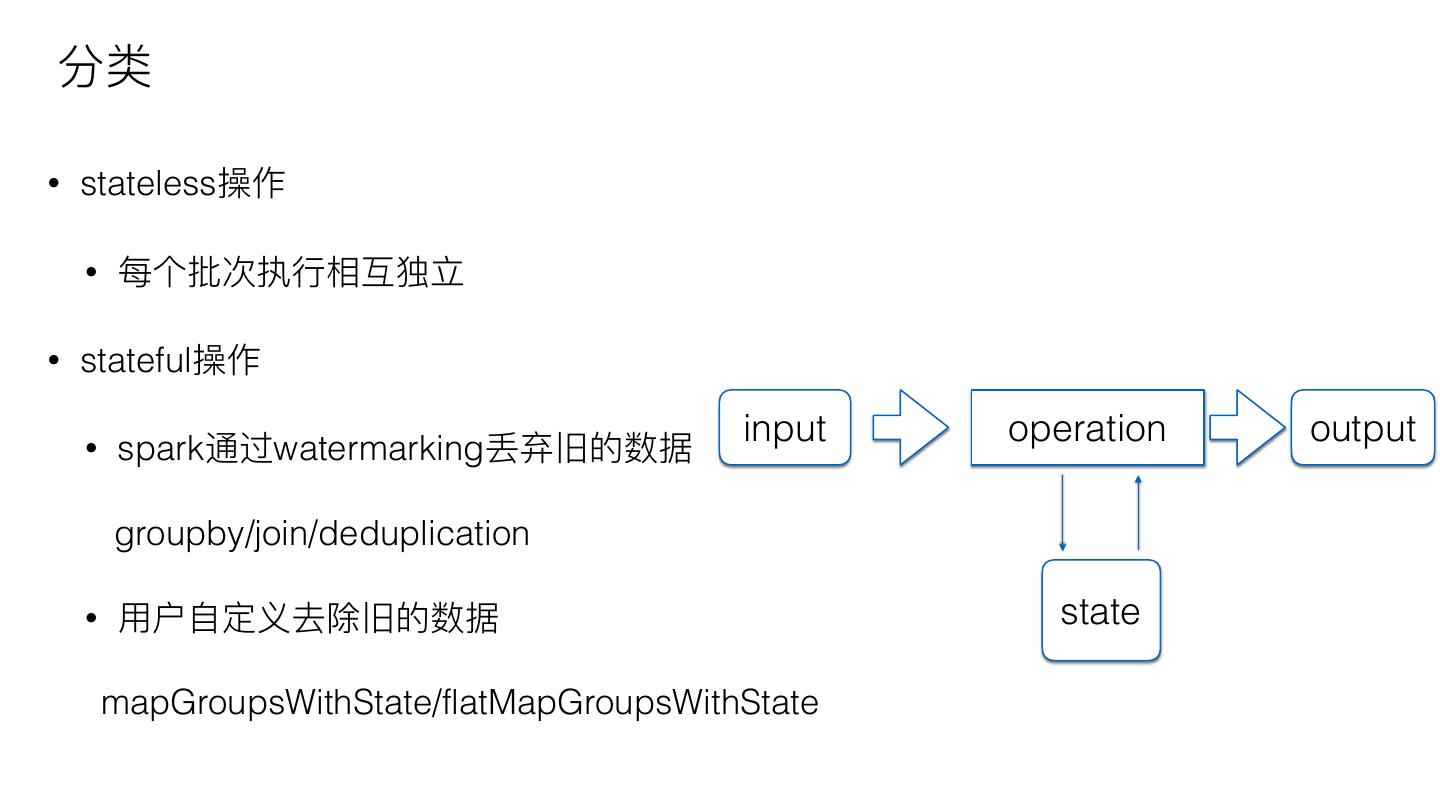
16 .分类
• stateless操作
• 每个批次执⾏行行相互独⽴立
• stateful操作
input operation output
• spark通过watermarking丢弃旧的数据
groupby/join/deduplication
• ⽤用户⾃自定义去除旧的数据 state
mapGroupsWithState/flatMapGroupsWithState
�
17 .groupby操作
• aggregation df.groupBy().avg("key");
• aggregation by df
event time .groupBy(window(“timestamp”,”10mins"))
.avg("value")
• Aggregation by df
both .groupBy(window($"timestamp", "10 minutes"), “key")
.count()
�
18 .stateful操作问题
• 旧数据持续更更新state
• state持续增⻓长
�
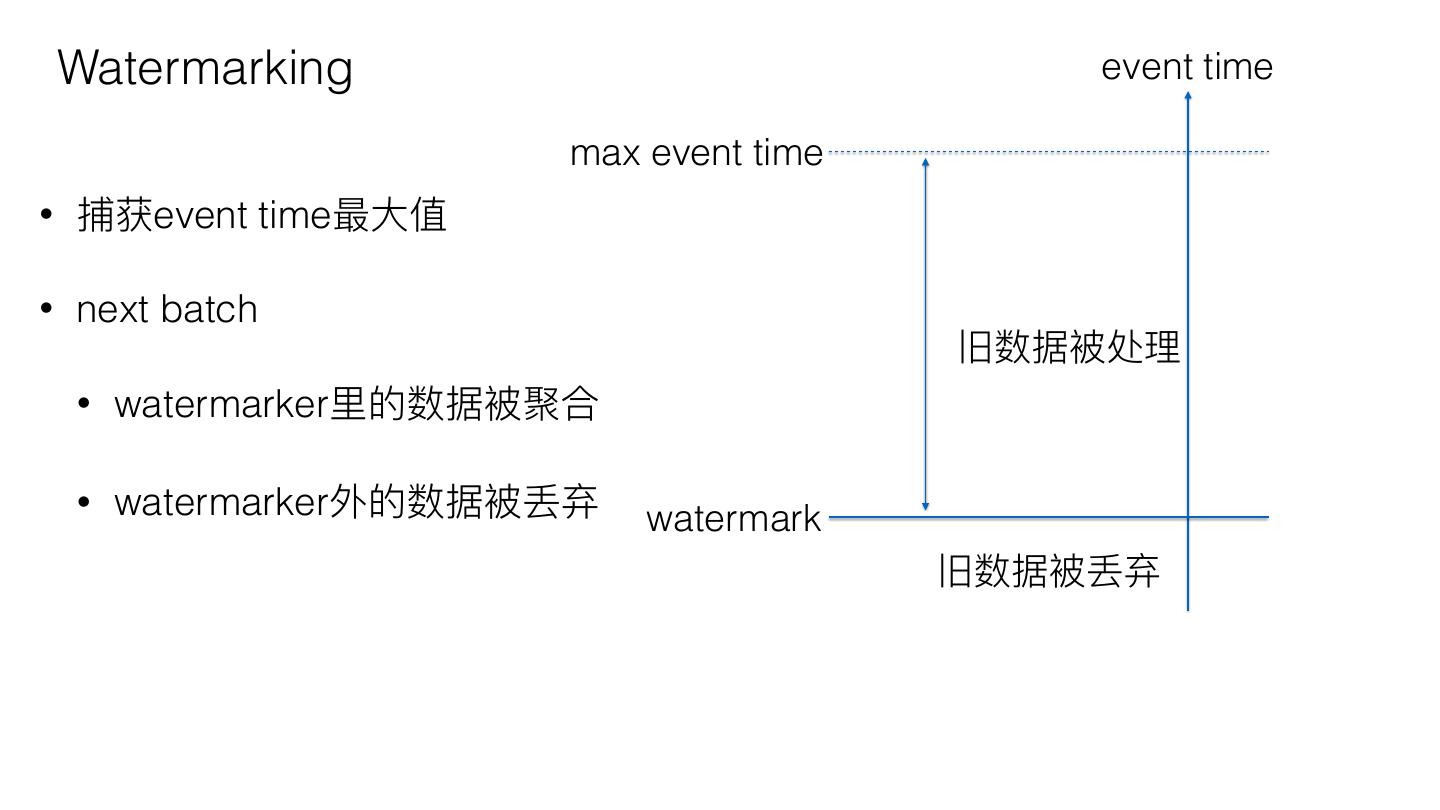
19 . Watermarking event time
max event time
• 捕获event time最⼤大值
• next batch
旧数据被处理理
• watermarker⾥里里的数据被聚合
• watermarker外的数据被丢弃 watermark
旧数据被丢弃
�
20 .Watermarking举例例
• 数据去重
userActions
.withWatermark("timestamp", "10 seconds")
.dropDuplicates("uniqueRecordId")
�
21 . mapGroupsWithState/flatMapGroupsWithState
• ⾃自定义state数据类型 def mappingFunction(key: String, value: Iterator[Int], state: GroupState[Int]): String = {
if (state.hasTimedOut) {
• ⾃自定义state操作 // 处理理超时
state.remove()
• ⾃自定义state状态管理理 } else {
val existingState = state.getOption.getOrElse(new UserStatus())
• timeout
val newState = existingState.handle(value) //业务处理理,更更新state
• value=empty state.update(newState)
state.setTimeoutDuration("1 hour")
• hasTimedOut = }
true // return something
}
dataset.groupByKey(...)
.mapGroupsWithState(GroupStateTimeout.ProcessingTimeTimeout)(mappingFunction)
�
22 .continuous aggregation操作
• 处于实验阶段,不不⽀支持⽣生产
• 只⽀支持map filter等操作
• 不不⽀支持聚合,如果要执⾏行行聚合,需要coalesce(1)
�
23 . Part 5
Structured Streaming的使⽤用场景
�
24 . 周期性的处理理最近的数据
• Trigger.Once
• 处理理上个batch到最近的数据
Structured Streaming
• 周期性启动job
input
last ~ latest
�
25 .低时延获取数据更更新
• stateful操作
• 数据存储KV数据库,⽅方便便key查询
• redis structured streaming a
key1 value1
perfect combination to scale key1:value0 Structured Streaming
out your continuous key1:value1
key2:value2 key2 value2
applications
…
… …
�
26 .结合维表
• join数据合并 batch job
slow input
• 重启作业获取更更新的数据
join
fast input
streaming job
�
27 .Change data capture
• 采集MySQL数据导⼊入Hive
• binglog-> streaming -> delta
databricks blog
�
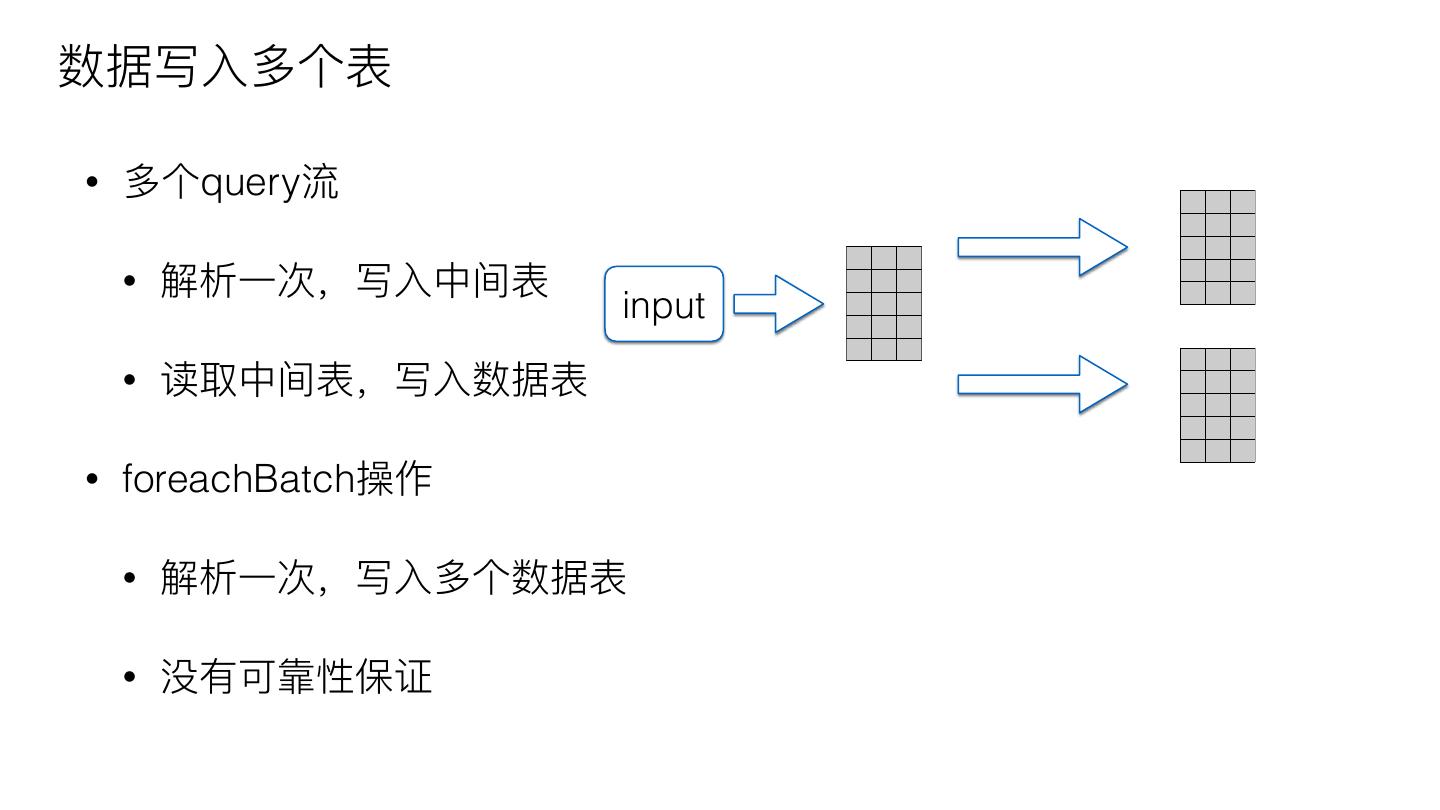
28 .数据写⼊入多个表
• 多个query流
• 解析⼀一次,写⼊入中间表
input
• 读取中间表,写⼊入数据表
• foreachBatch操作
• 解析⼀一次,写⼊入多个数据表
• 没有可靠性保证
�
29 . SPARK+AI SUMMIT 2019 案例例
• Streaming + Batch + SQL
• Near Real-Time Analytics with Apache Spark: Ingestion, ETL, and Interactive Queries
• NHSD
how australias national health services directory improved data quality reliability and integrity with
databricks delta and structured streaming
• Zalando
Continuous Applications at Scale of 100 Teams with Databricks Delta and Structured Streaming
• PySpark API
writing continuous applications with structured streaming pyspark api
�