展开查看详情
1 .Spark for ETL & Data Science
章剑锋 · 阿⾥巴巴 /⾼级技术专家
�
2 .2008
Who Am I
2011
2013
2014
2018
�
3 . 01
What is ETL & Data Science
02
CONTENT
How to do ETL in Spark
⽬录 >> 03
How to do Data Science in Spark
04
Demo via Spark on Zeppelin
�
4 . 01
What is ETL & Data Science
Apache Flink 中⽂学习⽹站: ververica.cn
© Apache Flink Community China 严禁商业⽤途
�
5 .Data Pipeline
ETL Data Science
�
6 .线下交流
微信公众号 钉钉群
We are hiring (校招,社招)
jeffzhang.zjf@alibaba-inc.com
�
7 . 02
How to do ETL in Spark
Apache Flink 中⽂学习⽹站: ververica.cn
© Apache Flink Community China 严禁商业⽤途
�
8 .What is ETL
• Extract
- Read raw data from single/multiple sources (no schema, uncompressed, dirty)
• Transform
- Transform raw data (Filtering/Aggregation/Normalization/Join)
• Load
- Write data into sinks (compressed, structured, cleaned, well-organized)
Source Sink
�
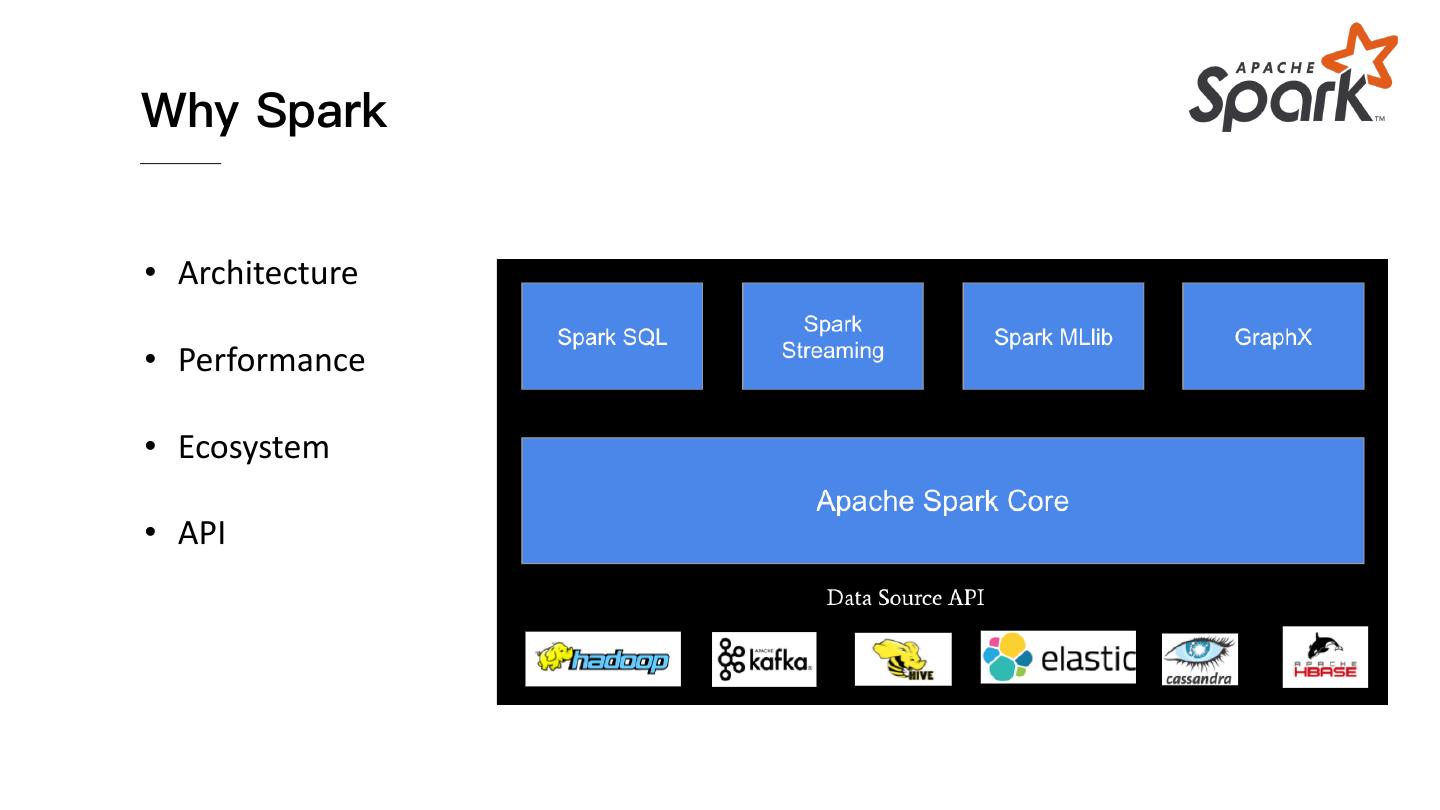
9 .Why Spark
• Architecture
• Performance
• Ecosystem
• API
�
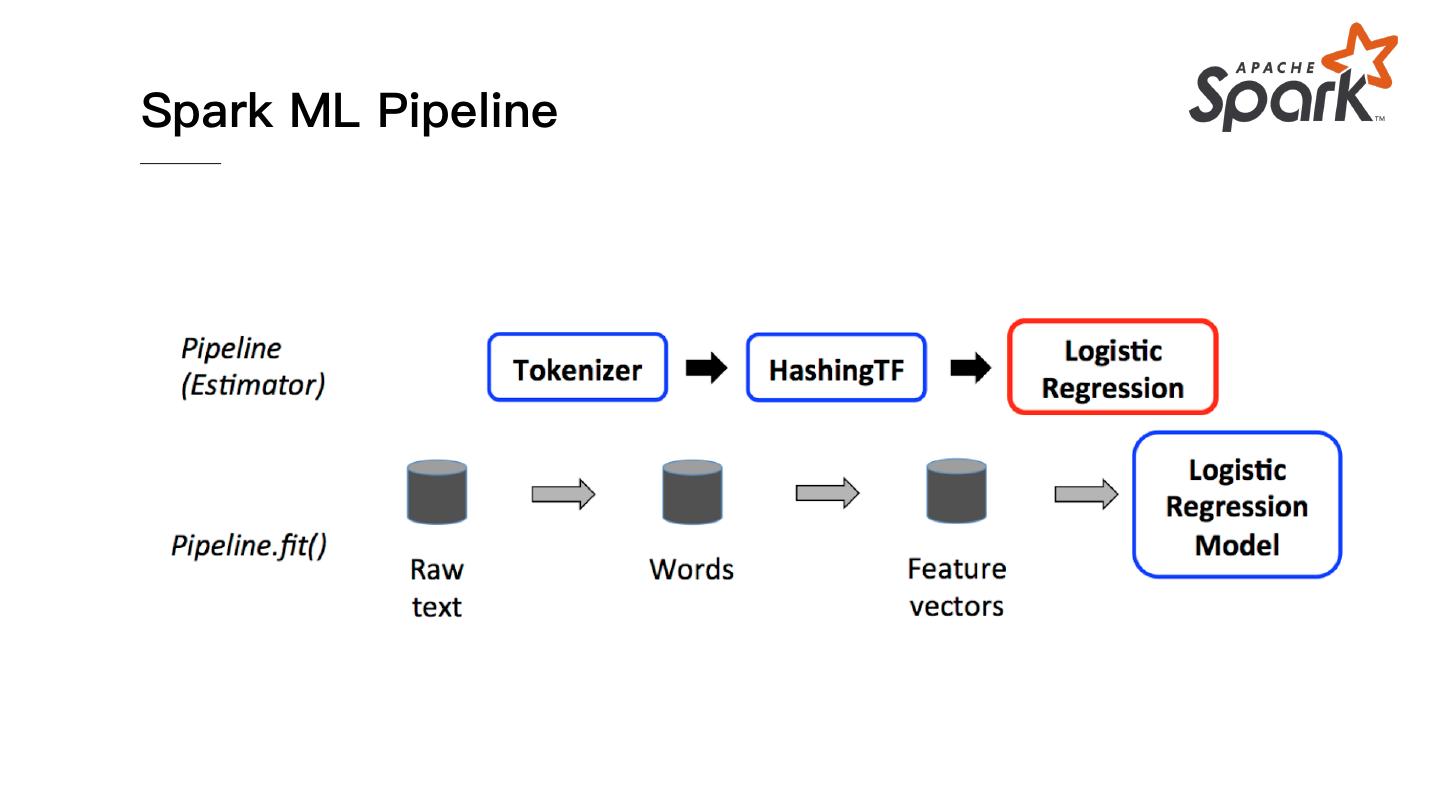
10 .ETL Example in Spark
spark.read.csv(“source_path”) Extract
.filter(...)
.agg(...) Transform
.write.mode(“append”)
.orc(“sink_path”) Load
�
11 .Handling bad record
Text format (csv, json) supports 3 parsing mode
• PERMISSIVE
- sets other fields to `null` when it meets a corrupted record and puts the malformed string into a
new field configured by `spark.sql.columnNameOfCorruptRecord`.
• DROPMALFORMED
- ignores the whole corrupted records
• FAILFAST
- throws an exception when it meets corrupted records
�
12 .Handling record corrupted
�
13 .Keep in mind
• You have no control on source data (format / scale / schema)
• You have no control on hardware/network (fault tolerance)
�
14 . 03
How to do data science in Spark
Apache Flink 中⽂学习⽹站: ververica.cn
© Apache Flink Community China 严禁商业⽤途
�
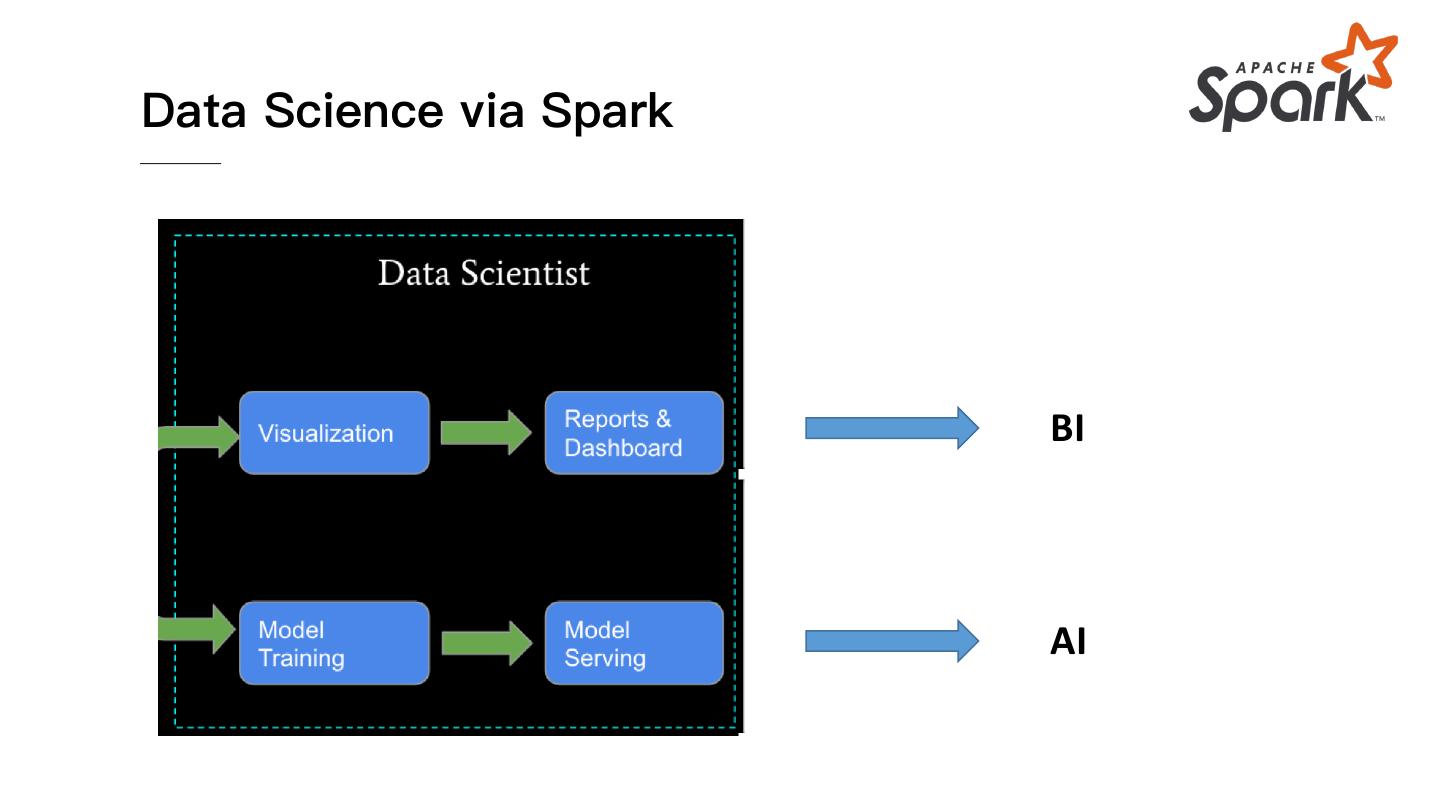
15 .Data Science via Spark
BI
AI
�
16 .Spark SQL Operation
• Add or update columns
• Drop column
• Where | Filter
• Group by
• Aggregation
• Join
• Union
• UDF
�
17 .Visualization
• Zeppelin Notebook (SQL)
• PySpark (Python)
• Sparkr (R)
�
19 .PySpark
• Matplotlib
• Pandas
• Bokeh
• Seaborn
• Plotnine
• Holoviews
�
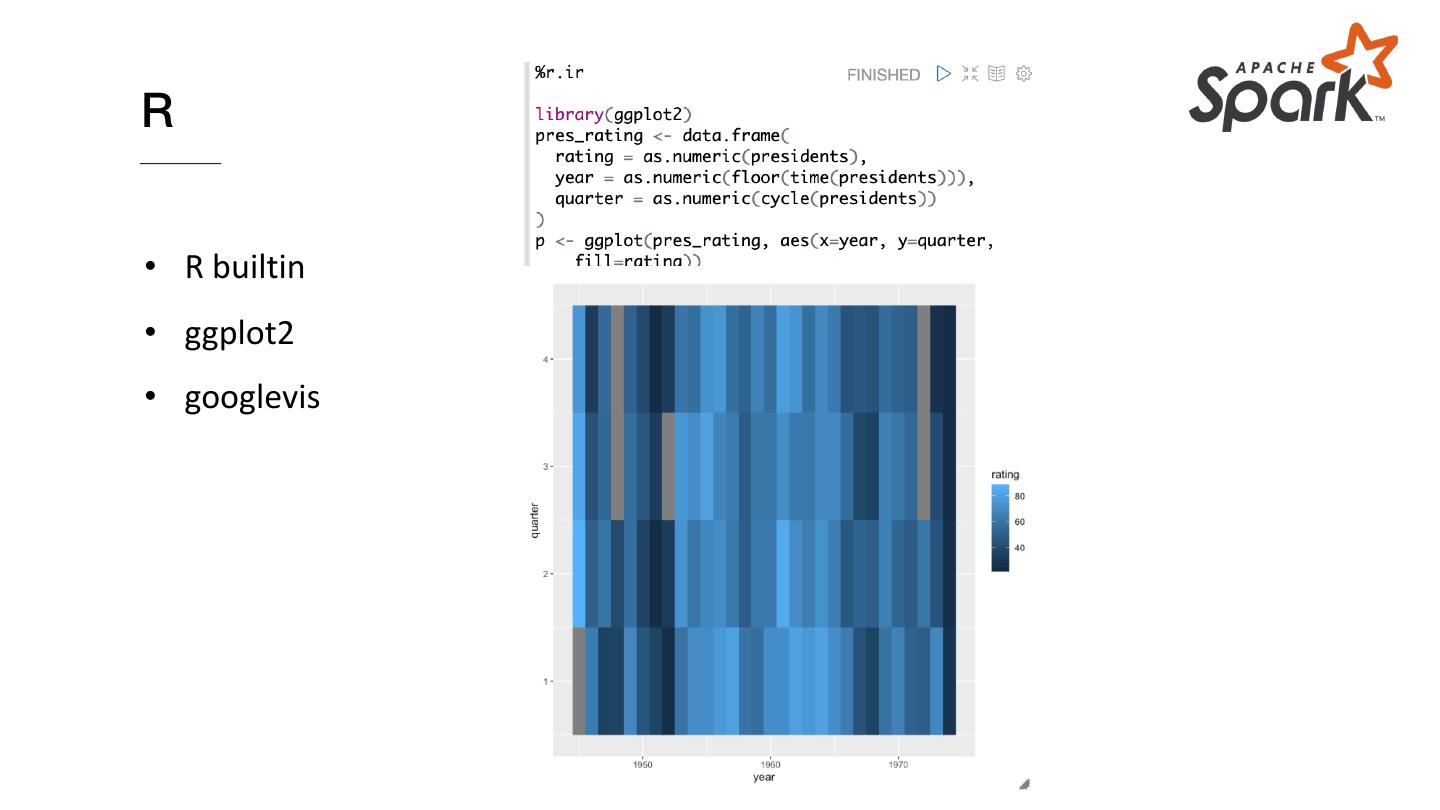
20 .R
• R builtin
• ggplot2
• googlevis
�
21 .Three types of Machine Learning
• Supervised Learning
- Labeled data is available
- Classification / Regression
• Unsupervised Learning
- No labeled data is available
• Reinforcement Learning
- Model is continuously learned and relearn based on the action and effects/rewards based on the actions
�
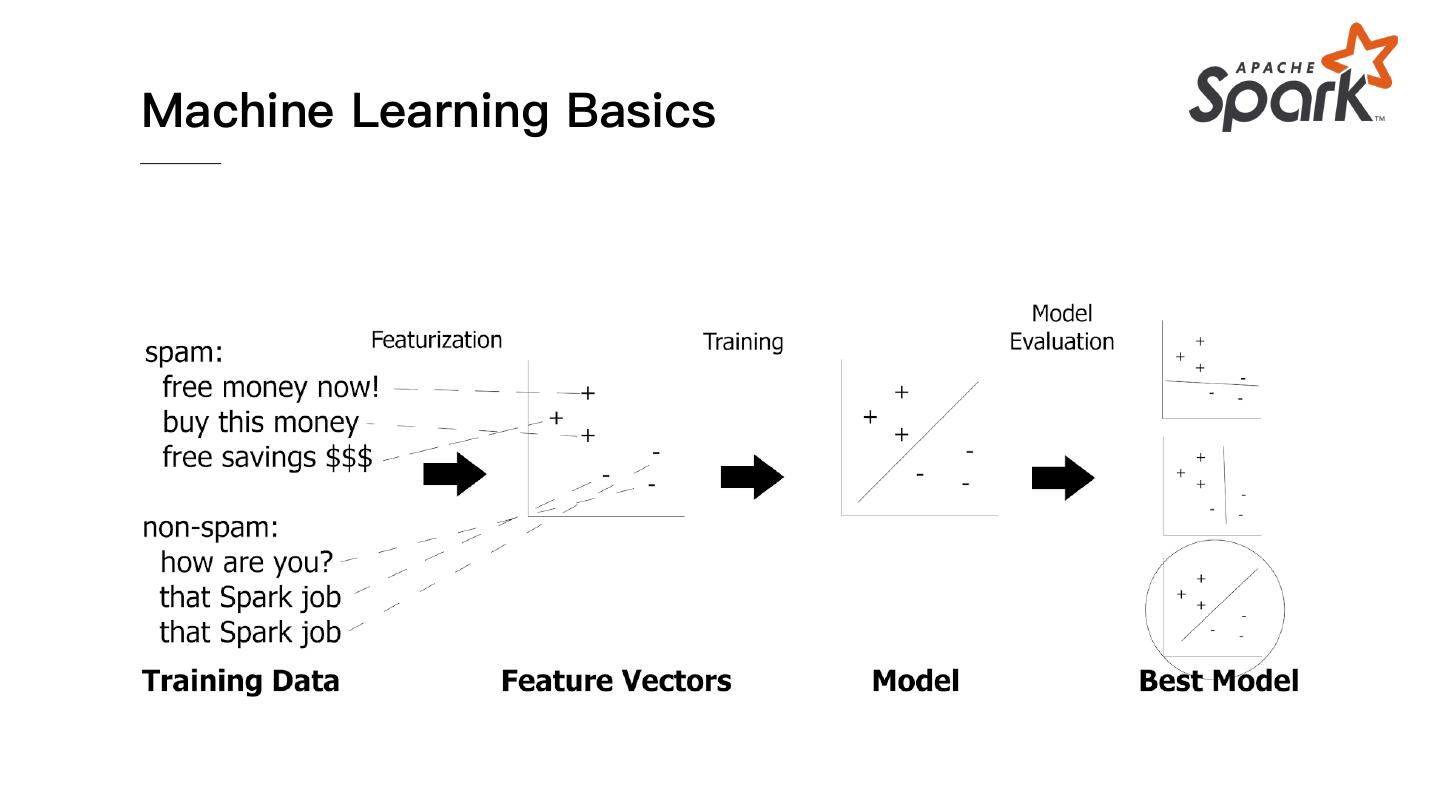
22 .Machine Learning Basics
�
24 . 04
Demo via Spark on Zeppelin
Apache Flink 中⽂学习⽹站: ververica.cn
© Apache Flink Community China 严禁商业⽤途
�
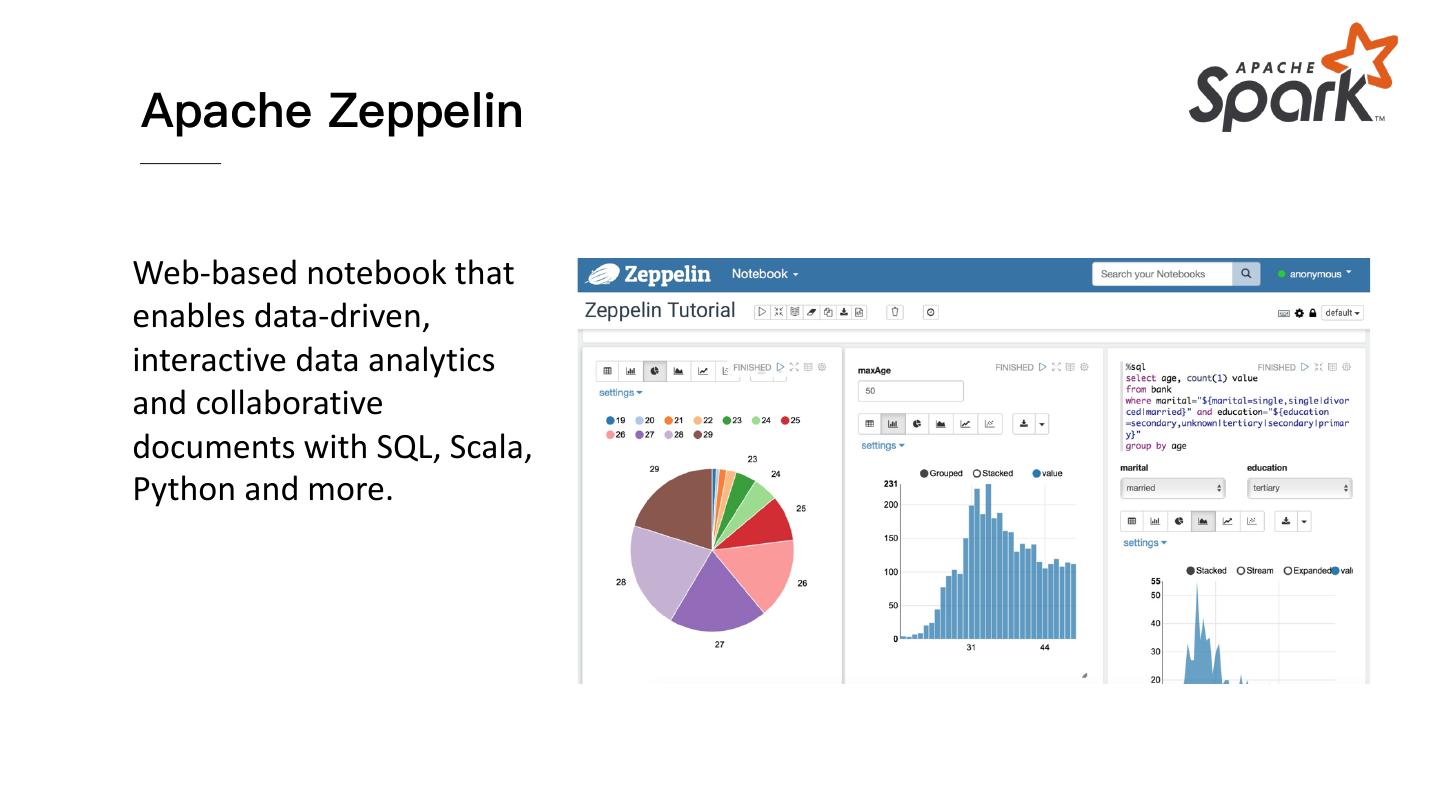
25 .Apache Zeppelin
Web-based notebook that
enables data-driven,
interactive data analytics
and collaborative
documents with SQL, Scala,
Python and more.
�