



















- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 视频嵌入链接 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Spark Relational Cache实现亚秒级响应的交互式分析
分享
点赞
7
收藏
2
主讲人:王道远,花名健身,阿里云EMR技术专家,Apache Spark活跃贡献者,主要关注大数据计算优化相关工作。
简介:2019杭州云栖大会大数据生态专场中的分享《Spark Relational Cache实现亚秒级响应的交互式分析》
Apache Spark被广泛用于超大规模的数据分析处理,在交互式分析等时间敏感的场景中,超大规模数据量的处理时间可能无法满足用户快速响应的需求。通过数据的预组织和预计算,将频繁访问的数据和计算提前执行并保存在Relational Cache中,优化后续特定模式的查询,可以显著提高查询速度,实现亚秒级的响应。本议题主要介绍Spark Relational Cache的实现原理和使用场景。
展开查看详情
1 .Spark Relational Cache 实现亚秒级响应的数据分析 Spark Relational Cache: interactive data analysis with sub-second response 王道远 (健身) 阿里云智能计算平台事业部技术专家
2 . 01 项目介绍 What is Relational Cache Contents 02 技术分析 ⽬目录 Technical Details 03 如何使用 How To Use 04 性能分析 Performance Analysis
3 .项⽬目介绍 What is Spark Relational Cache 01
4 . 项⽬目背景 Background Hue Jupyter Zeppelin …… Impala 阿⾥里里云 EMR …… Hive Spark Presto Flink 海海量量数据 快速分析 Large Scale Fast Analysis Object Store HDFS Stream … (对象存储 OSS)
5 . 云上Adhoc数据分析痛点 Adhoc Data Analysis on Cloud 快速响应 • Spark 应⽤用⼴广泛 Fast • Spark is popular in OLAP data analysis • Spark ⽬目前的缓存机制有不不⾜足 之处 • Current cache mechanism in Apache 巨量量数据 云原⽣生 Spark is insufficient Large scale Cloud Native
6 . Spark Relational Cache SQL Apache Spark Relational EMR Spark Cache Matching ~1000s ~1s Relational Cache Raw Files Cache Effective Storage Format Jindo FS 集群HDFS Aliyun OSS
7 . Spark Relational Cache 特点 Features 快速响应·Fast ⽤用户透明·User-transparent 秒级/亚秒级响应速度 只需管理理员维护Cache 满⾜足多⽤用户查询需求 客户Query⽆无需更更新,Relational Cache⾃自动匹配 Query latency in sub-seconds. Data scientists can focus exclusively on queries. Multi-tenancy supported. No query modification is needed. 海海量量数据·Large-scale data ⾃自动更更新·Data Refresh ⽀支持海海量量数据预计算 根据策略略按需更更新 ⽀支持关联表提⾼高命中效果 数据变动差量量更更新 Supports large data scales. On Commit/On Demand strategies. Supports PK/FK. Only calculate if needed. ⾼高效存储·Efficient Storage 智能推荐·Smart Recommendation 默认列列存格式、⾼高效存储与检索预计算结果 根据历史查询⾃自动推荐缓存⽅方案 云原⽣生架构中缓存放在集群内部,原始数据放在集群外 统计命中情况展示缓存效果 Using columnar store by default. Recommend Cache definitions based on historic queries. Supports data skipping with properly partitioned data. Show hit rates.
8 .技术分析 Why Spark Relational Cache is fast 02
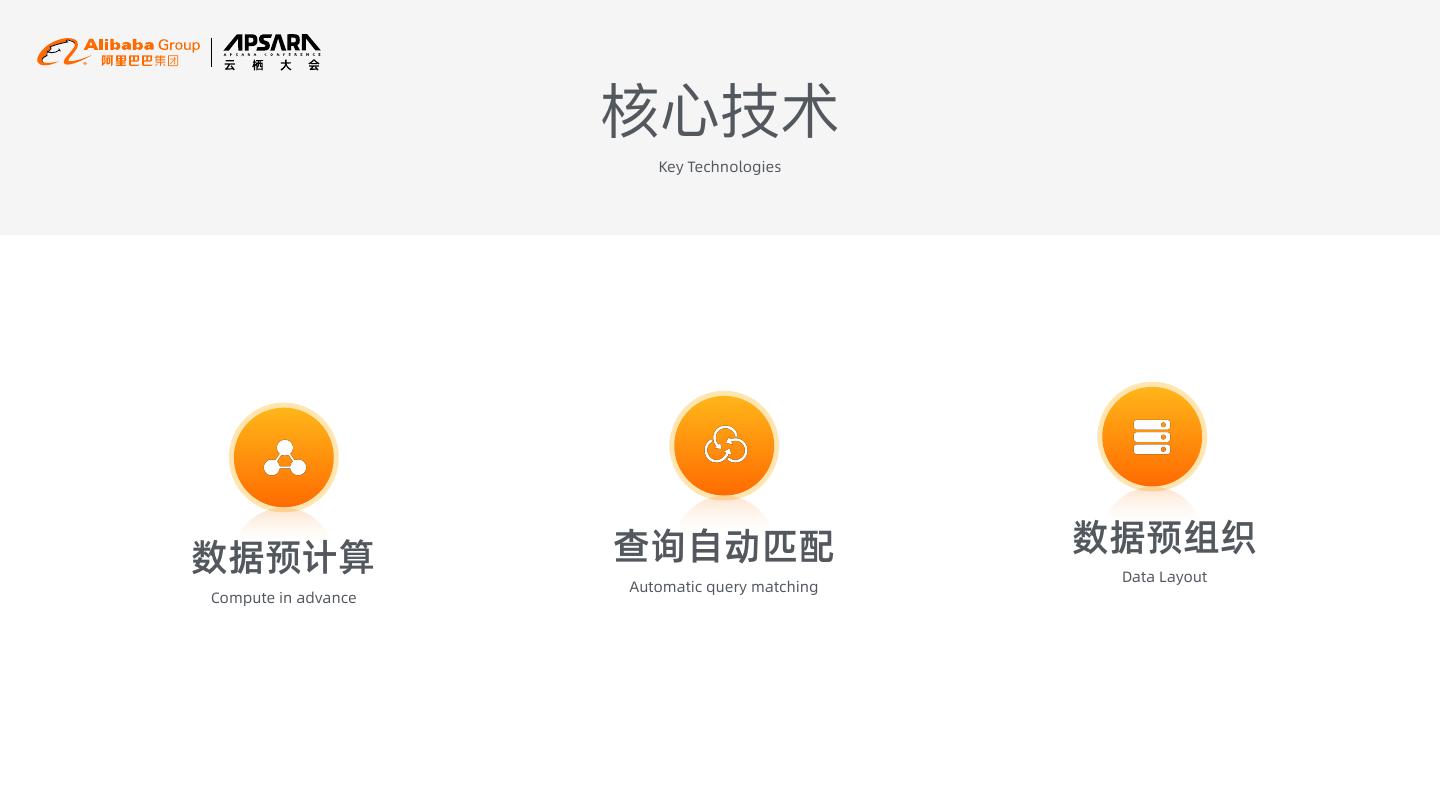
9 . 核⼼心技术 Key Technologies 查询自动匹配 数据预组织 数据预计算 Data Layout Automatic query matching Compute in advance
10 .数据预计算 Compute in advance 雪花模型·Snowflake Schema 允许⽤用户通过Primary Key/Foreign Key明确表之间的关系,提⾼高匹 配成功率。 Allow user to specify PK/FK to match more cases. 预计算·Pre Aggregate/Join/Cube 充分利利⽤用EMR Spark加强的计算能⼒力力。 Leverage the power of EMR Spark. 数据⽴立⽅方·Data Cube ⽀支持多维数据分析。 Supports multi-dimensional data analysis.
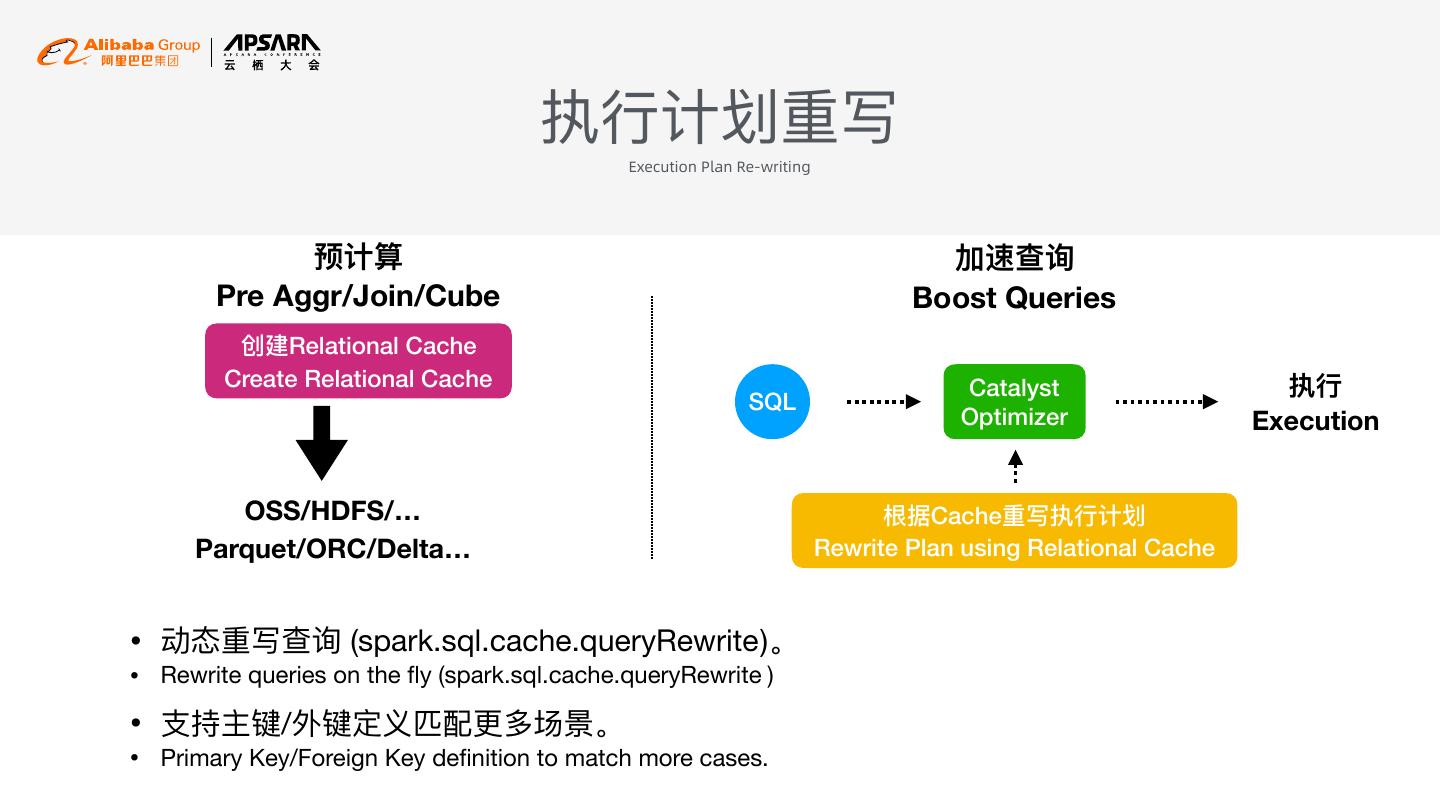
11 . 执⾏行行计划重写 Execution Plan Re-writing 预计算 加速查询 Pre Aggr/Join/Cube Boost Queries 创建Relational Cache Create Relational Cache Catalyst 执⾏行行 SQL Optimizer Execution OSS/HDFS/… 根据Cache重写执⾏行行计划 Parquet/ORC/Delta… Rewrite Plan using Relational Cache • 动态重写查询 (spark.sql.cache.queryRewrite )。 • Rewrite queries on the fly (spark.sql.cache.queryRewrite ) • ⽀支持主键/外键定义匹配更更多场景。 • Primary Key/Foreign Key definition to match more cases.
12 . 查询⾃自动匹配 Query Automatic Matching Relational Cache: Rewritten Query: CACHE TABLE mv SELECT empid, deptname, hire_date USING parquet FROM mv AS SELECT empid, deptname, hire_date WHERE hire_date >= ‘2018-01-01’ AND FROM emps JOIN depts ON (emps.depno = depts.depno) hire_date <= ‘2018-06-30’ WHERE hire_date > ‘2016-01-01’ empid deptname hire_date 10320 IT 2016-03-23 empid deptname hire_date Query: SELECT empid, deptname, hire_date 10201 HR 2018-04-02 10201 HR 2018-04-02 FROM emps JOIN depts ON (emps.depno = depts.depno) 10203 DEV 2018-05-29 10203 DEV 2018-05-29 WHERE hire_date >= ‘2018-01-01’ AND hire_date <= 13094 QA 2019-01-09 ‘2018-06-30’ mv result
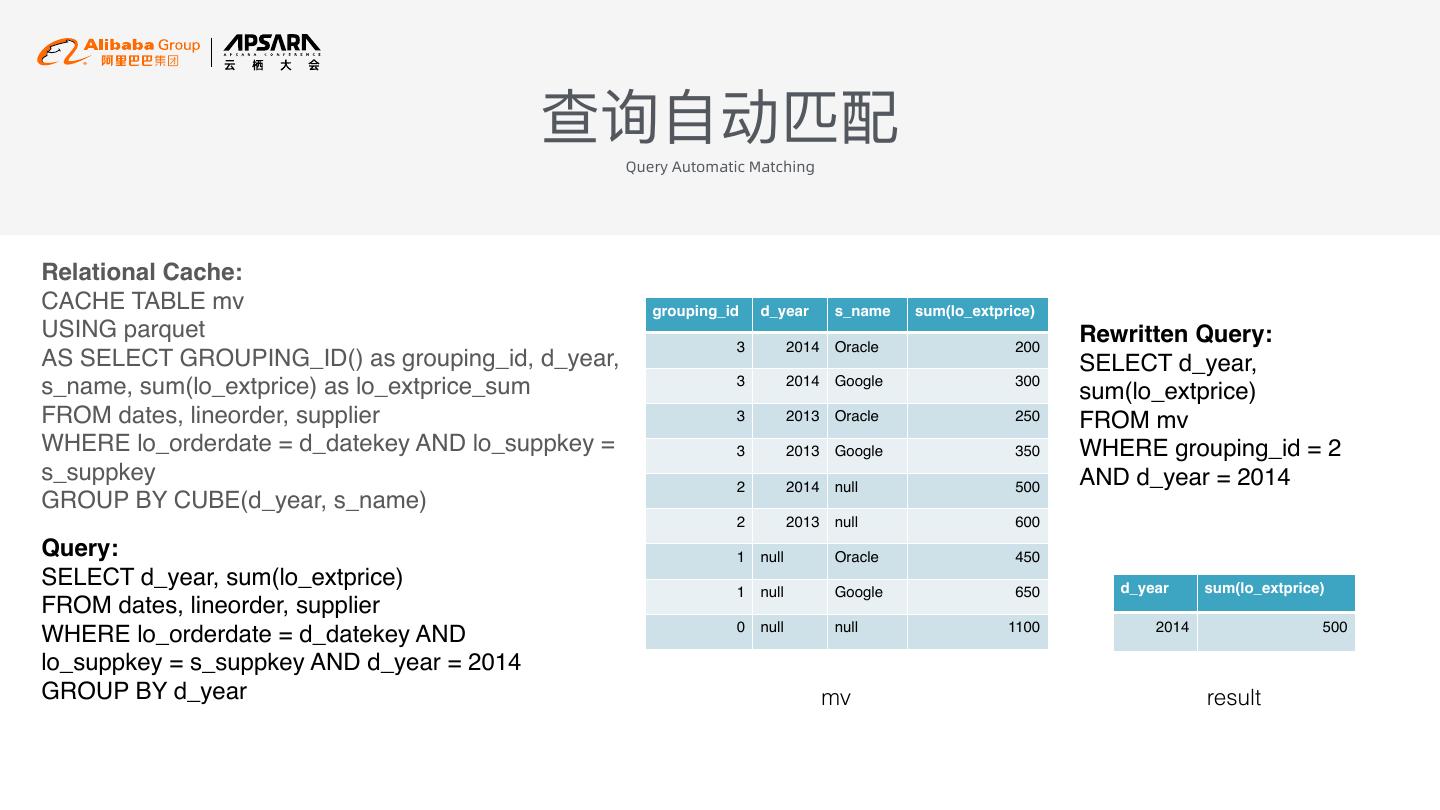
13 . 查询⾃自动匹配 Query Automatic Matching Relational Cache: CACHE TABLE mv grouping_id d_year s_name sum(lo_extprice) USING parquet Rewritten Query: 3 2014 Oracle 200 AS SELECT GROUPING_ID() as grouping_id, d_year, SELECT d_year, 3 2014 Google 300 s_name, sum(lo_extprice) as lo_extprice_sum sum(lo_extprice) FROM dates, lineorder, supplier 3 2013 Oracle 250 FROM mv WHERE lo_orderdate = d_datekey AND lo_suppkey = 3 2013 Google 350 WHERE grouping_id = 2 s_suppkey AND d_year = 2014 2 2014 null 500 GROUP BY CUBE(d_year, s_name) 2 2013 null 600 Query: 1 null Oracle 450 SELECT d_year, sum(lo_extprice) d_year sum(lo_extprice) 1 null Google 650 FROM dates, lineorder, supplier 0 null null 1100 2014 500 WHERE lo_orderdate = d_datekey AND lo_suppkey = s_suppkey AND d_year = 2014 GROUP BY d_year mv result
14 . 数据预组织 Data Layout 文件索引 列式存储 数据分区与ZOrder File Index Columnar Store Partitioning & Files 过滤所需读取的⽂文件总量量 ⾼高效压缩与⾼高效读取 Cube数据按Grouping进⾏行行分区 Filter files to load. Efficient Compression and loading ⼀一个分区内按ZOrder加强多列列过滤效果 Better filtering
15 .如何使⽤用 How to use Spark Relational Cache 03
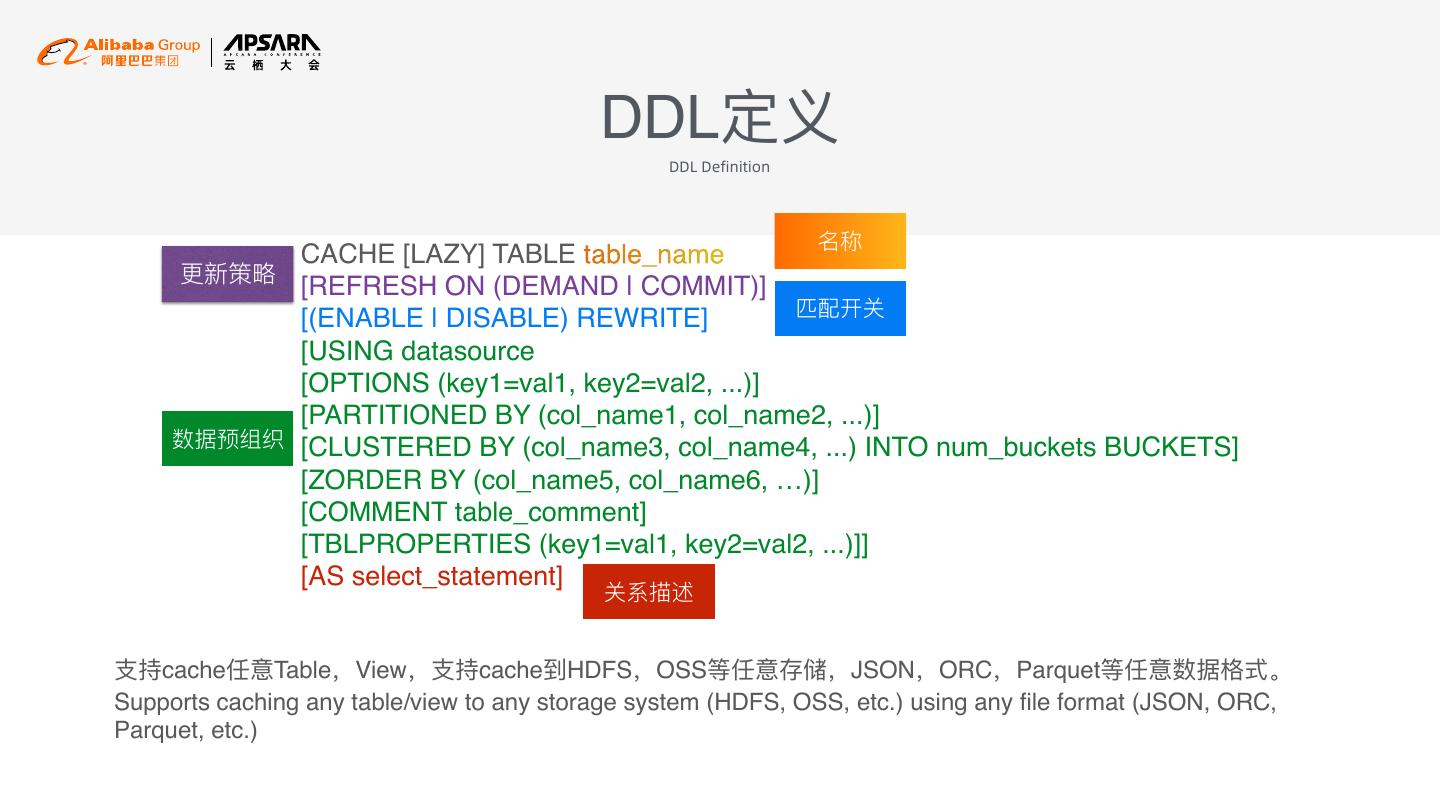
16 . DDL定义 DDL Definition 名称 CACHE [LAZY] TABLE table_name 更更新策略略 [REFRESH ON (DEMAND | COMMIT)] 匹配开关 [(ENABLE | DISABLE) REWRITE] [USING datasource [OPTIONS (key1=val1, key2=val2, ...)] [PARTITIONED BY (col_name1, col_name2, ...)] 数据预组织 [CLUSTERED BY (col_name3, col_name4, ...) INTO num_buckets BUCKETS] [ZORDER BY (col_name5, col_name6, …)] [COMMENT table_comment] [TBLPROPERTIES (key1=val1, key2=val2, ...)]] [AS select_statement] 关系描述 ⽀支持cache任意Table,View,⽀支持cache到HDFS,OSS等任意存储,JSON,ORC,Parquet等任意数据格式。 Supports caching any table/view to any storage system (HDFS, OSS, etc.) using any file format (JSON, ORC, Parquet, etc.)
17 . 数据更更新 Data Refresh Relational Cache ON COMMIT: 创建Cache时指定更更新策 基于数据分区进⾏行行增量量更更 当cache依赖的数据发⽣生更更 略略。 新。 新时,⾃自动更更新cache。 CRM Specify refresh strategy Incremental updating based Triggered when data inserts. when creating cache. on partitions. ON DEMAND(default): 可以通过ALTER命令修改 通过指令⼿手动更更新特定分 ⽤用户通过REFRESH命令⼿手 更更新策略略。 区。 动触发更更新。 Use ALTER command to DDL to trigger refresh of Triggered by user DDL. modify refresh strategy. certain partitions.
18 .性能分析 Performance Analysis 04
19 .Star Schema Benchmark 星型模型·Star-Schema 专为数据仓库设计 Designed for data warehouse 基于TPC-H·Based on TPC-H 根据TPC-H数据模型修改⽽而来 Modified based on TPC-H 测试环境·Test Spec 1 master w/ 6 slave nodes(32 cores + 256GB RAM(ecs.i2.8xlarge)) 云盘Cloud SSD 1788GB * 4
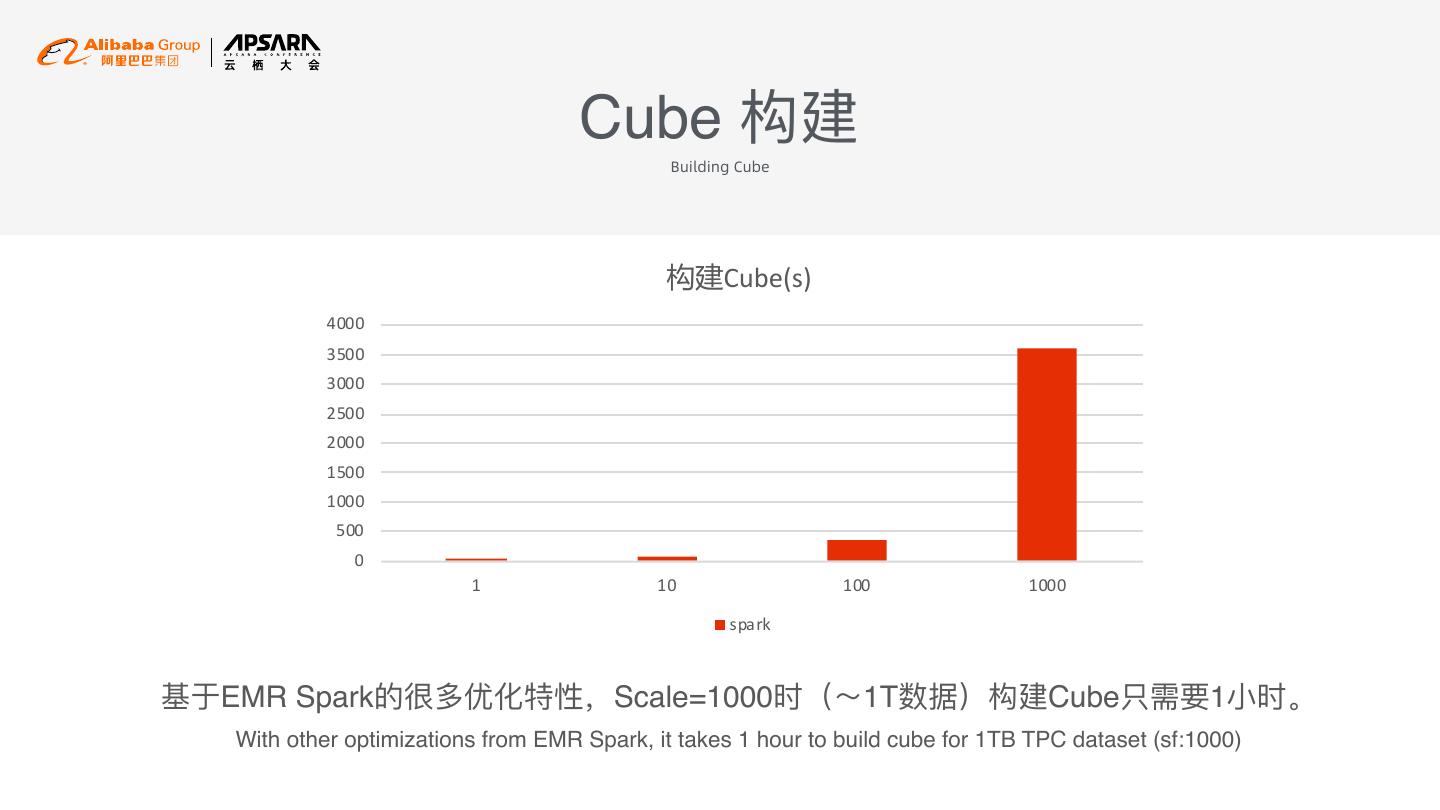
20 . Cube 构建 Building Cube Cube(s) 4000 3500 3000 2500 2000 1500 1000 500 0 1 10 100 1000 spark 基于EMR Spark的很多优化特性,Scale=1000时(~1T数据)构建Cube只需要1⼩小时。 With other optimizations from EMR Spark, it takes 1 hour to build cube for 1TB TPC dataset (sf:1000)
21 . 查询性能⽐比较 Query Time Comparison Cache vs No Cache(ms) Lower is better 262144 250 Cache数据以Parquet格式存储在 65536 HDFS上。 16384 200 Data is Cached on EMR HDFS using Parquet. 4096 SSB平均查询耗时,⽆无cache时查询 150 1024 256 时间按scale成⽐比例例增加,cache 100 64 cube后始终保持在亚秒级响应。 16 50 The chart shows average time of all queries 4 from SSB. Query latency in sub-second level. 1 Cached(ms) No Cache(ms) Speedup 0 2 20 40 200 1000
22 .THANKS !
7点赞
2收藏
3秒后跳转登录页面
去登陆

