展开查看详情
1 .Spark Streaming SQL 介绍
阿⾥里里巴巴计算平台事业部EMR
云魄
�
2 . 内容概要
• Spark Streaming SQL简介
• Spark Streaming SQL操作
• Spark Streaming SQL典型案例例
�
3 . Part 1
Spark Streaming SQL简介
�
4 .Spark Streaming SQL概述
• SQL开发流式作业
• Spark Streaming 扩展
• 基于Spark Structured Streaming
• runtime
• Spark Structured Streaming调度引擎
• Spark SQL执⾏行行引擎
�
5 .Spark Streaming SQL特点
• SQL 数据源 读 写
• 开发和应⽤用成本 Kafka ✅ ✅
• 接近应⽤用 HDFS/OSS ✅ ✅
✅ ✅
• 底层API变动透明 Aliyun Loghub
Aliyun TableStore ✅
• 批流统⼀一
Hbase ✅
• 开发和迁移
JDBC ✅
• 多种数据源⽀支持
Druid ✅
aliyun-emapreduce-sdk
Aliyun Datahub ✅
• Spark⽣生态⽀支持
Redis ✅
�
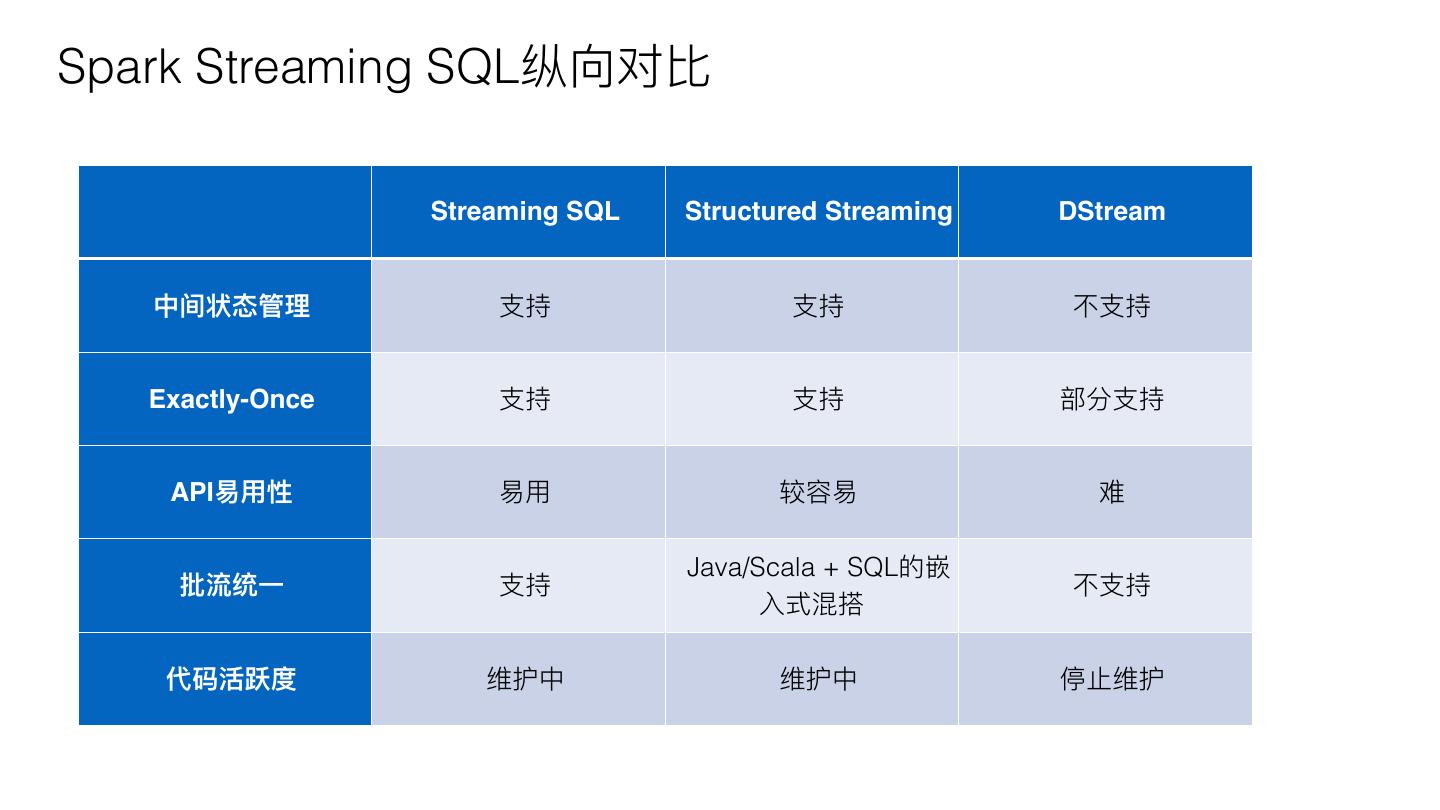
6 .Spark Streaming SQL纵向对⽐比
Streaming SQL Structured Streaming DStream
中间状态管理理 ⽀支持 ⽀支持 不不⽀支持
Exactly-Once ⽀支持 ⽀支持 部分⽀支持
API易易⽤用性 易易⽤用 较容易易 难
Java/Scala + SQL的嵌
批流统⼀一 ⽀支持 不不⽀支持
⼊入式混搭
代码活跃度 维护中 维护中 停⽌止维护
�
7 .Spark Streaming SQL横向对⽐比
Spark Streaming SQL Flink SQL KSQL
批流统⼀一 ⽀支持 ⽀支持 只⽀支持流
中间状态管理理 ⽀支持 ⽀支持 ⽀支持
mini-batch: 秒级
实时性 continuous:亚秒级(⾮非⽣生产实 event-mode:亚秒级 亚秒级
现)
UDF⽀支持 ⽀支持 ⽀支持 不不⽀支持
SQL ⽀支持 ⽀支持 ⽀支持
SQL标准 Industry-standard SQL Industry-standard SQL SQL-like
按数据源⽀支持端到端的 按数据源⽀支持端到端的
数据投递 ⽀支持Kafka的Exactly-Once
Exactly-Once Exactly-Once
容错性 ⽀支持 ⽀支持 ⽀支持
�
8 .Spark社区
• SPIP: Support Streaming SQL interface in Spark
• 流式SQL标准
�
9 . Part 2
Spark Streaming SQL操作
�
10 . 配置数据源
• CREATE TABLE with column
CREATE TABLE tbName(columnName dataType [,columnName dataType]*)
USING providerName
OPTIONS(propertyName=propertyValue[,propertyName=propertyValue]*);
�
11 . 配置数据源
• CREATE TABLE without column
CREATE TABLE tbName
USING providerName
OPTIONS(propertyName=propertyValue[,propertyName=propertyValue]*);
�
13 .配置流式作业
• streaming.query.name
• spark.sql.streaming.checkpointLocation
• spark.sql.streaming.query.trigger
�
14 .创建流式作业
• INSERT
INSERT INTO tbName
queryStatement;
�
15 .创建流式作业
• CTAS
CREATE TABLE tbName[(columnName dataType [,columnName dataType]*)]
USING providerName
OPTIONS(propertyName=propertyValue[,propertyName=propertyValue]*)
AS queryStatement;
�
16 .窗⼝口函数
• 滚动窗⼝口(TUMBLING)
• 滑动窗⼝口(HOPPING)
• slideDuration和windowDuration
• window.start 和 window.end
�
17 .窗⼝口函数
• 滚动窗⼝口(TUMBLING)
• 滑动窗⼝口(HOPPING)
�
18 .delay
• watermark
WHERE delay ( colName ) < ‘duration'
�
19 . Part 3
Spark Streaming SQL典型案例例
�
20 .ETL
Spark Streaming SQL id data-id
msg data-message
date data-date
select json_tuple(CAST(value AS STRING), date, msg, id) as (date, msg, id)
�
21 .实时⼤大屏
user0 5 Spark Streaming SQL
user0 11
user1 8
user1 8
user0 6
select sum(cast(visit as int)) as click, userId
from table
where delay(__time__)<"10 second”
group by TUMBLING(__time__, interval 10 second), userId;
�
22 .维表join
level id value
Spark Streaming SQL level id value
level0 id0 value0
user1 id0 value0
level1 id1 value1
level note
level0 note-info
SELECT level, id, value from loghub_source_table
join hdfs_source_table
on loghub_source_table.level = hdfs_source_table.level
�
23 .更更多实践案例例
• EMR云栖号
• Spark开源中国社区
�