展开查看详情
2 .Running Spark on Kubernetes:
Best practice and pitfalls
范振
阿里云计算平台事业部EMR团队-高级技术专家
�
3 .Agenda
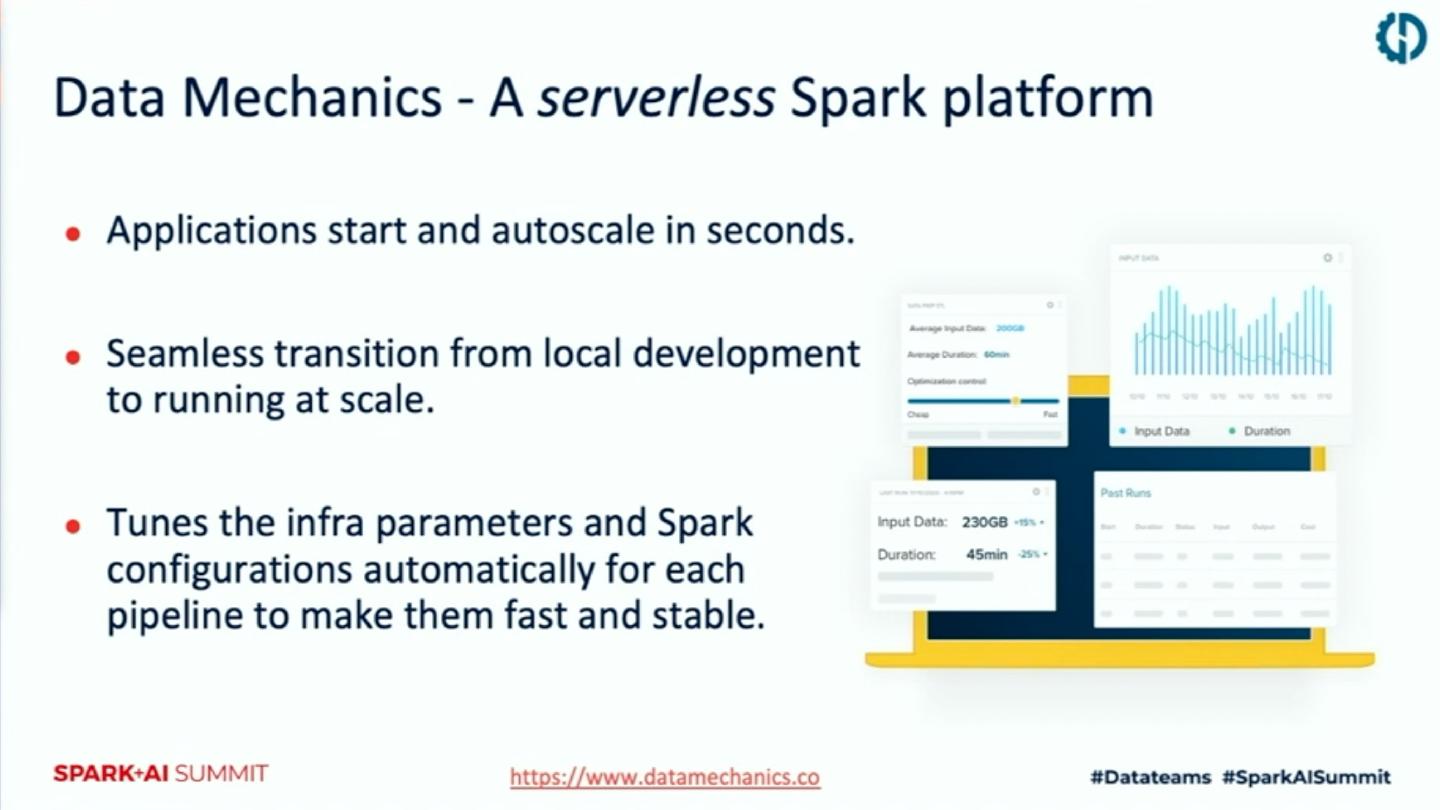
Data Mechanic平台介绍
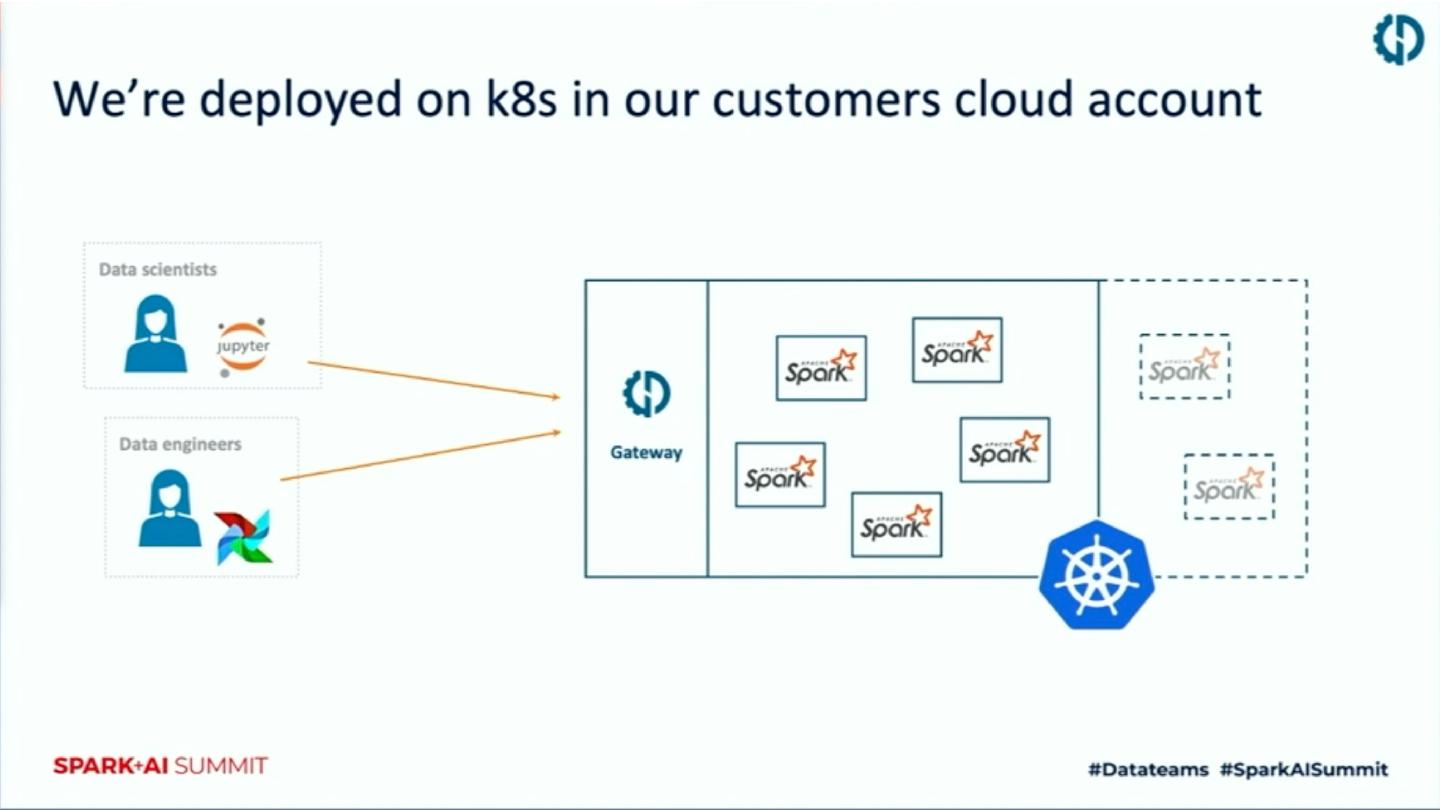
Spark on k8s
- 核心概念
- 配置&性能
- 监控&安全
- 未来工作
EMR团队云原生的思考和实践
�
5 .Who are you
▪ Bullet 1
▪ Sub-bullet
▪ Sub-bullet
▪ Bullet 2
▪ Sub-bullet
▪ Sub-bullet
▪ Bullet 3
▪ Sub-bullet
▪ Sub-bullet
�
6 .Reduce Long Titles
By splitting them into a short title, and a more detailed subtitle using this slide format that includes a
subtitle area
▪ Bullet 1
▪ Sub-bullet
▪ Sub-bullet
▪ Bullet 2
▪ Sub-bullet
▪ Sub-bullet
�
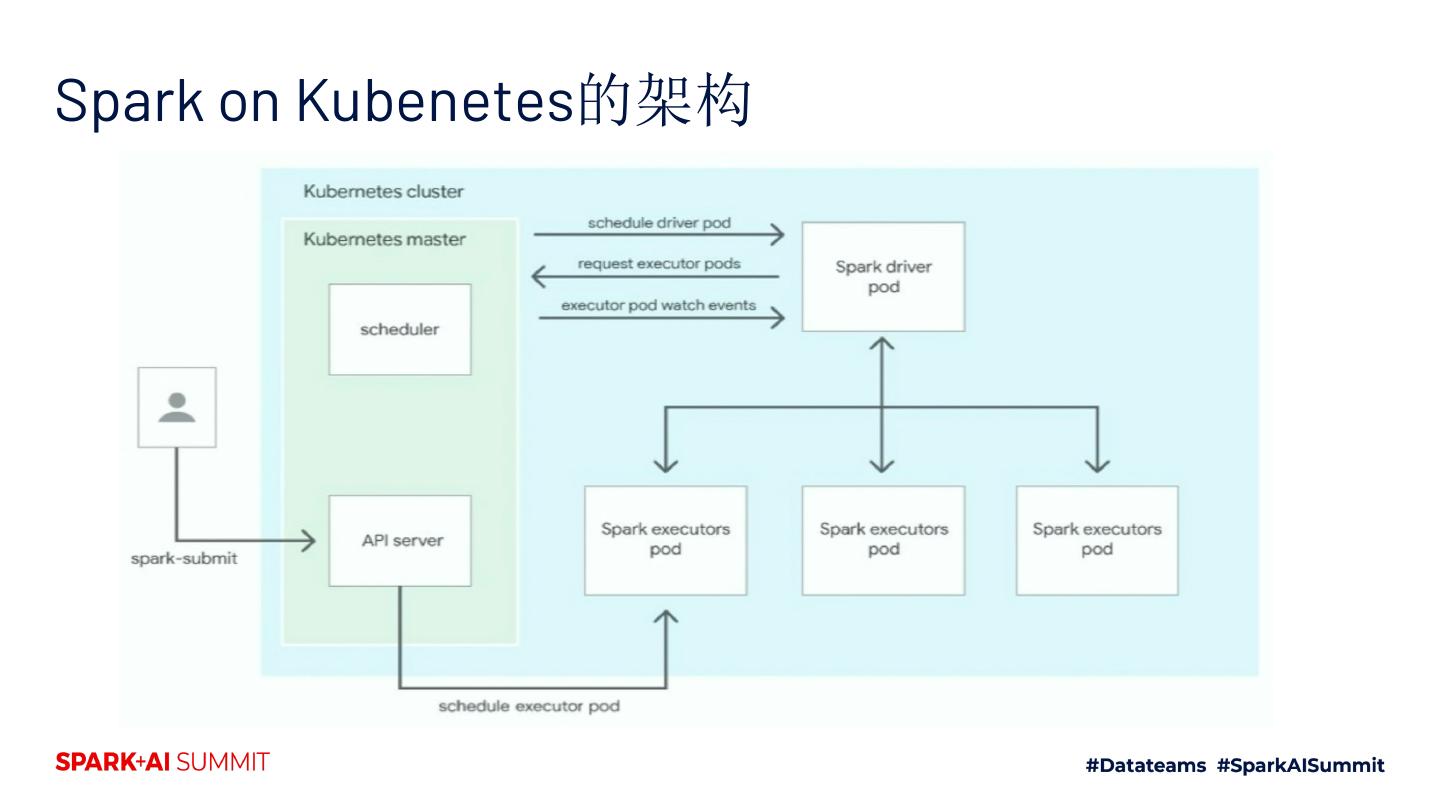
8 .Kubernetes和spark的结合
▪ Standalone
▪ Apache mesos
▪ Yarn
▪ Kubernetes
�
10 .提交Application的两种方式
Spark submit Spark-on-k8s operator
▪ 通过--conf进行参数配置,包括spark ▪ Google开源
内核的参数和k8s相关的参数 https://github.com/GoogleCloudPlat
▪ Spark3.0之前,关于个性化的配置比 form/spark-on-k8s-operator
较少 ▪ 通过yaml方式提交,每一个app对应
▪ App的管理不方便 一个yaml
▪ K8s Operator云原生方式部署
▪ 提供了一些kill、list、restart、
reschedule等命令
�
11 .依赖管理
Yarn kubernetes
▪ 缺少环境隔离 ▪ 完全环境隔离
▪ 全局的spark版本 ▪ 每一个application可以跑在完全不同的
环境、版本等
▪ 全局的python版本
▪ K8s Operator云原生方式部署
▪ 全局的包依赖
▪ 包管理方案
▪ 包管理方案 ▪ 自己管理镜像仓库
▪ 上传依赖包到HDFS ▪ 将依赖包打入image中
▪ 支持包依赖管理,将包上传到
OSS/HDFS
▪ 区分不同级别任务,混合使用以上两种
模式
�
13 .配置spark executors的小坑
假设k8s node为16G-RAM,4-core的ECS
下面的配置会一个executor都申请不到~!
▪ spark.executor.cores=4
▪ spark.executor.memory=11g
�
14 .K8s aware executor sizing
▪ 发生了什么?
▪ Spark pod只能按照node资源的一定比例来申请资源
▪ spark.executor.cores=4占用了node cores全部资源
▪ 计算可用资源
▪ 预估node allocatable 95%
▪ Daemonsets的资源占用(say 10%)
▪ 85%的pods可用资源
▪ 配置资源
▪ spark.executor.cores=4
▪ spark.kubernetes.executor.request.cores=3400m
�
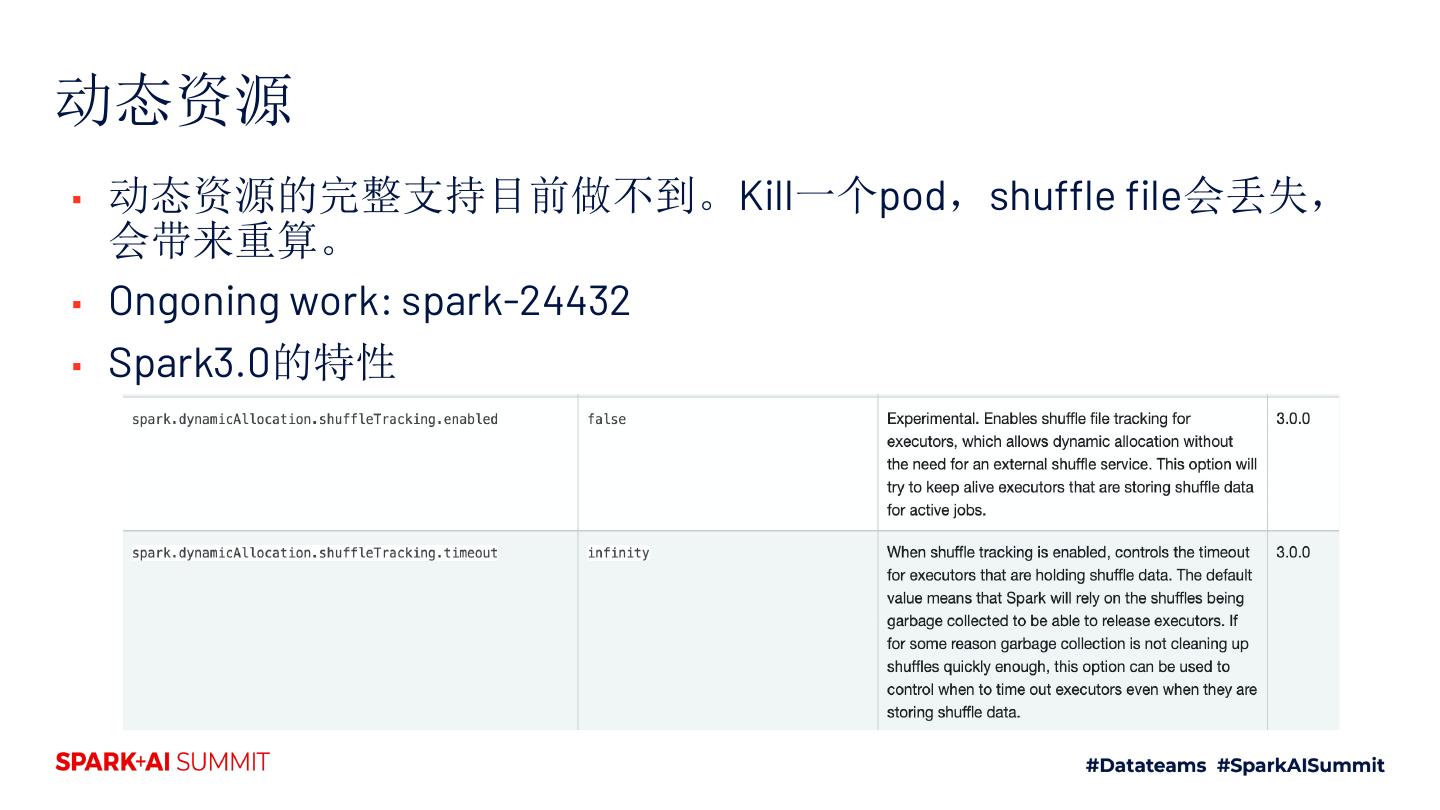
15 .动态资源
▪ 动态资源的完整支持目前做不到。Kill一个pod,shuffle file会丢失,
会带来重算。
▪ Ongoning work: spark-24432
▪ Spark3.0的特性
�
16 .Cluster autoscaling & dynamic allocation
▪ k8s cluster autoscaler:当pod处于pending
状态不能被分配资源时,扩展node节点
▪ Autoscaling和动态资源配合起来工作:
▪ 当有资源时,executor会在10s内注册到driver
▪ 当没有资源时,先通过autoscaling添加ECS资源,再申请
executors
▪ 大约在1min~2min内完成executor申请过程
▪ Aliyun ACK/ASK,AWS EKS,GOOGLE GCP,
AZURE AKS都有该功能,需要安装autoscaler
https://github.com/kubernetes/autoscaler
�
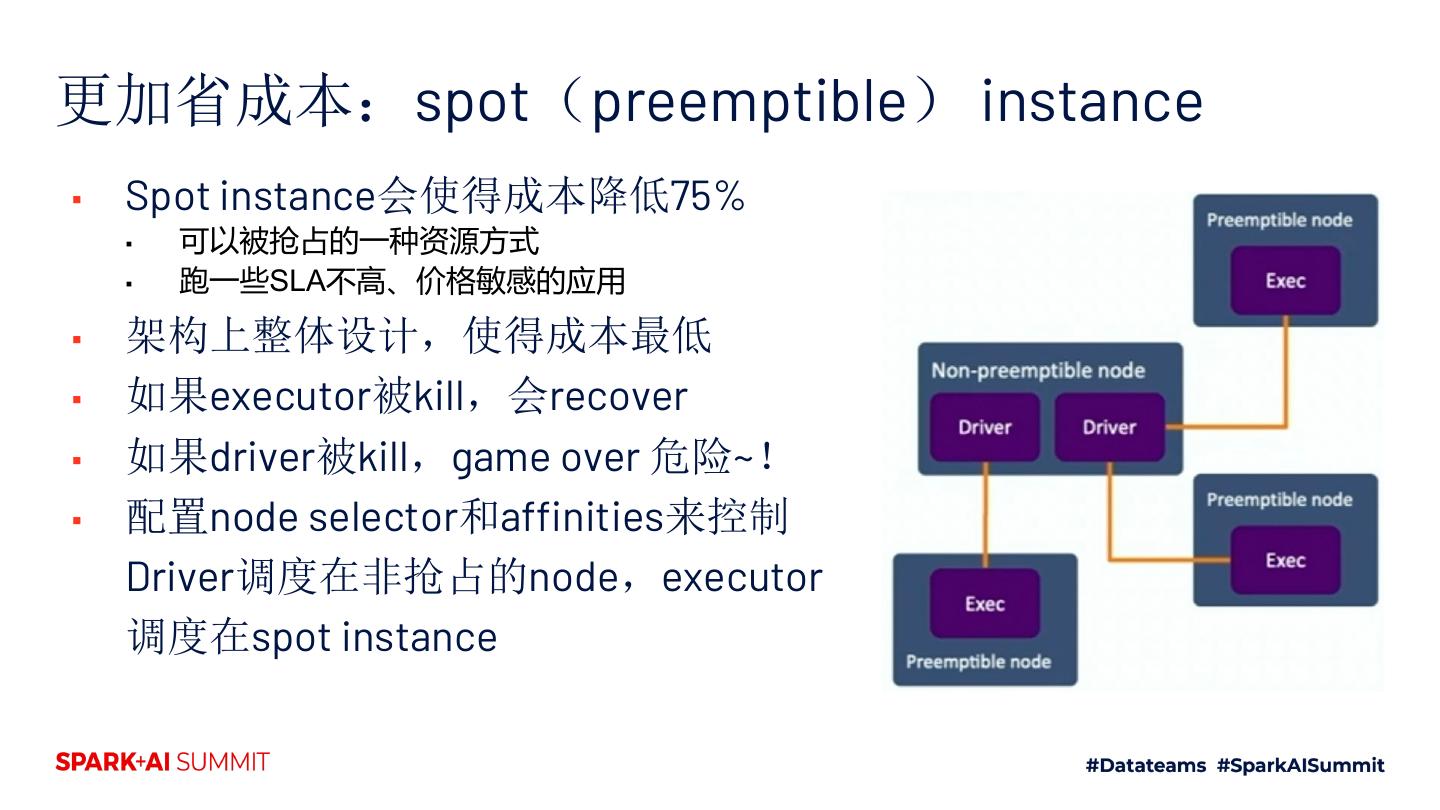
17 .更加省成本:spot(preemptible) instance
▪ Spot instance会使得成本降低75%
▪ 可以被抢占的一种资源方式
▪ 跑一些SLA不高、价格敏感的应用
▪ 架构上整体设计,使得成本最低
▪ 如果executor被kill,会recover
▪ 如果driver被kill,game over 危险~!
▪ 配置node selector和affinities来控制
Driver调度在非抢占的node,executor
调度在spot instance
�
18 .对象存储的IO问题
▪ Spark on k8s通常都是针对对象存储(OSS,S3,WASB)
▪ rename,list,commit task/job会非常费时
▪ S3A committers,Jindofs JobCommitter
▪ 如果没有以上的committer,应该设置
▪ spark.hadoop.mapreduce.fileoutputcommitter.algorithm.version=2
▪ 之前EMR团队给过一些介绍
▪ 阿里云客户需求:
▪ 打通ACK与EMR集群可以读写EMR的HDFS
�
19 .Shuffle性能
▪ I/O性能是shuffle bound workload的关键点,spark2.x版本用docker
file system(可以配置成emptydir)
▪ Docker file system是非常慢的,需要用volume来代替
▪ emptyDir:3.0的默认方式
▪ Hostpath:可以利用宿主机的快速磁盘(nvme-based SDD)
▪ Tmpfs:利用ram,危险
�
21 .Spark history server&metrics
▪ 配置spark.eventLog.dir到对象存储S3/WASB/OSS等
▪ 通过helm安装spark history server
▪ Prometheus jmx exporter
▪ Native support for Prometheus
�
24 .Future works
▪ Shuffle提升:中间数据的存储与计算分离
▪ Spark-25299
▪ Enable完整的动态资源特性
▪ Spark容忍executor pod和node级别的lost
▪ Facebook cosco
▪ Aliyun EMR jindo shuffle service
▪ Node decommission
▪ Spark-20624
▪ Copy shuffle data和cache data
▪ 支持上传python依赖文件
▪ Spark-27936
▪ Job queue&资源管理
�
25 .We choose Kubernetes, should you
Pors Cons
▪ 云原生扩缩容,天然容器隔离性 ▪ 需要学习Kubernetes
▪ 所有技术栈统一为Kubernetes ▪ 大规模调度性能、启动性能受限
▪ 在线离线服务统一调度 ▪ Shuffle & 动态资源
▪ 成本更低
▪ 运维一致性
�
26 .部署spark on k8s checklist
▪ Setup the infrastructure
▪ 建立k8s cluster
▪ 部署spark operator
▪ 准备spark镜像
▪ 部署spark history service
▪ 部署log系统、Prometheus for monitor and metrics
▪ Config your apps for success
▪ 配置好node池子,包括node labels等,确定好executor pod的规格打下
▪ 配置好IO相关的jar,包括对象存储file committer等,配置好对应的volumes
▪ 可选:配置好k8s cluster autoscaling,动态资源等
▪ 可选:Spot instance等相关配置以节省成本
▪ Enjoy the Ride!
�
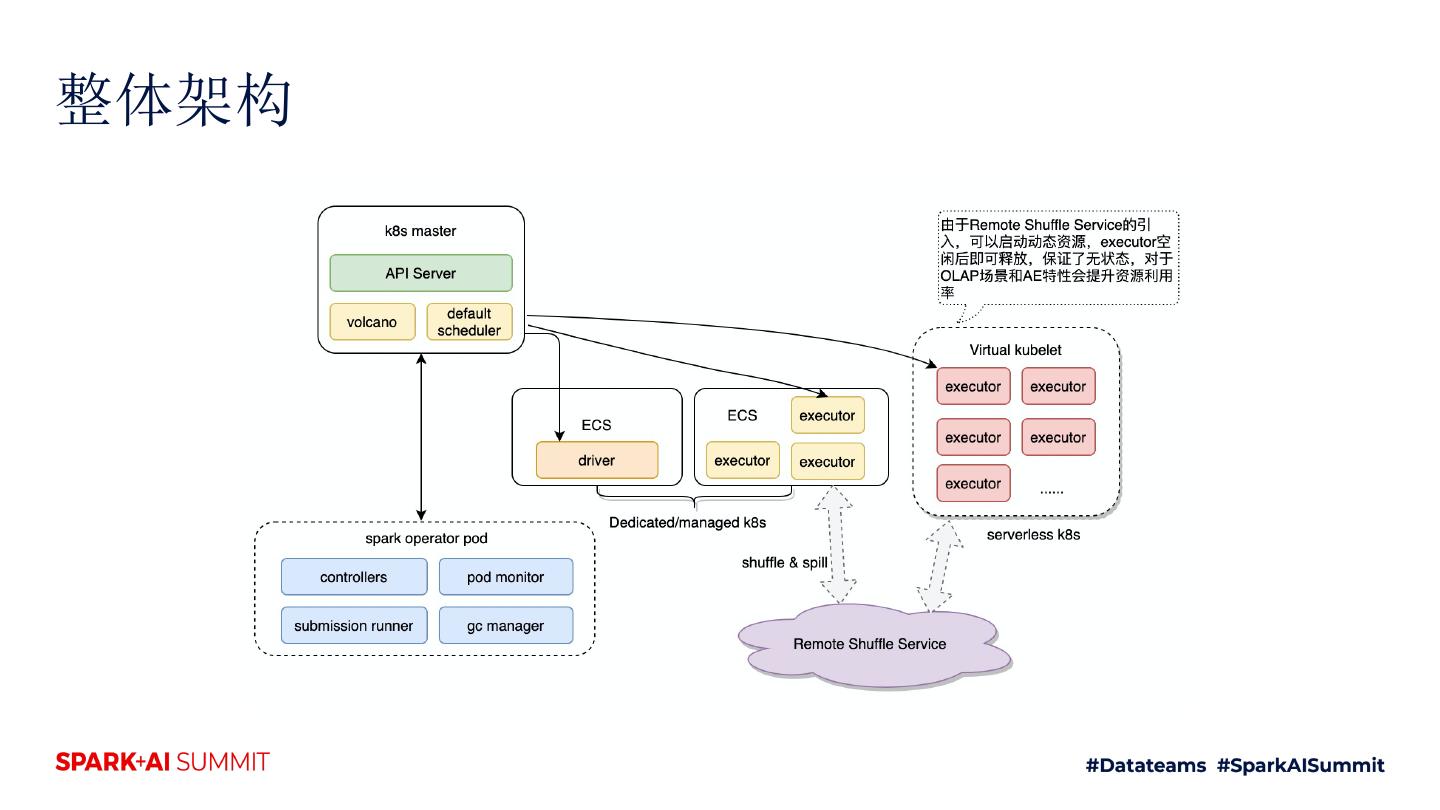
29 .动态资源&shuffle提升 — jindo shuffle service
Shuffle service解决核心问题:
▪ 解决动态资源问题
▪ 解决挂载云盘贵,事前不确定大小的痛点
▪ 解决NAS作为中心存储的扩展性以及性能问题
▪ 避免task由于fetch失败重新计算的问题,提升中大作业的稳定性
▪ 通过Tiered存储提升作业性能
�