展开查看详情
1 .Spark Relational Cache: Spark
-EM R
�
2 .Agenda
• Relational Cache
• Relational Cache
•
• Relational Cache
•
�
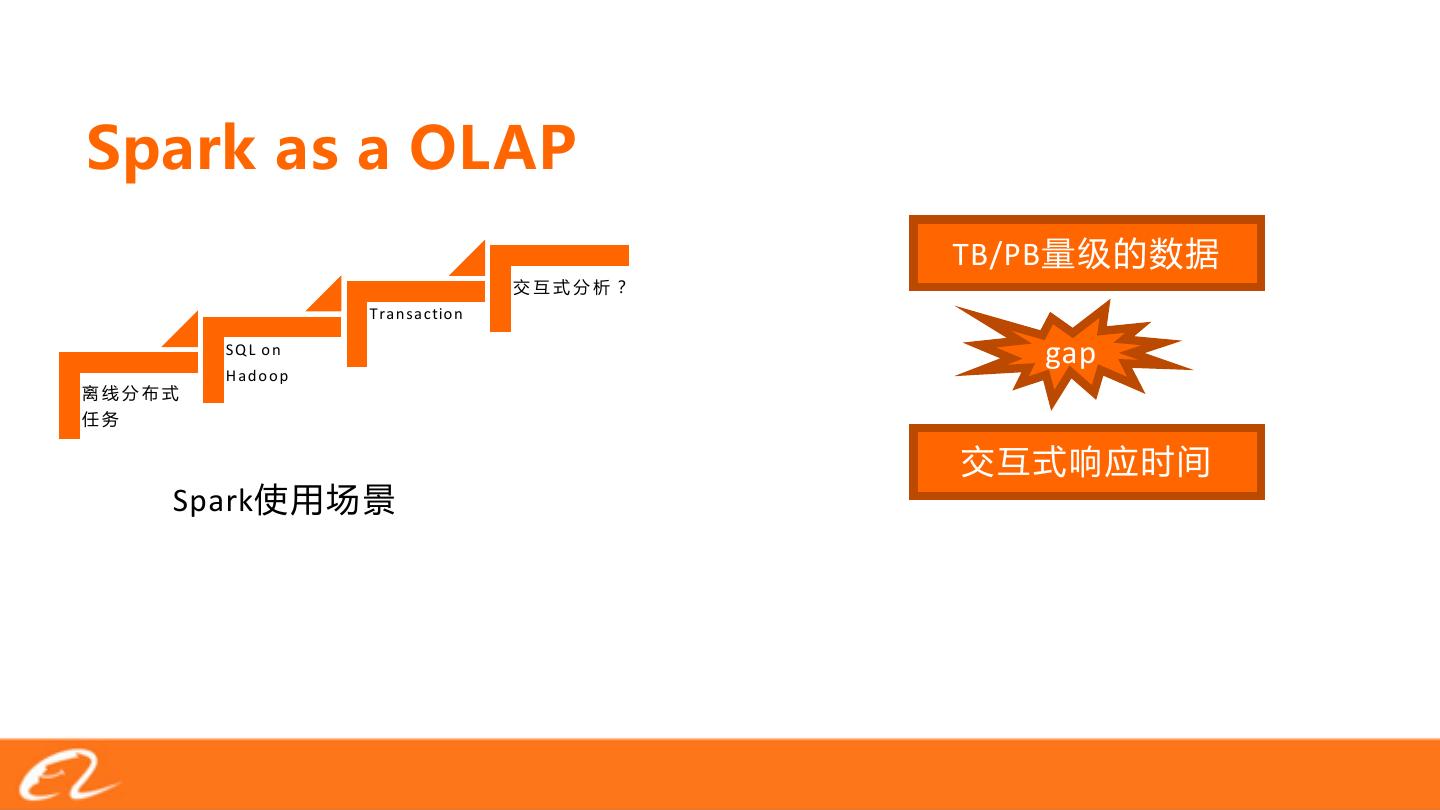
3 . TB/PB
Tran sactio n
SQ L o n gap
H ad o o p
Spark
�
4 . J c O
•
•
•
•
• a
•
• a •
bd ZI e
•
F
�
6 .,3 143m B rVnC
3u iec sie tw s
3 A32 . 3 3 4 4
B 4 2
• 3 O 1 143
ieR
• P r 1 143I Q S z p Brap k LhB
ie
ra M l
• d P bieo BR o 1 143D i
e
�
7 . Relational Cache
Admin
User
Cache
�
8 .Relational Cache
Part I
�
9 . Relational Cache
CACHE [LAZY] TABLE view_name
[REFRESH ON (DEMAND | COMMIT)]
[(ENABLE | DISABLE) REWRITE]
JSON
[USING datasource PARQUET…
[LOCATION cache_storage_dir] HDFS
OSS…
[PARTITIONED BY (col_name1, col_name2, ...)]
[CLUSTERED BY (col_name3, col_name4, ...) INTO num_buckets BUCKETS]
[ZORDER BY (col_name5, col_name6, …)]
[AS select_statement]
cache Table View cache HDFS OSS JSON ORC Parquet
�
10 . Relational Cache –
flat_sales orders, customers, nation, region cache HDFS parquet
CACHE TABLE flat_orders
REFRESH ON COM M IT
ENABLE REW RITE
USING parquet
PARTITIONED BY (o_orderdate)
COM M ENT “denormalized orders table”
AS SELECT *
FROM orders, customers, nation, region
W HERE o_custkey = c_custkey AND c_nationkey = n_nationkey AND n_regionkey = r_regionkey
�
11 . DDL
• UNCACHE TABLE [IF EXISTS] table_name
• ALTER TABLE table_name (ENABLE | DISABLE) REW RITE
• ALTER TABLE table_name REFRESH ON (DEM AND | COM M IT)
• REFRESH CACHE cache_name [W ITH TABLE base_table_name partition(key=value)]
• SHOW CACHES
�
13 .1. Spark spark.sql.cache.queryRewrite
2. ALTER Relational Cache
3. Relational Cache
�
14 .Query Rewrite case1
Relational Cache: Rewritten Query:
CACHE TABLE mv SELECT empid, deptname, hire_date
USING parquet
AS SELECT empid, deptname, hire_date FROM mv
FROM emps JOIN depts ON (emps.depno = WHERE hire_date >= ‘2018-01-01’ AND
depts.depno) hire_date <= ‘2018-06-30’
WHERE hire_date > ‘2016-01-01’
empid deptnam hire_date
e
Query:
10320 IT 2016-03- empid deptnam hire_date
SELECT empid, deptname, hire_date 23 e
FROM emps JOIN depts ON (emps.depno = 10201 HR 2018-04- 10201 HR 2018-04-
depts.depno) 02 02
WHERE hire_date >= ‘2018-01-01’ AND 10203 DEV 2018-05- 10203 DEV 2018-05-
29 29
hire_date <= ‘2018-06-30’
13094 QA 2019-01-
09
mv result
�
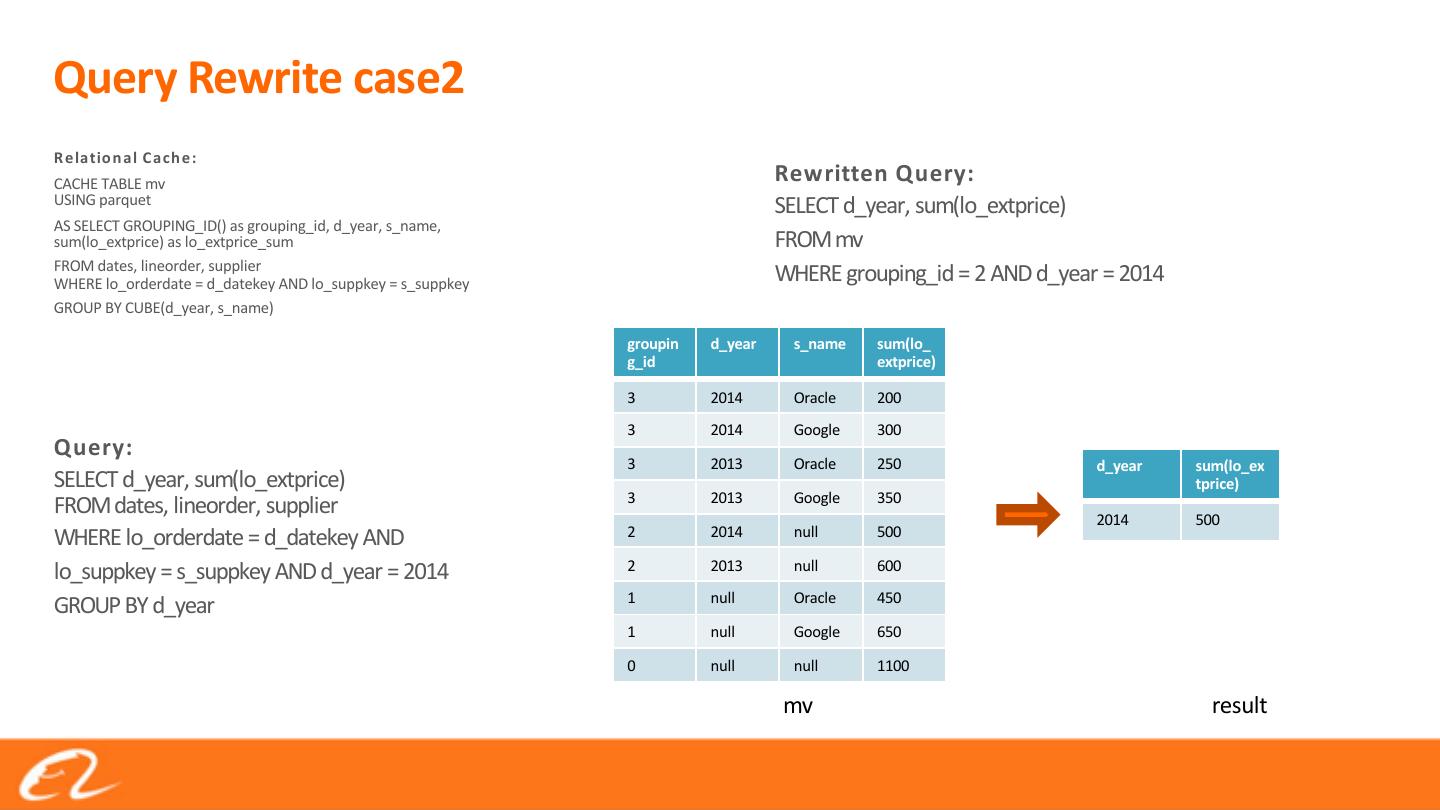
15 .Query Rewrite case2
R elatio n al C ach e:
CACHE TABLE mv Rewritten Query:
USING parquet SELECT d_year, sum(lo_extprice)
AS SELECT GROUPING_ID() as grouping_id, d_year, s_name,
sum(lo_extprice) as lo_extprice_sum FROM mv
FROM dates, lineorder, supplier
WHERE lo_orderdate = d_datekey AND lo_suppkey = s_suppkey WHERE grouping_id = 2 AND d_year = 2014
GROUP BY CUBE(d_year, s_name)
groupin d_year s_name sum(lo_
g_id extprice)
3 2014 Oracle 200
3 2014 Google 300
Query:
3 2013 Oracle 250 d_year sum(lo_ex
SELECT d_year, sum(lo_extprice) tprice)
3 2013 Google 350
FROM dates, lineorder, supplier 2014 500
WHERE lo_orderdate = d_datekey AND 2 2014 null 500
lo_suppkey = s_suppkey AND d_year = 2014 2 2013 null 600
1 null Oracle 450
GROUP BY d_year
1 null Google 650
0 null null 1100
mv result
�
16 .Relational Cache
Part III
�
17 . Cache
• ON COM M IT cache cache
• ON DEM AND REFRESH
• Cache
• ON DEM AND
• ALTER
�
18 .1. Cache
2. cache
3.
REFRESH CACHE cache_name W ITH TABLE base_table PARTITION(part_key=‘value’)
Relational Cache + Delta =>
�
19 .Relational Cache OLAP
�
20 . EMR Spark Relational Cache OLAP
•
• Spark SQL/Dataset API
• One Cache for All Queries Cache
• Cube
�
21 .Star Schema Benchmark
• TPCH
•
Benchmark
• Oracle, ClickHouse OLAP SSB
�
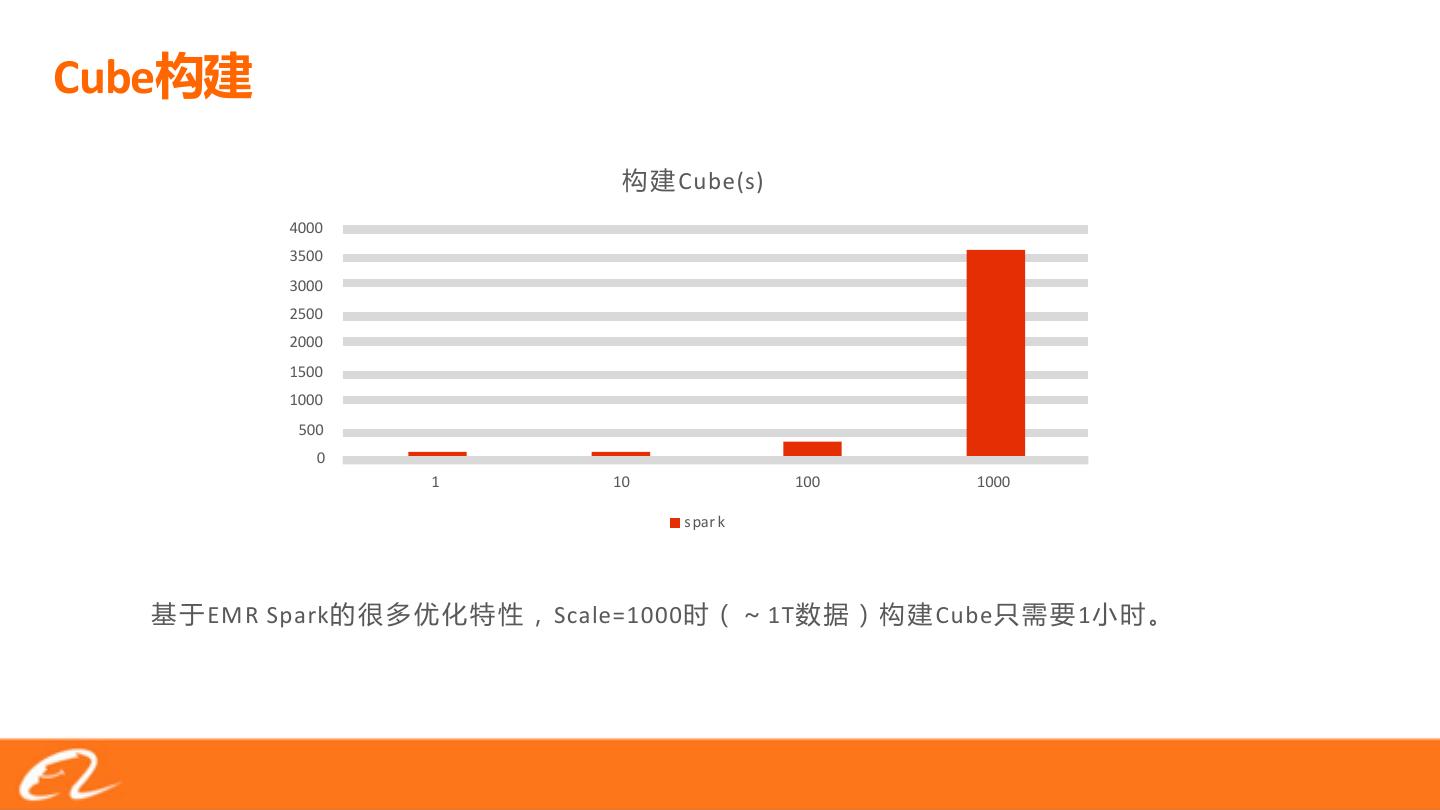
22 .Cube
Cube(s)
4000
3500
3000
2500
2000
1500
1000
500
0
1 10 100 1000
s par k
EM R Spark Scale=1000 1T Cube 1
�
23 .Spark Cached vs Uncached
• Cache Parquet Cache vs No Cache(ms)
HDFS Lower is better
262144 250
• SSB cache
65536
scale cache 16384 200
cube 4096
150
1024
256
100
64
16 50
4
1 Cached( m s ) No Cache( m s ) Speedu p 0
2 20 40 200 1000
scale
�