展开查看详情
1 .基于Spark实现的MLSQL
如何帮助企业构建数据中台
MLSQL Stack 系列
�
2 . 分享内容
Stage1:数据中台和架构 Stage2: MLSQL Stack Stage3: 核心技术点解析
• MLSQL Stack 架构 • 如何扩展Spark SQL使其成为
• 数据中台定义 一个数据/AI语言
• 数据中台架构 • 多租户
• 实现对各种数据源譬如
• 数据中台职责 • 权限 HDFS/ES/MySQL/MongoDB
等细化到列的权限控制
• 弹性资源
• 构建二层RPC通讯强化对
• 多数据源支持 Executor的控制,实现对机
器学习更好的支持。
• python/java/scala 动态支持
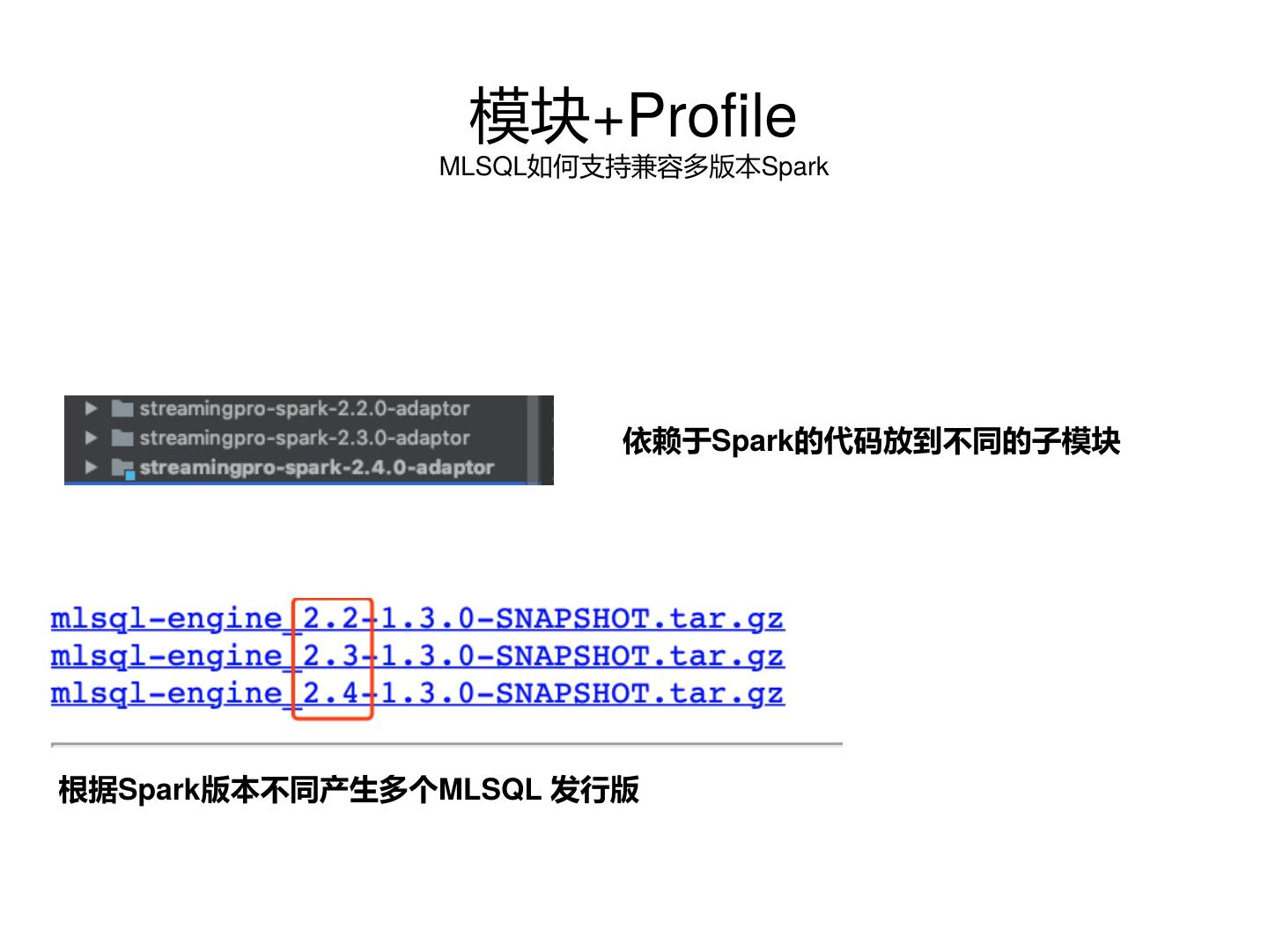
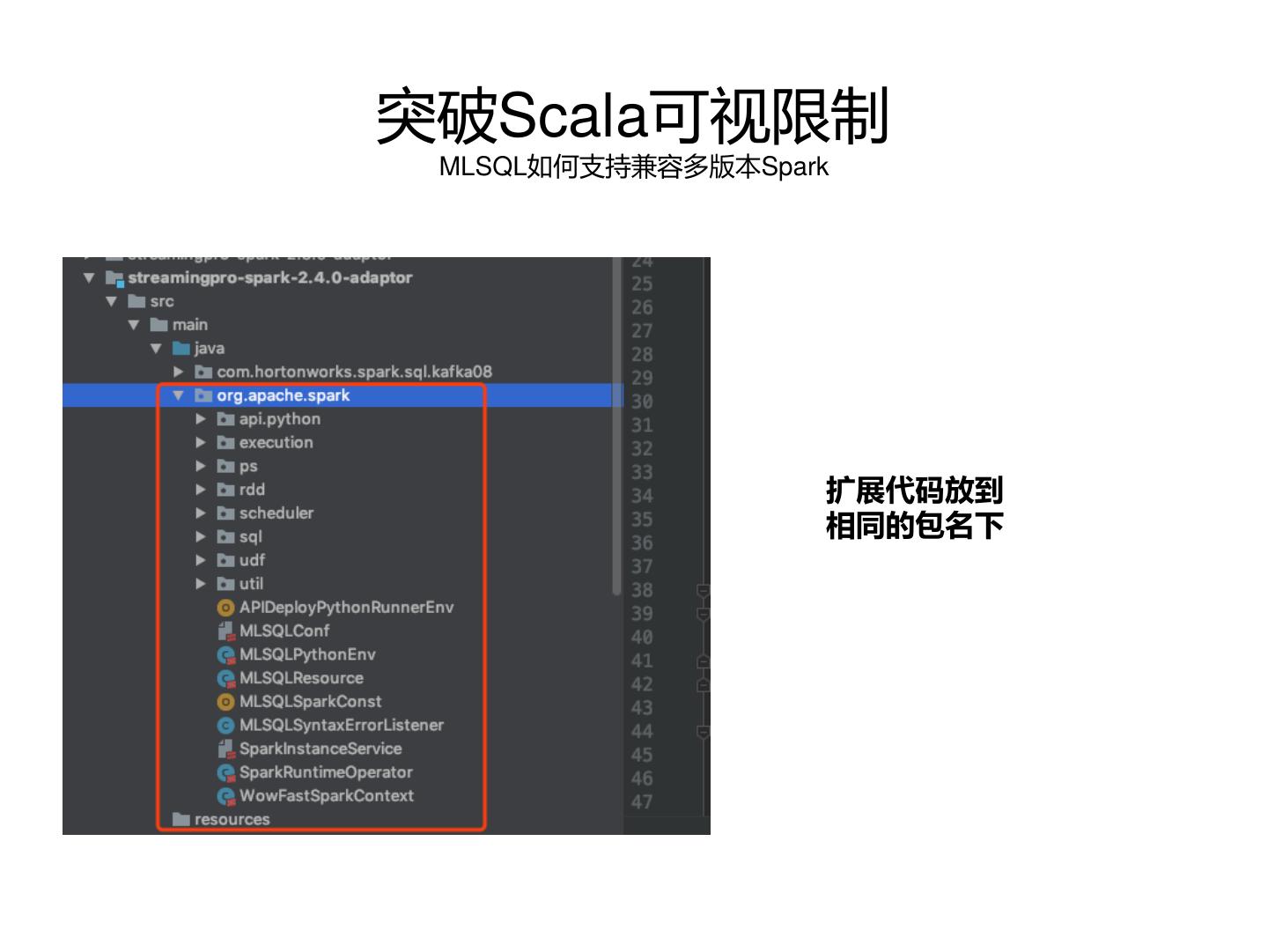
• 兼容多版本Spark经验
• 工程化与语法糖
• 如何避免机器学习中预测阶
段无法复用训练时的代码和
• 扩展接口
数据
• 流支持、机器学习支持
• Delta 相关
• 日志回显,表缓存,爬虫…
�
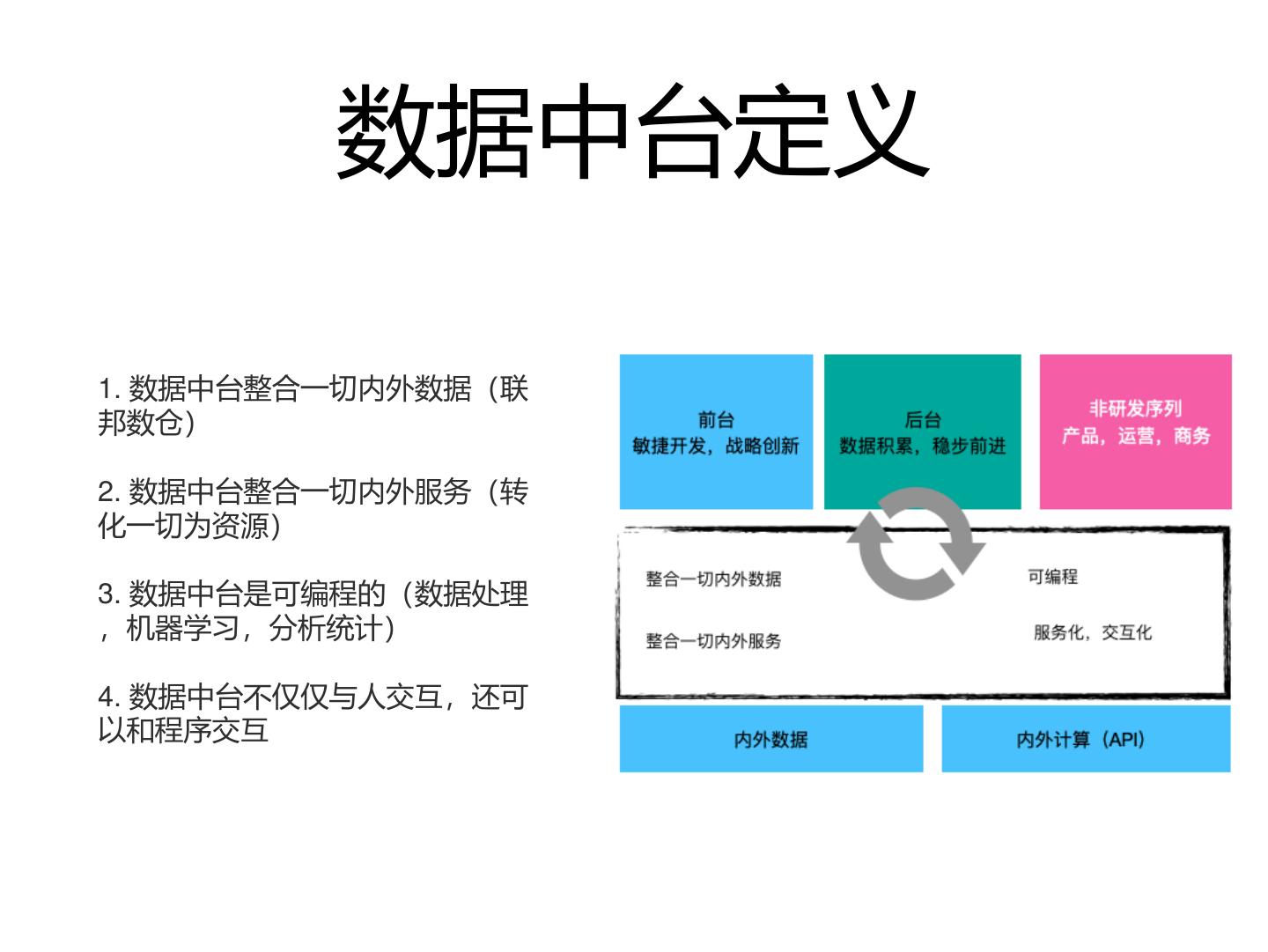
4 . 数据中台定义
1. 数据中台整合一切内外数据(联
邦数仓)
2. 数据中台整合一切内外服务(转
化一切为资源)
3. 数据中台是可编程的(数据处理
,机器学习,分析统计)
4. 数据中台不仅仅与人交互,还可
以和程序交互
�
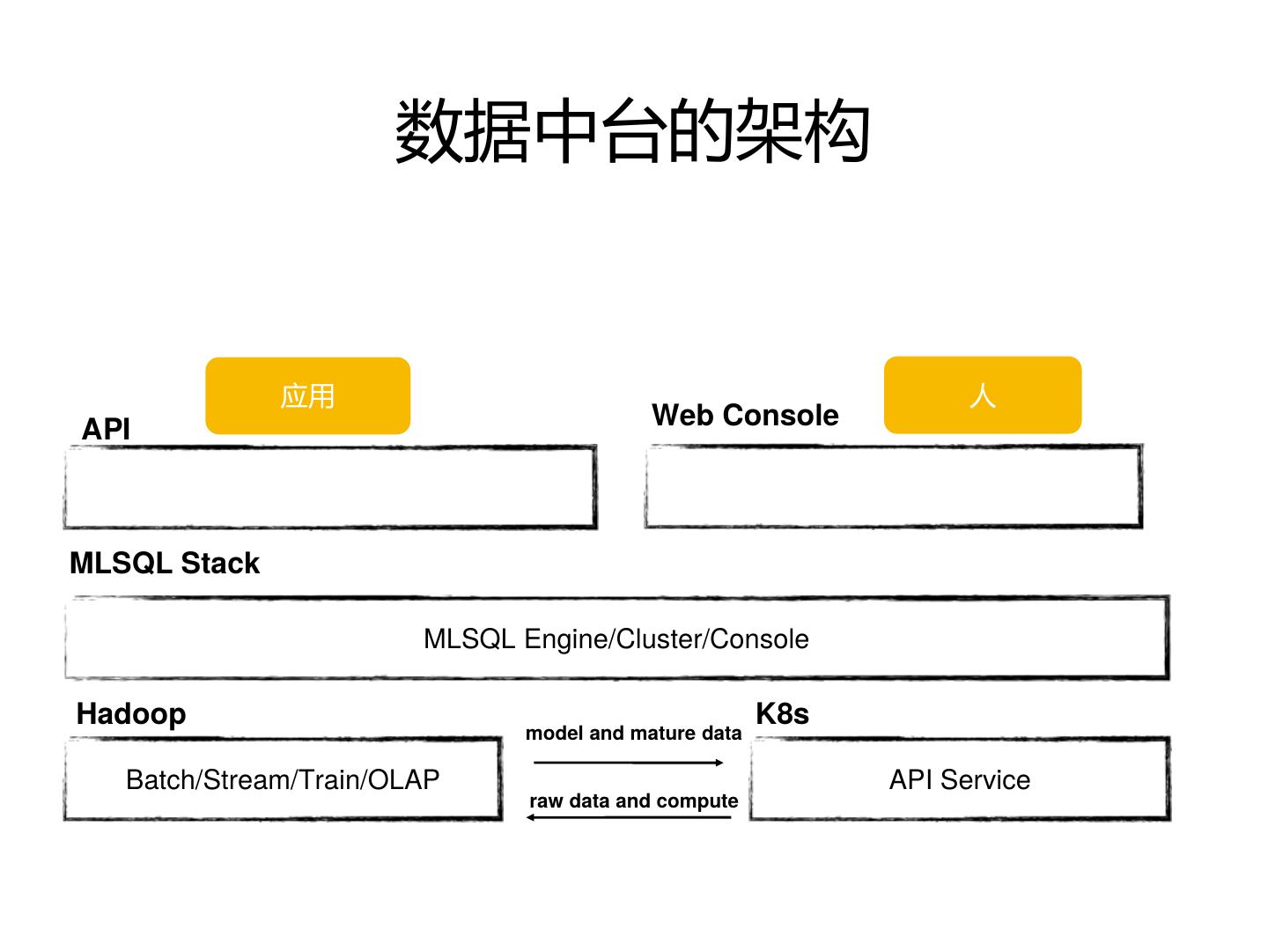
5 . 数据中台的架构
应用 人
API Web Console
MLSQL Stack
MLSQL Engine/Cluster/Console
Hadoop K8s
model and mature data
Batch/Stream/Train/OLAP API Service
raw data and compute
�
6 . (MLSQL)数据中台的大饼
• 报表平台
• 自由的探索数据(OLAP)
• 复用企业现有资产(组合一切现有接口完成新的业务逻辑)
• 所写即所得(无需资源申请,编译,上传等)
• 完整算法Pipline(实现数据获取,处理,特征化,训练,部署API全套)
• 所有成果易于发布(部署成API,注册成函数供流,批使用)
• 研发,算法,分析师,产品,运营等人群的数据工作台
�
7 .Stage2: MLSQL Stack 介绍
�
11 . MLSQL Stack项目
• 开发时间 >= 3年
• 完全开源,Apache-2.0协议
• 17名contributor, Start数> 900 && Fork > 300
• 最新Release 1.2.0, 六月份准备Release 1.3.0
• > 2400 Commits && > 700 PRs
• 很多公司已经应用于生产中,不少大公司也在调研中
�
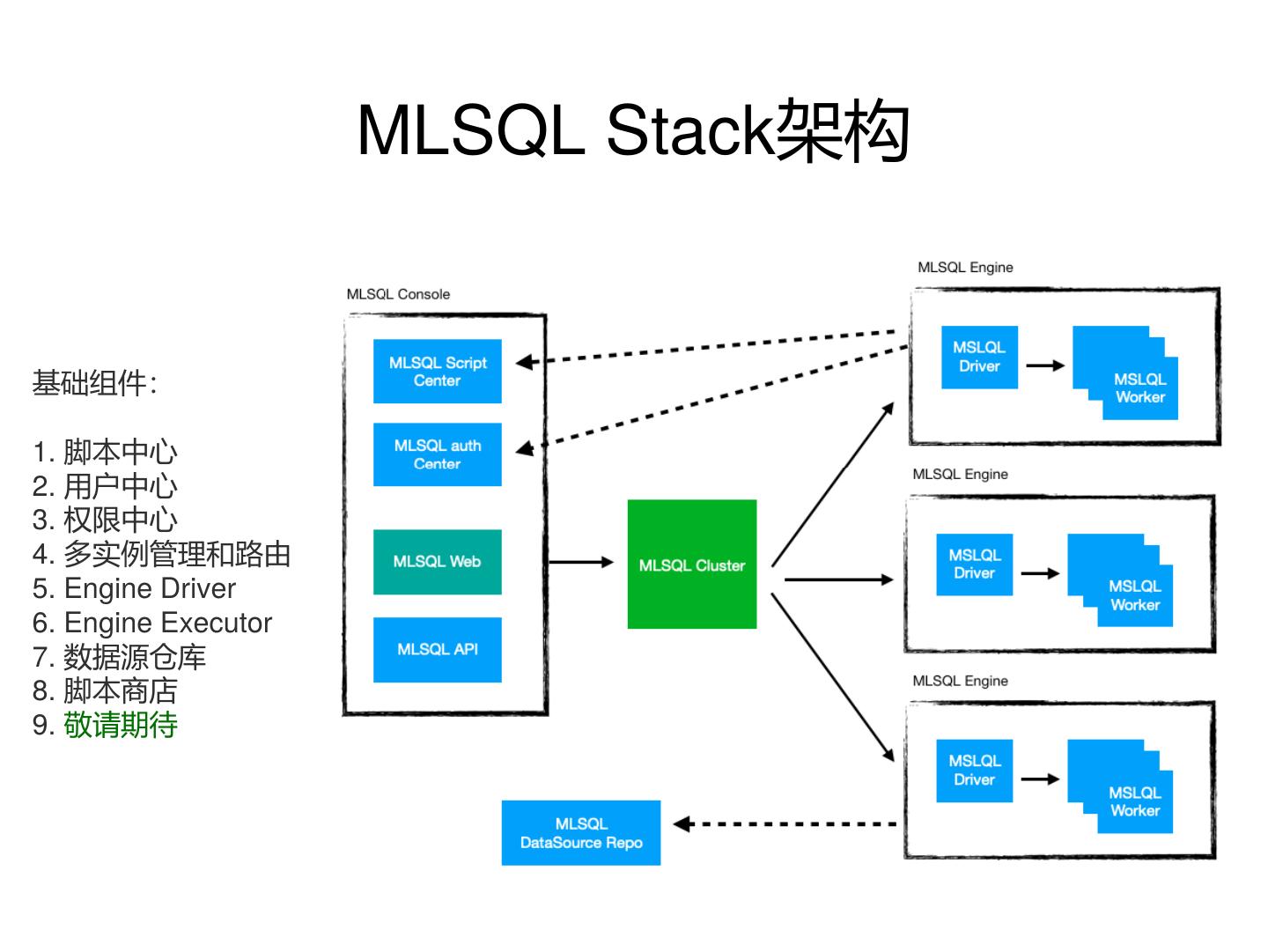
12 . MLSQL Stack架构
基础组件:
1. 脚本中心
2. 用户中心
3. 权限中心
4. 多实例管理和路由
5. Engine Driver
6. Engine Executor
7. 数据源仓库
8. 脚本商店
9. 敬请期待
�
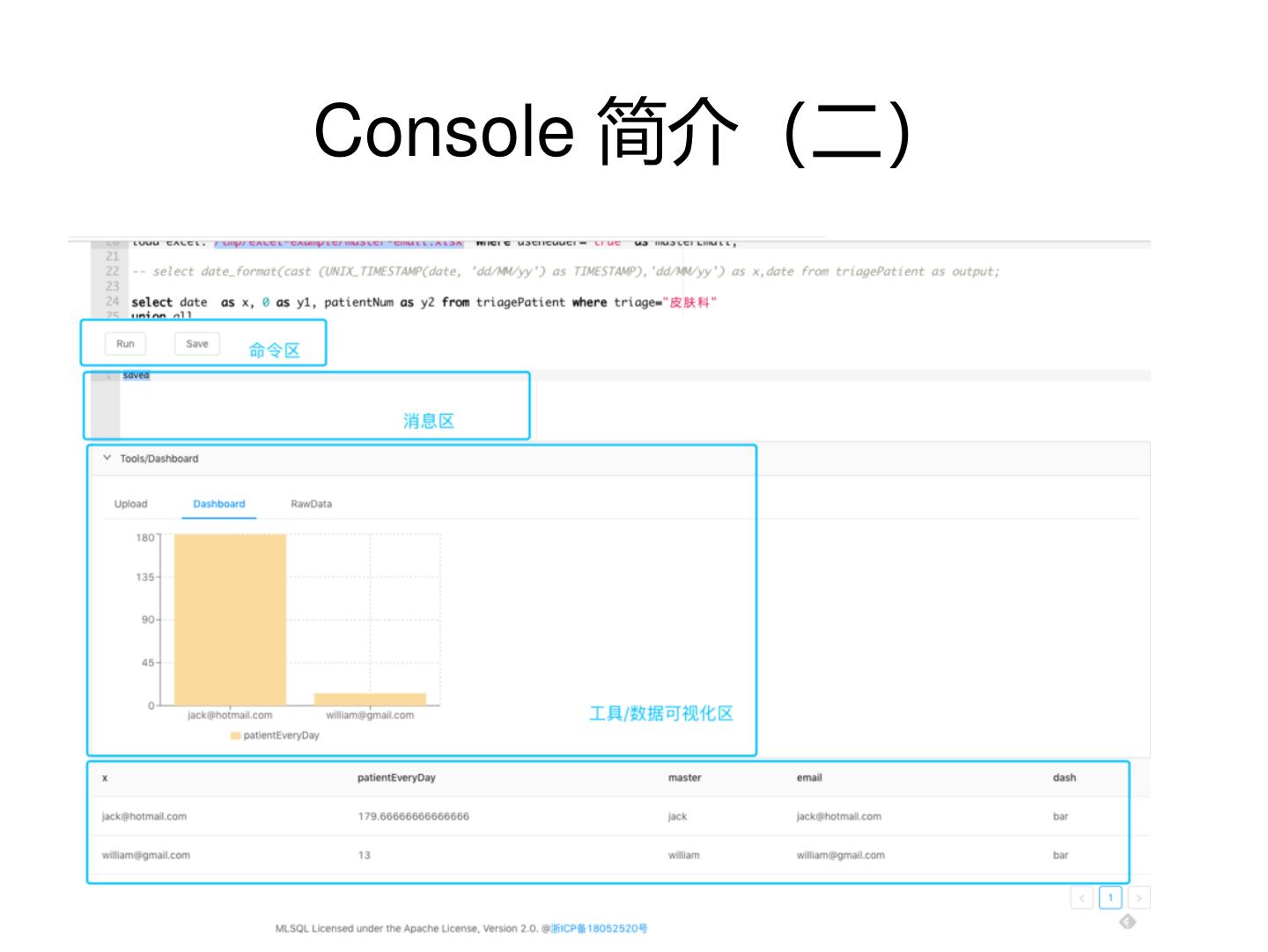
13 . MLSQL Stack工作原理
• 利用MLSQL Console,用户编写MLSQL脚本
• 脚本会被Cluster发送到最优的Engine执行
• Engine返回结果给用户
�
14 . 多租户
• 表、变量隔离(支持session/request两种模式)
• HDFS隔离、管理(主目录)
• 自主任务管理
�
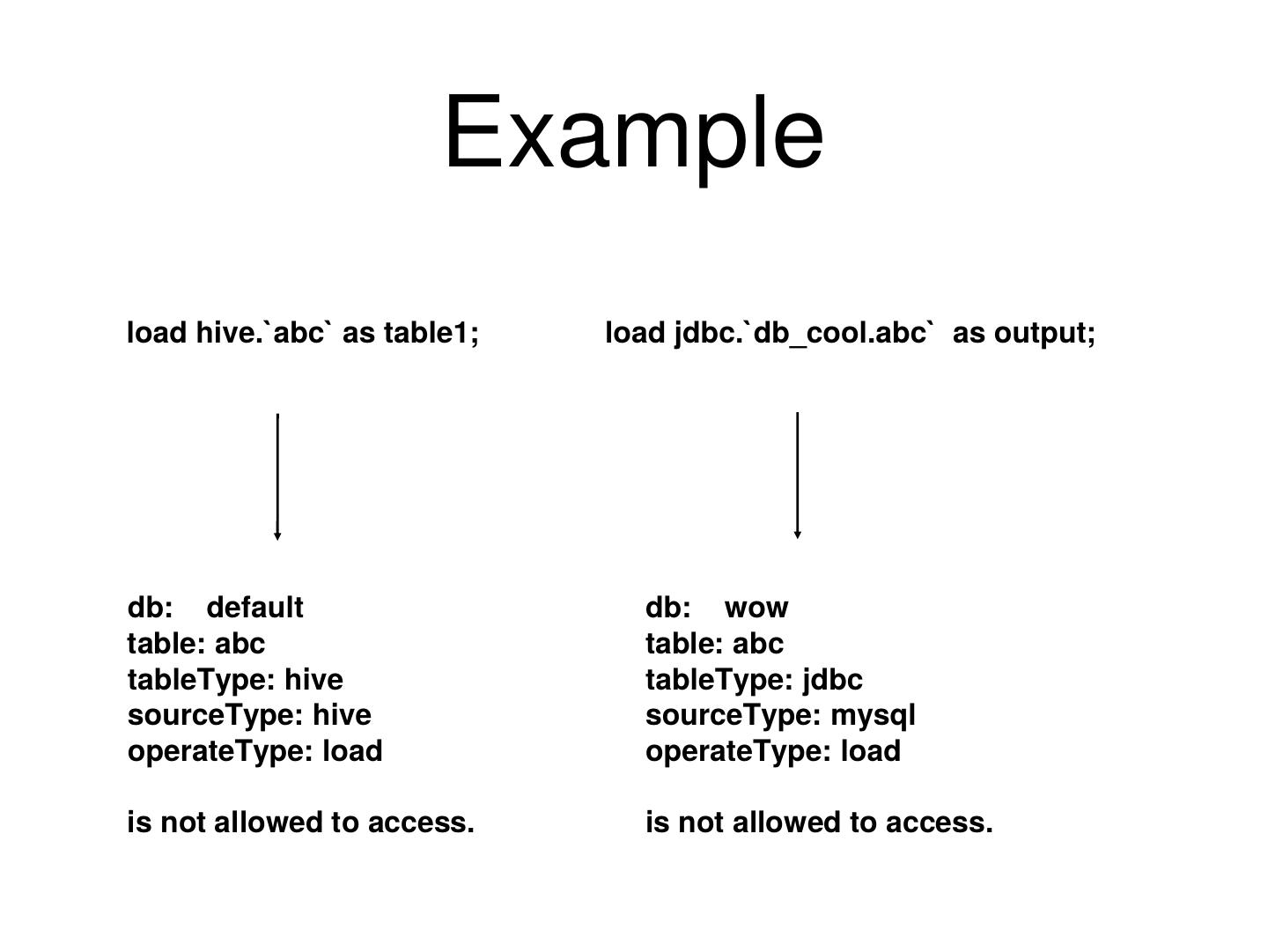
15 . 权限
• 支持MLSQL所有支持的数据源
• 支持不同操作类型,粒度为库,表,列
• 支持用户自定义权限逻辑
• 完整用户,团队,角色,表概念
• 后面我们详细讨论权限的设计
�
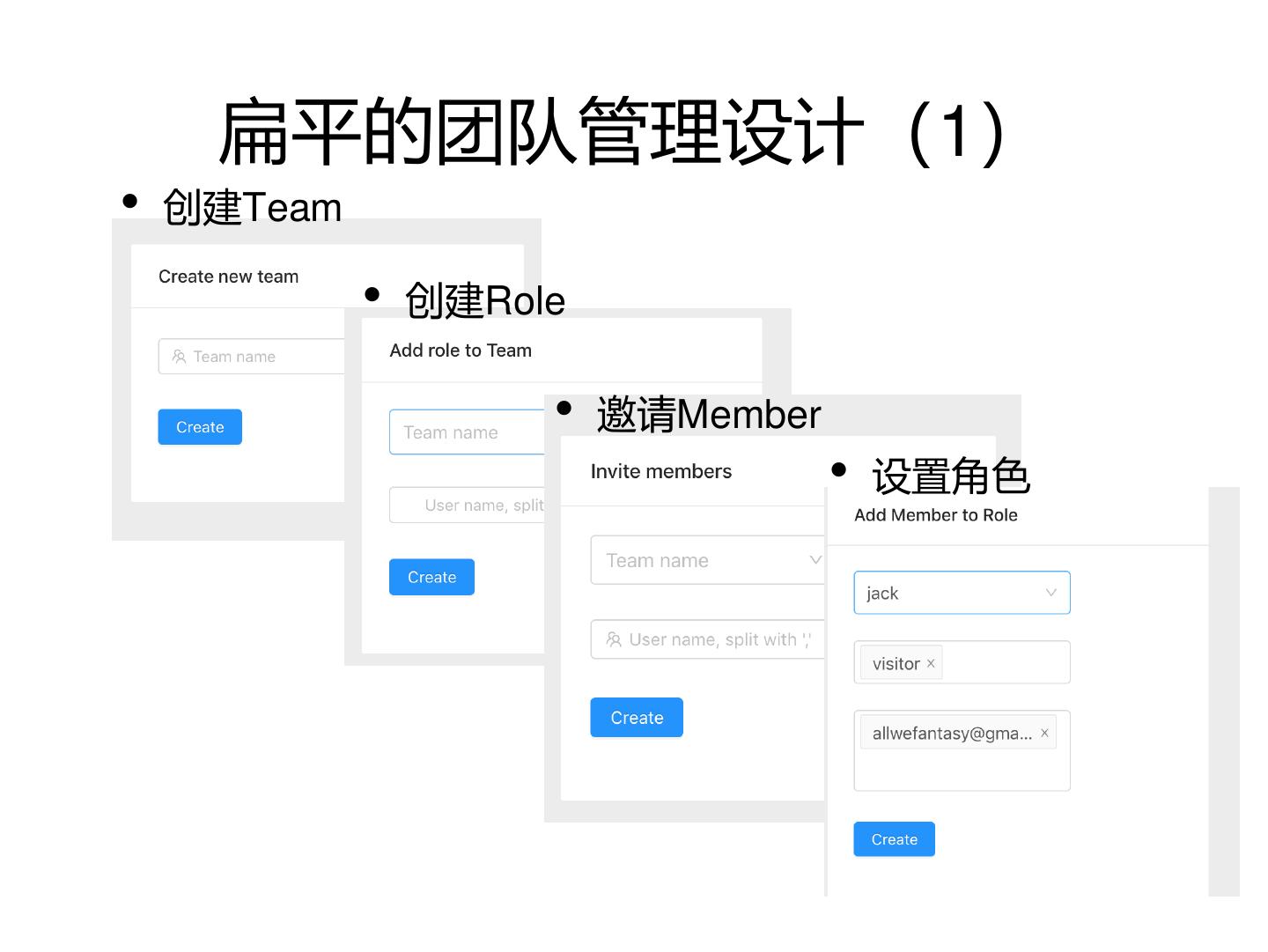
16 . 扁平的团队管理设计(1)
• 创建Team
• 创建Role
• 邀请Member
• 设置角色
�
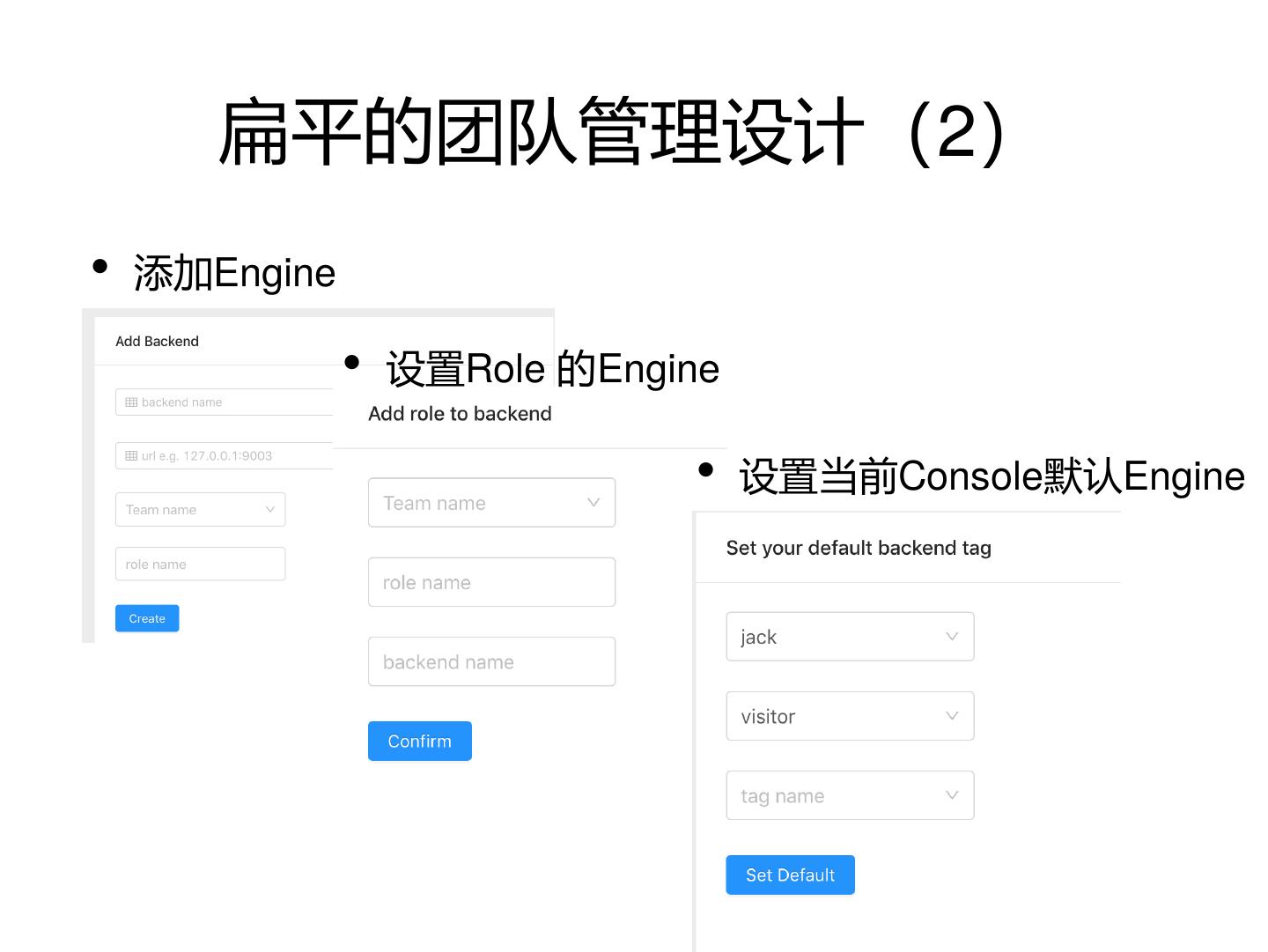
17 . 扁平的团队管理设计(2)
• 添加Engine
• 设置Role 的Engine
• 设置当前Console默认Engine
�
18 . 弹性资源
• MLSQL Stack 支持Mesos/Yarn/K8s/Local/Standalone多种
模式
• MLSQL Stack 支持多Engine实例管理(增加删以及路由策
略)
• 单个Engine实例可动态调整资源(Yarn/K8s/Mesos)
�
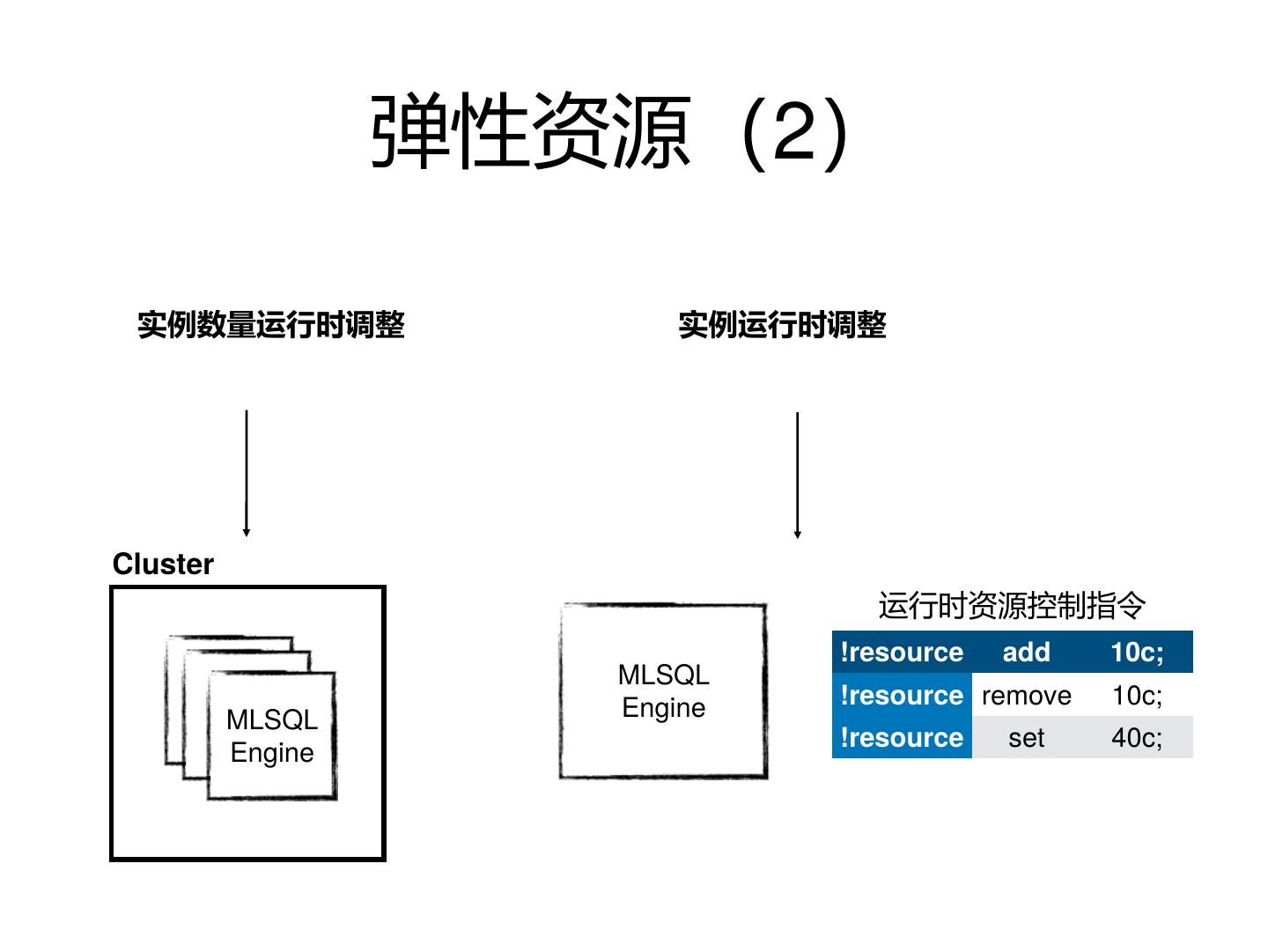
19 . 弹性资源(2)
实例数量运行时调整 实例运行时调整
Cluster
运行时资源控制指令
!resource add 10c;
MLSQL
Engine !resource remove 10c;
MLSQL
!resource set 40c;
Engine
�
20 . 多数据源支持
• 各种支持JDBC协议的数据库,Oracle,MySQL等
• 各种有Spark原生适配数据库,比如ES, Solr,MongoDB等
• HDFS各种格式类型,比如Parquet,CSV,Excel等等
• directQuery支持(同样支持到列权限),让联邦数仓更高
效
• Delta/Rate
�
21 .多语言UDF支持
• Python/Scala/Java 三种
语言
• 无需编译部署
�
22 .项目化支持
支持脚本互相包含
支持脚本封装
�
23 . 良好的扩展性
• 用户可自定义数据源、权限
• 用户可自定义ET模块,并且可以封装成命令
• 用户可扩展UDF支持的语言种类
�
25 . 流/机器学习
• 都是MLSQL语法
• 流批基本无差别
• 机器学习支持Python框架集成,支持Spark内置算法,支持
外部算法框架如BigDL等
• 支持无编码实现预测API部署(后续探讨实现细节)
�
27 . 如何扩展Spark SQL使其成为一个数据
/AI语言
• 脚本化(一切都通过表来连接)
• 使用load/save简化如insert into
操作
• 新增train/predict/register 机器
学习相关语法
• include/! 实现脚本复用 (!hdfs
-ls /tmp)
• 支持python/scala/java UDF 以
及Python脚本
�
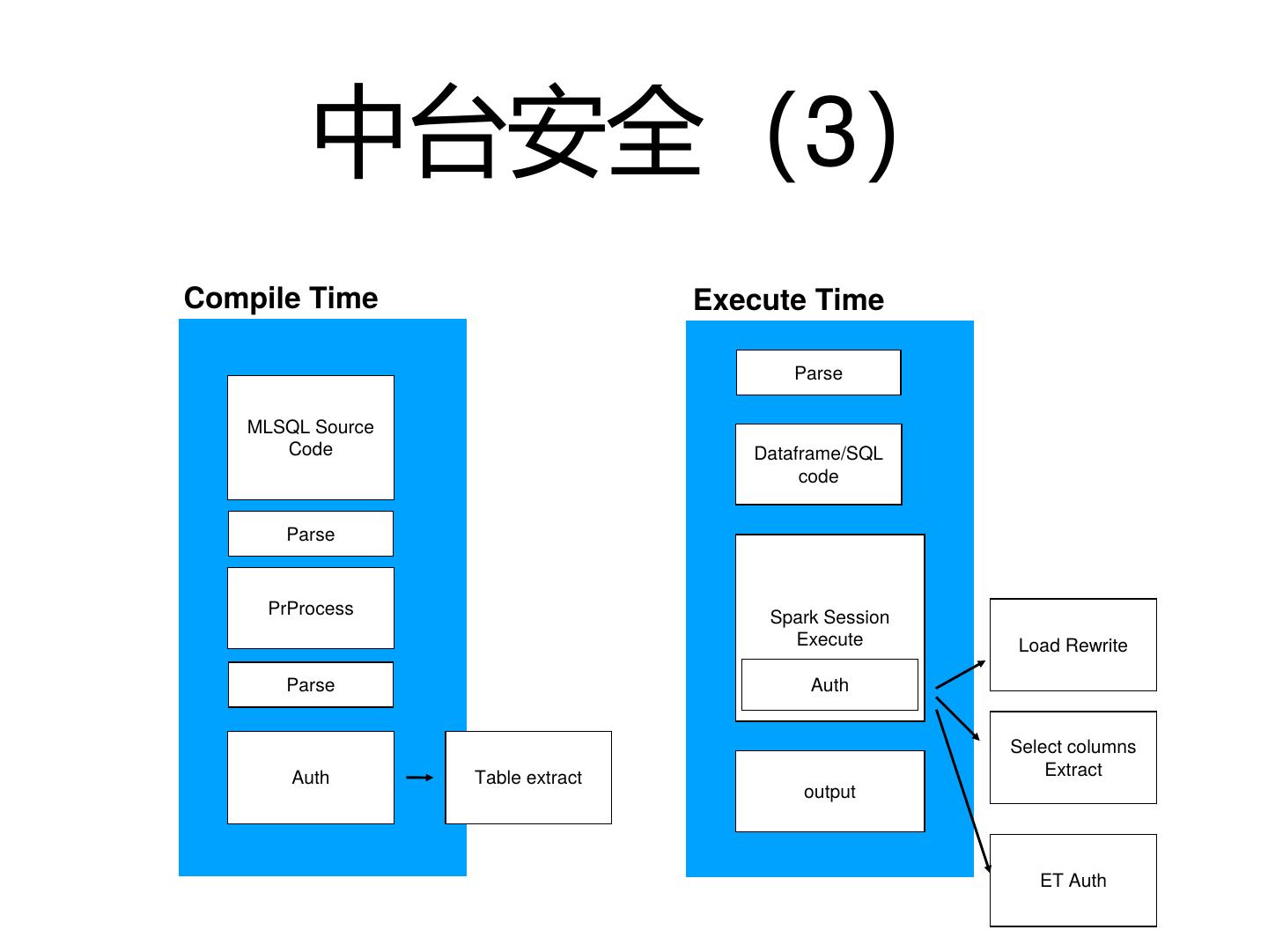
28 . MLSQL解析流程
• Antlrv4 做语法解析
• 预处理器(包括include展开,
变量生成,宏展开,语法检查)
• 权限检查(编译时权限)
• 物理执行(翻译成Spark代码,
运行时权限校验)
�
29 . 中台安全
• 中台暴露一切数据 如何保证安全
• 中台暴露一切服务
• 中台暴露一切计算
�