【数据湖JindoFS+OSS 实操干货36讲】第3/4讲
分享
点赞
0
收藏
0
下载 0
-
快召唤伙伴们来围观吧
-
微博
QQ
QQ空间
贴吧
-
视频嵌入链接
文档嵌入链接
- 复制
-
-
微信扫一扫分享
-
已成功复制到剪贴板
概念简述
JindoFS 作为阿里云基于 OSS 的一揽子数据湖存储优化方案,完全兼容 Hadoop/Spark 生态,并针对 Spark、Hive、Flink、Presto 等大数据组件和 AI 生态实现了大量扩展和优化。
JindoFS 项目包括 JindoFS OSS 支持、JindoFS 分布式缓存系统(JindoFS Cache 模式)和 JindoFS 分布式存储优化系统(JindoFS Block 模式)。
JindoSDK 是各个计算组件可以用来使用JindoFS 这些优化扩展功能和模式的套件,包括 Hadoop Java SDK、Python SDK 和 Fuse/POSIX 支持。JindoSDK 在阿里云 E-MapReduce 产品中被深度集成,同时也开放给非 EMR 产品用户在各种 Hadoop/Spark 环境上使用。
GitHub 地址:
https://github.com/aliyun/alibabacloud-jindofs
课程背景
为了让更多开发者了解并使用 JindoFS,由阿里云 JindoFS+OSS 团队打造的专业公开课【数据湖 JindoFS+OSS 实操干货36讲】会在每周二16:00准时开讲!从五大板块入手,玩转数据湖!
本期主题:
1、如何将 HDFS 数据归档到 OSS
2、如何将 Hive 数据按分区归档到 OSS
主讲人:
辰石 - 阿里巴巴计算平台事业部 EMR 技术专家
健身 - 阿里巴巴计算平台事业部 EMR 技术专家
展开查看详情
12 . | E-MapReduce | 对象存储OSS
数据湖 JindoFS + OSS 实操36讲
【数据迁移】如何将 Hive 数据按分区归档到 OSS
演讲人:健身
阿里巴巴计算平台事业部 EMR 技术专家
2021.05.18
�
13 . 背景介绍
功能介绍
CONTENT
实现原理
使用示例
�
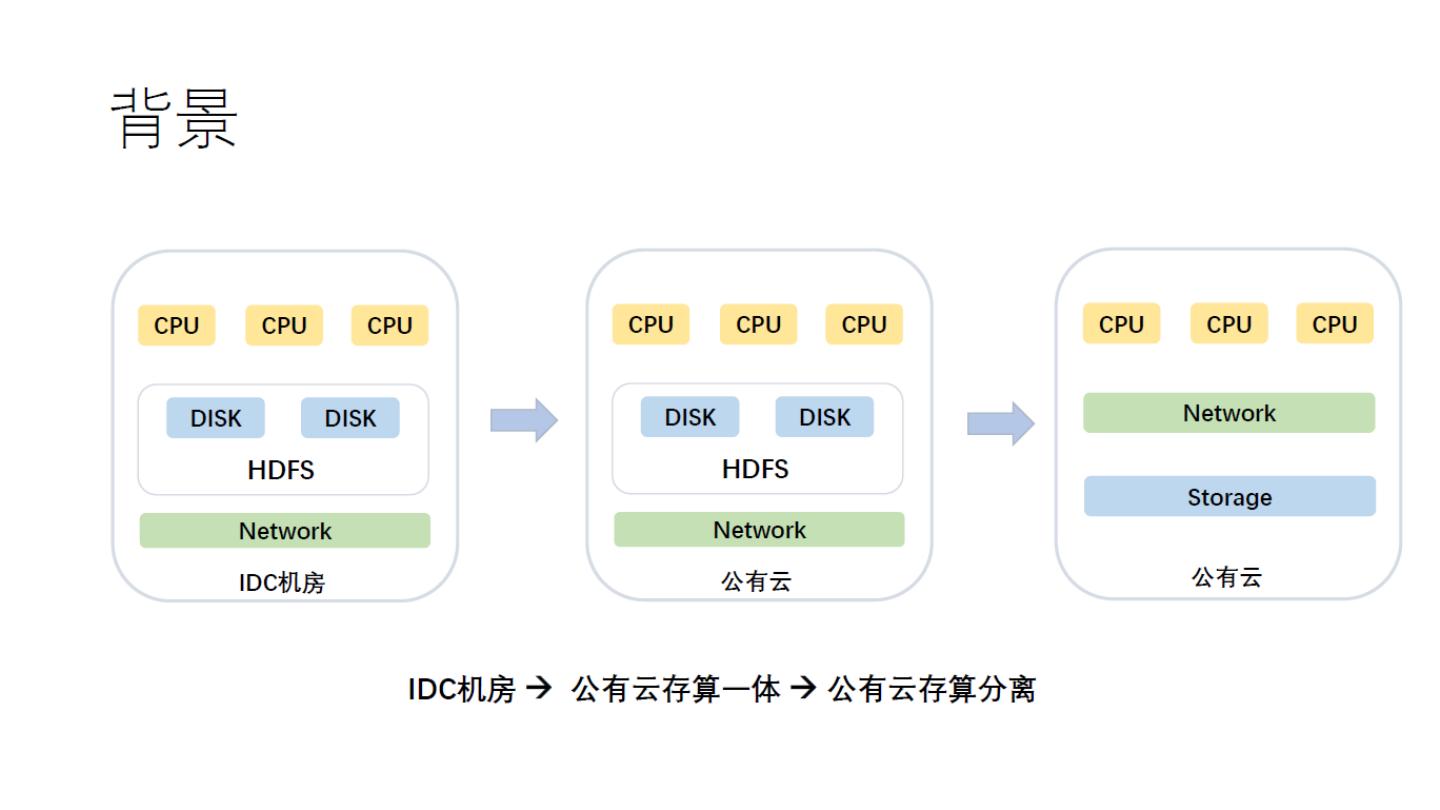
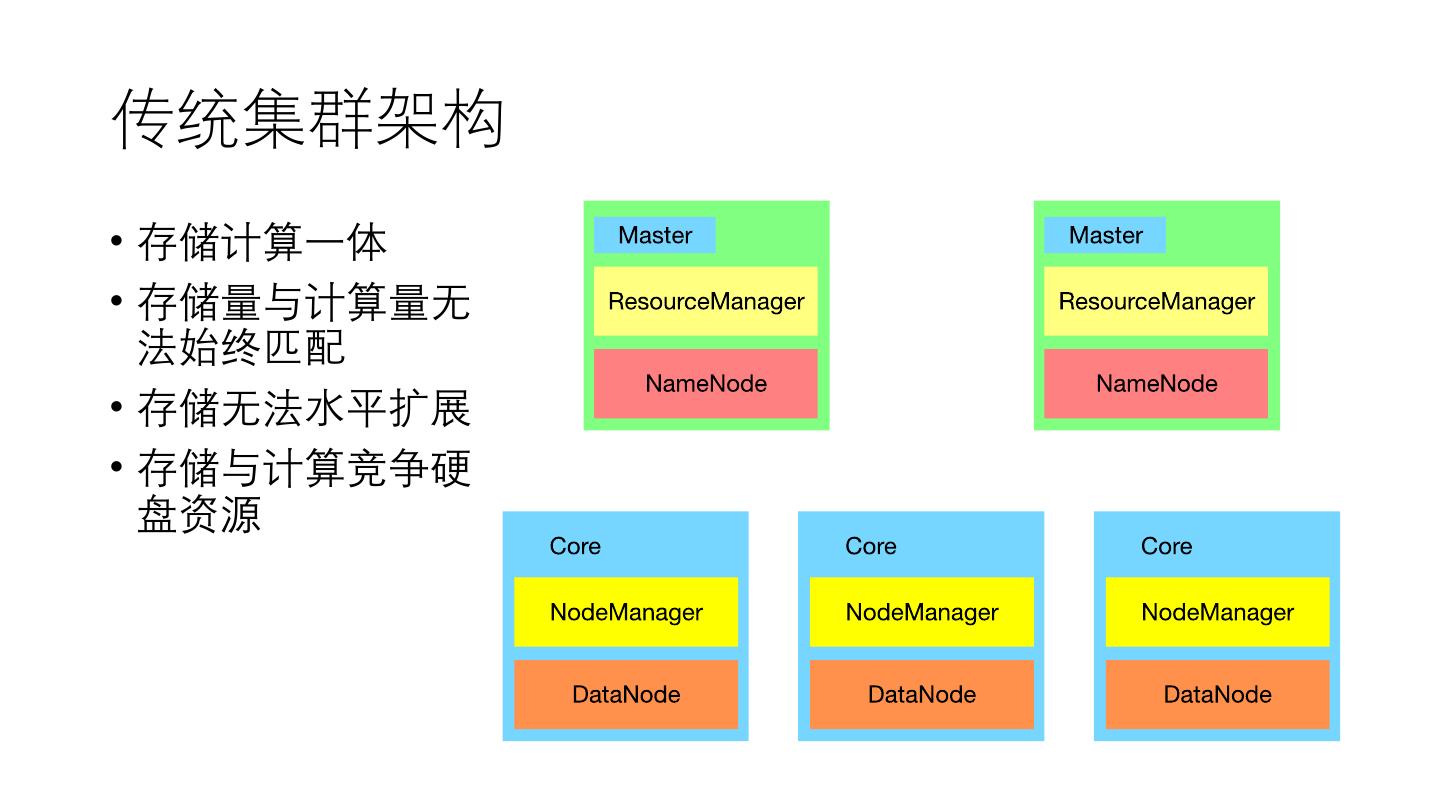
14 .传统集群架构
• 存储计算一体
• 存储量与计算量无
法始终匹配
• 存储无法水平扩展
• 存储与计算竞争硬
盘资源
�
15 .存储分层架构
• 计算资源动态伸缩
• 存储资源使用云存储作为HDFS的替代或补充
• 相比存算分离架构,对于已有 HDFS 数据比较平滑,可以逐渐过
渡到存算分离架构
存算分离
存储分层
�
16 .数据仓库
• 数据仓库是大数据的典型场景
• 每天的 ETL 作业新增大量数据
• Hive 支持分区表,使用分区可以快速裁剪数据
• Hive 数仓中大量 Hive 表以时间日期作为分区字段
• 在数仓中很多表的较老的日期分区平常一般不会被访问,可以考
虑把这部分数据移出 HDFS
• Hive 的每个分区都有自己的 storage descriptor,可以有单独的存
储路径
�
17 .分区表的结构
• partitioned_table_xx
• dt=2021-05-16/category=1/
• dt=2021-05-16/category=2/
• dt=2021-05-16/category=5/
• dt=2021-05-16/category=8/
• dt=2021-05-15/category=2/
• dt=2021-05-15/category=3/
• dt=2021-05-15/category=4/
• ……
�
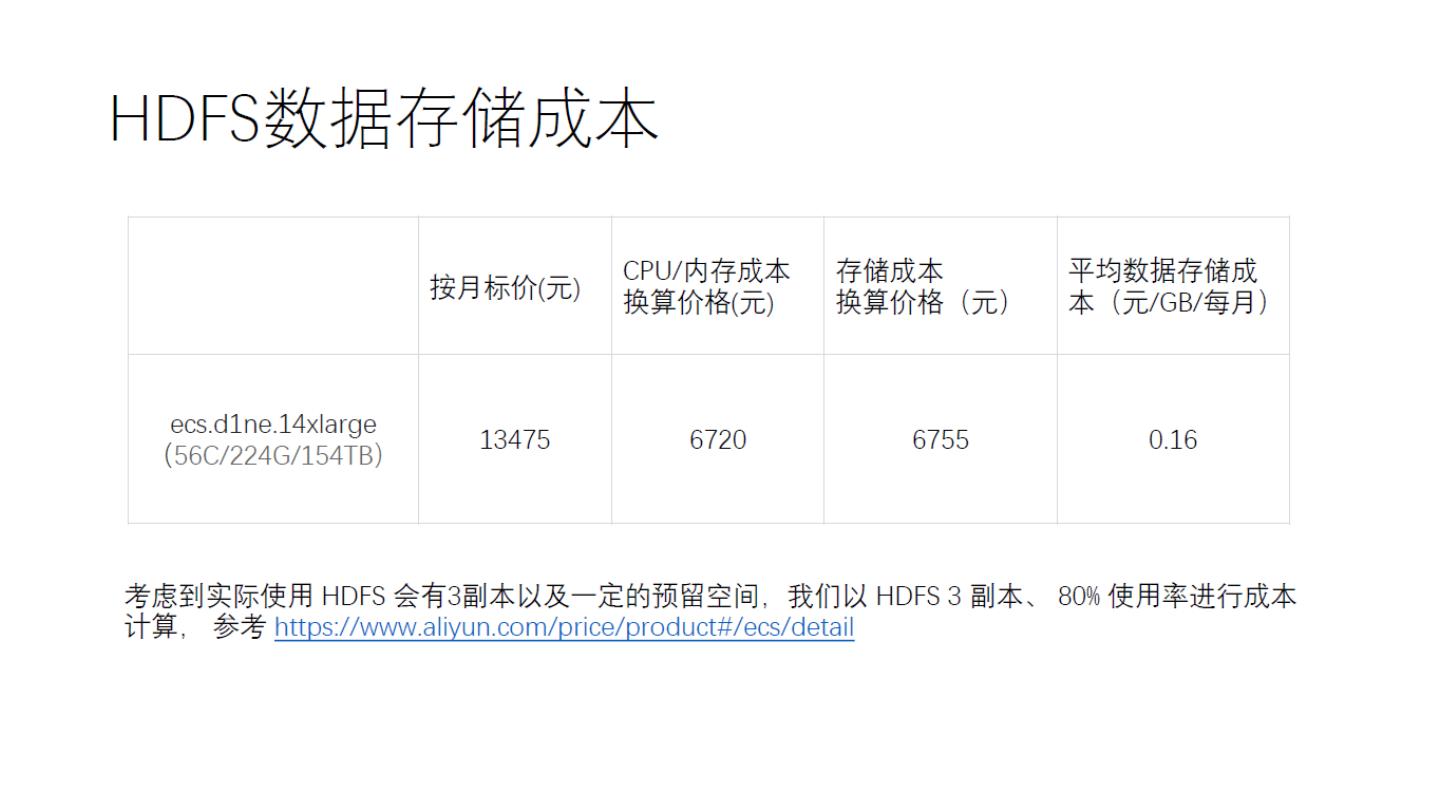
18 .使用 JindoTable 按分区归档数据
• 在本地盘机型上,HDFS 可以提供较好的性能,对集群已有存储
空间也能较好利用
• 一般情况下用不到的数据移动到 OSS,释放集群存储空间,减小
NameNode 压力
• 需要读取这部分数据时,也可以直接从 OSS 读取,不影响上层作
业
• 每天 ETL 完成后可以移动数据
• https://github.com/aliyun/alibabacloud-
jindofs/blob/master/docs/tools/table_moveto.md
�
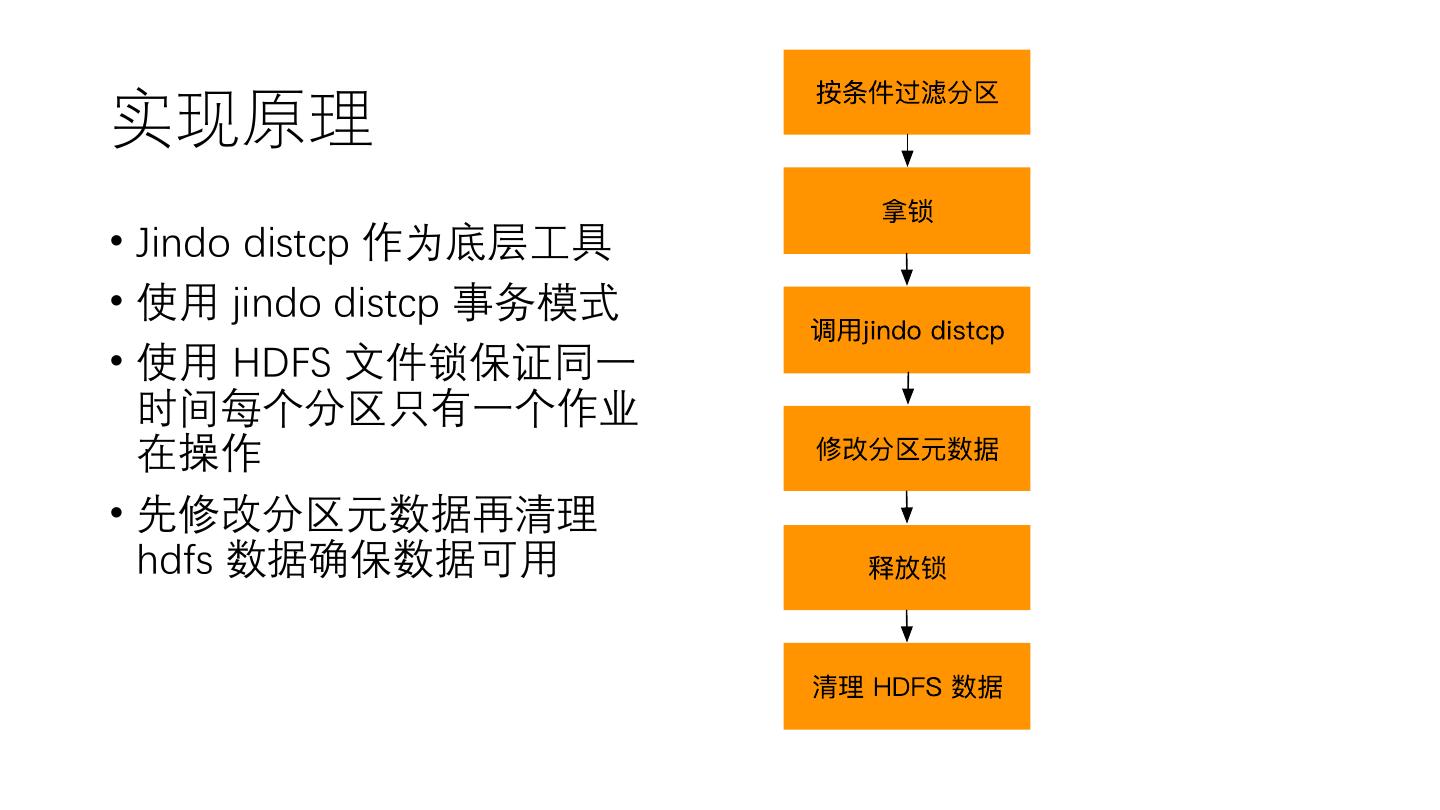
19 .实现原理
• Jindo distcp 作为底层工具
• 使用 jindo distcp 事务模式
• 使用 HDFS 文件锁保证同一
时间每个分区只有一个作业
在操作
• 先修改分区元数据再清理
hdfs 数据确保数据可用
�
20 .使用示例
jindo table -moveTo -t <dbName.tableName> -d <destination path> [-c "<condition>" | -
fullTable] [-b/-before <before days>] [-p/-parallel <parallelism>] [-o/-overWrite] [-r/-
removeSource] [-e/-explain] [-l/-logDir <log directory>]
参数 说明
<dbName.tableName> 要移动的表。
<destination path> 目标路径,为表级别的路径,分区路径会在这个路径下自动创建。
<condition> 分区过滤条件表达式,支持基本运算符,不支持udf。
<before days> 根据分区创建时间,创建时间超过给定天数的分区进行移动。
<parallelism> 整个moveTo任务的最大task并发度,默认为1。
-o/-overWrite 是否覆盖最终目录。分区级别覆盖,不会覆盖本次移动不涉及的分区。
-r/-removeSource 是否在移动完成后删除源路径。
<log directory> 本地日志目录,默认为/tmp/<current user>/
-e/-explain 如果指定explain模式,不会触发实际操作,仅打印会同步的分区。
�
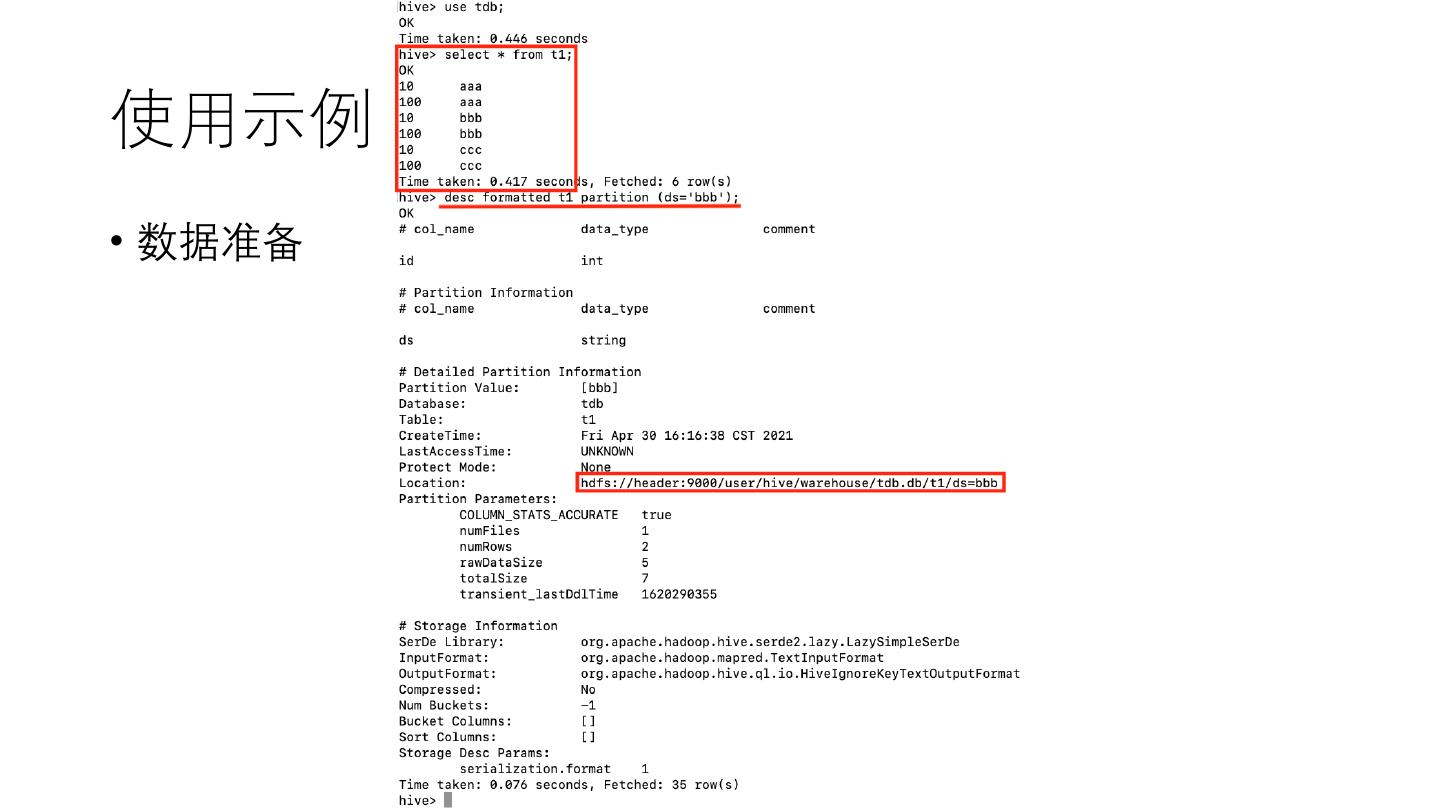
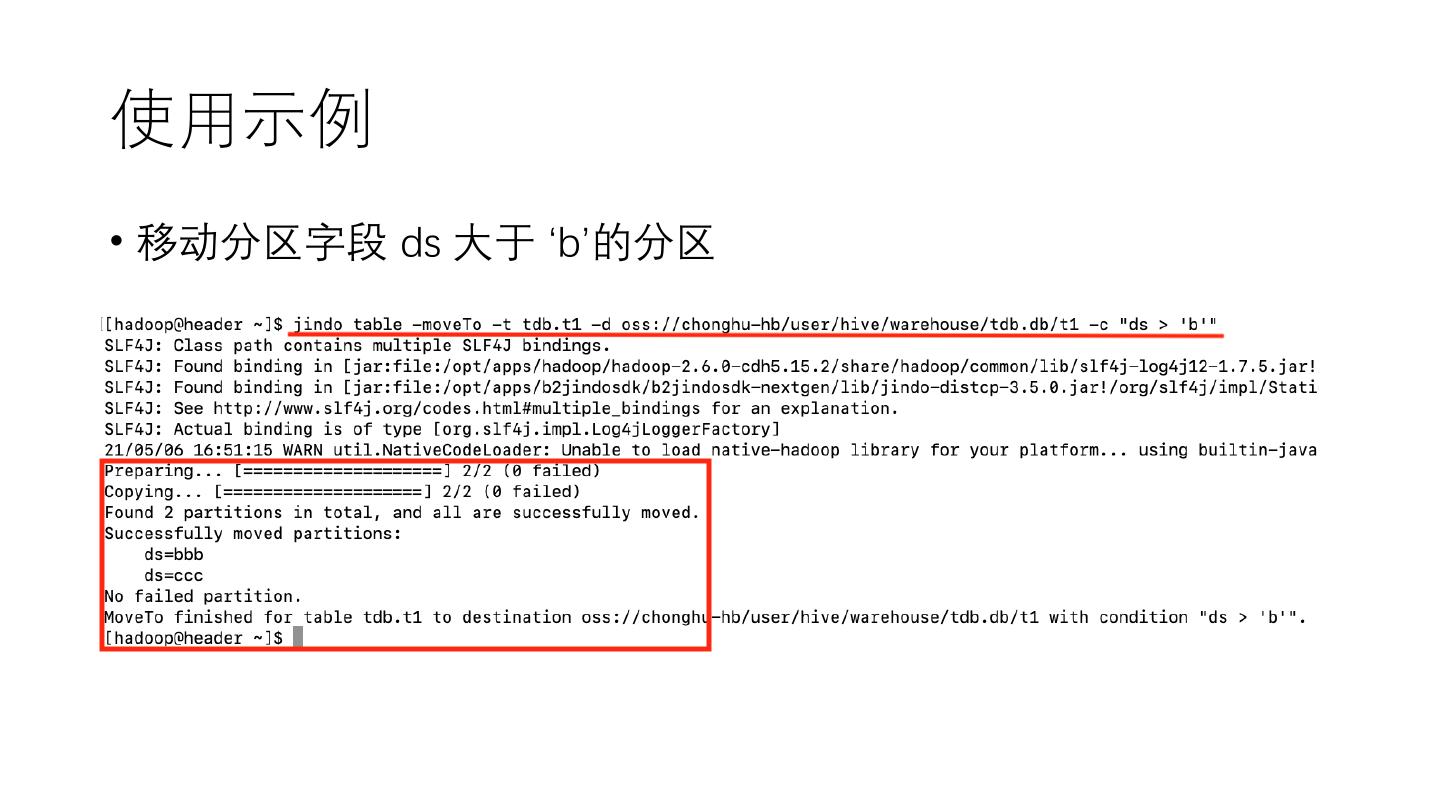
22 .使用示例
• 移动分区字段 ds 大于 ‘b’的分区
�
24 . E-MapReduce
| E-MapReduce | 对象存储OSS
每周二 16:00 锁定系列直播
▲ 欢迎钉钉扫码入群交流 ▲
�